
Нейронная сеть на практике: Зарисовка нейрона

Введение
Всем привет и добро пожаловать в очередную статью о нейронных сетях.
В предыдущей статье Нейронная сеть на практике: Псевдообратная (II), я показал важность и причину, по которой разрабатываются специальные системы вычислений. В данной статье мы начинаем новый этап изучения нейронных сетей. Разработать материал для этого этапа нелегко. Нужно найти способ простого объяснения темы, которая порождает столько путаницы.
И что мы увидим на данном этапе? Здесь я хочу показать вам, как обучается нейронная сеть. До настоящего момента мы рассматривали, как нейронная сеть может установить корреляцию между различными данными. Однако то, что мы видели до сих пор имеет значение, когда у нас уже есть база данных с предварительно отфильтрованной и отобранной информацией и записями, что позволяет нейронной сети найти наилучшее решение для представления этих данных. Но как нейронная сеть может установить корреляцию, если данные не отфильтрованы? Это именно та часть, где многие думают, что нейронная сеть - это интеллектуальная сущность, поскольку они представляют, что она учится отсортировать разные элементы.
Именно из-за этого непонимания людям так трудно объяснить суть вопроса. Часто те, кто стремится разобраться в них, не имеют базовых знаний о том, как отсортировать различные виды информации, даже если эти данные имеют определенную взаимосвязь друг с другом. Это самый запутанный момент для тех, кто не работает с этим. При объяснении слушателю может прийти в голову что-то совершенно не связанное с первоначальным объяснением, и по этой причине он не сможет понять, как нейронная сеть отсортирует информацию.
Обратите внимание: я ни в коем случае не утверждаю, что нейронная сеть обучается или что она обладает каким-то скрытым интеллектом. Тот, кто так думает, абсолютно не прав. Нейронная сеть - это не что иное, как большое математическое уравнение, и это уравнение, как мы увидим в этой части статей, понимает данные и классифицирует их определенным образом. После сортировки данных любая информация, похожая или близкая к уже отсортированной, будет рассматриваться как данные с определенной степенью вероятности, связанные с чем-то уже известным.
Я уже поднимал данный вопрос в предыдущих статьях, но здесь мы увидим нечто совсем другое. Не много, совсем чуть-чуть, но всё равно интересное. Итак, давайте начнем с основ и дойдем до построения нейронной сети на основе нейронов, которые мы создали в самом начале.
Основы основ
Чтобы действительно понять, как нейронная сеть обучается, когда мы показываем ей информацию, я прошу вас забыть всё, что как вам кажется, вы знаете об искусственном интеллекте и нейронных сетях. Многое из того, что (как вам кажется) вы знаете, скорее всего, чистая чепуха или дезинформация, особенно если вы видели это на новостных сайтах или в других подобных источниках. Тема нейронных сетей стала достоянием общественности в основном благодаря тому, что некоторые предприниматели увидели в ней возможность для заработка, но нейронные сети разрабатываются уже несколько десятилетий. Это уже давняя разработка, и она не работает так, как многие говорят. Это полезные инструменты, но в основном они предназначены для тех, кто действительно интересуется программированием.
По сути, любая нейронная сеть, а вы можете считать ее искусственным интеллектом, основана на очень простой концепции, о которой уже рассказывалось в предыдущих статьях. Здесь мы рассмотрим данную концепцию более подробно. Это и есть секущая линия. Что бы кто ни говорил, всё в нейронных сетях сводится к следующей концепции: найдите секущую линию, которая приближается к касательной линии. Всё очень просто.
В предыдущих статьях мы пропустили эту часть и сразу перешли к поиску касательной линии. Отсюда и происходят формулы, приведенные выше. Его цель - создать короткую дорогу для касательной линии. Весь этот материал относится к очень конкретному факту: когда в нашей базе данных есть отфильтрованная, отобранная информация. Когда это происходит, нам не нужна секущая линия, мы переходим непосредственно к касательной, создавая формулу, которая наилучшим образом отражает содержимое этой базы данных или, как её еще можно назвать, "банка знаний". Таким образом, когда программа по поиску запрашивает этот банк, она может выдать практически идеальный результат касательно определенной информации. Данный вид программ многие называют искусственным интеллектом. Однако бывают случаи, когда у нас нет всей информации, необходимой для создания базы данных, но даже в этом случае нам нужно, чтобы нейронная сеть установила некоторую корреляцию между данными, поступающими в банк. Этот механизм мы называем обучением. То есть у нас есть множество, казалось бы, некоррелированных данных, но можно отсортировать их простым способом. Затем отправляем эти данные в случайном порядке в нейронную сеть и учим ее находить знаменитую касательную линию. В итоге получится математическое уравнение. Именно данное уравнение позволит искусственному интеллекту генерировать из него результаты. Это подтверждается, когда для проверки уравнения используются данные, неизвестные сети, но отсортированные человеком.
Не знаю, удалось ли вам понять, как всё это работает, но я постараюсь изложить всё более понятно, для тех, кто еще не является программистом, но уже имеет опыт работы на финансовом рынке. Когда мы начинаем работать на рынке, первое, что должны сделать, - это так называемый BackTest. Мы выбираем модель для торговли, переходим на график и ищем все сигналы, в которых появляется эта модель. Это эквивалентно этапу обучения нейронной сети. Как только модель полностью проверена в течение определенного времени, мы перейдем к этапу тестирования. Здесь мы выбираем случайные дни и проверяем, была ли презентована модель или нет. Если не удается распознать модель, даже когда кажется, что ее нет, это значит, что мы ее поняли и можем выразить математической формулой. Теперь наступает третья фаза - слепое тестирование. Мы выходим на рынок и, используя демо-счет, проверяем, работает ли эта математическая формула для определения нашей торговой модели. Если вы уже делали это раньше, тогда вы знаете, что это никогда не бывает на 100% точным, система всегда имеет право на ошибку. Но если эта маржа невелика, всё в порядке: формула работает.
Именно это и пытается сделать нейронная сеть. Поиск этой формулы, будь то распознавание почерка, лиц, молекул, растений, животных, звуков, изображений или чего-то еще, что мы хотим, чтобы было распознано.
Так что давайте перейдем к новой теме и начнем изучать, как это можно сделать.
Нейрон
Теперь, когда мы разобрались с предыдущей темой, давайте начнем с самого простого, что можно создать: с одного нейрона. Но не стоит отчаиваться, думая, что один нейрон бесполезен. Вы увидите, как быстро все разрастется. Не надо спешить, дорогой читатель. Начните неторопливо, разберитесь, что к чему, чтобы действительно понять, как мы строим нейронные архитектуры.
Итак, давайте начнем со следующего кода.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { Print("The first neuron..."); } //+------------------------------------------------------------------+
Этот код, кажущийся неинтересным на первый взгляд, просто выводит сообщение на терминал. И это всё! Но имейте в виду, что это скрипт, хотя он может стать и служебной программой. На данный момент мы оставим его в виде простого скрипта. Итак, что всё-таки должен делать нейрон? Вы можете придумать тысячу разных вещей, но постарайтесь свести их к одной общей цели. Это первая часть, в которой всё сводится к одной задаче, которую должен выполнить нейрон.
Нейрону необходимо знать, как выполнять вычисления. Это важно, так как он должен вернуть некую информацию. Однако мы пока не знаем, что это за вычисления, у нас есть только данные, необходимые для обучения нейрона. Таким образом, приведенный выше код модифицируется и превращается в код, показанный ниже.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; Print("The first neuron..."); } //+------------------------------------------------------------------+
Очевидно, что при одном взгляде на обучающие данные, сразу становится заметно, что в них есть какая-то закономерность. То есть мы умножаем первое число на два. Однако наш нейрон этого не знает, но мы хотим, чтобы он научился составлять уравнения и мог дать правильный ответ. Затем наш нейрон использует созданное им уравнение и выдает информацию, основанную на полученных знаниях.
Отлично, но как заставить нейрон найти данную формулу? Одна важная деталь: Знания, полученные в предыдущих статьях, недостаточны. Итак, как заставить нейрон найти уравнение, которое лучше всего отражает данные обучения?
И снова можно столкнуться с непонятным моментом. Мы просто прикажем нейрону использовать любое случайное значение и на его основе попытаемся найти математическое уравнение. Именно в данной части многие путаются. Мы не просим нейрон искать значение, которое будет использоваться при умножении. Кроме того, мы можем использовать сложение, деление или еще что-то, даже случайные данные. Мы хотим, чтобы нейрон искал и находил математическое уравнение, а не конкретное значение. То есть значение, которое мы позволяем ему использовать, - это просто отправная точка, и не более того. Затем мы еще немного улучшили код, что можно увидеть ниже.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; } //+------------------------------------------------------------------+
Ну что, мы продолжаем. Но сначала давайте разберемся. Обычно в функции MathSrand мы используем значение из системных часов. Это нужно для того, чтобы каждый раз, когда мы запускаем генератор случайных чисел, он начинал с другого значения. Напоминаем, что генерируемые числа не являются случайными, они псевдослучайны. То есть, даже если они не совсем случайны, трудно найти закономерность, позволяющую узнать, каким будет следующий номер в списке. Но поскольку мы хотим, чтобы начиналось всегда с некоторого значения, мы указываем его в MathSrand. Тогда мы сможем опробовать всё более спокойно. Но нас интересует значение переменной weight. Данное значение говорит нейрону о том, на правильном или неправильном пути он находится. Поскольку это случайная величина, у нее еще нет определенного направления.
Теперь обратите внимание на другой момент. Значение веса укладывается в диапазоне от 0 до 1, поскольку в макросе значение функции rand делится на максимальное значение, которое может вернуть rand. Подробнее об этом можно узнать в документации. Но я ограничиваю weight 0 и 1, чтобы облегчить то, что мы увидим позже. Однако ничто не мешает вам использовать значение rand напрямую; необходимо будет лишь внести некоторые поправки в будущем, когда мы будем рассматривать другие вопросы вычислений.
Хорошо, теперь давайте начнем воплощать задуманное. Наш нейрон начинает обретать форму. Но чтобы двигаться дальше, нам сначала нужно сказать нейрону, чтобы он использовал исходную математическую формулу. Обратите внимание, что это не происходит неожиданно: мы должны указать нейронной сети, как ей работать. Она не способна создать саму себя. Если вы хоть немного знакомы с математическими вычислениями, то знаете, что все, абсолютно все, от самых простых до самых сложных полиномов, можно свести к одному. Я имею в виду производную. Но не любую производную, мы ищем очень конкретный, максимально простой вариант. В предыдущих статьях я показал, что уравнение прямой линии - это самое простое из возможных уравнений. Любой полином или уравнение можно свести к этому уравнению прямой линии, если вывести уравнение до его максимального предела. В последнем случае мы можем получить константу, но нам нужна производная, которую мы могли бы использовать в качестве минимального расчета. Поэтому вернемся к уравнению, приведенному ниже.
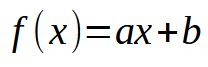
Порядок данной производной здесь не имеет значения. Для нас важно то, что при дальнейшем упрощении мы приходим к константе, а это не то, чего мы хотим, поскольку постоянство нам ни к чему. Однако значение константы < b >, которая является точкой пересечения, на этом раннем этапе следует считать нулевым. При определении значения константы < a >, которая является угловым коэффициентом, мы будем пользоваться тем значением, которое находится в переменной веса. Таким образом, у нас получился новый код:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, x; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; for (uint c = 0; c < Train.Size() / 2; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); } } //+------------------------------------------------------------------+
Запустив данный код, мы увидим в терминале MetaTrader изображение, похожее на то, что показано ниже.
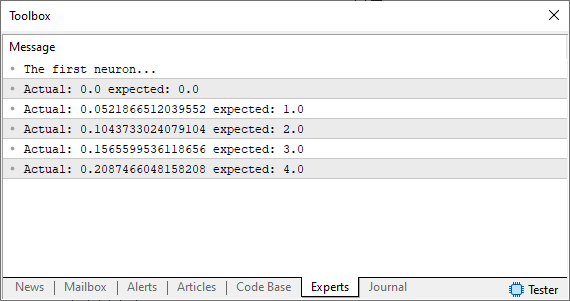
Обратите внимание на то, что мы используем предположение, которое является тем самым случайным числом, не приближающимся к тому, что мы хотим или ожидаем получить. Как же мы можем улучшить ситуацию? Ну хорошо, наш базовый нейрон уже в пути. Теперь нам нужно использовать тот же принцип, что и в предыдущих статьях. Другими словами, мы определим систему ошибок, чтобы нейрон знал, куда продвигаться, чтобы найти наиболее подходящее уравнение. Сделать это довольно просто, как можно видеть в приведенном ниже коде.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, dx, x, err; const uint nTrain = Train.Size() / 2; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; err = 0; for (uint c = 0; c < nTrain; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); dx = fx - Train[c][1]; err += MathPow(dx, 2); } Print("Err: ", err / nTrain); } //+------------------------------------------------------------------+
Когда вы запустите данный код, вы увидите нечто подобное изображению ниже.
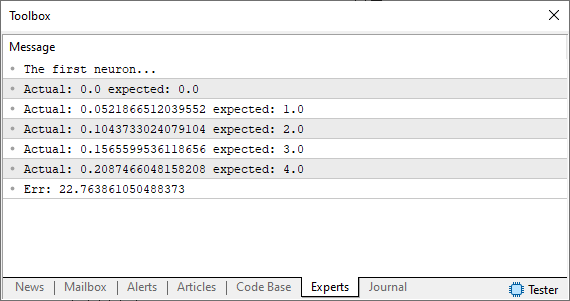
На данный момент мы находимся на перепутье. Это происходит, потому что мы находимся как раз на том этапе, когда вносили поправки вручную, чтобы найти малейшую ошибку. Если вы не понимаете, о чем я, то рекомендую ознакомиться с предыдущими статьями. Но, в отличие от привычных ручных настроек, здесь мы заставим компьютер найти оптимальную настройку. Мы не будем искать касательную линию так, как делали это раньше. Мы найдем касательную линию с помощью секущей. И именно с этого момента машина начнет "сходить с ума", сходясь в одних точках и отклоняясь от правильного решения в других.
Запомните следующий момент: Мы хотим, чтобы значение переменной err уменьшилось, и именно данный факт позволит машине "сойти с ума". Но чтобы лучше понять это, давайте перейдем к новой теме.
Использование секущей линии
В статье "Нейронная сеть на практике: секущая линия " я вкратце упомянул, что секущая линия - это главная линия в нейронной сети. Там я показал рисунок, который вы можете рассмотреть ниже.
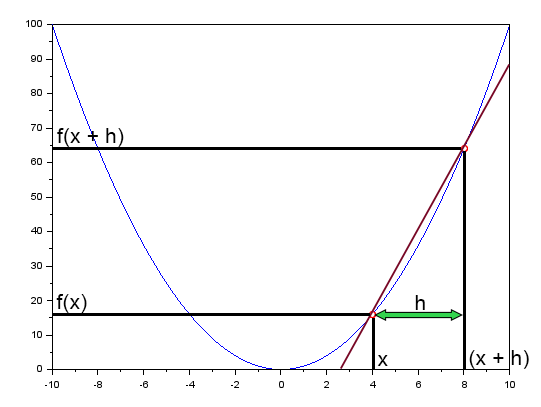
На этом рисунке мы видим кривую ошибок, а также прямую линую. Это и есть секущая линия. Очистив предыдущий рисунок, оставив только выделенную секущую линию, мы получим следующее изображение.
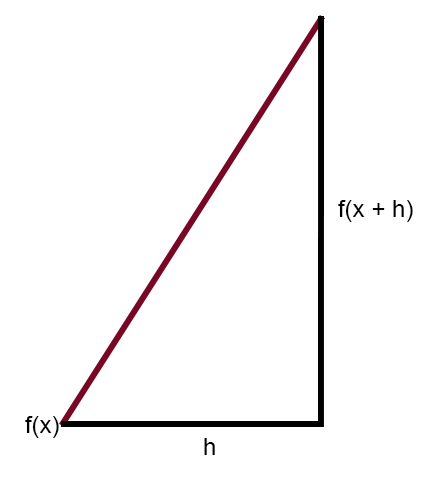
Если сформулировать это же изображение так, чтобы значение константы < h > было равно нулю, то получится следующее выражение, приведенное ниже.
