
Нейросети в трейдинге: Анализ рыночной ситуации с использованием Трансформера паттернов

Введение
За последнее десятилетие глубокое обучение (DL) достигло значительных успехов в различных областях, и эти достижения привлекли внимание исследователей финансовых рынков. Вдохновленные успехом DL, многие стремятся использовать его для прогнозирования рыночных трендов и анализа сложных взаимосвязей в данных. Одним из ключевых аспектов такого анализа является форма представления исходных данных, которая позволила бы сохранить внутренние связи и структуру анализируемых инструментов. Большинство существующих моделей работают с однородными графами, что ограничивает их способность учитывать богатую семантическую информацию, связанную с рыночными паттернами. Аналогично N-граммам в обработке естественного языка, часто встречающиеся рыночные паттерны могут быть использованы для более точного выявления взаимосвязей и прогнозирования трендов.
Для решения этой задачи мы решили заимствовать некоторые подходы из области анализа химических элементов. Где подобно рыночным паттернам, мотивы (значимые подграфы) часто встречаются в структуре молекул, и могут быть использованы для раскрытия молекулярных свойств. Я предлагаю вам познакомиться с фреймворком Molformer, который был представлен в работе "Molformer: Motif-based Transformer on 3D Heterogeneous Molecular Graphs".
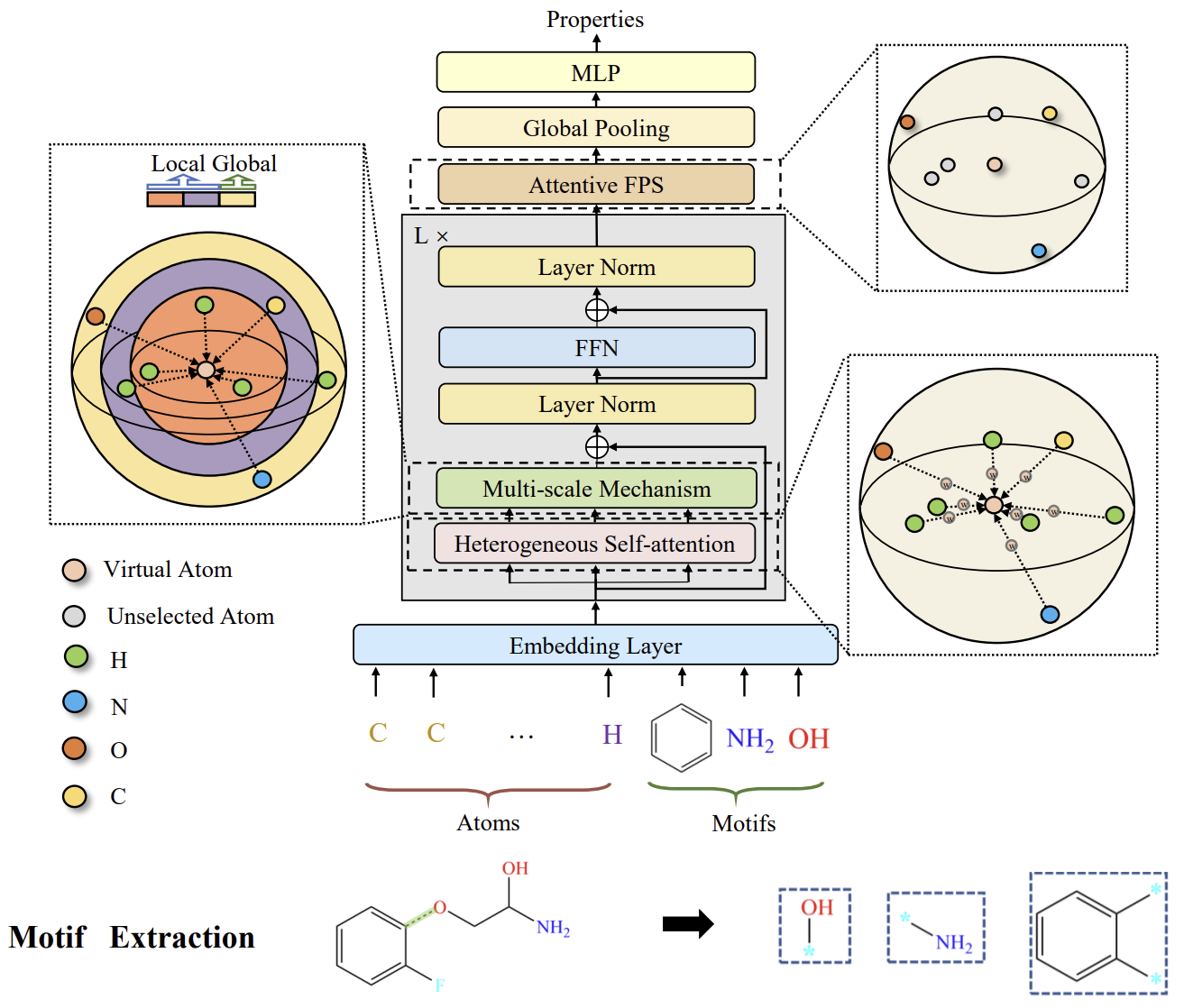
Авторы Molformer в качестве исходных данных модели формулируют новый гетерогенный молекулярный граф (Heterogeneous Molecular Graph — HMG), который состоит из узлов как на уровне атомов, так и на уровне мотивов. Он предоставляет чистый интерфейс для объединения узлов разных уровней и предотвращает распространение ошибок, вызванных неправильной семантической сегментацией атомов. Касательно мотивов авторы метода используют разные стратегии для разных типов молекул. С одной стороны, для малых молекул лексика мотивов определяется функциональными группами, основанными на знаниях о химической области. С другой стороны, для белков, состоящих из последовательных аминокислот, вводится метод интеллектуального анализа мотивов обучения с подкреплением (RL) для обнаружения наиболее значимых аминокислотных подпоследовательностей.
