Artigos sobre análise de dados e estatísticas na MQL5
Muitos traders apreciam artigos sobre modelos matemáticos e teoria das probabilidades. Afinal de contas, a matemática é a base dos indicadores técnicos, e o conhecimento em estatística é necessário para analisar os resultados das operações e desenvolver estratégias.
Leia sobre lógica fuzzy, filtros digitais, perfil do mercado, mapas de Kohonen, redes neurais e muitas outras ferramentas que podem ser usadas para negociação.
Novo artigo

Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se

Indicador de avaliação da força e da fraqueza dos pares de moedas em MQL5 puro
Estamos criando um indicador profissional para análise da força das moedas em MQL5. Neste guia passo a passo, você aprenderá a desenvolver uma poderosa ferramenta de trading com painel visual para o MetaTrader 5, a calcular a força das moedas em múltiplos timeframes (H1, H4 e D1), a implementar a atualização dinâmica de dados e a criar uma interface amigável para o usuário.

Algoritmos de otimização populacional: algoritmos de estratégias evolutivas (Evolution Strategies, (μ,λ)-ES e (μ+λ)-ES)
Neste artigo, vamos falar sobre um grupo de algoritmos de otimização conhecidos como "Estratégias Evolutivas" (Evolution Strategies ou ES). Eles são alguns dos primeiros algoritmos que usam princípios de evolução para encontrar soluções ótimas. Vamos mostrar as mudanças feitas nas versões clássicas das ES, além de revisar a função de teste e a metodologia de avaliação dos algoritmos.


Como usar registros de parada de funcionamento para depurar os seus próprios DLLs
De 25 a 30% de todos os registros de parada de funcionamento recebidos de usuários surgem por conta de erros ocorridos quando funções importadas de dlls personalizados são executadas.
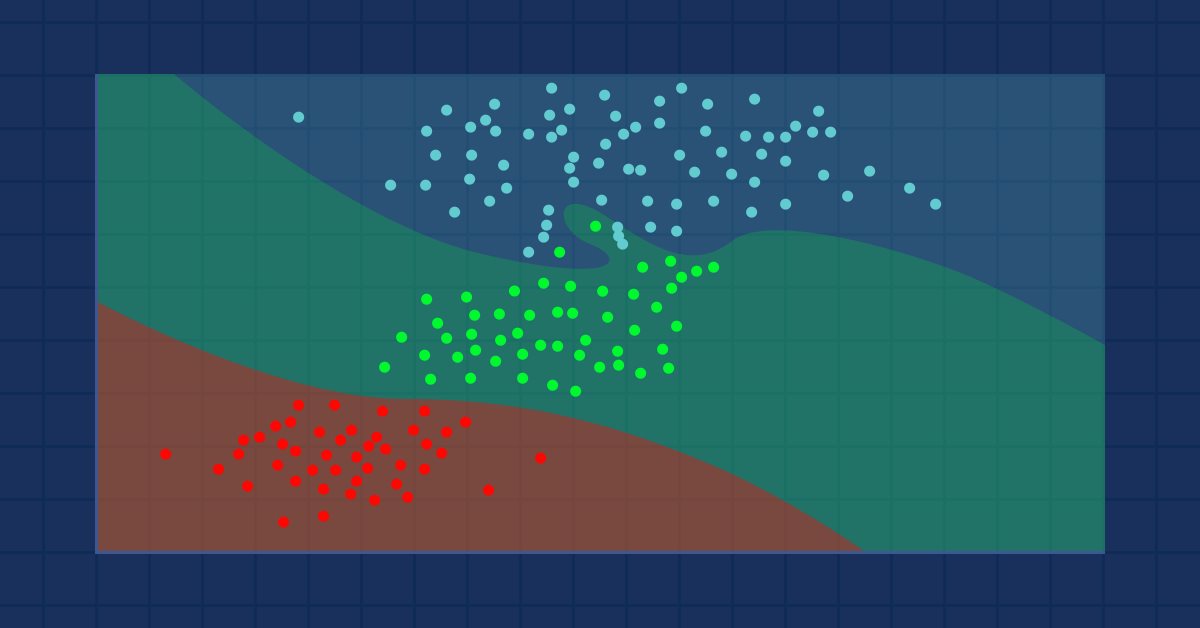
Ciência de dados e Aprendizado de Máquina (parte 09): O algoritmo K-vizinhos mais próximos (KNN)
Este é um algoritmo preguiçoso que não aprende com o conjunto de dados de treinamento, ele armazena o conjunto de dados e age imediatamente quando ele recebe uma nova amostra. Por mais simples que ele seja, ele é usado em uma variedade de aplicações do mundo real

Algoritmos de otimização populacionais: Otimização de colônia de formigas (ACO)
Desta vez, vamos dar uma olhada no algoritmo de otimização de colônia de formigas ("Ant Colony optimization algorithm", em inglês). O algoritmo é muito interessante e ambíguo. Trata-se de uma tentativa de criar um novo tipo de ACO.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 08): Travando o Indicador
Aqui vou mostrar como travar um indicador, usando pura e simplesmente a linguagem MQL5, de uma forma muito interessante e surpreendente.
Outras classes na biblioteca DoEasy (Parte 69): classe-coleção de objetos-gráficos
Com este artigo, começaremos o desenvolvimento de uma classe-coleção de objetos-gráficos que armazenará uma lista-coleção de objetos-gráficos com suas subjanelas e indicadores, e tornará possível trabalhar com gráficos selecionados e suas subjanelas, ou com uma lista de vários gráficos ao mesmo tempo.
Trabalhando com séries temporais na biblioteca DoEasy (Parte 48): indicadores multissímbolos multiperíodos num buffer de uma subjanela
Neste artigo consideraremos um exemplo que mostra como criar indicadores padrão multissímbolos e multiperíodos que usam um buffer de indicador e funcionam numa subjanela do gráfico principal. Prepararemos classes da biblioteca para trabalhar com indicadores padrão que funcionam na janela principal do programa, ou que tenham mais de um buffer para exibir seus dados.
Trabalhando com séries temporais na biblioteca DoEasy (Parte 59): objeto para armazenar dados de um tick
Com este artigo, vamos começar a criar a funcionalidade de biblioteca para trabalhar com dados de preços. Hoje vamos criar uma classe de objeto que armazenará todos os dados de preços recebidos no tick a seguir.

Redes neurais de maneira fácil (Parte 26): aprendizado por reforço
Continuamos a estudar métodos de aprendizado de máquina. Com este artigo, começamos outro grande tópico chamado aprendizado por reforço. Essa abordagem permite que os modelos estabeleçam certas estratégias para resolver as tarefas. E esperamos que essa propriedade inerente ao aprendizado de reforço abra novos horizontes para a construção de estratégias de negociação.

Redes neurais de maneira fácil (Parte 17): Redução de dimensionalidade
Continuamos a estudar modelos de inteligência artificial, em particular, algoritmos de aprendizado não supervisionados. Já nos encontramos com um dos algoritmos de agrupamento. E neste artigo quero compartilhar com vocês outra maneira de resolver os problemas de redução de dimensionalidade.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 07): Primeiras melhorias (II)
No artigo anterior fizemos a correção de alguns pontos, e adicionamos alguns testes no nosso sistema de replay, estes tentam garantir a maior estabilidade quanto for possível obter, ao mesmo tempo iniciamos a criação e o uso de um arquivo de configuração para o sistema de replay.

Conselhos de um programador profissional (Parte III): Registro de Logs. Conectando-se ao sistema Seq de coleta e análise de logs
Implementação da classe Logger para unificar e estruturar as mensagens que são impressas no log da guia Experts na caixa de ferramentas. Conexão com o sistema Seq de coleta e análise de logs. Monitoramento de mensagens de log online.

Simulação de mercado (Parte 02): Cross Order (II)
Diferente do que foi visto no artigo anterior, aqui vamos fazer o controle de seleção no Expert Advisor. Porém, esta não é uma solução ainda definitiva. Mas irá nos atender por hora. Então acompanhe o artigo para entender como implementar uma das soluções possíveis.
Trabalhando com preços na biblioteca DoEasy (Parte 60): lista-série de dados de dados de tick do símbolo
Neste artigo, criaremos uma lista para armazenar dados de tick de um símbolo e verificaremos tal criação e respectiva recepção de dados a partir dela no EA. Essas listas de dados de tick - separadamente para cada símbolo usado - formarão uma coleção de dados de tick.

Implementação do teste aumentado de Dickey-Fuller no MQL5
Neste artigo, vamos mostrar como implementar o teste aumentado de Dickey-Fuller e sua aplicação para realizar testes de cointegração usando o método de Engle-Granger.

Implementando o fator Janus em MQL5
Gary Anderson desenvolveu um método de análise de mercado baseado em uma teoria que chamou de fator Janus. Essa teoria descreve um conjunto de indicadores que podem ser usados para identificar tendências e avaliar o risco de mercado. Neste artigo, vamos implementar essas ferramentas no MQL5.

Desenvolvendo um sistema de Replay — Simulação de mercado (Parte 03): Ajustando as coisas (I)
Vamos dar uma ajeitada nas coisas, pois este começo não está sendo um dos melhores. Se não fizermos isto agora, vamos ter problemas logo, logo.

O modelo de movimento dos preços e suas principais disposições (Parte 1): A versão do modelo mais simples e suas aplicações
O artigo fornece os fundamentos de um movimento de preços matematicamente rigoroso e a teoria do funcionamento do mercado. Até o presente, nós não tivemos nenhuma teoria de movimento de preços matematicamente rigorosa. Em vez disso, nós tivemos que lidar com as suposições baseadas na experiência, afirmando que o preço se move de uma certa maneira após um determinado padrão. É claro que essas suposições não foram apoiadas nem pela estatística e nem pela teoria.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 25): Preparação para a próxima etapa
Aqui neste artigo iremos finalizar a primeira etapa do desenvolvimento do sistema de replay / simulador. Ao finalizar esta etapa, estou dizendo a você, caro leitor, que o sistema já estará em um estágio avançado o suficiente para que novas funcionalidades possam de fato serem implementadas. Isto a fim de tornar o sistema ainda mais elaborado e mais útil para efetuar estudos e desenvolver conceitos de analise de mercado.

Redes neurais de maneira fácil (Parte 21): Autocodificadores variacionais (VAE)
No último artigo, analisamos o algoritmo do autocodificador. Como qualquer outro algoritmo, tem suas vantagens e desvantagens. Na implementação original, o autocodificador executa a tarefa de separar os objetos da amostra de treinamento o máximo possível. E falaremos sobre como lidar com algumas de suas deficiências neste artigo.

Simulação de mercado (Parte 19): Iniciando o SQL (II)
Como eu disse no primeiro artigo sobre SQL, não faz sentido você perder tempo, programado rotinas e mais rotinas a fim de conseguir, gerar ou produzir algo que o próprio SQL já contém. Porém sem saber o básico do básico, você não conseguirá fazer nada em SQL, a fim de aproveitar de alguma forma o que esta ferramenta tem a nos oferecer. Sendo assim, aqui neste artigo iremos ver como fazer para conseguir executar tarefas primordiais a serem feitas em bancos de dados.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 24): FOREX (V)
Aqui estamos retirando o bloqueio de simulação baseada na plotagem LAST, e adicionando um ponto de entrada para este tipo de simulação. Agora prestem atenção ao fato de que todo o funcionamento, irá se basear no sistema do forex. Sendo que a única diferença, aqui nesta rotina, é o fato de que estaremos separando uma simulação BID, de uma LAST. Mas a questão de randomização do tempo e a sua correção para ser utilizado pela classe C_Replay, é a mesma em ambos modos de simulação. Isto é uma coisa boa, já que se modificarmos um dos modos, o outro irá se beneficiar, pelo menos no que rege a parte do tempo entre os tickets
Trabalhando com preços na biblioteca DoEasy (Parte 61): coleção de séries de ticks para símbolos
Visto que diferentes símbolos podem ser usados durante a operação do programa, é necessário criar uma lista própria para cada um deles. Hoje vamos combinar essas listas numa coleção de dados de ticks. Na verdade, irá tratar-se de uma lista normal baseada numa classe de array dinâmico de ponteiros para instâncias da classe CObject e seus herdeiros da Biblioteca Padrão.

Algoritmo de recompra: modelo matemático para aumentar a eficiência
Neste artigo, usaremos o algoritmo de recompra como um guia para um entendimento mais profundo da eficiência dos sistemas de negociação e começaremos a trabalhar com os princípios gerais de aumentar a eficiência de negociação usando matemática e lógica, bem como aplicar os métodos mais inovadores para aumentar a eficiência no contexto de usar qualquer sistema de negociação.
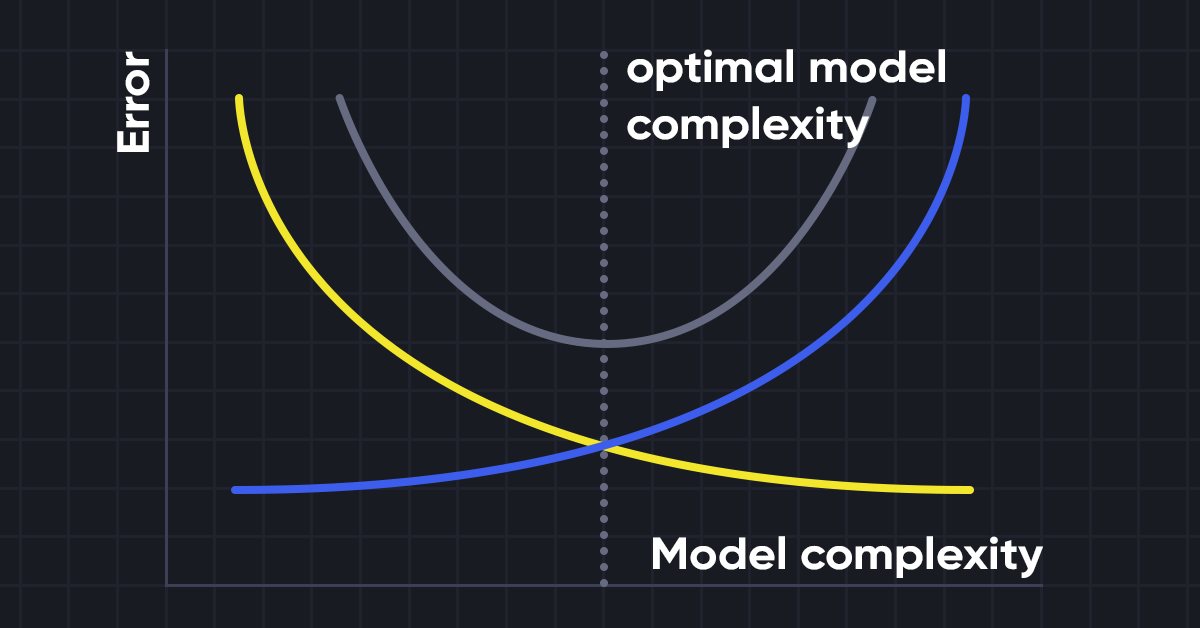
Ciência de dados e Aprendizado de Máquina (parte 10): Regressão de Ridge
A regressão de Ridge é uma técnica simples para reduzir a complexidade do modelo e evitar o ajuste excessivo que pode resultar da regressão linear simples

Desenvolvendo um sistema de Replay (Parte 66): Dando play no serviço (VII)
Aqui neste artigo, vamos implementar uma primeira solução, para que possamos saber o momento em que uma nova barra poderá vim a surgir no gráfico. Esta solução se adequa a diversas situações. Porém entender como a mesma foi desenvolvida pode lhe ajudar a entender diversas questões. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Trabalhando com séries temporais na biblioteca DoEasy (Parte 54): classes herdeiras do indicador base abstrato
Neste artigo, analisaremos a criação de classes de objetos herdeiros do indicador base abstrato. Esses objetos nos darão acesso à capacidade de criar EAs de indicador, coletar e receber estatísticas sobre valores de dados de diferentes indicadores e preços. Também criaremos uma coleção de objetos-indicadores a partir da qual será possível acessar as propriedades e dados de cada indicador criado no programa.
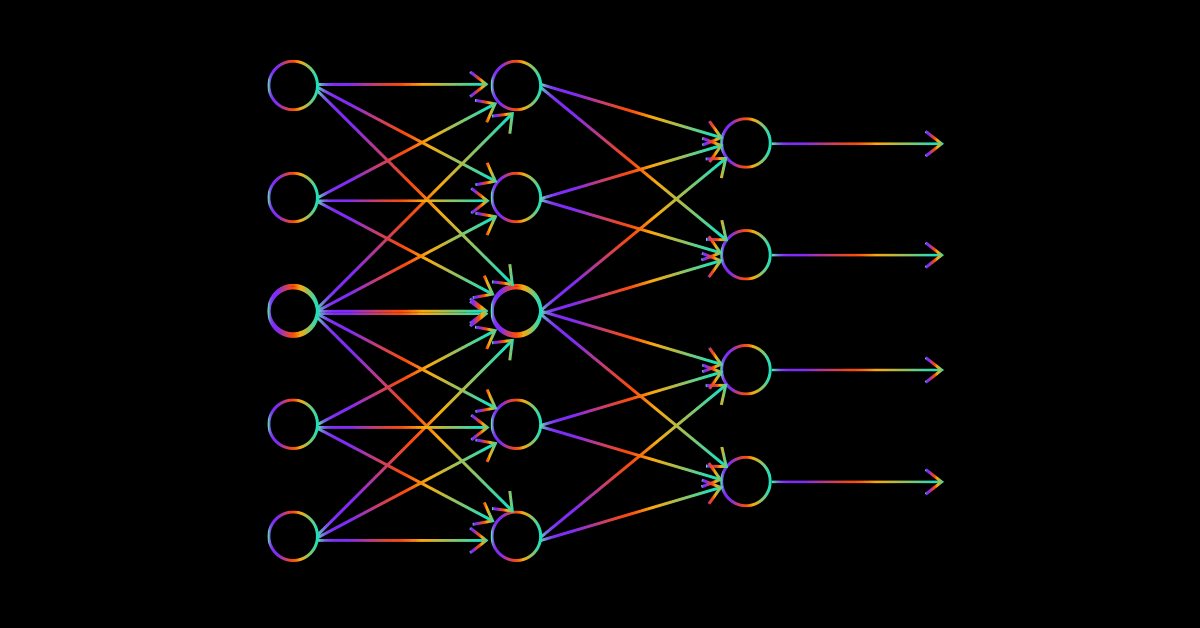
Ciência de Dados e Aprendizado de Máquina — Redes Neurais (Parte 02): Arquitetura das Redes Neurais Feed Forward
Há detalhes a serem abordadas na rede neural feed-forward antes de finalizarmos este assunto, a arquitetura é uma delas. Vamos ver como nós podemos construir e desenvolver uma rede neural flexível para as nossas entradas, o número de camadas ocultas e os nós para cada rede.

Data Science e Machine Learning (Parte 24): Previsão de Séries Temporais no Forex Usando Modelos de IA Clássicos
Nos mercados de forex, é muito desafiador prever a tendência futura sem ter uma ideia do passado. Poucos modelos de machine learning são capazes de fazer previsões futuras considerando valores passados. Neste artigo, vamos discutir como podemos usar modelos clássicos (não específicos para séries temporais) de Inteligência Artificial para superar o mercado.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 13): Nascimento do SIMULADOR (III)
Aqui iremos dar uma leve otimizada nas coisas. Isto para facilitar o que iremos fazer no próximo artigo. Mas também irei explicar como você pode visualizar o que o simulador está gerando em termos de aleatoriedade.
Fatorando Matrizes — O Básico
Como o intuito aqui é ser didático. Vou manter a coisa no seu padrão mais simples. Ou seja, iremos implementar apenas e somente o que será preciso. A multiplicação de matrizes. E você verá que isto será o suficiente para simular a multiplicação de uma matriz por um escalar. A grande dificuldade que muita gente tem em implementar um código usando fatoração de matrizes, é que diferente de uma fatoração escalar, onde em quase todos os casos a ordem dos fatores não altera o resultado. Quando se usa matrizes, a coisa não é bem assim.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 15): Nascimento do SIMULADOR (V) - RANDOM WALK
Neste artigo iremos finalizar a fase, onde estamos desenvolvendo o simulador para o nosso sistema. O principal proposito aqui será ajustar o algoritmo visto no artigo anterior. Tal algoritmo tem como finalidade criar o movimento de RANDOM WALK. Por conta disto, o entendimento do conteúdo dos artigos anteriores, é primordial para acompanhar o que será explicado aqui. Se você não acompanhou o desenvolvimento do simulador, aconselho você a ver esta sequência desde o inicio. Caso contrário, poderá ficar perdido no que será explicado aqui.

Análise quantitativa no MQL5: implementando um algoritmo promissor
Vamos explorar o que é a análise quantitativa, como os grandes players a utilizam e criar um dos algoritmos de análise quantitativa na linguagem MQL5.

Desenvolvendo um sistema de Replay (Parte 67): Refinando o Indicador de controle
Neste artigo mostrarei o que um pouco de refinamento no código é capaz de fazer. Tal refinamento tem como objetivo tornar mais simples o nosso código. Fazer um maior uso das chamadas de biblioteca do MQL5. Mas principalmente fazer com que o nosso código se torne bem mais estável, seguro e fácil de ser usado por outras classe, ou outros códigos que por ventura construiremos. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 14): Nascimento do SIMULADOR (IV)
Neste artigo continuaremos a fase de desenvolvimento do simulador. Mas agora, vamos ver como criar de fato um movimento do tipo RANDOM WALK. Este tipo de movimentação é muito interessante, pois tudo envolvido no mercado de capitais tem como base este tipo de movimentação. Além do mais você vai começar a entender alguns conceitos importantes para quem faz estáticas de mercado.

Ciência de Dados e ML (Parte 27): Redes Neurais Convolucionais (CNNs) em Bots de Trading no MetaTrader 5 — Vale a Pena?
As Redes Neurais Convolucionais (CNNs) são renomadas por sua capacidade de detectar padrões em imagens e vídeos, com aplicações em diversos campos. Neste artigo, exploramos o potencial das CNNs para identificar padrões valiosos nos mercados financeiros e gerar sinais de trading eficazes para bots de negociação no MetaTrader 5. Vamos descobrir como essa técnica de aprendizado profundo pode ser aproveitada para decisões de trading mais inteligentes.

Desenvolvendo um sistema de Replay (Parte 65): Dando play no serviço (VI)
Aqui neste artigo mostrarei como faremos para conseguir implementar o avanço rápido, assim como também resolveremos o problema do indicador de mouse, quando este está sendo usando junto com a aplicação de replay / simulação. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Redes neurais de maneira fácil (Parte 14): Agrupamento de dados
Devo confessar que já se passou mais de um ano desde que o último artigo foi publicado. Em um período tão longo como esse, é possível reconsiderar muitas coisas, desenvolver novas abordagens. E neste novo artigo, gostaria de me afastar um pouco do método de aprendizado supervisionado usado anteriormente, e sugerir um pouco de mergulho nos algoritmos de aprendizado não supervisionado. E, em particular, desejaria analisar um dos algoritmos de agrupamento, o k-médias (k-means).

Algoritmos de otimização populacionais: salto de sapo embaralhado
O artigo apresenta uma descrição detalhada do algoritmo salto de sapo embaralhado (Shuffled Frog Leaping Algorithm, SFL) e suas capacidades na solução de problemas de otimização. O algoritmo SFL é inspirado no comportamento dos sapos em seu ambiente natural e oferece uma nova abordagem para a otimização de funções. O algoritmo SFL é uma ferramenta eficaz e flexível, capaz de lidar com diversos tipos de dados e alcançar soluções ótimas.