
Преодоление ограничений машинного обучения (Часть 1): Нехватка совместимых метрик

К сожалению, опасности слепого следования «лучшим практикам» молчаливо портят другие инструменты, на которые мы полагаемся в наших торговых стратегиях, и практикам не следует думать, что эта проблема свойственна только для технических индикаторов.
В данной серии статей мы рассмотрим критические проблемы, с которыми ежедневно сталкиваются алгоритмические трейдеры, вызванные именно рекомендациями и практиками, призванными обеспечить их безопасность при использовании моделей машинного обучения. Короче говоря, если модели машинного обучения, ежедневно развертываемые в облаке MQL5, будут знать представленные в этом обсуждении факты, опережая ответственных практиков, то проблемы неизбежны. Инвесторы могут быстро обнаружить, что подвергаются большему риску, чем они ожидали.
Честно говоря, этим проблемам не уделяется достаточного внимания даже в ведущих мировых книгах по статистическому обучению. Предметом нашего обсуждения является простая истина, которую должен знать каждый практик в нашем сообществе:
«Можно аналитически доказать, что первая производная Евклидовых метрик дисперсии, таких как RMSE, MAE или MSE, может быть решена с помощью среднего значения цели».
Тем, кто уже знаком с этим фактом и его последствиями, нет нужды читать дальше.
Однако именно для тех практиков, которые не понимают, что это значит, мне необходимо срочно донести эту статью. Вкратце, используемые нами для построения наших моделей регрессионные метрики не подходят для моделирования доходности активов.
В настоящей статье вы узнаете, как это происходит, какие опасности это для вас представляет и какие изменения вы можете осуществить, чтобы начать использование этого принципа в качестве компаса для фильтрации рынков, имея на выбор сотни потенциальных рынков, на которых вы можете торговать.
Практики, желающие получить более глубокие доказательства, могут найти литературу Гарвардского университета, в которой обсуждаются ограничения таких метрик, как RMSE. В частности, в гарвардской статье представлено аналитическое доказательство того, что среднее значение выборки минимизирует среднеквадратичную ошибку. Читатель может найти статью, ссылка на которую находится здесь.
Другие учреждения, такие как Исследовательская сеть социальных наук (SSRN), ведут журнал опубликованных и рецензируемых статей из различных областей, включая статью, нужную для нашего обсуждения, в которой исследуются альтернативные функции потерь для замены среднеквадратичной ошибки (RMSE) в задачах ценообразования активов. В статье, которую я выбрал для читателя, рассматривается ряд других работ в этой области, а также предлагается краткий обзор современной литературы, после чего демонстрируется новый подход. Эту статью читатель может легко найти здесь.
Мысленный эксперимент (это должен понять каждый)
Представьте, что вы участвуете в соревновании типа лотереи. Вы и 99 других человек случайным образом выбраны для игры за джекпот в размере 1 000 000 долларов. Правила просты: вам необходимо угадать рост остальных 99 участников. Победителем становится тот, у кого будет наименьшая общая ошибка среди 99 попыток.
А теперь немного неожиданно: для этого примера представьте, что средний рост человека в мире составляет 1,1 метра. Если вы просто предположите вариант 1,1 метра для каждого, вы действительно можете выиграть джекпот, даже если каждое предсказание технически неверно. И почему же? Потому что в шумной, неопределенной обстановке угадывание среднего значения, как правило, дает наименьшую общую ошибку.
Параллель в трейдинге
Целью этого мысленного эксперимента было наглядно продемонстрировать читателю, как именно отбирается большинство моделей машинного обучения для использования на финансовых рынках.
Например, предположим, что вы создаете модель для прогнозирования доходности индекса S&P 500. Модель, которая всегда предсказывает историческое среднее значение индекса, примерно 7% в год, фактически может превзойти более сложные модели, если оценивать по таким показателям, как RMSE, MAE или MSE. Но здесь кроется ловушка: Эта модель не научилась ничему полезному. Она просто группировалась вокруг статистического среднего значения. И что еще хуже, метрики и процедуры проверки, которым вы доверяли, вознаграждали вас за это.
Примечание для начинающих: RMSE (среднеквадратическая ошибка) — это «единица», используемая для оценки качества моделей машинного обучения, обучающихся прогнозировать реальные значимые цели.
Она наказывает за большие отклонения, но не заботится о том, почему модель допустила ошибку. Однако помните, что некоторые из этих отклонений, за которые модель наказывается, на самом деле приносили прибыль.
Таким образом, модель, которая всегда предсказывает среднее значение (даже если у нее нет никакого понимания рынка), может отлично выглядеть на бумаге, если оценивать ее с помощью среднеквадратичной ошибки. К сожалению, это позволяет нам создавать модели, которые математически обоснованы, но практически бесполезны.
Что происходит на самом деле
Финансовые данные зашумлены. Мы не можем наблюдать такие ключевые переменные, как истинное глобальное соотношение спроса и предложения, настроения инвесторов или институциональную глубину книги заказов. Таким образом, чтобы минимизировать ошибку, ваша модель будет делать наиболее статистически логичное действие: предсказывать среднее значение.
И читатель должен понимать, что с математической точки зрения это разумная практика. Прогнозирование среднего значения минимизирует наиболее распространенные ошибки регрессии. Но суть торговли заключается не в минимизации статистической погрешности, а в принятии прибыльных решений в условиях неопределенности. И это различие имеет значение. В нашем сообществе такое поведение можно сравнить с переобучением, но статистики, построившие эти модели, видели вещи не так, как мы.
Было бы наивно полагать, что эта проблема свойственна только регрессионным моделям. В задачах классификации модель может минимизировать ошибки, просто всегда предсказывая наиболее распространенный класс в обучающей выборке. И если так уж получилось, что наибольший класс в обучающем наборе соответствует наибольшему классу во всей популяции, я считаю, что практикующий специалист может быстро увидеть, как модель может легко имитировать свои навыки.
Хакерство с целью получения вознаграждения: когда модели выигрывают за счет обмана
Это явление называется «хакерством с целью получения вознаграждения»: модель достигает желаемого уровня эффективности, обучаясь нежелательному поведению. В случае трейдинга хакерство с целью получения вознаграждения приводит к тому, что специалисты выбирают модель, которая кажется профессиональной, но на самом деле эта модель просто играет в игру средних значений, представляя собой статистический карточный домик. Вы думаете, что она чему-то научилась, но на самом деле она сделала статистический эквивалент утверждения «рост всех людей составляет 1,1 метра». И RMSE принимает это каждый раз без вопросов.
Реальные доказательства
Теперь, когда наша мотивация ясна, давайте отойдем от использования аллегорий и вместо этого рассмотрим реальные рыночные данные. Используя MetaTrader 5 Python API, я получил доступ к 333 рынкам от своего брокера. Мы отфильтровали рынки, по которым имелись реальные исторические данные не менее чем за четыре года. Этот фильтр сократил число наших рынков до 119.
Затем мы построили две модели для каждого рынка:
- Модель управления: Всегда прогнозирует среднюю 10-дневную доходность.
- Модель прогнозирования: Пытается изучить и предсказать будущие доходы.
Наши результаты
На 91,6% протестированных нами рынков победу одержала модель управления. Другими словами, модель, всегда предсказывающая историческую среднюю доходность за 10 дней, допускала меньшую ошибку за период в 4 года, в 91% времени! Как вскоре увидят практикующие специалисты, даже когда мы попробовали более глубокие нейронные сети, улучшение было незначительным.
Поэтому должен ли специалист следовать «лучшим практикам» машинного обучения и всегда выбирать модель, обеспечивающую наименьшую ошибку, и при этом помнить, всегда ли модель предсказывает среднюю доходность?
Примечание для начинающих: Это не значит, что машинное обучение не может вам помочь. Это значит, что вам следует быть крайне осторожным в отношении того, как следует определять «хорошую эффективность» в контексте вашей торговли. Если вы не будете осторожны, было бы разумно ожидать, что вы можете неосознанно выбрать модель, получающую вознаграждение за прогнозирование средней доходности рынка.
И что теперь?
Вывод очевиден: используемые нами в настоящее время метрики оценки — RMSE, MSE, MAE — не предназначены для торговли. Они появились в статистике, медицине и других естественных науках, где прогнозирование среднего значения имеет смысл. Но в нашем сообществе алгоритмической торговли прогнозирование средней доходности иногда может быть даже хуже, чем полное отсутствие прогноза; полное отсутствие ИИ иногда даже безопаснее. Но ИИ без понимания никогда не будет безопасным!
Нам нужны фреймворки оценки, которые поощряют полезные навыки, а не статистические показатели сотрудничества. Нам нужны показатели, учитывающие прибыль и убытки. Кроме того, нам нужны протоколы обучения, наказывающие за «привязывание» к среднему значению, процедуры, поощряющие модель следовать ценностям нашего сообщества, изучая при этом реалии торговли. И именно этому посвящена данная серия. Уникальный набор задач, которые не генерируются рынком напрямую. Скорее, они вытекают из тех самых инструментов, которые мы хотим использовать, и редко обсуждаются в других статьях, академических книгах по статистическому обучению или даже в обсуждениях нашего сообщества.
Практикующим специалистам необходимо хорошо знать эти факты ради собственной безопасности. К сожалению, элементарная осведомленность об этих ограничениях не является общеизвестной и общедоступной для каждого участника нашего сообщества. Ежедневно практикующие специалисты без колебаний повторяют весьма опасные статистические приемы.
Начинаем
Давайте посмотрим, есть ли хоть какая-то польза в том, что мы обсуждали до сих пор. Загрузим наши стандартные библиотеки.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import MetaTrader5 as mt5 import multiprocessing as mp
Определим, насколько далеко в будущее мы хотим заглянуть в нашем прогнозе.
HORIZON = 10Загрузим терминал MetaTrader 5, чтобы иметь возможность получать реальные рыночные данные.
if(not mt5.initialize()): print("Failed to load MT5")
Получите полный список всех доступных символов.
symbols = mt5.symbols_get()
Просто извлечём названия символов.
symbols[0].name
symbol_names = []
for i in range(len(symbols)):
symbol_names.append(symbols[i].name)Теперь подготовимся проверить, сможем ли мы превзойти модель, всегда предсказывающую среднее значение.
from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Создадим разделитель для проверки временных рядов.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)Нам нужен метод, который будет возвращать наши уровни ошибок при прогнозировании средней рыночной доходности и наши уровни ошибок при попытке прогнозирования будущей рыночной доходности.
def null_test(name): data_amount = 365 * 4 f_data = pd.DataFrame(mt5.copy_rates_from_pos(name,mt5.TIMEFRAME_D1,0,data_amount)) if(f_data.shape[0] < data_amount): print(f"{symbol_names[i]} did not have enough data!") return(None) f_data['time'] =pd.to_datetime(f_data['time'],unit='s') f_data['target'] = f_data['close'].shift(-HORIZON) - f_data['close'] f_data.dropna(inplace=True) model = Ridge() res = [] res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open']] * 0,f_data['target'],cv=tscv)))) res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open','high','low','close']],f_data['target'],cv=tscv)))) return(res)
Теперь проведем тестирование на всех доступных нам рынках.
res = pd.DataFrame(columns=['Mean Forecast','Direct Forecast'],index=symbol_names) for i in range(len(symbol_names)): test_score = null_test(symbol_names[i]) if(test_score is None): print(f"{symbol_names[i]} does not have enough data!") res.iloc[i,:] = [np.nan,np.nan] continue res.iloc[i,0] = test_score[0] res.iloc[i,1] = test_score[1] print(f"{i/len(symbol_names)}% complete.") res['Score'] = ((res.iloc[:,1] / res.iloc[:,0])) res.to_csv("Deriv Null Model Test.csv")
Выполнено 0,06606606606606606%.
Выполнено 0,06906906906906907%.
Выполнено 0,07207207207207207%.
...
У индекса нисходящего тренда GBPUSD RSI было недостаточно данных!
У индекса нисходящего тренда GBPUSD RSI недостаточно данных!
Из всех доступных нам рынков сколько нам удалось проанализировать?
#How many markets did we manage to investigate? test = pd.read_csv("Null Model Test.csv") print(f"{(test.dropna().shape[0] / test.shape[0]) * 100}% of Markets Were Evaluated")
35,73573573573574% рынков были оценены
Теперь сгруппируем наши 119 рынков на основе оценки, присвоенной каждому рынку. Оценка будет представлять собой отношение нашей ошибки при прогнозировании рынка к нашей ошибке при постоянном прогнозировании средней доходности. Результаты ниже 1 впечатляют, поскольку означают, что мы превзошли модель, всегда предсказывающую среднюю доходность. В противном случае показатели выше 1 подтверждают нашу мотивацию для проведения этого упражнения в свете того, о чем мы поделились во введении к настоящей статье.
Примечание для начинающих: Кратко описанный нами метод оценки показателей не является чем-то новым в области машинного обучения. Это метрика, широко известная как r-квадрат. Он показывает нам, какую часть дисперсии целевого показателя мы объясняем с помощью предлагаемой нами модели. Мы не используем точную формулу r-квадрата, с которой вы, возможно, знакомы из собственных независимых исследований.
Сначала сгруппируем все рынки, где мы получили показатель меньше 1.
res.loc[res['Score'] < 1]
| Название рынка | Прогноз среднего значения | Прямой прогноз | Показатель |
|---|---|---|---|
| AUDCAD | 0.022793 | 0.018566 | 0.814532 |
| EURCAD | 0.037192 | 0.027209 | 0.731587 |
| NZDCAD | 0.019124 | 0.015117 | 0.790466 |
| USDCNH | 0.125586 | 0.112814 | 0.898297 |
На каком проценте всех протестированных нами рынков мы превзошли модель, всегда предсказывающую среднюю доходность рынка, за 4 года? Примерно 8%.
res.loc[res['Score'] < 1].shape[0] / res.shape[0]
0.08403361344537816
Таким образом, это также означает, что за 4 года мы не смогли превзойти модель, всегда предсказывающую среднюю доходность примерно для 91,6% всех протестированных нами рынков.
res.loc[res['Score'] > 1].shape[0] / res.shape[0]
0.9159663865546218
На этом этапе некоторые читатели могут подумать: «Автор использовал простые линейные модели, а если бы мы не торопились и построили более гибкие модели, то всегда могли бы превзойти модель, предсказывающую среднюю доходность. Это чушь». Что частично верно. Давайте построим глубокую нейронную сеть на рынке EURUSD, которая превзойдет модель, прогнозирующую среднюю доходность рынка.
Во-первых, нам понадобится скрипт MQL5 для сбора подробной рыночной информации о курсе EURUSD. Мы зафиксируем рост каждого из четырех уровней цен, а также их рост относительно друг друга.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " IID Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; input int HORIZON = 10; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta Open","Delta High","Delta Low","Delta Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Теперь перетащите свой скрипт на график, чтобы получить исторические данные о рынке, и затем мы можем начать.
#Read in market data HORIZON = 10 data = pd.read_csv('EURUSD IID Candlestick Recognition.csv') #Label the data data['Null'] = 0 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last HORIZON rows of data data = data.iloc[:-HORIZON,:] data
Читатели, считающие, что глубокие нейронные сети и сложные модели решат проблему превосходства модели, предсказывающей среднюю доходность рынка, будут шокированы, прочитав то, что последует далее в этой статье.
Прежде чем внедрять свои модели с использованием своего капитала, рекомендую вам повторить этот эксперимент со своим брокером. Теперь загрузим инструменты scikit learning, чтобы сравнить, насколько хорошо наша глубокая нейронная сеть работает с нашей простой линейной моделью.
#Load our models from sklearn.neural_network import MLPRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,train_test_split,cross_val_score
Разделим данные.
#Split the data into half train,test = train_test_split(data,test_size=0.5,shuffle=False)
Создадим объект для проверки временных рядов.
#Create a time series validation object tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)
Подберите модель, всегда предсказывающую среднюю доходность рынка. Ошибка, вызванная постоянным прогнозированием среднего значения, называется «общей суммой квадратов» (TSS). TSS — это критический критерий погрешности в машинном обучении, он сообщает нам, где находится север.
#Fit the model predicting the mean on the train set null_model = Ridge() null_model.fit(train[['Null']],train['Target']) tss = np.mean(np.abs(cross_val_score(null_model,test[['Null']],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) tss
np.float64(0.011172426520738554)
Определим наши входные данные и цель.
X = data.iloc[:,4:-2].columns y = 'Target'
Настройте свою глубокую нейронную сеть. Я призываю читателя свободно настраивать эту нейронную сеть по своему усмотрению, чтобы увидеть, есть ли в ней то, что нужно, чтобы превзойти среднее значение.
#Let us now try to outperform the null model model = MLPRegressor(activation='logistic',solver='lbfgs',random_state=0,shuffle=False,hidden_layer_sizes=(len(X),200,50),max_iter=1000,early_stopping=False) model.fit(train.loc[:,X],train['Target']) rss = np.mean(np.abs(cross_val_score(model,test.loc[:,X],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) print(f"Test Passed: {rss < tss} || New R-Squared Metric {rss/tss}") res = [] res.append(rss) res.append(tss) sns.barplot(res,color='black') plt.axhline(tss,color='red',linestyle=':') plt.grid() plt.ylabel("RMSE") plt.xticks([0,1],['Deep Neural Network','Null Model']) plt.title("Our Deep Neural Network vs The Null Model") plt.show()
После множества настроек, корректировок и оптимизаций мне удалось победить предсказывающую среднюю доходность модель с помощью глубокой нейронной сети. Однако давайте подробнее рассмотрим, что здесь происходит.

Рис. 1: Превзойти предсказывающую среднюю рыночную доходность модель — задача не из легких
Давайте наглядно представим улучшения, которые вносит наша глубокая нейронная сеть. Сначала я создам сетку, с помощью которой мы сможем оценить распределение доходности рынка в тестовом наборе, а также распределение доходности, предсказанной нашей моделью. Сохраним доходность, предсказанную моделью для тестового набора.
predictions = model.predict(test.loc[:,X])
Начнем с того, что обозначим среднюю рыночную доходность, которую мы наблюдали в обучающем наборе, как красную пунктирную линию в середине схемы.
plt.title("Visualizing Our Improvements")
plt.plot()
plt.grid()
plt.xlabel("Return")
plt.axvline(train['Target'].mean(),color='red',linestyle=':')
legend = ['Train Mean']
plt.legend(legend)
Рис. 2: Визуализация средней рыночной доходности на основе обучающего набора
Теперь наложим прогноз модели для тестового набора на среднюю доходность обучающего набора. Как видит читатель, прогнозы модели распределены вокруг среднего значения обучающего набора. Однако проблема становится очевидной, когда мы наконец накладываем истинное распределение, которому следовал рынок, в виде черного графика ниже.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(predictions,color='blue') legend = ['Train Mean','Model Predictions'] plt.legend(legend)
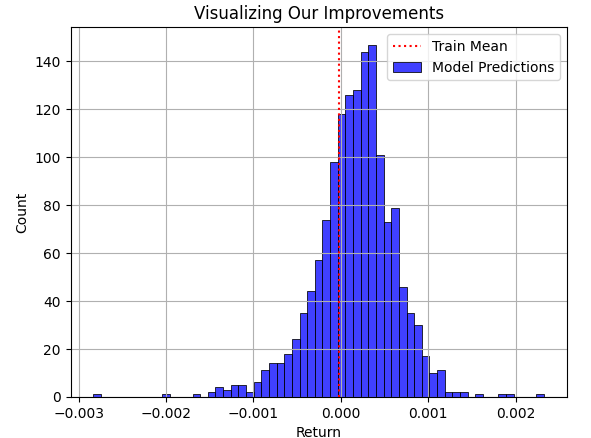
Рис. 3: Визуализация прогнозов нашей модели относительно средней доходности, наблюдаемой моделью в обучающем наборе
Синяя область прогнозов, сделанных нашей моделью, выглядит разумной на рис. 3, но когда мы наконец рассматриваем истинное распределение, которому следовал рынок на рис. 4, становится очевидным, что эта модель не подходит для поставленной задачи. Модель не в состоянии охватить всю ширину истинного распределения рынка, где некоторые из крупнейших прибылей и убытков скрываются от внимания нашей модели. К сожалению, RMSE часто будет указывать практикам на такие модели, если метрика RMSE не будет должным образом понята, уважаться и интерпретироваться ответственным практикующим специалистом. Использование такой модели в реальной торговле будет иметь катастрофические последствия для вашего опыта торговли в реальном времени.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(test['Target'],color='black') sns.histplot(predictions,color='blue') legend = ['Train Mean','Test Distribution','Model Prediction'] plt.legend(legend)
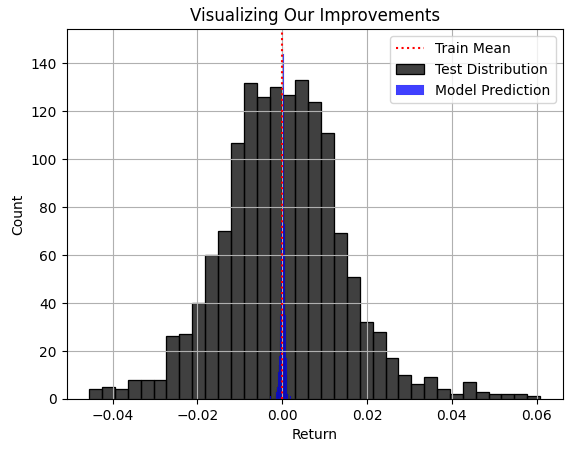
Рис. 4: Визуализация распределения прогнозов наших моделей относительно истинного распределения рынка
Предлагаемое нами решение
На этом этапе мы продемонстрировали читателю, что такие показатели, как RMSE, можно легко оптимизировать, всегда прогнозируя среднюю доходность рынка, и мы продемонстрировали, почему это непривлекательно, поскольку RMSE часто может сообщать нам, что такая бесполезная модель — это лучшее, что мы можем сделать. Мы выразили очевидную потребность в процедурах и новых методах, которые четко:
- Тестируют реальное понимание рынка.
- Понимают разницу между прибылью и убытком.
- Препятствуют поведению «привязывания».
Я хотел бы предложить уникальную архитектуру модели, которая могла бы стать возможным решением, которое читатель может рассмотреть. Я называю эту стратегию «Моделями динамического переключения режимов» или сокращенно DRS. В отдельном обсуждении высоковероятностных конфигураций мы отметили, что моделирование прибыли/убытка, генерируемых торговой стратегией, может быть проще, чем попытка прямого прогнозирования рынка. Читатели, которые еще не читали эту статью, могут найти ссылку на нее здесь.
Теперь мы продолжим использовать это наблюдение интересным образом. Мы разработаем две идентичные модели, чтобы моделировать противоположные версии одной торговой стратегии. Одна модель всегда предполагает, что рынок находится в состоянии следования за трендом, тогда как последняя всегда предполагает, что рынок находится в состоянии возврата к среднему значению. Каждая модель будет обучаться отдельно и не будет иметь никакой осведомленности или средств для координации своих прогнозов с другой моделью.
Читателю следует помнить, что гипотеза эффективного рынка учит инвесторов тому, что покупка и продажа одинаковых объемов одного и того же актива позволит инвестору полностью захеджировать свои риски, а если обе позиции открываются и закрываются одновременно, общая прибыль равна 0, не включая какие-либо транзакционные комиссии. Следовательно, мы должны ожидать, что наши модели всегда будут согласовываться с этим фактом. Фактически, мы можем проверить, соответствуют ли наши модели этой истине. Модели, не соответствующие этой истине, не имеют истинного понимания рынка.
Таким образом, мы можем отказаться от необходимости полагаться на такие показатели, как RMSE, и начать проверять, демонстрирует ли наша модель DVM понимание этого принципа, формирующего структуру рынка. Вот здесь-то и вступает в игру наш тест на понимание реального рынка. Если обе наши модели действительно понимают реалии торговли, то сумма их прогнозов всегда должна равняться 0, в любое время. Мы обучим наши модели на обучающем наборе, а затем протестируем их вне выборки, чтобы увидеть, всегда ли сумма прогнозов модели равна 0, даже если модели недостаточно нагружены.
Напомним, что прогнозы моделей никаким образом не координируются, ни в каком виде или форме. Модели обучаются отдельно и не имеют никакой информации друг о друге. Таким образом, если модели не «взламывают» желаемые показатели ошибок, а действительно изучают базовую структуру рынка, то они докажут, что пришли к своим прогнозам посредством этического поведения, если сумма обоих прогнозов модели равна 0.
Только одна из этих моделей может рассчитывать на положительное вознаграждение в любой момент времени. Если сумма прогнозов нашей модели не равна 0, то, возможно, в модели непреднамеренно заложена направленная предвзятость, нарушающая гипотезу эффективного рынка. В противном случае, при лучшем сценарии, мы сможем динамически переключаться между этими двумя состояниями рынка с уровнем уверенности, с которым мы не были знакомы в прошлом. Только одна модель может рассчитывать на положительную прибыль в любой момент времени, и наша торговая философия заключается в том, что мы считаем, что модель соответствует скрытому состоянию, в котором в данный момент находится рынок. И это потенциально может быть для нас более ценным, чем низкие показания RMSE.
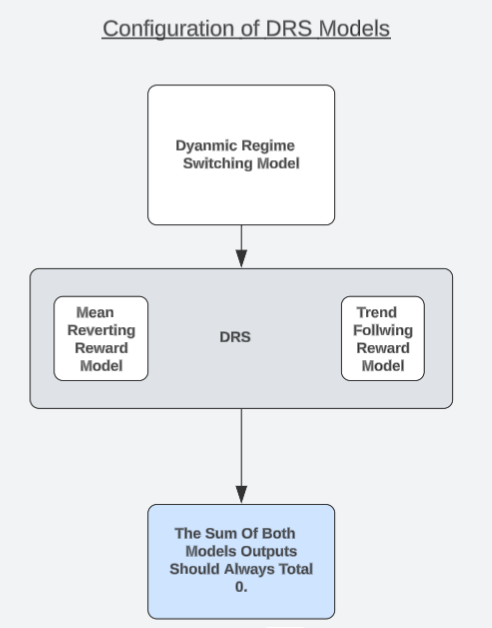
Рис. 5: Понимание общей архитектуры наших моделей DRS
Получение данных из нашего терминала
Для достижения наилучших результатов наши данные должны быть максимально подробными. Поэтому мы отслеживаем текущие значения наших технических индикаторов и уровни цен, а также рост, который происходит в динамике рынка в то же время.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 10 //--- Our handlers for our indicators int ma_handle; //--- Data structures to store the readings from our indicators double ma_reading[]; //--- File name string file_name = Symbol() + " DRS Modelling.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta O","Delta H","Delta Low","Delta Close","SMA 5","Delta SMA 5"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), ma_reading[i], ma_reading[i] - ma_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Начинаем
Для начала импортируем наши стандартные библиотеки.
#Load our libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Теперь мы можем прочитать данные, которые мы ранее записали в CSV.
#Read in the data data = pd.read_csv("/content/drive/MyDrive/Colab Data/Financial Data/FX/EUR USD/DRS Modelling/EURUSD DRS Modelling.csv") data
При создании нашего скрипта на MQL5 мы прогнозировали будущее на 10 шагов. Необходимо это сохранить.
#Recall that in our MQL5 Script our forecast horizon was 10 HORIZON = 10 #Calculate the returns generated by the market data['Return'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last horizon rows data = data.iloc[:-HORIZON,:]
Теперь выполним разметку данных. Напомним, что у нас будет 2 метки: одна всегда предполагает, что рынок продолжит движение в тренде, а другая всегда предполагает, что рынок застрял в состоянии возврата к среднему значению.
#Now let us define the signals being generated by the moving average, in the DRS framework there are always at least n signals depending on the n states the market could be in #Our simple DRS model assumes only 2 states #First we will define the actions you should take assuming the market is in a trending state #Therefore if price crosses above the moving average, buy. Otherwise, sell. data['Trend Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Trend Action'] = 1 data.loc[data['Close'] < data['SMA 5'], 'Trend Action'] = -1 #Now calculate the returns generated by the strategy data['Trend Profit'] = data['Trend Action'] * data['Return']
После разметки следующих за трендом действий вставьте действия, возвращающиеся к среднему значению.
#Now we will repeat the procedure assuming the market was mean reverting data['Mean Reverting Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Mean Reverting Action'] = -1 data.loc[data['Close'] < data['SMA 5'], 'Mean Reverting Action'] = 1 #Now calculate the returns generated by the strategy data['Mean Reverting Profit'] = data['Mean Reverting Action'] * data['Return']
Помечая данные таким образом, мы надеемся, что компьютер определит условия, при которых каждая стратегия теряет деньги, и когда следует прислушиваться к каждой стратегии. Если мы построим график совокупного целевого значения, то ясно увидим, что за выбранный период времени в наших данных рынок EURUSD больше времени демонстрировал возврат к среднему значению, чем следование тренду. Однако обратите внимание, что на обеих линиях присутствуют внезапные толчки. Я считаю, что эти толчки могут соответствовать внезапным изменениям режима на рынке.
#If we plot our cumulative profit sums, we can see the profit and losses aren't evenly distributed between the two states plt.plot(data['Trend Profit'].cumsum(),color='black') plt.plot(data['Mean Reverting Profit'].cumsum(),color='red') #The mean reverting strategy appears to have been making outsized profits with respect to the trending stratetefgy #However, closer inspection reveals, that both strategies are profitable, but never at the same time! #The profit profiles of both strategies show abrupt shocks, when the opposite strategy become more profitable. plt.legend(['Trend Profit','Mean Reverting Profit']) plt.xlabel('Time') plt.ylabel('Profit/Loss') plt.title('A DRS Model Visualizes The Market As Being in 2 Possible States') plt.grid() plt.axhline(0,color='black',linestyle=':')
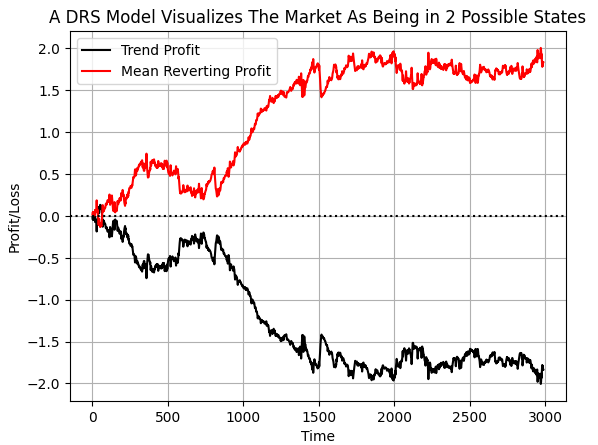
Рис. 6: Визуализация распределения прибыли по двум противоположным стратегиям
Определите свои входные данные и цель.
#Let's define the inputs and target X = data.iloc[:,1:-5].columns y = ['Trend Profit','Mean Reverting Profit']
Выберем наши инструменты для моделирования рынка.
#Import the modelling tools from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.ensemble import RandomForestRegressor
Разделим данные дважды. Таким образом, у нас есть обучающий набор, валидационный набор и окончательный тестовый набор.
#Split the data train , test = train_test_split(data,test_size=0.5,shuffle=False) f_train , f_validation = train_test_split(train,test_size=0.5,shuffle=False)
Подготовим сейчас наши 2 модели. Напомним, что обе модели дадут нам двойной взгляд на мир, но они не должны каким-либо образом координироваться.
#The trend model trend_model = RandomForestRegressor() #The mean reverting model mean_model = RandomForestRegressor()
Обучим наши модели.
trend_model.fit(f_train.loc[:,X],f_train.loc[:,y[0]]) mean_model.fit(f_train.loc[:,X],f_train.loc[:,y[1]])
Проверка достоверности наших моделей. Мы запишем прогнозы обеих моделей относительно того, какие значения примут их целевые показатели в тестовом наборе. Напомним, что модели изучают не одну и ту же цель. Каждая модель независимо изучала собственную цель и работала над уменьшением своей погрешности независимо от другой модели.
pred_1 = trend_model.predict(f_validation.loc[:,X]) pred_2 = mean_model.predict(f_validation.loc[:,X])
Содержимое валидационного набора выходит за рамки выборки для наших моделей. По сути, мы проводим стресс-тестирование моделей, используя данные, с которыми они ранее не сталкивались, чтобы увидеть, будут ли наши модели вести себя этично в условиях существенного стресса.
Наш тест проводится на основе суммы прогнозов обеих моделей. Если максимальное значение суммы прогнозов модели равно 0,0, то наша модель прошла тест. Потому что наша модель по сути согласуется с гипотезой эффективного рынка о том, что, следуя обеим моделям одновременно, инвестор не заработает ничего. Мы намерены следовать только одной модели за раз. Поэтому мы будем динамически переключаться между режимами. Другими словами, наша стратегия имеет возможность менять стратегию без вмешательства человека.
test_result = pred_1 + pred_2 print(f" Test Passed: {np.linalg.norm(test_result,ord=2) == 0.0}")
Пакет numpy содержит множество таких полезных библиотек, как пакет линейной алгебры, который мы использовали выше. Функция нормы, которую мы вызвали, просто возвращает общую сумму содержимого вектора или наибольшее значение в векторе, в зависимости от того, как вызывается метод. Логически это то же самое, что вручную проверить содержимое массива, чтобы убедиться, что все числа в массиве равны 0. Обратите внимание: я обрезал выходные данные массива, но читатель может быть уверен, что все они равны 0.
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
Когда мы построили график фактической прибыли, выполненный с помощью стратегии следования за трендом, и сравнили его с прогнозами, сделанными моделью следования за трендом, мы поняли, что, сдержав несколько крупных колебаний прибыльности, например, в течение 600- и 700-дневного интервала, когда рынок ERUUSD колебался со значительной волатильностью, наша модель смогла угнаться за другими прибылями обычного размера.
plt.plot(f_validation.loc[:,y[0]],color='black') plt.plot(pred_1,color='red',linestyle=':') plt.legend(['Actual Profit','Predicted Profit']) plt.grid() plt.ylabel('Loss / Profit') plt.xlabel('Out Of Sample Days') plt.title('Visualizing Our Model Performance Out Of Sample on the EURUSD 10 Day Return')
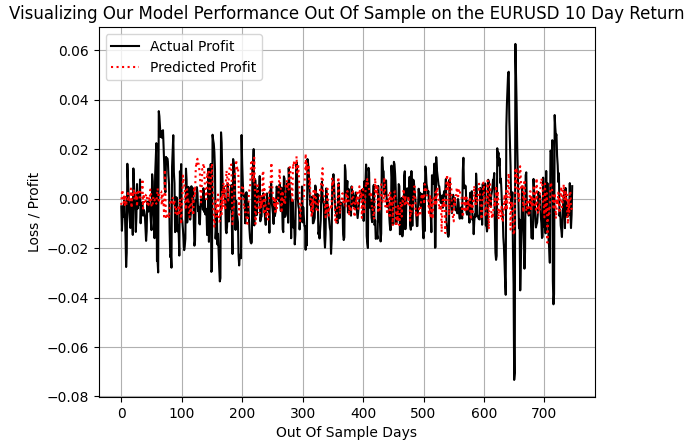
Рис. 7: Наша модель DRS не смогла уловить истинную волатильность рынка
Теперь мы готовы экспортировать наши модели машинного обучения в формат ONNX и начать развивать наши торговые приложения в новых направлениях. ONNX расшифровывается как Open Neural Network Exchange и позволяет создавать и развертывать модели машинного обучения с помощью набора широко распространенных API. Такое широкое распространение позволяет различным языкам программирования работать с одной и той же моделью ONNX. Напомним, что модель ONNX — это просто представление вашей модели машинного обучения. Если у вас еще не установлены библиотеки skl2onnx и ONNX, начните с их установки.
!pip install skl2onnx onnx
Теперь загрузим библиотеки, которые нам нужно экспортировать.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Определите форму ввода-вывода ваших моделей ONNX.
eurusd_drs_shape = [("float_input",FloatTensorType([1,len(X)]))] eurusd_drs_output_shape = [("float_output",FloatTensorType([1,1]))]
Подготовим прототипы ONNX вашей модели DRS.
trend_drs_model_proto = convert_sklearn(trend_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12) mean_drs_model_proto = convert_sklearn(mean_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12)
Сохраним модели.
onnx.save(trend_drs_model_proto,"EURUSD RF D1 T LBFGSB DRS.onnx") onnx.save(mean_drs_model_proto,"EURUSD RF D1 M LBFGSB DRS.onnx")
Поздравляем, вы построили свою первую архитектуру модели DRS. Теперь приготовимся к обратному тестированию моделей и посмотрим, есть ли разница, и смогли ли мы осмысленно заменить среднеквадратичную ошибку (RMSE) из нашего процесса проектирования.
Начинаем на MQL5
Для начала определим системные константы, которые важны для нашей торговой деятельности.
//+------------------------------------------------------------------+ //| EURUSD DRS.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 #define MA_PERIOD 5 #define MA_SHIFT 0 #define MA_MODE MODE_SMA #define TRADING_VOLUME SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN)
Теперь мы можем загрузить наши системные ресурсы.
//+------------------------------------------------------------------+ //| System dependencies | //+------------------------------------------------------------------+ #resource "\\Files\\DRS\\EURUSD RF D1 T DRS.onnx" as uchar onnx_proto[] //Our Trend Model #resource "\\Files\\DRS\\EURUSD RF D1 M DRS.onnx" as uchar onnx_proto_2[] //Our Mean Reverting Mode
Загрузим торговую библиотеку.
//+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Нам также понадобятся переменные для наших технических индикаторов.
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int ma_o_handle,ma_c_handle,atr_handle; double ma_o[],ma_c[],atr[]; double bid,ask; int holding_period;
Укажем глобальные переменные.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model,onnx_model_2;
При первоначальной загрузке нашего приложения мы вызовем метод, отвечающий за загрузку наших технических индикаторов и моделей ONNX.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Если мы не используем приложение, очистим ресурсы, которые нам больше не нужны.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); }
Наконец, получив обновленные уровни цен, мы либо будем искать торговые возможности, либо управлять имеющимися открытыми позициями.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- static datetime time_stamp; datetime current_time = iTime(Symbol(),PERIOD_D1,0); if(time_stamp != current_time) { time_stamp = current_time; update_variables(); if(PositionsTotal() == 0) { find_setup(); } else if(PositionsTotal() > 0) { manage_setup(); } } } //+------------------------------------------------------------------+
Это реализация функции, которую мы написали для настройки всей системы.
//+------------------------------------------------------------------+ //| Attempt To Setup Our System Variables | //+------------------------------------------------------------------+ bool setup(void) { atr_handle = iATR(Symbol(),PERIOD_CURRENT,14); ma_c_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_OPEN); holding_period = 0; onnx_model = OnnxCreateFromBuffer(onnx_proto,ONNX_DEFAULT); onnx_model_2 = OnnxCreateFromBuffer(onnx_proto_2,ONNX_DEFAULT); if(onnx_model == INVALID_HANDLE) { Comment("Failed to load Trend DRS model"); return(false); } if(onnx_model_2 == INVALID_HANDLE) { Comment("Failed to load Mean Reverting DRS model"); return(false); } ulong input_shape[] = {1,10}; ulong output_shape[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set Trend DRS Model input shape"); return(false); } if(!OnnxSetInputShape(onnx_model_2,0,input_shape)) { Comment("Failed to set Mean Reverting DRS Model input shape"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set Trend DRS Model output shape"); return(false); } if(!OnnxSetOutputShape(onnx_model_2,0,output_shape)) { Comment("Failed to set Mean Reverting DRS Model output shape"); return(false); } return(true); }
При деинициализации системы мы вручную освободим индикаторы и модели ONNX, которые больше не используем.
//+------------------------------------------------------------------+ //| Free up system resources | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); OnnxRelease(onnx_model); OnnxRelease(onnx_model_2); }
Обновляем системные переменные всякий раз при появлении новой информации о ценах.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update_variables(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(ma_c_handle,0,1,(HORIZON*2),ma_c); CopyBuffer(ma_o_handle,0,1,(HORIZON*2),ma_o); CopyBuffer(atr_handle,0,0,1,atr); ArraySetAsSeries(ma_c,true); ArraySetAsSeries(ma_o,true); }
Управляйте открытыми сделками, по сути, путем отсчета 10-дневного срока нашей доходности.
//+------------------------------------------------------------------+ //| Manage The Trade We Have Open | //+------------------------------------------------------------------+ void manage_setup(void) { if((PositionsTotal() > 0) && (holding_period < (HORIZON-1))) holding_period +=1; else if((PositionsTotal() > 0) && (holding_period == (HORIZON - 1))) Trade.PositionClose(Symbol()); }
Найдите торговую конфигурацию, получив подробную информацию о текущем состоянии рынка и передав ее в нашу модель. Наша стратегия основана на использовании скользящих средних в качестве индикаторов настроений инвесторов. Когда скользящие средние подают сигналы на продажу, мы предполагаем, что большинство инвесторов хотят открыть короткую позицию, но мы считаем, что на валютном рынке большинство, как правило, ошибается.
//+------------------------------------------------------------------+ //| Find A Trading Oppurtunity For Our Strategy | //+------------------------------------------------------------------+ void find_setup(void) { vectorf model_inputs = vectorf::Zeros(10); vectorf model_outputs = vectorf::Zeros(1); vectorf model_2_outputs = vectorf::Zeros(1); holding_period = 0; int i = 0; model_inputs[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); model_inputs[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); model_inputs[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); model_inputs[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); model_inputs[4] = (float)(iOpen(Symbol(),PERIOD_CURRENT,0) - iOpen(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[5] = (float)(iHigh(Symbol(),PERIOD_CURRENT,0) - iHigh(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[6] = (float)(iLow(Symbol(),PERIOD_CURRENT,0) - iLow(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[7] = (float)(iClose(Symbol(),PERIOD_CURRENT,0) - iClose(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[8] = (float) ma_c[0]; model_inputs[9] = (float)(ma_c[0] - ma_c[HORIZON]); if(!OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(!OnnxRun(onnx_model_2,ONNX_DEFAULT,model_inputs,model_2_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(model_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } else if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } else if(model_2_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } Comment("0: ",model_outputs[0],"1: ",model_2_outputs[0]); }
Отменим определение системных констант.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_MODE #undef MA_PERIOD #undef MA_SHIFT #undef TRADING_VOLUME //+------------------------------------------------------------------+
Сначала нам нужно выбрать даты нашего тестирования на истории. Напомним, что мы всегда выбираем даты, находящиеся за пределами обучающего набора модели, чтобы получить надежное представление о том, насколько хорошо модель может работать в будущем.
Рис. 8: Убедитесь, что вы выбрали даты, выходящие за рамки обучающего набора модели
Обычно мы хотим провести стресс-тест нашей модели, поэтому выбираем «Random delay» и «Every tick based on real ticks», чтобы протестировать нашу стратегию в реалистичных и сложных рыночных условиях.
Рис. 9: Использование «Every tick based on real ticks» — наиболее реалистичный вариант моделирования, который можно выбрать для стресс-тестирования нашей архитектуры DRS
Ниже мы приводим подробный отчет об эффективности нашей новой стратегии DRS. Интересно осознать, что нам удалось заменить RMSE на DRS и все равно получить прибыльную стратегию, хотя это была наша первая попытка заменить RMSE в нашем процессе построения модели формальным образом.
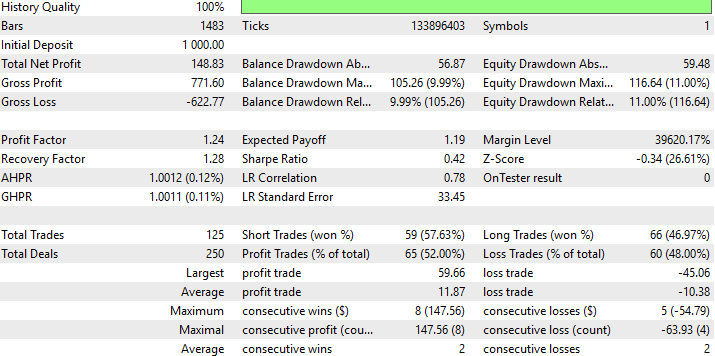
Рис. 10: Подробные результаты эффективности нашей стратегии на данных, которые она ранее не видела
Если взглянуть на кривую капитала, полученную в результате нашей стратегии, то можно увидеть проблемы, вызванные тем, что наша модель DRS не способна предвидеть волатильность рынка, как мы обсуждали ранее. Это заставляет нашу стратегию колебаться между прибыльными и убыточными периодами. Однако наша стратегия демонстрирует способность восстанавливаться и оставаться на верном пути, а это именно то, к чему мы стремимся.
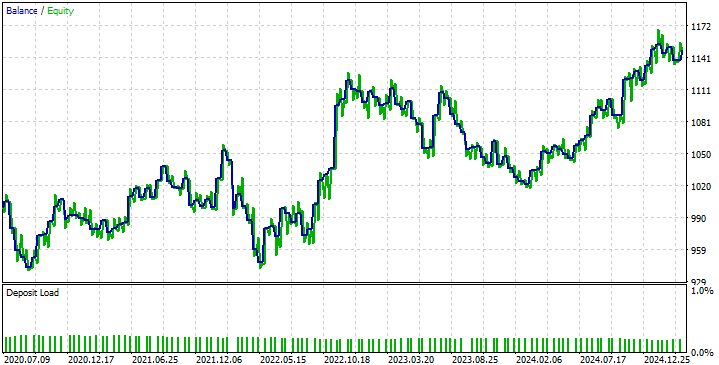
Рис. 11: Кривая капитала, полученная в результате нашей новой торговой стратегии
Заключение
Прочитав эту статью, читатели, не знавшие об ограничениях этих показателей, станут сильнее, чем были до прочтения этой статьи. Знание ограничений ваших инструментов так же важно, как и знание их сильных сторон. Методы оптимизации, которые мы используем для создания ИИ, могут «застрять» при попытке решить особенно сложные проблемы. И когда специалисты используют эти инструменты для моделирования доходности активов, они должны полностью осознавать, что их модели могут демонстрировать тенденцию к застреванию на уровне средней доходности рынка.
Читатель также получил практические знания и теперь понимает преимущества фильтрации рынков по тому, насколько хорошо они могут превзойти модель, прогнозирующую среднюю доходность на этом рынке, поскольку это подразумевает, что рынок имеет проявления неэффективности, которыми должен воспользоваться специалист.
Фильтруя рынки на основе того, насколько хорошо практикующий специалист может превзойти среднее значение, читатель научился воздерживаться от слепой интерпретации RMSE как отдельного показателя, а скорее всегда рассматривать RMSE относительно TSS. Читатель получил практическое понимание ограничений, которые эти показатели накладывают на повседневную работу, что нетипично для большинства литературных источников по этой теме или исследовательских работ, ссылки на которые здесь приведены.
И, наконец, если читатель намеревался вскоре развернуть модель машинного обучения для торговли своим частным капиталом, но не знал об этих ограничениях, то я бы порекомендовал ему сначала повторить упражнение, которое я продемонстрировал в этой статье, чтобы быть уверенным, что он не собирается молча выстрелить себе в ногу. RMSE позволяет нашим моделям мошенничать с тестами, но я уверен, что читателей, дочитавших до этого места, не так-то легко обмануть ограничениями ИИ.
| Название файла | Описание файла |
|---|---|
| DRS Models.mq5 | Скрипт на MQL5, который мы создали для извлечения подробных рыночных данных, необходимых для построения нашей модели DRS. |
| Dynamic_Regime_Switching_Models_(DRS_Modelling).ipynb | Jupyter notebook, который мы написали для проектирования нашей модели DRS. |
| EURUSD DRS.mq5 | Наш советник EURUSD, использовавший нашу модель DRS. |
| EURUSD RF D1 T DRS.onnx | Модель DRS следования за трендом всегда предполагает, что рынок находится в тренде. |
| EURUSD RF D1 M DRS.onnx | Модель DRS с возвратом к среднему значению всегда предполагает, что рынок находится в состоянии возврата к среднему значению. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17906
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
"Однако наша стратегия демонстрирует способность восстанавливаться и оставаться на верном пути, а это именно то, к чему мы стремимся."
Мне всегда казалось, что стремиться нужно к тому, чтобы стратегия генерила профит :)
"Однако наша стратегия показывает способность восстанавливаться и оставаться на трассе, а это именно то, к чему мы стремимся".
Я всегда считал, что нужно стремиться к тому, чтобы стратегия приносила прибыль :)
Спасибо за статью, @Gamuchirai Zororo Ndawana.
Я согласен с @Maxim Dmitrievsky, что конечной целью является прибыльность. Идея "восстановиться и не сбиться с пути" имеет смысл в качестве контроля устойчивости и просадки, но она не заменяет прибыль.
.
Практическое предложение: тестирование методом walk-forward, затраты и проскальзывание, асимметричные или квантильные цели, основанные на потерях или полезности, и штрафование оборота, чтобы избежать "обнимания среднего". (Прагматичный подход: согласуйте убытки с тем, как вы зарабатываете деньги).
Цитата: Да, но, к сожалению, у нас до сих пор нет стандартизированных метрик машинного обучения, которые бы понимали разницу между прибылью и убытком.
Ответ: Колонки прибыли и убытков будут существовать только в том случае, если ваш продукт, прошедший обратное тестирование, или флэтовый рынок так же хорош, как и форвардный рынок, который вы используете против последующего портфеля или корзины индексов, которые будут следовать за этой линией ордеров.
Есть некоторые индексы и недавно основанные ETF, которые выходят или которые производятся на растущей основе, как для этого предполагаемого использования, и будут давать эти результаты, прибыли, такие как индекс dowjones 30, а также многие другие индексы, которые были созданы для этого предполагаемого использования. Питер Мэтти
Спасибо за статью, @Gamuchirai Zororo Ndawana .
Я согласен с @Maxim Dmitrievsky , что конечная цель - это прибыльность. Идея восстанавливаться и не сходить с дистанции имеет смысл для устойчивости и контроля просадки, но это не заменит прибыли.
.
Иногда я задумываюсь о том, что инструменты перевода, на которые мы полагаемся, могут не улавливать оригинальное послание. Ваш ответ предлагает гораздо больше тезисов, чем то, что я понял из оригинального сообщения @Maxim Dmitrievsky .
Спасибо за то, что указали на огрехи в предвзятом отношении (функции с i + HORIZON), это худшие ошибки, которые я ненавижу, они требуют повторного тестирования. Но на этот раз более вдумчиво.
Вы также предоставили ценную информацию о мерах валидации, используемых для проверки моделей на практике, коэффициент Шарпа должен быть сродни универсальному золотому стандарту. Мне нужно больше узнать о Calmar и Sortino, чтобы составить свое мнение о них, спасибо вам за это.
Я согласен с вами, что эти два термина антисимметричны по замыслу, и тест заключается в том, что модели должны оставаться антисимметричными, любое отклонение от этого ожидания - это провал теста. Если одна или обе модели имеют неприемлемую погрешность, то их предсказания не будут оставаться антисимметричными, как мы ожидаем.
Однако понятие прибыли - это лишь простая иллюстрация, которую я привел, чтобы подчеркнуть проблему. Ни одна из существующих сегодня метрик не информирует нас о том, когда происходит "обнимание среднего". Ни в одной литературе по статистическому обучению не говорится о том, почему происходит обнимание среднего. К сожалению, это происходит из-за лучших практик, которым мы следуем, и это лишь один из многих способов, с помощью которых я хочу начать больше разговоров об опасности лучших практик.
Эта статья была скорее криком о помощи, о том, чтобы мы собрались вместе и разработали новые протоколы с нуля. Новые стандарты. Новые цели, над которыми будут работать непосредственно наши оптимизаторы и которые будут отвечать нашим интересам.