Обсуждение статьи "Как опередить любой рынок (Часть III): Индекс расходов Visa"
Спасибо, Гаму.
Отличная статья, спасибо, что поделились!!!
Еще раз спасибо Гаму. Хорошо написано, как обычно. Отличный прокомментированный шаблон о том, как визуализировать, масштабировать, тестировать, проверять на переоценку, реализовывать datafeed, прогнозировать и реализовывать торговую систему на основе набора данных. Фантастика заслуживает высокой оценки.
linfo2 #:
Еще раз спасибо Гаму. Хорошо написано, как обычно. Отличный шаблон с комментариями о том, как визуализировать, масштабировать, тестировать, проверять на перебор, реализовывать datafeed, прогнозировать и реализовывать торговую систему на основе набора данных. Фантастика очень ценна.
Спасибо, Нил, за ваш отзыв, очень приятно слышать такие добрые слова.Еще раз спасибо Гаму. Хорошо написано, как обычно. Отличный шаблон с комментариями о том, как визуализировать, масштабировать, тестировать, проверять на перебор, реализовывать datafeed, прогнозировать и реализовывать торговую систему на основе набора данных. Фантастика очень ценна.
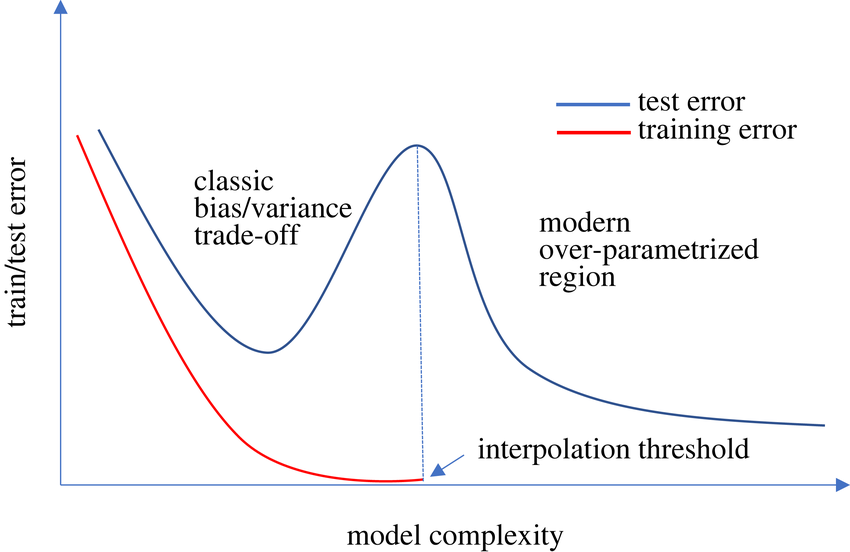
Самое интересное, что каждый день появляются новые исследования, которые ставят под сомнение все, что мы думали, что знаем. Недавно я узнал о феномене двойного спуска.
Если эта теория верна, то такого понятия, как чрезмерная подгонка, не существует. Согласно этому феномену, если продолжать обучение больших глубоких нейронных сетей в течение более длительного времени на одном и том же обучающем наборе, ошибка валидации будет продолжать снижаться до все более низких уровней, мой ниггер.
Изображение, которое я прикрепил ниже, наглядно демонстрирует это явление. Загвоздка в том, что обучение такой большой модели в течение такого длительного времени стоит дорого, и, кроме того, если данные зашумлены, это явление происходит дольше. Я не смог воспроизвести результаты на своем компьютере, однако эта статья уже на слуху.
{kind=link}
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Опубликована статья Как опередить любой рынок (Часть III): Индекс расходов Visa:
В мире больших данных существуют миллионы альтернативных наборов данных, которые потенциально могут улучшить наши торговые стратегии. В этой серии статей мы рассматриваем наиболее информативные общедоступные наборы данных.
VISA — американская транснациональная платежная компания. Компания была основана в 1958 году и сегодня является одной из крупнейших в мире сетей обработки транзакций. VISA имеет все возможности стать источником надежных альтернативных данных, поскольку она проникла практически на все рынки в развитых странах. Кроме того, Федеральный резервный банк Сент-Луиса также собирает некоторые макроэкономические данные, получаемые от VISA.
В этом обсуждении мы проанализируем индекс расходов VISA (VISA Spending Momentum Index, SMI). Индекс является макроэкономическим индикатором поведения потребительских расходов. Данные собираются компанией VISA с использованием ее собственных сетей и фирменных дебетовых и кредитных карт VISA. Все данные обезличены и собираются в основном на территории США. Поскольку VISA продолжает собирать данные с разных рынков, этот индекс в конечном итоге может стать эталонным показателем глобального потребительского поведения.
Для извлечения наборов данных VISA SMI мы будем использовать API Федерального резервного банка Сент-Луиса. API экономической базы данных Федеральной резервной системы (Federal Reserve Economic Database, FRED) позволяет нам получать доступ к сотням тысяч различных экономических временных рядов данных, собранных по всему миру.
Автор: Gamuchirai Zororo Ndawana