Для лучшего согласования с HMG был представлен фреймворк Molformer, эквивариантная геометрическая модель, основанная на архитектуре Transformer. Molformer отличается от ранее рассмотренных нами моделей на основе трансформаторов двумя основными аспектами. Во-первых, он использует гетерогенное Self-Attention (HSA) для выявления взаимодействий между узлами разных уровней. Во-вторых, алгоритм выборки в самой дальней точке с учетом зависимостей (Attentive Farthest Point Sampling — AFPS) вводится для агрегирования характеристик узлов и получения всестороннего представления всей молекулы.
В авторской статье приведены результаты экспериментов, подтверждающие эффективность предложенного решения для решения задач химической промышленности. И мы предлагаем оценить возможность использования предложенных подходов для решения задач прогнозирования трендов финансовых рынков.
1. Алгоритм Molformer
Мотивы представляют собой часто встречающиеся подструктурные узоры и служат строительными блоками сложных молекулярных структур. Они обладают большой выразительностью биохимических характеристик целых молекул. В химическом сообществе был разработан набор стандартных критериев для распознавания мотивов с существенными функциональными возможностями в малых молекулах. В больших белковых молекулах мотивы представляют собой локальные области трехмерных структур или аминокислотных последовательностей, общих для белков, которые влияют на их функции. Каждый мотив обычно состоит всего из нескольких элементов и может описывать связь между второстепенными структурными элементами. Основываясь на этой особенности, авторы фреймворка Molformer разрабатывают метод эвристического обнаружения белковых мотивов с помощью RL. В своей работе они предлагают рассматривать мотивы из четырех аминокислот, которые составляют мельчайший полипептид и обладают особыми функциональными свойствами в белках. На данном этапе основная цель — найти наиболее эффективный лексикон 𝓥 в составе K четвертичных аминокислотных матриц. Поскольку цель найти оптимальный лексикон для конкретной задачи, практически возможно рассматривать только существующие кватернионы в нисходящих наборах данных, а не все возможные.
Выученный лексикон 𝓥 используется в качестве шаблонов для извлечения мотивов и создания HMG в нижестоящих задачах. А затем, на основе этих HMG, обучается Molformer. Его эффективность рассматривается в качестве вознаграждения r для обновления параметров θ с помощью градиентов политики. В результате Агент может выбрать оптимальную лексику четвертичных мотивов для конкретной задачи.
Примечательно, что предложенный процесс майнинга мотивов представляет собой игру в один шаг, поскольку сеть политики πθ генерирует словарь 𝓥 только один раз в каждой итерации. Таким образом, траектория состоит только из одного действия, а результат Molformer, основанный на выбранной лексике 𝓥, составляет часть от общего вознаграждения.
Авторы фреймворка разделяют мотивы и атомы, рассматривая мотивы как новые узлы для формирования HMG. Таким образом, распутываются представления на уровне мотивов и атомов, тем самым облегчая для моделей задачу правильного извлечения семантических значений на уровне мотивов.
Подобно отношениям между фразами и отдельными словами в естественном языке, мотивы в молекулах несут семантические значения более высокого уровня, чем атомы. Таким образом, они играют существенную роль в определении функциональных возможностей своих атомных составляющих. Авторы Molformer рассматривают каждую категорию мотивов, как новый тип узла, и строят HMG в качестве исходных данных модели таким образом, что HMG включает в себя узлы как на уровне мотива, так и на уровне атома. В качестве положений каждого мотива используется взвешенная сумма 3D координат его составляющих. Аналогично сегментации слов, HMG, состоящие из многоуровневых узлов, избегают распространения ошибок из-за неподходящей семантической сегментации, используя информацию об атомах для обучения молекулярному представлению.
