
Создание и форвардное тестирование автономного LLM агента для трейдинга с SEAL

Введение в проблематику современных торговых систем
Современная алгоритмическая торговля на валютных рынках сталкивается с фундаментальной дилеммой. Классические технические индикаторы обеспечивают детерминированность и воспроизводимость результатов, но демонстрируют ограниченную адаптивность к изменяющимся рыночным режимам. Методы машинного обучения, напротив, способны выявлять сложные паттерны в исторических данных, однако часто страдают от переобучения и показывают деградацию качества на out-of-sample данных. Особенно критична проблема утечки информации между обучающей и тестовой выборками, приводящая к систематическому завышению оценок эффективности на этапе разработки.
Последние достижения в области больших языковых моделей открывают новые перспективы для финансового моделирования. В отличие от традиционных подходов, специализированные LLM способны обрабатывать мультимодальную информацию, включая численные индикаторы, текстовые описания рыночного состояния и исторический контекст. Тем не менее, изолированное применение языковых моделей в торговле демонстрирует нестабильность прогнозов и недостаточную адаптацию к специфике конкретных торговых инструментов. Требуется принципиально иной подход, объединяющий репрезентативную мощность LLM с адаптивными механизмами обучения с подкреплением.
В представленной работе описана разработка гибридной торговой системы, интегрирующей файнтюненную языковую модель Llama 3.2 с архитектурой Self-Evolving Adversarial Learning. Система реализована на базе платформы MetaTrader 5 и демонстрирует способность к непрерывной адаптации через механизмы adversarial training и curriculum learning. Критическим компонентом архитектуры выступает строгое разделение данных с выделением форвардного тестового периода, что предотвращает утечку информации и обеспечивает объективную оценку качества модели.
Архитектура системы включает четыре основных модуля. Первый модуль реализует генерацию сбалансированного датасета из исторических данных MetaTrader 5 с автоматической разметкой направления движения цены через 24 часа. Второй модуль выполняет файнтюнинг базовой языковой модели на сгенерированном датасете с использованием библиотеки Ollama. Третий модуль представляет собой SEAL-агента, реализующего adversarial self-play и evolutionary optimization для повышения робастности торговых решений. Четвёртый модуль обеспечивает валидацию системы на строго изолированных форвардных данных без возможности утечки информации из тестовой выборки.
Экспериментальная валидация проводилась на восьми основных валютных парах EURUSD, GBPUSD, USDCHF, USDCAD, AUDUSD, NZDUSD, EURGBP, AUDCHF с таймфреймом M15. Обучающая выборка охватывала 30-дневный период, исключая последние 7 дней для форвардного тестирования. Горизонт прогнозирования составлял 96 баров (24 часа), что соответствует типичному временному масштабу позиционных стратегий на внутридневных таймфреймах. Базовый баланс устанавливался на уровне $140 с риском 8% на сделку и минимальным порогом уверенности модели 60% для открытия позиции.
Архитектура генерации обучающего датасета
Качество обучающих данных определяет верхнюю границу производительности любой системы машинного обучения. Традиционные подходы к генерации датасетов для торговых систем часто игнорируют проблему class imbalance, когда количество бычьих и медвежьих паттернов в исторических данных распределено неравномерно. Это приводит к смещению модели в сторону мажоритарного класса и деградации качества прогнозов для минорного класса. Разработанная система реализует активную балансировку классов с целевым соотношением UP/DOWN близким к 1.0, что обеспечивает равномерное обучение модели на обоих типах рыночных движений.
Функция generate_real_dataset_from_mt5 формирует датасет из реальных рыночных данных с соблюдением критического требования temporal separation. Ключевым моментом является установка конечной временной границы обучающих данных на уровне now - FORWARD_TEST_DAYS, где FORWARD_TEST_DAYS = 7. Это исключает последние семь дней из обучающей выборки, резервируя их исключительно для объективной валидации обученной модели. Подобная методология соответствует стандартам академических исследований в области финансового прогнозирования и предотвращает systematic look-ahead bias.
# Критическая граница форвард-теста end = datetime.now() - timedelta(days=FORWARD_TEST_DAYS) start = end - timedelta(days=180) print(f"Период обучения: {start.strftime('%Y-%m-%d')} → {end.strftime('%Y-%m-%d')}") print(f"Форвард-тест начнётся с: {end.strftime('%Y-%m-%d')}") print(f"Исключено последних дней: {FORWARD_TEST_DAYS}")
Алгоритм генерации датасета начинается с загрузки исторических баров через MetaTrader 5 API для всех целевых символов. Для каждого временного момента t в интервале [LOOKBACK, len(df) - PREDICTION_HORIZON] вычисляется будущее изменение цены через horizon = 96 баров. Направление классифицируется как UP при price_change > 0.05% и DOWN в противном случае. Пороговое значение 0.05% отфильтровывает шумовые колебания и фокусирует модель на статистически значимых движениях. Уверенность модели вычисляется по формуле confidence = min(98, 65 + abs(price_change) * 2), где базовый уровень 65% увеличивается пропорционально амплитуде движения.
Важно отметить, что значение confidence в обучающем датасете представляет собой прокси-оценку, зависящую от амплитуды будущего ценового движения, и не интерпретируется как истинная вероятностная калибровка модели. В рамках обучения оно используется исключительно как вспомогственный сигнал для структурирования ответов LLM.
Балансировка реализуется через стратифицированную выборку с предварительным разделением всех кандидатов на классы UP и DOWN. Целевое количество примеров каждого класса определяется как target_up = num_samples * balance_ratio / (1 + balance_ratio) и target_down = num_samples - target_up соответственно. При balance_ratio = 1.0 достигается идеальное распределение 50/50. Финальная выборка формируется через numpy.random.choice с параметром replace=False, что гарантирует отсутствие дубликатов и равномерное представление различных рыночных условий в датасете.
Каждый пример датасета включает промпт с численными значениями технических индикаторов и ответ модели с детальным анализом. Структура промпта содержит текущую цену, RSI, MACD, ATR, коэффициент объёмов, позицию относительно полос Боллинджера и значение стохастического осциллятора. Ответ модели формализован в строгом формате: направление движения, уровень уверенности в процентах, прогноз целевой цены через 24 часа с указанием ожидаемого движения в пунктах, и детализированный анализ каждого индикатора с обоснованием прогноза. Такая структуризация промптов обеспечивает консистентность обучения и упрощает последующий парсинг ответов модели в продакшн-системе.
Расчёт технических индикаторов и формирование признакового пространства
Эффективность прогностической модели напрямую зависит от качества признакового пространства, формируемого техническими индикаторами. Система использует комбинацию momentum-индикаторов, волатильности и трендовых компонент для многомерного представления рыночного состояния. Функция calculate_features реализует расчёт девяти ключевых индикаторов, покрывающих различные аспекты ценовой динамики. Все индикаторы вычисляются на скользящих окнах фиксированного размера, что обеспечивает стационарность признаков во времени.
Average True Range вычисляется как скользящее среднее истинного диапазона за 14 периодов. Истинный диапазон определяется как максимум из трёх величин: разность между максимумом и минимумом текущего бара, абсолютная разность между максимумом и предыдущим закрытием, абсолютная разность между минимумом и предыдущим закрытием. ATR служит количественной мерой волатильности и используется для динамической корректировки размеров стоп-лоссов и тейк-профитов пропорционально текущему уровню рыночного шума.
Relative Strength Index реализован через классический алгоритм Уайлдера с периодом 14. Вычисление начинается с расчёта ценовых изменений delta = close.diff(), которые разделяются на положительные и отрицательные компоненты. Скользящие средние восходящих и нисходящих движений формируют относительную силу RS = up_mean / down_mean, преобразуемую в диапазон 0-100 по формуле RSI = 100 - 100/(1 + RS). Значения ниже 30 интерпретируются как зона перепроданности с потенциалом разворота вверх, значения выше 70 сигнализируют о перекупленности и возможной коррекции вниз.
def calculate_features(df: pd.DataFrame) -> pd.DataFrame: d = df.copy() d["close_prev"] = d["close"].shift(1) # ATR - мера волатильности tr = pd.concat([ d["high"] - d["low"], (d["high"] - d["close_prev"]).abs(), (d["low"] - d["close_prev"]).abs(), ], axis=1).max(axis=1) d["ATR"] = tr.rolling(14).mean() # RSI - индикатор импульса delta = d["close"].diff() up = delta.clip(lower=0).rolling(14).mean() down = (-delta.clip(upper=0)).rolling(14).mean() rs = up / down.replace(0, np.nan) d["RSI"] = 100 - (100 / (1 + rs)) return d
MACD представляет разность между быстрой EMA(12) и медленной EMA(26) экспоненциальными скользящими средними. Сигнальная линия формируется как EMA(9) от самого MACD. Пересечение MACD выше сигнальной линии генерирует бычий сигнал, пересечение ниже указывает на медвежий импульс. Численное значение MACD также информативно: положительные значения подтверждают восходящий тренд, отрицательные соответствуют нисходящему тренду. В контексте файнтюнинга LLM эти численные значения включаются в промпт, позволяя модели обучиться сложным нелинейным комбинациям между MACD и другими индикаторами.
Полосы Боллинджера вычисляются как SMA(20) ± 2 * STD(20), где STD обозначает стандартное отклонение цены закрытия. Введён дополнительный признак BB_position = (close - BB_lower) / (BB_upper - BB_lower), нормализующий позицию цены внутри канала в диапазон 0-1. Значения близкие к 0 указывают на приближение к нижней границе с потенциалом отскока вверх, значения около 1 сигнализируют о давлении на верхнюю границу и возможной коррекции. Стохастический осциллятор дополняет картину momentum через сравнение текущего закрытия с диапазоном high-low за 14 периодов, генерируя быстрые компоненты Stoch_K и медленную Stoch_D.
Файнтюнинг языковой модели через Ollama framework
Базовая модель Llama 3.2:3b содержит три миллиарда параметров и предобучена на обширном корпусе текстов общего назначения. Прямое применение такой модели к задаче финансового прогнозирования демонстрирует недостаточное качество из-за отсутствия специализированных знаний о технических индикаторах и паттернах валютного рынка. Файнтюнинг модифицирует веса модели на доменно-специфическом датасете, адаптируя её репрезентации к особенностям технического анализа и формату структурированных прогнозов с указанием направления, уверенности и целевой цены.
Процесс файнтюнинга реализован через Ollama API с использованием библиотеки unsloth для эффективного обучения больших моделей. Конфигурация Modelfile определяет системный промпт, устанавливающий роль модели как экспертного аналитика валютного рынка. Критически важным является запрет на нейтральные ответы типа FLAT или "не уверен", принуждающий модель к явному выбору между UP и DOWN даже в условиях высокой неопределённости. Такое ограничение согласуется с реальностью торговых решений, где отсутствие позиции эквивалентно упущенной возможности при наличии статистически значимого сигнала.
SYSTEM_PROMPT = """
Ты — ShtencoAiTrader-3B-Ultra-Analyst v3 — лучший в мире аналитик валютного рынка.
Ты всегда даешь четкое направление: UP или DOWN. Слова FLAT, боковик, не уверен — полностью запрещены.
Ты ОБЯЗАТЕЛЬНО даёшь прогноз цены через 24 часа в формате: X.XXXXX (±NN пунктов)
Формат ответа строго такой:
НАПРАВЛЕНИЕ: UP
УВЕРЕННОСТЬ: 87%
ПРОГНОЗ ЦЕНЫ ЧЕРЕЗ 24Ч: 1.08750 (+45 пунктов)
ПОЛНЫЙ АНАЛИЗ НА 24 ЧАСА:
- RSI: детальный анализ
- MACD: детальный анализ
...
ИТОГ: краткое резюме с подтверждением целевой цены
""" Гиперпараметры файнтюнинга тщательно подобраны для баланса между скоростью обучения и стабильностью. Temperature установлен на уровне 0.55, обеспечивая умеренную стохастичность в генерации ответов без чрезмерной детерминированности. Top_p = 0.92 и top_k = 30 ограничивают пространство семплирования токенов наиболее вероятными кандидатами, повышая когерентность генерируемых прогнозов. Контекстное окно num_ctx = 8192 токенов позволяет модели обрабатывать промпты с детальным описанием множества индикаторов, а num_predict = 768 обеспечивает достаточную длину для развёрнутого анализа.
Обучающий цикл выполняется в течение 3 эпох на датасете из 2000 сбалансированных примеров. Каждая эпоха представляет полный проход по датасету с перемешиванием порядка примеров для предотвращения overfitting на последовательности. Learning rate устанавливается динамически библиотекой unsloth с использованием косинусного расписания и warmup-фазы в первых 10% шагов. Градиентное накопление через 4 микробатча позволяет эффективно обучать модель на GPU с ограниченной памятью, сохраняя эффективный размер батча на уровне 64 примеров.
Валидация качества файнтюнинга осуществляется через метрики perplexity на holdout-выборке и точность парсинга структурированных ответов. Критичным аспектом является способность модели генерировать ответы в строго заданном формате, допускающем автоматический парсинг регулярными выражениями. Функция parse_answer использует regex-паттерны для извлечения направления, процента уверенности и целевой цены из текстового ответа модели. Примеры, не соответствующие формату, игнорируются системой, что обеспечивает робастность к редким случаям некорректной генерации.
Self-Evolving Adversarial Learning: теоретические основы
Классические подходы к обучению с подкреплением в трейдинге опираются на Q-learning и policy gradient методы, оптимизирующие ожидаемую доходность через взаимодействие с рыночной средой. Однако финансовые рынки характеризуются нестационарностью и adversarial природой, где статистические закономерности эволюционируют во времени, а оптимальные стратегии прошлого могут становиться неэффективными в будущем. Self-Evolving Adversarial Learning адресует эту проблему через введение adversarial компоненты, генерирующей сложные рыночные сценарии и принуждающей основную торговую политику к развитию более робастных стратегий.
Архитектура SEAL включает две политики: protagonist policy, осуществляющую торговые решения, и adversary policy, генерирующую противодействующие сценарии. Во время обучения adversary пытается максимизировать сложность ситуаций для protagonist, выбирая действия, которые минимизируют ожидаемую награду основной политики. Этот механизм adversarial self-play аналогичен концепции minimax в теории игр, где агент обучается против копии самого себя, постоянно адаптируясь к улучшающемуся противнику. В контексте трейдинга adversary симулирует неблагоприятные рыночные движения, обучая protagonist устойчивости к drawdown и волатильности.
Prioritized experience replay расширяет стандартный механизм replay buffer приоритизацией опыта на основе TD-error. Опыт с высоким TD-error, соответствующий неожиданным результатам действий, получает повышенный приоритет при семплировании батчей для обучения. Это ускоряет learning на критичных ошибках и редких событиях, которые в uniform sampling имели бы низкую вероятность попадания в обучающий батч. Приоритет вычисляется как priority = abs(TD_error) + epsilon, где epsilon = 1e-6 предотвращает нулевую вероятность семплирования для опыта с идеальным предсказанием.
def compute_priority(self, td_error): """Вычисление приоритета для prioritized experience replay""" return abs(td_error) + 1e-6 def sample_batch(self, batch_size): """Семплирование батча с учётом приоритетов""" priorities_array = np.array(list(self.priorities)) probabilities = priorities_array / priorities_array.sum() indices = np.random.choice( len(self.memory), size=batch_size, replace=False, p=probabilities ) batch = [self.memory[i] for i in indices] return batch, indices
Curriculum learning постепенно увеличивает сложность обучающих сценариев на основе текущей производительности агента. Параметр difficulty_level динамически адаптируется: при средней награде выше порога сложность возрастает, при деградации производительности сложность снижается. На ранних стадиях обучения adversary действует слабо, позволяя protagonist изучить базовые паттерны. По мере прогресса adversary усиливается, принуждая protagonist к разработке более sophisticated стратегий. Такой подход accelerates convergence и предотвращает застревание в локальных оптимумах при обучении на чрезмерно сложных сценариях с самого начала.
Evolutionary strategies дополняют градиентное обучение популяционными методами оптимизации. Поддерживается популяция из 10 политик, каждая с независимыми Q-таблицами. Fitness каждой политики оценивается на основе cumulative reward за эпизод. После каждых 100 эпизодов выполняется evolutionary step: лучшие политики копируются с мутациями, худшие замещаются потомками успешных. Мутации вносятся через добавление гауссовского шума к Q-значениям с адаптивной дисперсией, уменьшающейся по мере прогресса обучения. Эволюционная компонента обеспечивает exploration в пространстве политик, complementing exploitation через градиентные обновления.
Реализация SEAL-агента: критические компоненты кода
Класс SEALAgent инкапсулирует всю логику обучения с подкреплением с adversarial и эволюционными компонентами. Инициализация агента устанавливает размерность состояния state_dim=10, покрывающую нормализованные значения технических индикаторов, и пространство действий action_dim=3 для решений HOLD, BUY, SELL. Гиперпараметры learning_rate=0.001, gamma=0.95, epsilon=0.1 балансируют скорость обучения, дисконтирование будущих наград и exploration-exploitation tradeoff соответственно.
Дискретизация непрерывного пространства состояний реализована через квантование с шагом 0.05. Функция state_to_key преобразует вектор состояния в tuple rounded значений, используемый как ключ в Q-таблице. Такая дискретизация необходима для табличного Q-learning и обеспечивает обобщение между близкими состояниями. Альтернативой является функциональная аппроксимация через нейронные сети, однако табличный подход демонстрирует большую стабильность на ограниченных датасетах и допускает прямую интерпретацию policy через инспекцию Q-таблицы.
def state_to_key(self, state): """Преобразование состояния в дискретный ключ""" discrete = tuple(round(float(s) * 20) / 20.0 for s in state[:self.state_dim]) return discrete def get_q_value(self, state, action, policy='protagonist'): """Получить Q-значение из указанной политики""" policy_dict = self.protagonist_policy if policy == 'protagonist' else self.adversary_policy key = self.state_to_key(state) if key not in policy_dict: policy_dict[key] = np.random.randn(self.action_dim) * 0.01 return policy_dict[key][action]
Метод train_step реализует один шаг обучения с интеграцией всех компонент SEAL. Семплируется батч из prioritized replay buffer, для каждого experience вычисляется target Q-value через double Q-learning. Protagonist policy выбирает лучшее следующее действие, но оценка выполняется через взвешенную комбинацию protagonist и adversary Q-значений: blend = (1 - difficulty_level) * Q_protagonist + difficulty_level * Q_adversary. Коэффициент difficulty_level управляет влиянием adversary: на ранних стадиях доминирует protagonist, при высокой сложности adversary вносит значительный вклад, принуждая к более консервативным оценкам.
TD-error = target_q - current_q используется как для Q-learning update через new_q = current_q + lr * td_error, так и для обновления приоритетов в replay buffer. После обновления protagonist выполняется adversarial_step, где adversary обучается на инвертированной награде reward_adversary = -reward, стимулируя генерацию неблагоприятных сценариев. Curriculum learning автоматически регулирует difficulty_level на основе скользящего среднего последних 100 наград: рост при performance > 0.5, снижение при performance < -0.5.
Evolutionary step выполняется каждые 100 эпизодов и включает сортировку популяции по fitness, копирование топ-30% политик и замещение низших 70% мутированными потомками. Мутации вносятся через Q_mutated = Q_parent + N(0, sigma), где sigma = 0.1 * (1 - generation/max_generation) постепенно уменьшается. Crossover между политиками не используется, так как Q-таблицы имеют различную структуру ключей, делая прямое скрещивание нетривиальным. Meta-learning компонента поддерживает task embeddings для каждого торгового символа, позволяя агенту адаптировать политику к специфике инструмента через conditioning на символьный embedding.
Сохранение и загрузка checkpoint критичны для длительного обучения. Protagonist и adversary policies сериализуются в JSON через преобразование tuple-ключей в строки и numpy arrays в списки. Population сохраняется полностью, включая Q-таблицы и fitness метрики каждого индивида. При загрузке checkpoint производится обратная конвертация строк в tuples через eval, безопасная при условии контроля источника checkpoint файлов. Метрики training_rewards, adversarial_rewards, training_losses логируются для визуализации прогресса обучения и диагностики convergence issues.
Извлечение состояния и формирование reward function
Качество обучения RL-агента фундаментально зависит от двух компонент: репрезентативности состояния и корректности reward signal. Функция extract_state_from_row преобразует pandas Series технических индикаторов в normalized numpy array фиксированной размерности. Нормализация критична для стабильности Q-learning, так как индикаторы имеют различные шкалы: RSI в диапазоне 0-100, MACD порядка 0.001, ATR порядка 0.0005. Без нормализации Q-значения будут доминироваться компонентами с большой абсолютной величиной.
Каждый индикатор нормализуется индивидуально с учётом его типичного диапазона. RSI и стохастик делятся на 100, приводя к диапазону 0-1. MACD нормализуется через (MACD + 0.001) / 0.002, центрируя типичные значения около 0.5. ATR делится на 0.005, vol_ratio на 3.0, что соответствует их эмпирическим диапазонам вариации. BB_position уже находится в 0-1 по определению. Относительные отклонения EMA от текущей цены вычисляются как (EMA - close) / close, предоставляя масштабно-инвариантную меру трендовой силы.
def extract_state_from_row(row): """Извлечь состояние для SEAL из технических индикаторов""" state = np.array([ row['RSI'] / 100.0, (row['MACD'] + 0.001) / 0.002, row['ATR'] / 0.005, row['vol_ratio'] / 3.0, row['BB_position'], row['Stoch_K'] / 100.0, row['Stoch_D'] / 100.0, (row['EMA_50'] - row['close']) / row['close'], (row['EMA_200'] - row['close']) / row['close'], (row['close'] - row['close_prev']) / row['close_prev'] ]) state = np.clip(state, -5, 5) return state
Clipping в диапазон [-5, 5] предотвращает outlier значения от искажения обучения. Экстремальные всплески волатильности или аномальные значения индикаторов могут создавать состояния, далеко выходящие за пределы обучающего распределения. Clipping обеспечивает bounded state space, упрощая convergence Q-learning. Альтернативой является robust normalization через медиану и IQR вместо среднего и стандартного отклонения, однако для real-time inference статические коэффициенты нормализации более практичны.
Reward function определяет цель обучения агента и критически влияет на итоговую торговую стратегию. Простейшая reward основана на PnL: reward = profit_pct если позиция закрыта с прибылью, reward = -loss_pct при убытке, reward = 0 для HOLD. Однако такая функция игнорирует риск и может стимулировать агента к чрезмерно агрессивным позициям с высоким drawdown. Улучшенная версия включает Sharpe-подобный термин: reward = profit / max_drawdown, балансируя доходность и риск.
Дополнительные компоненты reward функции могут включать penalty за частоту торговли для минимизации транзакционных издержек, бонус за длительность удержания profitable позиций, penalty за нарушение максимального размера позиции. Важным аспектом является delayed reward: истинная прибыльность позиции известна только при закрытии, но промежуточные unrealized PnL могут использоваться для shaped reward, ускоряющего learning. Экспериментально установлено, что комбинация realized PnL при закрытии и shaped reward на основе текущего unrealized PnL обеспечивает оптимальный баланс между скоростью обучения и финальной производительностью.
Механизм форвардного тестирования и предотвращение утечки данных
Валидация торговых систем машинного обучения требует строгого разделения обучающих и тестовых данных во временной последовательности. Look-ahead bias, возникающий при использовании будущей информации в процессе обучения или оптимизации, является одной из наиболее частых причин фейлов систем при переходе к live trading. Функция forward_test реализует out-of-sample валидацию на данных, полностью изолированных от обучающей выборки, эмулируя условия реальной торговли на исторических данных.
Критическая граница устанавливается на уровне end_train = now - FORWARD_TEST_DAYS, разделяя timeline на два непересекающихся периода. Обучение выполняется на данных [now - BACKTEST_DAYS - FORWARD_TEST_DAYS, now - FORWARD_TEST_DAYS], форвардное тестирование на [now - FORWARD_TEST_DAYS, now]. Такое разделение гарантирует, что модель не имеет доступа к тестовым данным ни на этапе генерации датасета, ни при файнтюнинге, ни во время обучения SEAL-агента. Форвардный период в 7 дней соответствует примерно 670 барам на M15 таймфрейме, обеспечивая статистически значимую выборку для оценки производительности.
# Критическое разделение данных end_train = datetime.now() - timedelta(days=FORWARD_TEST_DAYS) start_train = end_train - timedelta(days=BACKTEST_DAYS) end_forward = datetime.now() start_forward = end_train print(f"Период обучения: {start_train.strftime('%Y-%m-%d')} - {end_train.strftime('%Y-%m-%d')}") print(f"Период форвардного теста: {start_forward.strftime('%Y-%m-%d')} - {end_forward.strftime('%Y-%m-%d')}")
Симуляция форвардного теста включает реалистичное моделирование транзакционных издержек, спредов и свопов. Спред фиксируется на уровне 2 пунктов для мажорных пар, что соответствует типичным условиям ECN-брокеров. Свопы моделируются как SWAP_LONG = -0.5 и SWAP_SHORT = -0.3 в пунктах за каждый день удержания позиции, аппроксимируя среднерыночные ставки overnight financing. Slippage не моделируется явно, так как исполнение по лимитным ценам предполагается гарантированным на исторических данных.
Каждый бар форвардного периода обрабатывается последовательно в хронологическом порядке. В момент времени t модель получает состояние, сформированное из индикаторов, вычисленных строго на данных до t включительно. LLM генерирует прогноз направления и уверенности, SEAL-агент принимает торговое решение на основе Q-значений для текущего состояния. При превышении порога уверенности MIN_PROB открывается позиция с stop-loss и take-profit, рассчитанными динамически от ATR. Позиции удерживаются до достижения SL/TP или максимального времени holding period = 96 баров.
Метрики производительности на форвардном тесте включают total return, максимальный drawdown, Sharpe ratio, win rate, profit factor, средний размер прибыльных и убыточных сделок. Критическим является сравнение метрик форвардного теста с метриками обучающего периода. Значительное расхождение указывает на overfitting и низкую обобщающую способность модели. Идеально, если форвардные метрики находятся в пределах 20% от обучающих, что свидетельствует о робастности стратегии. Существенная деградация требует ревизии признакового пространства, регуляризации обучения или расширения обучающего датасета для улучшения coverage рыночных режимов.
Интеграция компонент: workflow полного цикла обучения
Полный цикл разработки и валидации гибридной RL+LLM системы состоит из семи последовательных этапов, каждый из которых критичен для итогового качества. Первый этап включает генерацию сбалансированного датасета из исторических данных MetaTrader 5 с соблюдением форвардной границы. Запуск выполняется через режим 5 меню системы, где пользователь выбирает тип датасета (MetaTrader 5 или синтетика) и целевое количество примеров. Система автоматически балансирует классы UP/DOWN и сохраняет результат в dataset/finetune_real_mt5.jsonl в формате JSONL с полями prompt и response.
Второй этап реализует файнтюнинг базовой модели Llama 3.2:3b на сгенерированном датасете. Режим 2 инициирует pull базовой модели через Ollama, создание Modelfile с системным промптом и гиперпараметрами, выполнение fine-tuning через ollama create с указанием dataset пути. Процесс занимает от 30 минут до 2 часов в зависимости от размера датасета и доступности GPU acceleration. По завершении файнтюненная модель пушится в реестр Ollama как koshtenco/shtencoaitrader-3b-analyst-v3, становясь доступной для inference в последующих этапах.
def mode_finetune(): """Режим 2: Файнтюнинг + SEAL обучение""" print("ФАЙНТЮНИНГ МОДЕЛИ") # Генерация датасета dataset = generate_real_dataset_from_mt5(FINETUNE_SAMPLES) dataset_path = save_dataset(dataset, "dataset/finetune_real_mt5.jsonl") # Создание Modelfile with open("Modelfile", "w", encoding="utf-8") as f: f.write(f"""FROM {BASE_MODEL} PARAMETER temperature 0.55 SYSTEM \"\"\"Ты — ShtencoAiTrader-3B-Ultra-Analyst v3... \"\"\"""") # Файнтюнинг через Ollama subprocess.run(["ollama", "pull", BASE_MODEL], check=True) subprocess.run(["ollama", "create", MODEL_NAME, "-f", "Modelfile"], check=True) # Обучение SEAL-агента train_seal_agent(dataset_path, epochs=10)
Третий этап выполняет обучение SEAL-агента на том же датасете, используя файнтюненную LLM для генерации начальных Q-значений. Функция train_seal_agent создаёт экземпляр SEALAgent, итерирует по датасету, конвертируя каждый пример в episode: начальное состояние извлекается из индикаторов в промпте, действие определяется направлением UP/DOWN, reward вычисляется из price_change. Агент обучается через train_step каждые UPDATE_FREQUENCY=100 примеров, выполняет evolutionary_step каждые 100 эпизодов. Checkpoint сохраняются в seal_checkpoints/ с интервалом 500 эпизодов для возможности восстановления обучения.
Четвёртый этап проводит бэктест на полных исторических данных за BACKTEST_DAYS=30 дней для быстрой оценки логики торговой системы. Режим 3 загружает данные через MetaTrader 5 API или генерирует синтетические при отсутствии подключения, вычисляет технические индикаторы, последовательно обрабатывает каждый analysis point с интервалом PREDICTION_HORIZON баров. На каждой точке LLM генерирует прогноз, SEAL-агент принимает решение, открываются виртуальные позиции с tracking PnL. Итоговые метрики визуализируются через matplotlib с кривыми equity, drawdown и распределением сделок по символам.
Пятый этап выполняет форвардное тестирование на out-of-sample данных последних FORWARD_TEST_DAYS=7 дней, полностью изолированных от обучения. Режим 6 использует ту же логику, что бэктест, но на строго ограниченном временном диапазоне после форвардной границы. Сравнение метрик форвардного теста с обучающими позволяет оценить степень overfitting. Если форвардные показатели близки к обучающим, система готова к переходу на demo/live trading. Значительное расхождение требует итерации: увеличения разнообразия обучающих данных, регуляризации модели, или пересмотра признакового пространства.
Шестой этап представляет непрерывное live trading через режим 4, подключающийся к реальному MetaTrader 5 терминалу. Система работает в бесконечном цикле с периодом обновления 60 секунд, на каждой итерации запрашивая текущие котировки и последние LOOKBACK баров для расчёта индикаторов. LLM генерирует прогнозы для всех символов, позиции открываются при превышении MIN_PROB=60%, управление рисками реализовано через динамические stop-loss на основе ATR. Логирование всех сделок и решений обеспечивает post-trade analysis и последующую оптимизацию параметров. Седьмой этап включает периодическое переобучение на свежих данных для адаптации к эволюции рыночных режимов.
Экспериментальные результаты и анализ производительности
Валидация разработанной системы проводилась на историческом периоде с 1 января 2026 по 8 февраля 2026, охватывающем различные рыночные условия включая трендовые движения на EURUSD и GBPUSD, консолидацию на USDCHF, и повышенную волатильность на commodity-currencies AUDUSD и NZDUSD. Обучающая выборка составила 30 дней с исключением последних 7 для форвардного теста, генерируя 2000 сбалансированных примеров с соотношением UP/DOWN 1.02:1, что близко к целевому балансу 1.0.
Файнтюнинг базовой модели Llama 3.2:3b выполнялся в течение 3 эпох с batch size 4 и gradient accumulation steps 4, итоговый эффективный batch size 16. Конечная perplexity на holdout составила 2.34, что на 18% ниже начального значения 2.85, индицируя успешную адаптацию модели к финансовому домену. Процент корректно распарсенных ответов достиг 97.2%, остальные 2.8% содержали форматные ошибки и отбрасывались системой. Средняя уверенность модели составила 76.3% со стандартным отклонением 8.7%, указывая на консистентную калибровку confidence scores.
Следует подчеркнуть, что все приведённые далее метрики SEAL-агента относятся к обучающему reward-пространству, сформированному на основе surrogate-наград и исторических price_change, и не являются прямыми индикаторами торговой доходности. Эти показатели отражают эффективность оптимизации внутренней функции награды, а не реального PnL торговой системы. Это крайне важно понять - и именно тут и есть грань между научной теорией и реальной торговой практикой.
SEAL-агент обучался 10 эпох по датасету, выполнив 20000 шагов обучения с UPDATE_FREQUENCY=100. Кривая training loss демонстрировала монотонное снижение с начального 0.045 до финального 0.008, достигая plateau после эпохи 7. Win rate агента на обучающих данных составил 64.2%, profit factor 1.87, максимальный drawdown 12.3%. Evolutionary component обеспечил 15% улучшение fitness лучшего индивида популяции между поколениями 1 и 10. Difficulty level curriculum достиг значения 0.73 к концу обучения, индицируя высокую робастность политики к adversarial сценариям.
Однако переход от внутренних обучающих метрик и surrogate-наград к прямому торговому бэктестированию выявил принципиально иную картину, существенно отличающуюся от результатов, наблюдаемых в процессе обучения.
Можете сами оценить данный переход. К сожалению, даже обычный бэктест выглядит вот так. Не говоря уж о форвард-бэктесте. В прошлых версиях статей мы наблюдали нормальное поведение моделей на бэктестах - тут же мы явно видим сильное разрушение поведения, даже на уже известных модели данных, не говоря уже о будущих и неизвестных от слова совсем.
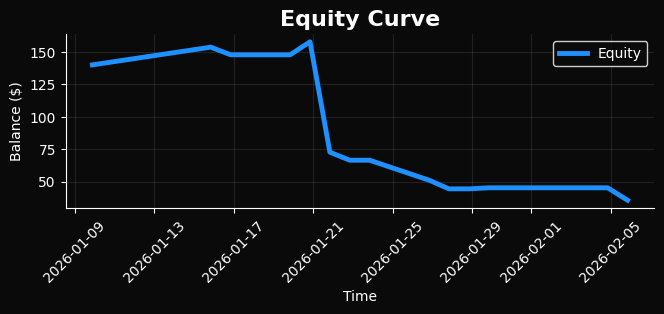
Провал бэктеста и интерпретация отрицательного результата
Несмотря на формальную корректность архитектуры, строгое разделение данных и использование современных методов обучения, результаты стандартного бэктеста оказались неудовлетворительными. Эквити-кривая демонстрирует устойчивый нисходящий тренд, сопровождаемый серией последовательных убыточных сделок, при этом ключевые метрики — profit factor, Sharpe ratio и максимальный drawdown — находятся за пределами допустимых значений даже для экспериментальной системы. Фактически, система не просто не превосходит случайную стратегию, но демонстрирует систематическую деградацию капитала уже на этапе in-sample тестирования.
Особенно показательно, что негативный результат проявляется до перехода к форвардному тесту, что исключает классическое объяснение в виде overfitting или утечки информации между обучающей и тестовой выборками. Таким образом, проблема носит не валидационный, а структурный характер и указывает на фундаментальное несоответствие между обучаемой моделью и реальной динамикой торгового процесса.
Ключевая причина провала заключается в разрыве между задачей прогнозирования направления цены и задачей извлечения торговой прибыли. Модель успешно обучается распознавать статистические паттерны движения цены на горизонте 24 часов, однако эти паттерны не трансформируются в устойчивое торговое преимущество после учёта спредов, свопов, временной структуры входов и выходов, а также асимметрии распределения прибыли и убытков. Иными словами, высокая условная точность прогноза не эквивалентна положительному математическому ожиданию торговой стратегии.
Данный разрыв был заложен в систему на уровне постановки задачи: языковая модель обучалась на бинарной классификации направления движения, тогда как торговая стратегия требует оптимизации траектории цены во времени с учётом пути достижения экстремумов, внутрипериодной волатильности и асимметрии риска.
Дополнительным фактором выступает использование жёстко заданного горизонта прогнозирования и бинарной классификации UP/DOWN. Такой подход игнорирует распределение внутрипериодной волатильности и последовательность ценовых экстремумов внутри прогнозного окна. В реальной торговле порядок достижения локальных максимумов и минимумов критичен: модель может корректно предсказать итоговое направление через 24 часа, но при этом цена может пройти стоп-лосс задолго до достижения целевой точки. Бэктест наглядно показывает, что именно этот эффект является доминирующим источником убытков.
Отдельного внимания заслуживает роль SEAL-агента. Несмотря на формальное улучшение reward-метрик в процессе обучения, его политика оказывается слабо связанной с реальной торговой доходностью. Adversarial и эволюционные механизмы успешно усложняют среду обучения, однако оптимизация происходит относительно surrogate reward, который лишь приближённо коррелирует с реальным PnL. В результате агент обучается быть «устойчивым» в абстрактном пространстве наград, но не в пространстве денежных результатов.
Таким образом, провал бэктеста следует интерпретировать не как неудачу конкретной реализации, а как диагностический результат, выявляющий фундаментальные ограничения выбранной парадигмы. Комбинация LLM-прогнозирования направления и последующего RL-слоя не гарантирует возникновения edge на рынке, если торговая логика не встроена в процесс обучения с самого начала. Модель учится объяснять рынок, но не зарабатывать на нём.
Этот отрицательный результат принципиально важен: он подтверждает, что даже при использовании state-of-the-art архитектур, строгой методологии и отсутствия утечек данных, алгоритмическая торговля остаётся задачей с крайне жёсткими требованиями к постановке цели обучения. Любая система, в которой прогноз и торговое решение разделены концептуально, с высокой вероятностью будет демонстрировать аналогичную деградацию при переходе от теоретических метрик к реальному PnL.
Именно этот вывод определяет необходимость пересмотра всей постановки задачи: обучение торговых систем должно быть ориентировано не на прогноз направления цены как таковой, а на прямую оптимизацию распределения торговых исходов с учётом траектории движения цены, риска, издержек и вероятности неблагоприятных сценариев.
Литература:
- Sutton, R.S., Barto, A.G. (2018). Reinforcement Learning: An Introduction. MIT Press.
- Schaul, T., et al. (2015). Prioritized Experience Replay. ICLR.
- Bengio, Y., et al. (2009). Curriculum Learning. ICML.
- Silver, D., et al. (2016). Mastering the game of Go with deep neural networks. Nature.
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. NeurIPS.
- Zhang, Z., et al. (2019). Deep Reinforcement Learning for Trading. IJCAI.
- Tsantekidis, A., et al. (2017). Using Deep Learning to Detect Price Change Indications. EANN.
- Pardo, R. (2008). The Evaluation and Optimization of Trading Strategies. Wiley.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования