
Neural Networks in Trading: Controlled Segmentation

Introduction
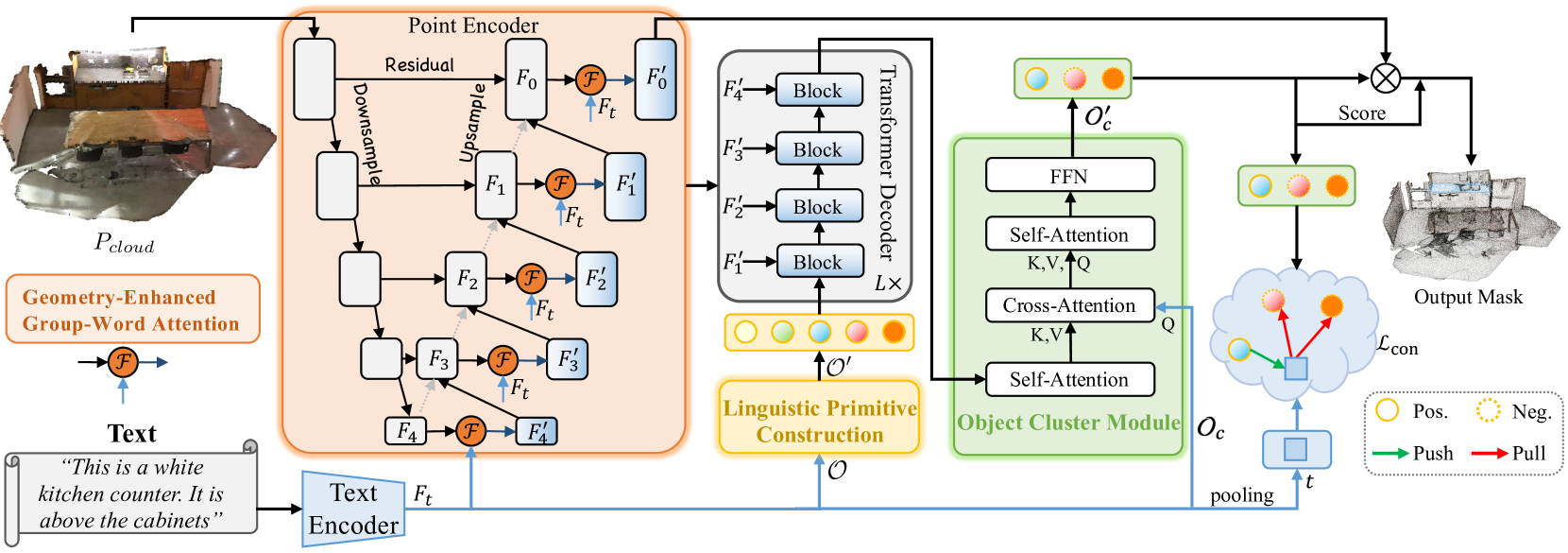
The task of guided segmentation requires the isolation of a specific region within a point cloud based on a natural language description of the target object. To solve this task, the model performs a detailed analysis of complex, fine-grained semantic dependencies and generates a point-wise mask of the target object. The paper "RefMask3D: Language-Guided Transformer for 3D Referring Segmentation" introduces an efficient and comprehensive framework that extensively leverages linguistic information. The proposed RefMask3D method enhances multimodal interaction and understanding capabilities.
The authors suggest the use of early-stage feature encoding to extract rich multimodal context. For this, they introduce the Geometry-Enhanced Group-Word Attention module, which enables cross-modal attention between the natural language object description and local point groups (sub-clouds) at each stage of feature encoding. This integration not only reduces the noise typically associated with direct point-word correlations which is caused by the sparse and irregular nature of point clouds, but also exploits intrinsic geometric relationships and fine structural details within the cloud. This significantly improves the model's ability to engage with both linguistic and geometric data.
Additionally, the authors incorporate a learnable "background" token that prevents irrelevant linguistic features from being entangled with local group features. This mechanism ensures that point-level representations are enriched with relevant semantic linguistic information, maintaining continuous and context-aware alignment with the appropriate language context across each group or object within the point cloud.
By combining computer vision and natural language processing features, the authors developed an effective strategy for target object identification in the decoder, termed Linguistic Primitives Construction (LPC). This strategy involves initializing a set of diverse primitives, each designed to represent specific semantic attributes such as shape, color, size, relationships, location, etc. Through interaction with relevant linguistic information, these primitives acquire corresponding attributes.
The use of semantically enriched primitives within the decoder enhances the model's focus on the diverse semantics of the point cloud, thereby significantly improving its ability to accurately localize and identify the target object.
To gather holistic information and generate object embeddings, the RefMask3D framework introduces the Object Cluster Module (OCM). Linguistic primitives are used to highlight particular parts of the point cloud that correlate with their semantic attributes. However, the ultimate goal is to identify the target object based on the provided description. This requires a comprehensive understanding of the language. This is achieved by integrating the object cluster module. Within this module, relationships among the linguistic primitives are first analyzed to identify shared features and distinctions in their core regions. Using this information, natural language-based queries are initialized. This allows us to capture these common features, forming the final embedding essential for target object identification.
The proposed Object Cluster Module plays a crucial role in enabling the model to achieve a deeper, more holistic understanding of both linguistic and visual information.
1. The RefMask3D algorithm
RefMask3D generates a point-wise mask of a target object by analyzing the initial point cloud scene along with the textual description of the desired attributes. The scene under analysis consists of N points, each containing 3D coordinate data P and an auxiliary feature vector F that describes attributes such as color, shape, and other properties.
Initially, a text encoder is employed to generate embeddings Ft from the textual description. Point-wise features are then extracted using a point encoder, which establishes deep interactions between the observed geometric form and the textual input via the Geometry-Enhanced Group-Word Attention module. The point encoder functions as a backbone similar to a 3D U-Net.
The Linguistic Primitives Constructor generates a set of primitives 𝒪′ to represent different semantic attributes, utilizing informative linguistic cues. This enhances the model's ability to accurately localize and identify the target object by attending to specific semantic signals.
The linguistic primitives 𝒪′, multi-scale point features {𝑭1′,𝑭2′,𝑭3′,𝑭4′} and language features 𝑭t serve as input to a four-layer cross-modal decoder built on the Transformer architecture.
Enriched linguistic primitives and object queries 𝒪c are then passed into the Object Cluster Module (OCM) to analyze interrelationships among the primitives, unify their semantic understanding, and extract shared characteristics.
A modality fusion module is deployed on top of the vision and language model backbones. The authors integrate multimodal fusion into the point encoder. Early-stage merging of cross-modal features improves the efficiency of the merging process. The Geometry-Enhanced Group-Word Attention mechanism innovatively processes local point groups (sub-clouds) with geometrically neighboring points. This approach reduces noise from direct point-word correlations and leverages inherent geometric relationships within the point cloud, improving the model’s capability to accurately fuse linguistic information with 3D structure.
Vanilla cross-modal attention mechanisms often struggle when a point lacks corresponding descriptive words. To address this issue, the authors introduce learnable background tokens. This strategy enables points with no related textual data to focus on a shared background token embedding, thereby minimizing distortion from unrelated text associations.
Incorporating points that lack linguistic matches into the background object cluster further reduces the impact of irrelevant elements. This results in point features refined with linguistically grounded attributes, centered on local centroids and unaffected by unrelated words. The background embedding is a trainable parameter that captures the overall distribution of the dataset and effectively represents the original input information. It is used exclusively in the attention computation phase. Through this mechanism, the model achieves more precise cross-modal interactions, uninfluenced by irrelevant language cues.
Most existing methods typically rely on centroids sampled directly from the point cloud. But a critical limitation of this approach is the neglect of linguistic context, which is essential for accurate segmentation. Sampling only the farthest points often causes predictions to deviate from the actual targets, particularly in sparse scenes, impeding convergence and leading to missed detections. This becomes especially problematic when selected points inaccurately represent the object or are tied to a single descriptive word. To address this, the authors propose the construction of linguistic primitives that incorporate semantic content, enabling the model to learn various semantic attributes associated with target-relevant objects.
These primitives are initialized by sampling from different Gaussian distributions. Each distribution represents a distinct semantic property. The primitives are designed to encode attributes such as shape, color, size, material, relationships, and location. Each primitive aggregates specific linguistic features and extracts the corresponding information. The linguistic primitives aim to express semantic patterns. Passing them through the Transformer decoder enables it to extract a wide range of linguistic cues, thereby improving object identification at later stages.
Each linguistic primitive focuses on distinct semantic patterns within the given point cloud that correlate with its respective linguistic attributes. The ultimate goal, however, remains the identification of a unique target object based on the provided textual description. This requires a comprehensive understanding and semantic interpretation of the object description. To achieve this, the authors employ the Object Cluster Module, which analyzes relationships among linguistic primitives, identifies common and divergent features across their key regions. This promotes a deeper understanding of the described objects. A Self-Attention mechanism is used to extract shared characteristics from the linguistic primitives. During decoding, object queries are introduced as Queries, while the shared features enriched by linguistic primitives serve as Key-Value. This configuration enables the decoder to merge linguistic insights from the primitives into object queries, thereby effectively identifying and grouping queries associated with the target object into 𝒪c′ and achieving precise identification.
While the proposed Object Cluster Module aids significantly in target object identification, it does not eliminate ambiguities that may arise during inference in other deployments. Such ambiguities can lead to false positives. To mitigate this, the authors of RefMask3D implement contrastive learning to distinguish the target token from others. This is done by maximizing similarity with the correct textual reference while minimizing similarity to negative (non-target) pairs.
A visualization of the RefMask3D method is presented below.
2. Implementation in MQL5
After considering the theoretical aspects of the RefMask3D method, let us move on to the practical part of our article. In this part, we will implement our vision of the proposed approaches using MQL5.
In the description above, the authors of the RefMask3D method divided the complex algorithm into several functional blocks. Therefore, it seems logical to build our implementations accordingly, in the form of corresponding modules.
2.1 Geometry-Enhanced Group-Word Attention
We begin by constructing the point encoder, which in the original method incorporates the Geometry-Enhanced Group-Word Attention module. We will implement this module in a new class named CNeuronGEGWA. As mentioned in the theoretical overview of RefMask3D, the point encoder is designed as a U-Net-style backbone. Accordingly, we selected CNeuronUShapeAttention as the parent class, which will provide the base functionality required for our object. The structure of the new class is shown below.
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
Most of the variables and objects that will allow us to organize the U-Net backbone are inherited from parent class. However, we introduce additional components for building cross-modal attention mechanisms.
All objects are declared as static, which allows us to leave the class constructor and destructor empty. The initialization of both inherited and newly added objects is handled within the Init method. As you know, this method receives parameters that provide explicit information about the required architecture of the object being created.
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
In the method body, we begin by calling the method of the same name from the base fully connected layer class CNeuronBaseOCL, which serves as the ultimate ancestor of all our neural layer objects.
Note that in this case, we are calling a method from the base class, rather than the immediate parent class. This is due to certain architectural features we use to build the U-Net backbone. Specifically, when constructing the "neck", we use the recursive creation of objects. At this stage, we need to utilize components from a different class.
Subsequently, we proceed to initialize the primary attention and scaling objects.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
Which is followed by the algorithm for creating the "neck". The type of "neck" object depends on its size. In general, we create an object similar to the current one. We just decrease the size of the inner "neck" by "1".
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
For the last layer, we use a cross-attention block.
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
We then initialize the re-attention and inverse scaling module.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
After that, we add a residual connection layer and a multimodal cross-attention module.
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
We also initialize an auxiliary buffer for temporary data storage.
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
At the end of the initialization method, we substitute pointers to data buffers to minimize the data copying operations.
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
We then return a Boolean value to the calling program, indicating the execution result of the method operations.
After completing the work on initializing the new object, we move on to constructing feed-forward algorithm in the feedForward method. Unlike the parent class, our new object requires two data sources. Therefore, the inherited method designed to work with a single data source has been overridden with a negative stub. The new method, in contrast, was written from scratch.
In the method parameters, we receive pointers to two input data objects. However, at this stage, no validation checks are performed on either of them.
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
First, we pass the pointer to one of the data sources to the method of the same name in the primary attention sublayer. Pointer validation is already handled internally by that method. So, we only need to check the logical result of its execution. Then we scale the output of the attention block.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
We pass the scaled data and a pointer to the second data source object to the "neck".
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
We pass the obtained result through the second attention block and perform inverse data scaling.
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
After that, we add residual connections and perform cross-modal dependency analysis.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
Before we begin working on the backpropagation methods, there is one point that needs to be discussed. Take a look at the excerpt from the visualization of the RefMask3D method below.
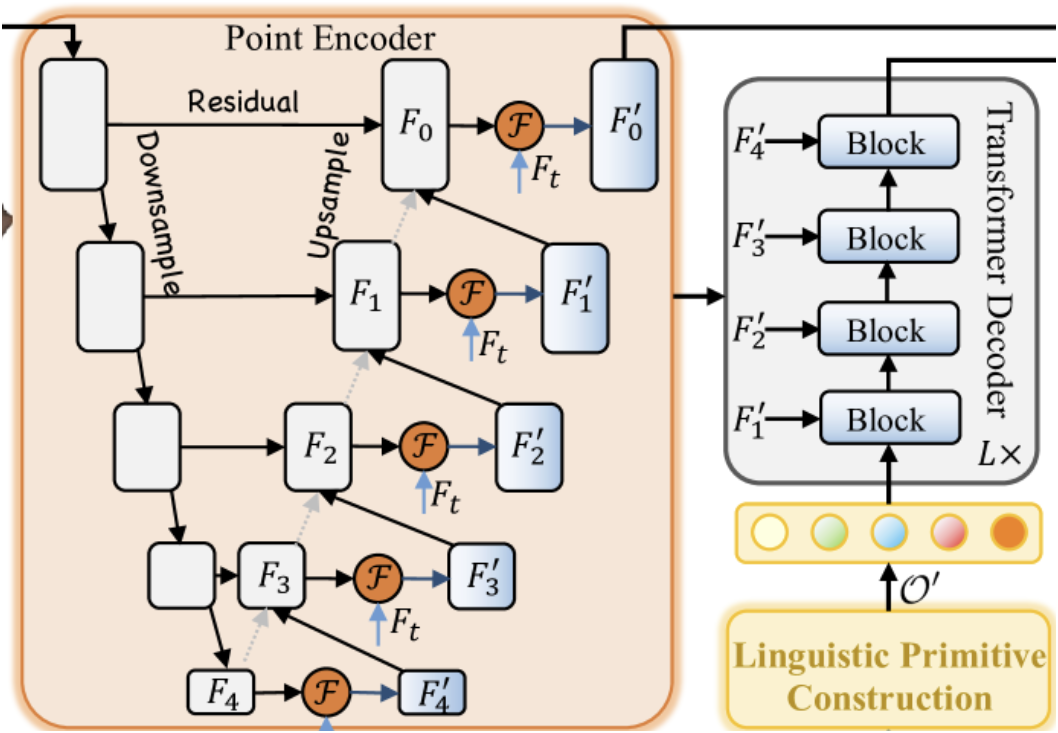
The key point here is that in the Decoder, cross-modal attention is performed between the trainable primitives and the intermediate outputs of our point Encoder. This seemingly simple operation actually implies the need for a corresponding error gradient flow. Naturally, we must implement the appropriate interfaces to support this. While implementing the gradient distribution across our unified RefMask3D block, we will first compute the Decoder gradients and then we calculate the gradients of the point Encoder. However, with a classic gradient backpropagation model, this sequencing would result in the loss of gradient data passed from the Decoder. We recognize, however, that this specific use of the block represents a special case. Therefore, in the calcInputGradients method, we provide two operational modes: one that clears previously stored gradients (standard behavior) and one that preserves them (for special cases like this). To enable this functionality, we introduced an internal flag variable bAddNeckGradient and a corresponding setter method AddNeckGradient.
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
But let's get back to or backpropagation algorithm. In the parameters of the calcInputGradients method, we get pointers to 3 objects and a constant of the activation function of the second data source.
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
In the method body, we check the relevance of the pointer to the first data source only. The rest of the pointers are checked in the body of the error gradient distribution methods of the internal layers.
Since we implemented substitution of pointers to data buffers, the error gradient distribution algorithm starts from the inner layer of cross-modal attention.
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
After that, we perform scaling of the error gradients.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Then we organize the branching of the algorithm depending on whether we need to preserve the previously accumulated error gradient. If the error needs to be preserved, we will replace the error gradient buffer in the "neck" with a similar gradient buffer from the first data scaling layer. Here we exploit the following property: the size of the output tensors of the specified scaling layer is equal to that of the "neck". We will transfer the error gradient to this layer later. Therefore, in this case, its operation is safe.
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
Next, we obtain the error gradient at the "neck" level using the classical method. We sum the results from the two information steams and return pointers to the objects.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
In the case where the previously accumulated error gradient is not needed, we simply obtain the error gradient using standard methods.
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
Next, we need to propagate the an error gradient through the "neck" object. This time we use the classical method. Here we receive the error gradient of the second data source into the temporary data storage buffer. Later, we will need to sum up the values obtained from the cross-modal attention module of the current object and the neck.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
We then propagate the error gradient to the level of the first source of input data.
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
We propagate the gradient of the residual connections error through the derivative of the activation function and sum the information from the two streams.
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
The updateInputWeights method for updating the model parameters is quite simple. We call the corresponding update methods of the internal layers that contain trainable parameters. Therefore, I encourage you to explore their implementations independently. The full implementation of this class and all its methods can be found in the attachment.
I'd like to add a few words about the creation of an interface for accessing "neck" objects. To implement this functionality, we've created the GetInsideLayer method. In its parameters, we will pass the index of the required layer.
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
If a negative index is obtained, this means an error has occurred. In this case, the method returns a NULL pointer. A value of zero indicates that the current layer is being accessed. Therefore, the method will return a pointer to the "neck" object.
if(layer == 0) return cNeck;
Otherwise, the neck must be an object of the corresponding class and we recursively call this method with the index of the required layer reduced by 1.
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 Linguistic Primitives Construction
In the next step, we create an object for the Linguistic Primitives Construction module in the CNeuronLPC class. The original visualization of this method is presented below.
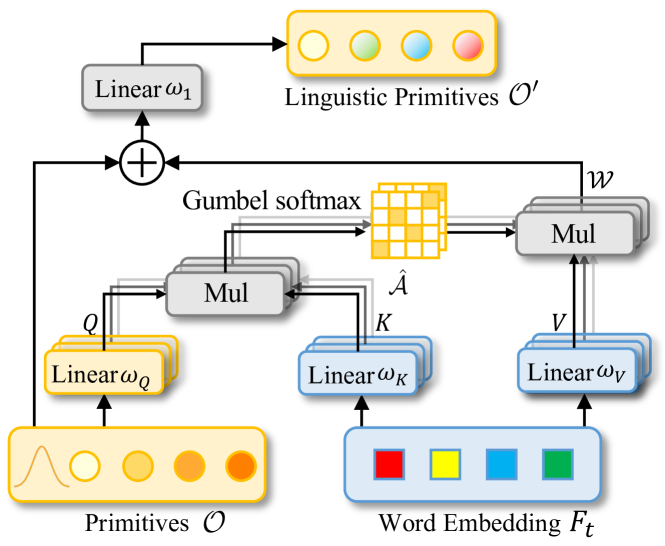
We can notice here the similarities with the classic cross-attention block, which suggests choosing the relevant parent class. In this case, we use a the CNeuronMLCrossAttentionMLKV cross-attention object class. The structure of the new class is shown below.
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
In the previous case, we added sources of input data for the feed-forward and backpropagation passes. However, in this case, it is the other way around. Although the cross-attention module requires two data sources, we will use only one in this implementation. This is because the second data source (the trainable primitives) is generated internally within this object.
To generate these trainable primitives, we define two internal fully connected layer objects. Both of these objects are declared as static, allowing us to leave the class constructor and destructor empty. The initialization of these declared and inherited objects is performed in the Init method.
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
In the parameters of this method, we receive constants that allow us to uniquely determine the architecture of the object being created. In the method body, we immediately call the relevant method of the parent class, which implements the control of the received parameters and the initialization of the inherited objects.
Please note that we use the parameters of the generated primitives as information about the primary data source.
Next, we generate a single fully connected layer consisting of one element.
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
Then we initialize the generation layer with a primitive.
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
Note that in this case, we do not use a positional encoding layer. According to the original logic, some primitives are responsible for capturing the object's position, while others accumulate its semantic attributes.
The feedForward method in this implementation is also quite simple. It takes as a parameter a pointer to the input data object, and the first step is to verify the validity of this pointer. I should point out that this is not commonly done in more recent feed-forward methods.
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Such checks are typically handled internally by nested components. However, in this case, the data received from the external program will be used as context. This means that when we call methods of internal objects, we will need to access nested members of the provided input object. For this reason, we are obligated to explicitly check the validity of the incoming pointer.
Next, we generate the feature tensor.
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
It should be noted here that, to reduce the duration of the decision-making process, this operation is only performed during training. In the deployment phase, the primitive tensor remains static, and therefore does not need to be regenerated on every iteration.
The forward pass concludes with a call of the feedForward method of the parent class. To this method, we pass the generated tensor of primitives as the primary data source and the contextual information from the external program as the secondary input.
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
In the calcInputGradients gradient propagation method, we perform the operations of the feed-forward pass algorithm in reverse order.
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Here we also first check the received pointer to the source data object. And then we call the method of the parent class with the same name, distributing the error gradient between the primitives and the original context.
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
After that, we add the gradient of the primitive diversification error.
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
The propagation of the error gradient down to the level of an individual layer holds little practical value, so we omit this operation. The parameter update algorithm is also left for independent exploration. You can find the full code of this class and all its methods in the attachment.
The next component in the RefMask3D pipeline is the vanilla Transformer decoder block, which implements the multimodal cross-attention mechanism between the point cloud and the learnable primitives. This functionality can be covered using the tools we have previously developed. So, we will not create a new block specifically for this purpose.
Another module we do need to implement is the object clustering module. The algorithm for this module will be implemented in the CNeuronOCM class. This is a fairly complex module. It combines two Self-Attention blocks: one for the primitives and another for the semantic features. They are augmented with a cross-attention block. The structure of the new class is shown below.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
I believe it's clear that the methods within this class involve fairly complex algorithms. Each of them requires detailed explanation. However, the format of this article is somewhat limited. Therefore, in order to provide a thorough and high-quality overview of the implemented algorithms, I propose to continue the discussion in a follow-up article. That article will also present the testing results of the models using the proposed approaches on real-world data.
Conclusion
In this article, we explored the RefMask3D method, designed for analyzing complex multimodal interactions and feature understanding. The method holds significant potential as an innovation in the field of trading. By leveraging multidimensional data, it can account for both current and historical patterns in market behavior. RefMask3D employs a range of mechanisms to focus on key features while minimizing the impact of noise and irrelevant inputs.
In the practical section, we began implementing the proposed concepts using MQL5 and developed the objects for two of the proposed modules. However, the scope of the completed work exceeds what can be reasonably covered in a single article. Therefore, the work we have started will be continued.
References
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA for collecting examples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA for collecting examples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Model training EA |
| 4 | Test.mq5 | Expert Advisor | Model testing EA |
| 5 | Trajectory.mqh | Class library | System state description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Library | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/16038
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use