Molformer модифицирует Transformer с помощью нескольких новых компонентов, специально разработанных для 3D HMG. Каждый блок энкодера состоит из HSA, сети FeedForward (FFN) и двухуровневой нормализации. За ними следует AFPS для адаптивного создания молекулярного представления, которое затем подается в полносвязный предиктор для прогнозирования свойств в широком спектре последующих задач.
После формулирования HMG с N+M узлов на уровне атомов и мотивов соответственно, важно наделить модель способностью разделять взаимодействия между многопорядковыми узлами. Для этого авторы метода используют функцию φ(i,j)→Z, которая определяет отношения между любыми двумя узлами в трех видах: атом-атом, атом-мотив и мотив-мотив. Затем обучаемый скаляр bφ(i,j) вводится для адаптивного обслуживания всех узлов в соответствии с их иерархическими отношениями внутри HMG.
Кроме того, авторы метода рассматривают возможность использования трехмерной молекулярной геометрии. Поскольку устойчивость к глобальным изменениям, таким как 3D-трансляции и вращения, является основополагающим принципом обучения молекулярным представлениям, они стремятся удовлетворить инвариантность ротационного перевода и используют сверточную операцию к матрице попарных расстояний 𝑫.
Более того, использование локального контекста оказалось важным в разреженном 3D-пространстве. Тем не менее, было отмечено, что Self-Attention хорошо помогает улавливать глобальные закономерности данных, но игнорирует местный контекст. Основываясь на этом факте, авторы метода накладывают ограничение на Self-Attention, основанное на расстоянии, чтобы извлечь многомасштабные закономерности как из местного, так и из глобального контекста. Для этого была разработана многомасштабная методология для надежного захвата деталей. В частности, осуществляется маскирование узлов за пределами определенного расстояния τs на каждом масштабе s. Затем функции, извлеченные из разных масштабов, объединяются в многомасштабное представление и направляются в FFN.
Авторская визуализация фреймворка Molformer представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка Molformer мы переходим к практической части данной статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. И здесь, как и в предыдущей работе, мы разделим весь процесс реализации фреймворка на отдельные блоки, выполняющие повторяющиеся операции.
2.1 Attention pooling
Для начала мы выделим в отдельный класс алгоритм пулинга на основе зависимостей, предложенный авторами метода R-MAT.
Не удивляйтесь, что реализацию фреймворка Molformer мы начинаем с реализации одного из подходов метода R-MAT. Оба метода были предложены для решения подобных задач химической промышленности. И, на наш взгляд, в них есть некоторые точки соприкосновения, которыми мы воспользуемся. Алгоритм пулинга на основе зависимостей один из них.
Процессы указанного алгоритма мы организуем в классе CNeuronMHAttentionPooling, структура которого представлена ниже.
class CNeuronMHAttentionPooling : public CNeuronBaseOCL { protected: uint iWindow; uint iHeads; uint iUnits; CLayer cNeurons; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHAttentionPooling(void) {}; ~CNeuronMHAttentionPooling(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMHAttentionPooling; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В данном классе мы объявляем 3 внутренние переменные и один динамический массив, в котором сохраним указатели на внутренние объекты в последовательности их вызова. Сам массив мы объявляем статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех унаследованных и вновь объявленных объектов осуществляется в методе Init, в параметрах которого мы получаем константы, однозначно определяющие архитектуру создаваемого объекта.
bool CNeuronMHAttentionPooling::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода инициализации объекта мы сначала вызываем одноименный метод родительского класса, в котором уже реализована часть необходимых контролей и алгоритм инициализации унаследованных объектов. После чего сохраним значение констант, полученных от внешней программы во внутренние переменные.
iWindow = window; iUnits = units_count; iHeads = heads;
Подготовим наш динамический массив.
cNeurons.Clear(); cNeurons.SetOpenCL(OpenCL);
И приступим к созданию структуры вложенных объектов. Здесь мы создаем двухслойную MLP, в которой воспользуемся гиперболическим тангенсом для создания нелинейности между нейронными слоями.
int idx = 0; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow*iHeads, iWindow*iHeads, 4*iWindow, iUnits, 1, optimization, iBatch) || !cNeurons.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 4*iWindow, 4*iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cNeurons.Add(conv) ) return false;
Результаты работы созданной MLP мы нормализуем функцией SoftMax в разрезе отдельных элементов последовательности.
idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cNeurons.Add(softmax) ) return false; softmax.SetHeads(iUnits); //--- return true; }
И завершаем работу метода, передав логический результат выполнения операций вызывающей программе.
Обратите внимание, что в данном случае мы не осуществляем подмену указателей на буфера данных. Это связано с тем, что созданные нами объекты генерируют лишь промежуточные данные. Результат же работы создаваемого объекта формируется путем умножения нормализованных результатов созданной MLP на тензор исходных данных. И именно результаты этой операции мы сохраним в соответствующем буфере, унаследованном от родительского класса. Аналогичная ситуация и с буфером градиентов ошибки.
После завершения работы с методом инициализации класса, мы переходим к построению алгоритма прямого прохода в методе feedForward.
bool CNeuronMHAttentionPooling::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *current = NULL; CObject *prev = NeuronOCL;
В параметрах метода мы получаем указатель на объект исходных данных. А в теле метода мы создаем 2 локальных переменных для временного хранения указателей на объекты. И одной из них передаем указатель на объект исходных данных.
Далее мы организуем цикл перебора объектов внутренней MLP с последовательным вызовом одноименных методов внутренней модели.
for(int i = 0; i < cNeurons.Total(); i++) { current = cNeurons[i]; if(!current || !current.FeedForward(prev) ) return false; prev = current;; }
После выполнения всех итераций цикла, мы получили коэффициенты влияния голов внимания на общий результат по каждому отдельному элементу последовательности. И теперь, как было сказано ранее, нам предстоит вычислить средневзвешенное голов внимания в исходных данных путем умножения полученных коэффициентов на тензор исходных данных. Произведение тензоров записываем в буфер результатов нашего объекта.
if(!MatMul(current.getOutput(), NeuronOCL.getOutput(), Output, 1, iHeads, iWindow, iUnits)) return false; //--- return true; }
И теперь нам остается лишь вернуть логический результат выполнения операций вызывающей программе, после чего завершаем работу метода.
Методы обратного прохода данного класса я предлагаю оставить для самостоятельного изучения. С полным кодом данного класса и всех его методов вы можете ознакомиться во вложении.
2.2 Экстракция паттернов
На следующем этапе нашей работы мы создадим объект экстракции паттернов. Как было сказано в теоретической части, эмбединги паттернов добавляются к тензору исходных данных перед подачей их в модель. Мы же поступим немного иначе — на вход модели подадим обычный набор данных, а экстракцию паттернов и конкатенирование их эмбедингов с тензором исходных данных осуществим в теле модели.
Здесь следует обратить внимание, что каждый эмбединг паттернов, добавляемых к исходным данным, должен иметь размерность одного элемента последовательности исходных данных и находиться в том же подпространстве. Первый вопрос решается путем принятия архитектурных решений. А второй мы постараемся решить в процессе обучения эмбедингов паттернов.
Для решения поставленных задач мы создадим новый класс CNeuronMotifs. Его структура представлена ниже.
class CNeuronMotifs : public CNeuronBaseOCL { protected: CNeuronConvOCL cMotifs; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMotifs(void) {}; ~CNeuronMotifs(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMotifs; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual void SetActivationFunction(ENUM_ACTIVATION value) override; };
В данном классе мы объявляем лишь один внутренний сверточный слой, который и будет выполнять функционал эмбединга паттернов. Однако обращает на себя внимание переопределения метода указания функции активации. Примечателен тот факт, что указанный метод мы ещё ни разу не переопределяли. В данном случае это сделано для синхронизации функции активации внутреннего слоя и объекта.
void CNeuronMotifs::SetActivationFunction(ENUM_ACTIVATION value) { CNeuronBaseOCL::SetActivationFunction(value); cMotifs.SetActivationFunction(activation); }
Инициализацию объявленного сверточного слоя, как и всех унаследованных объектов, мы осуществляем в методе Init. В параметрах данного метода мы получаем константы, которые позволяют нам однозначно определить архитектуру создаваемого объекта.
bool CNeuronMotifs::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch ) { uint inputs = (units_count * step + (window - step)) * dimension; uint motifs = units_count * dimension;
Однако, в отличие от рассмотренных ранее аналогичных методов, в данном случае у нас недостаточно данных для вызова одноименного метода родительского класса. И прежде всего это связано с размером буфера результатов. Как уже было сказано выше, на выходе мы ожидаем получить конкатенированный тензор исходных данных и эмбедингов паттернов. Поэтому мы сначала по имеющимся данным определим размеры тензоров исходных данных и эмбедингов паттернов, и лишь затем вызовем метод инициализации родительского класса с передачей суммы полученных размеров.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, inputs + motifs, optimization_type, batch)) return false;
Следующим шагом мы инициализируем внутренний сверточный слой эмбединга паттернов в соответствии с полученными от внешней программы параметрами.
if(!cMotifs.Init(0, 0, OpenCL, dimension * window, dimension * step, dimension, units_count, 1, optimization, iBatch)) return false;
Обратите внимание, что размер возвращаемых эмбедингов равен размерности исходных данных.
Тут же принудительно отменим функцию активации с помощью переопределенного выше метода.
SetActivationFunction(None); //--- return true; }
После чего завершаем работу метода с передачей логического результата выполнения операций вызывающей программе.
За инициализацией объекта следует построение процессов прямого прохода, которые мы реализуем в методе feedForward. Здесь все довольно прозаично.
bool CNeuronMotifs::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метода мы получаем указатель на объект исходных данных и сразу проверяем актуальность этого указателя. После чего синхронизируем функции активации слоя исходных данных и текущего объекта.
if(NeuronOCL.Activation() != activation)
SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation());
Данная операция позволит нам синхронизировать область результатов слоя эмбедингов с исходными данными.
И лишь после проведения подготовительной работы мы осуществляем прямой проход внутреннего слоя.
if(!cMotifs.FeedForward(NeuronOCL)) return false;
А затем конкатенируем тензор полученных эмбедингов с исходными данными.
if(!Concat(NeuronOCL.getOutput(), cMotifs.getOutput(), Output, NeuronOCL.Neurons(), cMotifs.Neurons(), 1)) return false; //--- return true; }
Конкатенированный тензор записываем в буфер результатов, унаследованный от родительского класса и завершаем работу метода, передав логический результат выполнения операций вызывающей программе.
Далее мы переходим к работе методов обратного прохода. И как вы могли догадаться, их алгоритм так же прост. К примеру, в методе распределения градиента ошибки calcInputGradients мы осуществляем лишь одну операцию деконкатенации буфера градиентов ошибки, унаследованного от родительского класса, с распределением значений между объектом исходных данных и внутренним слоем.
bool CNeuronMotifs::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeConcat(NeuronOCL.getGradient(),cMotifs.getGradient(),Gradient,NeuronOCL.Neurons(),cMotifs.Neurons(),1)) return false; //--- return true; }
Однако, к этой видимой простоте необходимо дать пару пояснений. Во-первых, мы не корректируем градиент ошибки, передаваемый исходным данным и внутреннему слою, на производную функции активации соответствующих объектов. В данном случае такая операция избыточна. И это достигается, благодаря синхронизации указателя функции активаций нашего объекта, внутреннего слоя и исходных данных, которую мы организовали при построении метода прямого прохода. Столь несложная операция позволила нам получить градиент ошибки, скорректированный на производную нужной функции активации, на уровне результатов объекта. Следовательно, мы осуществляем деконкатенацию уже скорректированного градиента ошибки.
Второй момент, на который следует обратить внимание, заключается в том, что мы не передаем градиент ошибки от внутреннего слоя экстракции паттернов к исходным данным. Причиной тому, как ни странно, является решаемая нами задача экстракции паттернов из исходных данных. При этом мы хотим найти именно значимые паттерны, а не "подогнать" исходные данные под желаемые паттерны. Однако, как легко заметить, исходные данные получают свой градиент ошибки по прямому потоку данных.
Ну а с полным кодом данного класса и всех его методов вы можете ознакомиться во вложении.
2.3 Мульти-масштабное внимание
Ещё один "кирпичик", который нам предстоит создать,— это объект мультимасштабного внимания. И должен сказать, что здесь мы сделали, наверное, наиболее крупное отступление от авторского алгоритма Molformer. Дело в том, что в данном блоке авторы фреймворка осуществляли маскирование объектов, удаленных от анализируемого более заданного расстояния. И таким образом акцентировали внимание только на заданной области.
Мы же в своей реализации поступили иначе. Во-первых, вместо предложенного механизма внимания мы воспользовались рассмотренным в предыдущей статье методом относительного Self-Attention, который помимо позиционного смещения анализирует и контекстуальное. Во-вторых, для изменения масштаба внимания мы увеличиваем размер одного анализируемого элемента до двух, трех и четырех элементов исходной последовательности. Что можно сравнить с анализом графика старшего таймфрейма. Реализация нашего решения представлена в классе CNeuronMultiScaleAttention. Структура нового класса приведена ниже.
class CNeuronMultiScaleAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; //--- CNeuronBaseOCL cWideInputs; CNeuronRelativeSelfAttention cAttentions[4]; CNeuronBaseOCL cConcatAttentions; CNeuronMHAttentionPooling cPooling; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultiScaleAttention(void) {}; ~CNeuronMultiScaleAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultiScaleAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Здесь мы явным образом определяем количество масштабов, объявив фиксированный массив объектов относительного внимания. Кроме того, в структуре класса объявляется еще 3 объекта, с назначением которых мы познакомимся в ходе реализации методов класса.
Все внутренние объекты мы объявляем статическими, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronMultiScaleAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В параметрах метода мы, как обычно, получаем константы, однозначно определяющие архитектуру создаваемого объекта. А в теле метода мы сразу вызываем одноименный метод родительского класса. Думаю, излишне повторять, что в нем уже реализованы необходимые контроли и алгоритмы инициализации унаследованных объектов.
После успешного выполнения метода родительского класса, мы сохраняем некоторые константы во внутренних переменных.
iWindow = window; iUnits = units_count;
И перед инициализацией вновь объявленных объектов следует обратить внимание на тот факт, что на данном этапе мы не знаем размер тензора исходных данных. Тем более мы не знаем кратность его размеров нашим масштабам анализа. Более того, получаемый на вход тензор в качестве исходных данных может быть и не кратен нашим масштабам. Однако на вход объектов крупномасштабного внимания нам необходимо подать тензор корректного размера. Для выполнения этого требования, мы создадим внутренний объект, в который скопируем исходные данные и добавим нулевые значения вместо недостающих. Но прежде определим необходимый размер буфера как максимальное из ближайших больших кратных нашим масштабам.
uint units1 = (iUnits + 1) / 2; uint units2 = (iUnits + 2) / 3; uint units3 = (iUnits + 3) / 4; uint wide = MathMax(MathMax(iUnits, units1 * 2), MathMax(units2 * 3, units3 * 4));
И затем мы инициализируем объект для копирования исходных данных необходимого размера.
int idx = 0; if(!cWideInputs.Init(0, idx, OpenCL, wide * iWindow, optimization, iBatch)) return false; CBufferFloat *temp = cWideInputs.getOutput(); if(!temp || !temp.Fill(0)) return false;
Буфер результатов данного слоя мы заполним нулевыми значениями.
Следующим шагом мы инициализируем внутренние объекты внимания различного масштаба с сохранением прочих параметров.
idx++; if(!cAttentions[0].Init(0, idx, OpenCL, iWindow, window_key, iUnits, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[1].Init(0, idx, OpenCL, 2 * iWindow, window_key, units1, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[2].Init(0, idx, OpenCL, 3 * iWindow, window_key, units2, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[3].Init(0, idx, OpenCL, 4 * iWindow, window_key, units3, heads, optimization, iBatch)) return false;
Здесь следует обратить внимание, что несмотря на различные масштабы объектов внимания, на выходе мы ожидаем получить тензоры сопоставимых размеров. Ведь по существу, все они используют единый источник исходных данных. Поэтому, для конкатенации результатов внимания мы объявим объект в 4 раза больше исходных данных.
idx++; if(!cConcatAttentions.Init(0, idx, OpenCL, 4 * iWindow * iUnits, optimization, iBatch)) return false;
И для усреднения результатов внимания, мы воспользуемся вышесозданным классом пулинга на основе зависимостей.
idx++; if(!cPooling.Init(0, idx, OpenCL, iWindow, iUnits, 4, optimization, iBatch)) return false;
В завершении метода инициализации мы осуществляем подмену указателей буферов результатов и градиентов ошибки создаваемого объекта на указатели соответствующих буферов слоя пулинга.
SetActivationFunction(None); if(!SetOutput(cPooling.getOutput()) || !SetGradient(cPooling.getGradient())) return false; //--- return true; }
В завершении метода мы передаем логический результат выполнения операций вызывающей программе.
Обратите внимание, что в данном классе мы не организовали объектов для осуществления остаточных связей, присущих ранее рассмотренным блокам внимания. Дело в том, что используемые нами внутренние блоки относительного внимания уже обладают остаточными связями. Следовательно, усреднение результатов внимания уже учитывает остаточные связи. И дополнительные операции здесь будут излишними.
После инициализации объекта мы переходим к построению процессов прямого прохода, которые мы реализуем в методе feedForward.
bool CNeuronMultiScaleAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Attention if(!cAttentions[0].FeedForward(NeuronOCL)) return false;
В параметрах метода прямого прохода мы, как обычно, получаем указатель на объект исходных данных, который мы сразу передаем в одноименный метод внутреннего слоя внимания оригинального (единичного) масштаба. В теле вызываемого метода внутреннего объекта, помимо основных операций, проведена и проверка актуальности полученного указателя. Следовательно, после успешного выполнения операций метода внутреннего класса, мы можем безопасно использовать полученный от внешней программы указатель. И на следующем шаге мы перенесем исходные данные в буфер соответствующего внутреннего слоя. После чего синхронизируем функции активации.
if(!Concat(NeuronOCL.getOutput(), NeuronOCL.getOutput(), cWideInputs.getOutput(), iWindow, 0, iUnits)) return false; if(cWideInputs.Activation() != NeuronOCL.Activation()) cWideInputs.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation());
Обратите внимание, в данном случае, для копирования исходных данных мы используем метод конкатенации, в параметрах которого дважды указываем указатель на буфер результатов объекта исходных данных. При этом для первого буфера мы указываем размер окна исходных данных, а для второго — "0". Очевидно, что при подобном указании параметров мы получим копию исходных данных в указанном буфере результатов. При этом не осуществляется операция добавления нулевых значений для недостающих данных, о которой мы говорили при инициализации объекта.
Тем не менее, добавление нулевых значений осуществляется неявным образом. Вспомните, при инициализации внутреннего объекта исходных данных, мы заполнили буфер его результатов нулевыми значениями. В процессе обучения и эксплуатации мы ожидаем получать тензоры исходных данных одинакового размера. Следовательно, каждый раз при копировании исходных данных мы будем изменять значения одних и тех же элементов, в то время как остальные будут оставаться нулевыми.
После формирования расширенного объекта исходных данных, мы организуем цикл для проведения операций мультимасштабного внимания. В теле данного цикла мы последовательно будем вызывать методы прямого прохода объектов большего масштаба с передачей им указателя на расширенный объект исходных данных.
//--- Multi scale attentions for(int i = 1; i < 4; i++) if(!cAttentions[i].FeedForward(cWideInputs.AsObject())) return false;
Результаты внимания всех масштабов мы конкатенируем в единый тензор. И здесь надо сказать, что несмотря на различие масштабов анализируемых данных, на выходе мы получаем сопоставимые тензоры, и каждый элемент исходной последовательности остается на своем месте. Поэтому и конкатенацию тензоров мы осуществляем в разрезе элементов исходной последовательности.
//--- Concatenate Multi-Scale Attentions if(!Concat(cAttentions[0].getOutput(), cAttentions[1].getOutput(), cAttentions[2].getOutput(), cAttentions[3].getOutput(), cConcatAttentions.getOutput(), iWindow, iWindow, iWindow, iWindow, iUnits)) return false;
И далее мы так же в разрезе элементов исходной последовательности осуществляем взвешенный пулинг результатов мультимасштабного внимания с учетом зависимостей.
//--- Attention pooling if(!cPooling.FeedForward(cConcatAttentions.AsObject())) return false; //--- return true; }
В завершении работы метода мы возвращаем логический результат выполнения операций вызывающей программе.
Напомню, что на стадии инициализации объекта мы осуществили подмену указателей на объекты буферов результатов и градиентов ошибки. Поэтому результаты пулинга сразу попадают в буферы интерфейсов передачи информации между нейронными слоями модели. Следовательно, мы опускаем излишнюю операцию копирования данных.
С методами обратного прохода данного класса я предлагаю вам ознакомиться самостоятельно. Полный код класса и всех его методов представлен во вложении.
2.4 Выстраиваем фреймворк Molformer
Выше была проведена большая работа по построению отдельных блоков фреймворка Molformer. И теперь пришло время для выстраивания отдельных блоков в целостную архитектуру фреймворка. С этой целью мы создадим новый класс CNeuronMolformer. В качестве родительского объекта в данном случае мы используем CNeuronRMAT, в котором реализован механизм простейшей линейной модели. Структура нового класса представлена ниже.
class CNeuronMolformer : public CNeuronRMAT { public: CNeuronMolformer(void) {}; ~CNeuronMolformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint motif_window, uint motif_step, ENUM_OPTIMIZATION optimization_type, uint batch); //Molformer //--- virtual int Type(void) override const { return defNeuronMolformer; } };
Обратите внимание, что, в отличие от выше реализованных объектов, здесь мы переопределяем лишь метод инициализации нового объекта класса Init. Это стало возможно благодаря организации линейной структуры родительского класса. И теперь нам достаточно заполнить унаследованный от родительского класса динамический массив нужным набором последовательных объектов. Весь алгоритм их взаимодействия уже построен в методах родительского класса.
В параметрах единственного переопределяемого метода мы получаем ряд констант, которые позволяют нам однозначно интерпретировать архитектуру создаваемого объекта, задуманную пользователем.
bool CNeuronMolformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint motif_window, uint motif_step, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
И в теле метода мы сразу вызываем одноименный метод базового класса полносвязного нейронного слоя.
Обратите внимание, что мы вызываем метод именно базового нейронного слоя, а не прямого родительского объекта. Ведь в теле метода нам предстоит создать полностью новую архитектуру. И нам нет необходимости воссоздавать архитектурные решения родительского класса.
Следующим шагом мы подготовим динамический массив, в который будем сохранять указатели на создаваемые объекты.
cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
И перейдем к непосредственным операциям создания и инициализации необходимых объектов. Здесь мы сначала создаем и инициализируем объект экстракции паттернов. Указатель на новый объект добавляем в динамический массив.
int idx = 0; CNeuronMotifs *motif = new CNeuronMotifs(); uint motif_units = units_count - MathMax(motif_window - motif_step, 0); motif_units = (motif_units + motif_step - 1) / motif_step; if(!motif || !motif.Init(0, idx, OpenCL, window, motif_window, motif_step, motif_units, optimization, iBatch) || !cLayers.Add(motif) ) return false;
Затем мы создадим локальные переменные для временного хранения указателей на объекты и организуем цикл создания внутренних слоев Энкодера, количество которых определяется константой в параметрах метода.
idx++; CNeuronMultiScaleAttention *msat = NULL; CResidualConv *ff = NULL; uint units_total = units_count + motif_units; for(uint i = 0; i < layers; i++) { //--- Attention msat = new CNeuronMultiScaleAttention(); if(!msat || !msat.Init(0, idx, OpenCL, window, window_key, units_total, heads, optimization, iBatch) || !cLayers.Add(msat) ) return false; idx++;
В теле цикла мы сначала создаем и инициализируем объект мультимасштабного внимания. А за ним добавляем сверточный блок с остаточной связью.
//--- FeedForward ff = new CResidualConv(); if(!ff || !ff.Init(0, idx, OpenCL, window, window, units_total, optimization, iBatch) || !cLayers.Add(ff) ) return false; idx++; }
Указатели на созданные объекты мы добавляем в динамический массив внутренних объектов.
Далее стоит обратить внимание, что на выходе блока мультимасштабного внимания мы получаем конкатенированный тензор исходных данных и эмбедингов паттернов, обогащенный информацией о внутренних зависимостях. Однако, на выходе класса нам необходимо вернуть тензор обогащенных исходных данных. Но вместо простого "откидывания" эмбедингов паттернов мы воспользуемся функцией масштабирования данных в рамках отдельных унитарных последовательностей. Для этого мы сначала транспонируем результаты работы предшествующего слоя.
//--- Out CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, idx, OpenCL, units_total, window, optimization, iBatch) || !cLayers.Add(transp) ) return false; idx++;
Затем добавим сверточный слой, который выполнит функционал масштабирования отдельных унитарных последовательностей.
CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, units_total, units_total, units_count, window, 1, optimization, iBatch) || !cLayers.Add(conv) ) return false; idx++;
И вернем полученные результаты в исходное представление данных.
idx++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cLayers.Add(transp) ) return false;
После чего нам остается лишь осуществить подмену указателей на буфера данных и вернуть логический результат выполнения операций вызывающей программе.
if(!SetOutput(transp.getOutput()) || !SetGradient(transp.getGradient())) return false; //--- return true; }
На этом мы завершаем рассмотрения классов построения фреймворка Molformer. А с полным кодом представленных классов и всех их методов вы можете ознакомиться во вложении. Там же вы найдете полный код всех программ, используемых при подготовке данной статьи. Сразу стоит сказать, что все программы взаимодействия с окружающей средой и обучения моделей были полностью перенесены из предыдущих работ без каких либо изменений. Были внесены лишь точечные правки в архитектуру Энкодера состояния окружающей среды, с которыми я предлагаю вам познакомиться самостоятельно. Полное описание архитектуры всех обучаемых моделей так же представлено во вложении. А мы переходим к заключительной части данной статьи — обучению моделей и тестированию результатов.
3. Тестирование
В рамках данной статьи мы реализовали фреймворк Molformer средствами MQL5 и теперь переходим к финальной стадии — обучению моделей и проверке обученной политики поведения Актера. Мы следуем алгоритму обучения, описанному в предыдущих работах, и одновременно обучаем три модели: Энкодер состояния счета, Актер и Критик. Энкодер анализирует рыночную ситуацию, Актер осуществляет торговые операции, опираясь на изученную политику, а Критик оценивает действия Актера и указывает направления коррекции политики поведения.
Обучение проводится на реальных исторических данных EURUSD, таймфрейм H1 за весь 2023 год, с использованием стандартных параметров анализируемых индикаторов.
Процесс обучения итеративен и включает периодическое обновление обучающей выборки.
Для проверки эффективности обученной политики используются исторические данные за январь 2024 года. Результаты тестирования приведены ниже.


Исходя из представленных данных следует, что обученная модель в период тестирования осуществила 25 торговых операций, из которых 17 закрылись с прибылью. Это составляет 68% от их общего числа. При этом средняя и максимальная прибыльные сделки в два раза превосходят соответствующие показатели убыточных сделок.
Потенциал предложенной модели также подтверждается графиком баланса, который демонстрирует четкую тенденцию к росту. Тем не менее короткий период тестирования и ограниченное количество сделок позволяют говорить лишь о наличии потенциала.
Заключение
Метод Molformer представляет собой значительный шаг вперёд в области анализа и прогнозирования рыночных данных. Использование гетерогенных рыночных графов, включающих как отдельные активы, так и их комбинации в виде рыночных паттернов, позволяет модели учитывать более сложные взаимосвязи и структуру данных, что значительно улучшает точность прогнозирования предстоящего ценового движения.
В практической части статьи мы реализовали свое видение подходов Molformer средствами MQL5. Мы внедрили предложенные решения в модель и обучили её на реальных исторических данных. В результате получили модель, способную обобщать полученные знания на новые рыночные ситуации и генерировать прибыль. Это подтверждается результатами тестирования. Мы уверены, что предложенный подход может стать основой для дальнейших исследований и применений в области финансового анализа, предоставляя трейдерам и аналитикам новые инструменты для принятия более обоснованных решений в условиях неопределённости.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Доброго дня, ни как не могу добиться выставления ордеров советником test.mq5.
дело в том что элементы массива temp[0] и temp[3] всегда меньше min_lot, где может быть моя ошибка?