
Переосмысливаем классические стратегии (Часть XI): Пересечение скользящих средних (II)

Ранее мы уже рассматривали идею прогнозирования пересечений скользящих средних, ссылка на статью находится здесь. Мы заметили, что пересечения скользящих средних прогнозировать легче, чем непосредственное изменение цен. Сегодня мы вернемся к этой знакомой проблеме, но с совершенно другим подходом.
Теперь мы хотим тщательно изучить, насколько это существенно влияет на наши торговые приложения и как этот факт может улучшить ваши торговые стратегии. Пересечения скользящих средних являются одной из старейших существующих торговых стратегий. Построить прибыльную стратегию, используя такую широко известную методику, непросто. Тем не менее, я надеюсь показать вам в этой статье, что старые собаки действительно могут научиться новым трюкам.
Чтобы быть эмпирическими в наших сравнениях, сначала построим торговую стратегию на MQL5 для валютной пары EURGBP, используя только следующие индикаторы:
- 2 Экспоненциальные скользящие средние, применяемые к цене закрытия. Одна с периодом 20, а другая установлена на 60.
- Стохастический осциллятор с примененными настройками по умолчанию 5,3,3 установлен в режим экспоненциальной скользящей средней и настроен на выполнение своих расчетов в режиме CLOSE_CLOSE
- Индикатор Средний истинный диапазон (Average True Range) с периодом в 14 минут для установки уровней тейк-профита и стоп-лосса.
Далее в статье мы подробно рассмотрим параметры, при которых проводилось бэк-тестирование. Однако в ходе бэк-теста мы обратим внимание на ключевые показатели эффективности, такие как коэффициент Шарпа, доля прибыльных сделок, максимальная прибыль и другие важные показатели эффективности.
После завершения мы внимательно заменим все традиционные торговые правила на алгоритмические торговые правила, которые мы узнали из рыночных данных. Мы обучим 3 модели ИИ прогнозированию:
- Будущая волатильность: Это будет сделано путем обучения модели ИИ прогнозированию показаний ATR.
- Взаимосвязь между изменением цены и пересечениями скользящих средних: Мы создадим 2 дискретных состояния, в которых могут находиться скользящие средние. Скользящие средние могут находиться только в одном состоянии одновременно. Это поможет нашей модели искусственного интеллекта сосредоточиться на критических изменениях индикатора и среднем влиянии этих изменений на будущие уровни цен.
- Взаимосвязь между изменением цены и стохастическим осциллятором: На этот раз мы создадим 3 дискретных состояния, которые стохастический осциллятор может занимать поочередно. Затем наша модель определит средний эффект критических изменений в стохастическом осцилляторе.
Эти 3 модели ИИ не будут обучаться ни на одном из периодов времени, которые мы будем использовать для нашего бэк-тестирования. Наш бэк-тест продлится с 2022 по июнь 2024 года, а наши модели ИИ будут обучаться с 2011 по 2021 год. Мы позаботились о том, чтобы обучение и бэк-тестирование не перекрывали друг друга, поэтому мы можем сделать все возможное, чтобы сохранить истинную эффективность модели на данных, которые она не видела.
Хотите верьте, хотите нет, но мы успешно улучшили все показатели эффективности по всем направлениям. Наша новая торговая стратегия была более прибыльной, имела повышенный коэффициент Шарпа и принесла прибыль более чем в половине случаев (55%) от всех сделок, совершенных в течение периода бэк-тестирования.
Если такую старую и широко используемую стратегию можно сделать более прибыльной, я полагаю, что это должно вдохновить любого читателя на то, что их стратегии также можно сделать более прибыльными, если только вы сможете правильно сформировать свою стратегию.
Большинство трейдеров упорно трудятся в течение длительного периода времени над созданием своих торговых стратегий и вряд ли когда-либо будут подробно обсуждать свои выигрышные личные стратегии. Соответственно, пересечение скользящих средних служит нейтральной точкой обсуждения, которую все члены нашего сообщества могут использовать в качестве ориентира. Надеюсь предоставить вам обобщенную структуру, которую вы сможете дополнить своими собственными торговыми стратегиями, и, следуя этой структуре соответствующим образом, вы увидите некоторые улучшения в собственных стратегиях.
Начинаем
Для начала запустим нашу среду разработки MetaEditor IDE и приступим к созданию торгового приложения, которое послужит нам основой.
Нам надо реализовать простую стратегию пересечения скользящей средней, так что давайте начнем. Сначала импортируем торговую библиотеку.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Определим глобальные переменные.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
Создание обработчиков для наших технических индикаторов.
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
Также исправим некоторые из наших переменных на постоянные.
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
Некоторыми из наших входных данных следует управлять вручную. Например, размер лота и ширина стоп-лосса.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
Пока наша система загружается, мы вызовем специальную функцию для настройки наших технических индикаторов и сохранения рыночных данных.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
В противном случае, если мы больше не пользуемся торговым приложением, освободим ресурсы, которые нам больше не нужны.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
Если у нас нет открытых позиций на рынке, мы будем искать возможность для торговли.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
Эта функция инициализирует наши технические индикаторы и сохранит размер лота, указанный конечным пользователем.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
Теперь мы создадим функцию сохранения обновленных ценовых предложений при их получении.
