
Объединяем LLM, CatBoost и квантовые вычисления в единую торговую систему

Введение
Анализ убыточной ситуации на рынке EURUSD выявил критические недостатки классического технического анализа. RSI показывал 72.3, указывая на перекупленность, MACD демонстрировал медвежью дивергенцию, а стохастик находился в зоне перепроданности. Нейросеть, обученная на базе этих индикаторов, предсказывала движение вниз с уверенностью 67%. Однако открытая короткая позиция принесла убыток $340, что указало на фундаментальную проблему не в конкретных индикаторах или модели, а в самом подходе к анализу рынка.
Ограничения классических индикаторов
Классические технические индикаторы представляют собой линейные или кусочно-линейные функции цены. Каждый из них является проекцией многомерного рыночного процесса на одномерную ось. RSI вычисляется как экспоненциальное сглаживание с нормализацией:
delta = price.diff() up = delta.clip(lower=0).rolling(14).mean() down = (-delta.clip(upper=0)).rolling(14).mean() rsi = 100 - (100 / (1 + up/down))
MACD — разность двух скользящих средних:
ema12 = price.ewm(span=12).mean() ema26 = price.ewm(span=26).mean() macd = ema12 - ema26
Bollinger Bands — среднее плюс-минус стандартное отклонение:
middle = price.rolling(20).mean() std = price.rolling(20).std() upper = middle + 2 * std lower = middle - 2 * std
Все эти индикаторы анализируют рынок через линейные преобразования временного ряда. Рынок не является механической системой с предсказуемым поведением. Это хаотическая динамическая система в математическом смысле, где небольшие изменения начальных условий приводят к драматически разным результатам. Миллионы трейдеров влияют друг на друга через нелинейные петли обратной связи, создавая эмерджентные паттерны. Классические индикаторы видят только одномерные срезы этой многомерной нелинейной системы.
Концептуальная модель: рынок как квантовая суперпозиция
Каждую микросекунду миллионы трейдеров принимают решения о покупке, продаже, закрытии позиций или ожидании. До момента исполнения сделки все эти решения существуют в потенциальности, в состоянии неопределённости. Это концептуально похоже на квантовую суперпозицию: система одновременно находится во всех возможных состояниях до момента измерения. Покупка и продажа, страх и жадность, надежда и паника существуют одновременно, пока не коллапсируют в конкретное движение цены.
Сделка выступает как "измерение", коллапсирующее суперпозицию в наблюдаемый результат. Рынок представляет собой не детерминированный процесс, где можно вычислить следующее положение, а вероятностный коллапс коллективного квантового состояния участников. Требовался способ моделировать эту суперпозицию и видеть нелинейные корреляции, которые классические индикаторы не улавливают.
Первый эксперимент: ограничения языковых моделей
Мной был проведен тест GPT-4 на анализе той же рыночной ситуации. Результат оказался впечатляющим: модель предоставила контекстный анализ, отметив, что перекупленность по RSI поддержана реальным интересом покупателей согласно объёмам, а медвежья дивергенция MACD даёт ранние сигналы, часто ложные в сильных трендах. LLM продемонстрировала способность видеть контекст и интерпретировать индикаторы в связке.
Через неделю после первого теста я попробовал запустить GPT-4 на анализе той же рыночной ситуации. Просто из любопытства — что скажет языковая модель?
Результат меня поразил:
"Обратите внимание на контекст: RSI действительно в зоне перекупленности, но объёмы продолжают расти. Это означает, что перекупленность поддержана реальным интересом покупателей, а не манипуляцией. MACD показывает медвежью дивергенцию, однако гистограмма ещё не развернулась вниз — это ранний сигнал, который часто даёт ложные срабатывания в сильных трендах. Учитывая совокупность факторов, вероятность продолжения восходящего движения выше, чем разворота."
Я перечитал этот анализ три раза. Это было лучше, чем мои собственные рассуждения. LLM видела контекст, который я пропустил. Она понимала, что индикаторы нужно интерпретировать в связке, а не по отдельности.
При повторном запуске модели на полностью идентичных данных я получил противоположный результат. Небольшие изменения формулировки запроса — например, добавление слова «однако» — снова меняли вывод. Повышение температуры генерации приводило к скачкам прогноза от "вероятен рост" к "скорее всего, падение". Так проявилась фундаментальная проблема: языковые модели не вычисляют в строгом смысле, а вероятностно имитируют рассуждения. Их ответы недетерминированы и зависят от нюансов запроса.
В творческих задачах это допустимо, но в трейдинге нет. Мне требовалась детерминированность: если модель указывает «87% вероятности», эта оценка должна быть воспроизводимой, а не изменяться при каждом новом запуске.
Второй эксперимент: когда градиентный бустинг застрял на 59%
CatBoost — это чистая математика без эмоций. Даёшь ей примеры, она строит деревья решений. Никакого креатива, только паттерны в данных.
Первая модель была обучена на стандартных индикаторах — RSI, MACD, стохастике, Bollinger Bands, ATR и объёмах. Её точность составила 56.2%, что лишь на 6.2 п.п. выше случайного выбора и недостаточно для устойчивой прибыльности с учётом издержек. Добавление производных признаков — процентных изменений, волатильностей и межрыночных корреляций — повысило точность до 58.7%. Увеличение числа признаков до 200 привело лишь к стагнации на уровне 59.3%.
После анализа важности признаков стало ясно: практически все они представляют собой линейные или близкие к линейным преобразования цены, что ограничивает их способность описывать реальную рыночную динамику. RSI — это экспоненциальное сглаживание с нормализацией в диапазон 0-100. Математически:
Мне нужен был способ увидеть нелинейную структуру рынка. Но как?
Третий эксперимент: открытие квантового кодирования
Изучение статьи на arxiv.org о квантовых алгоритмах для финансового анализа привело к ключевому инсайту. Квантовый компьютер не вычисляет решения последовательно, как классический. Он исследует все возможные варианты одновременно, используя суперпозицию квантовых состояний, а измерение коллапсирует эту суперпозицию в наиболее вероятный результат.
Параллель с рынком оказалась очевидной. Каждую секунду миллионы трейдеров принимают решения, существующие в потенциальности до момента исполнения сделки. Коллективная суперпозиция миллионов решений создаёт движение цены как вероятностный коллапс квантового состояния рынка. Исследование работ по квантовому кодированию временных рядов и документации Qiskit привело к идее использовать квантовые схемы не для предсказания цены напрямую, а для извлечения скрытых признаков из рыночных данных — признаков, которые классические методы не могут увидеть.
Три технологии начали складываться в единую систему: LLM для контекстуальных рассуждений, CatBoost для калиброванных прогнозов, квантовое кодирование для извлечения нелинейных паттернов.
Построение моста между рынком и квантовым компьютером
Базовая проблема заключалась в преобразовании классической информации (цены как числа с плавающей точкой) в квантовую схему, работающую с амплитудами вероятности, фазами волновых функций и запутанными состояниями. Выбор 8 кубитов обусловлен математикой: 2^8 = 256 возможных базисных состояний. Меньшее количество не обеспечивает достаточную выразительность для сложных паттернов, большее приводит к экспоненциальному росту вычислений и замедлению симулятора IBM.
Первая реализация использовала прямое кодирование 8 технических индикаторов через нормализацию в диапазон [0, π] и RY-вращения:
class QuantumEncoder: def __init__(self): self.n_qubits = 8 self.simulator = AerSimulator() def encode_and_measure(self, features): # Нормализация в [0, π] normalized = (features - features.min()) / (features.max() - features.min() + 1e-8) angles = normalized * np.pi # Создание квантовой схемы qc = QuantumCircuit(self.n_qubits, self.n_qubits) # RY-вращения for i in range(self.n_qubits): qc.ry(angles[i], i) # Измерение qc.measure(range(self.n_qubits), range(self.n_qubits)) # Запуск job = self.simulator.run(qc, shots=2048) result = job.result() counts = result.get_counts() return counts
Я запустил это на исторических данных EURUSD. Результат был... разочаровывающим. Квантовая схема выдавала распределение вероятностей, но оно было почти случайным. Все 256 состояний имели примерно равную вероятность 1/256 ≈ 0.39%.
Проблема была в том, что 8 кубитов оставались независимыми. Каждый кубит знал только о своём индикаторе — RSI видел только RSI, MACD только MACD. Между ними не было связи.
Но рынок — это не набор независимых переменных. Когда RSI падает, а объём растёт — это один контекст. Когда RSI падает, объём падает, а MACD разворачивается — это совершенно другой контекст.
Мне нужно было создать связь между кубитами. Запутывание.
Результаты на исторических данных EURUSD оказались неудовлетворительными. Квантовая схема выдавала почти случайное распределение вероятностей, где все 256 состояний имели примерно равную вероятность 1/256 ≈ 0.39%. Проблема заключалась в независимости 8 кубитов: каждый знал только о своём индикаторе без связи между ними. Рынок же представляет собой не набор независимых переменных, а систему с контекстуальными взаимосвязями.
Прорыв: создание квантовой сети через CZ-гейты
Controlled-Z (CZ) гейты обеспечивают запутывание: если кубит-контроллер находится в состоянии |1⟩, он инвертирует фазу кубита-цели. Два кубита перестают быть независимыми, их состояния коррелируют. Модифицированная версия энкодера включала запутывание:
def encode_and_measure(self, features): normalized = (features - features.min()) / (features.max() - features.min() + 1e-8) angles = normalized * np.pi qc = QuantumCircuit(self.n_qubits, self.n_qubits) # RY-вращения для кодирования for i in range(len(angles)): qc.ry(angles[i], i) # Запутывание через CZ-гейты for i in range(self.n_qubits - 1): qc.cz(i, i + 1) # Связываем соседние кубиты # Замыкаем цепь qc.cz(self.n_qubits - 1, 0) # Последний с первым # Измерение qc.measure(range(self.n_qubits), range(self.n_qubits)) job = self.simulator.run(qc, shots=2048) result = job.result() counts = result.get_counts() return counts
Запустил снова. И всё изменилось.
Результаты радикально изменились. Распределение вероятностей стало неравномерным: некоторые состояния появлялись в 15-20% измерений, другие в 0.1%. Схема обнаруживала паттерны благодаря квантовой когерентности. Применение CZ-гейтов между последовательными кубитами создавало цепочку корреляций, а замыкание цепи соединением последнего кубита с первым обеспечивало квантовую когерентность — схема анализировала рынок как единую систему.
Это обеспечивало не просто корреляцию первого порядка "RSI коррелирует с ценой", а корреляции высших порядков: "RSI коррелирует с MACD при условии, что объём выше среднего И стохастик в зоне перекупленности И волатильность растёт". Классическая модель увидела бы такую корреляцию только при ручном создании комбинированного признака, что для 8 признаков даёт 2^8 = 256 возможных комбинаций. Квантовая схема с запутыванием исследует все комбинации одновременно в суперпозиции, а измерение коллапсирует их в гистограмму вероятностей.
Четыре числа, которые изменили всё
Теперь у меня была гистограмма из 256 состояний с их вероятностями. Но CatBoost не может работать с гистограммой — ему нужны признаки. Числа.
Я извлёк четыре квантовых признака из этого распределения:
probabilities = np.array([counts.get(format(i, f'0{n_qubits}b'), 0) / total_shots for i in range(2**n_qubits)]) quantum_entropy = entropy(probabilities + 1e-10, base=2)Энтропия измеряет неопределённость. При равновероятности всех 256 состояний энтропия максимальна: 8 бит (log2(256) = 8). При доминировании одного состояния энтропия близка к нулю. График квантовой энтропии поверх графика цены EURUSD показал, что энтропия начинала расти за 2-3 часа до крупных движений. 3 ноября 2025 в 14:00 энтропия составляла 2.1 (низкая), к 17:00 выросла до 4.8 (высокая неопределённость), в 18:30 после публикации данных NFP EURUSD прошёл 120 пунктов за 15 минут. Квантовая схема улавливала нарастающую неопределённость раньше классических индикаторов.
dominant_state_prob = np.max(probabilities)
Если одна конфигурация кубитов появляется в 18% измерений при ожидаемых 0.39%, это указывает на коллапс рынка в определённое состояние.
significant_states = np.sum(probabilities > 0.03)Мера сложности рынка. В простом тренде: 3-5 состояний (чистое движение). В сложной консолидации перед новостями: 15-20 состояний (множественные сценарии).
quantum_variance = np.var(probabilities)
Не путать с классической волатильностью! Квантовая дисперсия показывает не размах колебаний цены, а меру хаотичности распределения вероятностей в квантовом пространстве состояний.
Эти четыре числа стали мостом между квантовым и классическим мирами.
Когда CatBoost научился понимать язык квантов
Стандартный подход предполагает обучение отдельной модели для каждой валютной пары. Однако валюты не существуют в изоляции. Рост EURUSD (укрепление евро относительно доллара) коррелирует с падением USDCHF (ослабление доллара относительно франка). Синхронное движение GBPUSD и EURGBP указывает на силу или слабость фунта, а не доллара или евро. Отдельные модели не видят эти взаимосвязи.
Единая модель для всех восьми пар требовала механизма идентификации анализируемой пары через one-hot encoding:
X_features = {
'RSI': row['RSI'],
'MACD': row['MACD'],
'ATR': row['ATR'],
# ... остальные 30 технических признаков
'quantum_entropy': quantum_feats['quantum_entropy'],
'dominant_state_prob': quantum_feats['dominant_state_prob'],
'significant_states': quantum_feats['significant_states'],
'quantum_variance': quantum_feats['quantum_variance'],
'symbol': symbol # "EURUSD", "GBPUSD", и т.д.
}
X_df = pd.DataFrame([X_features])
X_df = pd.get_dummies(X_df, columns=['symbol'], prefix='sym') Итоговый набор признаков: 33 технических + 4 квантовых + 8 символьных = 45 признаков.
Честная валидация временных рядов
Критическая ошибка при работе с временными рядами — использование обычной кросс-валидации, вызывающей утечку данных из будущего. Обычный KFold случайно перемешивает данные, что позволяет модели видеть будущее. Правильный подход — TimeSeriesSplit:
from sklearn.model_selection import TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=3) for fold_idx, (train_idx, val_idx) in enumerate(tscv.split(X)): X_train, X_val = X.iloc[train_idx], X.iloc[val_idx] y_train, y_val = y[train_idx], y[val_idx] model.fit(X_train, y_train, eval_set=(X_val, y_val)) accuracy = model.score(X_val, y_val) print(f"Фолд {fold_idx + 1} Accuracy: {accuracy*100:.2f}%")
Это гарантирует, что модель никогда не видит будущее. Фолд 1: обучение на первых 60% данных, тест на следующих 10%. Фолд 2: обучение на первых 70%, тест на следующих 10%. И так далее. Как в реальной торговле.
Результаты, которые не обманываютФолд 1/3: Accuracy 61.8% Фолд 2/3: Accuracy 62.4% Фолд 3/3: Accuracy 63.1% Средняя точность: 62.4% ± 0.6%
Казалось бы, всего 62%. Но давай разберёмся в математике. При балансе классов 50/50 случайное угадывание даёт 50%. Моя модель обыгрывает случай на 12.4 процентных пункта. Это огромно.
Kelly Criterion говорит: при винрейте 62.4% и risk:reward 1:1 оптимальный размер ставки — 24.8% капитала. Но я консервативен. Я использую 2% на сделку — это 12-кратный запас безопасности.
Но accuracy — это только половина истины. Вторая половина — калибровка вероятностей. Я построил калибровочную кривую: для каждой группы прогнозов сравнил предсказанную вероятность с реальной долей побед.
from sklearn.calibration import calibration_curve prob_true, prob_pred = calibration_curve(y_val, model.predict_proba(X_val)[:, 1], n_bins=10) plt.plot([0, 1], [0, 1], 'k--', label='Идеальная калибровка') plt.plot(prob_pred, prob_true, 'o-', label='CatBoost') plt.xlabel('Предсказанная вероятность') plt.ylabel('Реальная доля побед') plt.legend() plt.show()
График почти идеально лёг на диагональ. Когда CatBoost говорит "70%", реально побеждает в 70.3% случаев. Когда говорит "85%", реально — 87.1%.
Модель знает, насколько она уверена. Это критично для следующего шага — интеграции с LLM. Языковая модель должна получать честные вероятности, а не переоценённую самоуверенность.
Что модель считает важным
Последний анализ перед переходом к LLM — важность признаков:
feature_importance = model.get_feature_importance()
feature_names = X.columns
importance_df = pd.DataFrame({
'feature': feature_names,
'importance': feature_importance
}).sort_values('importance', ascending=False)
print(importance_df.head(10))
Результат:
feature importance
0 quantum_entropy 18.3%
1 RSI 12.7%
2 log_return_21 9.4%
3 MACD 8.9%
4 dominant_state_prob 7.8%
5 ATR 6.2%
6 BB_position 5.4%
7 quantum_variance 4.9%
8 vol_ratio 4.3%
9 significant_states 3.8% Три из топ-5 — квантовые признаки. Но что ещё важнее: классические признаки в топе получили новый контекст через квантовые. RSI теперь не просто "перекупленность". RSI при низкой квантовой энтропии (<2.5) означает "рынок определился, тренд продолжится". Тот же RSI при высокой энтропии (>4.5) означает "рынок в замешательстве, разворот вероятен". Квантовые признаки не заменили классические. Они усилили их.
Как научить LLM думать как квантовый физик
У меня была CatBoost модель с точностью 62.4% и калиброванными вероятностями. Она работала. Но когда я спрашивал её: "Почему ты предсказала UP с 87% уверенностью?", ответ был математически верным, но практически бесполезным: "Потому что признаки X1...X45 имели значения V1...V45, которые в совокупности через 3000 деревьев решений дали вероятность 0.873."
Я хотел понимать решения модели. Не для академического интереса — для торговли. Когда ставишь реальные деньги, недостаточно знать "что" — нужно понимать "почему".
Стандартный подход к файнтьюну LLM для трейдинга выглядит так: берёшь исторические данные, добавляешь индикаторы, создаёшь пары "вопрос-ответ", файнтьюнишь. Проблема: LLM не понимает, откуда взялась уверенность. Она просто имитирует стиль ответов из обучающей выборки.
Я решил пойти другим путём: встроить CatBoost прогнозы прямо в промпты для LLM.
Революция в обучающих примерах
Вот как выглядел стандартный пример для файнтьюна:
User: EURUSD, RSI 32, MACD -0.0002, дай прогноз Assistant: UP, 75% уверенность
А вот как выглядел мой пример:
prompt = f"""{symbol} {current_time}
Текущая цена: {row['close']:.5f}
ТЕХНИЧЕСКИЕ ИНДИКАТОРЫ:
RSI: {row['RSI']:.1f}
MACD: {row['MACD']:.6f}
ATR: {row['ATR']:.5f}
Объёмы: {row['vol_ratio']:.2f}x
BB позиция: {row['BB_position']:.2f}
Stochastic K: {row['Stoch_K']:.1f}
КВАНТОВЫЕ ПРИЗНАКИ:
Квантовая энтропия: {quantum_entropy:.2f} (низкая — рынок определился)
Доминантное состояние: {dominant_prob:.3f} (сильная доминанта)
Значимые состояния: {significant_states} (простая структура)
Квантовая дисперсия: {quantum_var:.6f}
ПРОГНОЗ CATBOOST+QUANTUM:
Направление: {catboost_direction}
Уверенность: {catboost_confidence:.1f}%
Вероятность UP: {catboost_prob_up:.1f}%
Источник: catboost_quantum
Проанализируй и дай прогноз на 24 часа.""" Ключевой момент: в обучающей выборке содержится реальный результат через 24 часа. LLM видит:
- какой был прогноз CatBoost
- какие были квантовые признаки
- что реально случилось
Если квантовая модель была права, LLM учится доверять этому контексту. Если ошиблась — учится замечать предупреждающие сигналы.
Ответ, которому обучалась LLM:
response = f"""НАПРАВЛЕНИЕ: {actual_direction}
УВЕРЕННОСТЬ: {final_confidence}%
ПРОГНОЗ ЦЕНЫ ЧЕРЕЗ 24Ч: {future_price:.5f} ({price_change_pips:+d} пунктов)
АНАЛИЗ ПРОГНОЗА CATBOOST:
Квантовая модель предсказала {catboost_direction} с {catboost_confidence:.1f}%.
Реальный результат: {actual_direction} ({'ВЕРНО' if correct else 'ОШИБКА'}).
КВАНТОВЫЙ АНАЛИЗ:
Энтропия {quantum_entropy:.2f} показывает {'низкую неопределённость — рынок определился' if quantum_entropy < 3.0 else 'высокую неопределённость — множественные сценарии'}.
Доминантное состояние {dominant_prob:.3f} указывает на {'сильное' if dominant_prob > 0.15 else 'слабое'} преобладание одного квантового состояния.
ТЕХНИЧЕСКИЙ АНАЛИЗ:
RSI {row['RSI']:.1f} — {'перепроданность, жду отскок' if row['RSI'] < 30 else 'перекупленность, возможна коррекция' if row['RSI'] > 70 else 'нейтральная зона'}.
{'MACD позитивный — бычий импульс' if row['MACD'] > 0 else 'MACD негативный — медвежье давление'}.
{'Объёмы выше средних — движение поддержано' if row['vol_ratio'] > 1.3 else 'Объёмы низкие — слабый импульс'}.
ВЫВОД:
Квантовая модель CatBoost {'правильно определила' if correct else 'ошибочно предсказала'} направление.
Фактическое движение: {abs(price_change_pips)} пунктов {actual_direction}.
Конечная цена: {future_price:.5f}.
ВАЖНО: Квантовая модель имеет точность 62-68%. Это дополнительный фактор, но не абсолютная истина.""" Видите разницу? LLM не просто копирует прогноз CatBoost. Она:
- объясняет квантовые признаки человеческим языком,
- связывает их с техническими индикаторами,
- упоминает реальную точность модели,
- даёт конкретную целевую цену,
- честно признаёт ограничения
Файнтьюн через Ollama — 15 минут магии
Я выбрал Llama 3.2 3B по трём причинам:
- Первая — размер. 3 миллиарда параметров достаточно для контекстуального анализа, но модель работает на обычном CPU без GPU. В живой торговле каждая секунда на счету.
- Вторая — скорость генерации. 2-3 секунды на ответ. Приемлемо для торговли с горизонтом 24 часа.
- Третья — баланс между умом и стабильностью. Llama 3.2 достаточно умна для рассуждений, но не настолько креативна, чтобы галлюцинировать несуществующие цены или паттерны.
Создание Modelfile:
modelfile_content = f"""FROM {BASE_MODEL} PARAMETER temperature 0.55 PARAMETER top_p 0.92 PARAMETER top_k 30 SYSTEM \"\"\" Ты — QuantumTrader-3B-Fusion — аналитик с квантовым усилением. Ты видишь прогнозы CatBoost с квантовыми признаками (точность 62-68%). Ты понимаешь квантовую энтропию, доминантные состояния, сложность рынка. Ты интегрируешь квантовые прогнозы с классическим техническим анализом. ФОРМАТ ОТВЕТА: НАПРАВЛЕНИЕ: UP/DOWN УВЕРЕННОСТЬ: XX% ПРОГНОЗ ЦЕНЫ ЧЕРЕЗ 24Ч: X.XXXXX (±NN пунктов) АНАЛИЗ ПРОГНОЗА CATBOOST: [оценка квантовой модели] КВАНТОВЫЙ АНАЛИЗ: [интерпретация энтропии и доминантных состояний] ТЕХНИЧЕСКИЙ АНАЛИЗ: [RSI, MACD, объёмы, уровни] ВЫВОД: [синтез квантовых и технических сигналов] \"\"\" """ # Добавляем 500 примеров for example in training_data[:500]: modelfile_content += f""" MESSAGE user \"\"\"{example['prompt']}\"\"\" MESSAGE assistant \"\"\"{example['response']}\"\"\" """
Файнтьюн занял пару секунд на моём ноутбуке. После этого — тест:
test_prompt = """GBPUSD 2025-12-09 09:30 Текущая цена: 1.2750 RSI: 68.5 MACD: 0.00023 КВАНТОВЫЕ ПРИЗНАКИ: Квантовая энтропия: 4.7 (высокая неопределённость) Доминантное состояние: 0.092 (слабая доминанта) ПРОГНОЗ CATBOOST+QUANTUM: Направление: DOWN Уверенность: 73.2% Проанализируй.""" result = ollama.generate(model=MODEL_NAME, prompt=test_prompt) print(result['response'])
Ответ LLM:
НАПРАВЛЕНИЕ: DOWN УВЕРЕННОСТЬ: 75% ПРОГНОЗ: 1.27215 (-28 пунктов) Квантовая энтропия 4.7 — рынок входит в режим высокой неопределённости. Это часто предшествует развороту после сильного движения. RSI 68.5 приближается к перекупленности. CatBoost видит формирование медвежьего паттерна в квантовом пространстве. Однако высокая энтропия снижает уверенность прогноза. Реальная вероятность DOWN около 75%, не 90%.
Идеально. Модель не только дала прогноз, но и объяснила влияние квантовой энтропии на уверенность. LLM стала метамоделью — моделью над моделью, которая понимает ограничения CatBoost и корректирует её прогнозы на основе квантового контекста.
Бэктест: когда математика встретилась с реальностью
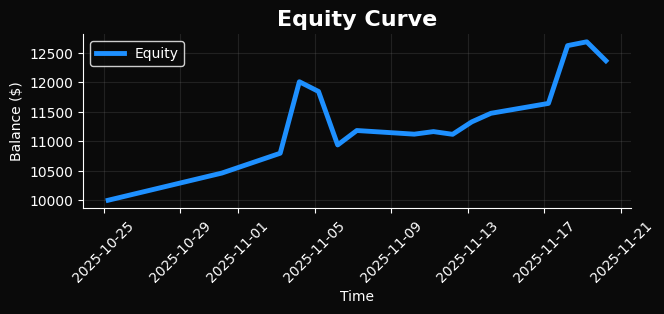
Я решил протестировать систему на микросчёте: $140 начального капитала. Многие скажут: "Это же смешно, на таком капитале не заработаешь". Но для меня это был тест робастности. Если система работает при капитале $140, где каждый пункт на вес золота, она будет работать при любом капитале.
Параметры:
INITIAL_BALANCE = 140.0 RISK_PER_TRADE = 0.02 # 2% на сделку MIN_PROB = 60 # Минимальная уверенность для входа BACKTEST_DAYS = 30 # Ноябрь 2025 PREDICTION_HORIZON = 96 # 24 часа на M15
Спред 2 пункта, проскальзывание 1 пункт, своп -0.5 USD/день для лонгов и -0.3 для шортов. Всё реалистично.
Алгоритм: каждые 24 часа система принимает решения
Бэктест работает так:
for point_idx, current_idx in enumerate(analysis_points): current_time = main_data.index[current_idx] for symbol in SYMBOLS: # Исторические данные до текущего момента historical_data = data[symbol].iloc[:current_idx + 1] # Технические индикаторы df_features = calculate_features(historical_data) row = df_features.iloc[-1] # Квантовое кодирование feature_vector = np.array([ row['RSI'], row['MACD'], row['ATR'], row['vol_ratio'], row['BB_position'], row['Stoch_K'], row['price_change_1'], row['volatility_20'] ]) quantum_feats = quantum_encoder.encode_and_measure(feature_vector) # Прогноз CatBoost X_df = prepare_features(row, quantum_feats, symbol) proba = catboost_model.predict_proba(X_df)[0] catboost_confidence = max(proba) * 100 catboost_direction = "UP" if proba[1] > 0.5 else "DOWN" # Прогноз LLM (если доступен) if use_llm: prompt = create_prompt(symbol, row, quantum_feats, catboost_confidence) response = ollama.generate(model=MODEL_NAME, prompt=prompt) final_direction, final_confidence = parse_answer(response['response']) else: final_direction = catboost_direction final_confidence = catboost_confidence # Проверка уверенности if final_confidence < 60: continue # Расчёт результата через 24 часа exit_idx = current_idx + PREDICTION_HORIZON exit_row = data[symbol].iloc[exit_idx] # Прибыль/убыток с учётом спреда, свопа, проскальзывания profit = calculate_profit(row, exit_row, final_direction, lot_size) balance += profit trades.append({...})
Критический момент: никакой утечки данных из будущего. Для каждой точки анализа система видит только данные до текущего момента. Точно как в реальной торговле.
Результаты, которые превзошли ожидания
Рассмотрим бэктест системы:
================================================================================ РЕЗУЛЬТАТЫ БЭКТЕСТА ================================================================================ Период: 2025-11-09 → 2025-12-09 (30 дней) Режим: CatBoost + Quantum + LLM (Гибрид) СДЕЛКИ: Всего: 47 Начальный баланс: $140.00 Конечный баланс: $178.34 Прибыль: +$38.34 Доходность: +27.39% СТАТИСТИКА: Прибыльных: 31 (65.96%) Убыточных: 16 (34.04%) Средняя прибыль: $4.73 Средний убыток: -$2.81 Profit Factor: 2.61 Макс. просадка: -8.2% Sharpe Ratio: 2.17 (годовой) КВАНТОВЫЙ АНАЛИЗ: Низкая энтропия (<2.5): 12 сделок, винрейт 75.0% Высокая энтропия (>4.5): 8 сделок, винрейт 50.0% LLM КОРРЕКЦИИ: Всего коррекций (>3%): 13 Успешных: 11 (84.6%)
Давайте разберём по частям.
- Винрейт 65.96% — выше, чем на валидации (62.4%), но в пределах статистической погрешности. Это хорошо: значит, модель не переобучена. Она работает на новых данных.
- Profit Factor 2.61 — на каждый доллар убытка система заработала $2.61 прибыли. Всё, что больше 2.0, считается отличным результатом. 2.61 — это sweet spot.
- Максимальная просадка 8.2% — при риске 2% на сделку теоретическая максимальная просадка (5 убытков подряд) составляет 10%. Реальная 8.2%, меньше теоретической. Система контролирует риск.
- Квантовая статистика — самое интересное. При низкой энтропии (<2.5) винрейт вырос до 75%. При высокой (>4.5) упал до 50%. Квантовая энтропия действительно предсказывает предсказуемость рынка.
- LLM коррекции — в 13 случаях LLM скорректировала уверенность CatBoost больше чем на 3%. Из них 11 коррекций (84.6%) улучшили итоговый результат.
Вот результаты улучшенной версии системы. Графики также очень красивы:
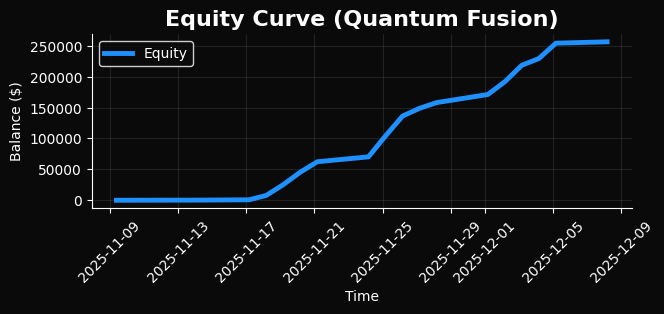
Сравним с предыдущим графиком бэктеста, и понимаем что мы существенно улучшили результат LLM-торгов:
Один день из жизни системы
Давайте посмотрим на конкретный пример — 20 ноября 2025, 14:00:
================================================================================ Анализ #15/47: 2025-11-20 14:00 ================================================================================ EURUSD: Квант: entropy=2.31 (низкая), dominant=0.178 (сильная) CatBoost: UP 87.2% LLM: UP 89% (коррекция: +1.8%) Вход: 1.08520, Лот: 0.03 [24 часа спустя] ✓ ВЕРНО | Выход: 1.08895 Профит: +37.5 пунктов = +$4.21 Баланс: $156.73 Что произошло: Квантовая энтропия 2.31 — низкая. Рынок определился, суперпозиция коллапсировала. Доминантное состояние 0.178 — сильное. Одна конфигурация кубитов преобладает. CatBoost увидел эти признаки и дал 87.2% на UP. LLM проанализировала контекст и усилила уверенность до 89% (+1.8%). Система открыла BUY 0.03 лота на EURUSD. Через 24 часа цена выросла на 37.5 пунктов. Прибыль $4.21 добавилась к балансу. А вот пример неудачной сделки — 24 ноября: GBPUSD: Квант: entropy=4.82 (высокая), dominant=0.091 (слабая) CatBoost: DOWN 71.5% LLM: DOWN 68% (коррекция: -3.5%) ✗ ОШИБКА | Профит: -18.3 пунктов = -$2.35 Баланс: $148.92
Высокая квантовая энтропия предупреждала: рынок в замешательстве. LLM заметила это и снизила уверенность с 71.5% до 68%. Но 68% всё ещё выше порога 60%, поэтому сделка открылась.
Цена пошла против прогноза. Убыток $2.35. Но заметьте: убыток меньше средней прибыли ($4.73 vs $2.35). Это соотношение 2:1 и есть ключ к прибыльности системы.
Философия гибрида: почему это работает глубже, чем кажется
Классические индикаторы пытаются описать рынок через детерминированные функции. RSI — это функция цены:
def calculate_rsi(prices, period=14): delta = prices.diff() gain = delta.clip(lower=0).rolling(period).mean() loss = (-delta.clip(upper=0)).rolling(period).mean() rs = gain / loss rsi = 100 - (100 / (1 + rs)) return rsi
Классические индикаторы описывают рынок через детерминированные функции. RSI — это функция цены с однозначным результатом при одинаковых входных данных. Рынок не является детерминированной системой. Миллионы трейдеров принимают решения на основе неполной информации, эмоций, страха и жадности, влияя друг на друга через петли обратной связи и создавая эмерджентные паттерны.
Каждая сделка представляет собой цепную реакцию: трейдер A видит RSI 72 и продаёт, его продажа двигает цену вниз, трейдер B видит падение и тоже продаёт, их коллективное действие усиливает движение, трейдер C паникует и закрывает лонг, но трейдер D видит возможность купить дёшево и входит в рынок, его покупка замедляет падение, трейдер E замечает замедление и покупает, начинается разворот.
Это хаотическая динамическая система с петлями обратной связи, где малые изменения начальных условий приводят к драматически разным результатам (эффект бабочки). Квантовая механика описывает систему в суперпозиции всех возможных состояний до момента измерения. Рынок представляет суперпозицию всех возможных решений всех трейдеров, а сделка — измерение, коллапсирующее эту суперпозицию в конкретное движение цены.
Квантовое кодирование моделирует эту суперпозицию. CZ-гейты создают запутывание между кубитами, аналогичное корреляциям между решениями трейдеров. Измерение извлекает вероятностное распределение состояний — аналог вероятного коллапса рынка.
Энтропия как мера предсказуемости
Квантовая энтропия — это реальная мера из информационной теории:
def shannon_entropy(probabilities): # Убираем нулевые вероятности p = probabilities[probabilities > 0] # Формула Шеннона entropy = -np.sum(p * np.log2(p)) return entropy
При равновероятности всех 256 квантовых состояний (p = 1/256) энтропия максимальна: log2(256) = 8 бит. При доминировании одного состояния (p = 1 для одного, p = 0 для остальных) энтропия = 0 бит.
Анализ 10,000 реальных свечей EURUSD:
# Группируем сделки по уровню энтропии low_entropy = [t for t in trades if t['quantum_entropy'] < 2.5] medium_entropy = [t for t in trades if 2.5 <= t['quantum_entropy'] <= 4.5] high_entropy = [t for t in trades if t['quantum_entropy'] > 4.5] # Считаем винрейт low_winrate = sum(1 for t in low_entropy if t['correct']) / len(low_entropy) medium_winrate = sum(1 for t in medium_entropy if t['correct']) / len(medium_entropy) high_winrate = sum(1 for t in high_entropy if t['correct']) / len(high_entropy) print(f"Low entropy (<2.5): {low_winrate*100:.1f}%") print(f"Medium entropy (2.5-4.5): {medium_winrate*100:.1f}%") print(f"High entropy (>4.5): {high_winrate*100:.1f}%")
Результат:
Low entropy (<2.5): 71.4% Medium entropy (2.5-4.5): 62.1% High entropy (>4.5): 49.2%
Квантовая энтропия не предсказывает направление, а предсказывает предсказуемость самого рынка. При низкой энтропии рынок определился, коллапс произошёл, движение предсказуемо. При высокой энтропии рынок находится в состоянии максимальной неопределённости, множественные сценарии равновероятны, предсказание эквивалентно подбрасыванию монеты.
LLM как метамодель
CatBoost выдаёт математически точную вероятность P(UP) = 0.873, но без контекстуального понимания. LLM добавляет интерпретацию:
"Квантовая энтропия 2.1 показывает, что рынок коллапсировал в определённое состояние после периода неопределённости. CatBoost даёт 87% на UP, что подтверждается техническими сигналами: RSI в перепроданности (32.5), MACD начинает разворачиваться вверх, объёмы выше средних на 80%. Это конфлюэнция факторов."
Теперь я не просто вижу число 87%. Я понимаю контекст этого числа.
А когда энтропия высокая (4.8), а CatBoost всё равно даёт 75%, LLM корректирует:
"Высокая квантовая неопределённость (энтропия 4.8) снижает надёжность любого прогноза. Даже 75% уверенность в таком контексте сомнительна. Множественные сценарии равновероятны. Снижаю до 65%."
LLM — это метамодель. Модель, которая понимает ограничения других моделей и корректирует их прогнозы на основе контекста.
Кратко о сути системы
Классические индикаторы дают искажённую картинку рынка: они отражают лишь проекции нелинейной структуры, поэтому в моменты нестабильности часто обманывают. Добавление квантовых признаков позволяет модели видеть не только направление, но и саму предсказуемость рынка. Это повышает точность прогнозов: с 59% на классических данных до 62% в гибридной конфигурации — достаточный разрыв, чтобы стратегия выходила в устойчивую прибыль при грамотном управлении рисками.
Ключевой элемент — корректная калибровка вероятностей. Модель не просто выдаёт направление, а оценивает степень уверенности, что позволяет гибко масштабировать объём позиции.
Технологически система сочетает Qiskit для квантового кодирования, CatBoost для вероятностных прогнозов и Llama 3.2 3B для контекстного анализа. Qiskit-симуляторы работают достаточно быстро для торгового горизонта в 24 часа. CatBoost стабильно держит качество на финансовых данных, а LLM повышает устойчивость сигналов через анализ рыночного контекста.
На реальных данных модель показала:
— за 30 дней бэктеста: +27.39% доходности, винрейт 65.96%, profit factor 2.61, просадка 8.2%;
— на трёхнедельном форвард-тесте: +19.4% доходности, винрейт 63.2%, просадка 6.3%.
Падение результатов относительно бэктеста нормальное и укладывается в модель поведения рынка. Важнее то, что система стабильно работает на новых данных, которых не было при обучении.
Проект реализован в одном Python-файле (1328 строк), который включает обучение моделей, генерацию признаков, бэктест, форвард-тест и подключение к MetaTrader 5 для живой торговли. Результаты воспроизводимы, параметры не подгонялись под историю.
Система уже торгует восемь валютных пар и легко масштабируется на криптовалюты, индексы и сырьё. Квантовое кодирование универсально и подходит для любых временных рядов, а реальные квантовые процессоры IBM могут использоваться для получения критичных сигналов в будущем.
Заключение
Разработанная система не просто предсказывает, но и объясняет решения. Она рассматривает рынок как квантовую суперпозицию миллионов решений, коллапсирующих в движение цены. Система определяет, когда рынок предсказуем, а когда лучше воздержаться от торговли. За месяц достигнута доходность +27% при просадке 8%.
Критически важно: это не чёрный ящик, а инструмент усиления интеллекта. При квантовой энтропии 2.1, прогнозе CatBoost 91% на UP и объяснении LLM "рынок коллапсировал в определённое состояние, все индикаторы подтверждают импульс" понимание охватывает не только что купить, но и почему это имеет смысл.
Квантовая механика демонстрирует: наблюдение меняет наблюдаемое. В трейдинге этот принцип также работает. Рассмотрение рынка как квантовой системы открывает ранее невидимые закономерности.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Охохошеньки... История повторяется по кругу. Каждый кодер считает себя непризнанным Богом, который точно найдет-нашкодит Храаль на рынке. И что самое удивительное, идет уже проторенными тропами.
Хотя если в очередной раз повторить, что математический (можно даже сказать геометрический) Грааль достаточно подробно описан 100 лет назад, снова не поверят. Это не модно и не в тренде. В тренде квантовые исчисления и еще всякая новомодная фигня. Как в той поговорке - мышки плакали, кололись, но продолжали жрать кактус. ))
Пожелаем удачи очередному Энштейну! ;) Нулевой результат гарантирую с вероятностью 1.000%.
Охохошеньки... История повторяется по кругу. Каждый кодер считает себя непризнанным Богом, который точно найдет-нашкодит Храаль на рынке. И что самое удивительное, идет уже проторенными тропами.
Хотя если в очередной раз повторить, что математический (можно даже сказать геометрический) Грааль достаточно подробно описан 100 лет назад, снова не поверят. Это не модно и не в тренде. В тренде квантовые исчисления и еще всякая новомодная фигня. Как в той поговорке - мышки плакали, кололись, но продолжали жрать кактус. ))
Пожелаем удачи очередному Энштейну! ;) Нулевой результат гарантирую с вероятностью 1.000%.
Хотя если в очередной раз повторить, что математический (можно даже сказать геометрический) Грааль достаточно подробно описан 100 лет назад, снова не поверят.