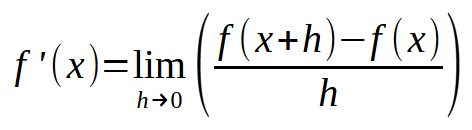
Теперь подходим к самой интересной части: Данная формула, приведенная выше, как раз и является магической формулой нейронной сети, которая учится на своих ошибках. То есть, если использовать это уравнение, можно заставить компьютер найти линейное уравнение, которое наилучшим образом представляет данные, поступающие в нейронную сеть, и таким образом заставить машину научиться решать поставленную задачу, какой бы она ни была. Независимо от того, какие данные подаются в нейронную сеть, вычисления всегда будут одинаковыми. Теперь обратите внимание: секрет в том, чтобы использовать подходящее значение для < h >. Если значение превысит определенный предел, машина будет "сходить с ума", пытаясь найти наилучшее уравнение линии. Если значение слишком мало, машина потратит много времени на поиск наиболее подходящего уравнения, так что немного здравого смысла в этом деле не помешает. Не будьте слишком требовательны, но и не будьте небрежны: Будьте благоразумны.
А как мы добавим это к нейрону? Прежде, чем мы это сделаем, давайте проведем небольшой тест. Посмотрите, какой вид должен быть у кода.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((Train[c][0] * w) - Train[c][1], 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; Print("Err: ", Cost(weight)); Print("Err: ", Cost(weight + eps)); } //+------------------------------------------------------------------+
Упс! Теперь это действительно интересная программа. Запустив её, вы увидите нечто подобное изображению ниже.
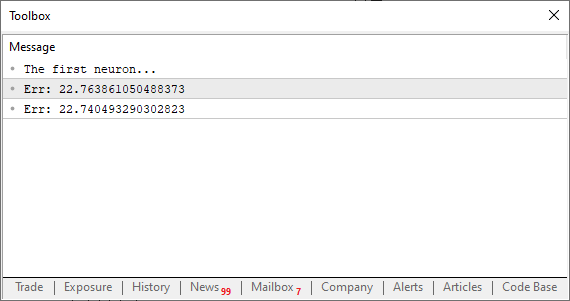
Здесь важно, увеличивается или уменьшается значение ошибки. Само по себе значение нас не интересует. Теперь обратим внимание: значение eps - это наша < h > в формуле выше. Чем ближе это значение к нулю, тем ближе мы к касательной линии на каждой выполненной итерации. Это происходит, потому что секущая линия начинает сходиться к предельной точке. Теперь нам нужно сделать кое-что очень простое: нам нужно создать цикл, чтобы это значение ошибки или «стоимость», становилось всё меньше и меньше. Наступит момент, когда она перестанет уменьшаться и начнет увеличиваться. В этот самый момент программа должна осознать это и выйти из цикла, иначе она попадет в бесконечный цикл, но мы можем создать и другой вид ограничений, чтобы избежать бесконечного цикла. Обычно мы просим цикл выполнить определенное количество итераций перед завершением, на случай если программа не сходится или "сходит с ума". Но может случиться так, что программа станет нестабильной из-за значения, используемого для выполнения этапов. Мы рассмотрим данный вопрос в ближайшее время. Пока не стоит беспокоиться об этом. Но, несмотря на это, ничто не мешает вам заставить программу искать наименьшее значение. Вы сами решаете, когда завершить цикл. В любом случае, давайте посмотрим, как это будет выглядеть на практике. Чтобы понять это, давайте рассмотрим приведенный ниже код.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err; 31. 32. Print("The first neuron..."); 33. MathSrand(512); 34. weight = (double)macroRandom; 35. 36. for(ulong c = 0; c < 10; c++) 37. { 38. err = ((Cost(weight + eps) - Cost(weight)) / eps); 39. weight -= (err * eps); 40. Print(c, " --> ", weight, " :: ", err); 41. } 42. Print("Weight: ", weight); 43. } 44. //+------------------------------------------------------------------+
Когда вы запустите этот код, в терминале вы увидите нечто похожее на следующее изображение.
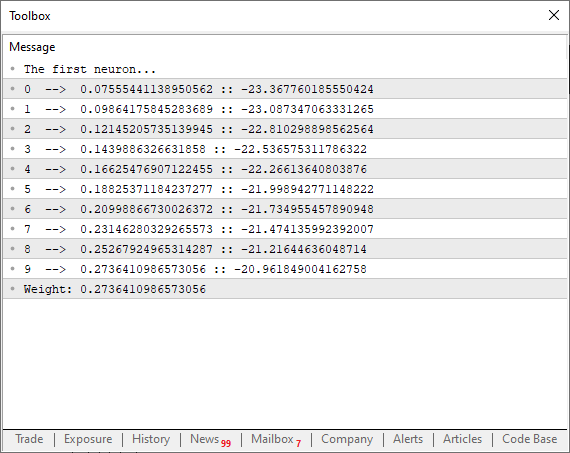
Заметьте, что здесь происходит нечто интересное. В строке 38 мы выполняем именно то вычисление, которое было показано выше, где мы заставляем секущую линию найти минимальную предельную точку для схождения функции. Однако обратите внимание, что в строке 39 я не просто изменяю точку на кривой функции, используя только значение ошибки или итоговую цену. Почему? Причина в том, что если сделать это таким образом, программа начнет прыгать туда-сюда по параболической кривой, а это не то, чего мы хотим. Мы хотим, чтобы значение изменялось плавно, без каких-либо скачков. Почему бы нам не использовать значение eps для соответствия следующей точке кривой параболы? Причина в том, что для этого нам пришлось бы знать, увеличивается или уменьшается ошибка, что становится совершенно ненужным, если мы выполняем факторизацию, указанную в строке 39. Кроме того, это заставляет нейрон делать попытки сходиться быстрее в начале процесса, а по мере приближения к идеальному значению кривая затухания начнет сглаживаться, что приводит к появлению перевернутой логарифмической функции затухания. Это, кстати, очень хорошо, поскольку мы сможем гораздо быстрее найти подходящее значение ошибки.
Хорошо, но показанный выше код можно еще улучшить. Мы можем добавить еще несколько элементов, чтобы лучше проанализировать происходящее. В то же время мы можем добавить дополнительный тест, целью которого будет заставить цикл завершиться, как только будет достигнута минимальная точка схождения, даже до того, как счетчик достигнет максимального количества итераций. Таким образом, новый код будет следующим.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err, e1; 31. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 32. 33. Print("The first neuron..."); 34. MathSrand(512); 35. weight = (double)macroRandom; 36. 37. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight)) > eps); c++) 38. { 39. err = (Cost(weight + eps) - e1) / eps; 40. weight -= (err * eps); 41. if (f != INVALID_HANDLE) 42. FileWriteString(f, StringFormat("%I64u;%f;%f\n", c, err, e1)); 43. } 44. if (f != INVALID_HANDLE) 45. FileClose(f); 46. Print("Weight: ", weight); 47. } 48. //+------------------------------------------------------------------+
Этот код увлекателен тем, что он невероятно интересен, поскольку позволяет изучать его и работать над ним. Я позволил себе вывести значения не в терминал MetaTrader 5, а в файл. При этом можно построить график, чтобы спокойно изучать происходящее. В данном случае, когда код настроен соответствующим образом, у нас получится график, показанный ниже:
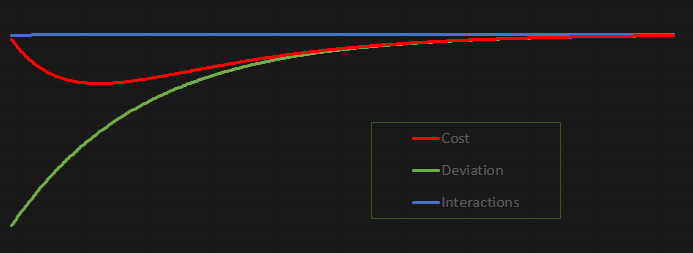
Данный график был построен в Excel на основе значений, хранящихся в файле, созданном нейроном. Правда, способ создания файла несколько примитивен, но, учитывая, что это приложение, созданное для обучения и развлечения, я не вижу проблем в том, как мы передаем данные в файл.
Заключительные идеи
В этой статье мы показали как строить базовый нейрон. Хотя он очень прост, и многие думают, что код совершенно тривиален и не имеет никакой цели, я хочу, чтобы вы поэкспериментировали с ним и вам стало интересно изучать этот простой нейрон. Не бойтесь изменять код, чтобы лучше его понять. Код находится в приложении именно для этих целей. Я хочу, чтобы вы спокойно прочитали статью. Попробуйте написать код с нуля и протестируйте каждый шаг, пока не достигнете окончательного варианта кода, представленного в статье. Сделайте это, не копируя код напрямую, и создайте свою собственную версию, убедившись, что она работает так, как показано в статье. Создайте свою собственную версию, чтобы она была вам понятна, не пытайтесь подражать мне, но постарайтесь получить тот же результат: значение, которое устанавливает корреляцию между данными, присутствующими в обучающем массиве. Всё очень просто.
Поскольку код находится в приложении, я хотел бы дать вам несколько советов по тем элементам, которые вы можете изменить, что будет довольно интересно в этом первом контакте. Не забывайте спокойно изучать каждое изменение. Первый элемент - обучающий массив, расположенный в шестой строке кода приложения. Можно поместить туда разные значения, чтобы нейрон попытался найти между ними корреляцию.
Еще один очень интересный момент - изменение значения константы в строке 15. Измените его на большее или меньшее значение и наблюдайте за результатом, который нейрон сообщает в конце своей работы. Вы так заметите, что более низкие значения требуют больше времени для обработки, но в качестве компромисса результат будет гораздо ближе к идеальному значению.
Другой не менее интересный момент находится в строке 35, где мы присваиваем вес, который будет колебаться между нулем и единицей. Но можно изменить его, умножив значение, возвращаемое макросом. Например, попробуйте поместить в строку 35 что-то такого плана.
weight = (double)macroRandom * 50;
Вы заметите, что всё будет совсем по-другому, просто потому, что вы изменили начальный вес, с которым нейрон начнет работу. И когда будет полная уверенность в том, что происходит, то можно будет изменить код в строке 34 на тот, что указан ниже.
MathSrand(GetTickCount());
После этого вы заметите, что всё гораздо интереснее, чем многие думают. Но, самое главное, вы начнете понимать, как отдельный нейрон в нейронной сети может чему-то научиться. В следующей статье мы превратим этот нейрон в нечто еще более интересное. Поэтому, прежде чем переходить к следующей статье, изучите данный код и поэкспериментируйте с ним. Потому что это только начало.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/13744
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована новая статья Нейронная сеть на практике: зарисовка нейрона:
Автор: Даниэль Хосе
Отличная статья, поздравляю с дидактическим подходом. С нетерпением жду следующих!
Спасибо за содержание.
Следующие, связанные с нейронными сетями, будут еще лучше. И намного веселее. Это я могу гарантировать. 😁👍 Поскольку цель - показать, как нейронные сети работают под капотом.
Одна деталь: как вы могли заметить. Я тоже работаю над другим профилем. Поскольку я хочу передать как можно больше своих знаний всем участникам сообщества. Но на самом деле, контент по нейронным сетям создан именно для того, чтобы объяснить, как они на самом деле работают. Спасибо за ваш комментарий. И я надеюсь, что вы получите удовольствие от контента, так же как я получаю удовольствие, показывая вам, как все это работает. 🙂 👍
Маленькая деталь: как вы, возможно, уже заметили, я работаю и по другому профилю. Я хочу передать максимум своих знаний всем членам сообщества. На самом деле, контент на нейронных сетях создан для того, чтобы объяснить их функционирование. Спасибо за ваш комментарий. Я надеюсь, что вы с удовольствием изучите его, так же как я с удовольствием покажу вам, как все это работает. 🙂 👍