
Ciência de dados e aprendizado de máquina (Parte 44): Previsão de séries OHLC no Forex pelo método de autorregressão vetorial (VAR)

Sumário
- O que é autorregressão vetorial (VAR)?
- A matemática por trás da autorregressão vetorial
- Premissas subjacentes ao modelo VAR
- Implementação do modelo VAR para valores OHLC em Python
- Previsão fora da amostra usando o modelo VAR
- Robô de trading baseado em VAR
- Considerações finais
O que é autorregressão vetorial (VAR)?
É uma ferramenta estatística tradicional de previsão de séries temporais, usada para investigar relações dinâmicas entre várias variáveis temporais. Diferentemente dos modelos autorregressivos univariados, como o ARIMA (que discutimos no artigo anterior), que preveem apenas uma variável com base em seus valores passados, os modelos VAR investigam as relações entre múltiplas variáveis.
Para isso, os modelos VAR modelam cada variável como função não apenas de seus próprios valores passados, mas também dos valores passados de outras variáveis do sistema. Neste artigo, veremos os fundamentos da autorregressão vetorial e sua aplicação no trading.
Origem
A autorregressão vetorial foi apresentada pela primeira vez na década de 1960 pelo economista Clive Granger. Suas contribuições estabeleceram as bases para a compreensão e a modelagem das interações dinâmicas entre fatores econômicos. Os modelos VAR passaram a ser amplamente utilizados na econometria e na macroeconomia nas décadas de 1970 e 1980. na econometria e na macroeconomia nas décadas de 1970 e 1980.
Essa técnica é uma variante multivariada dos modelos autorregressivos (AR). Os modelos AR tradicionais, como o ARIMA, analisam a dependência de uma variável em relação às suas defasagens, enquanto os modelos VAR consideram várias variáveis simultaneamente. No VAR, cada variável é regredida sobre suas próprias defasagens, cada variável é regredida sobre suas próprias defasagens e sobre as defasagens das demais variáveis do sistema.
No artigo anterior, discutimos o ARIMA e vimos que ele não consegue incorporar várias variáveis durante o treinamento e a previsão. Neste artigo, analisaremos o VAR, um modelo que alguns podem considerar predecessor do ARIMA, pois tenta superar a limitação da previsão univariada de séries temporais.
Para compreender a técnica por trás do modelo, vamos examinar sua estrutura matemática.
A matemática por trás da autorregressão vetorial
A principal diferença entre o VAR e os demais modelos autorregressivos (AR, ARMA, ARIMA) está no fato de que os primeiros são unidirecionais (as variáveis preditoras influenciam a variável-alvo, mas não o contrário), enquanto o VAR é bidirecional.
Matematicamente, um modelo VAR(p) com 'p' defasagens pode ser representado como:
![]()
em que:
- c — termo constante (intercepto) do modelo
-
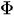 — coeficientes das defasagens de Y até a ordem p
— coeficientes das defasagens de Y até a ordem p -
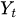 — valor da série temporal no momento t
— valor da série temporal no momento t -
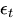 — erro no momento t
— erro no momento t
Um modelo VAR k-dimensional de ordem P, denotado como VAR(p), para k=2 terá a seguinte forma:
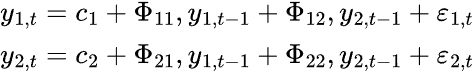
Em um modelo VAR, há várias séries temporais que influenciam umas às outras. O modelo é representado por um sistema de equações, uma equação para cada variável. Na forma matricial, a fórmula assume a seguinte forma:
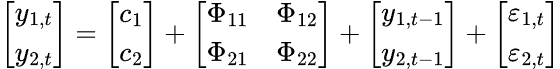
A equação final do VAR será a seguinte:
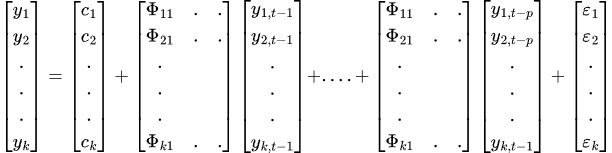
Para que os resultados do VAR sejam corretos e confiáveis, é necessário atender a uma série de premissas e requisitos.
Premissas subjacentes ao modelo VAR
- Linearidade
Como se observa pela fórmula, o VAR é um modelo linear, portanto todas as variáveis usadas no modelo devem entrar de forma linear, isto é, ser expressas como somas ponderadas de defasagens., isto é, expressas como somas ponderadas de defasagens. - Estacionariedade
Todas as variáveis devem ser estacionárias, isto é, a média, a variância e a covariância de cada variável da série temporal devem permanecer constantes ao longo do tempo. Todos os atributos não estacionários precisam ser transformados em estacionários. - Ausência de multicolinearidade perfeita entre os atributos
Para que o modelo VAR funcione corretamente, as variáveis explicativas não devem ser uma combinação linear exata das demais variáveis explicativas. Isso é importante porque evita matrizes singulares durante a estimação pelo método OLS, isto é, a matriz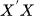 deve ser inversível. Atributos redundantes devem ser removidos, ou então deve-se usar um método de regularização.
deve ser inversível. Atributos redundantes devem ser removidos, ou então deve-se usar um método de regularização. - Ausência de autocorrelação dos resíduos
Pressupõe-se que os resíduos não sejam correlacionados ao longo do tempo e representem ruído branco. A autocorrelação distorce os erros-padrão e invalida os testes estatísticos. - Quantidade suficiente de observações
O VAR pressupõe um volume de dados suficiente para estimar os parâmetros. É preciso fornecer ao modelo a maior quantidade possível de informações para que ele seja eficiente.
A seguir, veremos como implementar o modelo em Python.
Implementação do modelo VAR com valores OHLC em Python
Vamos começar instalando todas as dependências do Python. O arquivo requirements.txt está na seção de anexos.
pip install -r requirements.txt
Importação.
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import warnings # Suppress all warnings warnings.filterwarnings("ignore") sns.set_style("darkgrid")
Importamos os valores Open, High, Low e Close do MetaTrader 5.
symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 if not mt5.symbol_select(symbol, True): print("Failed to select and add a symbol to the MarketWatch, Error = ",mt5.last_error) quit() rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 10000) df = pd.DataFrame(rates) # convert rates into a pandas dataframe df
Resultados.
| time | open | high | low | close | tick_volume | spread | real_volume | |
|---|---|---|---|---|---|---|---|---|
| 0 | 611280000 | 1.00780 | 1.01050 | 1.00630 | 1.00760 | 821 | 50 | 0 |
| 1 | 611366400 | 0.99620 | 1.00580 | 0.99100 | 0.99600 | 2941 | 50 | 0 |
| 2 | 611452800 | 0.99180 | 0.99440 | 0.98760 | 0.99190 | 1351 | 50 | 0 |
| 3 | 611539200 | 0.99330 | 0.99370 | 0.99310 | 0.99310 | 101 | 50 | 0 |
| 4 | 611798400 | 0.97360 | 0.97360 | 0.97320 | 0.97360 | 81 | 50 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9995 | 1748390400 | 1.13239 | 1.13453 | 1.12838 | 1.12910 | 153191 | 0 | 0 |
| 9996 | 1748476800 | 1.12918 | 1.13849 | 1.12105 | 1.13659 | 191948 | 0 | 0 |
| 9997 | 1748563200 | 1.13630 | 1.13901 | 1.13127 | 1.13470 | 186924 | 0 | 0 |
| 9998 | 1748822400 | 1.13435 | 1.14500 | 1.13412 | 1.14436 | 168697 | 0 | 0 |
| 9999 | 1748908800 | 1.14385 | 1.14549 | 1.13642 | 1.13708 | 147424 | 0 | 0 |
Obtivemos 10 000 barras do timeframe diário. É um volume elevado, e esses dados devem ser suficientes para o modelo.
Como o modelo será aplicado aos valores OHLC, removeremos todas as outras colunas., removeremos todas as outras colunas.
ohlc_df = df.drop(columns=[ "time", "tick_volume", "spread", "real_volume" ]) ohlc_df
Decidi usar apenas OHLC, pois acredito que exista uma forte inter-relação entre essas variáveis que o modelo pode identificar. Além disso, essas quatro variáveis são características fundamentais dos instrumentos financeiros.
Como o modelo pressupõe estacionariedade dos atributos, e os valores OHLC não são estacionários, é necessário torná-los estacionários, aplicando uma diferenciação de primeira ordem de cada valor em relação ao valor anterior.
stationary_df = pd.DataFrame() for col in df.columns: stationary_df["Diff_"+col] = df[col].diff() stationary_df.dropna(inplace=True) stationary_df
Resultados.
| Diff_Open | Diff_High | Diff_Low | Diff_Close | |
|---|---|---|---|---|
| 1 | 0.00080 | 0.00180 | -0.01670 | -0.00950 |
| 2 | -0.00960 | -0.00840 | -0.01370 | -0.01880 |
| 3 | -0.01870 | -0.01930 | -0.00350 | -0.00190 |
| 4 | -0.00180 | -0.00210 | -0.00590 | -0.00870 |
| 5 | -0.00890 | -0.00310 | -0.01300 | -0.01200 |
| ... | ... | ... | ... | ... |
Uma vez obtidas as novas variáveis, também é possível verificar sua estacionariedade., também é possível verificar sua estacionariedade.
from statsmodels.tsa.stattools import adfuller for col in stationary_df.columns: result = adfuller(stationary_df[col]) print(f'{col} p-value: {result[1]}')
Resultados.
Diff_Open p-value: 0.0 Diff_High p-value: 1.0471939301334604e-28 Diff_Low p-value: 1.1015540451195308e-23 Diff_Close p-value: 0.0
Para que os dados sejam considerados estacionários, o valor-p deve ser menor que 0,05 (<0,05). No nosso caso, p é menor que 0,05, portanto os dados são adequados para o modelo.
Ainda de acordo com as premissas do VAR, não deve haver multicolinearidade perfeita entre os atributos. Vamos verificar isso.
stationary_df.corr()
Resultados.
| Diff_Open | Diff_High | Diff_Low | Diff_Close | |
|---|---|---|---|---|
| Diff_Open | 1.000000 | 0.565829 | 0.563516 | 0.036347 |
| Diff_High | 0.565829 | 1.000000 | 0.452775 | 0.564026 |
| Diff_Low | 0.563516 | 0.452775 | 1.000000 | 0.557139 |
| Diff_Close | 0.036347 | 0.564026 | 0.557139 | 1.000000 |
A matriz de correlações entre os atributos parece correta. Também podemos verificar o módulo médio dos coeficientes de correlação de toda a matriz, que deve satisfazer |p| < 0,8.
print("Mean absolute |p|:", np.abs(np.corrcoef(stationary_df, rowvar=False).mean()))
Resultados.
Mean absolute |p|: 0.5924538886295351 Escolha do número ideal de defasagens
Como indica a fórmula, o VAR usa informações passadas (defasagens) para prever o futuro (defasagens) para prever o futuro, portanto é necessário determinar o número ideal de defasagens. Convenientemente, a função VAR da biblioteca statsmodels permite escolher o número de defasagens com base em vários critérios:
- AIC (critério de Akaike)
- BIC (critério de informação bayesiano/critério de Schwarz)
- FPE (erro final de previsão)
- HQIC (critério de Hannan-Quinn)
# Select optimal lag using AIC lag_order = model.select_order(maxlags=30) print(lag_order.summary())
Resultados.
VAR Order Selection (* highlights the minimums) ================================================== AIC BIC FPE HQIC -------------------------------------------------- 0 -41.87 -41.87 6.537e-19 -41.87 1 -45.15 -45.14 2.457e-20 -45.15 2 -45.63 -45.60 1.530e-20 -45.62 3 -45.85 -45.81 1.225e-20 -45.84 4 -45.99 -45.94 1.065e-20 -45.97 5 -46.18 -46.12 8.805e-21 -46.16 6 -46.24 -46.17 8.256e-21 -46.22 7 -46.28 -46.20 7.951e-21 -46.25 8 -46.31 -46.22 7.708e-21 -46.28 9 -46.34 -46.24 7.471e-21 -46.31 10 -46.36 -46.24 7.368e-21 -46.32 11 -46.41 -46.28 6.979e-21 -46.37 12 -46.42 -46.28 6.890e-21 -46.38 13 -46.44 -46.28 6.806e-21 -46.38 14 -46.45 -46.28 6.730e-21 -46.39 15 -46.45 -46.28 6.697e-21 -46.39 16 -46.46 -46.28 6.628e-21 -46.40 17 -46.49 -46.29* 6.460e-21 -46.42 18 -46.50 -46.28 6.419e-21 -46.42 19 -46.50 -46.28 6.383e-21 -46.43 20 -46.50 -46.27 6.358e-21 -46.43 21 -46.51 -46.27 6.306e-21 -46.43 22 -46.52 -46.26 6.292e-21 -46.43 23 -46.53 -46.26 6.216e-21 -46.44 24 -46.53 -46.25 6.185e-21 -46.44 25 -46.54 -46.24 6.162e-21 -46.44 26 -46.54 -46.24 6.113e-21 -46.44 27 -46.55 -46.23 6.092e-21 -46.44 28 -46.55 -46.22 6.086e-21 -46.44 29 -46.56* -46.22 6.031e-21* -46.44* 30 -46.56 -46.21 6.033e-21 -46.44 --------------------------------------------------
Cada linha mostra os valores para diferentes ordens de defasagem. O valor marcado com asterisco é o mínimo para o respectivo critério e indica a "melhor" ordem segundo esse critério.
Assim, estes são os valores obtidos:
- AIC: melhor resultado com 29 defasagens (valor -46.56) (valor -46.56)
- BIC: o melhor modelo foi obtido com 17 defasagens (valor -46,29).
- FPE: melhor resultado com 29 defasagens (-6.031e-21)
- HQIC: melhor resultado com 29 defasagens (-46.44)
Na maioria dos casos, AIC e BIC são usados para escolher o modelo. O AIC, em geral, seleciona modelos mais complexos, com maior número de defasagens, enquanto o BIC penaliza a complexidade e frequentemente seleciona modelos mais simples.
O HQIC ocupa uma posição intermediária entre AIC e BIC, e o método FPE avalia o erro de previsão.
Vamos treinar o modelo com o número de defasagens obtido pelo critério AIC.
# Fit the model with selected lag results = model.fit(lag_order.aic) print(results.summary())
Resultados.
Summary of Regression Results ================================== Model: VAR Method: OLS Date: Wed, 04, Jun, 2025 Time: 10:40:37 -------------------------------------------------------------------- No. of Equations: 4.00000 BIC: -46.2188 Nobs: 9970.00 HQIC: -46.4425 Log likelihood: 175968. FPE: 6.03280e-21 AIC: -46.5571 Det(Omega_mle): 5.75774e-21 -------------------------------------------------------------------- Results for equation diff_open ================================================================================= coefficient std. error t-stat prob --------------------------------------------------------------------------------- const -0.000002 0.000013 -0.115 0.908 L1.diff_open -0.959329 0.010918 -87.867 0.000 L1.diff_high 0.009878 0.004957 1.993 0.046 L1.diff_low 0.006869 0.005010 1.371 0.170 L1.diff_close 0.995718 0.004583 217.244 0.000 L2.diff_open -0.935345 0.015071 -62.062 0.000 L2.diff_high 0.007118 0.006749 1.055 0.292 L2.diff_low 0.022288 0.006819 3.268 0.001 L2.diff_close 0.939861 0.011863 79.226 0.000 L3.diff_open -0.906595 0.018115 -50.045 0.000 L3.diff_high 0.003072 0.007954 0.386 0.699 L3.diff_low 0.018535 0.008097 2.289 0.022 L3.diff_close 0.910898 0.015703 58.006 0.000 L4.diff_open -0.898803 0.020501 -43.841 0.000 L4.diff_high 0.003670 0.008912 0.412 0.681 L4.diff_low 0.015668 0.009103 1.721 0.085 L4.diff_close 0.886824 0.018628 47.606 0.000 L5.diff_open -0.867308 0.022560 -38.445 0.000 L5.diff_high 0.001318 0.009676 0.136 0.892 L5.diff_low -0.000027 0.009942 -0.003 0.998 L5.diff_close 0.884632 0.020996 42.133 0.000 ... ... ... L29.diff_open -0.005922 0.004617 -1.283 0.200 L29.diff_high 0.007026 0.004956 1.418 0.156 L29.diff_low 0.004387 0.005005 0.876 0.381 L29.diff_close 0.035169 0.010568 3.328 0.001 ================================================================================= Results for equation diff_high ================================================================================= coefficient std. error t-stat prob --------------------------------------------------------------------------------- const 0.000008 0.000048 0.165 0.869 L1.diff_open -0.010294 0.038697 -0.266 0.790 L1.diff_high -0.887555 0.017570 -50.515 0.000 L1.diff_low -0.020634 0.017757 -1.162 0.245 L1.diff_close 0.969305 0.016245 59.667 0.000 L2.diff_open 0.006028 0.053418 0.113 0.910 L2.diff_high -0.838250 0.023920 -35.043 0.000 L2.diff_low -0.057396 0.024169 -2.375 0.018 L2.diff_close 0.914246 0.042047 21.744 0.000 L3.diff_open -0.160354 0.064208 -2.497 0.013 L3.diff_high -0.807663 0.028191 -28.650 0.000 L3.diff_low -0.042960 0.028698 -1.497 0.134 L3.diff_close 0.869460 0.055659 15.621 0.000 L4.diff_open -0.168775 0.072664 -2.323 0.020 L4.diff_high -0.785399 0.031589 -24.863 0.000 L4.diff_low -0.054113 0.032265 -1.677 0.094 L4.diff_close 1.013851 0.066026 15.355 0.000 L5.diff_open -0.146275 0.079959 -1.829 0.067 L5.diff_high -0.746785 0.034295 -21.775 0.000 L5.diff_low -0.098885 0.035238 -2.806 0.005 L5.diff_close 1.012989 0.074419 13.612 0.000 ... ... ... L27.diff_open 0.020345 0.053645 0.379 0.705 L27.diff_high -0.153391 0.028136 -5.452 0.000 L27.diff_low -0.065690 0.028874 -2.275 0.023 L27.diff_close 0.251005 0.062004 4.048 0.000 L28.diff_open -0.005863 0.040235 -0.146 0.884 L28.diff_high -0.087603 0.023901 -3.665 0.000 L28.diff_low 0.008246 0.024229 0.340 0.734 L28.diff_close 0.134924 0.051754 2.607 0.009 L29.diff_open -0.000480 0.016364 -0.029 0.977 L29.diff_high -0.051136 0.017564 -2.911 0.004 L29.diff_low 0.035083 0.017741 1.977 0.048 L29.diff_close 0.054123 0.037457 1.445 0.148 ================================================================================= Results for equation diff_low ================================================================================= coefficient std. error t-stat prob --------------------------------------------------------------------------------- const 0.000005 0.000047 0.101 0.920 L1.diff_open 0.024212 0.038141 0.635 0.526 L1.diff_high -0.058570 0.017317 -3.382 0.001 L1.diff_low -0.904567 0.017501 -51.686 0.000 L1.diff_close 0.976598 0.016012 60.993 0.000 L2.diff_open 0.067049 0.052650 1.274 0.203 L2.diff_high -0.084679 0.023576 -3.592 0.000 L2.diff_low -0.866233 0.023822 -36.363 0.000 L2.diff_close 0.937652 0.041442 22.626 0.000 L3.diff_open 0.065284 0.063284 1.032 0.302 L3.diff_high -0.108128 0.027785 -3.892 0.000 L3.diff_low -0.791679 0.028285 -27.989 0.000 L3.diff_close 0.844047 0.054858 15.386 0.000 L4.diff_open 0.018366 0.071619 0.256 0.798 L4.diff_high -0.116216 0.031134 -3.733 0.000 L4.diff_low -0.747223 0.031801 -23.497 0.000 L4.diff_close 0.816060 0.065076 12.540 0.000 L5.diff_open -0.040872 0.078809 -0.519 0.604 L5.diff_high -0.110998 0.033802 -3.284 0.001 L5.diff_low -0.731241 0.034731 -21.054 0.000 L5.diff_close 0.832344 0.073348 11.348 0.000 ... ... ... L29.diff_open 0.024357 0.016128 1.510 0.131 L29.diff_high 0.026179 0.017312 1.512 0.130 L29.diff_low -0.072592 0.017486 -4.151 0.000 L29.diff_close 0.051738 0.036919 1.401 0.161 ================================================================================= Results for equation diff_close ================================================================================= coefficient std. error t-stat prob --------------------------------------------------------------------------------- const 0.000013 0.000071 0.185 0.853 L1.diff_open 0.037592 0.057827 0.650 0.516 L1.diff_high 0.007085 0.026256 0.270 0.787 L1.diff_low 0.011658 0.026535 0.439 0.660 L1.diff_close -0.020373 0.024276 -0.839 0.401 L2.diff_open 0.150341 0.079825 1.883 0.060 L2.diff_high -0.035345 0.035745 -0.989 0.323 L2.diff_low -0.041114 0.036117 -1.138 0.255 L2.diff_close -0.012920 0.062832 -0.206 0.837 L3.diff_open -0.000054 0.095949 -0.001 1.000 L3.diff_high -0.047439 0.042126 -1.126 0.260 L3.diff_low 0.028500 0.042884 0.665 0.506 L3.diff_close -0.113979 0.083173 -1.370 0.171 L4.diff_open -0.083562 0.108585 -0.770 0.442 L4.diff_high -0.083193 0.047204 -1.762 0.078 L4.diff_low 0.055907 0.048215 1.160 0.246 L4.diff_close 0.026375 0.098665 0.267 0.789 L5.diff_open -0.148622 0.119487 -1.244 0.214 L5.diff_high -0.065192 0.051248 -1.272 0.203 L5.diff_low 0.011819 0.052658 0.224 0.822 L5.diff_close 0.125327 0.111207 1.127 0.260 ... ... ... L29.diff_open 0.002852 0.024453 0.117 0.907 L29.diff_high -0.011652 0.026247 -0.444 0.657 L29.diff_low -0.004191 0.026511 -0.158 0.874 L29.diff_close 0.070689 0.055974 1.263 0.207 ================================================================================= Correlation matrix of residuals diff_open diff_high diff_low diff_close diff_open 1.000000 0.223818 0.241416 0.126479 diff_high 0.223818 1.000000 0.452061 0.770309 diff_low 0.241416 0.452061 1.000000 0.765777 diff_close 0.126479 0.770309 0.765777 1.000000
Assim como outros modelos estatísticos tradicionais de séries temporais, o VAR fornece um um resumo detalhado dos resultados do modelo e das propriedades das variáveis. Essa análise ajuda a compreender melhor o modelo. Vamos analisar brevemente os resultados.
-------------------------------------------------------------------- No. of Equations: 4.00000 BIC: -46.2188 Nobs: 9970.00 HQIC: -46.4425 Log likelihood: 175968. FPE: 6.03280e-21 AIC: -46.5571 Det(Omega_mle): 5.75774e-21
- Número de equações: 4 significa que o modelo contém 4 variáveis endógenas: diff_open, diff_high, diff_low, diff_close.
- Nobs (número de observações usadas): como escolhemos o critério AIC, que usa 29 defasagens, 29+1 atributos não foram incluídos no treinamento (estimação), pois esses valores foram usados como defasagens iniciais.
- AIC, BIC, HQIC e FPE: todos os valores são negativos, o que é normal, e indicam um bom ajuste do modelo aos dados.
- Log Likelihood (função de log-verossimilhança): um valor positivo elevado indica bom ajuste do modelo.
Resultados de cada equação
Para cada variável (diff_open, diff_high, diff_low e diff_close), são apresentados:
- Coeficientes
Eles mostram a influência de cada variável defasada (L1, L2 etc.) sobre o valor atual. Os coeficientes refletem a direção e a magnitude da influência das respectivas variáveis defasadas sobre o valor atual. Um sinal positivo indica uma relação direta; um sinal negativo indica uma relação inversa.
Por exemplo:
Results for equation diff_open ================================================================================= coefficient std. error t-stat prob --------------------------------------------------------------------------------- const -0.000002 0.000013 -0.115 0.908 L1.diff_open -0.959329 0.010918 -87.867 0.000
O coeficiente -0,959329 significa que um aumento de 1 unidade em diff_open no período anterior (lag-1) está associado a uma redução de 0,959329 unidade no diff_open de hoje, mantidas constantes todas as demais variáveis. -
Erro-padrão
Reflete a precisão das estimativas dos coeficientes. -
t-stat
Mostra a significância estatística. Quanto maior o valor absoluto |t-stat|, mais significativa é a variável. Um valor absoluto elevado, por exemplo, |t|>2, indica significância estatística.
Por exemplo, |(-87,867)| = 87,867 é um valor muito alto, o que indica alta significância da influência da variável diff_open na defasagem 1, o que sugere que o efeito não é aleatório. -
prob
Valor-p associado à estatística t do coeficiente. Ele mostra se uma variável defasada específica tem influência significativa sobre o valor atual da variável dependente.
Se prob ≤ 0,05, a variável é considerada estatisticamente significativa.
Matriz de correlação dos resíduos
Correlation matrix of residuals diff_open diff_high diff_low diff_close diff_open 1.000000 0.223818 0.241416 0.126479 diff_high 0.223818 1.000000 0.452061 0.770309 diff_low 0.241416 0.452061 1.000000 0.765777 diff_close 0.126479 0.770309 0.765777 1.000000
Mostra a correlação entre os erros de previsão em diferentes equações.
A alta correlação entre diff_high/diff_close (0,77) e diff_low/diff_close (aproximadamente 0,766) indica a presença de fatores comuns não explicados que afetam esses pares de variáveis.
Previsão fora da amostra usando o modelo VAR
Assim como no caso do modelo ARIMA, do qual falamos no artigo anterior, a previsão fora da amostra com VAR é uma tarefa bastante complexa. Diferentemente dos modelos de aprendizado de máquina, esses modelos precisam ser atualizados regularmente com novas informações.
Para isso, criaremos uma função.
def forecast_next(model_res, symbol, timeframe): forecast = None # Get required lags for prediction rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, model_res.k_ar+1) # Get rates starting at the current bar to bars=lags used during training if rates is None or len(rates) < model_res.k_ar+1: print("Failed to get copy rates Error =", mt5.last_error()) return forecast, None # Prepare input data and make forecast input_data = pd.DataFrame(rates)[["open", "high", "low", "close"]].values stationary_input = np.diff(input_data, axis=0)[-model_res.k_ar:] # get the recent values equal to the number of lags used by the model try: forecast = model_res.forecast(stationary_input, steps=1) # predict the next price except Exception as e: print("Failed to forecast: ", str(e)) return forecast, None try: updated_data = np.vstack([model_res.endog, stationary_input[-1]]) # concatenate new/last datapoint to the data used during previous training updated_model = VAR(updated_data).fit(maxlags=model_res.k_ar) # Retrain the model with new data except Exception as e: print("Failed to update the model: ", str(e)) return forecast, None return forecast, updated_model
Para obter a previsão, é preciso usar o modelo treinado e atualizá-lo após cada previsão. Para isso, vamos reatribuir a variável a si mesma.
res_model = results # Initial model forecast, res_model = forecast_next(model_res=res_model, symbol=symbol, timeframe=timeframe) forecast_df = pd.DataFrame(forecast, columns=stationary_df.columns) print("next forecasted:\n", forecast_df)
Resultados.
next forecasted: diff_open diff_high diff_low diff_close 0 0.00435 0.003135 0.001032 -0.000655
Para simplificar o treinamento e a previsão, encapsularemos tudo em uma classe.
Arquivo VAR.py
import pandas as pd import numpy as np import MetaTrader5 as mt5 from statsmodels.tsa.api import VAR class VARForecaster: def __init__(self, symbol: str, timeframe: int): self.symbol = symbol self.timeframe = timeframe self.model = None def train(self, start_bar: int=1, total_bars: int=10000, max_lags: int=30): """Trains the VAR model using the collected OHLC from given bars from MetaTrader5 start_bar: int: The recent bar according to copyrates_from_pos total_bars: int: Total number of bars to use for training max_lags: int: The maximum number of lags to use """ self.max_lags = max_lags if not mt5.symbol_select(self.symbol, True): print("Failed to select and add a symbol to the MarketWatch, Error = ",mt5.last_error()) quit() rates = mt5.copy_rates_from_pos(self.symbol, self.timeframe, start_bar, total_bars) if rates is None: print("Failed to get copy rates Error =", mt5.last_error()) return if total_bars < max_lags: print(f"Failed to train, max_lags: {max_lags} must be > total_bars: {total_bars}") return train_df = pd.DataFrame(rates) # convert rates into a pandas dataframe train_df = train_df[["open", "high", "low", "close"]] stationary_df = np.diff(train_df, axis=0) # Convert OHLC values into stationary ones by differenciating them self.model = VAR(stationary_df) # Select optimal lag using AIC lag_order = self.model.select_order(maxlags=self.max_lags) print(lag_order.summary()) # Fit the model with selected lag self.model_results = self.model.fit(lag_order.aic) print(self.model_results.summary()) def forecast_next(self): """Gets recent OHLC from MetaTrader5 and predicts the next differentiated prices Returns: np.array: predicted values """ forecast = None # Get required lags for prediction rates = mt5.copy_rates_from_pos(self.symbol, self.timeframe, 0, self.model_results.k_ar+1) # Get rates starting at the current bar to bars=lags used during training if rates is None or len(rates) < self.model_results.k_ar+1: print("Failed to get copy rates Error =", mt5.last_error()) return forecast # Prepare input data and make forecast input_data = pd.DataFrame(rates)[["open", "high", "low", "close"]] stationary_input = np.diff(input_data, axis=0)[-self.model_results.k_ar:] # get the recent values equal to the number of lags used by the model try: forecast = self.model_results.forecast(stationary_input, steps=1) # predict the next price except Exception as e: print("Failed to forecast: ", str(e)) return forecast try: updated_data = np.vstack([self.model_results.endog, stationary_input[-1]]) # concatenate new/last datapoint to the data used during previous training updated_model = VAR(updated_data).fit(maxlags=self.model_results.k_ar) # Retrain the model with new data except Exception as e: print("Failed to update the model: ", str(e)) return forecast self.model = updated_model return forecast
Agora vamos implementar tudo isso como um robô de trading em Python.
Robô de trading baseado em VAR
Usando a classe mostrada acima, que permite treinar o modelo e prever os próximos valores, incorporaremos essas previsões a uma estratégia de trading.
No exemplo anterior, usamos valores estacionários obtidos pela diferenciação dos valores atuais em relação aos anteriores. Embora essa abordagem funcione de modo geral, ela não é muito prática para construir uma estratégia de trading.
Em vez disso, vamos definir a diferença entre a abertura e a máxima do candle, para medir o movimento de alta do preço a partir da abertura, e a diferença entre a abertura e a mínima, para medir o movimento de baixa do preço a partir da abertura.
Esses dois valores permitem acompanhar o movimento do candle para cima e para baixo, e os valores previstos podem ser usados para definir o stop-loss e o take-profit.
Vamos alterar os atributos usados no modelo.
# Prepare input data and make forecast input_data = pd.DataFrame(rates)[["open", "high", "low", "close"]] stationary_input = pd.DataFrame({ "high_open": input_data["high"] - input_data["open"], "open_low": input_data["open"] - input_data["low"] })
Os atributos obtidos após a diferenciação provavelmente são estacionários, portanto a verificação não é necessária nesta etapa.
No arquivo principal do robô, adicionaremos o treinamento e a exibição dos valores previstos.
Arquivo VAR-TradingRobot.py
import MetaTrader5 as mt5 import schedule import time from VAR import VARForecaster symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 mt5_path = r"c:\Users\Omega Joctan\AppData\Roaming\Pepperstone MetaTrader 5\terminal64.exe" # replace this with a desired MT5 path if not mt5.initialize(mt5_path): # initialize MetaTrader5 print("Failed to initialize MetaTrader5, error =", mt5.last_error()) quit() var_model = VARForecaster(symbol=symbol, timeframe=timeframe) var_model.train(start_bar=1, total_bars=10000, max_lags=30) # Train the VAR Model def get_next_forecast(): print(var_model.forecast_next()) schedule.every(1).minutes.do(get_next_forecast) while True: schedule.run_pending() time.sleep(60) else: mt5.shutdown()
Resultados.
[[0.00464001 0.00439884]]
Obtivemos duas previsões separadas para high_open e open_low. Agora vamos criar uma estratégia de trading simples baseada na média móvel.
Arquivo VAR-TradingRobot.py
import MetaTrader5 as mt5 import schedule import time import ta from VAR import VARForecaster from Trade.Trade import CTrade from Trade.SymbolInfo import CSymbolInfo from Trade.PositionInfo import CPositionInfo import numpy as np import pandas as pd symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 mt5_path = r"c:\Users\Omega Joctan\AppData\Roaming\Pepperstone MetaTrader 5\terminal64.exe" # replace this with a desired MT5 path if not mt5.initialize(mt5_path): # initialize MetaTrader5 print("Failed to initialize MetaTrader5, error =", mt5.last_error()) quit() var_model = VARForecaster(symbol=symbol, timeframe=timeframe) var_model.train(start_bar=1, total_bars=10000, max_lags=30) # Train the VAR Model # Initlalize the trade classes MAGICNUMBER = 5062025 SLIPPAGE = 100 m_trade = CTrade(magic_number=MAGICNUMBER, filling_type_symbol=symbol, deviation_points=SLIPPAGE) m_symbol = CSymbolInfo(symbol=symbol) m_position = CPositionInfo() ##################################################### def pos_exists(pos_type: int, magic: int, symbol: str) -> bool: """Checks whether a position exists given a magic number, symbol, and the position type Returns: bool: True if a position is found otherwise False """ if mt5.positions_total() < 1: # no positions whatsoever return False positions = mt5.positions_get() for position in positions: if m_position.select_position(position): if m_position.magic() == magic and m_position.symbol() == symbol and m_position.position_type()==pos_type: return True return False def trading_strategy(): forecasts_arr = var_model.forecast_next().flatten() high_open = forecasts_arr[0] open_low = forecasts_arr[1] print(f"high_open: ",high_open, " open_low: ",open_low) # Get the information about the market rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 50) # Get the last 50 bars information rates_df = pd.DataFrame(rates) if rates is None: print("Failed to get copy rates Error =", mt5.last_error()) return sma_buffer = ta.trend.sma_indicator(close=rates_df["close"], window=20) m_symbol.refresh_rates() if rates_df["close"].iloc[-1] > sma_buffer.iloc[-1]: # current closing price is above sma20 if pos_exists(pos_type=mt5.POSITION_TYPE_BUY, symbol=symbol, magic=MAGICNUMBER) is False: # If a buy position doesn't exist m_trade.buy(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.ask(), sl=m_symbol.ask()-open_low, tp=m_symbol.ask()+high_open) else: # if the closing price is below the moving average if pos_exists(pos_type=mt5.POSITION_TYPE_SELL, symbol=symbol, magic=MAGICNUMBER) is False: # If a buy position doesn't exist m_trade.sell(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.bid(), sl=m_symbol.bid()+high_open, tp=m_symbol.bid()-open_low) schedule.every(1).minutes.do(trading_strategy) while True: schedule.run_pending() time.sleep(60) else: mt5.shutdown()
Aqui, como de costume, usamos as classes de trading. Verificamos se já existe uma posição aberta do mesmo tipo na conta. Se não houver, abrimos uma posição. Usamos os valores previstos de high_open e open_low para definir o take-profit e o stop-loss para compras e, de forma inversa, para vendas.
Como sinal de confirmação, usamos o indicador de média móvel simples com período 20. Se o preço de fechamento atual estiver acima da média móvel, abrimos uma compra. Caso contrário, uma venda.
Resultados.
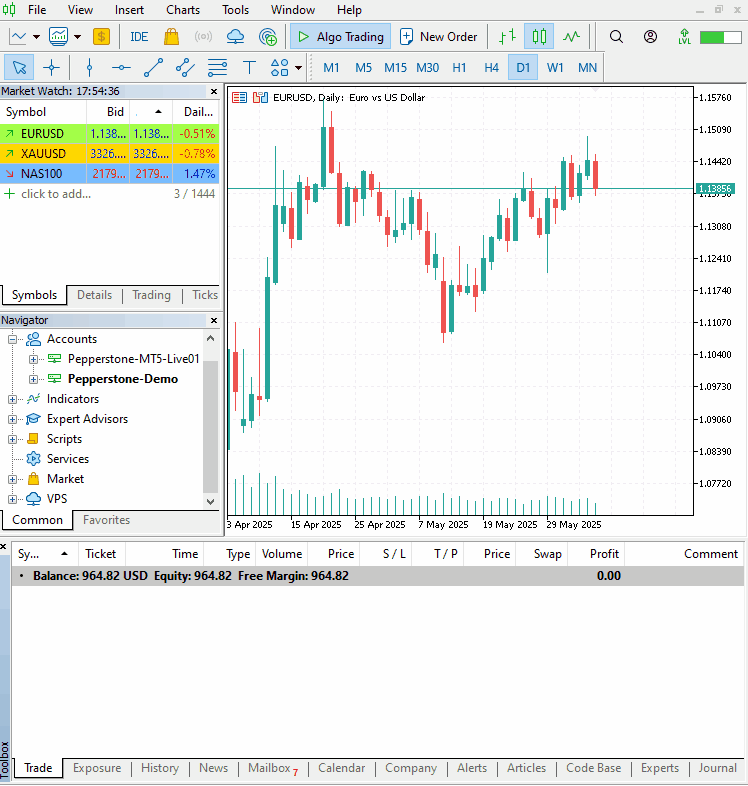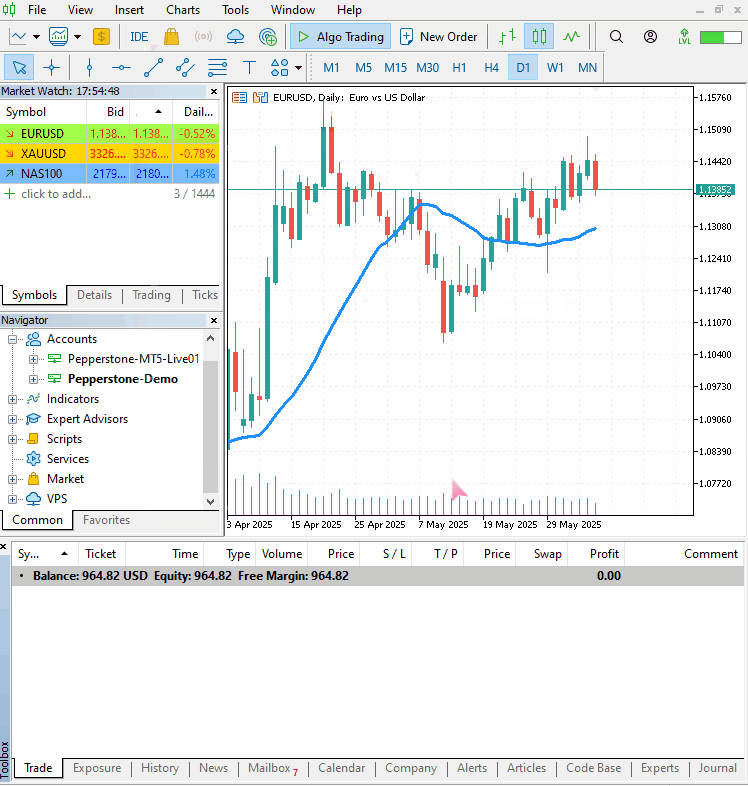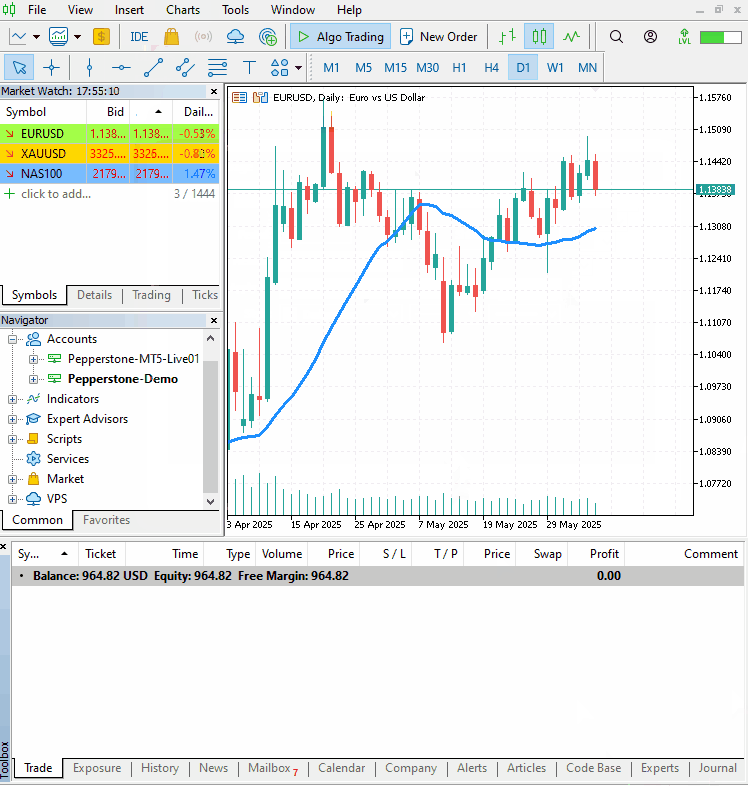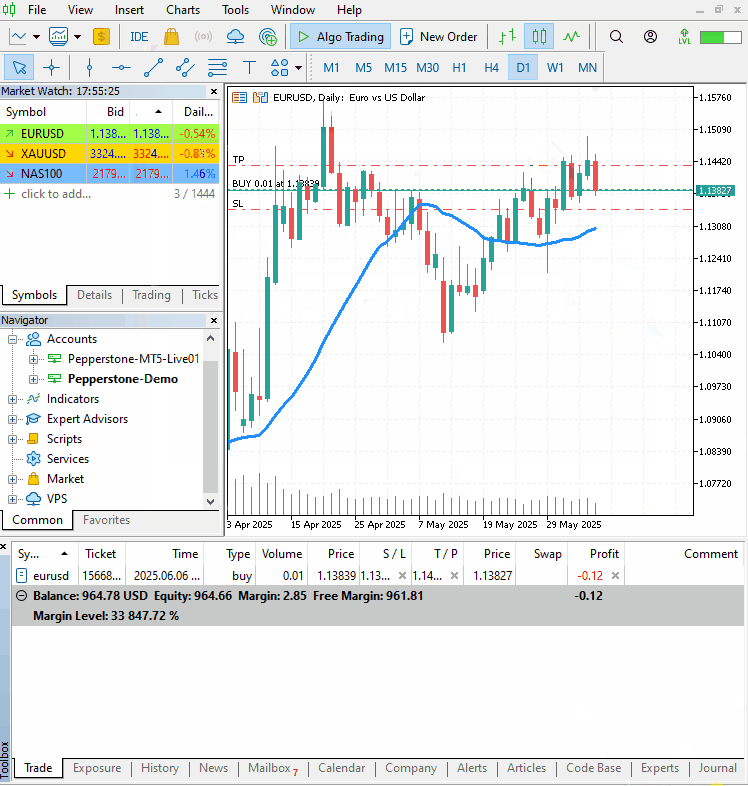
Considerações finais
A autorregressão vetorial é um modelo clássico de séries temporais capaz de prever múltiplas variáveis de regressão, algo que a maioria dos modelos de aprendizado de máquina não consegue fazer.
Vantagens desses modelos:
- Estrutura flexível de defasagens, permitindo usar diferentes números de defasagens para diferentes variáveis para diferentes variáveis.
- Captura interdependências, isto é, relações dinâmicas entre as variáveis.
- Não exige exogeneidade estrita, como nos modelos de regressão tradicionais.
No entanto, também há desvantagens:
- Sensibilidade à estacionariedade dos atributos: o modelo funciona melhor com dados estacionários.
- Pressupõe uma relação linear entre a variável e suas defasagens, o que nem sempre se verifica nos mercados financeiros.
- Há risco de sobreajuste quando há muitas variáveis e defasagens.
O objetivo do artigo é apresentar o modelo VAR, suas características e sua aplicação a dados de trading, já que há pouca informação sobre esse tema na internet. Incentivo todos a experimentar e adaptar essas ideias às suas próprias necessidades.
Boa sorte a todos!
Tabela de anexos
| Nome do arquivo | Descrição e finalidade |
|---|---|
| Trade/* | Classes de trading semelhantes às do MQL5, em Python. |
| error_description.py | Contém descrições dos códigos de erro do MetaTrader 5. |
| forex-ts-forecasting-using-var.ipynb | Notebook Jupyter contendo exemplos de treinamento do modelo. |
| VAR.py | Contém a classe que utiliza o modelo VAR para treinamento e geração de previsões. |
| VAR-TradingRobot.py | Robô de trading que executa operações de compra e venda com base nas previsões feitas pelo modelo VAR. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/18371
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso