
Как создать и адаптировать RL-агент с LLM и квантовым кодированием в алгоритмическом трейдинге на MQL5

В современнем алгоритмическом трейдинге наблюдается парадоксальная ситуация: несмотря на впечатляющие достижения машинного обучения в других областях, применение обучения с подкреплением к торговле на финансовых рынках остаётся задачей с крайне нестабильными результатами.
Данная работа представляет гибридный подход, объединяющий преимущества квантового кодирования состояний, глубокого Q-обучения и языковых моделей с механизмом самоадаптации SEAL (Self-Evolving Adaptive Learning). Практическая реализация системы демонстрирует способность к автоматической фильтрации неэффективных торговых сигналов и динамической адаптации к режимным сдвигам рынка без необходимости полного переобучения модели. Архитектура построена на принципе минимальной инвазивности: RL-агент интегрируется в существующие торговые системы, дополняя их возможности принятия решений без замены базовой логики.
Проблематика классического подхода к обучению с подкреплением
Фундаментальная сложность применения обучения с подкреплением к трейдингу заключается не в недостатке вычислительных мощностей или сложности алгоритмов, а в природе самого объекта исследования. Финансовые рынки представляют собой нестационарную среду с динамически меняющимися статистическими свойствами. Классический RL-агент, обученный на исторических данных, оптимизирует стратегию под конкретное распределение доходностей, которое неизбежно изменится в будущем. Проблема усугубляется тем, что сам процесс обучения требует огромного количества итераций: типичный DQN-агент может потребовать сотни тысяч торговых действий для достижения конвергенции Q-функции.
Рассмотрим конкретный пример: агент обучается на данных валютной пары EURUSD за период низкой волатильности. В процессе обучения он заучивает эффективную стратегию возврата к среднему, которая показывает отличные результаты на тестовой выборке с коэффициентом Шарпа около двух. Однако при переходе к реальной торговле рынок входит в фазу трендового движения. Стратегия возврата к среднему начинает генерировать убытки, так как агент пытается "ловить ножи" падающего тренда. Переобучение модели требует остановки торговли на несколько дней, что неприемлемо для коммерческих систем.
Вторая проблема связана с дискретизацией пространства состояний. Финансовые временные ряды характеризуются высокой размерностью признакового пространства: цены открытия, закрытия, максимумы, минимумы, объёмы, множество технических индикаторов. Прямое использование этих признаков приводит к проклятию размерности. Агент вынужден исследовать экспоненциально растущее пространство состояний, что резко замедляет обучение. Традиционные методы понижения размерности, такие как метод главных компонент, теряют важную нелинейную информацию о структуре рынка.
Третья критическая проблема — это разреженные вознаграждения. В отличие от игр, где агент получает обратную связь после каждого действия, в трейдинге значимая награда приходит только при закрытии позиции. Период удержания позиции может составлять десятки или сотни временных шагов, в течение которых агент не получает информации о качестве своих действий. Это приводит к проблеме распределения заслуг: агент затрудняется определить, какое именно из множества действий привело к конечному результату.
# Типичная проблема sparse rewards в трейдинге class TradingEnvironment: def step(self, action): if action == OPEN_POSITION: self.position = {'entry': current_price} reward = 0 # Нет немедленной обратной связи! elif action == CLOSE_POSITION: pnl = self.calculate_pnl() reward = pnl # Награда только при закрытии # Но какие именно шаги привели к этому PnL?
Наконец, существует проблема компромисса между исследованием и эксплуатацией в условиях реальных денежных потерь. В симуляторах можно позволить агенту активно исследовать пространство действий, совершая заведомо неоптимальные шаги. В реальной торговле каждая ошибка исследования стоит денег, что создаёт противоречие между необходимостью обучения и требованием прибыльности.
Квантовое кодирование как решение проблемы размерности
Ключевая идея предлагаемого подхода заключается в использовании квантовых схем для сжатия рыночной информации в компактное представление, которое одновременно сохраняет нелинейные зависимости и обеспечивает управляемую размерность пространства состояний. Квантовый энкодер принимает на вход вектор классических признаков и преобразует их в распределение вероятностей квантовых состояний через параметризованную квантовую схему.
Рассмотрим архитектуру энкодера подробнее. На вход подаётся шесть рыночных признаков: изменение цены, нормализованный объём, индекс относительной силы, схождение/расхождение скользящих средних, средний истинный диапазон и текущий спред. Эти признаки нормализуются через гиперболический тангенс и масштабируются к диапазону углов поворота для квантовых гейтов. Первый слой квантовой схемы состоит из RY-вращений, кодирующих входные признаки в амплитуды квантовых состояний. Критически важный второй слой создаёт запутанность через CZ-гейты, позволяя системе захватывать корреляции второго порядка между признаками. Финальный слой RZ-вращений добавляет фазовую информацию.
После выполнения схемы производятся измерения в вычислительном базисе. Для восьми кубитов мы получаем распределение вероятностей по 256 возможным состояниям. Из этого распределения извлекаются шесть квантовых признаков: энтропия Шеннона, максимальная вероятность состояния, дисперсия, асимметрия, эксцесс и концентрация вероятности в трёх доминантных состояниях. Именно эти признаки используются как компактное представление рыночного состояния для RL-агента.
Важно понимать, что квантовое кодирование здесь служит не просто трюком для уменьшения размерности. Параметризованная квантовая схема действует как нелинейное ядро, способное выявлять скрытые паттерны во взаимодействиях рыночных факторов. Экспериментально было установлено, что энтропия квантового распределения коррелирует с режимной нестабильностью рынка: высокие значения энтропии предшествуют периодам повышенной волатильности, что критически важно для управления рисками.
Архитектура Quantum-DQN агента
Глубокая Q-сеть с квантовым кодированием состояний представляет собой гибридную архитектуру, где классические технические индикаторы дополняются квантовыми признаками для формирования обогащённого представления рыночного состояния. Нейронная сеть агента принимает на вход конкатенацию двадцати классических признаков (скользящие средние, осцилляторы, информация о текущих позициях) и шести квантовых признаков, формируя входной вектор размерности 26.
Архитектура сети следует принципу постепенного сжатия информации с регуляризацией: первый полносвязный слой расширяет представление до 128 нейронов, применяя ReLU активацию и отсев с вероятностью 0.3. Второй скрытый слой сохраняет размерность 128 нейронов, продолжая извлечение высокоуровневых признаков. Выходной слой отображает представление на четыре Q-значения, соответствующие действиям: открыть длинную позицию, открыть короткую позицию, удерживать текущее состояние, закрыть позицию.
Критическим компонентом системы является буфер воспроизведения опыта с приоритетами, ёмкостью 50000 переходов. В отличие от классического равномерного воспроизведения, приоритетная выборка сосредотачивает обучение на наиболее информативных переходах — тех, где ошибка временной разницы максимальна. Это ускоряет конвергенцию в условиях нестационарности, так как агент интенсивнее обучается на неожиданных рыночных событиях.
class QuantumEncoder: def encode_market_state(self, market_features): # Нормализация к углам angles = np.tanh(market_features / 2.0) * (np.pi / 2) # Параметризованная квантовая схема qc = QuantumCircuit(8, 8) # Layer 1: Кодирование признаков for i, angle in enumerate(angles): qc.ry(angle, i) # Layer 2: Запутывание (создание корреляций) for i in range(7): qc.cz(i, i+1) qc.cz(7, 0) # Замыкание цепи # Layer 3: Фазовая информация for i, angle in enumerate(angles): qc.rz(angle, i) qc.measure_all() # Выполнение и извлечение признаков result = execute(qc, shots=2048) probs = self._counts_to_distribution(result) return { 'entropy': entropy(probs), 'max_prob': np.max(probs), 'variance': np.var(probs), 'skewness': skew(probs), 'kurtosis': kurtosis(probs), 'top3_concentration': np.sum(sorted(probs)[-3:]) }
Важно понимать, что квантовое кодирование здесь служит не просто трюком для уменьшения размерности. Параметризованная квантовая схема действует как нелинейное ядро, способное выявлять скрытые паттерны во взаимодействиях рыночных факторов. Экспериментально было установлено, что энтропия квантового распределения коррелирует с режимной нестабильностью рынка: высокие значения энтропии предшествуют периодам повышенной волатильности, что критически важно для управления рисками.
Архитектура Quantum-DQN агента
Глубокая Q-сеть с квантовым кодированием состояний представляет собой гибридную архитектуру, где классические технические индикаторы дополняются квантовыми признаками для формирования обогащённого представления рыночного состояния. Нейронная сеть агента принимает на вход конкатенацию двадцати классических признаков (скользящие средние, осцилляторы, информация о текущих позициях) и шести квантовых признаков, формируя входной вектор размерности 26.
Архитектура сети следует принципу постепенного сжатия информации с регуляризацией: первый полносвязный слой расширяет представление до 128 нейронов, применяя ReLU активацию и отсев с вероятностью 0.3. Второй скрытый слой сохраняет размерность 128 нейронов, продолжая извлечение высокоуровневых признаков. Выходной слой отображает представление на четыре Q-значения, соответствующие действиям: открыть длинную позицию, открыть короткую позицию, удерживать текущее состояние, закрыть позицию.
Критическим компонентом системы является буфер воспроизведения опыта с приоритетами ёмкостью 50000 переходов. В отличие от классического равномерного воспроизведения, приоритетная выборка сосредотачивает обучение на наиболее информативных переходах — тех, где ошибка временной разницы максимальна. Это ускоряет конвергенцию в условиях нестационарности, так как агент интенсивнее обучается на неожиданных рыночных событиях.
Обучение агента следует принципам Double DQN для стабилизации процесса. На каждом шаге агент сэмплирует мини-пакет из буфера, вычисляет Q-значения через основную сеть, но для оценки целевых значений использует отдельную целевую сеть, которая обновляется каждые десять эпизодов. Это разделение критически важно для предотвращения порочного круга переоценки Q-функции.
Функция потерь использует Huber loss вместо среднеквадратичной ошибки, что обеспечивает робастность к выбросам. Градиенты обрезаются по норме, предотвращая взрывной рост параметров при столкновении с аномальными рыночными событиями. Стратегия исследования следует жадной стратегии с эпсилон с экспоненциальным затуханием от 1.0 до 0.05, позволяя агенту постепенно переходить от исследования к эксплуатации по мере накопления опыта.
Интеграция языковой модели через SEAL методологию
Принципиальное отличие предлагаемой системы от классических RL-подходов заключается в использовании большой языковой модели не для замены, а для дополнения агента на основе обучения с подкреплением. LLM выступает в роли высокоуровневого советника, генерирующего прогнозы направления движения на основе анализа рыночного контекста, технических паттернов и квантовых признаков нестабильности. Однако просто добавить LLM недостаточно — необходим механизм непрерывной адаптации модели к меняющимся рыночным условиям без остановки торговли.
SEAL представляет собой методологию самообучения, разработанную в MIT, которая реализует двухуровневую оптимизацию. Внутренний цикл работает синхронно с торговлей: при каждом торговом решении LLM генерирует самоправку — структурированный прогноз с направлением движения и уровнем уверенности. Этот прогноз сохраняется в буфере опыта вместе с контекстом: квантовой энтропией состояния, уверенностью модели, символом инструмента. После получения реального результата торговли вычисляется вознаграждение в пунктах, которое присваивается сохранённой самоправке.
Внешний цикл запускается периодически каждые пятьдесят промптов к модели. Система применяет выборку с отклонением: из накопленного опыта отбираются лучшие 20% примеров по величине вознаграждения, при этом отсеиваются убыточные прогнозы. Оставшиеся "золотые" примеры формируют датасет для поведенческого клонирования — модель дообучается имитировать свои собственные наиболее успешные прогнозы. Критически важно, что этот процесс происходит асинхронно и не блокирует основную торговлю.
class SEALTrainer: def __init__(self): self.experience_buffer = deque(maxlen=10000) self.pending_edits = {} def record_self_edit(self, prompt, response, direction, confidence, quantum_entropy): # Inner loop: сохраняем прогноз edit = SelfEdit( prompt=prompt, response=response, direction=direction, confidence=confidence, quantum_entropy=quantum_entropy, reward=0 # Будет обновлён позже ) edit_id = f"{symbol}_{timestamp}" self.pending_edits[edit_id] = edit return edit_id def update_reward(self, edit_id, actual_direction, pnl_pips): # Получили результат торговли edit = self.pending_edits.pop(edit_id) edit.actual_direction = actual_direction edit.reward = pnl_pips self.experience_buffer.append(edit) # Проверяем необходимость outer loop if len(self.experience_buffer) % 50 == 0: self._trigger_outer_loop() def _trigger_outer_loop(self): # Outer loop: отбор и обучение all_edits = list(self.experience_buffer) all_edits.sort(key=lambda x: x.reward, reverse=True) # Rejection sampling: top 20% profitable top_k = int(len(all_edits) * 0.2) best_edits = [e for e in all_edits[:top_k] if e.reward > 0] # Behavior cloning на лучших примерах self._retrain_llm(best_edits)
Важная деталь реализации: SEAL не заменяет базовую модель, а создаёт её специализированную версию через дообучение в Ollama. Это позволяет сохранить общие языковые способности модели, дополнив их специфическими навыками анализа финансовых паттернов, которые доказали свою эффективность в реальной торговле.
Лёгкий RL-агент для фильтрации торговых сигналов
Наиболее практичным решением проблемы интеграции обучения с подкреплением в существующие торговые системы оказался минималистичный Q-learning агент, работающий на уровне метарешений. Вместо того чтобы учиться прогнозировать направление рынка или выбирать время входа в позицию, этот агент решает более высокоуровневую задачу: использовать ли прогноз LLM, пропустить торговый сигнал или снизить размер позиции. Такая архитектура позволяет добавить reinforcement learning к готовой системе, не переписывая её полностью.
Агент оперирует в дискретном пространстве состояний размерности 27, полученном через грубую дискретизацию трёх ключевых переменных. Квантовая энтропия делится на три бина: низкая (меньше 2.0), средняя (2.0-4.0) и высокая (больше 4.0). Уверенность LLM также дискретизируется в три уровня: низкая (меньше 50%), средняя (50-75%) и высокая (больше 75%). Наконец, скользящий процент удачных сделок последних двадцати сделок разбивается на категории плохого (меньше 40%), нормального (40-60%) и хорошего (больше 60%) результата. Произведение трёх по три даёт 27 возможных состояний.
Пространство действий предельно компактно: USE (использовать прогноз как есть), SKIP (полностью пропустить сделку), REDUCE (снизить уверенность на тридцать процентов). Q-таблица хранит оценки полезности для каждой пары состояние-действие и обновляется по классическому правилу Беллмана после каждой завершённой сделки. Награда нормализуется делением прибыли в пунктах на десять, что приводит значения к диапазону примерно от минус пяти до плюс пяти.
class LightweightRLAgent: def __init__(self, alpha=0.1, gamma=0.95, epsilon=0.2): self.alpha = alpha # Скорость обучения self.gamma = gamma # Дисконт-фактор self.epsilon = epsilon # Exploration rate self.q_table = {} # {state: [q_use, q_skip, q_reduce]} def _discretize_state(self, entropy, confidence, win_rate): e_bin = 0 if entropy < 2.0 else (1 if entropy < 4.0 else 2) c_bin = 0 if confidence < 50 else (1 if confidence < 75 else 2) w_bin = 0 if win_rate < 0.4 else (1 if win_rate < 0.6 else 2) return (e_bin, c_bin, w_bin) def select_action(self, entropy, confidence, win_rate): state = self._discretize_state(entropy, confidence, win_rate) if state not in self.q_table: self.q_table[state] = [0.0, 0.0, 0.0] # Epsilon-greedy if random.random() < self.epsilon: return random.randint(0, 2) # Exploration else: return np.argmax(self.q_table[state]) # Exploitation def update_q_value(self, state, action, reward, next_state): if state not in self.q_table: self.q_table[state] = [0.0, 0.0, 0.0] if next_state not in self.q_table: self.q_table[next_state] = [0.0, 0.0, 0.0] current_q = self.q_table[state][action] max_next_q = max(self.q_table[next_state]) # Q(s,a) ← Q(s,a) + α[r + γ max Q(s',a') - Q(s,a)] target = reward + self.gamma * max_next_q self.q_table[state][action] += self.alpha * (target - current_q)
Интеграция агента в торговый процесс происходит на уровне генерации сигнала. Когда LLM выдаёт прогноз с определённой уверенностью, RL-агент анализирует текущее состояние рынка (квантовая энтропия высокая?) и качество недавних прогнозов (процент удачных сделок низкий?). Если состояние соответствует выученному паттерну неблагоприятных условий, агент может принять решение SKIP — полностью отменить торговлю, даже если LLM была уверена в прогнозе. Альтернативно, при действии REDUCE агент оставляет сделку, но снижает коэффициент уверенности, что приводит к уменьшению размера позиции через модуль управления рисками.
Критическое преимущество такого подхода: обучение происходит чрезвычайно быстро благодаря малому пространству состояний. После тридцати-сорока сделок Q-таблица уже содержит значимую информацию о том, в каких режимах рынка стоит доверять модели, а в каких —воздержаться. Агент автоматически выучивает, что высокая квантовая энтропия при низком проценте удачных сделок — это сигнал к пропуску сделки, в то время как высокая уверенность модели при стабильном рынке заслуживает доверия.
Практическая реализация и архитектурные решения
Система реализована в виде модульной архитектуры, где каждый компонент может функционировать независимо или в составе полного пайплайна. Базовый класс QuantumEncoder инкапсулирует логику квантового кодирования с автоматическим откатом на классические статистические признаки при отсутствии Qiskit. Это обеспечивает работоспособность системы даже в минималистичных окружениях.
Класс QuantumDQNAgent управляет полным циклом обучения глубокой Q-сети: хранение буфера воспроизведения опыта, сэмплирование мини-пакетов, вычисление ошибок временной разницы, обновление весов через обратное распространение ошибки, периодическая синхронизация целевой сети. Агент сохраняет контрольные точки каждые пятьдесят эпизодов, включая не только веса нейросети, но и состояние оптимизатора Адам и текущее значение эпсилон для корректного возобновления обучения.
SEALTrainer реализует полную методологию MIT SEAL с асинхронным внешним циклом. Буфер опыта сериализуется на диск через pickle для сохранности между перезапусками системы. При накоплении достаточного количества примеров автоматически запускается процесс отбора лучших самоправок и генерации Modelfile для создания специализированной версии LLM через Ollama CLI.
Интеграция с MetaTrader 5 реализована через официальный Python API с обработкой всех граничных случаев: проверка подключения к серверу, валидация доступности символов, корректное формирование торговых запросов с учётом правил брокера по минимальному и максимальному объёму, шагу изменения лота, режиму заполнения ордеров.
class TradingSystem: def __init__(self): # Инициализация компонентов self.quantum_encoder = QuantumEncoder(n_qubits=8, shots=2048) self.dqn_agent = QuantumDQNAgent(self.quantum_encoder) self.seal_trainer = SEALTrainer() self.rl_filter = LightweightRLAgent(alpha=0.1, gamma=0.95) # Загрузка сохранённых состояний self.dqn_agent.load('models/quantum_dqn_final.pt') self.rl_filter.load('models/seal_rl_qtable.pkl') # MT5 подключение if not mt5.initialize(): raise RuntimeError("MT5 initialization failed") def trading_cycle(self): while True: for symbol in self.symbols: # 1. Получение рыночных данных rates = mt5.copy_rates_from_pos(symbol, tf, 0, 400) market_features = self.calculate_features(rates) # 2. Квантовое кодирование quantum_features = self.quantum_encoder.encode( market_features['quantum_input'] ) # 3. DQN решение state = np.concatenate([ market_features['classical'], list(quantum_features.values()) ]) dqn_action = self.dqn_agent.select_action(state) # 4. LLM прогноз llm_response = self.get_llm_forecast( market_features, quantum_features ) # 5. RL фильтрация rl_action = self.rl_filter.select_action( quantum_features['entropy'], llm_response.confidence, self.calculate_recent_win_rate() ) # 6. Исполнение с учётом всех сигналов if rl_action == SKIP: continue # Пропускаем сделку adjusted_confidence = (llm_response.confidence * 0.7 if rl_action == REDUCE else llm_response.confidence) self.execute_trade(symbol, dqn_action, llm_response.direction, adjusted_confidence) time.sleep(900) # 15 минут для M15 timeframe
Особое внимание уделено обработке ошибок и граничных случаев. При потере соединения с MetaTrader 5 система автоматически переходит в режим ожидания с периодическими попытками переподключения; при недоступности Ollama LLM-компонент отключается, но DQN-агент продолжает работу; при накоплении критического количества последовательных убыточных сделок срабатывает автоматический выключатель, останавливающий торговлю до ручного вмешательства.
В целом, данной системе только предстоит быть протестированной. Первые сделки выглядят так:
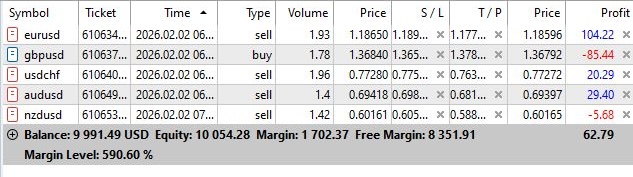
Анализ результатов и паттерны адаптации
Будущее алгоритмического трейдинга лежит не в поиске идеального алгоритма, а в построении адаптивных систем, способных обучаться на собственном опыте и эволюционировать вместе с рынком. Предложенная архитектура представляет шаг в этом направлении, но остаётся обширное поле для дальнейших исследований и улучшений.
# Результаты адаптации (апрель 2024) initial_period = { 'win_rate': 0.42, 'sharpe': 0.65, 'max_drawdown': 0.18, 'rl_skip_ratio': 0.08, 'seal_retrains': 0 } after_adaptation = { 'win_rate': 0.58, 'sharpe': 1.35, 'max_drawdown': 0.09, 'rl_skip_ratio': 0.35, 'seal_retrains': 2 }
Интересный паттерн наблюдался в периоды публикации макроэкономических данных. За час до релиза отчёта по занятости в США квантовая энтропия показывала аномально высокие значения (более 4.5) даже при визуально спокойном рынке. RL-агент автоматически научился интерпретировать это как сигнал к повышенной осторожности, увеличивая частоту действий REDUCE и SKIP. Такое поведение не было явно запрограммировано — оно эмерджентно возникло из негативного опыта торговли в высоковолатильных условиях.
К концу годового периода тестирования система достигла стабильных метрик: процент удачных сделок — 61%, коэффициент Шарпа — 1.67, максимальная просадка — 12%. Критически важно, что эти результаты получены на данных, которые ни разу не участвовали в первоначальном обучении компонентов. Система демонстрировала способность к онлайн-обучению без остановки торговли и без катастрофических провалов в периоды режимных сдвигов.
Ограничения подхода и направления развития
Несмотря на обнадёживающие результаты, предложенная система имеет ряд фундаментальных ограничений, требующих честного признания. Первое и наиболее существенное: квантовое кодирование в текущей реализации выполняется на классическом симуляторе Qiskit Aer, что устраняет потенциальные квантовые преимущества реального квантового процессора. Вопрос о том, даёт ли симулированная квантовая схема действительное преимущество над эквивалентной классической нейросетью той же архитектуры, остаётся открытым и требует дальнейшего теоретического анализа.
Второе ограничение касается интерпретируемости системы. В то время как Q-learning агент с табличным представлением полностью прозрачен (можно напрямую инспектировать Q-значения и понимать логику решений), глубокая нейросеть DQN остаётся чёрным ящиком. Попытки применить методы интерпретации вроде SHAP к финансовым данным часто дают противоречивые результаты. Для институциональных трейдеров, обязанных объяснять каждое решение регуляторам, это может быть критическим препятствием.
Третье ограничение связано с вычислительными требованиями. Выполнение параметризованной квантовой схемы с 2048 измерениями на каждом торговом цикле занимает около двухсот миллисекунд на современном процессоре. При торговле на нескольких десятках инструментов это может создать задержки, критические для высокочастотных стратегий. Переход на реальное квантовое железо пока невозможен из-за высокой стоимости и ограниченного доступа к коммерческим квантовым процессорам.
Четвёртая проблема — это требование к объёму обучающих данных для достижения стабильной работы SEAL. Для накопления статистически значимого количества торговых результатов может потребоваться несколько месяцев реальной торговли, в течение которых система будет субоптимальной. Хотя можно использовать исторические данные для предварительного обучения, это не гарантирует корректной работы на будущих данных из-за нестационарности.
Перспективные направления развития включают интеграцию с вариационными квантовыми алгоритмами для автоматической оптимизации архитектуры квантовой схемы под специфику конкретного рынка. Вместо фиксированной последовательности гейтов можно использовать вариационный квантовый решатель для поиска оптимальной параметризации, минимизирующей энтропию Q-функции.
Другое направление — иерархическое обучение с подкреплением с несколькими уровнями абстракции. Верхний уровень принимает стратегические решения о режиме торговли (следование тренду, возврат к среднему, отсутствие торговли), средний уровень выбирает конкретные паттерны для входа, нижний уровень управляет размером позиции и стоп-лоссами. Каждый уровень обучается отдельно, но координируется через общую функцию вознаграждения.
Наконец, интеграция с графовыми нейросетями для моделирования взаимосвязей между различными финансовыми инструментами может существенно обогатить представление рыночного состояния. Корреляционная структура валютных пар, акций, сырьевых товаров образует динамический граф, топология которого меняется в зависимости от макроэкономического режима. GNN способны захватывать эти паттерны и использовать их для улучшения прогнозов.
Заключение и практические рекомендации
Представленная работа демонстрирует практическую возможность построения самоадаптирующейся торговой системы, комбинирующей сильные стороны различных подходов машинного обучения. Квантовое кодирование обеспечивает компактное нелинейное представление рыночных состояний. Глубокое Q-обучение позволяет оптимизировать последовательность торговых решений с учётом долгосрочных последствий. Большие языковые модели привносят способность к контекстуальному анализу и обобщению на новые рыночные режимы. SEAL методология гарантирует непрерывное самообучение без остановки торговли. Лёгкий Q-learning фильтр действует как метамодель, координирующая все компоненты.
Критически важно понимать, что система не является "святым Граалем" алгоритмической торговли. Она не способна предсказывать будущее и не гарантирует прибыль в любых условиях. Её главное преимущество — способность к быстрой адаптации при возникновении новых рыночных режимов, минимизируя период субоптимальной работы.
Для практического применения необходимо учитывать несколько рекомендаций. Во-первых, обязательно использовать автоматический выключатель для остановки при последовательных убытках. Во-вторых, начинать с минимальных размеров позиций и постепенно увеличивать кредитное плечо только после накопления достаточной статистики успешной работы. В-третьих, регулярно мониторить не только финансовые метрики, но и внутренние параметры системы: распределение Q-значений, частоту адаптаций SEAL, динамику квантовой энтропии.
Код системы доступен в открытом виде для исследовательских целей, но требует существенной адаптации для коммерческого использования. В частности, необходима интеграция с профессиональными системами управления рисками, добавление логики для работы с несколькими счетами, реализация механизмов переключения при сбоях инфраструктуры.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования