
Нейросети в трейдинге: Масштабируемые трансформеры со структурной декомпозицией признаков (Окончание)

Введение
Развитие алгоритмического трейдинга всегда шло по пути усложнения моделей. От простых линейных регрессий и скользящих средних — к ансамблям, от ансамблей — к глубоким нейронным сетям, от рекуррентных архитектур — к механизмам внимания и трансформерам. Каждый виток сопровождался надеждой на устойчивое преимущество. И каждый виток в конечном итоге упирался в одну и ту же реальность — рынок сложнее, чем кажется на обучающей выборке.
Глубокие модели, особенно трансформеры, выглядят чрезвычайно привлекательно. Они способны моделировать дальние зависимости, работать с высокоразмерными исходными данными, выявлять сложные нелинейные структуры. Однако их успех в обработке текста и изображений не гарантирует аналогичного результата в финансовых временных рядах. Причина не в мощности архитектуры, а в природе данных.
Финансовый рынок — это система с изменяющейся статистикой. Корреляционные структуры непостоянны, волатильность кластеризуется, режимы чередуются, а значимость одного и того же признака может радикально меняться в зависимости от контекста. Более того, существенная часть наблюдаемых зависимостей носит временный характер. Модель, обладающая высокой гибкостью, легко подстраивается под исторические закономерности, но столь же легко фиксирует шум.
Именно здесь возникает типичная ситуация, знакомая большинству алготрейдеров-разработчиков. Модель демонстрирует убедительный результат на обучении, адекватный — на валидации, а затем постепенно теряет устойчивость при эксплуатации. Out-of-sample показатели начинают дрейфовать, поведение сигналов становится менее предсказуемым, а чувствительность к краткосрочным всплескам волатильности усиливается. Попытки решить проблему через увеличение числа признаков или глубины модели лишь повышают вычислительную нагрузку и усложняют обучение, не устраняя фундаментального источника нестабильности.
В определённый момент становится очевидно, что проблема лежит не только в данных или процедуре кросс-валидации. Она может быть связана с самой архитектурной парадигмой.
Классический Self-Attention изначально создавался для однородных данных. Каждый элемент анализируемой последовательности рассматривается как равноправный токен, и модель самостоятельно определяет структуру взаимодействий. Для текстов это естественно: слова формируют предложения, предложения — абзацы, и внимание действительно может распределяться свободно. В финансовых данных ситуация иная. Признаки обладают различной семантической природой. Цена и объём — не то же самое, что производные индикаторы. Временные компоненты отличаются от рыночных агрегатов. Их статистические свойства различны, а их взаимодействия не должны быть полностью произвольными.
Когда модель не получает явной структурной информации, она вынуждена извлекать её из данных. В условиях высокой размерности и ограниченного объёма истории это увеличивает риск фиксации случайных зависимостей. Внимание может перераспределяться в пользу временно коррелирующих признаков, формируя иллюзию закономерности. На обучении это выглядит как успех, на реальном рынке — как деградация.
Field-Aware Transformer был предложен как попытка системно решить эту проблему. Его центральная идея проста, но принципиальна: признаки должны быть организованы в поля, отражающие их семантическую и статистическую природу. Архитектура не должна быть полностью слепой к структуре исходных данных. Напротив, она должна учитывать её изначально.
Полеориентированная свёртка формирует компактные представления внутри каждого поля, снижая избыточность и стабилизируя распределения. Далее многоголовое внимание строится с учётом границ полей и контролируемых взаимодействий между ними. Таким образом, пространство внимания ограничивается осмысленной структурой, что уменьшает вероятность спонтанных кросс-зависимостей и повышает управляемость модели.
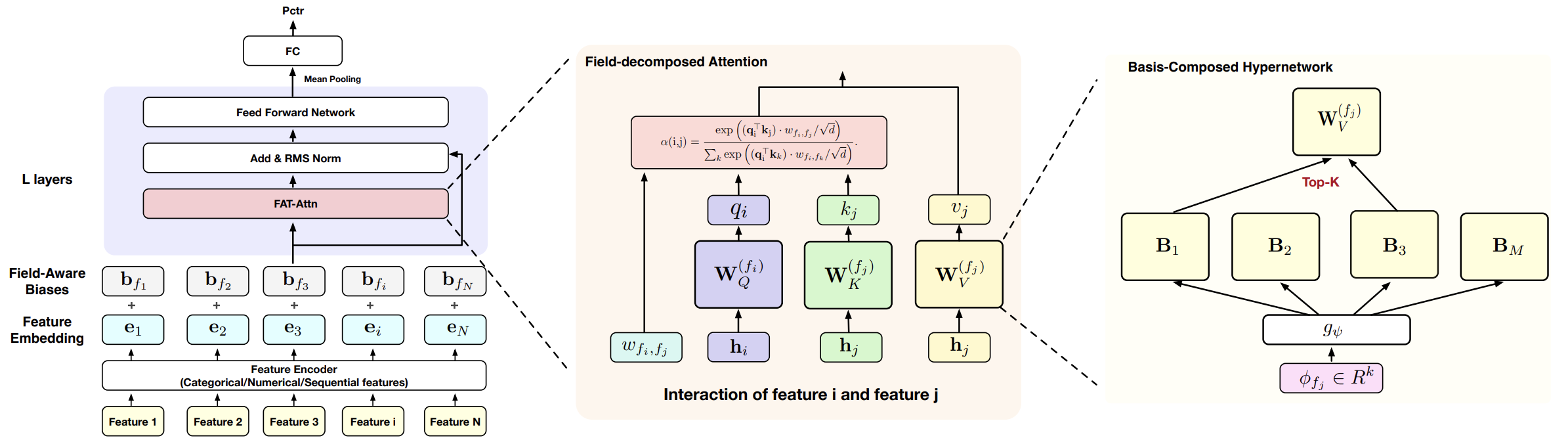
В предыдущих статьях была выполнена инженерная реализация этих принципов средствами MQL5 с использованием OpenCL. Мы детально разобрали архитектуру модулей, логику прямого и обратного прохода. Этот этап имел фундаментальное значение. Без детерминированной, оптимизированной и контролируемой реализации невозможно переходить к практической оценке.
Однако сама по себе корректная реализация ещё не отвечает на главный вопрос: оправдано ли архитектурное усложнение с точки зрения торговой системы?
Алготрейдер-разработчик, интегрирующий нейросетевой модуль в торгового агента, оценивает его не по числу параметров и не по элегантности кода. Его интересуют поведенческие характеристики. Станет ли система менее чувствительной к смене режима? Снизится ли склонность к переобучению? Будет ли модель демонстрировать более согласованную динамику прогнозов? Улучшится ли устойчивость результатов вне обучающего окна?
Кроме того, существует и вычислительный аспект. Реальные торговые платформы накладывают ограничения на латентность и ресурсы. Использование OpenCL позволяет вынести тяжёлые операции на GPU, сохраняя детерминированность и управляемость.
Наш проект развивается как инфраструктурная платформа. Его цель — создать управляемую, масштабируемую и детерминированную архитектуру для финансовых временных рядов.
Объект кодирования паттернов
В предыдущих статьях мы последовательно выстраивали архитектурный каркас фреймворка FAT. Сначала разобрали его концептуальную основу, затем перешли к инженерной реализации ключевых модулей — полеориентированной свёртки и многоголового внимания с учётом структуры полей. По сути, был построен рабочий механизм обработки и агрегации информации.
Но любой механизм начинается не с обработки, а с входа. Именно здесь возникает вопрос, который нельзя обходить стороной: каким должно быть представление исходных данных? Каким образом формируется эмбеддинг? И насколько он соответствует идее структурированной модели?
Авторы оригинального фреймворка FAT сознательно не навязывают конкретный алгоритм эмбеддинга. Это принципиальная позиция. Архитектура задаёт способ взаимодействия полей, но не ограничивает способ их первичного представления. При этом подчёркивается важное требование — эмбеддинг должен быть контекстно-зависимым. Иначе говоря, он не может быть универсальной линейной проекцией, одинаково применяемой к любым данным. Более того, допускается использование различных алгоритмов эмбеддинга для разных полей, если их контекст отличается. Это ключевой момент.
Финансовые данные неоднородны не только на уровне взаимодействий, но и на уровне первичного смысла. Цена несёт один тип информации, объём — другой, индикаторы — третий, временные признаки — четвёртый. Попытка описать всё единым алгоритмом преобразования выглядит удобной с точки зрения реализации, но стратегически это компромисс.
В наших предыдущих проектах мы традиционно использовали свёрточные слои для генерации эмбеддингов. Это логично: свёртка хорошо извлекает локальные зависимости, сглаживает шум, формирует компактные представления. Такой подход дисциплинирован и вычислительно эффективен. Однако у него есть ограничение — все поля обрабатываются по одной и той же схеме. Фактически мы навязываем рынку гипотезу о том, что природа локальных закономерностей одинакова для всех типов данных. И вот здесь возникает та же проблема, с которой мы боролись на уровне attention. Мы снова возвращаемся к универсальности там, где нужна дифференцируемость.
Объект полеориентированной свёртки частично сглаживает эту ситуацию, позволяя учитывать принадлежность признаков к разным полям. Но по своей сути он всё равно остаётся линейным отображением входа в пространство представлений. Эмбеддинг в этом случае напрямую зависит от текущих значений анализируемых данных и их локальной структуры. Это удобно математически, но не всегда удобно концептуально.
Рынок редко ведёт себя линейно. Он формирует повторяющиеся конфигурации, режимные комбинации, характерные рисунки поведения. Опытный трейдер, работающий вручную, мыслит не в терминах линейных проекций, а в терминах паттернов. Он видит ускорение, сжатие волатильности, ложный пробой, разворотную структуру. Его решение опирается не на отдельное значение индикатора, а на конфигурацию признаков во времени.
Если мы строим архитектуру, которая стремится к устойчивости и интерпретируемости, логично задать себе вопрос: почему бы не приблизить этап эмбеддинга к этой логике?
Именно поэтому в рамках развития проекта мы пошли на шаг дальше. По аналогии с ручными стратегиями был разработан объект паттерно-ориентированного эмбеддинга. Его задача — не просто сжать анализируемые данные в компактный вектор, а выделить устойчивые конфигурации поведения внутри каждого поля.
Вместо прямой линейной зависимости эмбеддинга от текущих значений формируется представление, чувствительное к характерным структурным комбинациям. Важно подчеркнуть, что речь не идёт о ручной фиксации конкретных торговых паттернов. Мы не возвращаемся к жёстким правилам, мы формируем механизм, способный выделять конфигурации, близкие по структуре, и кодировать их в устойчивом пространстве признаков. Иначе говоря, мы переносим идею паттерна в уровень представления данных, не нарушая общей нейросетевой парадигмы.
Это решение имеет несколько стратегических последствий. Во-первых, эмбеддинг становится менее чувствительным к мелкому шуму. Поскольку кодируется конфигурация, а не отдельное значение. Случайные отклонения оказывают меньший эффект.
Во-вторых, появляется дополнительный уровень нелинейности до этапа внимания. Attention-механизм получает на вход уже структурированное пространство, в котором взаимодействуют поведенческие представления.
В-третьих, возникает возможность действительно дифференцировать поля. Для одного поля может быть целесообразен более динамический паттерн, для другого — более сглаженный, для третьего — ориентированный на относительные соотношения. Архитектура FAT это допускает, а паттерно-ориентированный эмбеддинг делает такую гибкость практически реализуемой.
Описанные идеи воплощаются в отдельный объект — CNeuronFieldPatternEmbedding. Это полноценный нейронный модуль, встроенный в общую иерархию.
class CNeuronFieldPatternEmbedding : public CNeuronBaseOCL { protected: uint iFields; uint iWindow; CParams cCandidates; CLayer cScore; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronFieldPatternEmbedding(void) {}; ~CNeuronFieldPatternEmbedding(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronFieldPatternEmbedding; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual uint GetFiedls(void) const { return iFields; } };
Структурно класс аккуратно отражает логику поставленной задачи. Параметр iFields фиксирует количество анализируемых полей. Мы заранее задаём, сколько независимых контекстов будет обрабатываться. Параметр iWindow определяет глубину временного окна, внутри которого формируется паттерн. Иными словами, эмбеддинг не видит одиночную точку, он анализирует локальную конфигурацию поведения.
Далее появляются два ключевых внутренних объекта — cCandidates и cScore. Первый отвечает за формирование набора паттернов-кандидатов, второй — за их оценку и ранжирование. Здесь и реализуется переход от линейного преобразования к структурному отбору. Вместо того чтобы просто умножить вход на матрицу весов, модель генерирует несколько возможных представлений и выбирает наиболее релевантные в текущем контексте. Параметры candidates и topK, передаваемые при инициализации, позволяют управлять этим процессом. Мы не жёстко фиксируем единственный вариант эмбеддинга, а допускаем конкуренцию паттернов внутри поля.
Метод инициализации — это сердце паттерн-ориентированного эмбеддинга. Представьте, что вы запускаете торговую стратегию. Сначала вы готовите инструменты, потом оцениваете варианты сценариев и только после этого принимаете решение о сделке. Здесь всё устроено аналогично.
bool CNeuronFieldPatternEmbedding::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, embed_size * fields, optimization_type, batch)) ReturnFalse;
На вход методу подаются все ключевые параметры: размер окна анализа, количество полей, размер эмбеддинга, число кандидатов, Top-K. Каждое значение задаёт правила игры. Размер окна определяет, насколько широко смотрит слой на локальный паттерн. Число полей фиксирует дисциплину модели. Top-K регулирует, сколько сценариев допускается в итоговой комбинации. Всё это позволяет точно настроить чувствительность эмбеддинга к структуре данных.
Первым делом мы вызываем одноименный метод родительского класса. Это фундамент. Размер результатов задаётся как embed_size * fields, и благодаря этому каждое поле остаётся независимым — ни один паттерн не смешивается с другим. Если базовая инициализация не удаётся, метод немедленно завершает работу. Никаких полуготовых решений. Система либо собрана корректно, либо не запускается.
Следующий этап — формирование библиотеки кандидатов cCandidates. Здесь создаётся фиксированное число обучаемых векторов, каждый из которых в будущем сможет представлять определённый тип паттерна.
uint index = 0; if(!cCandidates.Init(0, index, OpenCL, embed_size * candidates, optimization, iBatch)) ReturnFalse; cCandidates.SetActivationFunction(None);
Пока что активация отключена. На этом шаге мы не оцениваем входные данные, а просто готовим набор гипотез. Это как если бы вы подготовили несколько торговых сценариев перед открытием рынка — вариантов больше, чем реально потребуется, но они все важны для анализа.
Далее внимание к блоку оценки cScore. Он — наш аналитический комитет. Сначала структура очищается, затем назначается OpenCL-контекст.
index++; cScore.Clear(); cScore.SetOpenCL(OpenCL);
Внутри создаются два последовательных сверточных слоя. Первый расширяет пространство признаков до 4 * candidates, извлекая структурные сигналы из паттерна, а второй сжимает это пространство обратно к числу кандидатов, формируя компактную и сравнимую оценку каждого сценария.
CNeuronConvOCL* conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, window, window, 4 * candidates, fields, 1, optimization, iBatch) || !cScore.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SoftPlus); index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, 4 * candidates, 4 * candidates, candidates, fields, 1, optimization, iBatch) || !cScore.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SoftPlus);
Активация SoftPlus обеспечивает плавность градиентов — слой учится стабильно, без резких скачков. Как опытный трейдер, который аккуратно взвешивает сигнал.
Финальный элемент — CNeuronSparseSoftMax. Здесь паттерн проходит фильтр. Вычисляются вероятности, с которыми текущий паттерн принадлежит каждому кандидату, и одновременно оставляются только Top-K наиболее релевантных кандидатов.
index++; CNeuronSparseSoftMax* softmax = new CNeuronSparseSoftMax(); if(!softmax || !softmax.Init(0, index, OpenCL, fields, candidates, topK, optimization, iBatch) || !cScore.Add(softmax)) DeleteObjAndFalse(softmax); iFields = fields; //--- return true; }
Это ключевой момент. Эмбеддинг формируется как взвешенная комбинация лучших обучаемых кандидатов. Анализируемые данные уже не определяют результат напрямую — они лишь указывают, какой из обученных паттернов лучше подходит. Можно сказать, что слой проводит расследование: полученные признаки анализируются, кандидаты оцениваются, а результат объединяется в структурированное представление.
Таким образом, инициализации — это настоящий процесс настройки интеллектуальной системы, которая способна выявлять паттерны, оценивать их по заранее обученным сценариям и создавать устойчивое структурное представление данных.
Метод прямого прохода — это ключевой этап работы любого объекта. В данном случае он превращает анализируемый паттерн данных в эмбеддинг через оценку кандидатов и Top-K селекцию. Процесс можно представить как многоэтапную экспертизу каждого паттерна.
bool CNeuronFieldPatternEmbedding::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain) if(!cCandidates.FeedForward()) ReturnFalse;
Сначала идёт проверка режима обучения. В процессе обучения выполняется прямой проход по объекту cCandidates — нашей библиотеке обучаемых векторов. Он гарантирует, что их внутренние состояния актуальны. Если что-то идёт не так — сразу возвращаем false. Это страхует от неполной или некорректной активации.
Далее начинается последовательное прохождение блока оценки cScore. Мы заводим два указателя: prev и curr. Первый (prev) указывает на предыдущий активный слой, curr — на текущий.
CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cScore.Total(); i++) { curr = cScore[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Цикл перебирает все слои внутри cScore (два сверточных слоя + SparseSoftMax) и вызывает метод прямого прохода для каждого, передавая результат предыдущего слоя. Если какой-либо слой не прошёл прямой проход, метод возвращает false. Таким образом, мы гарантируем корректную последовательную обработку паттерна через всю цепочку оценки.
После завершения цикла проверяем тип последнего слоя. Ожидается SparseSoftMax. Это критично, потому что именно он формирует распределение вероятностей принадлежности паттерна к кандидатам.
if(prev.Type() != defNeuronSparseSoftMax) ReturnFalse; CNeuronSparseSoftMax* softmax = prev; uint topK = softmax.DimensionOut(); uint params_to_field = Neurons() / iFields; uint candidates = cCandidates.Neurons() / params_to_field;
Далее идёт магия Top-K. Основная операция — вызов SparseMatMul. Она делает то, что и делает смысл паттерн-ориентированного эмбеддинга. Берёт разреженные индексы Top-K от SparseSoftMax, умножает их на матрицу обучаемых кандидатов cCandidates. Тем самым формирует итоговый эмбеддинг для каждого поля.
if(!SparseMatMul(softmax.GetIndexes(), softmax.getOutput(), cCandidates.getOutput(), Output, iFields, topK, candidates, params_to_field)) ReturnFalse; dActivation(this); //--- return true; }
Таким образом, каждый анализируемый паттерн получает комбинацию обученных кандидатов, взвешенную вероятностями из SoftMax, и при этом зависимость эмбеддинга от исходных данных не является линейной. Это делает слой устойчивым к шуму и различным режимам рынка.
Наконец, вызывается финальная функция активации слоя, которая гарантирует корректное масштабирование выходного вектора перед передачей его следующему компоненту сети.
В результате метод прямого прохода полностью реализует три ключевых шага:
- Обновление состояния обучаемых кандидатов (если тренируем).
- Последовательная оценка входного паттерна через сверточные слои и SparseSoftMax.
- Формирование итогового эмбеддинга через взвешенную комбинацию Top-K кандидатов.
Именно этот метод превращает исходные данные в структурированное, обучаемое и устойчивое представление для дальнейшего внимания и принятия решений в FAT.
Важно и то, что вся архитектура изначально строится поверх OpenCL. Это означает масштабируемость. Мы не ограничены лабораторными экспериментами. Решение рассчитано на практическую нагрузку. На поток данных. На реальную инфраструктуру.
Если сравнить этот подход с классическим сверточным эмбеддингом, разница становится очевидной. Обычная свёртка — это единый алгоритм для всех полей. Да, она может учитывать поле-ориентированность через специальные модификации. Но логика остаётся линейной: вход — фильтр — выход. Здесь же мы формируем пространство паттернов, оцениваем их и лишь затем агрегируем результат. Это уже двухэтапная модель принятия решения.
По сути, мы перенесли логику ручной стратегии в архитектуру нейронного слоя. Сначала формируются сценарии, затем они оцениваются, и только после этого формируется итоговое представление. Такой подход лучше соответствует природе рыночных данных. Он менее наивен и более устойчив к структурным сдвигам.
Именно поэтому CNeuronFieldPatternEmbedding — это шаг к более интеллектуальному представлению данных. Шаг от линейной обработки к структурному анализу. А в задачах, где важны нюансы и скрытые зависимости, это различие может оказаться решающим.
Важно подчеркнуть, что данный объект не заменяет полеориентированную свёртку, а расширяет идею структурности.
Архитектура моделей
Мы успешно завершили создание отдельных компонентов фреймворка FAT, и теперь настало время переходить к следующему этапу — формированию полноценной архитектуры обучаемых моделей. В рамках этого проекта мы, как и прежде, создаём торгового робота, способного самостоятельно анализировать рыночную ситуацию и принимать торговые решения.
При этом подходы, предложенные авторами FAT, мы интегрируем практически во все компоненты обучаемой модели. Это позволяет сохранять единую философию фреймворка.
В связи с этим стало необходимым полностью переработать архитектуру обучаемых моделей. Новый подход ориентирован на модульность и масштабируемость. Каждый компонент теперь интегрируется в общую сеть так, чтобы обеспечить корректное обучение и устойчивость к рыночным шумам.
Метод CreateDescriptions задаёт полную архитектуру обучаемой модели. В нем мы формируем слои для четырёх ключевых компонентов — энкодера состояния, STFS-блока, Актёра и Критика. Каждый из этих компонентов имеет свою роль в торговой системе.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&stfs, CArrayObj *&actor, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!stfs) { stfs = new CArrayObj(); if(!stfs) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Сначала метод проверяет, созданы ли массивы слоев для каждого компонента, и если нет — выделяет память. Это как подготовка строительной площадки: без прочного фундамента никакая архитектура не устоит.
Далее начинается формирование энкодера. Здесь мы видим постепенное расширение и обработку данных. Сначала создаётся базовый слой, принимающий анализируемые исторические бары.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer = 0;
Затем добавляются слои нормализации, транспонирования и, что особенно важно, слой CNeuronFieldPatternEmbedding. Именно он обеспечивает паттерн-ориентированное представление данных. Каждый анализируемый паттерн получает свой обучаемый эмбеддинг, а зависимость эмбеддинга от входа остаётся не линейной. Это делает модель устойчивой к рыночным шумам и изменению режимов.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFieldPatternEmbedding; descr.count = BarDescr; descr.window = HistoryBars; descr.window_out = HistoryBars; descr.layers = NExperts; descr.step = TopK; descr.batch = BatchSize; descr.activation = SoftPlus; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++;
Следующим шагом идут слои CNeuronFieldAwareConv и CNeuronResFlowLattice. Они расширяют возможности энкодера, позволяя сети захватывать локальные зависимости и строить прогнозы на основе сегментов и скрытых представлений. Это позволяет модели учиться выявлять структурные особенности рынка, сохраняя гибкость и масштабируемость.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFieldAwareConv; descr.count = BarDescr; { uint temp[] = {HistoryBars, // Inputs window HistoryBars, // Outputs window EmbeddingSize // Embedding size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.variables = NExperts; descr.step = TopK; descr.batch = BatchSize; descr.activation = SoftPlus; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResFlowLattice; descr.variables = 4; //HTR points to Segment descr.count = (NForecast + descr.variables - 1) / descr.variables; //LTR Forecast descr.window = BarDescr * HistoryBars; //Dimension In descr.window_out = EmbeddingSize; //Hidden dimension descr.layers = 3; //LTR layers descr.step = NExperts; //LTR candidates descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; //--- uint window = descr.window; uint count = descr.count * descr.variables;
Далее строится Актёр. Его архитектура впечатляет разнообразием слоев: от многоканальной свёртки до многолового внимания MHFAT и кросс-внимания MHCrossFAT. Каждый слой добавляет глубину анализа, позволяя роботу учитывать как локальные, так и глобальные рыночные паттерны, комбинируя их с историей позиций и состояния счёта.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvOCL; descr.count = 1; { uint temp[] = {4, // Account 5, // Position 4 // Time }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = EmbeddingSize; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFieldAwareConv; descr.count = 3; { uint temp[] = {EmbeddingSize, // Inputs window EmbeddingSize, // Outputs window EmbeddingSize // Embedding size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.variables = NExperts; descr.step = TopK; descr.batch = BatchSize; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMHFAT; { uint temp[] = {EmbeddingSize, // Inputs window EmbeddingSize, // Key Dimension EmbeddingSize // Embedding size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.count = 3; descr.step = NHeads; // Heads descr.batch = 1e4; descr.layers = NExperts; // Candidates descr.variables = TopK; // Top-K descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMHCrossFAT; { uint temp[] = {EmbeddingSize, // Inputs window EmbeddingSize, // Key Dimension window, // Cross window EmbeddingSize // Embedding size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {3, // Query units count // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = NHeads; // Heads descr.batch = 1e4; descr.layers = NExperts; // Candidates descr.variables = TopK; // Top-K descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Слои SpikeConv и базовые нейроны накапливают латентные представления и формируют окончательные сигналы действий.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeConvBlock; descr.count = 3; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = (LatentCount + 2) / 3; descr.variables = 1; descr.batch = BatchSize; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А VAE-слой придаёт модели способность к генерации устойчивых стратегий через латентное пространство.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Наконец, Критик получает аналогичную глубину: MHCrossFAT для оценки кросс-зависимостей, SpikeConv-блоки для агрегирования сигналов и базовые слои для окончательной оценки наград (NRewards). Таким образом, Критик вырабатывает меру качества каждого действия, позволяя Актёру корректировать стратегию.
В итоге метод CreateDescriptions формирует целостную архитектуру робота. Здесь каждая часть, от входного слоя до Критика, взаимосвязана, а данные проходят через паттерн-ориентированные эмбеддинги, полеориентированные свёртки и многоголовое внимание. Это инструмент, способный анализировать рынок, выявлять паттерны и принимать решения с учётом комплексного контекста, что является основой всех практических преимуществ фреймворка FAT.
Тестирование
Архитектура собрана, модули согласованы. Теперь важно проверить, как вся система ведёт себя в реальных рыночных условиях. Обучение стартовало на исторических данных EURUSD H1 за период с Января 2024 по Июнь 2025 года. Это была фаза базовой подготовки — своего рода тренировочный полигон. На этом этапе модель постепенно накапливала статистику поведения рынка, училась различать повторяющиеся структуры и формировала внутреннее представление динамики цены.
Именно здесь латентная решётчатая структура модели начала проявлять себя как связующее звено между прошлым, настоящим и будущим. Она фиксировала последовательность баров, выстраивала структурные зависимости, позволяя строить прогнозы на основе конфигурации рынка, а не отдельных значений. Это принципиально важный момент: модель обучалась понимать структуру движения, а не запоминать фрагменты истории.
Следующий этап — онлайн-обучение в тестере стратегий MetaTrader 5. Здесь система перешла в режим адаптации в реальном времени. Параметры корректировались по мере поступления новых данных, но при этом сохранялся накопленный опыт. Важно подчеркнуть: обновления не разрушали ранее сформированные представления. Архитектура позволяла мягко перестраивать внутренние оценки даже при резких импульсах и смене рыночного режима.
Латентная структура сохраняла целостность прогнозов, сглаживая локальные колебания и удерживая стратегическое направление анализа. Это и есть практическое проявление устойчивости модели: способность адаптироваться, не теряя внутренней логики.
Финальная проверка проводилась на новых данных за период с Июля по Декабрь 2025 года. Это был полноценный out-of-sample тест — без подстройки под уже изученные события.


Тестирование проводилось на депозите 100 USD, что позволяет рассматривать результаты в реальном денежном выражении. За период тестирования модель заработала 42.97 USD, увеличив капитал почти на 43%. Итоговый баланс составил 142.97 USD.
При этом стратегия не строится на высокой точности входов. Доля прибыльных сделок — около 48%, то есть убыточных даже немного больше. Преимущество создаётся через соотношение прибыли к риску. Средний выигрыш 6.79 USD против среднего убытка 4.98 USD. Именно эта асимметрия формирует математическое ожидание 0.64 USD на сделку. Модель не угадывает рынок — она дисциплинированно извлекает больше, чем отдаёт. Такой подход традиционно считается более устойчивым, чем попытка повысить точность любой ценой.
Риск-профиль остаётся умеренным. Максимальная просадка составила около 27%. Для депозита 100 USD это чувствительно, но важно понимать масштаб. При большем капитале относительные показатели сохраняются, меняется лишь абсолютная величина. При этом нагрузка на депозит не превышала 25%, а уровень маржи оставался комфортным. Система не работала на пределе возможностей счёта, сохраняя запас прочности.
В целом результаты показывают сбалансированную архитектуру — положительное математическое ожидание, умеренный риск и способность адаптироваться к разным фазам рынка.
Да, есть зоны для оптимизации — прежде всего сглаживание просадок и повышение коэффициента восстановления.
Заключение
В рамках данного проекта нам удалось построить архитектуру обучаемой торговой модели, интегрировать ключевые механизмы адаптации и протестировать систему на реальных исторических данных без подгонки под будущие события. Результат — положительное математическое ожидание, структурно согласованные метрики и рабочая динамика капитала.
Мы показали, как структурировать исходные данные по полям, как встроить ограничение внимания на уровне самой модели, как реализовать Field-Aware свёртку и многофакторное внимание в MQL5 без потери управляемости вычислений. Мы построили инженерный каркас: классы, инициализацию, прямой проход, OpenCL-ядро, логику масштабирования и обратного распространения. Архитектура стала детерминированной, контролируемой и масштабируемой.
Именно здесь проявляется преимущество фреймворка FAT. Он вводит структурные ограничения, которые снижают избыточность, стабилизируют обучение и делают поведение модели предсказуемым при смене рыночного режима. Attention перестаёт быть всё со всем и начинает учитывать природу данных: цены, объёмы, индикаторы, производные признаки. Это изменение геометрии представления рынка внутри модели.
Ссылки
- From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Добрый день, Дмитрий!
Скомпелировал и попробовал приложения - всё работает в любых сочетаниях!