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
Эта функция окончательно проверит наличие нашего торгового сигнала. Если сигнал будет найден, мы откроем наши позиции со стоп-лоссами и тейк-профитами, установленными ATR.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Теперь мы готовы к бэк-тестированию нашей торговой системы. Мы будем тренировать простой торговый алгоритм пересечения скользящих средних, который мы только что определили выше, на ежедневных рыночных данных по паре EURGBP. Период нашего бэк-тестирования будет с начала января 2022 года по конец июня 2024 года. Мы установим для параметра "Forward" значение false. Рыночные данные будут смоделированы с использованием реальных тиков, которые наш терминал должен будет запросить у нашего брокера. Это гарантирует, что результаты наших тестов будут точно соответствовать рыночным условиям, сложившимся в тот день.
Рис. 1: Некоторые настройки для нашего бэк-теста
Рис. 2: Остальные параметры нашего бэк-теста
Результаты нашего бэк-теста не внушают оптимизма. Наша торговая стратегия приносила убытки на протяжении всего теста. Впрочем, в этом тоже нет ничего удивительного, поскольку мы уже знаем, что пересечения скользящих средних являются запоздалыми торговыми сигналами. На рисунке 3 ниже представлен баланс нашего торгового счета во время тестирования.
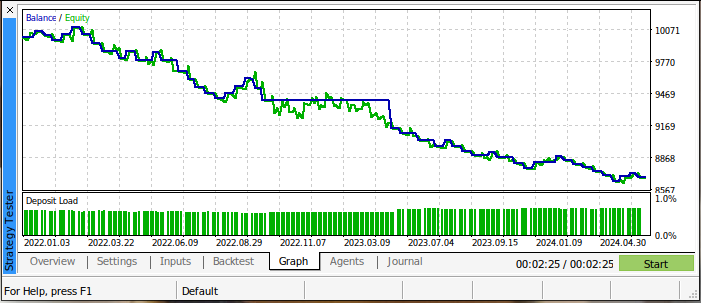
Рис. 3: Баланс нашего торгового счета на момент проведения бэк-теста
Наш коэффициент Шарпа составил -5,0, и мы потерпели убытки в 69,57% всех заключенных нами сделок. Наш средний убыток был больше, чем наша средняя прибыль. Это плохие показатели эффективности. Если бы мы использовали эту торговую систему в ее нынешнем состоянии, мы бы наверняка быстро потеряли свои деньги.
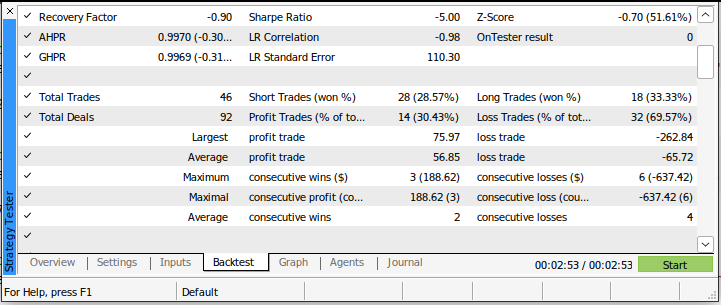
Рис. 4: Подробности нашего бэк-теста с использованием традиционного подхода к торговле на рынках
Стратегии, основанные на пересечениях скользящих средних и стохастическом осцилляторе, широко использовались и вряд ли будут иметь какое-либо существенное преимущество, которое мы могли бы использовать как трейдеры-люди. Но это не означает, что наши модели ИИ не могут освоить каких-либо существенных преимуществ. Мы собираемся использовать специальное преобразование, известное как «думми-кодирование», чтобы представить текущее состояние рынков в нашей модели ИИ.
Думми-кодировка используется, когда у вас есть неупорядоченная категориальная переменная, и мы присваиваем один столбец для каждого значения, которое она может принимать. Например, изображение, если команда разработчиков MQL5 позволила вам выбрать, в какой цветовой гамме вы хотите установить MetaTrader 5. Вы можете выбрать: красный, розовый или синий. Мы можем собрать эту информацию, создав базу данных с тремя столбцами, озаглавленными "Красный", "Розовый" и "Синий" соответственно. Столбец, который вы выбрали во время установки, будет равен единице, остальные столбцы останутся равными 0. В этом заключается идея думми-кодирования.
Думми-кодирование является мощным средством, потому что, если бы мы выбрали другое представление информации, например, 1-красный, 2-розовый и 3-синий, наши модели ИИ могли бы обучаться ложным взаимодействиям в данных, которых нет в реальной жизни. Например, модель может узнать, что 2 с половиной - это оптимальный цвет. Таким образом, думми-кодирование помогает нам представлять нашим моделям категориальную информацию таким образом, чтобы гарантировать, что модель неявным образом не предполагает наличие масштаба для предоставляемых ей данных.
Наши скользящие средние будут иметь два состояния, первое состояние будет активировано, когда быстрая движущаяся средняя окажется выше медленной. В противном случае будет активировано второе состояние. В любой момент времени может быть активным только одно состояние. Невозможно, чтобы цена находилась в обоих состояниях одновременно. Аналогично, наш стохастический осциллятор будет иметь 3 состояния. Один из них будет активен, если цена превысит значение 80 на индикаторе, второй будет активирован, когда цена опустится ниже отметки 20. В противном случае будет активировано третье состояние.
Активному состоянию будет присвоено значение 1, а всем остальным состояниям - 0. Это преобразование заставит нашу модель изучать среднее изменение целевого показателя по мере того, как цена проходит через различные состояния нашего индикатора. Это близко к тому, что делают профессиональные трейдеры-люди. Трейдинг - это не то же самое, что инженерия, мы не можем ожидать миллиметровой точности. Скорее, лучшие трейдеры-люди со временем познают, что, скорее всего, произойдет дальше. Обучение нашей модели с использованием думми-кодирования приведет нас к той же цели. Наша модель оптимизирует свои параметры, чтобы узнать среднее изменение цены, учитывая текущее состояние технических индикаторов.
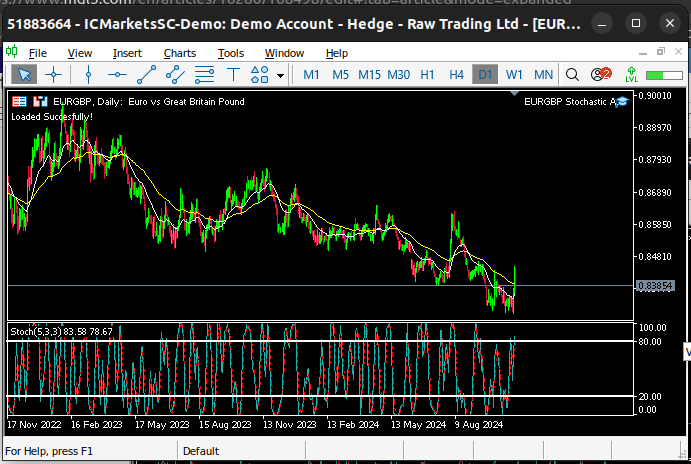
Рис. 5: Визуализация дневного рынка EURGBP
Первый шаг, который мы предпримем для создания наших моделей ИИ, - это получение необходимых нам данных. Всегда рекомендуется извлекать те же данные, которые вы будете использовать в рабочей среде. Именно по этой причине мы будем использовать этот скрипт на MQL5 для извлечения всех наших рыночных данных из терминала MetaTrader 5. Неожиданные различия в способах расчета значений индикаторов в разных библиотеках могут привести к неудовлетворительным результатам в конце дня.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Разведочный анализ данных
Теперь, когда мы извлекли наши рыночные данные из терминала, давайте приступим к анализу рыночных данных.
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Считаем данные.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
Добавим двоичную цель, которая поможет нам визуализировать данные.
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
Масштабируем данные.
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Для визуализации данных будем использовать библиотеку Plotly.
import plotly.express as px
Давайте посмотрим, насколько хорошо медленная и быстрая скользящая средняя помогают нам различать восходящие и нисходящие движения рынка.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
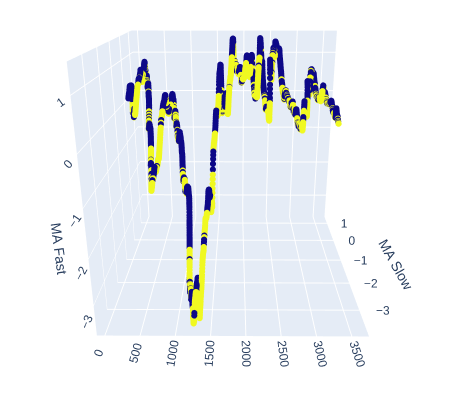
Рис. 6: Визуализация взаимосвязи между скользящими средними и целью
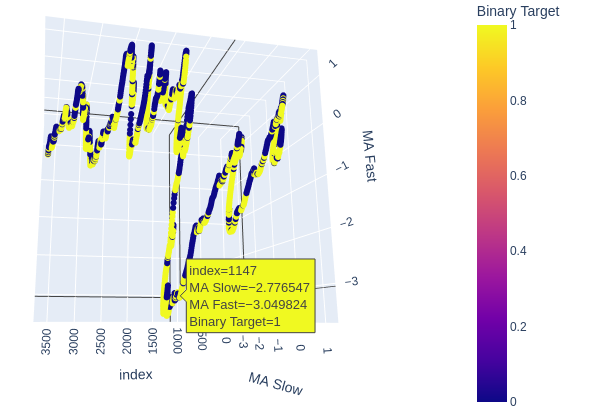
Рис. 7: Складывается впечатление, что наши скользящие средние в разумной степени группируют бычье и медвежье ценовое движение
Давайте посмотрим, может ли волатильность рынка повлиять на достижение цели. Мы заменим время на оси x и вместо него поместим значение ATR, а медленная и быстрая скользящие средние сохранят свои позиции.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
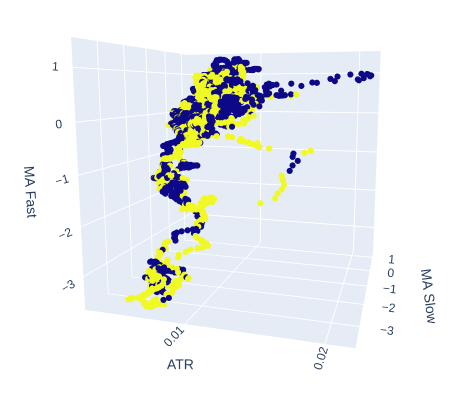
Рис. 8: По-видимому, ATR вносит немного ясности в нашу картину рынка. Возможно, нам придется немного изменить показания волатильности, чтобы они были информативными
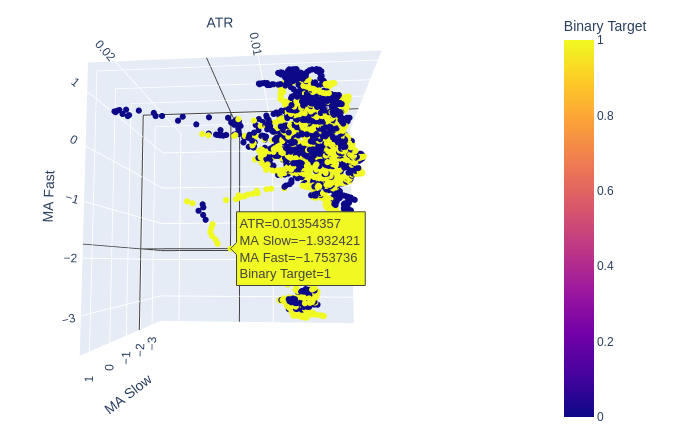
Рис. 9: Индикатор ATR, по-видимому, демонстрирует скопления бычьих и медвежьих ценовых движений. Однако кластеры невелики и могут возникать недостаточно часто, чтобы быть частью надежной торговой стратегии
Две скользящие средние и стохастический осциллятор вместе придают нашим рыночным данным новую структуру.
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
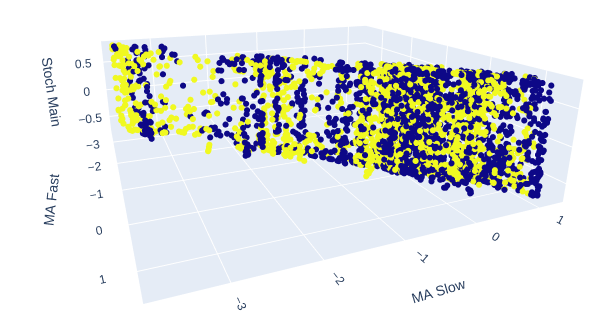
Рис. 10: Значение индикатора Stochastic Main и две скользящие средние дают несколько четко выраженных бычьих и медвежьих зон
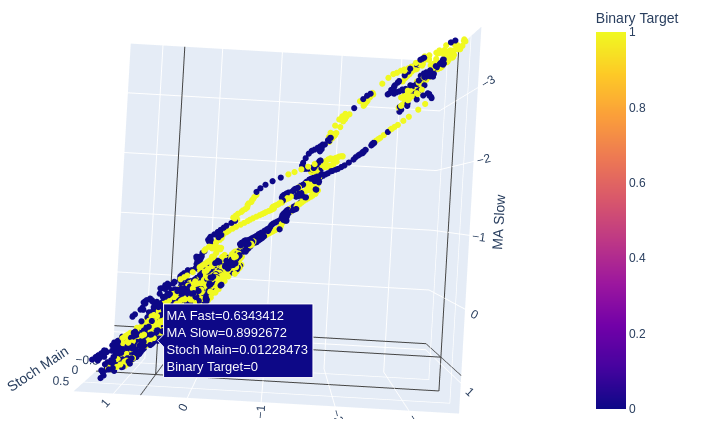
Рис. 11: Отношение между двумя скользящими средними и индикатором stochastic может лучше подходить для выявления бычьего ценового движения, чем медвежьего
При этом, мы используем 3 технических индикатора и 4 различных ценовых предложения, наши данные имеют 7 измерений, но мы можем визуализировать максимум 3 из них. Мы можем преобразовать наши данные всего в 2 столбца, используя методы снижения размерности. Метод главных компонент является популярным методом решения подобных задач. Мы можем использовать этот алгоритм для суммирования всех столбцов в нашем исходном наборе данных всего в 2 столбца.
Затем мы создадим диаграмму рассеяния из двух главных компонентов и определим, насколько хорошо они раскрывают для нас цель.
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()
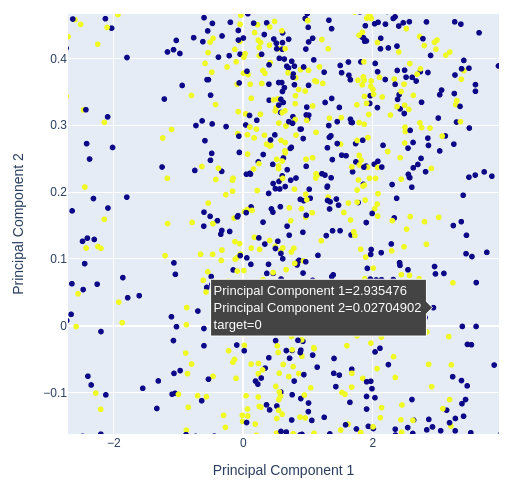
Рис. 12: Увеличение масштаба на случайной части нашей диаграммы рассеяния первых 2-х главных компонентов, чтобы увидеть, насколько хорошо они разделяют колебания цен
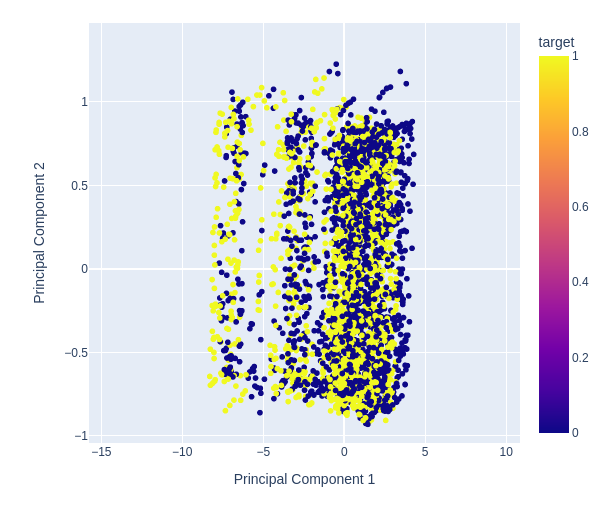
Рис. 13: Визуализация наших данных показывает, что PCA не улучшает разделение в наборе данных
Неконтролируемые алгоритмы обучения, такие как KMeansClustering, могут быть способны выявлять паттерны в данных, которые нам не очевидны. Алгоритм создаст метки для предоставленных ему данных без какой-либо информации о цели.
Идея заключается в том, что наш алгоритм кластеризации KMeans может извлечь 2 класса из нашего набора данных, что позволит хорошо разделить наши 2 класса. К сожалению, алгоритм KMeans на самом деле не оправдал наших ожиданий. Мы наблюдали как бычье, так и медвежье ценовое движение в обоих классах, сгенерированное алгоритмом на основе полученных данных.
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
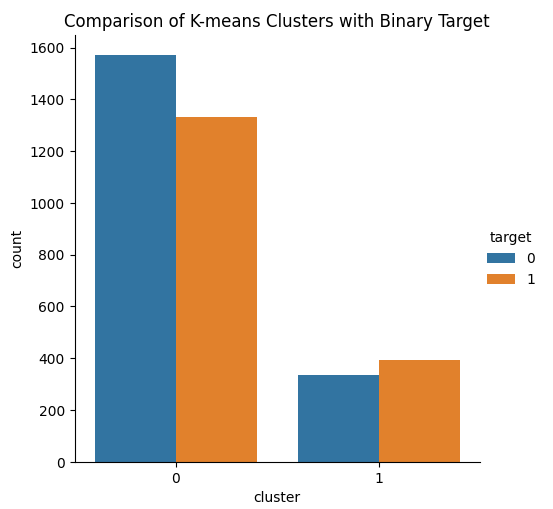
Рис. 14: Визуализация 2 кластеров, извлеченных нашим алгоритм KMeans из рыночных данных
Мы также можем провести испытание взаимосвязей между переменными, измерив корреляцию каждого входного сигнала с нашей целью. Ни одни из наших исходных данных не имеют сильных коэффициентов корреляции с нашей целью. Обратите внимание, что это не опровергает существование взаимосвязи, которую мы можем смоделировать.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
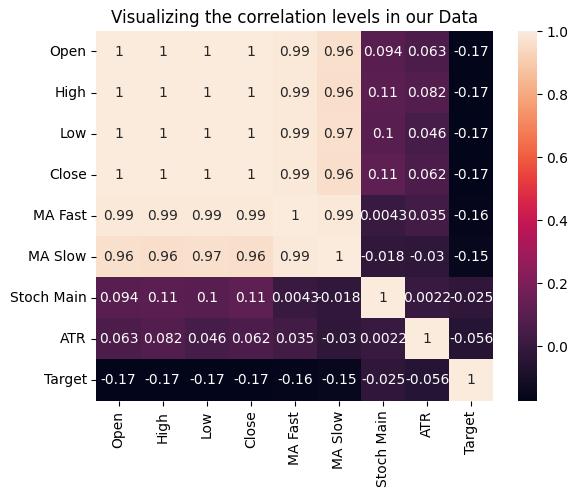
Рис. 15: Визуализация уровней корреляции в нашем наборе данных
Теперь преобразуем наши входные данные. У нас есть 3 формы, в которых мы можем использовать наши индикаторы:
- Текущее значение.
- Состояния Маркова.
- Разница между его прошлым значением.
Каждая форма имеет свой набор преимуществ и недостатков. Оптимальная форма представления данных будет варьироваться в зависимости от таких факторов, как: какой индикатор моделируется и на каком рынке индикатор применяется. Поскольку другого способа определить идеальный вариант нет, мы проведем поиск методом перебора по всем возможным вариантам для каждого индикатора.
Обратите внимание на столбец "Время" (Time) в нашем наборе данных. Обратите внимание, что наши данные относятся к периоду с 2010 по 2021 год. Это не совпадает с периодом, который мы будем использовать для нашего бэк-тестирования?
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
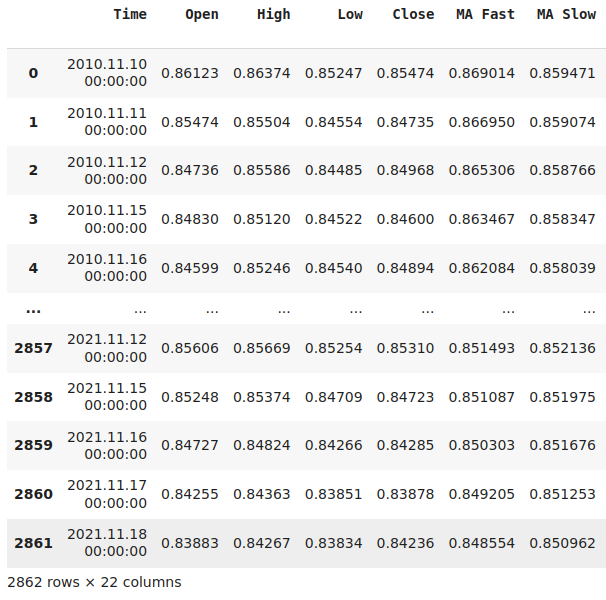
Рис. 16: Визуализация наших рыночных данных после их соответствующего преобразования
Давайте посмотрим, какая форма представления наиболее эффективна для нашей модели, чтобы узнать об изменении цены с учетом изменения наших индикаторов. В качестве выбранной нами модели мы будем использовать регрессионное дерево градиентного бустинга.
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Определим параметры нашей кросс-валидации временных рядов.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)Теперь установим пороговое значение. Любая модель, которую можно превзойти, просто используя цену закрытия для прогнозирования изменения цены, не является хорошей моделью.
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
В большинстве случаев мы всегда можем повысить эффективность работы, используя изменение цены, а не только снятие текущего значение цены.
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
Наша модель может работать еще лучше, если мы вместо этого предоставим стохастический осциллятор.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
Однако, неужели это лучшее, что мы можем сделать? Что произошло бы, если бы вместо этого мы внесли в нашу модель изменение стохастического осциллятора? Наша способность прогнозировать изменения цен становится все лучше!
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
Как вы думаете, что произойдет, если мы сейчас применим метод думми-кодирования? Мы создали 3 столбца, чтобы они просто указывали нам в каком состоянии находится индикатор. Количество наших ошибок сокращается. Этот результат очень интересен. Наши результаты намного лучше, чем у трейдера, который пытается предсказать изменения цены, учитывая текущую цену или текущие показания стохастического осциллятора. Но имейте в виду, что мы не знаем, верно ли это в отношении всех возможных рынков. Мы уверены, что это верно только для рынка EURGBP на дневном таймфрейме.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
Теперь оценим точность нашего прогнозирования изменений цены с помощью текущих показаний двух скользящих средних. Результаты выглядят не очень хорошо, частота наших ошибок выше, чем наша точность при использовании только цены закрытия для прогнозирования будущего изменения цены. От этой модели следует отказаться, она не пригодна для использования в реальных условиях.
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
Если мы преобразуем наши данные таким образом, чтобы видеть изменение значений скользящих средних, наши результаты станут лучше. Однако нам все равно будет лучше использовать более простую модель, которая просто использует текущую цену закрытия.
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
Однако, если применить метод думми-кодирования к рыночным данным, мы начнем опережать любого трейдера на том же рынке, используя обычные ценовые котировки на дневном таймфрейме. Частота наших ошибок снижается до новых минимумов, которые мы раньше не видели. Это мощное преобразование. Напомним, что это помогает модели в большей степени сосредоточиться на критических изменениях значения индикатора, в отличие от изучения точного отображения каждого возможного значения, которое может принять наш индикатор.
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
Для читателей, которые впервые знакомятся с этой темой, этот раздел особенно важен. Поскольку мы являемся человеческими существами, мы склонны видеть паттерны, даже если их не существует. То, что вы прочитали до сих пор, может оставить у вас впечатление, что думми-кодировка всегда является вашим лучшим другом. Но это не так. Понаблюдайте за тем, что происходит, когда мы пытаемся оптимизировать нашу окончательную модель ИИ, которая будет прогнозировать будущие показания ATR.
Не сравнивайте результаты, которые вы увидите сейчас, с результатами, которые мы только что обсуждали. Изменились единицы измерения цели. Таким образом, прямое сравнение между нашей точностью прогнозирования изменений цен и нашей точностью прогнозирования будущего значения ATR практически не имеет смысла.
По сути, мы создаем новое пороговое значение. Наша точность прогнозирования ATR с помощью предыдущих значений ATR является нашим новым базовым показателем. Любой метод, приводящий к большей погрешности, не является оптимальным и от него следует отказаться.
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
Пока что, сегодня мы заметили, что частота наших ошибок снижалась всякий раз, когда мы передавали нашей модели разницу в данных по сравнению с данными в их текущем виде. Однако на этот раз наша ошибка усугубилась.
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
Кроме того, мы выполнили думми-кодирование индикатора ATR, чтобы указать, повышался он или падал. Уровень наших ошибок по-прежнему оставался неприемлемым. Соответственно, мы будем использовать наш индикатор ATR таким, какой он есть, а стохастический осциллятор и наши скользящие средние будут закодированы фиктивно.
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
Экспортирование в ONNX
Open Neural Network Exchange (ONNX) — это протокол с открытым исходным кодом, определяющий универсальное представление для всех моделей машинного обучения. Это позволяет нам разрабатывать модели и обмениваться ими на любом языке при условии, что этот язык полностью поддерживает ONNX API. ONNX позволяет нам экспортировать только что разработанные нами модели ИИ и использовать их непосредственно в наших моделях ИИ для принятия торговых решений, в отличие от используемых фиксированных правил торговли.
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Определим входную форму каждой модели.
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
Обучим модель на всех имеющихся у нас данных.
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
Сохраним модели ONNX.
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
Реализация средствами MQL5
Мы будем использовать тот же торговый алгоритм, который мы разработали до сих пор. Мы всего лишь изменим установленные правила, которые мы изначально задали, и вместо этого дадим нашему торговому приложению совершать сделки всякий раз, когда наши модели дают нам четкий сигнал. Более того, мы начнем с импорта разработанных нами моделей ONNX.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
Теперь определим глобальные переменные, в которых будут храниться прогнозы нашей модели.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
Нам также необходимо обновить нашу процедуру деинициализации. Наша модель также должна освободить ресурсы, которые использовались нашими ONNX-моделями.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
Получение прогнозов с помощью наших моделей ONNX обходится не так дорого, как обучение моделей. Однако для быстрого бэк-тестирования наших торговых алгоритмов получение прогноза с помощью ИИ на каждом тике становится дорогостоящим. Наши бэк-тесты будут проходить намного быстрее, если мы будем получать прогнозы от наших моделей ИИ каждые 5 минут.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
Нам также необходимо обновить функцию, отвечающую за настройку наших технических индикаторов. Эта функция настроит наши модели ИИ и проверит корректность их загрузки.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
В нашем предыдущем торговом алгоритме мы просто открывали позиции до тех пор, пока индикаторы выравнивались для нас. Теперь мы вместо этого будем открывать свои позиции, если наши модели ИИ подадут нам четкий торговый сигнал. Кроме того, наши уровни тейк-профита и стоп-лосса будут динамически устанавливаться на ожидаемые уровни волатильности. Надеемся, что мы создали фильтр с использованием ИИ, который будет давать нам более прибыльные торговые сигналы.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Мы проведем наше бэк-тестирование в течение того же периода, который использовали ранее, с начала января 2022 года по июнь 2024 года. Напомним, что когда мы тренировали нашу модель ИИ, у нас не было никаких данных в диапазоне бэктеста. Мы будем проводить тестирование, используя один и тот же символ, пару EURGBP, на одном и том же таймфрейме, дневном таймфрейме.
Рис. 17: Бэк-тестирование нашей модели ИИ
Мы исправим все остальные параметры бэк-тестирования, чтобы наши тесты были по существу идентичны. По сути, мы пытаемся выделить разницу, возникающую благодаря тому, что наши решения принимаются с помощью моделей ИИ.
Рис. 18: Остальные параметры нашего бэк-теста
Наша торговая стратегия была более прибыльной в течение периода проведения теста! Это отличная новость, потому что моделям не были показаны данные, которые мы использовали при бэк-тестировании. Таким образом, мы можем иметь положительные ожидания при использовании этой модели для торговли на реальном счете.
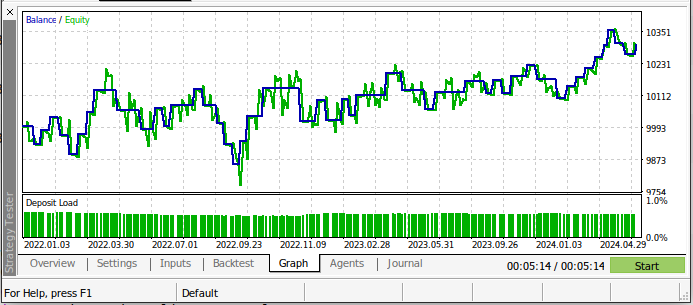
Рис. 19: Результаты бэк-тестирования нашей модели ИИ за все время тестирования
В ходе бэк-тестирования на основе новой модели было заключено меньше сделок, но доля выигрышных сделок в ней была выше, чем в нашем старом торговом алгоритме. Кроме того, наш коэффициент Шарпа теперь положительный, и только 44% наших сделок были убыточными.
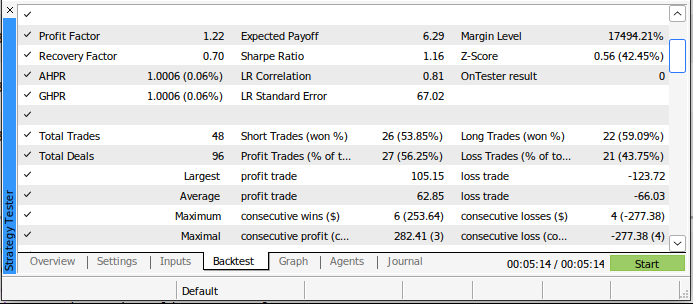
Рис. 20: Подробные результаты бэк-тестирования нашей торговой стратегии на базе ИИ
Заключение
Надеюсь, прочитав эту статью, вы согласитесь со мной, что ИИ действительно можно использовать для улучшения наших торговых стратегий. Даже самая старая классическая торговая стратегия может быть переосмыслена с помощью ИИ и доведена до нового уровня эффективности. Похоже, весь фокус заключается в разумном преобразовании данных ваших индикаторов, чтобы помочь моделям эффективно обучаться. Сегодня нам очень помог продемонстрированный нами метод думми-кодирования. Но мы не можем сделать вывод, что это лучший выбор на всех возможных рынках. Вполне возможно, что метод думми-кодирования может оказаться лучшим выбором, который у нас есть для определенной группы рынков. Однако мы можем с уверенностью заключить, что пересечение скользящих средних может быть эффективно изменено с помощью ИИ.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16280
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Спасибо Гаму. Мне нравятся ваши публикации, и я стараюсь учиться, воспроизводя ваши шаги.
У меня есть некоторые проблемы, надеюсь, это может помочь другим.
1) мои тесты с вашим EURGBP_Stochastic daily с использованием предоставленного скрипта дают только 2 ордера и впоследствии Sharpe ration 0.02. Я полагаю, что у меня те же настройки, что и у вас, но на 2 брокерах он выдает только 2 ордера.
2) в качестве предупреждения для других, вам может понадобиться изменить настройки символа в соответствии с вашим брокером (например, EURGBP на EURGBP.i), если это необходимо
3) далее, когда я пытаюсь экспортировать данные, я получаю массив вне диапазона для ATR, я полагаю, это потому, что я не получаю 100000 записей в мой массив (если я изменю его на 677), я могу соответственно получить файл с 677 строками. для меня по умолчанию максимальное количество баров на графике составляет 50000, если я изменю это на 100000, мой размер массива составляет только 677, но, возможно, у меня плохая настройка. Может быть, вы могли бы также включить скрипт извлечения данных в вашу загрузку.
4)Я скопировал код из вашей статьи, чтобы попробовать в Python Я получаю ошибку look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: имя 'look_ahead' не определено
5) когда я загрузил ваш блокнот Juypiter, я обнаружил, что в нем нужно установить опережающий прогноз #Let us forecast 20 steps into future
look_ahead = 20 , После этого я использовал только ваш включенный файл, но я застрял на следующей ошибке, возможно, связанной с тем, что у меня всего 677 строк.
Я запускаю #Масштабирование данных перед тем, как мы начнем их визуализировать
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
что дает ошибку, которую я не понимаю, как решить
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Значение пытается быть установлено на копии фрагмента из DataFrame. Попробуйте вместо этого использовать .loc[row_indexer,col_indexer] = value См. предостережения в документации: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Спасибо Гаму. Я наслаждаюсь вашими публикациями и стараюсь учиться, воспроизводя ваши шаги.
У меня возникли некоторые проблемы, надеюсь, это поможет другим.
1) мои тесты с вашим EURGBP_Stochastic daily с использованием предоставленного скрипта дают только 2 ордера и впоследствии Sharpe ration 0.02. Я считаю, что у меня те же настройки, что и у вас, но на 2 брокерах он выдает только 2 ордера.
2) в качестве предупреждения для других, вам может потребоваться изменить настройки символа в соответствии с вашим брокером (например, EURGBP на EURGBP.i), если это необходимо.
3) далее, когда я пытаюсь экспортировать данные, я получаю массив вне диапазона для ATR, я полагаю, это потому, что я не получаю 100000 записей в мой массив (если я изменю его на 677), я могу соответственно получить файл с 677 строками. для меня по умолчанию максимальное количество баров на графике составляет 50000, если я изменю это на 100000, мой размер массива составляет только 677, но, возможно, у меня плохая настройка. Может быть, вы могли бы также включить скрипт извлечения данных в вашу загрузку.
4)Я скопировал код из вашей статьи, чтобы попробовать в Python Я получаю ошибку look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: имя 'look_ahead' не определено
5) когда я загрузил ваш блокнот Juypiter, я обнаружил, что в нем нужно установить параметр look ahead #Let us forecast 20 steps into future
look_ahead = 20 , После этого я использовал только ваш включенный файл, но я застрял на следующей ошибке, возможно, связанной с тем, что у меня всего 677 строк.
Я запускаю #Масштабирование данных, прежде чем мы начнем их визуализировать
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
что выдает ошибку, которую я не понимаю, как решить
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Значение пытается быть установлено на копии фрагмента из DataFrame. Попробуйте вместо этого использовать .loc[row_indexer,col_indexer] = value См. предостережения в документации: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Как дела, Нил, надеюсь, у тебя все хорошо.
Спасибо, Gamu, я ценю это, да, я знаю, что есть много движущихся частей, я посмотрю, решит ли это мои проблемы.
Спасибо, Gamu Ценю это, да я знаю, что есть много движущихся частей, я посмотрю, если это решит мои проблемы