
Нейросети в трейдинге: Масштабируемые трансформеры со структурной декомпозицией признаков (Основные компоненты)

Введение
В предыдущей статье мы подробно рассмотрели проблему, которая на протяжении многих лет остаётся почти неизменной в алгоритмическом трейдинге — разрыв между академическими архитектурами глубокого обучения и реальными условиями финансовых рынков. Теоретически мощные модели демонстрируют впечатляющие результаты на синтетических наборах данных. Однако при переносе в реальную среду финансовых рынков они быстро сталкиваются с фундаментальными ограничениями — шумом, режимной нестабильностью, коррелированностью признаков и ограниченными вычислительными ресурсами.
Финансовый рынок — это не изображение и не текст. Это сложная мультимодальная структура, в которой каждая группа признаков живёт по собственным законам. Ценовая динамика, объёмы, временные характеристики, индикаторные трансформации, производные признаки — всё это формирует неоднородное пространство данных. Классические трансформеры, построенные на универсальном механизме Self-Attention, обрабатывают такие признаки как однородную последовательность токенов: формально — корректно, практически — избыточно и часто неустойчиво.
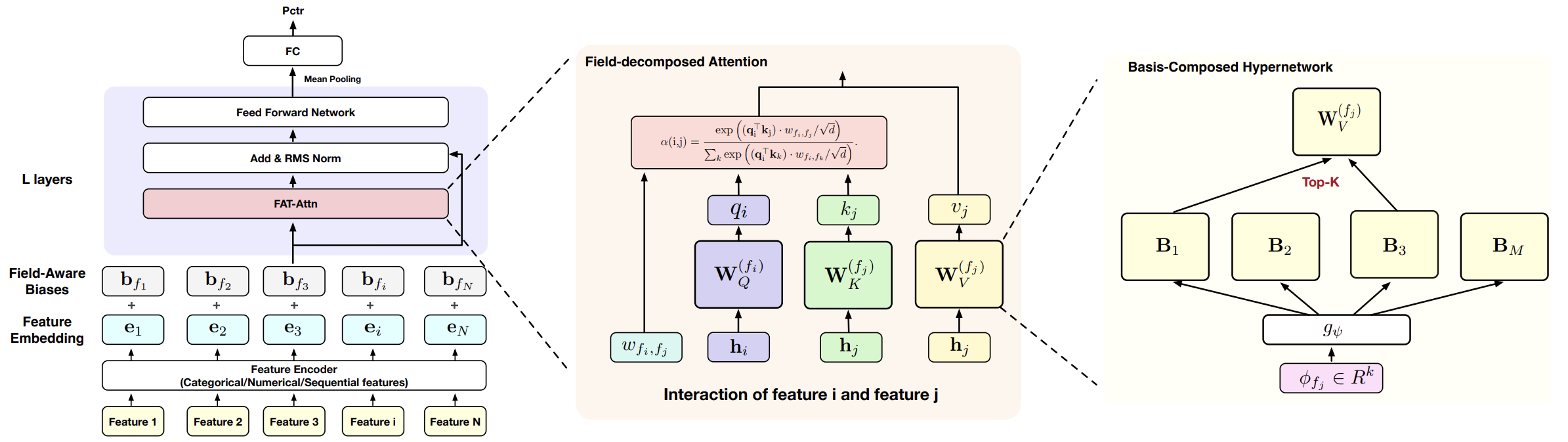
Именно на этом противоречии строится концепция Field-Aware Transformer (FAT). Его ключевая идея проста и в то же время фундаментальна. Если структура данных известна заранее, её необходимо учитывать на уровне архитектуры, а не оставлять модели разбираться самой. В финансовых задачах это особенно важно. Игнорирование структурной декомпозиции приводит к размыванию сигналов, увеличению числа параметров и росту вычислительной энтропии.
FAT предлагает иной подход к построению внимания. Вместо глобального смешения всех признаков модель вводит явную декомпозицию по полям. Признаки группируются в логически связанные блоки. Для каждого блока формируются собственные проекции. Взаимодействия между блоками становятся контролируемыми и структурированными. Внимание перестаёт быть всеобщим голосованием и превращается в управляемую систему межмодальных связей.
Это решение выглядит консервативным. Авторы фреймворка FAT сознательно ограничивают свободу модели. Однако именно такие ограничения формируют устойчивые индуктивные предположения. А в условиях финансовых рынков устойчивость зачастую важнее универсальности.
Архитектурно фреймворк FAT опирается на несколько принципиальных положений. Во-первых, декомпозиция признаков на поля. Каждое поле представляет собой подпространство признаков с собственной семантикой. Например, ценовые лаги и технические индикаторы не должны конкурировать за внимание напрямую — их взаимодействие должно быть структурировано.
Во-вторых, параметризация проекций Query, Key и Value с учётом принадлежности к полю. В классическом трансформере используется единая линейная проекция на всё входное пространство. FAT заменяет её набором структурированных матриц, что позволяет учитывать специфику каждого блока признаков.
В-третьих, контролируемые межполевые взаимодействия. Авторы фреймворка FAT вводят механизм параметрического масштабирования внимания, позволяющий регулировать интенсивность взаимодействий между различными полями признаков. Такое масштабирование задаёт различную степень зависимости между модальностями и делает возможным моделирование как симметричных, так и однонаправленных связей. В результате внимание остаётся глобальным по своей природе, однако его структура становится управляемой. Сила влияния одного поля на другое определяется встроенной параметризацией. Это усиливает индуктивные предположения модели и делает межфакторные зависимости более устойчивыми.
Наконец, четвёртый аспект — масштабируемость. Поскольку взаимодействия ограничены структурой полей, рост числа признаков не приводит к квадратичному росту числа свободных параметров в той же степени, как в классическом Self-Attention. Для задач с большим количеством факторов это принципиально.
Реализация нейросетевой архитектуры в торговой платформе — это всегда баланс между теорией и практикой. С одной стороны, необходимо сохранить математическую целостность модели, с другой — обеспечить вычислительную эффективность, числовую устойчивость и корректную работу.
Работа над FAT — это попытка сформировать структурированную, масштабируемую и адаптивную основу для построения торговых моделей.
Объект свертки с учетом особенностей поля
В предыдущей статье мы реализовали модуль генерации модально-зависимых параметров CFieldAwareParams. Он отвечает за формирование весов с учётом структуры полей. Однако сами параметры — это лишь заготовка. Чтобы архитектура FAT начала работать как целостная система, необходим механизм, который применит эти параметры к данным, выполнит проекцию и встроит результат в общий вычислительный поток модели. Именно эту роль берёт на себя класс CNeuronFieldAwareConv.
По своей природе это специализированный нейрон свёрточного типа, адаптированный под логику Field-Aware Transformer. В отличие от классических сверточных слоёв, где веса статичны и напрямую хранятся в объекте, здесь параметризация формируется динамически через CFieldAwareParams. Таким образом, объект оперирует структурированными, модально-зависимыми проекциями, которые учитывают принадлежность признаков к различным полям.
class CNeuronFieldAwareConv : public CNeuronBaseOCL { protected: CFieldAwareParams cParams; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronFieldAwareConv(void) {}; ~CNeuronFieldAwareConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_out, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronFieldAwareConv; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Новый объект наследуется от CNeuronBaseOCL, что сразу задаёт вычислительную среду. Все ключевые операции выполняются через OpenCL. Это не формальность. В условиях финансовых рынков эффективность — не академический вопрос, а инженерная необходимость. Любая избыточная аллокация памяти или лишний проход по данным мгновенно отражаются на времени принятия решения. Поэтому CNeuronFieldAwareConv объединяет генерацию параметров, прямой проход и обратное распространение в рамках единой структуры, минимизируя накладные расходы.
Инициализация объекта — это не формальность и не техническая рутина. Именно на этом этапе закладывается структурная логика всей последующей работы. Достаточно внимательно посмотреть на метод инициализации, чтобы увидеть, как теоретическая архитектура аккуратно переводится в вычислительные параметры.
bool CNeuronFieldAwareConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_out, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * fields, optimization_type, batch)) ReturnFalse;
Сначала вызывается базовая инициализация родительского класса. Здесь размер буфера результатов определяется как window_out * fields. Это уже важный сигнал: слой изначально мыслит данными как структурой, пространство признаков формируется осознанно — с учётом их модальной принадлежности.
Далее инициализируется объект cParams. И вот здесь сосредоточена вся философия FAT.
if(!cParams.Init(0, 0, OpenCL, window_in * window_out, fields, embed_size, candidates, topK, optimization, iBatch)) ReturnFalse; cParams.SetActivationFunction(None); //--- return true; }
В параметрах явно задаются:
- произведение window_in * window_out — масштаб взаимодействия между входным и выходным контекстом;
- число полей fields, определяющее модальную декомпозицию;
- размер embedding-пространства embed_size, задающий ёмкость внутреннего представления;
- количество кандидатов candidates, формирующее библиотеку возможных проекций;
- механизм отбора topK.
Это управляемая система, где каждый аргумент влияет на геометрию вычислений. Увеличение числа полей расширяет пространство межмодальных взаимодействий, изменение размера embedding регулирует выразительность модели, рост числа кандидатов увеличивает гибкость параметризации, а topK действует как дисциплинирующий механизм — он не позволяет модели разрастаться бесконтрольно, сохраняя вычислительный баланс.
Обратите внимание и на то, что для cParams активационная функция явно устанавливается как None. Это не случайность. Модуль генерации параметров не должен искажать структуру через нелинейность. Его задача — сформировать корректную геометрию проекций. Нелинейность будет применяться позже, в соответствующих слоях, здесь же важна чистота линейной параметризации.
Таким образом, метод инициализации фиксирует архитектурные принципы: структурированность, масштабируемость и контролируемую сложность. Именно здесь становится видно, что FAT — это продуманная система. В ней параметры и вычислительная структура развиваются согласованно.
И в этом, пожалуй, главное отличие от типичных реализаций. Мы не подгоняем архитектуру под данные. Мы сразу задаём правильную форму пространства, в котором модель будет учиться.
Прямой проход в CNeuronFieldAwareConv устроен предельно дисциплинированно. Никакой магии, только чёткая последовательность шагов.
bool CNeuronFieldAwareConv::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain) if(!cParams.FeedForward()) ReturnFalse;
Если слой находится в режиме обучения, первым делом актуализируются параметры модели. Это принципиальный момент. Параметры не считаются заранее и навсегда, они формируются динамически, и в обучающем режиме слой обязан обновить их перед применением. В режиме инференса этот шаг пропускается — вычислительная экономия без потери корректности.
Далее из cParams извлекается количество полей. На основании этого вычисляется window_out — фактически размер выходного окна на одно поле. Он определяется как общее число нейронов слоя, делённое на число полей. Это снова подчёркивает структурную природу данных: выход не является монолитным вектором, он организован как набор полевых сегментов.
uint fields = cParams.GetFieals(); uint window_out = Neurons() / fields; uint window_in = cParams.Neurons() / (fields * window_out);
Затем вычисляется window_in. Он определяется через количество нейронов в cParams деленное на произведение числа полей и window_out. Иными словами, размер входного контекста выводится из уже сформированной параметрической структуры. Это не произвольное число — оно строго согласовано с геометрией модально-зависимых весов.
После проверки корректности входного слоя начинается ключевой этап — матричное умножение.
if(!NeuronOCL || NeuronOCL.Neurons() < int(window_in * fields)) ReturnFalse; if(!MatMul(NeuronOCL.getOutput(), cParams.getOutput(), Output, 1, window_in, window_out, fields, true)) ReturnFalse; dActivation(this); //--- return true; }
Вот здесь и происходит реальная проекция. Входной тензор умножается на модально-зависимые параметры. Причём операция выполняется с учётом числа полей. Это не обычное умножение двух плоских матриц. Это структурированная операция, где пространство разбито на сегменты по полям, а параметры уже организованы соответствующим образом.
Фактически каждый фрагмент входного окна, принадлежащий определённому полю, проецируется через собственную часть параметрического пространства. Межполевые взаимодействия при этом возникают не случайно, а через геометрию сформированных весов.
После проекции применяется заданная пользователем функция активации. И только на этом этапе результат становится полноценным выходом слоя.
Если посмотреть на всю процедуру целиком, видно важное отличие от классической линейной трансформации. Здесь сначала формируется структурированное пространство параметров, затем строго согласовывается размер входного и выходного контекста, и лишь после этого выполняется вычисление. Всё подчинено одной логике — сохранить модальную структуру данных на уровне алгебры.
Это аккуратная, но очень принципиальная деталь. Слой не просто умножает матрицы. Он поддерживает архитектурную дисциплину FAT на каждом шаге прямого прохода. И именно поэтому модель остаётся масштабируемой и численно устойчивой даже при увеличении числа полей и признаков.
Если смотреть шире, CNeuronFieldAwareConv — это практическое воплощение идеи Field-Aware проекции. Он соединяет теоретическую концепцию структурной декомпозиции с реальным вычислительным механизмом. Здесь нет случайного смешения признаков. Каждая проекция подчинена логике модальной принадлежности.
Модуль полеориентированного внимания
После того как мы реализовали объект свёртки с учётом особенностей полей, естественным продолжением становится создание компонента, который будет управлять вниманием на уровне полей. Этот объект — ядро идеи Field-Aware Transformer. Здесь внимание перестаёт быть универсальным и одинаковым для всех признаков. Вместо этого оно становится полеориентированным.
Каждое поле получает собственное представление. Каждая проекция формируется с учётом модальной принадлежности признаков. А взаимодействия между полями регулируются через параметрическое масштабирование. Таким образом, внимание перестаёт быть хаотичным или всем на всех, оно становится управляемым и интерпретируемым, отражая реальную структуру данных.
На первом этапе мы реализуем алгоритм внимания непосредственно на стороне OpenCL-программы, чтобы обеспечить максимальную скорость и контроль над памятью. Важный инженерный момент — буферы Query и Key-Value намеренно разделены. Это не случайность, а стратегическое решение — оно закладывает основу для дальнейшего построения объектов Self‑FAT и Cross‑FAT, где одни и те же представления могут использоваться в разных комбинациях внимания без лишнего копирования данных.
__kernel void MHFAT(__global const float *q, __global const float *kv, __global const float *scale, __global float *scores, __global float *out, const int dimension, const int mask_future ) { //--- init const int q_id = get_global_id(0); const int k_id = get_local_id(1); const int h_id = get_global_id(2); const int total_q = get_global_size(0); const int total_k = get_local_size(1); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE];
Кернел MHFAT начинает работу с инициализации индексов глобальных и локальных потоков, а также номера головы внимания. Локальный буфер temp создаётся для накопления промежуточных значений в пределах одного блока, что позволяет эффективно выполнять нормализацию и суммирование без обращения к глобальной памяти. Такой подход критически важен для быстрого вычисления при больших размерах окон и числа полей.
Далее вычисляются смещения для каждого потока.
//--- Shifts const int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id); const int shift_k = RCtoFlat(h_id, 0, total_heads, dimension, 2 * k_id); const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 2 * k_id + 1); const int shift_s = RCtoFlat(h_id, k_id, total_heads, total_k, q_id); const int shift_out = RCtoFlat(h_id, 0, total_heads, dimension, q_id);
Эти смещения обеспечивают корректное выравнивание элементов Query, Key и Value по головам и по полям, гарантируя, что каждый поток оперирует строго своим сегментом данных. Именно это превращает обычное скалярное умножение в модально-структурированную проекцию внимания.
Затем происходит основной расчёт — Score. Для каждой пары Query–Key вычисляется скалярное произведение по всем измерениям embedding.
//--- Score float score = 0; if(mask_future == 0 || q_id <= k_id) { for(int d = 0; d < dimension; d++) { float q_ = IsNaNOrInf(q[shift_q + d], 0.0f); if(q_ == 0) continue; float k = IsNaNOrInf(kv[shift_k + d], 0.0f); if(k == 0) continue; score += q_ * k; } score *= IsNaNOrInf(scale[shift_s], 0.0f); } else score = MIN_VALUE; //--- norm score score = LocalSoftMax(score, 1, temp); scores[shift_s] = score;
Важная особенность: применяются проверки на NaN и Inf. Это не декоративная защита — финансовые данные часто содержат выбросы или пропуски, и любая ошибка на этом уровне может разрушить весь проход внимания. Масштабирование score *= scale задаётся через отдельный буфер scale, что позволяет модульно регулировать влияние каждого элемента без изменения базовых проекций.
Если используется маскирование будущих значений (mask_future), то ядро корректно игнорирует будущие токены, обеспечивая возможность последовательного прогнозирования, как в классическом Self-Attention.
Нормализация проводится через SoftMax, который аккуратно использует локальный буфер temp. Это делает распределение весов стабильным и контролируемым и не создавая узких мест в производительности.
Наконец, вычисляется выход out. Каждый элемент Value масштабируется на нормализованный Score и суммируется по локальному буферу.
//--- out for(int d = 0; d < dimension; d++) { float val = 0; if(score > 0) { float v = IsNaNOrInf(kv[shift_v + d], 0); if(v != 0) val = v * score; } val = LocalSum(val, 1, temp); if(k_id == 0) out[shift_out + d] = val; } }
Только один поток записывает результат в глобальную память, что предотвращает гонки данных и обеспечивает детерминированность. Этот шаг аккуратно объединяет модально-зависимые веса с входными представлениями, создавая окончательное полеориентированное внимание.
В итоге мы получаем высокопроизводительный, управляемый компонент внимания, который полностью сохраняет структуру FAT. Каждое поле имеет собственное представление, межполевые зависимости регулируются через параметры Scale, а вычислительная нагрузка распределена эффективно между потоками OpenCL.
Следующим этапом нашей работы становится интеграция этого механизма в основную программу с помощью объекта CNeuronMHFAT. Этот объект — настоящая инженерная реализация многоголовой архитектуры FAT, где каждая голова внимания работает как самостоятельный детектор структурных связей между полями признаков.
class CNeuronMHFAT : public CNeuronMSRes { protected: uint iHeads; //--- CNeuronFieldAwareConv cQ_Embedding; CNeuronFieldAwareConv cKV_Embedding; CParams cScale; int ibScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronSpikeConvBlock cW0; CNeuronBaseOCL cAttentionOut; //--- virtual bool Attention(void); virtual bool AttentionGradients(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHFAT(void) {}; ~CNeuronMHFAT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMHFAT; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Ключевой параметр iHeads определяет количество параллельных представлений, которые формируются для каждого окна данных, позволяя модели одновременно фиксировать разные аспекты межполевых зависимостей и строить управляемые, интерпретируемые представления.
Внутри CNeuronMHFAT выделяются два блока для генерации проекций:
- cQ_Embedding формирует представления Query,
- cKV_Embedding — Key и Value.
Оба компонента построены на основе CNeuronFieldAwareConv, и именно здесь проявляется философия FAT. Каждый блок учитывает модальную структуру данных, аккуратно распределяет вычисления по полям и формирует параметры так, чтобы межполевые зависимости были встроены в геометрию представлений. Эти внутренние объекты создают основу, на которой строится механизм внимания — дисциплинированно, с учётом структуры рынка и особенностей исходных сигналов.
Непосредственно механизм внимания реализован через OpenCL‑кернел, описанный ранее. Он получает проекции Query и Key-Value и возвращает взвешенные комбинации в cMHAttentionOut. Здесь важно отметить, что результат многоголового внимания ещё не готов к использованию напрямую. Каждый выходной фрагмент содержит информацию о взаимодействиях разных полей, которую необходимо аккуратно агрегировать. Для этого используется модуль cW0, который сжимает многоголовое внимание, упорядочивает его и позволяет корректно интегрировать с исходными данными.
После этой операции результат суммируется с базовыми представлениями в cAttentionOut, создавая согласованное, структурированное внутреннее состояние слоя, готовое к дальнейшей обработке.
Инициализация CNeuronMHFAT — это больше, чем простое присвоение параметров. Здесь закладывается структура всего объекта и определяется, как он будет работать с данными на уровне каждой головы внимания.
bool CNeuronMHFAT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMSRes::Init(numOutputs, myIndex, open_cl, fields, window, 1, optimization_type, batch)) ReturnFalse;
Сначала вызывается инициализация родительского класса, которая задаёт базовые размеры и конфигурацию блока.
После этого сохраняется число голов, которое определяет, сколько параллельных представлений будет формироваться для каждого окна.
iHeads = heads;
Каждая голова — это отдельный поток обработки, способный фиксировать разные аспекты межполевых зависимостей.
Затем последовательно инициализируются проекционные слои. Оба слоя используют модально-зависимые свёртки, при этом для них задаются функции активации SoftPlus, что обеспечивает плавную нелинейность и стабильность численных вычислений.
uint index = 0; if(!cQ_Embedding.Init(0, index, OpenCL, window, window_key * iHeads, fields, embed_size, candidates, topK)) ReturnFalse; cQ_Embedding.SetActivationFunction(SoftPlus); index++; if(!cKV_Embedding.Init(0, index, OpenCL, window, 2 * window_key * iHeads, fields, embed_size, candidates, topK)) ReturnFalse; cKV_Embedding.SetActivationFunction(SoftPlus);
Следующий важный шаг — инициализация компонента cScale, который отвечает за масштабирование Attention‑Score.
index++; if(!cScale.Init(0, index, OpenCL, cQ_Embedding.GetUnits() * cKV_Embedding.GetUnits() * iHeads, optimization, iBatch)) ReturnFalse; cScale.SetActivationFunction(TANH);
Здесь применяется TANH, чтобы значения оставались в контролируемом диапазоне, предотвращая взрыв градиентов и обеспечивая управляемую динамику внимания.
Память под вычисление Score выделяется отдельно в буфере ibScoreIndex, что позволяет OpenCL‑ядру аккуратно и эффективно хранить результаты промежуточных вычислений.
ibScoreIndex = OpenCL.AddBuffer(sizeof(float) * cScale.Neurons(), CL_MEM_READ_WRITE); if(ibScoreIndex == INVALID_HANDLE) ReturnFalse;
Далее создаётся объект cMHAttentionOut, который аккумулирует результаты многоголового внимания. Поскольку это промежуточное представление, активация здесь отсутствует, чтобы не искажать структуру вычислений.
index++; if(!cMHAttentionOut.Init(0, index, OpenCL, cQ_Embedding.Neurons(), optimization, iBatch)) ReturnFalse; cMHAttentionOut.SetActivationFunction(None);
После него инициализируется cW0 — свёрточный блок, который сжимает многоголовое внимание и подготавливает его к интеграции с исходными данными.
index++; if(!cW0.Init(0, index, OpenCL, window_key * iHeads, window * iHeads, window, fields, 1, optimization, iBatch)) ReturnFalse;
A завершает цепочку cAttentionOut, аккуратно агрегирующий информацию для дальнейшей обработки.
index++; if(!cAttentionOut.Init(0, index, OpenCL, cW0.Neurons(), optimization, iBatch)) ReturnFalse; //--- return true; }
Каждый параметр и каждый шаг инициализации имеют конкретное назначение. Увеличение числа голов расширяет спектр отслеживаемых зависимостей. Размер embedding‑пространства регулирует ёмкость представления. Количество кандидатов и top-K ограничивают сложность, предотвращая избыточное разрастание вычислений. Все эти настройки вместе создают управляемый, масштабируемый и детерминированный модуль, который точно следует архитектуре FAT и готов эффективно работать на финансовых потоках данных.
Прямой проход — это тщательно организованный процесс, в котором каждый компонент модуля выполняет строго свою роль.
bool CNeuronMHFAT::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cQ_Embedding.FeedForward(NeuronOCL)) ReturnFalse; if(!cKV_Embedding.FeedForward(NeuronOCL)) ReturnFalse;
Сначала вызываются методы FeedForward для проекционных слоёв cQ_Embedding и cKV_Embedding. Они формируют представления Query, Key и Value с учётом модально-зависимых свёрток, превращая анализируемые данные в структурированные тензоры, готовые для расчёта внимания.
Если модель находится в режиме обучения, дополнительно обновляются масштабирующие параметры через cScale.
if(bTrain) if(!cScale.FeedForward()) ReturnFalse;
Этот шаг обеспечивает динамическое регулирование влияния каждого элемента внимания, контролируя взвешенные связи между полями и предотвращая числовую нестабильность.
Далее вызывается метод Attention, который вызывает OpenCL‑кернел.
if(!Attention())
ReturnFalse;
Здесь вычисляются скалярные произведения Query и Key с учетом коэффициентов зависимости полей, нормализуются через SoftMax и перемножаются с Value, формируя взвешенные комбинации для каждой головы. Промежуточные результаты сохраняются в cMHAttentionOut, аккумулируя информацию обо всех межполевых взаимодействиях.
После этого свёрточный блок cW0 сжимает многоголовое внимание, упорядочивает данные и готовит их к интеграции с исходным сигналом.
if(!cW0.FeedForward(cMHAttentionOut.AsObject()))
ReturnFalse;
Агрегация выполняется через SumAndNormalize, где результаты cW0 суммируются с анализируемым сигналом, создавая согласованное представление в cAttentionOut.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), cW0.GetFilters(), true, 0, 0, 0, 1)) ReturnFalse;
На этом этапе модуль объединяет локальные корреляции и глобальные межполевые зависимости, создавая внутреннее состояние, которое максимально отражает структуру исходных данных.
Наконец, готовое представление передаётся родительскому классу CNeuronMSRes, который выполняет функционал стандартного блока Feed-Forward, обеспечивая совместимость с последующими слоями.
if(!CNeuronMSRes::feedForward(cAttentionOut.AsObject())) ReturnFalse; //--- return true; }
Вся последовательность работы прямого прохода демонстрирует главный принцип FAT. Сначала структурируются анализируемые данные через модально-зависимые свёртки, затем формируется управляемое многоголовое внимание, потом результаты аккуратно сжимаются и интегрируются с исходным сигналом, и только после этого данные передаются дальше.
Прямой проход — это лишь половина пути. Пока модель только формирует представления, но прогноз, основанный на случайных параметрах, малоинформативен. Чтобы слой начал действительно выявлять структурные закономерности в данных, необходим этап обучения. А ключевым элементом этого процесса является корректное распределение градиентов ошибки по всей цепочке вычислений. В CNeuronMHFAT это реализовано в методе calcInputGradients.
bool CNeuronMHFAT::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) ReturnFalse;
Процесс начинается с проверки наличия предыдущего слоя — без него распространение градиентов невозможно. Затем вызывается одноименный метод родительского класса, который спускает градиенты ошибки на уровень внутренних компонентов модуля.
if(!CNeuronMSRes::feedForward(cAttentionOut.AsObject()))
ReturnFalse;
Следующий шаг — корректировка полученных значений на производную функции активации для блока cW0.
if(!DeActivation(cW0.getOutput(),cW0.getGradient(),cAttentionOut.getGradient(),cW0.Activation()))
ReturnFalse;
В рамках прямого прохода этот модуль сжимает многоголовое внимание, и корректное распространение градиентов через него критично. Именно здесь вычисляется, как ошибки на выходе слоя влияют на каждую голову внимания и на локальные корреляции внутри блока.
После этого градиенты передаются в cMHAttentionOut, аккумулируя ошибки от всех голов.
if(!cMHAttentionOut.CalcHiddenGradients(cW0.AsObject()))
ReturnFalse;
Метод AttentionGradients затем распределяет градиенты через сам OpenCL‑кернел, обеспечивая, чтобы каждая проекция Query, Key и Value получила свою долю коррекции.
if(!AttentionGradients())
ReturnFalse;
Далее градиенты направляются обратно на уровень исходных данных через проекционные слои cQ_Embedding и cKV_Embedding.
if(!prevLayer.CalcHiddenGradients(cQ_Embedding.AsObject())) ReturnFalse; if(prevLayer.Activation()!=None) if(!DeActivation(prevLayer.getOutput(),cAttentionOut.getGradient(),cAttentionOut.getGradient(), prevLayer.Activation())) ReturnFalse; if(!SumAndNormilize(prevLayer.getGradient(),cAttentionOut.getGradient(),cAttentionOut.getGradient(), 1,false,0,0,0,1)) ReturnFalse; if(!prevLayer.CalcHiddenGradients(cKV_Embedding.AsObject())) ReturnFalse; if(!SumAndNormilize(prevLayer.getGradient(),cAttentionOut.getGradient(),prevLayer.getGradient(), 1,false,0,0,0,1)) ReturnFalse; //--- return true; }
Здесь выполняются все необходимые операции по распределению и суммированию градеинтов через все информационные потоки, чтобы корректно объединить ошибку и подготовить её для обновления весов. Этот этап гарантирует, что каждая модально-зависимая свёртка получает точное направление для корректировки своих весов, а масштабирование внимания через cScale остаётся согласованным с общей структурой слоя.
В итоге метод calcInputGradients аккуратно и детерминировано распределяет ошибку по всей структуре модуля, от многоголового внимания до модально-зависимых свёрток, обеспечивая корректное обучение. Именно здесь теория превращается в практику. Правильное распределение градиентов позволяет модели постепенно научиться выявлять скрытые структурные сигналы в финансовых данных, превращая случайные проекции в управляемые, информативные представления.
В результате CNeuronMHFAT превращается в полноценный инструмент анализа структурных зависимостей. Каждая голова внимания выполняет свою роль, каждая проекция обрабатывается через модально-зависимые свёртки, а OpenCL‑ядро обеспечивает высокую скорость даже при больших объёмах данных. Объект одновременно управляемый, масштабируемый и детерминированный. Он аккуратно интегрирует теоретическую архитектуру FAT в практическую вычислительную реализацию. Именно здесь концепция Field-Aware Transformer оживает, превращаясь в компонент, способный выявлять скрытые структурные сигналы в динамике финансовых рынков, аккуратно упорядочивая хаотичный поток данных в понятное и управляемое внутреннее представление.
Заключение
Фреймворк FAT демонстрирует высокую гибкость в построении торговых моделей с учётом структурных особенностей финансовых потоков. Реализация модально-зависимых свёрток, полеориентированного и многоголового механизма внимания обеспечивает точное моделирование межмодальных взаимодействий, позволяя системе выявлять скрытые закономерности и структурные сигналы даже в шумных данных.
Одним из ключевых преимуществ фреймворка является детерминированность и управляемость всех этапов вычислений. Это позволяет одновременно сохранять высокую производительность, обеспечиваемую OpenCL, и надёжность обучения через корректное распределение градиентов ошибки.
Кроме того, архитектура FAT обладает высокой масштабируемостью. Возможность параллельной обработки нескольких голов внимания и модально-зависимых полей обеспечивает гибкость при расширении модели, позволяя адаптировать её под разные задачи прогнозирования и под различные объёмы данных.
В совокупности, все эти элементы формируют уникальное сочетание модульности, точности и эффективности, делая фреймворк FAT мощным инструментом для анализа финансовых потоков и построения торговых стратегий.
Ссылки
- From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования