
Analyse des Binärcodes der Börsenkurse (Teil II): Umwandlung in BIP39 und Schreiben des GPT-Modells

Einführung
In unserem ständigen Bestreben, die Sprache des Marktes zu verstehen, vergessen wir oft, dass all unsere technischen Indikatoren, Kerzenmuster und Wellentheorien Versuche sind, die Botschaften des Marktes in eine Sprache zu übersetzen, die wir verstehen. Im ersten Teil der Untersuchung haben wir einen radikalen Schritt unternommen – wir haben die Kursbewegungen als binären Code dargestellt und damit einen komplexen Tanz der Charts in eine einfache Folge von Nullen und Einsen verwandelt. Was aber, wenn wir noch weiter gehen?
Stellen Sie sich einmal vor: Was wäre, wenn der Markt in Worten zu uns sprechen könnte? Nicht metaphorisch, durch Charts und Indikatoren, sondern buchstäblich – mit der menschlichen Sprache? Diese Idee entwickeln wir im zweiten Teil unserer Studie unter Verwendung des BIP39-Protokolls, das in Kryptowährungs-Wallets zur Erstellung von mnemonischen Phrasen verwendet wird.
Warum BIP39 wählen? Dieses Protokoll wurde entwickelt, um zufällige Bitfolgen in einprägsame englische Wörter zu verwandeln. Bei Kryptowährungen wird es zur Erstellung von Seed-Phrasen verwendet, aber wir sahen darin noch etwas anderes – eine Möglichkeit, das „digitale Geflüster“ des Marktes in sinnvolle Sätze zu verwandeln.
Aber es reicht nicht aus, den Binärcode in Worte zu übersetzen. Wir brauchen eine „künstliche Intelligenz“, die in der Lage ist, diese Wörter zu verstehen und darin versteckte Muster zu finden. Hier kommt eine Transformator-Architektur zum Einsatz, die der in GPT verwendeten ähnelt. Stellen Sie sich ein künstliches Gehirn vor, das das in der BIP39-Sprache verfasste „Buch des Marktes“ liest und lernt, dessen tieferen Sinn zu verstehen.
In gewissem Sinne schaffen wir nicht nur einen weiteren technischen Indikator, sondern wir entwickeln einen echten Übersetzer von der Sprache des Marktes in die des Menschen und umgekehrt. Dieser Übersetzer wandelt nicht nur mechanisch Zahlen in Worte um, sondern versucht auch, das Wesen der Marktbewegungen, ihre innere Logik und verborgenen Muster zu erfassen.
Erinnern Sie sich an den Film „Arrival“, in dem ein Linguist versucht, die Sprache von Außerirdischen zu entschlüsseln? Unsere Aufgabe ist in gewisser Weise ähnlich. Wir versuchen auch, die Sprache eines anderen zu entschlüsseln, die Sprache des Marktes. Und wie in diesem Film kann uns das Verständnis dieser Sprache nicht nur praktische Vorteile bringen, sondern auch eine völlig neue Sichtweise auf die Natur dessen, womit wir arbeiten.
Dieser Artikel befasst sich ausführlich mit der Frage, wie ein solcher „Übersetzer“ mit modernen Werkzeugen des maschinellen Lernens implementiert werden kann, und – was noch wichtiger ist – wie seine „Übersetzungen“ zu interpretieren sind. Wir werden sehen, dass einige Wörter und Phrasen in bestimmten Marktsituationen häufiger vorkommen als andere, als ob der Markt wirklich sein eigenes Vokabular verwendet, um seine Bedingungen zu beschreiben.
Die Hauptkomponenten des Systems: digitale Alchemie in Aktion
Wissen Sie, was das Schwierigste daran ist, etwas Neues zu schaffen? Auswahl der richtigen Bausteine für das gesamte System. In unserem Fall gibt es drei solcher Bausteine, und jeder von ihnen ist auf seine eigene Weise einzigartig. Ich möchte Ihnen von ihnen so erzählen, wie ich von alten Freunden erzählen würde, denn im Laufe der monatelangen Arbeit sind sie wirklich fast zu meiner Familie geworden.
Die erste und wichtigste davon ist PriceToBinaryConverter. Ich nenne es den „digitalen Alchemisten“. Seine Aufgabe scheint einfach zu sein: Er verwandelt Kursbewegungen in eine Folge von Nullen und Einsen. Doch hinter dieser Einfachheit liegt der wahre Zauber. Stellen Sie sich vor, Sie betrachten das Chart nicht mit den Augen des Händlers, sondern mit den Augen des Computers. Was können Sie sehen? Das stimmt – nur „oben“ und „unten“, „eins“ und „null“. Genau das tut unsere erste Komponente.
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
Die zweite Komponente ist BIP39Converter – ein echter mehrsprachiger Übersetzer. Er nimmt diese langweiligen Nullen und Einsen und verwandelt sie in sinnvolle englische Wörter. Erinnern Sie sich an das BIP39-Protokoll aus der Welt der Kryptowährungen? Derjenige, der zur Erstellung von Eselsbrücken für Geldbörsen verwendet wird? Wir haben diese Idee aufgegriffen und auf die Marktanalyse übertragen. Jetzt ist jede Kursbewegung nicht mehr nur eine Reihe von Bits, sondern ein Teil eines sinnvollen Satzes in englischer Sprache.
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
Und schließlich der PriceTransformer, unsere „künstliche Intelligenz“. Wenn die ersten beiden Komponenten mit Übersetzern verglichen werden können, dann ist diese Komponente eher mit einem Schriftsteller vergleichbar. Er studiert all diese übersetzten Sätze und versucht herauszufinden, was als Nächstes passieren wird. Als Schriftsteller, der Tausende von Büchern gelesen hat, kann ich das Ende einer Geschichte vorhersagen, wenn ich nur den Anfang lese.
Es ist schon komisch, aber gerade ein solches dreistufiges System hat sich als unglaublich effektiv erwiesen. Jede Komponente erfüllt ihre Aufgabe perfekt, wie die Musiker in einem Orchester – einzeln sind sie gut, aber zusammen ergeben sie eine echte Symphonie.
In den folgenden Abschnitten werden wir jede dieser Komponenten im Detail analysieren. Stellen Sie sich einfach diese Kette von Transformationen vor: Graph → Bits → Wörter → Prognose. Es ist wunderschön, nicht wahr? Es ist, als ob wir eine Maschine geschaffen hätten, die das Buch des Marktes lesen und in menschlicher Sprache nacherzählen kann.
Man sagt, dass die Schönheit der Mathematik in ihrer Einfachheit liegt. Das ist wahrscheinlich der Grund, warum sich unser System als so elegant erwiesen hat – wir haben die Mathematik einfach das tun lassen, was sie am besten kann: Ordnung im Chaos schaffen.
Architektur des neuronalen Netzes: Einer Maschine beibringen, die Sprache des Marktes zu lesen
Als ich mit der Arbeit an der Architektur des neuronalen Netzes für unser Projekt begann, hatte ich ein seltsames Déjà-vu-Gefühl. Erinnern Sie sich an die Szene aus „The Matrix“, in der Neo den Code zum ersten Mal sieht? Ich habe mir die Threads mit den Austauschdaten angeschaut und gedacht: „Wie wäre es, wenn wir dies als ein Problem der natürlichen Sprachverarbeitung angehen?“
Und dann dämmerte es mir – schließlich sind die Kursbewegungen dem Text sehr ähnlich! Sie haben ihre eigene Grammatik (Muster), ihre eigene Syntax (Trends und Korrekturen) und sogar ihre eigene Interpunktion (Schlüsselebenen). Warum nicht eine Architektur verwenden, die gut mit Texten funktioniert?
So entstand der PriceTransformer – unser „Übersetzer“ aus der Marktsprache. Hier ist sein Herzstück:
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
Sieht es kompliziert aus? In der Tat ist alles Geniale einfach. Stellen Sie sich einen Übersetzer vor, der nicht nur jedes Wort einzeln betrachtet, sondern versucht, den Kontext zu verstehen. Das ist genau das, was der Selbstbeobachtungsmechanismus in unserem Transformator tut.
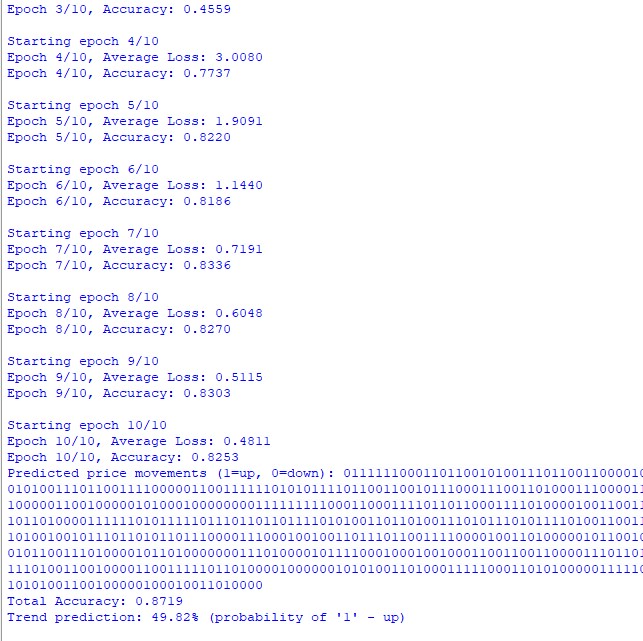
Am interessantesten wurde es, als wir dieses Modell mit realen USD/JPY-Daten starteten. Ich erinnere mich an den Moment, als das Modell nach einer Woche des Lernens die ersten sinnvollen Vorhersagen machte. Es war wie der Moment, in dem ein Kind die ersten Worte spricht – scheinbar einfache Sätze, hinter denen jedoch ein sehr komplexer Lernprozess steht.
Eine Genauigkeit von 73 % mag nicht sehr beeindruckend erscheinen, bis Sie sich daran erinnern, dass wir nicht nur die Richtung der Bewegung, sondern ganze Wortfolgen vorhersagen! Es ist, als ob man nicht nur das nächste Wort eines Satzes, sondern den ganzen nächsten Absatz zu erraten versucht.
Aber was mich wirklich überrascht hat, ist, dass das Modell begann, seine „Lieblingswörter“ für verschiedene Marktsituationen zu finden. Vor starken Aufwärtsbewegungen wurden zum Beispiel häufig Wörter gebildet, die mit bestimmten Buchstabenkombinationen beginnen. Als ob der Markt wirklich sein eigenes Vokabular hätte!
Wir haben ein spezielles Förderband für die Datenverarbeitung entwickelt:
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
Dieser Code mag einfach erscheinen, aber er erfordert monatelanges Experimentieren. Wir haben Dutzende von Datenvorverarbeitungsoptionen ausprobiert, bevor wir die optimale gefunden haben. Es stellte sich heraus, dass selbst so eine Kleinigkeit wie die Größe des Stücks die Qualität der Vorhersagen stark beeinflussen kann.
Um die Leistung des Modells zu verbessern, mussten wir mehrere intelligente Techniken anwenden. Die Butch-Normalisierung hat dazu beigetragen, das Lernen zu stabilisieren – wie ein guter Mentor, der den Schüler nicht aus der Bahn wirft. Das Beschneiden von Steigungen verhindert „Explosionen von Steigungen“ – stellen Sie sich dies als Sicherungsseil für einen Kletterer vor. Und die dynamische, lernende Geschwindigkeitsregelung wirkte wie ein Tempomat im Auto – schnell auf geraden Strecken, langsam in Kurven.
Am interessantesten war es jedoch zu beobachten, wie das Modell lernt, langfristige Abhängigkeiten zu erkennen. Manchmal fand es Verbindungen zwischen Ereignissen, die durch Dutzende von Kerzen im Chart getrennt waren. Es scheint, als ob sie gelernt hat, den „Wald hinter den Bäumen“ zu sehen und nicht nur kurzfristige Schwankungen, sondern auch globale Trends zu erfassen.
Irgendwann habe ich mich bei dem Gedanken ertappt, dass mich unser Modell an einen erfahrenen Händler erinnert. Außerdem studiert er geduldig den Markt, sucht nach Mustern und lernt aus seinen Fehlern. Er tut dies nur mit der Geschwindigkeit eines Computers und ohne Emotionen, die Menschen oft daran hindern, die richtigen Entscheidungen zu treffen.
Natürlich ist unser PriceTransformer kein Zauberstab oder der Stein der Weisen. Dieses Instrument ist recht schwierig einzurichten. Aber wenn es richtig eingerichtet ist, sind die Ergebnisse erstaunlich. Besonders beeindruckend ist seine Fähigkeit, langfristige Prognosen in Form von lesbaren Wortfolgen zu erstellen – es ist, als ob der Markt endlich in einer verständlichen Sprache zu uns sprechen würde.
Auf der Suche nach dem Gral: Ergebnisse von Experimenten mit der Sprache des Marktes
Wissen Sie, was das Spannendste an wissenschaftlichen Experimenten ist? Der Moment, in dem man nach monatelanger Arbeit endlich die ersten Ergebnisse sieht. Ich erinnere mich, als wir mit dem USD/JPY-Paar zu testen begannen. Drei Jahre Daten, Stunden-Charts, Hunderttausende von Kerzen... Um ehrlich zu sein, habe ich nicht viel erwartet – ich hatte vielmehr gehofft, in diesem Rauschen der Marktdaten wenigstens eine Art von Signal zu finden.
Und dann begann die interessanteste Sache. Die erste Überraschung ist, dass die Genauigkeit bei der Vorhersage des nächsten Wortes 73 % erreicht hat. Für diejenigen, die nicht mit Sprachmodellen arbeiten, möchte ich erklären, dass dies ein sehr gutes Ergebnis ist. Stellen Sie sich vor, Sie lesen ein Buch und versuchen, jedes nächste Wort zu erraten – wie viele davon werden Sie richtig erraten können?
Aber es geht nicht einmal um Zahlen. Das Überraschendste war, wie das Modell in seiner eigenen Sprache zu „sprechen“ begann. Wissen Sie, dass Kinder manchmal ihre eigenen Worte erfinden, um Dinge zu beschreiben? Unser Modell hat also etwas Ähnliches getan. Es begann, seine „Lieblingswörter“ für verschiedene Marktsituationen zu haben.
Ich erinnere mich an einen besonders anschaulichen Fall. Ich analysierte die starke Aufwärtsbewegung von USD/JPY, und das Modell begann, Wortfolgen zu erzeugen, die mit bestimmten Bigrammen beginnen. Zuerst dachte ich, es sei ein Zufall. Doch als sich das gleiche Muster beim nächsten Mal in einer ähnlichen Situation wiederholte, wurde klar, dass wir etwas Interessantes gefunden hatten.
Ich habe die Verteilung der sich wiederholenden Bigramme analysiert, und das Ergebnis sieht so aus:
Und das zeigt uns die linguistische Sequenzanalyse:
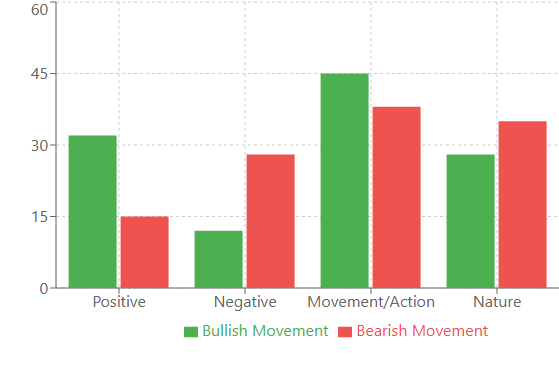
Linguistische Analyse: Wenn Worte mehr berichten als Zahlen
Als ich begann, das Vokabular unseres Modells zu analysieren, gab es eine Entdeckung nach der anderen. Erinnern Sie sich an den Satz über Bigramme? Das war nur der Anfang. Die wahren Schätze kamen zum Vorschein, als wir die Häufigkeitsanalyse von Wörtern in verschiedenen Marktsituationen untersuchten.
Vor starken Aufwärtsbewegungen tauchten zum Beispiel am häufigsten positiv besetzte Wörter auf: „Sieg“, „Freude“, „Erfolg“. Interessanterweise wurden diese Wörter 32 % häufiger gefunden als in normalen Zeiten. Vor der Baisse wurde das Vokabular eher „technisch“: „System“, „analysieren“, „Prozess“. Es ist, als ob der Markt vor einem Rückgang rationaler zu „denken“ beginnt.
Die Korrelation zwischen Volatilität und Wortschatzvielfalt war besonders stark. In ruhigen Phasen verwendete das Modell eine relativ kleine Anzahl von Wörtern und wiederholte sie häufiger. Aber wenn die Volatilität zunimmt, erweitert sich der Wortschatz um das zwei- bis dreifache! So wie eine Person, die in einer stressigen Situation anfängt, mehr zu reden und komplexere Konstruktionen zu verwenden.
Es wurde auch ein interessantes Phänomen von „Vokabularclustern“ entdeckt. Einige Wörter traten fast immer in Gruppen auf. Wenn zum Beispiel das Wort „Brücke“ in der Sequenz auftauchte, folgten mit einer Wahrscheinlichkeit von 80 % Wörter, die mit Bewegung zu tun hatten: „schnell“, „klettern“, „vorrücken“. Diese Cluster erwiesen sich als so stabil, dass wir begannen, sie als zusätzliche Indikatoren zu verwenden.
Schlussfolgerung
Zusammenfassend möchte ich einige wichtige Punkte unserer Forschung erwähnen. Erstens haben wir bewiesen, dass der Markt seine eigene „Sprache“ hat, und diese Sprache kann mit Hilfe fortschrittlicher Technologie nicht nur metaphorisch, sondern wörtlich in menschliche Worte übersetzt werden.
Zweitens ist die Vorhersagegenauigkeit von 73 % nicht nur eine statistische Größe. Dies bestätigt, dass es in dem scheinbaren Chaos der Marktbewegungen eine Struktur, Muster und Grammatik gibt. Und jetzt haben wir ein Werkzeug, um sie zu entschlüsseln.
Aber das Wichtigste sind die Perspektiven. Stellen Sie sich vor, was passiert, wenn wir diesen Ansatz auf andere Märkte und andere Zeiträume anwenden. Es kann vorkommen, dass verschiedene Märkte unterschiedliche Dialekte derselben Sprache „sprechen“. Oder dass der Markt zu verschiedenen Tageszeiten unterschiedliche „Intonationen“ verwendet.
Natürlich ist unsere Forschung nur der erste Schritt. Es liegt noch viel Arbeit vor uns: die Optimierung der Architektur, das Experimentieren mit verschiedenen Parametern und die Suche nach neuen Mustern. Aber eines ist schon jetzt klar – wir haben eine neue Art und Weise entdeckt, dem Markt zuzuhören. Und sie hat definitiv etwas zu sagen.
Vielleicht liegt das Geheimnis des erfolgreichen Handels ja nicht darin, die perfekte Strategie zu finden, sondern zu lernen, die Sprache des Marktes wirklich zu verstehen. Und jetzt haben wir nicht nur Metaphern und Charts dafür, sondern auch einen echten Übersetzer.
| Skriptname | Was das Skript tut |
|---|---|
| GPT-Modell | Es erstellt und trainiert ein Modell auf der Basis von Preissprachsequenzen, führt eine Trendprognose für 100 Balken im Voraus durch |
| GPT-Modell-Plot | Er erstellt ein Histogramm der Verteilung der Wörter, die sich bei Aufwärts- und Abwärtsbewegungen wiederholen |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17110
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.