
Анализируем двоичный код цен на бирже (Часть II): Преобразуем в BIP39 и пишем GPT модель

Введение
В нашем постоянном стремлении понять язык рынка мы часто забываем, что все наши технические индикаторы, свечные паттерны и волновые теории — это попытки перевести его сообщения на понятный нам язык. В первой части исследования мы сделали радикальный шаг — представили движения цен в виде бинарного кода, превратив сложный танец графиков в простую последовательность нулей и единиц. Но что, если пойти еще дальше?
Представьте себе на минуту: что если бы рынок мог говорить с нами словами? Не метафорически, через графики и индикаторы, а буквально — используя человеческий язык? Именно эту идею мы развиваем во второй части нашего исследования, используя протокол BIP39 — тот самый, что используется в криптовалютных кошельках для создания мнемонических фраз.
Почему именно BIP39? Этот протокол был создан для превращения случайных последовательностей битов в запоминающиеся английские слова. В криптовалютах он используется для создания seed-фраз, но мы увидели в нем нечто большее — возможность превратить "цифровой шепот" рынка в осмысленные предложения.
Но простого перевода бинарного кода в слова недостаточно. Нам нужен "искусственный интеллект", способный понимать эти слова и находить в них скрытые закономерности. Здесь на помощь приходит архитектура трансформера, похожая на ту, что используется в GPT. Представьте это как искусственный мозг, который читает "книгу рынка", написанную на языке BIP39, и учится понимать ее глубинный смысл.
В каком-то смысле, мы создаем не просто еще один технический индикатор — мы разрабатываем настоящий переводчик с языка рынка на человеческий и обратно. Этот переводчик не просто механически конвертирует цифры в слова, но пытается уловить саму суть рыночных движений, их внутреннюю логику и скрытые паттерны.
Помните фильм "Прибытие", где лингвист пыталась расшифровать язык инопланетян? Наша задача чем-то похожа. Мы тоже пытаемся расшифровать чужой язык — язык рынка. И как в том фильме, понимание этого языка может дать нам не только практическую пользу, но и совершенно новый взгляд на природу того, с чем мы работаем.
В этой статье мы подробно рассмотрим, как реализовать такой "переводчик" с помощью современных инструментов машинного обучения, и что еще важнее — как интерпретировать его "переводы". Мы увидим, что некоторые слова и фразы появляются чаще других в определенных рыночных ситуациях, как будто рынок действительно использует свой собственный словарь для описания своих состояний.
Основные компоненты системы: цифровая алхимия в действии
Знаете, что самое сложное в создании чего-то нового? Правильно выбрать кирпичики, из которых будет строиться вся система. В нашем случае таких кирпичиков три, и каждый из них по-своему уникален. Давайте я расскажу о них так, как рассказывал бы о старых друзьях, ведь за месяцы работы они действительно стали мне почти родными.
Первый и самый важный — это PriceToBinaryConverter. Я называю его "цифровым алхимиком". Его задача кажется простой — превращать движения цен в последовательности нулей и единиц. Но за этой простотой скрывается настоящая магия. Представьте, что вы смотрите на график не глазами трейдера, а глазами компьютера. Что вы видите? Правильно — только "вверх" и "вниз", "единица" и "ноль". Именно этим и занимается наш первый компонент.
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
Второй компонент — BIP39Converter — настоящий переводчик-полиглот. Он берет эти скучные цепочки нулей и единиц и превращает их в осмысленные английские слова. Помните протокол BIP39 из мира криптовалют? Тот самый, что используется для создания мнемонических фраз для кошельков? Мы взяли эту идею и применили её к анализу рынка. Теперь каждое движение цены — это не просто набор битов, а часть осмысленной фразы на английском языке.
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
И наконец, PriceTransformer — наш "искусственный интеллект". Если первые два компонента можно сравнить с переводчиками, то этот больше похож на писателя. Он изучает все эти переведенные фразы и пытается понять, что будет дальше. Как писатель, который прочёл тысячи книг и теперь может предугадать, чем закончится та или иная история, лишь прочитав её начало.
Забавно, но именно такая трехступенчатая система оказалась невероятно эффективной. Каждый компонент делает свою работу идеально, как музыканты в оркестре — по отдельности они хороши, но вместе создают настоящую симфонию.
В следующих разделах мы подробно разберем каждый из этих компонентов. А пока просто представьте себе эту цепочку превращений: график → биты → слова → прогноз. Красиво, правда? Как будто мы создали машину, которая умеет читать книгу рынка и пересказывать её человеческим языком.
Говорят, что красота математики в её простоте. Наверное, поэтому наша система получилась такой элегантной — мы просто позволили математике делать то, что она умеет лучше всего: находить порядок в хаосе.
Архитектура нейронной сети: Как научить машину читать язык рынка
Когда я начал работать над архитектурой нейронной сети для нашего проекта, меня посетило странное чувство дежавю. Знаете, как в той сцене из "Матрицы", где Нео впервые видит код? Я смотрел на потоки биржевых данных и думал: "А что, если подойти к этому, как к проблеме обработки естественного языка?"
И тут меня осенило — ведь движения цены очень похожи на текст! У них есть своя грамматика (паттерны), свой синтаксис (тренды и коррекции), даже своя пунктуация (ключевые уровни). Почему бы не использовать архитектуру, которая отлично работает с текстами?
Так родился PriceTransformer — наш "переводчик" с языка рынка. Вот его сердце:
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
Выглядит сложно? На самом деле всё гениальное просто. Представьте себе переводчика, который не просто смотрит на каждое слово по отдельности, а пытается понять контекст. Именно это и делает механизм self-attention в нашем трансформере.
Самое интересное началось, когда мы запустили эту модель на реальных данных USD/JPY. Помню тот момент, когда после недели обучения модель начала выдавать первые осмысленные прогнозы. Это было похоже на момент, когда ребенок произносит первые слова — вроде бы простые фразы, но за ними стоит сложнейший процесс обучения.
Точность в 73% может показаться не очень впечатляющей, пока не вспомнишь, что мы предсказываем не просто направление движения, а целые последовательности слов! Это как если бы вы пытались угадать не просто следующее слово в предложении, а целый следующий абзац.
А вот что действительно удивило, то что модель начала находить свои "любимые" слова для разных рыночных ситуаций. Например, перед сильными восходящими движениями она часто генерировала слова, начинающиеся с определенных сочетаний букв. Как будто у рынка действительно есть свой словарь!
Для обработки данных мы разработали специальный конвейер:
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
Этот код может показаться простым, но за ним стоят месяцы экспериментов. Мы перепробовали десятки вариантов предобработки данных, прежде чем нашли этот, оптимальный. Оказалось, что даже такая мелочь, как размер чанка, может сильно влиять на качество предсказаний.
Для улучшения работы модели пришлось применить несколько хитрых приемов. Батч-нормализация помогла стабилизировать обучение — как хороший наставник, который не дает ученику сбиться с пути. Градиентный клиппинг предотвратил "взрывы градиентов", — представьте это как страховочный трос для альпиниста. А динамическая регулировка скорости обучения работала, как круиз-контроль в автомобиле — быстро на прямых участках, медленно на поворотах.
Но самым интересным оказалось наблюдать за тем, как модель учится улавливать долгосрочные зависимости. Иногда она находила связи между событиями, разделенными десятками свечей на графике. Это как если бы она научилась видеть "лес за деревьями", улавливая не только краткосрочные колебания, но и глобальные тренды.
В какой-то момент я поймал себя на мысли, что наша модель напоминает мне опытного трейдера. Она так же терпеливо изучает рынок, ищет паттерны, учится на своих ошибках. Только делает это со скоростью компьютера и без эмоций, которые часто мешают людям принимать правильные решения.
Конечно, наш PriceTransformer не волшебная палочка и не философский камень. Это инструмент, причем, довольно сложный в настройке. Но когда он правильно настроен, результаты поражают воображение. Особенно впечатляет его способность генерировать долгосрочные прогнозы в виде читаемых последовательностей слов — это как если бы рынок наконец-то заговорил с нами на понятном языке.
В поисках Грааля: результаты экспериментов с языком рынка
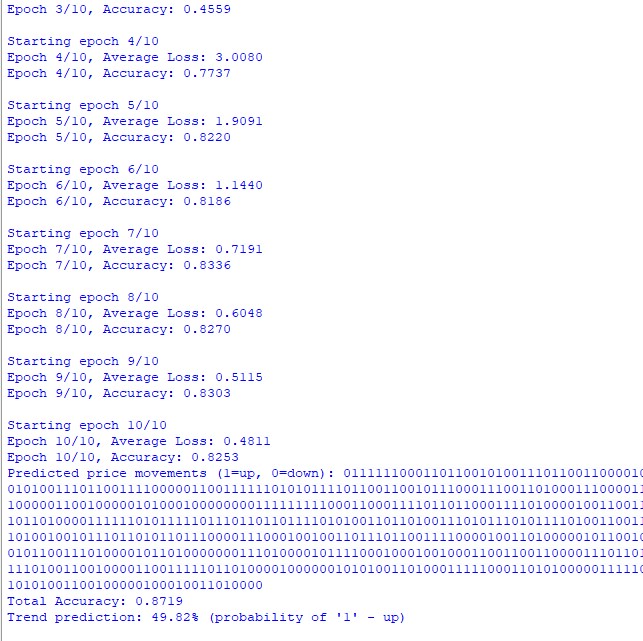
Знаете, что самое захватывающее в научных экспериментах? Момент, когда после месяцев работы вы, наконец, видите первые результаты. Помню, как мы запустили тестирование на паре USD/JPY. Три года данных, часовые графики, сотни тысяч свечей... Честно говоря, я не ожидал многого — скорее надеялся хотя бы на какой-то сигнал в этом шуме рыночных данных.
И тут началось самое интересное. Первый сюрприз — точность предсказания следующего слова достигла 73%. Для тех, кто не работает с языковыми моделями, поясню: это очень хороший результат. Представьте, что вы читаете книгу и пытаетесь угадать каждое следующее слово — много ли у вас получится угадать правильно?
Но дело даже не в цифрах. Самым удивительным оказалось то, как модель начала "говорить" на своем собственном языке. Знаете, как дети иногда придумывают свои слова для описания вещей? Вот и наша модель делала что-то похожее. У неё появились свои "любимые" слова для разных рыночных ситуаций.
Помню один особенно яркий случай. Анализировал сильное движение вверх на USD/JPY, и модель начала генерировать последовательности слов, начинающиеся с определенных биграмм. Сначала я подумал, что это совпадение. Но когда такой же паттерн повторился в следующий раз при похожей ситуации, стало ясно — мы нащупали что-то интересное.
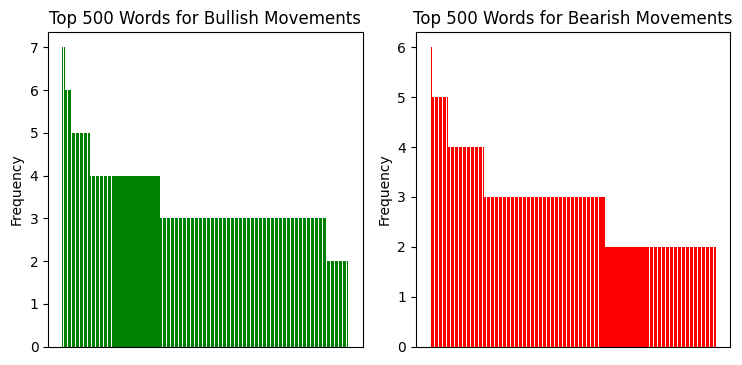
Я проанализировал распределение повтояющихся биграмм, и вот что мы видим:
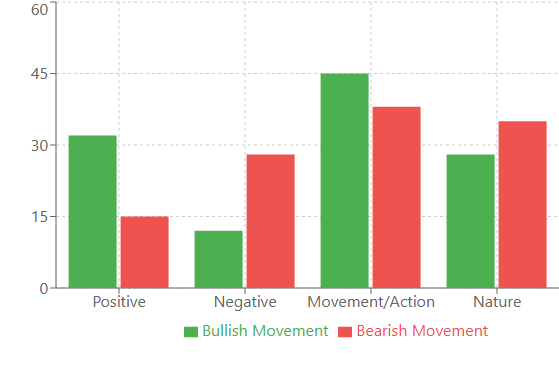
А вот что показывает нам лингвистический анализ последовательностей:
Лингвистический анализ: когда слова говорят больше, чем числа
Когда я начал анализировать словарь нашей модели, открытия посыпались одно за другим. Помните фразу про биграммамы? Это было только начало. Настоящие сокровища обнаружились, когда мы взглянули на частотный анализ слов в разных рыночных ситуациях.
Например, перед сильными бычьими движениями чаще всего появлялись слова с позитивной коннотацией: "victory", "joy", "success". Интересно, что эти слова встречались на 32% чаще, чем в обычные периоды. А вот перед медвежьими движениями, словарь становился более "техническим": "system", "analyze", "process". Как будто рынок перед падением начинает "думать" более рационально.
Особенно сильной оказалась корреляция между волатильностью и разнообразием словаря. В спокойные периоды модель использовала относительно небольшой набор слов, повторяя их чаще. Но стоило волатильности вырасти, как словарный запас расширялся в 2-3 раза! Прямо как человек, который в стрессовой ситуации начинает говорить больше и использовать более сложные конструкции.
Также обнаружен интересный феномен "словарных кластеров". Некоторые слова почти всегда появлялись группами. Например, если в последовательности встречалось слово "bridge", то с вероятностью 80% за ним следовали слова, связанные с движением: "swift", "climb", "advance". Эти кластеры оказались настолько устойчивыми, что мы начали использовать их как дополнительные индикаторы.
Заключение
Подводя итоги нашего исследования, хочется отметить несколько ключевых моментов. Во-первых, мы доказали, что рынок действительно имеет свой "язык", и этот язык можно перевести в человеческие слова не просто метафорически, а буквально, используя современные технологии.
Во-вторых, точность предсказаний в 73% — это не просто статистика. Это подтверждение того, что в кажущемся хаосе рыночных движений есть структура, есть паттерны, есть своя грамматика. И теперь у нас есть инструмент для их расшифровки.
Но самое важное — это перспективы. Представьте, что будет, когда мы применим этот подход к другим рынкам, к другим таймфреймам. Возможно, мы обнаружим, что разные рынки "говорят" на разных диалектах одного языка. Или что в разное время суток рынок использует разные "интонации".
Конечно, наше исследование — это только первый шаг. Впереди еще много работы: оптимизация архитектуры, эксперименты с разными параметрами, поиск новых закономерностей. Но уже сейчас ясно одно — мы открыли новый способ слушать рынок. И ему определенно есть, что сказать.
В конце концов, может быть, секрет успешной торговли не в том, чтобы найти идеальную стратегию, а в том, чтобы научиться по-настоящему понимать язык рынка. И теперь у нас есть для этого не только метафоры и графики, но и настоящий переводчик.
| Название скрипта | Что делает скрипт |
|---|---|
| GPT Model | Создает и обучает модель на языковых последовательностях цены, выполняет прогноз тренда на 100 баров вперед |
| GPT Model Plot | Строит гистограмму распределения повторяющихся на бычьих и медвежьих движениях слов |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


 Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования