
取引所価格のバイナリコードの分析(第2回):BIP39への変換とGPTモデルの記述

はじめに
市場の言語を理解しようとする際、私たちはしばしば、すべてのテクニカル指標、ローソク足パターン、波動理論は、市場からのメッセージを私たちが理解できる言語に翻訳しようとする試みであることを忘れてしまいがちです。研究の第1回では、思い切った一歩を踏み出しました。価格の動きをバイナリコードとして表現し、複雑なチャートの動きを単純な0と1の列に変換したのです。しかし、さらに一歩進めたらどうでしょうか。
少し想像してみてください。もし市場が私たちに言葉で語りかけてくるとしたら?比喩的にチャートや指標を通してではなく、文字通り人間の言語で?研究の第2回ではこのアイデアを展開し、BIP39プロトコルを用いる方法をご紹介します。BIP39は暗号通貨ウォレットでニーモニックフレーズを作るために使用されるプロトコルです。
BIP39を選ぶ理由は、このプロトコルが、ランダムなビット列を覚えやすい英単語に変換するために作られているということです。暗号通貨の世界ではシードフレーズの生成に使われますが、私たちはそこに別の可能性を見出しました。市場の「デジタルなささやき」を意味のある文章に変換する機会です。
しかし、単にバイナリコードを単語に翻訳するだけでは不十分です。これらの単語を理解し、隠れたパターンを見つけることのできる「人工知能」が必要です。ここで、GPTに使われているようなTransformerアーキテクチャが役立ちます。これは、BIP39言語で書かれた「市場の書」を読み、その深い意味を理解しようと学習する人工の脳のようなものです。
ある意味で、私たちは単なるテクニカル指標を作っているのではありません。市場の言語を人間の言語に、またその逆に翻訳する真の翻訳機を開発しているのです。この翻訳機は、数字を単に単語に変換するだけでなく、市場の動きそのものの本質や内部ロジック、隠れたパターンを捉えようと試みます。
映画『メッセージ』(原題:Arrival)で、言語学者が異星人の言語を解読しようとした場面を覚えていらっしゃいますか。私たちの課題も少し似ています。私たちは他者の言語、つまり市場の言語を解読しようとしているのです。そしてその言語を理解することで、実用的な利益だけでなく、私たちが扱っているものの本質に対するまったく新しい視点を得ることができるのです。
本記事では、現代の機械学習ツールを用いてそのような「翻訳機」を実装する方法を詳しく考察します。そして何よりも、その「翻訳」をどのように解釈するかに焦点を当てます。特定の市場状況では、特定の単語やフレーズが他よりも頻繁に現れることが分かります。まるで市場が独自の語彙を使って自らの状態を表現しているかのようです。
システムの主な構成要素:デジタル錬金術の実践
新しいものを創り出す際に最も難しいことをご存知でしょうか。それは、システム全体のための正しいブロックを選ぶことです。私たちの場合、そんなブロックが3つあります。そして、それぞれが独自の個性を持っています。ここでは、長い時間を共に過ごしてきた古い友人のように、それぞれを紹介します。数か月にわたる作業を通じて、ほとんど家族のような存在になったのです。
最初で最も重要な構成要素はPriceToBinaryConverterです。私はこれを「デジタル錬金術師」と呼んでいます。その役割は一見単純で、価格の動きを0と1の列に変換することです。しかし、この単純さの裏に本当の魔法があります。チャートをトレーダーの目で見るのではなく、コンピュータの目で見たと想像してみてください。何が見えるでしょうか。その通り、「上がるか下がるか」、「1か0か」だけです。まさに、この最初の構成要素がそれを実現しています。
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
2つ目の構成要素はBIP39Converter、つまり本物の多言語翻訳者です。この構成要素は、退屈な0と1の列を意味のある英単語に変換します。暗号通貨の世界のBIP39プロトコルを覚えていらっしゃいますか。ウォレットのニーモニックフレーズを作るためのものです。私たちはそのアイデアを市場分析に応用しました。これにより、価格の動きは単なるビットの集合ではなく、意味のある英語フレーズの一部になったのです。
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
最後にPriceTransformerです。これは私たちの「人工知能」にあたります。最初の2つの構成要素を翻訳者に例えるなら、この構成要素は作家のような存在です。翻訳されたフレーズを読み込み、次に何が起こるかを予測しようとします。まるで何千冊もの本を読んできて、物語の冒頭だけで結末を予測できる作家のようにです。
この3段階のシステムが、驚くほど効果的であることは面白いことに判明しました。それぞれの構成要素は自分の役割を完璧に果たします。オーケストラの演奏者のように、個々は優れていますが、共に演奏すると本物の交響曲を作り上げるのです。
次のセクションでは、これらの構成要素を詳しく分析していきます。今のところ、グラフ → ビット → 単語 → 予測の変換の連鎖を想像してみてください。美しいと思いませんか。まるで市場の本を読み、それを人間の言葉で語り直す機械を作ったかのようです。
数学の美しさはその「単純さ」にあると言われます。おそらくそれが、私たちのシステムが非常に洗練されたものになった理由でしょう。混沌の中に秩序をもたらすという数学の力を、そのまま活かしたのです。
ニューラルネットワークアーキテクチャ:機械に市場の言語の読み方を教える
私がこのプロジェクトのニューラルネットワークアーキテクチャに取り組み始めたとき、奇妙なデジャヴを感じました。『マトリックス』のあのシーンを覚えていますか。ネオが初めてコードを目にする場面です。私は取引所のデータスレッドを眺めながら、「これを自然言語処理の問題として扱ったらどうなるだろう」と考えていました。
そしてふと思いつきました。そもそも価格の動きはテキストに非常によく似ているのです。独自の文法(パターン)、独自の構文(トレンドや調整)、さらには独自の句読点(重要な価格帯)まで持っています。テキストに強いアーキテクチャを使ってみてはどうでしょうか。
こうしてPriceTransformerが誕生しました。市場の言語を翻訳する「翻訳者」です。その心臓部は以下の通りです。
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
複雑に見えますか。実際には、天才的なものほど単純です。単語一つひとつを見るだけでなく、文脈を理解しようとする翻訳者を想像してください。それが、Transformerの自己アテンション機構の役割です。
最も興味深かったのは、このモデルを実際のUSD/JPYデータに投入したときです。1週間の学習後、モデルが最初の意味のある予測を出し始めた瞬間を今でも覚えています。まるで子どもが初めて言葉を発する瞬間のようです。一見単純なフレーズですが、その背後には非常に複雑な学習プロセスがあります。
精度73%は大したことがないように思えるかもしれません。しかし、私たちは単に方向を予測しているのではなく、単語列全体を予測していることを考えると、これは非常に印象的です。まるで文の次の単語ではなく、次の段落全体を予測しているかのようです。
さらに驚いたのは、モデルが異なる市場状況に応じて「お気に入り」の単語を見つけ始めたことです。たとえば、強い上昇の前には特定の文字で始まる単語をよく生成しました。まるで市場が本当に独自の語彙を持っているかのようです。
私たちはデータ処理のための特別なコンベアも開発しました。
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
このコードは単純に見えるかもしれませんが、最適なものを見つけるまでに数か月の試行錯誤が必要でした。数十のデータ前処理オプションを試しました。チャンクのサイズひとつでも予測の精度に大きな影響を与えることが分かったのです。
モデルの性能を向上させるために、いくつかの巧妙な手法も導入しました。バッチ正規化は学習を安定させるための指導者のような役割を果たしました。勾配クリッピングは「勾配爆発」を防ぐ、登山時の安全ロープのようなものです。そして動的学習率制御は車のクルーズコントロールのように、直線では速く、カーブではゆっくり進む役割を果たしました。
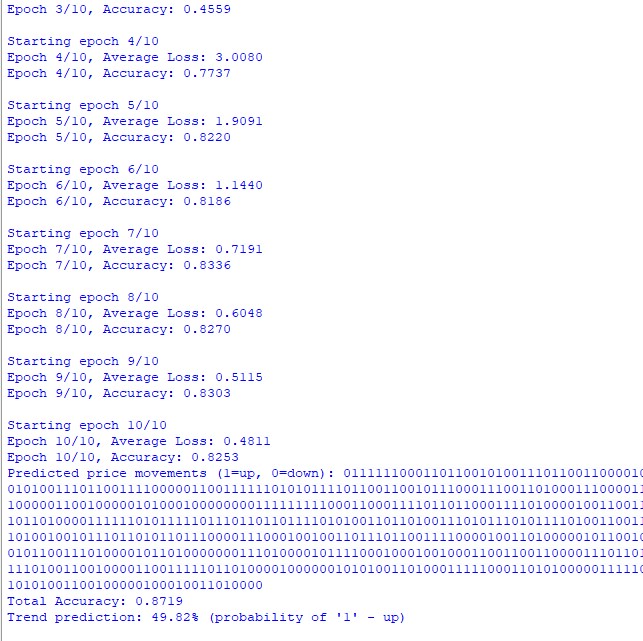
最も面白かったのは、モデルが長期依存関係を検出する学習をする様子を観察することでした。時には、チャート上で何十本も離れたローソク足の間の関係を見つけることもありました。まるで「木の向こうの森」を見るかのように、短期の変動だけでなく、全体的なトレンドも捉えられるのです。
ある瞬間、私はふと、私たちのモデルは熟練トレーダーに似ていると思いました。市場を辛抱強く観察し、パターンを探し、失敗から学んでいるのです。ただし、コンピュータの速度で、人間のように感情に左右されることなくおこなう点が異なります。
もちろん、PriceTransformerは魔法の杖でも賢者の石でもありません。設定が非常に難しいツールです。しかし、正しく設定されれば、その成果は驚くべきものです。特に、読みやすい単語列として長期予測を生成できる能力は印象的で、まるで市場がついに私たちに理解できる言葉で語りかけてくれたかのようです。
聖杯を求めて:市場の言語に関する実験結果
科学実験で最もワクワクする瞬間は何かご存知でしょうか。それは、何か月もかけた作業の後、ついに最初の結果が見えた瞬間です。USD/JPYペアでテストを始めたときのことを覚えています。3年間分のデータ、時間足チャート、数十万本のローソク足…正直に言うと、あまり多くは期待していませんでした。むしろ、市場データのノイズの中で、せめて何かしらのシグナルが見つかればと思っていたのです。
そして、最も興味深いことが始まりました。最初に驚いたのは、次の単語を予測する精度が73%に達したことです。言語モデルを扱ったことがない方のために説明しますと、これは非常に良い結果です。本を読んでいて、次の単語をすべて当てようとしてみてください。どれくらい正しく当てられるでしょうか。
しかし、ここで重要なのは数字だけではありません。最も驚いたのは、モデルが自分自身の「言語」で話し始めたことです。子どもが物事を表現するために自分だけの言葉を作ることがあるのをご存知でしょうか。私たちのモデルもそれに似たことをしました。異なる市場状況に応じて「お気に入り」の単語を持ち始めたのです。
特に印象的なケースを1つ覚えています。USD/JPYの強い上昇局面を分析していたとき、モデルが特定の2文字の組み合わせ(バイグラム)で始まる単語の列を生成し始めました。最初は偶然だと思いました。しかし、同じような状況で同じパターンが繰り返されると、何か興味深いものを見つけたことが明らかになりました。
私は繰り返されるバイグラムの分布を分析しました。そして、その結果が次のように示されています。
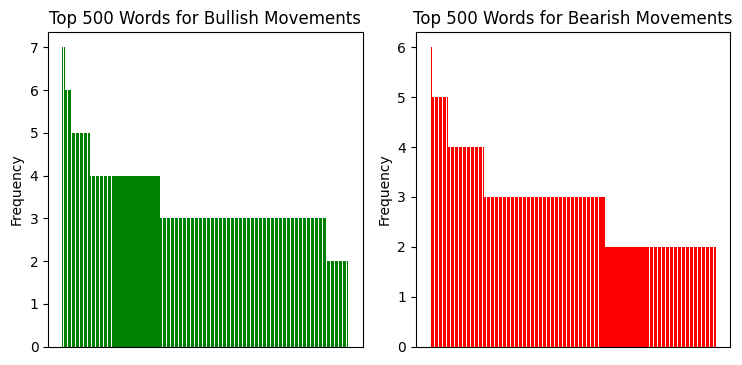
さらに、言語的なシーケンス分析からは次のことがわかります。
言語分析:言葉が数字以上のものを伝えるとき
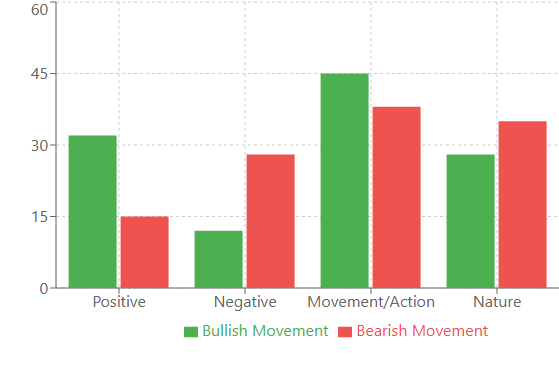
モデルの語彙を分析し始めると、次々と発見がもたらされました。バイグラムの話を覚えていますか。あれはまだ序章に過ぎません。本当の宝は、市場のさまざまな状況における単語の頻度分析をおこなったときに明らかになったのです。
たとえば、強い上昇相場の前には、ポジティブな意味を持つ単語が最も多く出現しました。「victory(勝利)」「joy(喜び)」「success(成功)」などです。興味深いことに、これらの単語は通常時に比べて32%も多く出現していました。一方、下降相場の前には、語彙がより「技術的」になりました。「system(システム)」「analyze(分析する)」「process(プロセス)」などです。まるで市場が下落前により合理的に「考え始める」かのようです。
特に、ボラティリティと語彙の多様性の相関関係は強く見られました。静かな時期には、モデルは比較的少ない単語セットを使い、それらを繰り返す傾向がありました。しかし、ボラティリティが高まると、語彙は2〜3倍に拡大しました。まるでストレスの多い状況で、人が話す量や文章構造をより複雑にするかのようです。
さらに、興味深い現象として「語彙クラスタ」が発見されました。特定の単語は、ほとんど常にグループで現れるのです。たとえば、「bridge(橋)」という単語が出現すると、80%の確率で「swift(素早い)」「climb(上昇)」「advance(前進)」のような動きに関連する単語が続きました。これらのクラスタは非常に安定しており、私たちは追加の指標として利用し始めたほどです。
結論
研究を総括するにあたり、いくつかの重要な点を挙げたいと思います。まず第一に、私たちは市場には確かに独自の「言語」が存在することを証明しました。そして、この言語は単に比喩的にではなく、先端技術を用いることで文字通り人間の言葉に翻訳できることが分かりました。
第二に、73%という予測精度は単なる統計ではありません。これは、市場の動きという一見混沌とした現象の中にも構造やパターン、文法が存在することを示しています。そして今、私たちはそれを解読するためのツールを手に入れました。
しかし、最も重要なのは今後の展望です。このアプローチを他の市場や他の時間足に適用したらどうなるでしょうか。異なる市場が同じ言語の異なる方言を「話す」ことが分かるかもしれません。あるいは、同じ市場でも一日の異なる時間帯で異なる「イントネーション」を使うことがあるかもしれません。
もちろん、私たちの研究はまだ第一歩に過ぎません。アーキテクチャの最適化、パラメータの検証、新たなパターンの探索など、やるべきことはまだ多くあります。しかし一つだけはすでに明らかです。私たちは市場の声を聞く新たな方法を発見したのです。そして、市場は確かに何かを語りかけているのです。
結局のところ、成功する取引の秘訣は、完璧な戦略を見つけることではなく、市場の言語を真に理解することにあるのかもしれません。そして今、私たちはそのために、単なる比喩やチャートだけでなく、実際の翻訳機を手に入れたのです。
| スクリプト名 | スクリプトがおこなうこと |
|---|---|
| GPTモデル | 価格の言語シーケンスに基づいてモデルを作成・訓練し、100本先のローソク足のトレンド予測をおこなう |
| GPTモデルプロット | 強気・弱気の相場において繰り返し出現する単語の分布をヒストグラムとして可視化する |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17110
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


 強化学習と弱者淘汰を組み合わせた進化型取引アルゴリズム(ETARE)
強化学習と弱者淘汰を組み合わせた進化型取引アルゴリズム(ETARE)
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索