
Нейросети в трейдинге: Адаптивная факторная токенизация (MTmixAtt)

Введение
Современные финансовые рынки представляют собой сложные и динамичные системы, в которых ежедневно формируется огромное количество информации. Для корректного и всестороннего анализа рыночной ситуации необходимо учитывать десятки, а порой и сотни разнородных факторов. Среди них технические индикаторы, волатильность цен, макроэкономические показатели и корпоративные события. Каждый из этих факторов сам по себе содержит определённую ценность, но одновременно способен создавать шум, маскировать важные сигналы и усложнять прогнозирование.
Классические модели анализа признаков обычно используют одну из двух стратегий, каждая из которых имеет свои ограничения.
Первая стратегия — анализ всех признаков одновременно, так сказать все ко всему. Модель получает полное множество факторов и пытается выявить взаимосвязи без предварительной фильтрации. На первый взгляд это кажется естественным: чем больше информации, тем выше точность прогнозов. На практике такой подход часто приводит к переобучению и снижению интерпретируемости результатов. Например, когда несколько коррелированных индикаторов одновременно реагируют на волатильность, модель может придавать избыточный вес шумовым сигналам. Это приводит к нестабильным прогнозам в новых рыночных условиях.
Вторая стратегия — ручная группировка признаков. Аналитик заранее распределяет признаки по категориям: трендовые индикаторы в одну группу, показатели объёма — в другую, волатильность — в третью. Такой подход облегчает интерпретацию и снижает размерность модели, но ограничивает её адаптивность. Фиксированные группы не отражают меняющиеся взаимосвязи между факторами, зависят от субъективного выбора аналитика и могут не учитывать неожиданные комбинации признаков, которые оказывают существенное влияние на краткосрочные колебания цен.
Таким образом, классические подходы сталкиваются с двумя фундаментальными ограничениями. Первый — риск хаотичного переобучения и потери структуры, второй — ограниченная гибкость и зависимость от субъективного анализа. Эти проблемы особенно остро проявляются в условиях современной торговли: динамика рынка постоянно меняется, а влияние факторов нестабильно.
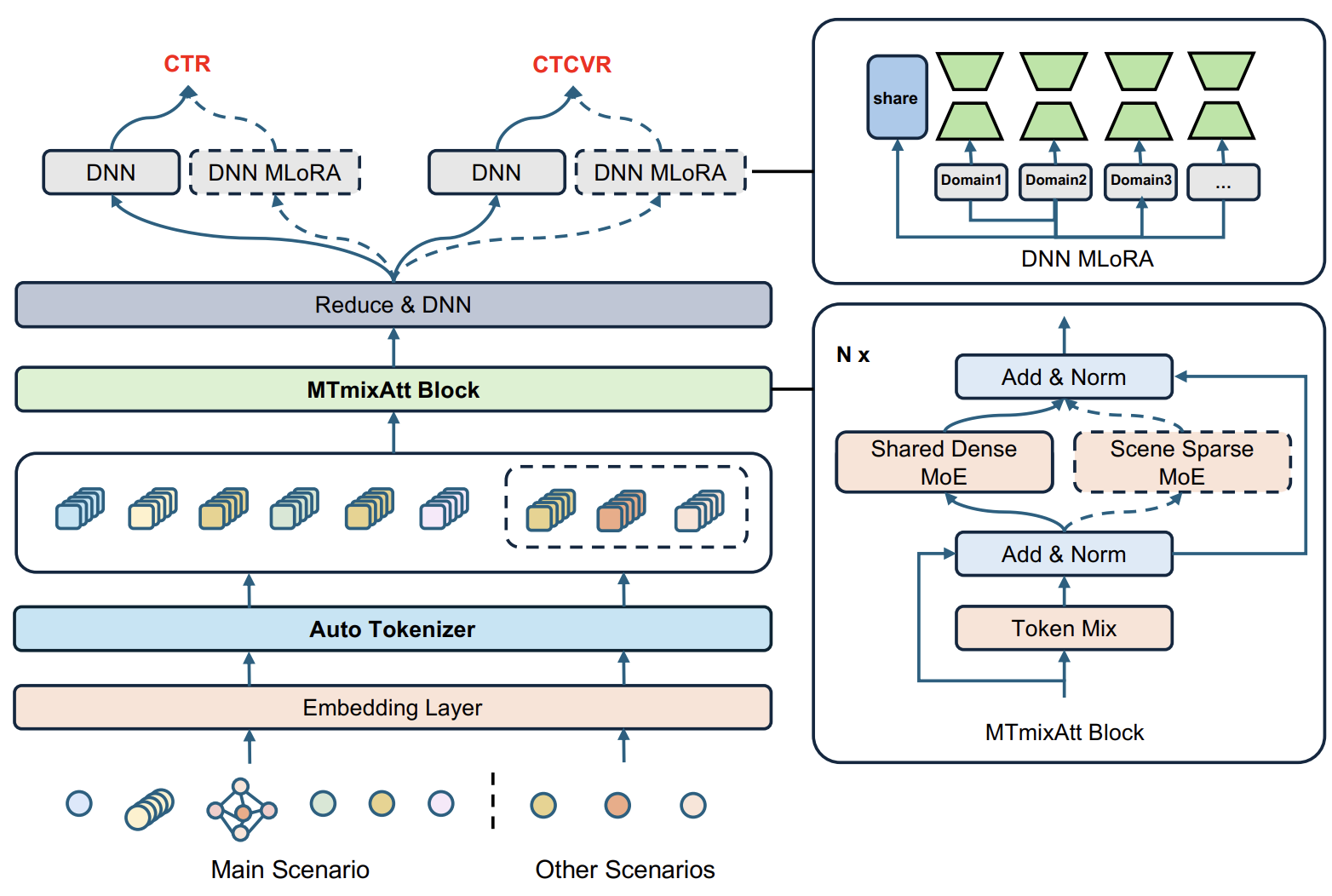
Решение этой задачи требует обучаемого механизма динамической группировки признаков, способного выявлять значимые комбинации факторов автоматически и адаптироваться к изменяющимся условиям рынка. В этом контексте мы обращаем свое внимание на работу "MTmixAtt: Integrating Mixture-of-Experts with Multi-Mix Attention for Large-Scale Recommendation". Её авторы предложили фреймворк MTmixAtt, изначально разработанный для рекомендательных систем. Хотя его первичное применение было в другом контексте, архитектурные принципы MTmixAtt — работа с разнородными признаками, выявление скрытых зависимостей и формирование компактных представлений — могут найти свое применение и для анализа финансовых рынков.
Один из ключевых компонентов MTmixAtt — модуль AutoToken формирует структурированные токены из исходного множества признаков. Каждый токен агрегирует несколько исходных признаков и сохраняет важные взаимосвязи между ними, создавая удобную единицу анализа для последующих компонентов фреймворка. Это позволяет модели автоматически определять, какие комбинации факторов наиболее значимы для прогнозирования, снижая зависимость от ручной группировки и улучшая адаптивность модели.
Использование MTmixAtt в контексте финансовых рынков предоставляет следующие преимущества:
- автоматическая структуризация множества признаков — позволяет снизить шум и выявить ключевые комбинации факторов;
- сохранение и выявление взаимосвязей внутри токенов — обеспечивает более надежные прогнозы при динамичных рыночных условиях;
- дифференцируемая структура модели — обеспечивает возможность обучения и оптимизации на исторических данных;
- прозрачность и интерпретируемость — позволяет аналитикам понимать, какие комбинации факторов влияют на построение прогнозов моделью.
В периоды высокой волатильности рынка отдельные индикаторы могут реагировать синхронно, создавая ложные сигналы. Ручная группировка не способна адаптироваться к такой ситуации: фиксированные группы либо игнорируют новые паттерны, либо включают шумовые признаки. AutoToken динамически формирует токены, выявляя значимые комбинации признаков в текущем рыночном контексте.
Алгоритм MTmixAtt
Архитектура MTmixAtt является логичным развитием идеи структурного анализа рынка. Мы не хотим складывать индикаторы в одну корзину. Напротив, нам надо понять, как они образуют устойчивые конфигурации.
На вход модели обычно поступает вектор анализируемых признаков. Это могут быть значения скользящих средних разных периодов, осцилляторы импульса, характеристики волатильности, объёмные показатели, производные доходности, межрыночные спреды. В реальности это всегда смесь сигналов разной природы и масштаба. Если обрабатывать их напрямую, возникает перекос. Признаки с большей амплитудой начинают доминировать. Коррелированные факторы усиливают друг друга. А слабые, но важные взаимодействия теряются в шуме.
Если перенести логику рекомендательных систем в плоскость финансовых рынков, становится очевидно: корректность стратегии группировки признаков напрямую влияет на способность модели уловить семантические взаимосвязи между факторами. В рекомендательных задачах это связи между характеристиками пользователя и объекта. В финансовых — между трендом, волатильностью, ликвидностью, импульсом и множеством производных величин. Ошибка в структурировании признаков разрушает внутреннюю логику данных.
Теоретически некорректная кластеризация способна разорвать естественные связи между признаками. В финансовом контексте это означает, что значимая взаимосвязь отдельных признаков может быть искусственно размазана по разным группам. В результате модель теряет выразительную способность, появляется нестабильность. А в торговле нестабильность — это прямой путь к просадке.
Именно здесь появляется AutoToken — модуль, который отказывается от ручной группировки в пользу данных. Он не предполагает заранее заданной структуры, он извлекает её в процессе оптимизации.
Первым этапом работы AutoToken становится выравнивание размерностей. Исходные признаки могут иметь различную природу и масштаб. Если их напрямую объединить, возникает перекос влияния. Поэтому для каждого признака используется отдельное обучаемое нелинейное преобразование.
X̂i = DNNi(Xi), i = 1,2,…,nf
где Xi — исходный i-й признак,
X̂i — его представление в выровненном латентном пространстве,
DNNi — многослойный перцептрон, закреплённый за данным признаком,
nf — общее число признаков.
Важно подчеркнуть, что это параметризованное преобразование. Каждый признак получает собственный небольшой нейронный блок, который обучается представлять его в общем пространстве размерности e. Таким образом формируется матрица выровненных представлений. В ней каждая строка соответствует отдельному финансовому фактору, а каждая колонка — координате в общем латентном пространстве.
С точки зрения финансового моделирования это ключевой момент. Мы приводим разнородные сигналы к единому представлению. Индикатор волатильности и краткосрочный импульс больше не находятся в разных метрических мирах, они описываются в общей системе координат. Это создаёт основу для корректного анализа их взаимодействий. Если пропустить этот этап, дальнейшая структуризация будет искажена, поэтому выравнивание — фундамент архитектуры.
Далее вступает в работу ключевой механизм — адаптивная токенизация. До этого момента каждый признак уже представлен в общем латентном пространстве, и мы имеем матрицу выровненных эмбеддингов X̂ ∈ Rnf×e. Однако сами по себе эти эмбеддинги всё ещё независимы. Структуры пока нет, есть только согласованное представление факторов.
Чтобы перейти от набора признаков к их обучаемым комбинациям, вводится матрица выбора признаков W ∈ Rng×nf, где ng — количество формируемых групп, то есть будущих токенов.
Интуитивно каждая строка матрицы W отвечает за один токен. Значения в строке отражают предпочтение данного токена к тем или иным исходным признакам. В финансовой интерпретации это означает следующее: модель сама решает, какие факторы логично объединить в рамках одной структурной единицы анализа.
Это уже принципиально отличается от ручной группировки. Мы не фиксируем заранее, что тренд должен быть отдельной категорией. А волатильность — другой. Мы позволяем матрице W в процессе обучения выявить устойчивые сочетания факторов.
Во время прямого прохода в каждой строки Wi выбираются k признаков с наибольшими значениями весов в данной строке. Эти индексы образуют множество I. Далее из матрицы X̂ извлекаются соответствующие выровненные эмбеддинги и конкатенируются. Фактически, для каждого токена мы собираем k наиболее релевантных признаков и объединяем их представления. Полученная структура имеет размерность Rk×e×ng. Первые две размерности затем разворачиваются в одну, формируя итоговое представление размерности ∈ Rd×ng (d = k • e).
С практической точки зрения это означает, что каждый токен становится компактным и информативным вектором, включающим k наиболее значимых признаков в согласованном пространстве признаков.
Однако на этом этапе возникает тонкий момент. Операция Top-K дискретна. Если оставить её в жёстком виде, градиент не сможет корректно распространяться через матрицу W, а значит, механизм группировки перестанет обучаться. С целью сохранения дифференцируемости, применяется нормализация выбранных весов функцией SoftMax. Полученные коэффициенты используются как веса при агрегации. Таким образом, итоговое представление токена формируется не просто конкатенацией, а взвешенной комбинацией наиболее значимых эмбеддингов.
Это делает весь процесс кластеризации признаков непрерывным и оптимизируемым. Матрица W обучается через стандартный градиентный спуск, постепенно усиливая устойчивые комбинации факторов и подавляя случайные.
Для финансовых рынков это особенно важно. В одни периоды ключевым оказывается сочетание объёма и краткосрочного импульса, в другие — взаимодействие среднесрочного тренда и расширяющейся волатильности. Если группы признаков фиксированы, модель оказывается заложником прошлого режима. Адаптивная токенизация позволяет перестраивать внутреннюю структуру при изменении рыночной динамики. Это уже не набор индикаторов, а динамическая карта факторов.
После того как AutoToken сформировал адаптивные токены и мы получили матрицу представлений X̂, начинается следующий стратегический этап — моделирование взаимодействий между этими токенами. Именно здесь архитектура выходит за пределы простой агрегации и переходит к анализу структуры рыночного состояния.
Авторы фреймворка MTmixAtt переосмыслили идею токенного взаимодействия и предложили собственный модуль — MTmixAttBlock. В нем смешивание токенов становятся обучаемыми и контекстно-зависимыми. Это принципиально для финансовых рынков, где зависимость между факторами меняется от режима к режиму.
Концептуально MTmixAttBlock объединяет три механизма:
- обучаемое смешивание токенов,
- плотную MoE-структуру,
- мультисценарную экспертную сеть.
Но начнём с базового элемента — Learnable Mixing Matrix. До этого момента токены существуют как независимые агрегированные представления. Однако рынок — это не сумма независимых факторов, а система взаимосвязей. Тренд усиливается объёмом, волатильность изменяет силу сигнала, ликвидность влияет на устойчивость движения, поэтому необходимо явно моделировать потоки информации между токенами. Для этого матрица X̂ сначала транспонируется, и измерение токенов становится основной осью преобразования. Это важный архитектурный ход. Мы перестаём смотреть на признаки внутри токена и начинаем анализировать отношения между самими токенами.
Далее матрица разбивается на H семантических голов вдоль признакового измерения. Каждая голова отвечает за собственное подпространство признаков. В финансовой интерпретации это можно понимать как разные аспекты рыночной структуры: одна голова может акцентировать динамику импульса, другая — распределение волатильности, третья — факторы ликвидности. Разделение позволяет избежать смешивания несопоставимых паттернов.
Для каждой головы вводится обучаемая матрица взаимодействия Wh ∈ Rng×ng. Она применяется вдоль токенного измерения и определяет, как информация перетекает между токенами внутри соответствующей семантической головы. Фактически каждый элемент Wh(i,j) регулирует, насколько токен j влияет на токен i. Это уже явная линейная структура взаимодействий.
В финансовом контексте это означает следующее. Если токен, отражающий краткосрочный импульс, системно усиливается при росте токена волатильности, соответствующие веса будут увеличиваться. Если связь ослабевает — веса уменьшаются. Архитектура не предполагает фиксированной структуры корреляций, она обучает её.
Чтобы сохранить стабильность обучения и не разрушить исходную семантику токенов, применяется остаточная связь. Данный механизм выполняет две функции. Во-первых, он стабилизирует оптимизацию. Во-вторых, гарантирует, что исходная информация токена не теряется даже при активном перераспределении весов. Это особенно важно на финансовых данных, где переобучение может быстро привести к нестабильности.
После обработки всеми головами результаты конкатенируются, формируя обновлённое представление токенов, в котором уже явно учтены межтокенные зависимости.
Принципиальное отличие от классического Self-Attention здесь в том, что взаимодействие моделируется через обучаемые матрицы, действующие по токенной оси после транспонирования. Это делает структуру более контролируемой и вычислительно эффективной. Мы избегаем квадратичной сложности стандартного внимания по всем парам признаков, сохраняя при этом гибкость моделирования зависимостей.
Концептуально токенное смешивание в MTmixAttBlock играет роль продвинутого токенизатора второго уровня. Если AutoToken формирует первичную структуру факторов, то Learnable Mixing Matrix перестраивает эту структуру с учётом глобального контекста.
Здесь важно подчеркнуть, что мы формируем динамическую карту взаимодействий между группами признаков. Это приближает модель к реальной природе рынка, ведь движение цены — результат взаимодействия множества сил, а не отдельного сигнала.
После того как межтокенные зависимости стали явной частью представления, архитектура делает следующий шаг — усиливает семантическую специализацию через механизм Shared Dense MoE. Если смешивание токенов отвечает за перераспределение информации между группами факторов, то MoE-слой отвечает за то, как эта информация интерпретируется.
Идея проста, но стратегически важна. Даже после структурного взаимодействия токены остаются разнородными по своей природе. Один может отражать импульсно-объёмную конфигурацию, другой — латентные корреляционные эффекты. Обрабатывать их одним и тем же преобразованием — значит снова возвращаться к усреднению. А рынок редко прощает усреднение.
Именно поэтому вводится Shared Dense MoE — слой смеси экспертов, который позволяет каждому токену выбрать собственную траекторию обработки.
Предложенная авторами фреймворка MTmixAtt конструкция исходит из того, что в реальных данных группы никогда не являются полностью независимыми. В рекомендательных системах клики и покупки коррелированы. В финансах тренд и волатильность, ликвидность и спреды, импульс и глубина рынка — всегда переплетены, поэтому необходима архитектура, которая одновременно поддерживает специализацию и интеграцию.
Shared Dense MoE состоит из двух принципиальных элементов: тонкой декомпозиции экспертов и механизма общих экспертов.
Первая проблема масштабных MoE-моделей известна: простое увеличение размера экспертов даёт убывающий эффект. Слишком крупный эксперт начинает усреднять различные паттерны вместо того, чтобы специализироваться. В финансовых данных это особенно заметно — эксперт, который должен был бы улавливать резкие импульсные всплески, начинает сглаживать их, если внутри него смешаны несовместимые режимы.
Поэтому используется Fine-Grained Splitting. Каждый базовый FFN-эксперт делится на m более мелких под-экспертов. Общее число экспертов увеличивается, но суммарная вычислительная сложность остаётся контролируемой. Авторы фреймворка не расширяют модель бесконтрольно — они увеличивают её дискретность. Это позволяет формировать более гибкие комбинации экспертов для каждого токена.
Формально агрегация на уровне токена t и слоя l записывается следующим образом:
Ĥt = ∑i ɑi,tFFNi(ut) + ∑j βj,tFFNj(ut),
где ut — входное представление токена, а Ĥt — агрегированный выход.
Первая сумма соответствует общим экспертам, вторая — тонко разделённым под-экспертам. Вес каждого эксперта определяется гейтинговой функцией.
Экономический смысл здесь очевиден. Одни паттерны рынка требуют общей логики — например, базовых закономерностей распределения доходностей, другие — специфических интерпретаций, характерных для конкретного сочетания факторов. Shared эксперты служат якорем — они улавливают универсальные свойства рыночной динамики. Fine-Grained эксперты обеспечивают гибкость и специализацию.
Без Shared-механизма эксперты начинают дублировать друг друга. Каждый пытается заново выучить одни и те же фундаментальные зависимости. Это приводит к параметрической избыточности, нестабильности и ухудшению обобщающей способности.
Следующий уровень усложнения — мультисценарная экспертная архитектура. Финансовый рынок по своей природе многорежимен. Трендовый рынок, флэт, кризисная турбулентность, постновостной всплеск ликвидности — это разные сценарии, хотя формально мы работаем с одними и теми же признаками.
Традиционные методы идут по одному из двух путей. Либо полностью общая модель для всех сценариев — что лишает её гибкости. Либо отдельная модель под каждый режим — что раздувает параметры и разрушает перенос знаний.
Здесь авторы MTmixAtt предлагают гибридную разреженную архитектуру. На уровне сценариев вводятся общие эксперты и сценарно-специфические эксперты. Общие эксперты обучаются универсальным паттернам, повторяющимся вне зависимости от режима. Сценарные эксперты специализируются на поведении, уникальном для конкретного состояния рынка.
Для вычисления весов Shared-экспертов используется объединённое представление токена и сценария. Таким образом, даже общие эксперты получают информацию о контексте.
Для сценарно-специфических экспертов вычисляются логиты разреженной маршрутизации. Сохраняются только Top-k экспертов с максимальными значениями, остальные обнуляются. Это создаёт баланс между изоляцией и совместным использованием знаний. В результате каждый токен обрабатывается как универсальными экспертами, так и ограниченным набором сценарных экспертов.
В финансовой интерпретации это означает, что общие эксперты отвечают за фундаментальные закономерности распределения и взаимодействия факторов, сценарные — за поведение в конкретном режиме рынка. При этом модель избегает полного дублирования параметров и сохраняет вычислительную эффективность.
Именно сочетание Learnable Mixing Matrix, Fine-Grained MoE и мультисценарной маршрутизации превращает MTmixAttBlock в полноценный механизм структурного анализа рынка. Он не просто усиливает модель по глубине, а вводит управляемую иерархию взаимодействий. Сначала между признаками внутри токенов, затем — между токенами, а потом — между экспертными интерпретациями этих токенов в разных рыночных режимах.
Реализация средствами MQL5
После детального разбора архитектуры MTmixAtt логично перейти к прикладной реализации. Теория задаёт направление, но в прикладных задачах финансовых рынков ценность имеют только идеи, доведенные до работающего кода и способные выдерживать поток реальных данных. Именно поэтому мы начинаем практическую имплементацию предложенных подходов средствами MQL5.
Сразу подчеркнём, что полная реализация всей архитектуры — задача объёмная и по сути выходит за рамки одной статьи. MTmixAtt включает несколько взаимосвязанных уровней, поэтому мы будем двигаться последовательно, закладывая основу постепенно. И первым шагом становится модуль AutoToken — тот самый фундамент, на котором затем будет строиться вся логика смешивания, экспертной специализации и многосценарной адаптации.
Выбор не случаен. В архитектуре MTmixAtt именно AutoToken определяет, какие признаки вообще попадут в дальнейшую обработку и в каком объеме. Фактически это интеллектуальный фильтр, который формирует компактное представление из избыточного пространства анализируемых факторов. В задачах алгоритмической торговли это особенно важно. Рыночные данные всегда перегружены. Если без отбора передать всё это в модель, мы почти гарантированно получим переобучение, нестабильность и рост вычислительных затрат без пропорционального прироста качества.
AutoToken решает эту проблему дисциплинированно. Он оценивает значимость токенов и группирует их в группы по Top-k наиболее информативных. Формально мы начинаем с матрицы признаков. Далее вычисляется функция скоринга, формирующая вектор важностей. На основе этих значений применяется оператор Top-k, и в модель передаётся уже сжатое представление.
Для переноса этой логики в MQL5 мы создаем новый самостоятельный нейронный блок CNeuronAutoToken, наследующийся от базового CNeuronBaseOCL.
class CNeuronAutoToken : public CNeuronBaseOCL { protected: uint iEmbedingSize; uint iTopK; uint iUnits; uint iGroups; //--- CLayer cDNN; CLayer cW; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAutoToken(void) {}; ~CNeuronAutoToken(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint embed_size, uint units_in, uint groups, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronAutoToken; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Внутренняя структура класса не является формальной декларацией полей — она напрямую отражает архитектурную идеологию AutoToken и задаёт геометрию вычислений. Каждая переменная фиксирует конкретный уровень преобразования данных и тем самым определяет поведение блока в общей системе MTmixAtt.
Параметр iEmbedingSize задаёт размерность embedding-пространства e. Это та глубина представления, в которую проецируются исходные признаки перед процедурой отбора. По сути, именно здесь формируется компактная семантическая плоскость, в которой модель будет сравнивать токены между собой. Слишком малая размерность приведёт к потере информации, чрезмерная — к избыточной сложности и росту шума. В финансовых данных баланс здесь особенно критичен.
iTopK определяет число выбираемых токенов для каждой группы. Это центральный параметр компрессии, он задаёт, какая доля исходного информационного потока будет допущена к дальнейшей обработке. В практических задачах торговли именно этот гиперпараметр регулирует компромисс между чувствительностью модели и её устойчивостью. Малое значение усиливает фильтрацию и снижает переобучение, большое — повышает гибкость, но увеличивает риск захвата случайных корреляций.
iUnits описывает количество анализируемых признаков в исходных данных. Фактически это ширина входного пространства до токенизации.
iGroups задаёт число групп, формируемых на выходе блока. Это уже шаг к структурированию информации. Группировка позволяет разделять токены по смысловым или статистическим признакам, что облегчает дальнейшую работу механизмов смешивания и экспертной маршрутизации.
После параметрического уровня начинается функциональный. В классе предусмотрены два ключевых компонента, образующих параллельные магистрали обработки данных.
cDNN выполняет роль блока формирования эмбеддингов признаков. Здесь происходит нелинейное преобразование исходного пространства в более компактное и семантически насыщенное представление. Этот модуль отвечает за извлечение латентных факторов. В контексте финансовых рынков именно здесь могут выявляться скрытые режимы, структурные зависимости или комплексные комбинации индикаторов, которые невозможно обнаружить линейными методами.
cW представляет собой обучаемую матрицу выбора признаков. Если cDNN отвечает за извлечение структуры, то cW реализует механизм ранжирования. Она формирует финальные оценки, на основе которых выполняется процедура Top-K отбора. С инженерной точки зрения это этап принятия решения — какие токены продолжат путь по вычислительной цепочке, а какие будут отброшены.
Такое разделение — не просто архитектурная аккуратность, оно создаёт устойчивую двухуровневую систему: сначала извлечение латентной информации, затем её строгая селекция. В условиях рыночных данных это особенно важно. Сначала модель должна понять структуру сигналов, а уже потом — выбрать наиболее значимые.
Метод инициализации становится центральной точкой конфигурации всего блока AutoToken. Именно здесь из абстрактной архитектурной идеи формируется конкретная вычислительная геометрия, согласованная с OpenCL-ядрами и внутренними буферами.
bool CNeuronAutoToken::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint embed_size, uint units_in, uint groups, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, embed_size * topK * groups, optimization_type, batch)) ReturnFalse;
В первой строке управление передается родительскому классу. Объём пространства результатов передаётся как embed_size * topK * groups. Мы заранее фиксируем, что после отбора Top-K токенов каждый из них будет представлен в embedding-пространстве размерности embed_size, а далее структурирован по группам. Если на этом этапе допустить несогласованность размеров, дальше ошибка будет масштабироваться по всей вычислительной цепочке.
Затем фиксируются внутренние параметры. Это статическая геометрия слоя. После инициализации она уже не должна меняться — иначе возникнет рассинхронизация с выделенной памятью GPU.
iEmbedingSize = embed_size; iTopK = topK; iUnits = units_in; iGroups = groups;
Далее очищаются контейнеры cDNN и cW. И им передаётся указатель на общий OpenCL-контекст.
cDNN.Clear(); cW.Clear(); cDNN.SetOpenCL(OpenCL); cW.SetOpenCL(OpenCL);
Мы явно закрепляем все подслои за одним вычислительным контекстом. Разные OpenCL-контексты означают разные буферы, а значит — лишние копирования и потери производительности.
Блок cDNN формирует embedding-представление признаков. Здесь создаются два слоя CNeuronFieldAwareConv. Первый слой расширяет представление до 2 * embed_size, усиливая взаимодействия между полями признаков. Второй слой возвращает размерность обратно к embed_size, но уже в более структурированном виде. Оба слоя используют сигмоидную активацию. Это подчёркивает, что на этапе эмбеддинга мы работаем в режиме мягкой нелинейной компрессии, а не агрессивного отсечения.
CNeuronFieldAwareConv* conv = NULL; CFieldAwareParams* params = NULL; CNeuronSparseSoftMax* softmax = NULL; uint index = 0; //--- DNN conv = new CNeuronFieldAwareConv(); if(!conv || !conv.Init(0, index, OpenCL, window_in, 2 * embed_size, units_in, embed_size, candidates, topK, optimization, iBatch) || !cDNN.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SIGMOID); index++; conv = new CNeuronFieldAwareConv(); if(!conv || !conv.Init(0, index, OpenCL, 2 * embed_size, embed_size, units_in, embed_size, candidates, topK, optimization, iBatch) || !cDNN.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SIGMOID);
С инженерной точки зрения здесь формируется семантическое пространство токенов. Мы создаём представление, пригодное для ранжирования.
После этого инициализируется блок cW, который отвечает за выбор признаков. Сначала создаётся объект CFieldAwareParams. Это обучаемая матрица параметров, фактически реализующая механизм взвешивания групп.
//--- W index++; params = new CFieldAwareParams(); if(!params || !params.Init(0, index, OpenCL, units_in, groups, embed_size, candidates, topK, optimization, iBatch) || !cW.Add(params)) DeleteObjAndFalse(params); params.SetActivationFunction(None);
Активация здесь отключена (None), потому что на этом этапе требуется линейная проекция перед нормализацией.
Завершающим элементом выступает CNeuronSparseSoftMax. Именно он превращает линейные логиты в разреженное распределение, соответствующее механизму Top-K отбора.
index++; softmax = new CNeuronSparseSoftMax(); if(!softmax || !softmax.Init(0, index, OpenCL, groups, units_in, topK, optimization, iBatch) || !cW.Add(softmax)) DeleteObjAndFalse(softmax); //--- return true; }
В отличие от обычного SoftMax, разреженная версия позволяет сохранить только наиболее значимые кандидаты, не тратя вычисления на несущественные.
В итоге метод инициализации — это точка, где архитектурная теория окончательно превращается в инженерную реальность. Здесь задаётся каркас AutoToken, который далее будет работать как управляемый механизм адаптивной компрессии признакового пространства.
Метод прямого прохода — это уже строго выстроенная вычислительная последовательность, где каждый шаг соответствует архитектурной логике AutoToken.
bool CNeuronAutoToken::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; //--- DNN for(int i = 0; i < cDNN.Total(); i++) { curr = cDNN[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
В начале локальный указатель на объект исходных данных prev устанавливается на предыдущий слой NeuronOCL. Это и есть исходный тензор признаков, сформированный более ранним блоком модели. Далее запускается первый контур — cDNN.
Цикл по cDNN последовательно прогоняет данные через все его подслои. Каждый вызов одноименного метода вложенного компонента выполняет преобразование входного представления и нелинейную трансформацию, а после успешного прохода указатель prev переустанавливается на текущий слой. Таким образом формируется цепочка, где выход одного слоя автоматически становится входом следующего.
На выходе cDNN мы получаем embedding-представление токенов — уже структурированное и подготовленное к ранжированию.
Затем начинается второй контур — блок cW. Это этап вычисления скорингов и подготовки к разреженной селекции. Здесь логика немного отличается. Для первого слоя обучаемых параметров вызывается специализированный метод FeedForward без передачи указателя на исходные данные. Это отражает архитектурную особенность. Параметры CFieldAwareParams работают напрямую со своим внутренним состоянием и заранее подготовленными буферами.
//--- W for(int i = 0; i < cW.Total(); i++) { curr = cW[i]; if(!curr) ReturnFalse; if(curr.Type() == defFieldAwareParams) { if(!((CFieldAwareParams*)curr).FeedForward()) ReturnFalse; } else if(!curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Для остальных слоёв используется стандартный метод прямого прохода.
После прохождения всех элементов cW, переменная prev должна указывать на объект типа defNeuronSparseSoftMax. Это принципиальная проверка целостности архитектуры. Если последний слой не является разреженным SoftMax, значит нарушена логика отбора.
if(prev.Type() != defNeuronSparseSoftMax)
ReturnFalse;
Далее происходит ключевой этап — фактическая реализация Top-K отбора.
Мы получаем:
- индексы выбранных токенов через softmax.GetIndexes(),
- их нормализованные веса через softmax.getOutput(),
- embedding-выход последнего слоя cDNN через cDNN[-1].getOutput().
Функция SparseConcat выполняет финальную сборку выходного буфера. Она берёт только выбранные индексы, извлекает соответствующие embedding-векторы и формирует итоговый выход с учетом группировки.
CNeuronSparseSoftMax* softmax = prev; if(!SparseConcat(softmax.GetIndexes(), softmax.getOutput(), cDNN[-1].getOutput(), Output, iGroups, iTopK, iUnits, iEmbedingSize)) ReturnFalse; //--- return true; }
Именно здесь пять логических этапов AutoToken сходятся в единый вычислительный результат.
Важно отметить один тонкий момент. Градиенты в дальнейшем будут распространяться только по тем индексам, которые вернул SparseSoftMax. Это означает, что AutoToken действительно управляет информационным потоком, а не просто переупорядочивает признаки.
В контексте всей архитектуры MTmixAtt именно этот метод превращает избыточное пространство признаков в дисциплинированный набор информативных токенов. И если выражаться языком финансовых рынков — он не пытается слушать весь шум биржевого зала. Выбирает только тех, кто действительно влияет на цену.
С архитектурной точки зрения это первый реальный строительный блок MTmixAtt внутри торговой среды. Фундамент заложен, и в следующей статье мы будем усиливать его.
Заключение
В рамках данной статьи мы рассмотрели архитектурную концепцию MTmixAtt и приступили к её практической реализации в среде MQL5. Предложенный авторский фреймворк обладает рядом принципиальных преимуществ.
Во-первых, он вводит управляемую компрессию признакового пространства через адаптивный механизм Top-K отбора. Это позволяет снизить шум, повысить устойчивость модели и ограничить избыточную сложность. Критически важный фактор для финансовых рынков, где переобучение стоит особенно дорого.
Во-вторых, архитектура изначально строится вокруг разделения ролей: семантическое преобразование, параметризованное ранжирование и разреженная маршрутизация выполняются независимыми, но согласованными блоками. Такая модульность повышает прозрачность системы и облегчает дальнейшее масштабирование.
Важно подчеркнуть, что в данной статье мы лишь начали практическую реализацию предложенных подходов. Создан и структурирован базовый модуль AutoToken, определена вычислительная геометрия и заложена архитектурная дисциплина. Однако впереди остаётся значительный объём работы — развитие механизмов обучения, интеграция Learnable Mixing, построение Shared Dense MoE и многосценарной маршрутизации экспертов, а также комплексное тестирование на реальных рыночных данных.
Ссылки
- MTmixAtt: Integrating Mixture-of-Experts with Multi-Mix Attention for Large-Scale Recommendation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Возможности Мастера MQL5, которые вам нужно знать (Часть 64): Использование паттернов каналов Демарка и конвертов с ядром белого шума
Возможности Мастера MQL5, которые вам нужно знать (Часть 64): Использование паттернов каналов Демарка и конвертов с ядром белого шума
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования