
Ciência de Dados e ML (Parte 35): NumPy em MQL5 – A Arte de Desenvolver Algoritmos Complexos com Menos Código

Conteúdo
- Introdução
- Por que NumPy?
- Inicialização de Vetores e Matrizes
- Funções Matemáticas
- Funções Estatísticas
- Geradores de Números Aleatórios
- - Distribuição Uniforme
- - Distribuição Normal
- - Distribuição Exponencial
- - Distribuição Binomial
- - Distribuição de Poisson
- - Embaralhamento
- - Escolha Aleatória
- Transformada Rápida de Fourier (FFT)
- - Transformadas Rápidas de Fourier Padrão
- Álgebra Linear
- Polinômios (séries de potência)
- Métodos NumPy comumente utilizados
- Codificação de modelos de ML do zero
- Conclusão
Acredite que você pode e você já está no meio do caminho
-- Theodore Roosevelt.
Introdução
Nenhuma linguagem de programação é totalmente autossuficiente para todas as tarefas que possamos imaginar implementar em código, toda linguagem de programação depende de ferramentas bem elaboradas, que são bibliotecas, frameworks e módulos, para ajudar a resolver determinados problemas e transformar algumas ideias em realidade.
MQL5 não é exceção. Projetada principalmente para negociação algorítmica, sua funcionalidade inicial era majoritariamente limitada a operações de negociação. Ao contrário de sua predecessora, MQL4 — considerada uma linguagem mais fraca — MQL5 é muito mais poderosa e capaz. No entanto, construir um robô de negociação totalmente funcional requer mais do que simplesmente chamar funções para executar ordens de compra e venda.
Para lidar com as complexidades dos mercados financeiros, os traders frequentemente utilizam operações matemáticas sofisticadas, incluindo aprendizado de máquina e Inteligência Artificial (AI). Isso criou uma demanda crescente por bases de código otimizadas e frameworks especializados capazes de lidar com cálculos complexos de forma eficiente.

Por que NumPy?
Quando se trata de lidar com cálculos complexos em MQL5, temos muitas boas bibliotecas fornecidas pela MetaQuotes, como aquelas encontradas em Fuzzy, Stat e a poderosa Alglib (encontrada no MetaEditor em MQL5\Include\Math).
Essas bibliotecas possuem muitas funções adequadas para programar expert advisors complexos com esforço mínimo, no entanto, a maioria das funções nessas bibliotecas não é tão flexível devido ao uso excessivo de arrays e ponteiros de objetos, sem mencionar que algumas exigem conhecimento matemático para serem utilizadas corretamente.
Desde a introdução de Matrizes e Vetores a linguagem MQL5 tornou-se mais versátil e flexível quando se trata de armazenamento de dados e cálculos, esses arrays na forma de objetos são acompanhados por muitas funções matemáticas integradas que anteriormente exigiam implementações manuais.
Devido à flexibilidade de matrizes e vetores, podemos expandi-los para algo maior, criando uma coleção de várias funções matemáticas semelhantes às presentes no NumPy (Numerical Python, uma biblioteca Python que oferece uma coleção de funções matemáticas de alto nível, incluindo suporte para arrays multidimensionais, arrays mascarados e matrizes).
É justo dizer que a maioria das funções oferecidas por matrizes e vetores em MQL5 foi inspirada no NumPy, como pode ser visto na documentação, a sintaxe é muito semelhante.
MQL5 | Python |
|---|---|
vector::Zeros(3); vector::Full(10); | numpy.zeros(3) numpy.full(10) |
De acordo com a documentação, essa sintaxe semelhante foi introduzida para "facilitar a tradução de algoritmos e códigos de Python para MQL5 com o mínimo de esforço. Muitas tarefas de processamento de dados, equações matemáticas, redes neurais e tarefas de aprendizado de máquina podem ser resolvidas usando métodos e bibliotecas Python prontos".
Isso é verdade, mas as funções fornecidas por matrizes e vetores não são suficientes. Ainda faltam muitas funções cruciais que frequentemente precisamos para traduzir esses algoritmos e códigos de Python para MQL5; neste artigo, implementaremos algumas das funções e métodos mais úteis do NumPy em MQL5 utilizando uma sintaxe muito próxima para tornar muito mais fácil a tradução de algoritmos da linguagem de programação Python.
Para manter a sintaxe semelhante à do Python, implementaremos os nomes das funções em letras minúsculas. Começando com métodos para inicialização de vetores e matrizes.
Inicialização de Vetores e Matrizes
Para trabalhar com vetores e matrizes, precisamos ter métodos para inicializá-los preenchendo-os com alguns valores. Abaixo estão algumas das funções para essa tarefa.
Método | Descrição |
|---|---|
template <typename T> vector CNumpy::full(uint size, T fill_value) { return vector::Full(size, fill_value); } template <typename T> matrix CNumpy::full(uint rows, uint cols, T fill_value) { return matrix::Full(rows, cols, fill_value); } | Constrói um novo vetor/matriz de tamanho/linhas e colunas definidos, preenchido com um valor. |
vector CNumpy::ones(uint size) { return vector::Ones(size); } matrix CNumpy::ones(uint rows, uint cols) { return matrix::Ones(rows, cols); } | Constrói um novo vetor de um tamanho definido/matriz de linhas e colunas definidas, preenchido com uns |
vector CNumpy::zeros(uint size) { return vector::Zeros(size); } matrix CNumpy::zeros(uint rows, uint cols) { return matrix::Zeros(rows, cols); } | Constrói um vetor de um tamanho definido/matriz de linhas e colunas definidas, preenchido com zeros |
matrix CNumpy::eye(const uint rows, const uint cols, const int ndiag=0) { return matrix::Eye(rows, cols, ndiag); } | Constrói uma matriz com uns na diagonal e zeros nos demais elementos. |
matrix CNumpy::identity(uint rows) { return matrix::Identity(rows, rows); } | Constrói uma matriz quadrada com uns na diagonal principal. |
Apesar de sua simplicidade, esses métodos são cruciais na criação de matrizes e vetores de apoio que são frequentemente usados em transformações, padding e aumentos.
Exemplo de uso:
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Initialization // Vectors One-dimensional Print("numpy.full: ",np.full(10, 2)); Print("numpy.ones: ",np.ones(10)); Print("numpy.zeros: ",np.zeros(10)); // Matrices Two-Dimensional Print("numpy.full:\n",np.full(3,3, 2)); Print("numpy.ones:\n",np.ones(3,3)); Print("numpy.zeros:\n",np.zeros(3,3)); Print("numpy.eye:\n",np.eye(3,3)); Print("numpy.identity:\n",np.identity(3)); }
Funções Matemáticas
Este é um assunto amplo, pois há muitas funções matemáticas para implementar e descrever tanto para vetores quanto para matrizes, e discutiremos apenas algumas delas. Começando com constantes matemáticas.
Constantes
Constantes matemáticas são tão úteis quanto as funções.
Constant | Descrição |
|---|---|
numpy.e | Constante de Euler, base dos logaritmos naturais, constante de Napier. |
numpy.euler_gamma | Definida como a diferença limite entre a série harmônica e o logaritmo natural. |
np.inf | Representação de ponto flutuante IEEE 754 do infinito (positivo). |
np.nan |
|
| np.pi | Aproximadamente igual a 3.14159, que é a razão entre a circunferência de um círculo e seu diâmetro. |
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Mathematical functions Print("numpy.e: ",np.e); Print("numpy.euler_gamma: ",np.euler_gamma); Print("numpy.inf: ",np.inf); Print("numpy.nan: ",np.nan); Print("numpy.pi: ",np.pi); }
Funções
Abaixo estão algumas das funções presentes na classe CNumpy.
| Método | Descrição |
|---|---|
vector CNumpy::add(const vector&a, const vector&b) { return a+b; }; matrix CNumpy::add(const matrix&a, const matrix&b) { return a+b; }; | Soma dois vetores/matrizes. |
vector CNumpy::subtract(const vector&a, const vector&b) { return a-b; }; matrix CNumpy::subtract(const matrix&a, const matrix&b) { return a-b; }; | Subtrai dois vetores/matrizes. |
vector CNumpy::multiply(const vector&a, const vector&b) { return a*b; }; matrix CNumpy::multiply(const matrix&a, const matrix&b) { return a*b; }; | Multiplica dois vetores/matrizes. |
vector CNumpy::divide(const vector&a, const vector&b) { return a/b; }; matrix CNumpy::divide(const matrix&a, const matrix&b) { return a/b; }; | Divide dois vetores/matrizes |
vector CNumpy::power(const vector&a, double n) { return MathPow(a, n); }; matrix CNumpy::power(const matrix&a, double n) { return MathPow(a, n); }; | Eleva todos os elementos da matriz/vetor a à potência n. |
vector CNumpy::sqrt(const vector&a) { return MathSqrt(a); }; matrix CNumpy::sqrt(const matrix&a) { return MathSqrt(a); }; | Calcula a raiz quadrada de cada elemento no vetor/matriz a. |
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Mathematical functions vector a = {1,2,3,4,5}; vector b = {1,2,3,4,5}; Print("np.add: ",np.add(a, b)); Print("np.subtract: ",np.subtract(a, b)); Print("np.multiply: ",np.multiply(a, b)); Print("np.divide: ",np.divide(a, b)); Print("np.power: ",np.power(a, 2)); Print("np.sqrt: ",np.sqrt(a)); Print("np.log: ",np.log(a)); Print("np.log1p: ",np.log1p(a)); }
Funções Estatísticas
Estas também podem ser classificadas como funções matemáticas, mas ao contrário das operações matemáticas básicas, essas funções ajudam a fornecer métricas analíticas a partir dos dados fornecidos. Em Aprendizado de Máquina, elas são usadas principalmente na engenharia de atributos e normalização.
A tabela abaixo representa algumas das funções implementadas na classe MQL5-Numpy.
Método | Descrição |
|---|---|
double sum(const vector& v) { return v.Sum(); } double sum(const matrix& m) { return m.Sum(); }; vector sum(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Sum(axis); }; | Calcula a soma dos elementos do vetor/matriz, que também pode ser realizada para o eixo (ou eixos) fornecido. |
double mean(const vector& v) { return v.Mean(); } double mean(const matrix& m) { return m.Mean(); }; vector mean(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Mean(axis); }; |
|
double var(const vector& v) { return v.Var(); } double var(const matrix& m) { return m.Var(); }; vector var(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Var(axis); }; |
|
double std(const vector& v) { return v.Std(); } double std(const matrix& m) { return m.Std(); }; vector std(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Std(axis); }; |
|
double median(const vector& v) { return v.Median(); } double median(const matrix& m) { return m.Median(); }; vector median(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Median(axis); }; | Calcula a mediana dos elementos do vetor/matriz. |
double percentile(const vector &v, int value) { return v.Percentile(value); } double percentile(const matrix &m, int value) { return m.Percentile(value); } vector percentile(const matrix &m, int value, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Percentile(value, axis); } | Essas funções calculam o percentil especificado dos valores dos elementos de um vetor/matriz ou dos elementos ao longo do eixo especificado. |
double quantile(const vector &v, int quantile_) { return v.Quantile(quantile_); } double quantile(const matrix &m, int quantile_) { return m.Quantile(quantile_); } vector quantile(const matrix &m, int quantile_, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Quantile(quantile_, axis); } | Elas calculam o quantil especificado dos valores dos elementos da matriz/vetor ou dos elementos ao longo do eixo especificado. |
vector cumsum(const vector& v) { return v.CumSum(); }; vector cumsum(const matrix& m) { return m.CumSum(); }; matrix cumsum(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.CumSum(axis); }; | Essas funções calculam a soma cumulativa dos elementos da matriz/vetor, incluindo aqueles ao longo do eixo fornecido. |
vector cumprod(const vector& v) { return v.CumProd(); } vector cumprod(const matrix& m) { return m.CumProd(); }; matrix cumprod(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.CumProd(axis); }; | Elas retornam o produto cumulativo dos elementos da matriz/vetor, incluindo aqueles ao longo do eixo fornecido. |
double average(const vector &v, const vector &weights) { return v.Average(weights); } double average(const matrix &m, const matrix &weights) { return m.Average(weights); } vector average(const matrix &m, const matrix &weights, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Average(weights, axis); } |
|
ulong argmax(const vector& v) { return v.ArgMax(); } ulong argmax(const matrix& m) { return m.ArgMax(); } vector argmax(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.ArgMax(axis); }; | Retornam o índice do valor máximo. |
ulong argmin(const vector& v) { return v.ArgMin(); } ulong argmin(const matrix& m) { return m.ArgMin(); } vector argmin(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.ArgMin(axis); }; | Retornam o índice do valor mínimo. |
double min(const vector& v) { return v.Min(); } double min(const matrix& m) { return m.Min(); } vector min(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Min(axis); }; | Retornam o valor mínimo em um vetor/matriz, incluindo aqueles ao longo do eixo especificado. |
double max(const vector& v) { return v.Max(); } double max(const matrix& m) { return m.Max(); } vector max(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Max(axis); }; | Retornam o valor máximo em um vetor/matriz, incluindo aqueles ao longo do eixo especificado. |
double prod(const vector &v, double initial=1.0) { return v.Prod(initial); } double prod(const matrix &m, double initial) { return m.Prod(initial); } vector prod(const matrix &m, double initial, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Prod(axis, initial); } | Retornam o produto dos elementos da matriz/vetor, que também pode ser realizado para o eixo fornecido. |
double ptp(const vector &v) { return v.Ptp(); } double ptp(const matrix &m) { return m.Ptp(); } vector ptp(const matrix &m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Ptp(axis); } | Retornam o intervalo de valores de uma matriz/vetor ou do eixo fornecido da matriz, equivalente a Max() - Min(). Ptp - Pico a pico. |
Essas funções são baseadas em funções estatísticas integradas para vetores e matrizes, como pode ser visto na documentação, tudo o que fiz foi criar uma sintaxe semelhante ao NumPy e encapsular essas funções.
Abaixo está um exemplo de como usar essas funções.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Statistical functions vector z = {1,2,3,4,5}; Print("np.sum: ", np.sum(z)); Print("np.mean: ", np.mean(z)); Print("np.var: ", np.var(z)); Print("np.std: ", np.std(z)); Print("np.median: ", np.median(z)); Print("np.percentile: ", np.percentile(z, 75)); Print("np.quantile: ", np.quantile(z, 75)); Print("np.argmax: ", np.argmax(z)); Print("np.argmin: ", np.argmin(z)); Print("np.max: ", np.max(z)); Print("np.min: ", np.min(z)); Print("np.cumsum: ", np.cumsum(z)); Print("np.cumprod: ", np.cumprod(z)); Print("np.prod: ", np.prod(z)); vector weights = {0.2,0.1,0.5,0.2,0.01}; Print("np.average: ", np.average(z, weights)); Print("np.ptp: ", np.ptp(z)); }
Geradores de Números Aleatórios
O NumPy possui vários submódulos úteis, sendo um deles o submódulo random.
O submódulo numpy.random fornece várias funções de geração de números aleatórios baseadas no gerador PCG64 (a partir do NumPy 1.17+). A maioria desses métodos é baseada em princípios matemáticos da teoriada probabilidade e distribuições estatísticas.
Em ML, frequentemente geramos números aleatórios para muitos casos de uso; geramos números aleatórios como pesos iniciais para redes neurais e muitos modelos que utilizam métodos iterativos baseados em descida de gradiente para treinamento, às vezes até geramos atributos aleatórios que seguem distribuição estatística para obter dados de teste para nossos modelos.
É muito importante que os números aleatórios que geramos sigam uma distribuição estatística, algo que não conseguimos alcançar utilizando as funções nativas/integradas de geração de números aleatórios no MQL5.
Primeiramente, veja como você pode definir a semente aleatória para o submódulo CNumpy.random.
np.random.seed(42); Distribuição Uniforme #
Geramos números aleatórios a partir de uma distribuição uniforme entre alguns valores mínimo e máximo.
Fórmula:
Onde R é um número aleatório em [0,1].
template <typename T> vector uniform(T low, T high, uint size=1) { vector res = vector::Zeros(size); for (uint i=0; i<size; i++) res[i] = low + (high - low) * (rand() / double(RAND_MAX)); // Normalize rand() return res; }
Uso.
Dentro do arquivo Numpy.mqh, uma estrutura separada foi criada com o nome CRandom, que então é chamada dentro da classe CNumpy, isso nos permite chamar uma estrutura dentro de uma classe, fornecendo uma sintaxe semelhante à do Python.
class CNumpy { protected: public: CNumpy(void); ~CNumpy(void); CRandom random; }
Print("np.random.uniform: ",np.random.uniform(1,10,10));
Saídas.
2025.03.16 15:03:15.102 Numpy np.random.uniform: [8.906552323984496,9.274605548265022,7.828760643330179,9.355082857753228,2.218420972319712,5.772331919309061,3.76067384868923,6.096438489944151,1.93908505508591,8.107272560808131]
Podemos visualizar os resultados para verificar se os dados estão distribuídos uniformemente.
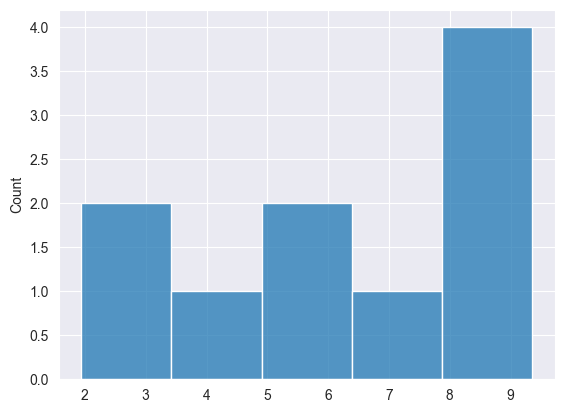
Distribuição Normal #
Este método é utilizado em muitos modelos de ML, como na inicialização de pesos de redes neurais.
Podemos implementar usando a transformação de Box-Muller.
Fórmula:
Onde:
![]() são números aleatórios em [0,1]
são números aleatórios em [0,1]
vector normal(uint size, double mean=0, double std=1) { vector results = {}; // Declare the results vector // We generate two random values in each iteration of the loop uint n = size / 2 + size % 2; // If the size is odd, we need one extra iteration // Loop to generate pairs of normal numbers for (uint i = 0; i < n; i++) { // Generate two random uniform variables double u1 = MathRand() / 32768.0; // Uniform [0,1] -> (MathRand() generates values from 0 to 32767) double u2 = MathRand() / 32768.0; // Uniform [0,1] // Apply the Box-Muller transform to get two normal variables double z1 = MathSqrt(-2 * MathLog(u1)) * MathCos(2 * M_PI * u2); double z2 = MathSqrt(-2 * MathLog(u1)) * MathSin(2 * M_PI * u2); // Scale to the desired mean and standard deviation, and add them to the results results = push_back(results, mean + std * z1); if ((uint)results.Size() < size) // Only add z2 if the size is not reached yet results = push_back(results, mean + std * z2); } // Return only the exact size of the results (if it's odd, we cut off one value) results.Resize(size); return results; }
Uso.
Print("np.random.normal: ",np.random.normal(10,0,1));
Saídas.
2025.03.16 15:33:08.791 Numpy test (US Tech 100,H1) np.random.normal: [-1.550635379340936,0.963285267506685,0.4587699653416977,-0.4813064556591148,-0.6919587880027229,1.649030932484221,-2.433415738330552,2.598464400400878,-0.2363726420659525,-0.1131299501178828]
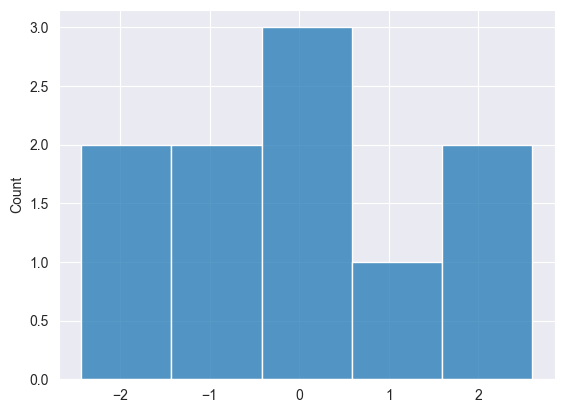
Distribuição Exponencial #
A distribuição Exponencial é uma distribuição de probabilidade que descreve o tempo entre eventos em um processo de Poisson, onde os eventos ocorrem continuamente e independentemente a uma taxa média constante.
Dada pela fórmula:
Para gerar números aleatórios com distribuição exponencial, usamos o método de amostragem por transformação inversa. A fórmula é.
Onde:
-
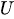 é um número aleatório uniforme entre 0 e 1.
é um número aleatório uniforme entre 0 e 1. -
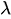 é o parâmetro de taxa.
é o parâmetro de taxa.
vector exponential(uint size, double lmbda=1.0) { vector res = vector::Zeros(size); for (uint i=0; i<size; i++) res[i] = -log((rand()/RAND_MAX)) / lmbda; return res; }
Uso.
Print("np.random.exponential: ",np.random.exponential(10));
Saídas.
2025.03.16 15:57:36.124 Numpy test (US Tech 100,H1) np.random.exponential: [0.4850272647406031,0.7617651806321184,1.09800210467871,2.658253432915927,0.5814831387699247,0.9920104404467721,0.7427922283035616,0.09323707153463576,0.2963563234048633,1.790326127008611]
Distribuição Binomial #
Esta é uma distribuição de probabilidade discreta que modela o número de sucessos em um número fixo de ensaios independentes, cada um com a mesma probabilidade de sucesso.
Dada pela fórmula.
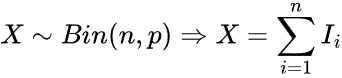
Podemos implementá-la da seguinte forma.
// Function to generate a single Bernoulli(p) trial int bernoulli(double p) { return (double)rand() / RAND_MAX < p ? 1 : 0; }
// Function to generate Binomial(n, p) samples vector binomial(uint size, uint n, double p) { vector res = vector::Zeros(size); for (uint i = 0; i < size; i++) { int count = 0; for (uint j = 0; j < n; j++) count += bernoulli(p); // Sum of Bernoulli trials res[i] = count; } return res; }
Uso.
Print("np.random.binomial: ",np.random.binomial(10, 5, 0.5));
Saídas.
2025.03.16 19:35:20.346 Numpy test (US Tech 100,H1) np.random.binomial: [2,1,2,3,2,1,1,4,0,3]
Distribuição de Poisson #
Esta é uma distribuição de probabilidade que expressa a probabilidade de um determinado número de eventos ocorrer em um intervalo fixo de tempo ou espaço, dado que esses eventos acontecem a uma taxa média constante e independentemente do tempo desde o último evento.
Fórmula:
Onde:
-
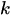 é o número de ocorrências (0,1,2...)
é o número de ocorrências (0,1,2...) -
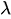 (lambda) é a taxa média de ocorrências.
(lambda) é a taxa média de ocorrências. - e é o número de Euler.
int poisson(double lambda) { double L = exp(-lambda); double p = 1.0; int k = 0; while (p > L) { k++; p *= MathRand() / 32767.0; // Normalize MathRand() to (0,1) } return k - 1; // Since we increment k before checking the condition }
// We generate a vector of Poisson-distributed values vector poisson(double lambda, int size) { vector result = vector::Zeros(size); for (int i = 0; i < size; i++) result[i] = poisson(lambda); return result; }
Uso.
Print("np.random.poisson: ",np.random.poisson(4, 10));
Saídas.
2025.03.16 18:39:56.058 Numpy test (US Tech 100,H1) np.random.poisson: [6,6,5,1,3,1,1,3,6,7]
Embaralhamento #
Ao tentar treinar modelos de aprendizado e máquina para compreender padrões nos dados, frequentemente embaralhamos as amostras para ajudar os modelos a entenderem os padrões presentes nos dados e não a organização dos dados.
A funcionalidade de embaralhamento é útil nessa situação.
Exemplo de uso.
vector data = {1,2,3,4,5,6,7,8,9,10}; np.random.shuffle(data); Print("Shuffled: ",data);
Saídas.
2025.03.16 18:55:36.763 Numpy test (US Tech 100,H1) Shuffled: [6,4,9,2,3,10,1,7,8,5]
Escolha Aleatória #
De forma semelhante ao embaralhamento, esta função amostra o vetor unidimensional fornecido aleatoriamente, mas com a opção de embaralhar com ou sem reposição.
template<typename T> vector<T> choice(const vector<T> &v, uint size, bool replace=false)
Com reposição
Os valores não serão únicos, os mesmos itens podem se repetir no vetor/array embaralhado resultante.
vector data = {1,2,3,4,5,6,7,8,9,10}; Print("np.random.choice replace=True: ",np.random.choice(data, (uint)data.Size(), true));
Saídas.
2025.03.16 19:11:53.520 Numpy test (US Tech 100,H1) np.random.choice replace=True: [5,3,9,2,1,3,4,7,8,3]
Sem reposição.
O vetor embaralhado resultante terá itens únicos, assim como estavam no vetor original, apenas sua ordem será alterada.
Print("np.random.choice replace=False: ",np.random.choice(data, (uint)data.Size(), false));
Saídas.
2025.03.16 19:11:53.520 Numpy test (US Tech 100,H1) np.random.choice replace=False: [8,4,3,10,5,7,1,9,6,2]
Todas as funções em um único lugar.
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Random numbers generating np.random.seed(42); Print("---------------------------------------:"); Print("np.random.uniform: ",np.random.uniform(1,10,10)); Print("np.random.normal: ",np.random.normal(10,0,1)); Print("np.random.exponential: ",np.random.exponential(10)); Print("np.random.binomial: ",np.random.binomial(10, 5, 0.5)); Print("np.random.poisson: ",np.random.poisson(4, 10)); vector data = {1,2,3,4,5,6,7,8,9,10}; //np.random.shuffle(data); //Print("Shuffled: ",data); Print("np.random.choice replace=True: ",np.random.choice(data, (uint)data.Size(), true)); Print("np.random.choice replace=False: ",np.random.choice(data, (uint)data.Size(), false)); }
Transformada Rápida de Fourier (FFT) #
Uma transformada rápida de Fourier (FFT) é um algoritmo que calcula a transformada discreta de Fourier (DFT) de uma sequência, ou sua inversa (IDFT). Uma transformada de Fourier converte um sinal de seu domínio original (frequentemente tempo ou espaço) para uma representação no domínio da frequência e vice-versa. A DFT é obtida decompondo uma sequência de valores em componentes de diferentes frequências, leia mais.
Esta operação é útil em muitas áreas, como:
- No processamento de sinais e áudio, é usada para converter ondas sonoras do domínio do tempo para espectros de frequência. Na codificação de formatos de áudio e filtragem de ruído.
- Também é utilizada na compressão de imagens e no reconhecimento de padrões em imagens.
- Cientistas de dados frequentemente usam FFT para extrair características de dados de séries temporais.
O submódulo numpy.fft é o responsável por lidar com FFT.
No nosso CNumpy, conforme está atualmente, implementei apenas as funções unidimensionais de FFT padrão.
Antes de explorarmos os métodos de "FFT padrão" implementados na classe, vamos entender a função para gerar frequências DFT.
Frequência FFT
Ao realizar FFT em um sinal ou dado, a saída está no domínio da frequência; para interpretá-la, precisamos saber a qual frequência cada elemento da FFT corresponde. É aqui que esse método entra.
Esta função retorna as frequências de amostra da Transformada Discreta de Fourier (DFT) associadas a uma FFT de um determinado tamanho. Ela ajuda a determinar as frequências correspondentes para cada coeficiente da FFT.
vector fft_freq(int n, double d)
Exemplo de uso.
2025.03.17 11:11:10.165 Numpy test (US Tech 100,H1) np.fft.fftfreq: [0,0.1,0.2,0.3,0.4,-0.5,-0.4,-0.3,-0.2,-0.1]
Transformadas Rápidas de Fourier Padrão #
FFT
Esta função calcula a FFT de um sinal de entrada, convertendo-o do domínio do tempo para o domínio da frequência. É um algoritmo eficiente para calcular a Transformada Discreta de Fourier (DFT).
vector<complex> fft(const vector &x)
Esta função é construída sobre CFastFourierTransform::FFTR1D, uma função fornecida pela ALGLIB. Consulte a ALGLIB para mais informações.
Exemplo de uso.
vector signal = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; Print("np.fft.fft: ",np.fft.fft(signal));
Saídas.
2025.03.17 11:28:16.739 Numpy test (US Tech 100,H1) np.fft.fft: [(4.5,0),(-0.4999999999999999,1.538841768587627),(-0.4999999999999999,0.6881909602355869),(-0.5000000000000002,0.3632712640026804),(-0.5000000000000002,0.1624598481164532),(-0.5,-3.061616997868383E-16),(-0.5000000000000002,-0.1624598481164532),(-0.5000000000000002,-0.3632712640026804),(-0.4999999999999999,-0.6881909602355869),(-0.4999999999999999,-1.538841768587627)]
FFT Inversa
Esta função calcula a Transformada Rápida de Fourier Inversa (IFFT), que converte dados do domínio da frequência de volta para o domínio do tempo. Ela essencialmente desfaz o efeito do método anterior np.fft.fft.
vector ifft(const vectorc &fft_values)
Exemplo de uso.
vector signal = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; vectorc fft_res = np.fft.fft(signal); //perform fft Print("np.fft.fft: ",fft_res); //fft results Print("np.fft.ifft: ",np.fft.ifft(fft_res)); //Original signal
Saídas.
2025.03.17 11:45:04.537 Numpy test np.fft.fft: [(4.5,0),(-0.4999999999999999,1.538841768587627),(-0.4999999999999999,0.6881909602355869),(-0.5000000000000002,0.3632712640026804),(-0.5000000000000002,0.1624598481164532),(-0.5,-3.061616997868383E-16),(-0.5000000000000002,-0.1624598481164532),(-0.5000000000000002,-0.3632712640026804),(-0.4999999999999999,-0.6881909602355869),(-0.4999999999999999,-1.538841768587627)] 2025.03.17 11:45:04.537 Numpy test np.fft.ifft: [-4.440892098500626e-17,0.09999999999999991,0.1999999999999999,0.2999999999999999,0.4,0.5,0.6,0.7,0.8000000000000002,0.9]
Álgebra Linear #
Álgebra linear é um ramo da matemática que lida com vetores, matrizes e transformações lineares. É fundamental para muitas áreas como física, engenharia, ciência de dados, etc.
O NumPy fornece o módulo np.linalg, um submódulo dedicado às funções de álgebra linear. Ele oferece praticamente todas as funções de álgebra linear, como resolução de sistemas lineares, cálculo de autovalores/autovetores e muito mais.
Abaixo estão algumas das funções de álgebra linear implementadas na classe CNumpy.
Método | Descrição |
|---|---|
matrix inv(const matrix &m) { return m.Inv(); } | Calcula o inverso multiplicativo de uma matriz quadrada invertível pelo método de Jordan-Gauss. |
double det(const matrix &m) { return m.Det(); } | Calcula o determinante de uma matriz quadrada invertível. |
matrix kron(const matrix &a, const matrix &b) { return a.Kron(b); } matrix kron(const vector &a, const vector &b) { return a.Kron(b); } matrix kron(const vector &a, const matrix &b) { return a.Kron(b); } matrix kron(const matrix &a, const vector &b) { return a.Kron(b); } | Calculam o produto de Kronecker entre duas matrizes, matriz e vetor, vetor e matriz ou dois vetores. |
struct eigen_results_struct { vector eigenvalues; matrix eigenvectors; }; eigen_results_struct eig(const matrix &m) { eigen_results_struct res; if (!m.Eig(res.eigenvectors, res.eigenvalues)) printf("%s failed to calculate eigen vectors and values, error = %d",__FUNCTION__,GetLastError()); return res; } | Esta função calcula os autovalores e autovetores à direita de uma matriz quadrada. |
double norm(const matrix &m, ENUM_MATRIX_NORM norm) { return m.Norm(norm); } double norm(const vector &v, ENUM_VECTOR_NORM norm) { return v.Norm(norm); } | Retorna a norma de uma matriz ou vetor, leia mais. |
svd_results_struct svd(const matrix &m) { svd_results_struct res; if (!m.SVD(res.U, res.V, res.singular_vectors)) printf("%s failed to calculate the SVD"); return res; } | Calcula a Decomposição em Valores Singulares (SVD). |
vector solve(const matrix &a, const vector &b) { return a.Solve(b); } | Resolve uma equação matricial linear, ou sistema de equações algébricas lineares. |
vector lstsq(const matrix &a, const vector &b) { return a.LstSq(b); } | Calcula a solução de mínimos quadrados de equações algébricas lineares (para matrizes não quadradas ou degeneradas). |
ulong matrix_rank(const matrix &m) { return m.Rank(); } | Esta função calcula o posto de uma matriz, que é o número de linhas ou colunas linearmente independentes na matriz. É um conceito-chave para entender o espaço de solução de um sistema de equações lineares. |
matrix cholesky(const matrix &m) { vector values = eig(m).eigenvalues; for (ulong i=0; i<values.Size(); i++) { if (values[i]<=0) { printf("%s Failed Matrix is not positive definite",__FUNCTION__); return matrix::Zeros(0,0); } } matrix L; if (!m.Cholesky(L)) printf("%s Failed, Error = %d",__FUNCTION__, GetLastError()); return L; } | A decomposição de Cholesky é usada para fatorar uma matriz definida positiva no produto de uma matriz triangular inferior e sua transposta. |
matrix matrix_power(const matrix &m, uint exponent) { return m.Power(exponent); } | Calcula a matriz elevada a uma potência inteira específica. Mais formalmente, calcula |
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Linear algebra matrix m = {{1,1,10}, {1,0.5,1}, {1.5,1,0.78}}; Print("np.linalg.inv:\n",np.linalg.inv(m)); Print("np.linalg.det: ",np.linalg.det(m)); Print("np.linalg.det: ",np.linalg.kron(m, m)); Print("np.linalg.eigenvalues:",np.linalg.eig(m).eigenvalues," eigenvectors: ",np.linalg.eig(m).eigenvectors); Print("np.linalg.norm: ",np.linalg.norm(m, MATRIX_NORM_P2)); Print("np.linalg.svd u:\n",np.linalg.svd(m).U, "\nv:\n",np.linalg.svd(m).V); matrix a = {{1,1,10}, {1,0.5,1}, {1.5,1,0.78}}; vector b = {1,2,3}; Print("np.linalg.solve ",np.linalg.solve(a, b)); Print("np.linalg.lstsq: ", np.linalg.lstsq(a, b)); Print("np.linalg.matrix_rank: ", np.linalg.matrix_rank(a)); Print("cholesky: ", np.linalg.cholesky(a)); Print("matrix_power:\n", np.linalg.matrix_power(a, 2)); }
Polinômios (Séries de Potência) #
O submódulo numpy.polynomial fornece um conjunto de ferramentas poderosas para criar, avaliar, diferenciar, integrar e manipular polinômios. Ele é mais estável numericamente do que usar numpy.poly1d para operações com polinômios.
Existem diferentes tipos de polinômios na biblioteca NumPy na linguagem de programação Python, porém, na nossa classe CNumpy-MQL5, implementei atualmente uma base de potência padrão (Polynomial).
class CPolynomial: protected CNumpy { protected: vector m_coeff; matrix vector21DMatrix(const vector &v) { matrix res = matrix::Zeros(v.Size(), 1); for (ulong r=0; r<v.Size(); r++) res[r][0] = v[r]; return res; } public: CPolynomial(void); CPolynomial(vector &coefficients); //for loading pre-trained model ~CPolynomial(void); vector fit(const vector &x, const vector &y, int degree); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::CPolynomial(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::~CPolynomial(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::CPolynomial(vector &coefficients): m_coeff(coefficients) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CPolynomial::fit(const vector &x, const vector &y, int degree) { //Constructing the vandermonde matrix matrix X = vander(x, degree+1, true); matrix temp1 = X.Transpose().MatMul(X); matrix temp2 = X.Transpose().MatMul(vector21DMatrix(y)); matrix coef_m = linalg.inv(temp1).MatMul(temp2); return (this.m_coeff = flatten(coef_m)); }
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Polynomial vector X = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; vector y = MathPow(X, 3) + 0.2 * np.random.randn(10); // Cubic function with noise CPolynomial poly; Print("coef: ", poly.fit(X, y, 3)); }
Saídas.
2025.03.17 14:01:43.026 Numpy test (US Tech 100,H1) coef: [-0.1905916844269999,2.3719065699851,-5.625684489899982,4.749058310806731]
Além disso, existem funções utilitárias para auxiliar na manipulação de polinômios, localizadas na classe principal CNumpy, essas funções incluem.
Função | Descrição |
|---|---|
vector polyadd(const vector &p, const vector &q); | Soma dois polinômios alinhando-os com base no seu grau (comprimento dos coeficientes). Se um polinômio for menor, ele é preenchido com zeros antes de realizar a soma. |
vector polysub(const vector &p, const vector &q); | Subtrai dois polinômios. |
vector polymul(const vector &p, const vector &q); | Multiplica dois polinômios usando a propriedade distributiva, cada termo de p é multiplicado por cada termo de q e os resultados são somados. |
vector polyder(const vector &p, int m=1); | Calcula as derivadas do polinômio p, a derivada é calculada aplicando a regra padrão de derivação. Cada termo |
vector polyint(const vector &p, int m=1, double k=0.0) | Calcula a integral do polinômio p, a integral de cada termo |
double polyval(const vector &p, double x); | Avalia o polinômio em um valor específico x somando os termos do polinômio, onde cada termo é calculado como |
struct polydiv_struct { vector quotient, remainder; }; polydiv_struct polydiv(const vector &p, const vector &q); | Esta função divide dois polinômios e retorna o quociente e o resto. |
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Polynomial utils vector p = {1,-3, 2}; vector q = {2,-4, 1}; Print("polyadd: ",np.polyadd(p, q)); Print("polysub: ",np.polysub(p, q)); Print("polymul: ",np.polymul(p, q)); Print("polyder:", np.polyder(p)); Print("polyint:", np.polyint(p)); // Integral of polynomial Print("plyval x=2: ", np.polyval(p, 2)); // Evaluate polynomial at x = 2 Print("polydiv:", np.polydiv(p, q).quotient," ",np.polydiv(p, q).remainder); }
Outros métodos NumPy comumente utilizados
É difícil classificar todos os métodos do NumPy, abaixo estão algumas das funções mais úteis da classe que ainda não discutimos.
Método | Descrição |
|---|---|
vector CNumpy::arange(uint stop) vector CNumpy::arange(int start, int stop, int step) | A primeira função cria um vetor com um intervalo de valores em um intervalo especificado. A segunda variante faz a mesma coisa, mas considera o passo para incrementar os valores. Essas duas funções são úteis para gerar um vetor de números em ordem crescente. |
vector CNumpy::flatten(const matrix &m) vector CNumpy::ravel(const matrix &m) { return flatten(m); }; | Elas transformam uma matriz 2D em um vetor 1D. Frequentemente terminamos com uma matriz de talvez uma linha e uma coluna que precisa ser convertida em um vetor para facilitar o uso. |
matrix CNumpy::reshape(const vector &v,uint rows,uint cols) | Redimensiona um vetor 1D em uma matriz de linhas e colunas (cols). |
matrix CNumpy::reshape(const matrix &m,uint rows,uint cols) | Redimensiona uma matriz 2D em uma nova forma (rows e cols). |
matrix CNumpy::expand_dims(const vector &v, uint axis) | Adiciona um novo axis ao vetor 1D, convertendo-o efetivamente em uma matriz. |
vector CNumpy::clip(const vector &v,double min,double max) | Limita os valores em um vetor para que fiquem dentro de um intervalo especificado (entre valores mínimo e máximo), útil para reduzir valores extremos e manter o vetor dentro de um intervalo desejado. |
vector CNumpy::argsort(const vector<T> &v) | Retorna os índices que ordenariam um array. |
vector CNumpy::sort(const vector<T> &v) | Ordena um array em ordem crescente. |
vector CNumpy::concat(const vector &v1, const vector &v2); vector CNumpy::concat(const vector &v1, const vector &v2, const vector &v3); | Concatena mais de um vetor em um único vetor grande. |
matrix CNumpy::concat(const matrix &m1, const matrix &m2, ENUM_MATRIX_AXIS axis = AXIS_VERT) | Quando axis=0, concatena a matriz ao longo das linhas (empilha as matrizes m1 com m2 horizontalmente). Quando axis=1, concatena a matriz ao longo das colunas (empilha as matrizes m1 com m2 verticalmente). |
matrix CNumpy::concat(const matrix &m, const vector &v, ENUM_MATRIX_AXIS axis = AXIS_VERT) | Se axis = 0, adiciona o vetor como uma nova linha (apenas se seu tamanho corresponder ao número de colunas na matriz). Se axis = 1, adiciona o vetor como uma nova coluna (apenas se seu tamanho corresponder ao número de linhas na matriz). |
matrix CNumpy::dot(const matrix& a, const matrix& b); double CNumpy::dot(const vector& a, const vector& b); matrix CNumpy::dot(const matrix& a, const vector& b); | Calculam o produto escalar (também conhecido como produto interno) de duas matrizes, vetores, ou uma matriz e um vetor. |
vector CNumpy::linspace(int start,int stop,uint num,bool endpoint=true) | Cria um array de números igualmente espaçados dentro de um intervalo especificado (start, stop). num = o número de amostras a serem geradas. endpoint (default=true), stop é incluído; se definido como false, stop é excluído. |
struct unique_struct { vector unique, count; }; unique_struct CNumpy::unique(const vector &v) | Retorna os itens únicos (unique) em um vetor e sua contagem de ocorrências (count). |
Exemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Common methods vector v = {1,2,3,4,5,6,7,8,9,10}; Print("------------------------------------"); Print("np.arange: ",np.arange(10)); Print("np.arange: ",np.arange(1, 10, 2)); matrix m = { {1,2,3,4,5}, {6,7,8,9,10} }; Print("np.flatten: ",np.flatten(m)); Print("np.ravel: ",np.ravel(m)); Print("np.reshape: ",np.reshape(v, 5, 2)); Print("np.reshape: ",np.reshape(m, 2, 3)); Print("np.expnad_dims: ",np.expand_dims(v, 1)); Print("np.clip: ", np.clip(v, 3, 8)); //--- Sorting Print("np.argsort: ",np.argsort(v)); Print("np.sort: ",np.sort(v)); //--- Others matrix z = { {1,2,3}, {4,5,6}, {7,8,9}, }; Print("np.concatenate: ",np.concat(v, v)); Print("np.concatenate:\n",np.concat(z, z, AXIS_HORZ)); vector y = {1,1,1}; Print("np.concatenate:\n",np.concat(z, y, AXIS_VERT)); Print("np.dot: ",np.dot(v, v)); Print("np.dot:\n",np.dot(z, z)); Print("np.linspace: ",np.linspace(1, 10, 10, true)); Print("np.unique: ",np.unique(v).unique, " count: ",np.unique(v).count); }
Saídas.
NJ 0 16:34:01.702 Numpy test (US Tech 100,H1) ------------------------------------ PL 0 16:34:01.703 Numpy test (US Tech 100,H1) np.arange: [0,1,2,3,4,5,6,7,8,9] LG 0 16:34:01.703 Numpy test (US Tech 100,H1) np.arange: [1,3,5,7,9] QR 0 16:34:01.703 Numpy test (US Tech 100,H1) np.flatten: [1,2,3,4,5,6,7,8,9,10] QO 0 16:34:01.703 Numpy test (US Tech 100,H1) np.ravel: [1,2,3,4,5,6,7,8,9,10] EF 0 16:34:01.703 Numpy test (US Tech 100,H1) np.reshape: [[1,2] NL 0 16:34:01.703 Numpy test (US Tech 100,H1) [3,4] NK 0 16:34:01.703 Numpy test (US Tech 100,H1) [5,6] NQ 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8] HF 0 16:34:01.703 Numpy test (US Tech 100,H1) [9,10]] HD 0 16:34:01.703 Numpy test (US Tech 100,H1) np.reshape: [[1,2,3] QD 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6]] OH 0 16:34:01.703 Numpy test (US Tech 100,H1) np.expnad_dims: [[1,2,3,4,5,6,7,8,9,10]] PK 0 16:34:01.703 Numpy test (US Tech 100,H1) np.clip: [3,3,3,4,5,6,7,8,8,8] FM 0 16:34:01.703 Numpy test (US Tech 100,H1) np.argsort: [0,1,2,3,4,5,6,7,8,9] KD 0 16:34:01.703 Numpy test (US Tech 100,H1) np.sort: [1,2,3,4,5,6,7,8,9,10] FQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: [1,2,3,4,5,6,7,8,9,10,1,2,3,4,5,6,7,8,9,10] FS 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: PK 0 16:34:01.703 Numpy test (US Tech 100,H1) [[1,2,3] DM 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6] CJ 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9] IS 0 16:34:01.703 Numpy test (US Tech 100,H1) [1,2,3] DH 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6] PL 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9]] FQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: CH 0 16:34:01.703 Numpy test (US Tech 100,H1) [[1,2,3,1] KN 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6,1] KH 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9,1]] JR 0 16:34:01.703 Numpy test (US Tech 100,H1) np.dot: 385.0 PK 0 16:34:01.703 Numpy test (US Tech 100,H1) np.dot: JN 0 16:34:01.703 Numpy test (US Tech 100,H1) [[30,36,42] OH 0 16:34:01.703 Numpy test (US Tech 100,H1) [66,81,96] RN 0 16:34:01.703 Numpy test (US Tech 100,H1) [102,126,150]] RI 0 16:34:01.703 Numpy test (US Tech 100,H1) np.linspace: [1,2,3,4,5,6,7,8,9,10] MQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.unique: [1,2,3,4,5,6,7,8,9,10] count: [1,1,1,1,1,1,1,1,1,1]
Codificando Modelos do Aprendizado de Máquina do Zero usando MQL5-NumPy
Como expliquei anteriormente, a biblioteca NumPy é a base de muitos modelos de ML que você vê implementados na linguagem de programação Python, devido à presença de um grande número de métodos para trabalhar com arrays, matrizes, matemática básica e até álgebra linear. Agora que temos algo semelhante em MQL5, vamos tentar usá-lo para implementar um modelo simples de aprendizado de máquina do zero.
Usando um modelo de regressão linear como exemplo.
Encontrei este código online, é um modelo de regressão linear usando descida de gradiente em sua função de treinamento.
import numpy as np from sklearn.metrics import mean_squared_error, r2_score class LinearRegression: def __init__(self, learning_rate=0.01, epochs=1000): self.learning_rate = learning_rate self.epochs = epochs self.weights = None self.bias = None def fit(self, X, y): """ Train the Linear Regression model using Gradient Descent. X: Input features (numpy array of shape [n_samples, n_features]) y: Target values (numpy array of shape [n_samples,]) """ n_samples, n_features = X.shape self.weights = np.zeros(n_features) self.bias = 0 for _ in range(self.epochs): y_pred = np.dot(X, self.weights) + self.bias # Predictions # Compute Gradients dw = (1 / n_samples) * np.dot(X.T, (y_pred - y)) db = (1 / n_samples) * np.sum(y_pred - y) # Update Parameters self.weights -= self.learning_rate * dw self.bias -= self.learning_rate * db def predict(self, X): """ Predict output for the given input X. """ return np.dot(X, self.weights) + self.bias # Example Usage if __name__ == "__main__": # Sample Data (X: Input features, y: Target values) X = np.array([[1], [2], [3], [4], [5]]) # Feature y = np.array([2, 4, 6, 8, 10]) # Target (y = 2x) # Create and Train Model model = LinearRegression(learning_rate=0.01, epochs=1000) model.fit(X, y) # Predictions y_pred = model.predict(X) # Evaluate Model print("Predictions:", y_pred) print("MSE:", mean_squared_error(y, y_pred)) print("R² Score:", r2_score(y, y_pred))
Saída da célula.
Predictions: [2.06850809 4.04226297 6.01601785 7.98977273 9.96352761] MSE: 0.0016341843485627612 R² Score: 0.9997957269564297
Preste atenção na função fit, temos alguns métodos NumPy na função de treinamento. Como também temos essas mesmas funções no CNumpy, vamos fazer a mesma implementação em MQL5.
#include <MALE5\Numpy\Numpy.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- // Sample Data (X: Input features, y: Target values) matrix X = {{1}, {2}, {3}, {4}, {5}}; vector y = {2, 4, 6, 8, 10}; // Create and Train Model CLinearRegression model(0.01, 1000); model.fit(X, y); // Predictions vector y_pred = model.predict(X); // Evaluate Model Print("Predictions: ", y_pred); Print("MSE: ", y_pred.RegressionMetric(y, REGRESSION_MSE)); Print("R² Score: ", y_pred.RegressionMetric(y_pred, REGRESSION_R2)); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CLinearRegression { protected: CNumpy np; double m_learning_rate; uint m_epochs; vector weights; double bias; public: CLinearRegression(double learning_rate=0.01, uint epochs=1000); ~CLinearRegression(void); void fit(const matrix &x, const vector &y); vector predict(const matrix &X); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLinearRegression::CLinearRegression(double learning_rate=0.01, uint epochs=1000): m_learning_rate(learning_rate), m_epochs(epochs) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLinearRegression::~CLinearRegression(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CLinearRegression::fit(const matrix &x, const vector &y) { ulong n_samples = x.Rows(), n_features = x.Cols(); this.weights = np.zeros((uint)n_features); this.bias = 0.0; //--- for (uint i=0; i<m_epochs; i++) { matrix temp = np.dot(x, this.weights); vector y_pred = np.flatten(temp) + bias; // Compute Gradients temp = np.dot(x.Transpose(), (y_pred - y)); vector dw = (1.0 / (double)n_samples) * np.flatten(temp); double db = (1.0 / (double)n_samples) * np.sum(y_pred - y); // Update Parameters this.weights -= this.m_learning_rate * dw; this.bias -= this.m_learning_rate * db; } } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CLinearRegression::predict(const matrix &X) { matrix temp = np.dot(X, this.weights); return np.flatten(temp) + this.bias; }
Saídas.
RD 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) Predictions: [2.068508094061713,4.042262972785917,6.01601785151012,7.989772730234324,9.963527608958529] KH 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) MSE: 0.0016341843485627612 RQ 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) R² Score: 1.0
Ótimo, obtivemos os mesmos resultados deste modelo que obtivemos no código Python.
E agora?
Você tem uma biblioteca poderosa e uma coleção de métodos valiosos que foram usados para construir inúmeros algoritmos do aprendizado de máquina e estatísticos na linguagem de programação Python, nada impede que você desenvolva robôs de negociação sofisticados equipados com cálculos complexos como aqueles que você frequentemente vê em Python.
No estado atual, a biblioteca ainda carece de muitas funções, pois levaria meses para escrever tudo, então sinta-se à vontade para adicionar as suas próprias, as funções presentes são aquelas que eu uso com frequência ou que sinto falta ao trabalhar com algoritmos de ML em MQL5.
A sintaxe Python em MQL5 pode ficar confusa às vezes, então não hesite em modificar os nomes das funções para o que for mais adequado para você.
Até mais.
Tabela de Anexos
| Nome do arquivo | Descrição |
|---|---|
| Include\Numpy.mqh | Clone do NumPy em MQL5, todos os métodos do NumPy para MQL5 podem ser encontrados neste arquivo. |
| Scripts\Linear regression from scratch.mq5 | Um script onde o exemplo de regressão linear é implementado usando CNumpy. |
| Scripts\Numpy test.mq5 | Este script chama todos os métodos de Numpy.mqh para fins de teste. É um ambiente de testes para todos os métodos discutidos neste artigo. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17469
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso