
Нейросети в трейдинге: Единая архитектура взаимодействия рыночных признаков и торгового контекста (OneTrans)

Введение
Финансовые рынки традиционно рассматриваются как последовательность наблюдений. Цена меняется во времени, формируя временной ряд, и именно этот ряд становится основным объектом анализа для большинства алгоритмических моделей. Нейронные сети, статистические методы и современные архитектуры глубокого обучения в подавляющем большинстве случаев решают одну и ту же задачу — пытаются выявить закономерности в динамике рынка и на основе этих закономерностей сформировать прогноз дальнейшего движения цены.
Подобный подход логичен и хорошо укоренился в практике алгоритмической торговли. В распоряжении исследователя находятся исторические данные рынка. На их основе формируется набор признаков, после чего обучаемая модель пытается установить связи между прошлым и будущим состоянием рынка. С точки зрения машинного обучения задача выглядит достаточно естественно. Рынок представляется как поток данных, который необходимо проанализировать и описать с помощью статистической модели.
Однако практическая торговля показывает, что прогноз движения цены — лишь часть более сложной задачи. Торговое решение принимается не в абстрактном пространстве рыночных данных, а в конкретной операционной среде. К моменту появления нового сигнала торговая система уже обладает определённым состоянием. Могут быть открыты позиции. Действует ряд ограничений по риску и управлению портфелем. Эти факторы напрямую влияют на итоговое решение системы.
Именно поэтому опытный трейдер оценивает рынок не изолированно, а в контексте текущего состояния стратегии. Один и тот же рыночный сигнал может привести к различным действиям в зависимости от того, удерживает ли система позицию, насколько загружен капитал или каков текущий уровень риска. В некоторых ситуациях сигнал может быть полностью проигнорирован, в других — наоборот усилен. Таким образом, реальное торговое решение формируется на пересечении двух потоков информации: динамики рынка и состояния торговой системы.
Тем не менее большинство алгоритмических моделей рассматривает эти два аспекта отдельно. Нейросеть анализирует рынок и формирует некоторую оценку будущего движения цены или вероятности роста и падения. Далее в работу вступает слой правил риск-менеджмента, который определяет допустимый размер позиции, условия открытия сделки и параметры сопровождения. Такая архитектура, несмотря на свою распространённость, фактически разделяет процесс анализа и процесс принятия решения. Модель оценивает рынок, а управление капиталом корректирует её действия уже после формирования сигнала.
Современные архитектуры глубокого обучения открывают возможность более тесной интеграции этих двух уровней. Вместо раздельного анализа рыночных данных и торгового контекста их можно объединить внутри единой модели представления признаков. В такой постановке нейронная сеть получает на вход не только последовательность наблюдений рынка, но и информацию о текущем состоянии торговой системы. Баланс счёта, структура открытых позиций, параметры риска и временные характеристики торговой среды становятся полноценными элементами исходных данных модели.
Особенно перспективным инструментом для решения подобных задач являются архитектуры на основе механизма внимания. Трансформеры позволяют рассматривать исходные данные как набор взаимосвязанных элементов, между которыми модель самостоятельно выявляет зависимости в процессе обучения. Благодаря этому различные типы признаков могут взаимодействовать друг с другом непосредственно внутри модели. Такой подход даёт возможность анализировать не только последовательность рыночных наблюдений, но и контекст, в котором принимается торговое решение.
Интересным шагом в этом направлении стала работа "OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender", в которой предложена архитектура, объединяющая моделирование последовательностей и взаимодействие признаков внутри единого Transformer-backbone. В исходной постановке задача относится к области рекомендательных систем, где необходимо одновременно анализировать последовательность действий пользователя и набор статических характеристик объектов. Авторы показывают, что представление всех входных данных в виде единого набора токенов позволяет эффективно моделировать сложные зависимости между различными типами признаков.
Ключевая идея этой архитектуры заключается в том, что последовательные и контекстные признаки не обрабатываются отдельными модулями. Вместо этого они объединяются в общую структуру исходных данных и совместно проходят через механизм Self-Attention. Благодаря этому модель получает возможность напрямую выявлять связи между временной динамикой и статическими характеристиками системы.
Несмотря на то что предложенный подход разрабатывался для задач рекомендаций, сама архитектурная идея представляет значительный интерес и для анализа финансовых рынков. Структура данных в этих задачах во многом схожа. С одной стороны присутствует последовательность рыночных наблюдений, отражающая эволюцию цены и ликвидности. С другой — существует набор параметров, описывающих текущий контекст торговли: состояние счёта, структуру позиций, временные особенности торговой сессии и другие характеристики операционной среды.
Если рассматривать эти данные совместно, становится очевидно, что они формируют единую информационную систему. Рыночная динамика определяет потенциальные возможности для открытия и закрытия позиций, в то время как состояние торговой системы задаёт ограничения и условия реализации этих возможностей. Объединение этих источников информации внутри одной нейросетевой архитектуры позволяет сформировать более целостное представление о текущей рыночной ситуации.
Архитектура OneTrans
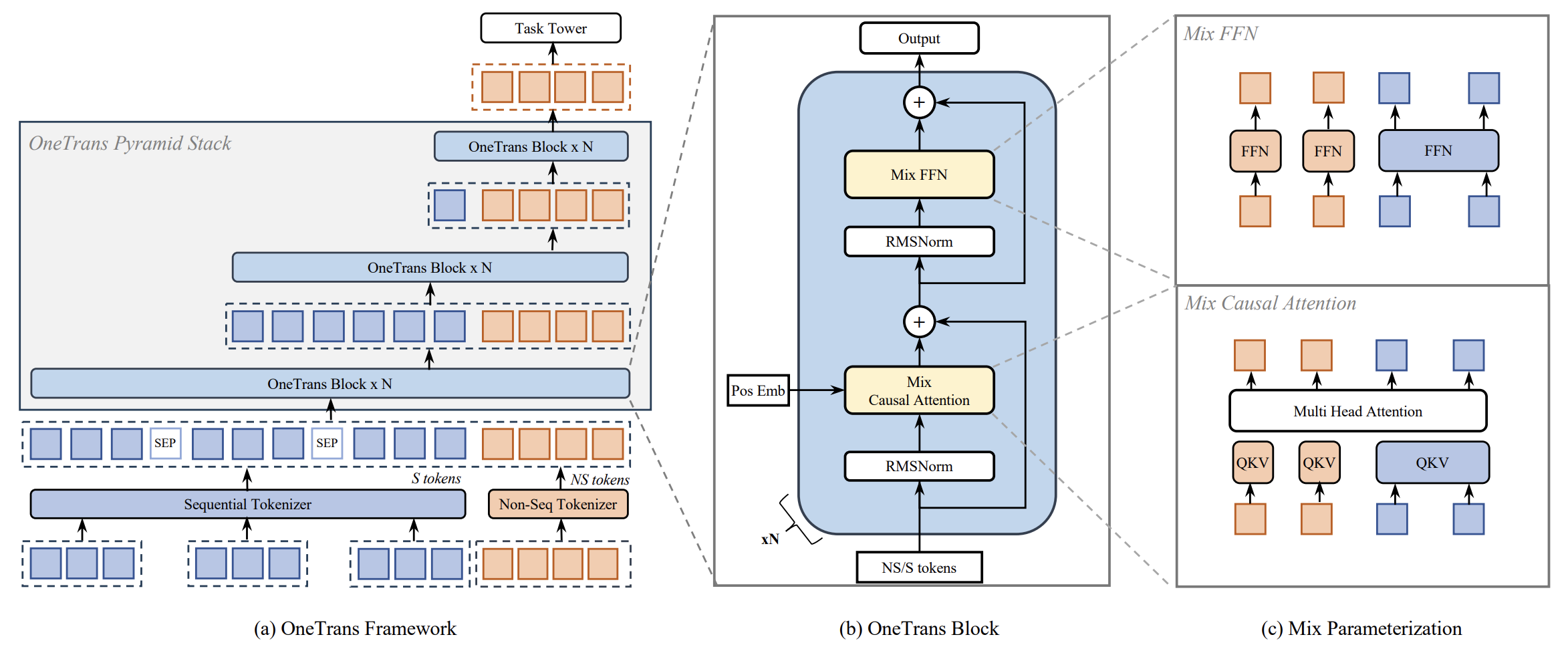
Архитектура фреймворка OneTrans строится вокруг идеи единого пространства представлений для всех анализируемых признаков, независимо от их природы. Для формирования начальной последовательности токенов модель пропускает все сырые признаки через pipeline предварительной обработки, который преобразует их в векторные эмбеддинги. Эти эмбеддинги затем делятся на два логических блока: последовательные признаки, отражающие многопоточную динамику поведения, и непоследовательные признаки, описывающие состояние системы, контекст или характеристики объектов. Каждый поднабор обрабатывается собственным токенизатором, что позволяет сохранить семантику и структуру данных при переходе к унифицированной последовательности.
Непоследовательные (NS) признаки включают числовые и категориальные данные. Признаки либо приводятся к дискретным корзинам (bucketized), либо кодируются в one-hot формат, после чего проходят эмбеддинг. В промышленных системах таких признаков может быть сотни, и их влияние на модель различается, поэтому предусмотрены два способа формирования NS-токенов. Первый — Group-wise Tokenizer — признаки вручную делятся на семантические группы, каждая из которых конкатенируется и проходит через MLP, формируя соответствующий токен. Второй — Auto-Split Tokenizer — все признаки объединяются и проецируются через единый MLP, после чего результат делится на нужное количество токенов. В обоих случаях результатом становится LNSNS-токенов, каждый фиксированной размерности d.
Последовательные признаки представляют собой набор событийных последовательностей S = {S1, …, Sn}. Каждая последовательность состоит из эмбеддингов событий eij, объединяющих идентификатор объекта и его вспомогательную информацию. Для каждого набора событий используется общий MLP, который приводит все события к одной размерности d. После этого последовательности выравниваются и объединяются в единую последовательность S-токенов.
Авторами фреймворка предлагается два способа их объединения: с учётом временных меток, события перемежаются в порядке времени с индикаторами типа последовательности, и без учёта меток, последовательности конкатенируются по важности действия пользователя. Между последовательностями вставляются обучаемые SEP-токены. Эксперименты, проведенные авторами фреймворка, показывают, что при наличии временных меток Timestamp-Aware объединение даёт более точные результаты.
Наконец, S- и NS-токены объединяются в единое пространство токенов, где каждый элемент имеет одинаковую размерность вектора d. В этом виде создаётся матрица исходных данных, одновременно отражающая динамику рыночных сигналов и состояние торговой системы. Такая унификация позволяет модели учитывать взаимодействие между последовательностями событий и контекстными признаками напрямую, обеспечивая целостное представление состояния рынка и стратегии.
Эта унифицированная последовательность токенов далее поступает в пирамидальный стек Transformer-блоков, где каждый блок постепенно уточняет состояния токенов, формируя всё более сложные внутренние представления. В отличие от стандартных трансформеров, OneTrans применяет mixed parameterization, учитывая различие между последовательными S-токенами и непоследовательными NS-токенами. S-токены, которые однородны по своей природе, используют общий набор параметров для проекций Query/Key/Value и Feed-Forward слоёв, тогда как NS-токены, представляющие разнотипные и семантически разнородные признаки, получают индивидуальные параметры, что позволяет модели точно обрабатывать различающиеся диапазоны значений и статистику признаков.
Механизм внимания реализован как стандартный многоголовый Self-Attention с Causal маской, применяемой к S-токенам. Это обеспечивает корректное агрегирование информации по последовательности и предотвращает утечку будущих данных в прошлое. В то же время NS-токены могут аккумулировать всю историю поведения, сохраняя при этом эффективность вычислений, характерную для Transformer-стиля. Одновременно Self-Attention позволяет каждому токену учитывать информацию обо всех остальных, создавая возможности для анализа как взаимодействий внутри каждой последовательности событий, так и связей между разными потоками данных.
Особое внимание уделено стабилизации обучения. Все токены проходят через RMSNorm как слой предварительной нормализации, выравнивая масштабы последовательных и контекстных признаков. Такой подход предотвращает возможный коллапс внимания или нестабильность градиентов.
Далее каждый токен проходит через Feed-Forward блок. Здесь для S-токенов используется общий FFN, а для NS-токенов — токен-специфический. Такая структура позволяет NS-токенам извлекать сложные зависимости из разнообразных источников информации, не теряя при этом вычислительной эффективности.
Особое внимание уделяется пирамидальной схеме внимания. На каждом слое Transformer постепенно уменьшается подмножество последних S-токенов, используемых для формирования запросов (Query), пока на последнем слое оно не сводится к нулю. Подмножество NS-токенов остаётся неизменным и полностью участвует в формировании Query на всех уровнях. Ключи (Key) и значения (Value) всегда формируются по полной последовательности, включающей все S- и NS-токены. Такая организация позволяет модели концентрироваться на последних событиях в последовательностях, одновременно сохраняя полную информацию о контексте и состоянии системы через NS-токены, что обеспечивает эффективную интеграцию истории поведения пользователя с контекстными признаками при формировании итоговых прогнозов.
В результате формируются целостные внутренние представления, где динамика рынка и контекст торговой системы интегрируются в одном пространстве. Итоговые токены подаются на выходные головы для прогнозирования и генерации сигналов принятия решений.
Ещё одна ключевая инженерная особенность архитектуры — Cross‑Request KV Caching. Механизм, который разделяет обработку внимания на два взаимосвязанных этапа. В торговых задачах это особенно важно. Модель оценивает рыночную ситуацию на каждом новом баре, при этом история рынка изменяется минимально. Добавляется только один свежий бар, а все предыдущие уже обработаны и остаются неизменными. Использование causal маски гарантирует, что новый бар не влияет на вычисления для прошлых событий.
Первый этап, выполняемый один раз при старте модели, обрабатывает все S‑токены с causal маской. Формируются ключи (Key), значения (Value) и промежуточные представления внимания, которые сохраняются в кэше. На втором этапе для каждого нового бара вычисляются только новые S‑ и NS‑токены. Они участвуют в Cross-Attention с уже закэшированными S‑токенами и затем проходят токен‑специфичные FFN‑слои. Специфические последовательности, которые не могут быть объединены с кэшем S‑токенов, предварительно агрегируются через pooling.
Такой подход существенно снижает вычислительную нагрузку для каждого кандидата и позволяет быстро оценивать множество торговых вариантов на каждом новом баре, не тратя ресурсы на повторную обработку всей истории рынка.
Для повышения производительности и снижения использования памяти авторы фреймворка OneTrans применяет FlashAttention‑2, решающий проблему квадратичной сложности классического Self-Attention. FlashAttention‑2 использует блочное разбиение, Fusion-ядра и оптимизацию онлайн-SoftMax, что позволяет вычислять внимание по частям, аккуратно управляя памятью, без необходимости хранить полную матрицу скалярных произведений. Особое внимание уделяется минимизации операций вне матричных умножений (non-matmul FLOPs).
На современных GPU матричные операции выполняются в сотни TFLOPs, тогда как стандартные операции вне умножения примерно в 16 раз медленнее. FlashAttention‑2 перераспределяет вычисления так, чтобы максимально концентрироваться на матричных умножениях, удерживая пропускную способность GPU выше 50% от теоретического максимума. Онлайн-SoftMax переписан так, чтобы не пересчитывать масштабирование на каждом шаге, а применять его только в конце блока. Это уменьшает ненужные операции. Causal masking позволяет пропускать вычисления для блоков, которые гарантированно не влияют на текущий токен, давая дополнительный выигрыш в 1.7–1.8 раза по скорости для длинных последовательностей.
Для финансовых рынков это обеспечивает несколько критически важных преимуществ:
- снижение расхода памяти, что позволяет обрабатывать длинные временные ряды без превышения ресурсов;
- высокую скорость инференса, благодаря объединению операций и эффективному кэшированию;
- сохранение точности полного внимания, что важно для корректного аккумулирования сигналов рынка и взаимодействий между событиями.
Дополнительно применяется смешанная точность обучения совместно с recomputation активаций, когда часть прямых активаций отбрасывается и пересчитывается на этапе обратного распространения градиента. Это позволяет строить более глубокие модели и использовать большие батчи, не меняя архитектуру, что особенно важно для сложного анализа финансовых данных.
В совокупности все эти инженерные решения — пошаговая оценка новых баров, Cross‑Request KV Caching, FlashAttention‑2 с оптимизацией non-matmul FLOPs, causal masking и смешанная точность обучения — превращают OneTrans в масштабируемую, высокоэффективную и точную платформу. Модель способна аккумулировать длинные рыночные истории, учитывать контекст стратегии и оценивать множество торговых вариантов на каждом новом баре с минимальной задержкой и высокой точностью, что является критическим условием для алгоритмического трейдинга.
Авторская визуализация фреймворка OneTrans представлена ниже.
Реализация средствами MQL5
После теоретического обзора подходов, предложенных авторами фреймворка OneTrans, мы переходим к практической части нашей работы, в которой представим один из возможных вариантов перенос предложенной архитектуры на задачи финансовых рынков. Это достаточно комплексная задача, и решать мы её будем пошагово. Отдельные модули реализуются как самостоятельные объекты, а затем интегрируются в единое архитектурное решение.
Начинаем с FlashAttention‑2, высокопроизводительного ядра для работы с длинными последовательностями. В контексте финансов каждая последовательность отражает историю рыночных баров, объёмы и индикаторы. Алгоритм оптимизирован для сокращения лишних операций, концентрируясь на матричных умножениях.
На стороне OpenCL-программы наше видение реализация алгоритма представлена кернелом MHFlashAttention. Ключевая логика вычислений переносится внутрь рабочей группы потоков, где каждый поток участвует в параллельной обработке элементов внимания. Такой подход позволяет максимально использовать архитектуру GPU: операции над элементами матриц распределяются между потоками, а промежуточные результаты аккумулируются при помощи локальной памяти и коллективных операций редукции. В рассматриваемом алгоритме каждая рабочая группа обрабатывает одно состояние запроса — Query-вектор
__kernel void MHFlashAttention(__global const float *query, __global const float *key_value, __global float *logsumexp, __global float *output, const int dimension, const int total_kv, const int mask_future ) { //--- init const int q_id = get_global_id(0); const int local_id = get_local_id(1); const int h_id = get_global_id(2); const int total_q = get_global_size(0); const int total_loc = get_local_size(1); const int total_heads = get_global_size(2);
Алгоритм кернела начинается с инициализации идентификаторов потоков: глобальный идентификатор запроса (q_id), локальный идентификатор внутри блока (local_id) и идентификатор головы внимания (h_id). А также вычисляются размеры общей последовательности запросов, локального блока и количества голов. Эти индексы определяют, какой запрос и какую часть последовательности обрабатывает каждый поток, что обеспечивает эффективное распределение вычислений на GPU.
Для локальных аккумулирующих операций создаётся массив temp, что минимизирует обращения к глобальной памяти.
__local float temp[LOCAL_ARRAY_SIZE];
Каждому запросу присваивается линейный сдвиг в массиве токенов, и инициализируются переменные для хранения предыдущего максимума, накопленной суммы экспонент и промежуточного результата.
const int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id); float prev_max = MIN_VALUE; float sumexp = 0; float out = 0;
Основной цикл проходит по ключам и значениям блоками, соответствующими локальному размеру потока. Для каждого ключа вычисляется скалярное произведение с запросом с учётом causal маски, которая запрещает будущим событиям влиять на текущий бар.
for(int k_id = local_id; k_id < max(total_kv, dimension); k_id += total_loc) { const int shift_k = RCtoFlat(h_id, 0, total_heads, dimension, k_id); const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 2 * k_id + 1); //--- Score float score = 0; if(k_id < total_kv && (mask_future == 0 || q_id <= k_id)) { for(int d = 0; d < dimension; d++) { float q = IsNaNOrInf(query[shift_q + d], 0.0f); if(q == 0.0f) continue; float k = IsNaNOrInf(key_value[shift_k + d], 0.0f); if(k == 0) continue; score += q * k; } } else score = MIN_VALUE;
Аномалии и пропуски обрабатываются функцией IsNaNOrInf, что обеспечивает устойчивость вычислений.
После расчёта скоров формируется локальный максимум для нормализации. Score преобразуется через экспоненту, а сумма экспонент аккумулируется с учётом предыдущих значений, стабилизируя SoftMax на длинных последовательностях.
//--- norm score float max = fmax(prev_max, LocalMax(score, 1, temp)); if(score > MIN_VALUE) score = exp(score - max); else score = 0.0f; if(sumexp == 0.0f) sumexp = LocalSum(score, 1, temp); else sumexp = IsNaNOrInf(exp(prev_max - max) * sumexp + LocalSum(score, 1, temp), 0.0f);
Особенность реализации заключается в том, что каждый поток внутри рабочей группы связан с конкретным элементом вектора признаков. Внутренний цикл проходит по всем измерениям пространства dimension. На каждой итерации вычисляется вклад текущего Value-элемента в результирующий контекстный вектор. Для начала формируется временная переменная val, отражающая вклад конкретной пары Key/Value с учётом рассчитанного веса внимания score. Если значение ключа корректно и вес внимания положителен, выполняется умножение соответствующего элемента Value на рассчитанный коэффициент внимания. Полученное значение представляет собой частичный вклад в итоговый результат.
for(int d = 0; d < dimension; d++) { float val = 0.0f; if(score > 0.0f && k_id < total_kv) { float v = IsNaNOrInf(key_value[shift_v + d], 0.0f); if(v != 0.0f) val = IsNaNOrInf(v * score, 0.0f); }
Этот вклад суммируется между потоками рабочей группы с использованием функции LocalSum. Это важный этап. Он выполняет редукцию значений внутри группы потоков, аккумулируя частичные результаты. Таким образом формируется скалярная сумма по всем потокам для текущего измерения.
val = LocalSum(val, 1, temp); if(local_id == d) { if(out != 0.0f) out = IsNaNOrInf(exp(prev_max - max) * out + val, 0.0f); else out = val; } } prev_max = max; }
После завершения редукции, управление фактически возвращается к потоку, индекс которого соответствует текущему измерению результирующего пространства. Условие local_id == d гарантирует, что обновление результирующего значения выполняет только один поток — тот, который отвечает за данное измерение вектора. Это позволяет избежать конфликтов записи и сохраняет строгую согласованность данных.
Накопление результата происходит с учётом численной стабилизации SoftMax-вычислений. Если для текущего измерения уже существует накопленное значение out, оно корректируется с использованием экспоненциального коэффициента exp(prev_max - max), после чего к нему добавляется новый вклад val. Такая схема соответствует классической технике стабильного вычисления SoftMax, используемой в FlashAttention. Максимум обновляется постепенно, а накопленные суммы пересчитываются без потери точности. Если же значение out ещё не было инициализировано, оно просто принимает текущее значение val. В результате каждый поток рабочей группы постепенно накапливает скалярный результат для своего измерения выходного вектора.
После завершения обработки всех Key/Value элементов рабочая группа фактически формирует полный контекстный вектор внимания, распределённый между потоками.
В конце нормализованный результат записывается в глобальный массив output, а максимальный score и логарифм суммы экспонент фиксируется в logsumexp.
if(local_id < dimension) { if(sumexp > 0.0f) output[shift_q + local_id] = IsNaNOrInf(out / sumexp, 0.0f); else output[shift_q + local_id] = 0.0f; } if(local_id == 0) { int shift_logse = RCtoFlat(q_id, h_id, total_q, total_heads, 0.0f); logsumexp[shift_logse] = IsNaNOrInf(prev_max + log(sumexp),0.0f); } }
В результате мы получаем скоростное и масштабируемое ядро, способное работать с реальными потоками рыночных данных, аккумулировать долгую историю баров и предоставлять точные представления для последующих модулей фреймворка в MQL5.
Заключение
В рамках данной статьи мы рассмотрели архитектуру фреймворка OneTrans, проанализировали заложенные в нём принципы обработки длинных последовательностей и реализовали один из его ключевых вычислительных компонентов — механизм эффективного внимания на базе FlashAttention-2. Это позволило заложить технологическую основу для дальнейшего переноса предложенных архитектурных решений в область построения торговых моделей.
Тем не менее сам по себе данный шаг является лишь отправной точкой. Реальная сила фреймворка раскрывается только в полной архитектуре, где отдельные модули совместно формируют многослойную систему обработки последовательностей. Именно такая композиция компонентов позволяет модели одновременно учитывать долгосрочную структуру рынка, локальную динамику цен и текущий контекст торговой ситуации.
Поэтому дальнейшая работа будет направлена на последовательную реализацию остальных элементов архитектуры OneTrans и их интеграцию в единый вычислительный конвейер. В следующей статье мы продолжим перенос предложенных авторами идей в прикладную плоскость алгоритмического трейдинга, реализуя новые модули модели и формируя полноценную систему анализа рыночных данных.
Ссылки
- OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования