
Redes neuronales en el trading: Actor—Director—Crítico (Actor—Director—Critic)

Introducción
El aprendizaje por refuerzo (Reinforcement Learning — RL) sigue siendo una de las áreas más prometedoras y de desarrollo más activo en el aprendizaje automático moderno. Su singularidad reside en la capacidad del Agente para aprender interactuando con el entorno, produciendo estrategias de comportamiento óptimas basadas en la experiencia acumulada. La síntesis con redes neuronales profundas, el llamado aprendizaje profundo por refuerzo (Deep Reinforcement Learning — Deep-RL) ha sido especialmente eficaz y ha dado lugar al desarrollo de sistemas autónomos en robótica, juegos, gestión industrial y mercados financieros.
El entorno financiero se caracteriza por una elevada estocasticidad, cambios continuos y un alto nivel de riesgo, lo cual lo convierte en un campo de pruebas ideal para aplicar y probar los métodos de Deep-RL. Aquí el Agente necesita adaptarse rápidamente a los cambios en los precios, los volúmenes comerciales, la volatilidad del mercado y tomar decisiones en condiciones de incertidumbre. Sin embargo, en la práctica, la aplicación de RL a las estrategias comerciales, especialmente en entornos comerciales de alta frecuencia y gestión de carteras, se enfrenta a una serie de retos. Uno de los principales retos sigue siendo el escaso uso de los datos, es decir, el altísimo coste de las acciones poco informativas y las estrategias equivocadas.
En los algoritmos clásicos Model-Free RL, en los que no se utiliza explícitamente ningún modelo del entorno, el Agente obtiene la información únicamente de la experiencia observada. Es decir, actúa por ensayo y error: realizando acciones, recibiendo recompensas y actualizando sus evaluaciones. Sin embargo, una gran proporción de estas interacciones resulta poco informativa. En condiciones de mercado, esto implica altos costes comerciales, pérdidas de capital y un largo camino para construir una estrategia sostenible. Por consiguiente, mejorar la eficacia del uso de los datos y acelerar la convergencia del entrenamiento se convierte en una tarea urgente.
Una de las arquitecturas más estables y utilizadas ha sido el framework Actor-Critic, que combina dos modelos:
- El Actor (Actor) estudia la estrategia (Policy),
- El Crítico (Critic) estima las acciones a través de la función de valor (Value Function).
En las aplicaciones financieras, la arquitectura Actor-Critic se utiliza para construir Agentes capaces de predecir los beneficios a corto plazo y gestionar el riesgo a largo plazo. Por ejemplo, en la tarea de reequilibrio de la cartera, el Crítico está entrenado para predecir los rendimientos esperados, mientras que el Actor selecciona los pesos de los activos para aumentar el valor de la cartera. Sin embargo, incluso una arquitectura tan avanzada tiene limitaciones: en las primeras fases del aprendizaje, la estimación del Crítico puede ser demasiado severa y las señales al Actor pueden ser erróneas. El Agente puede entonces volver a explorar las zonas desventajosas conocidas del espacio de acción.
Para subsanar esta deficiencia, en el artículo "Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework" se propuso el nuevo framework — Actor—Director—Critic (ADC). Además del Actor y el Crítico, se introduce en la arquitectura un tercer elemento, el Director (Director). Su tarea es actuar como clasificador capaz de distinguir las acciones de calidad de las que no lo son incluso antes de que el Crítico esté entrenado para dar evaluaciones correctas. A diferencia del Crítico, el Director tiene una función clasificatoria más que evaluativa. Se encarga de determinar si merece la pena intentar formar una política sobre una acción determinada, o si es de baja calidad intrínseca y puede excluirse de ulteriores consideraciones.
La introducción de un director ofrece las siguientes ventajas. En primer lugar, la selectividad resulta crucial en la fase inicial del aprendizaje: hay que evitar repetir acciones ineficaces. En segundo lugar, en los elevados costes de transacción y la volatilidad inherente a los mercados financieros, cada movimiento fallido resulta costoso para el Agente. En semejantes circunstancias, el Director actúa como mecanismo para la "dirección" inicial del Actor, permitiendo centrarse en acciones potencialmente eficaces. Este enfoque reduce la entropía del estudio y acelera la formación de estrategias productivas.
El proceso de aprendizaje del Director se basa en la construcción de dos subconjuntos empíricos de datos: uno incluye conjuntos de datos (estado, acción, recompensa) con altos rendimientos y el otro con bajos rendimientos. Una vez entrenado, el Director es capaz de realizar una clasificación binaria de las nuevas acciones, descartando las potencialmente ineficaces y reforzando así las señales procedentes del Crítico. La influencia del Director se regula a través del factor de atenuación: inicialmente tiene una gran influencia sobre el Actor, pero a medida que aumenta la precisión del Crítico, el peso del Director disminuirá. Este mecanismo permite mantener la flexibilidad y la resistencia durante la optimización.
Además de las mejoras estructurales de la arquitectura ADC, los autores del framework ofrecen una solución a otro problema fundamental: la sobreestimación de las acciones (Overestimation Bias). En el RL, la sobreestimación surge al utilizar como valores objetivo valores sobreestimados, lo que redunda en la presencia de recompensas esperadas sobreestimadas y la desestabilización del aprendizaje. Los motivos de la sobreestimación incluyen:
- El desplazamiento (sesgo) asociado a la elección de una función de valor sobrestimada (Maximization Bias);
- Errores de bootstrapping en los que se utilizan estimaciones prospectivas de recompensas futuras para actualizar el estado actual.
Uno de los enfoques más conocidos para combatir la sobreestimación ha sido el algoritmo Twin Delayed Deep Deterministic Policy Gradient (TD3). Utiliza dos funciones Q independientes y selecciona la mínima de ellas para actualizarla. Sin embargo, la estabilidad de este método sigue siendo limitada: los modelos objetivo se actualizan con retraso y sus estimaciones resultan inestables.
El framework ADC ofrece una modificación de este esquema: cada función Q recibe dos copias objetivo que se actualizan en un orden alterno a intervalos diferentes. Al calcular el valor objetivo, se usa la media de los dos modelos objetivo. Este enfoque reduce la variación de las calificaciones, minimiza la sobreestimación y hace que el aprendizaje sea más estable. Esto resulta especialmente importante en problemas en los que un error en la función Q puede provocar una pérdida de capital, como en las aplicaciones comerciales.
La combinación de la arquitectura Actor-Director-Critic con un avanzado sistema de evaluación dual da como resultado un framework potente, adaptable y resistente. Su aplicación en las tareas comerciales algorítmica, gestión de activos y cobertura automática puede aumentar significativamente la eficacia de las estrategias comerciales, acelerar el entrenamiento de los Agentes y reducir los riesgos gracias a la selección inteligente de acciones en las primeras fases del entrenamiento.
El algoritmo ADC
En una gran variedad de tareas de aprendizaje por refuerzo, la arquitectura Actor-Critic ha demostrado ser una herramienta robusta y eficaz. Su elegancia, comprensibilidad y capacidad para proporcionar estrategias de alta calidad han hecho de este modelo la base de futuros desarrollos en el aprendizaje por refuerzo. No obstante, con el aumento de la complejidad de los entornos analizados, especialmente en presencia de un espacio de acción del Agente continuo y escasa retroalimentación del entorno, ha surgido la necesidad de arquitecturas más potentes y flexibles. La respuesta a estos retos ha sido el innovador framework Actor-Director-Critic (ADC), que incorpora los principios de planificación estratégica, orientación heurística y evaluación profunda de la utilidad de las acciones.
Esta arquitectura se basa en tres componentes interrelacionados: El Actor (Actor), el Crítico (Critic) y el Director (Director). Juntos forman un sistema coordinado en el que cada elemento apoya y refuerza a los demás, creando las condiciones para que el aprendizaje del Agente sea más sostenible y rápido.
El Crítico actúa como centro analítico del sistema. Su objetivo principal es estimar la utilidad de las acciones del Agente a largo plazo aproximando una función de valor Q(s, a) que refleje la recompensa total esperada al utilizar la política actual. Se entrena minimizando el error entre el valor predicho y el valor objetivo:
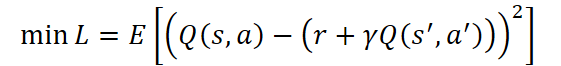
donde:
- r — recompensa del entorno por la última acción del Agente,
- γ ∈ [0,1) — factor de descuento,
- s' y a' — estado y la acción siguientes, respectivamente.
No obstante, confiar únicamente en las valoraciones del Crítico, sobre todo en las primeras fases del aprendizaje, puede resultar arriesgado porque sus predicciones aún son inestables. Para compensar esta incertidumbre y guiar al Agente hacia decisiones inteligentes, a la arquitectura se añade un Director, un componente que actúa como mentor. Actúa como un clasificador binario que distingue las acciones potencialmente buenas de las indeseables. El Director se entrena con muestras premarcadas de acciones positivas ah y negativas al sobre la siguiente función objetivo:
![]()
donde la función D(s, a) estima la probabilidad de que la acción a en el estado s sea apropiada. De este modo, el Director filtra las acciones del Actor y guía su aprendizaje, especialmente en las fases iniciales, cuando el juicio del Crítico puede resultar poco fiable.
El Actor, a su vez, representa la implementación de la política de comportamiento del Agente. Es una función paramétrica μθ(s) que devuelve la acción óptima (bajo la política de comportamiento actual) a, tras analizar el estado actual s. En el framework ADCActor, el actor no solo se entrena en función de las predicciones del Crítico, sino que también recibe orientación del Director. Esto le garantiza una mayor confianza a la hora de avanzar hacia estrategias óptimas. La función objetivo del Actor combina dos fuentes de información:
![]()
De este modo, el Actor busca elegir acciones que sean aprobadas por el Director y que tengan un alto valor esperado según el Crítico.
Para mejorar la robustez del entrenamiento y combatir la sobreestimación, los autores del framework ADC nos proponen usar un sistema avanzado de evaluación dual: a dos Críticos independientes se les dan dos copias objetivo con parámetros congelados para cada una. Al entrenar al Crítico, se toma la media de los resultados de la evaluación del estado y la acción posteriores por parte de los respectivos modelos objetivo, lo que ayuda a estabilizar el proceso. Y cuando se entrena al Actor, se utiliza el valor mínimo entre las puntuaciones de los dos Críticos, lo que evita la sobreestimación de la acción y fomenta una estrategia más conservadora pero fiable.
Los modelos objetivo de losCríticos se actualizan a su vez copiando los parámetros de los modelos entrenados correspondientes tras un intervalo de tiempo determinado. Esto garantiza la estabilidad del aprendizaje a largo plazo y evita saltos bruscos en los valores de las funciones objetivo.
También merece la pena prestar atención al hecho de que la optimización de los parámetros de los modelos Crítico entrenados se realiza en todas las iteraciones del proceso de entrenamiento. Sin embargo, el ajuste de la política del Actor se ejecuta con retraso, lo que da estabilidad adicional al proceso de aprendizaje. El periodo de retraso permite al Crítico evaluar con mayor precisión la política de comportamiento actual y ofrecer una orientación más mesurada para su ajuste.
Además, se aplican técnicas de suavizado estocástico para aumentar la diversidad y robustez del comportamiento del Agente, que incluyen:
- adición de ruido gaussiano a las acciones del Agente:
![]()
- adición de ruido limitado a las acciones objetivo:
![]()
La función final de optimización de los parámetros del Actor integra las señales del Crítico y del Director:
![]()
El framework Actor-Director-Critic abre nuevos horizontes para crear Agentes inteligentes que no solo puedan extraer conocimientos de la experiencia, sino también percibir la tutoría de forma similar al aprendizaje humano.
A continuación se muestra la visualización del framework Actor-Director-Critic realizada por el autor.

Implementación con MQL5
Tras considerar los aspectos teóricos del framework Actor-Director-Critic, pasaremos a la parte práctica de nuestro artículo, donde consideraremos nuestra propia visión de la implementación de los enfoques propuestos por los autores del framework utilizando herramientas MQL5.
Como habrá observado, el framework considerado no implica la creación de nuevos módulos como objetos independientes. Y este hecho distingue significativamente este artículo de otros anteriores. Hoy nos centraremos más en crear la arquitectura de modelos entrenados a partir de módulos creados previamente y en construir el proceso de aprendizaje considerando los enfoques propuestos.
Arquitectura de los modelos entrenados
Comenzando el trabajo de construcción de la arquitectura de los modelos entrenados, cabe destacar que el framework ADC propuesto por los autores es aplicable a una gama bastante amplia de soluciones arquitectónicas. El artículo del autor presenta los resultados de experimentos con una ampliación del framework TD3. En nuestro artículo, iremos más allá e intentaremos aplicar las soluciones propuestas a una solución arquitectónica más compleja del HiSSDque analizamos en el artículo anterior. Al hacerlo, no nos hemos limitado a añadir dos nuevos modelos: El Crítico y el Director, pero también hemos hecho algunas modificaciones en los anteriores.
Al igual que antes, la arquitectura de todos los modelos entrenados se representa en el método CreateDescriptions. En los parámetros de este método añadimos 2 arrays dinámicos para registrar la arquitectura de los modelos que se van a añadir.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método, comprobamos directamente los punteros recibidos y, si es necesario, creamos nuevas instancias de objetos de array dinámicos, lo que nos permitirá excluir errores críticos al acceder posteriormente a los arrays especificados.
En primer lugar, como antes, presentaremos la arquitectura de un planeador de alto nivel que actúa en parte como codificador del estado del entorno.
Recordemos que este modelo recibe como entrada un tensor que describe el estado del entorno. Además, genera una matriz de habilidades genéricas en el estado latente del modelo. Y predice una descripción de los estados del entorno posteriores para un horizonte de planificación determinado. Para construir los estados predictivos solo se usa información general sobre las habilidades. De este modo, incentivamos al modelo para que produzca el tensor de habilidades genéricas más informativo.
Como primera capa, seguimos usando una capa totalmente conectada cuyo tamaño es suficiente para registrar la descripción tensorial completa del estado del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Debemos recordar que la entrada del modelo son datos de origen "sin procesar", recibidos directamente del terminal MetaTrader 5. Pueden ser tanto secuencias de cotizaciones de precios como datos de indicadores técnicos, desde simples medias móviles hasta osciladores complejos.
Los datos analizados, aunque valiosos, son de naturaleza muy diversa. Sus rangos, distribuciones estadísticas y características acústicas pueden variar considerablemente. Sin un preprocesamiento adecuado, esta heterogeneidad provoca una drástica disminución del rendimiento del entrenamiento del modelo. Por consiguiente, el siguiente paso será llevarlos a una forma comparable. Para ello solemos usar una capa de normalización por lotes, que ayuda a eliminar el desequilibrio en la distribución de los valores.
Pero hoy no. Para mejorar la robustez del modelo y su capacidad de generalización, le proponemos mejorar este paso añadiendo ruido controlado a los datos normalizados. De este modo, se forma una especie de mecanismo de regularización que evita el sobreentrenamiento y aumenta la adaptabilidad del modelo a las turbulencias del mercado real.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Y solo entonces podemos usar el objeto de generación de habilidades universales, cuya tarea es crear un tensor de habilidades genéricas informativas para cada agente. Este tensor es una forma concentrada de características clave que pueden caracterizar el comportamiento y los objetivos de un agente en el contexto actual del mercado. En un entorno de elevada volatilidad e imprevisibilidad de los instrumentos financieros, esta abstracción permite reforzar la solidez de la estrategia reduciendo la sensibilidad al ruido a corto plazo y a los valores atípicos.
Debemos entender que el tensor de habilidades se utilizará más tarde como parte de los datos de entrada en el entrenamiento de la política de comportamiento del Agente. Su presencia aumenta significativamente la capacidad selectiva del modelo: le permite separar con mayor precisión las acciones potencialmente rentables de las poco prometedoras. Así, replanteamos los datos analizados en cuanto a las tareas y habilidades. Ya no se trata del clásico «state → action», sino de la transición interpretada: «contexto → habilidad → acción».
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Para mejorar la eficacia de las acciones de los agentes considerando la dinámica de los cambios en el tensor general de habilidades, añadimos además un bloque LSTM recurrente. Este elemento de la arquitectura desempeña un papel fundamental a la hora de dar sentido a la estructura temporal de los datos de mercado observados. Se sabe que los mercados financieros dependen en gran medida de estados pasados, y gran parte de la lógica del mercado se oculta precisamente en patrones temporales.
Aquí es donde el LSTM (Long Short-Term Memory) se muestra como una herramienta indispensable. Su memoria interna le permite almacenar y actualizar información sobre las principales transiciones del mercado y las pautas internas sin perder el contexto en largas dependencias temporales. De este modo, el modelo aprende no solo a reconocer las condiciones actuales del mercado, sino también a pronosticar posibles retrocesos o movimientos de continuación basándose en la compleja estructura de observaciones pasadas.
Conectar el bloque LSTM después de la capa de generación de habilidades es una decisión arquitectónica consciente. Primero, el modelo extrae una representación abstracta del estado actual y los objetivos del agente en forma de tensor de habilidades y, a continuación, el bloque LSTM rastrea la evolución de estas habilidades a lo largo del tiempo. Esto permite al agente percibir no solo una "instantánea estática" del mercado, sino también observar cómo cambia su perfil estratégico a lo largo del tiempo; por ejemplo, cómo cambia la tendencia dominante, cómo se forman los niveles de apoyo/resistencia y cómo se comporta la volatilidad.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = prev_out; // Common Skkills descr.layers = prev_count; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, conectamos secuencialmente dos capas convolucionales, cada una de las cuales desempeña un papel específico en el procesamiento de series temporales multivariantes procedentes de las capas de procesamiento anteriores. Estas capas convolucionales actúan como una especie de MLP con cabezas de predicción independientes diseñadas para analizar y predecir de forma autónoma la continuación de los componentes unitarios de una secuencia de mercado compleja en un horizonte de planificación determinado.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Luego transponemos los valores predichos de las secuencias unitarias a una representación multivariante de series temporales.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Y lo que es más importante, después de todo este procesamiento en cascada y de la transformación de características, devolvemos los valores predictivos resultantes a la escala y distribución de los datos de origen mediante normalización inversa. Este paso es necesario para garantizar que los resultados del modelo se inscriban en un marco comprensible e interpretable para el entorno comercial.
La aplicación de la normalización inversa preserva el vínculo entre el "mundo del modelo" y el espacio real del mercado, donde cada valor posee un significado cuantitativo preciso.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Me gustaría recordarle que la representación latente obtenida a la salida del bloque de entrenamiento del tensor de habilidades genéricas no es el producto final del procesamiento. Este representa una valiosa abstracción intermedia que se reutilizará muchas veces en el futuro en diversos componentes del framework Actor-Director-Critic implementado. Por este motivo, almacenamos la descripción del bloque LSTM recurrente en una variable local, garantizando así que esté disponible para operaciones posteriores.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
El siguiente paso consiste en describir la arquitectura del Controlador de bajo nivel. Este módulo analiza el mismo estado del entorno y genera un tensor de habilidades específicas. Por lo tanto, podemos simplemente copiar de la arquitectura del modelo anterior la descripción de las dos primeras capas: los datos de origen y su normalización.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
A continuación, se utiliza un objeto de Controlador de bajo nivel; una de las tareas del mismo consiste en generar un tensor de habilidades específicas. A diferencia del módulo construido anteriormente para generar habilidades generalizadas considerando el contexto estratégico, el Controlador trabaja a nivel táctico, analizando el estado actual del entorno.
El controlador no se limita a reaccionar ante la situación, sino que interpreta activamente el complejo entorno del mercado, extrayendo de él lo que podría denominarse la "intuición" a corto plazo del Agente. A partir de este análisis, se forma un tensor de habilidades específicas que refleja las preferencias instantáneas y las acciones que el Agente debe realizar en una situación concreta.
Luego se fusionan los tres flujos de información:
- La representación latente de las habilidades genéricas (de alto nivel).
- Las habilidades específicas de los tensores (de bajo nivel).
- La descripción normalizada del estado actual del entorno.
El tensor conjunto sirve de base para generar la matriz de acciones de los agentes. Esta estructura ofrece una gran adaptabilidad al modelo: los objetivos estratégicos se ajustan a las realidades tácticas. Las pautas de comportamiento de los agentes se hacen más flexibles, pero siguen sujetas a la lógica general de la política comercial.
Debemos subrayar que el Controlador no es solo un mecanismo de predicción de acciones, sino un vínculo semántico entre el mundo de las intenciones de alto nivel y el contexto específico del mercado. El Controlador permite al agente adaptarse a las condiciones cambiantes del mercado, manteniendo al mismo tiempo el enfoque estratégico de su comportamiento.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.layers, // Variables NSkills, // Task Skills latent.count, // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Luego procedemos a describir la arquitectura del modelo del Actor de alto nivel, responsable de generar la decisión comercial final. Su tarea consiste en interpretar la matriz de acciones propuesta por el Controlador en el paso anterior. En otras palabras, el Actor actúa como la autoridad final que determina qué comportamiento específico se aplicará en el contexto actual del mercado basándose en múltiples escenarios tácticos alternativos.
La arquitectura del Actor se ha tomado íntegramente de nuestro artículo anterior. Hemos tomado la decisión fundamental de no añadir ruido a las acciones generadas a partir de la matriz de alternativas posibles. A diferencia de muchas tareas del aprendizaje por refuerzo en las que añadir ruido puede fomentar la exploración y la variabilidad, en un entorno de mercado financiero incluso una mínima distorsión de la acción final puede tener consecuencias desastrosas. Un cambio en la proporción del volumen de posiciones, un ligero cambio en los niveles comerciales y, más aún, una interpretación incorrecta de la dinámica del mercado: todo ello puede provocar pérdidas sustanciales y, como consecuencia, una disminución de la confianza en el sistema.
En el modelo para predecir las probabilidades de la dirección del próximo movimiento, introducimos solo ediciones puntuales relacionadas con la transferencia del estado latente del Codificador de descripción del entorno desde el módulo de generación de habilidades genéricas al bloque recurrente. Este pequeño pero importante cambio pretende mejorar la capacidad del modelo para considerar las dependencias temporales y adaptarse a las cambiantes condiciones del mercado a lo largo del tiempo.
Dado que en el marco de esta sección del artículo nos esforzamos por mantener una presentación compacta, hemos decidido no ofrecer una descripción completa y detallada de las arquitecturas de estos modelos. No obstante, todos los lectores interesados pueden leer la descripción completa y los detalles de la aplicación en el anexo del artículo.
Casi todos los modelos descritos anteriormente forman la estructura jerárquica de Actor dentro del framework Actor-Director-Critic. El siguiente componente importante del framework implementado es el Director (Director), un modelo especializado cuya tarea principal consiste en clasificar contextualmente las acciones del Actor en rentables y no rentables.
El papel del Director no puede sobrestimarse: actúa como un filtro estratégico de calidad, cortando soluciones potencialmente no rentables antes de que se apliquen y provoquen pérdidas financieras. En unos mercados financieros tan volátiles, en los que cualquier error puede salir caro, este mecanismo de evaluación temprana cobra especial importancia.
Una característica especial del enfoque propuesto es que el Director no se limita a categorizar las acciones, sino que también genera retroalimentación de aprendizaje adicional. Esto acelera la adaptación de la estrategia del Actor porque le permite considerar las señales del Director sin tener que acumular repetidamente experiencias negativas. Este mecanismo resulta especialmente eficaz en entornos en los que el coste del error es elevado y el tiempo de formación limitado.
En las implementaciones tradicionales, a la entrada del Director se suministra un tensor de descripción del estado del entorno que refleja directamente las observaciones del Agente. Sin embargo, en nuestra implementación, el Director recibe como entrada una matriz genérica de habilidades, una representación latente informativa generada en el módulo de generación de habilidades a la salida de una unidad LSTM preentrenada para extraer patrones de comportamiento de series temporales multivariantes. Esta representación ya tiene en cuenta la dinámica de los cambios del entorno, se filtra de señales irrelevantes y centra los aspectos más relevantes del contexto actual. Por ello, el Director opera en un espacio de características comprimido y estable, lo que aumenta significativamente la precisión de la clasificación, mejora la estabilidad de las decisiones y permite la adaptación en tiempo real a las condiciones reales del mercado.
En el flujo de información principal, el tensor de acción del Agente se introduce en la entrada del Director, que inmediatamente normalizamos.
//--- Director director.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = NActions; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
El análisis directo de las acciones propuestas por el Actor en el contexto de la situación actual del mercado reflejada en la matriz de habilidades genéricas se realiza en el módulo de atención cruzada. Aquí es donde tiene lugar la comparación semántica entre lo que el agente pretende hacer y lo que realmente es pertinente y está justificado en el momento actual en cuando a la dinámica del mercado.
El mecanismo de atención cruzada permite al Director destacar las relaciones entre los componentes individuales del tensor de acciones y los características de la matriz de habilidades genéricas. Esto resulta especialmente importante en mercados muy volátiles en los que las relaciones lineales simples ya no funcionan. La atención cruzada permite esencialmente al modelo centrarse en aquellos aspectos del comportamiento del Agente que resultan más críticos en una situación concreta.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {3, // Inputs window latent.count // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {NActions/3, // Inputs units latent.layers // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
La salida del módulo de atención cruzada genera una representación semánticamente rica de la acción del Actor, ya adaptada al contexto actual del mercado. Esta representación refleja no solo la intención del Agente, sino su adecuación a la situación actual, teniendo en cuenta la totalidad de los patrones identificados y las relaciones entre acciones y habilidades generales.
Esta representación enriquecida por el contexto se convierte en la base de la última etapa de procesamiento: la clasificación de la acción según su rentabilidad potencial.
El procedimiento de clasificación se implementa usando una secuencia de tres capas neuronales totalmente conectadas, cada una de las cuales está equipada con su propia función de activación para introducir la no linealidad necesaria en los datos procesados. Esta cascada ofrece al modelo la flexibilidad necesaria para aproximarse a límites de decisión complejos, formando una separación más precisa entre acciones rentables y no rentables.
La última capa usa una función de activación sigmoidal para interpretar la salida del modelo como una estimación probabilística de si una acción pertenece a una de las dos clases. Así, el modelo no se limita a emitir un juicio binario, sino que ofrece una puntuación de confianza sobre la corrección de su clasificación.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 1; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
Cabe señalar que el modelo del Crítico dentro de esta aplicación se ha dotado de una arquitectura similar. Al igual que con el Director, se utiliza un módulo de atención cruzada para relacionar las acciones propuestas por el Actor con el contexto del entorno actual representado a través de la matriz de habilidades genéricas. Esto permite evaluar con mayor precisión las consecuencias de la acción elegida dadas las complejas dependencias entre el comportamiento del agente y la dinámica oculta del mercado.
Sin embargo, hay una diferencia crucial en la parte final de la arquitectura del Crítico. A diferencia del Director, que utiliza una sigmoidea para interpretar el resultado de forma probabilística, la capa de salida del Crítico no contiene una función de activación. Esto se debe a la naturaleza del valor objetivo: el valor esperado de la recompensa acumulada, que puede situarse en un rango prácticamente ilimitado.
En otras palabras, el resultado del Crítico es una estimación escalar de la utilidad de una acción propuesta en el contexto actual, expresada en unidades condicionales de ingresos esperados. Aplicar una función de activación limitadora distorsionaría el significado de esta cantidad al recortar los valores atípicos potencialmente importantes. Por ello, el valor final se suministra directamente, lo que permite al modelo variar libremente las puntuaciones según las representaciones entrenadas del entorno.
Pero esto no es más que un ajuste puntual de la arquitectura del modelo. Por consiguiente, en el ámbito de este artículo, omitiremos un examen detallado de la arquitectura del Crítico. En el anexo se ofrece una descripción completa de la arquitectura de los modelos descritos, que podrá estudiar por sí mismo.
Por desgracia, inmersos como estamos en el repaso detallado de las soluciones arquitectónicas utilizadas, casi hemos agotado la extensión del artículo. Así que haremos una merecida pausa: en el próximo artículo hablaremos del proceso de entrenamiento del modelo, y evaluaremos la eficacia de la solución implementada con datos históricos reales.
Conclusión
En este artículo, nos hemos familiarizado con el nuevo framework Actor-Director-Critic, diseñado para resolver problemas utilizando aprendizaje profundo y redes neuronales. Uno de los aspectos clave de este framework es la introducción del modelo de Director, que categoriza las acciones del Actor en el contexto del estado actual del entorno, permitiendo aumentar considerablemente la eficacia y la estabilidad del proceso de aprendizaje.
En la parte práctica del artículo, hemos analizado con detalle la arquitectura de los modelos entrenados que subyacen en el framework Actor-Director-Critic. Asimismo, hemos descrito detalladamente los principios de utilización de los distintos módulos y presentado los puntos importantes en los que se basa cada componente del sistema.
En el próximo artículo analizaremos con detalle el proceso de construcción de los programas necesarios para entrenar los modelos presentados, y también realizaremos una valoración de su rendimiento con datos históricos reales.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17796
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso