
Redes neurais de maneira fácil (Parte 62): uso do transformador de decisões em modelos hierárquicos

Introdução
Ao resolver problemas reais, frequentemente enfrentamos o problema de ambientes estocásticos e dinamicamente variáveis, o que nos obriga a buscar novos algoritmos adaptativos. Nas últimas décadas, esforços significativos foram direcionados ao desenvolvimento de métodos de aprendizado por reforço (RL), que permitem treinar agentes para se adaptarem a ambientes e tarefas variados. No entanto, a aplicação de RL em condições reais enfrenta uma série de dificuldades. Isso inclui o problema do treinamento offline em ambientes variáveis e estocásticos. Assim como as complexidades de planejamento e controle em espaços de ação e estado de alta dimensão.
Muito frequentemente, ao resolver tarefas complexas, a maneira mais eficaz é dividir um problema em suas subtarefas componentes. Discutimos as vantagens dessa abordagem ao considerar métodos hierárquicos. Essas abordagens integradas permitem criar modelos mais adaptativos.
Anteriormente, consideramos modelos hierárquicos para resolver problemas com a abordagem clássica de Markov. No entanto, as vantagens do uso de abordagens hierárquicas também são aplicáveis a tarefas de análise de sequências. Um desses algoritmos é o Control Transformer, apresentado no artigo "Control Transformer: Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling". Os autores do método o posicionam como uma nova arquitetura, projetada para resolver tarefas complexas de controle e navegação com base em aprendizado por reforço. Este método combina métodos modernos de aprendizado por reforço, planejamento e aprendizado de máquina, o que permite criar estratégias adaptativas de controle em ambientes variados.
O Control Transformer abre novas perspectivas para resolver tarefas complexas de controle em robótica, condução autônoma e outras áreas. Eu proponho que olhemos para as perspectivas de usar este método para resolver nossas tarefas de trading.
1. Control Transformer
O algoritmo Control Transformer é um método bastante complexo e inclui vários blocos distintos, característicos de modelos hierárquicos. Também é importante dizer que o algoritmo foi desenvolvido para a navegação e controle do comportamento de robôs. Cabe mencionar que é neste contexto que é apresentada a descrição do algoritmo.
Para resolver o problema de controle em um longo horizonte de planejamento, os autores do método propõem decompor em subtarefas menores, em forma de segmentos de distância limitada. Os autores usam mapas de rotas probabilístico para construir o grafo G, no qual os vértices são pontos, e as arestas indicam a possibilidade de movimento entre pontos conectados usando um planejador local. Este grafo é construído com base em uma amostra de n pontos aleatórios no ambiente, que são posteriormente conectados com pontos vizinhos a uma distância não maior que d (hiperparâmetro), formando uma aresta no grafo se houver um caminho entre os pontos.
Assim, no grafo obtido G podemos alcançar qualquer ponto de destino Xg a partir de qualquer ponto de partida X0. Isso é alcançado mediante a busca - no grafo - pelos vizinhos mais próximos dos pontos inicial e final. E então, usando um algoritmo de busca do caminho mais curto, obtemos uma sequência de pontos de passagem (trajetória). Após isso, o robô pode se mover do estado inicial ao objetivo, executando as ações da política do controlador local πc. A sequência de pontos de passagem ou plano, que orienta a política πc, pode ser fixa ou atualizada à medida que o robô avança.
Para treinar a política local πc, os autores do método usaram o método de aprendizado por reforço, direcionado ao alcance do objetivo (GCRL). Isso envolve modelar a tarefa mediante o processo de decisão de Markov condicionado pelo objetivo. A utilização de planejamento baseado em amostragem para estabelecer objetivos e treinar estratégias é presumida.
Para isso, dentro do ambiente de treinamento, primeiramente usa-se um mapa de rotas probabilístico para obter o grafo G, como descrito anteriormente. Em seguida, para cada episódio de treinamento, é escolhida uma aresta do grafo que serve como início e objetivo para esse episódio. Este processo é compatível com qualquer algoritmo de treinamento orientado a objetivos. Os autores usaram o Soft Actor-Critic em seus experimentos com recompensas densas proporcionais ao progresso até o objetivo. Estratégias de baixo nível podem ser eficazmente treinadas, uma vez que o espaço de estados das estratégias contém apenas informações sobre a posição própria e elas não precisam aprender a evitar restrições.
Após o treinamento da política local πc, precisamos configurar o processo que irá orientá-la para alcançar o objetivo global. Em outras palavras, temos que treinar o modelo que gera trajetórias planejadas. Os objetivos e recompensas deste modelo são definidos em relação ao objetivo final, e não aos pontos de passagem seguidos pela πc. Claramente, para alcançar os objetivos globais, o modelo requer mais dados de entrada. Dados de baixa dimensão sobre o estado local são complementados por observações de alta dimensão e outras informações disponíveis. Por exemplo, um mapa local.
Para treinar o modelo com dados coletados mediante planejamento baseado em amostragem, examinamos a tarefa de modelagem de sequência. Mas incluímos uma orientação para alcançar o objetivo. Em seu trabalho, os autores do método também consideram um ambiente de múltiplas tarefas parcialmente observável, onde a estratégia pode operar em vários ambientes com a mesma tarefa de navegação, mas com estruturas diferentes para cada ambiente. Apesar da possibilidade de treinar a previsão autorregressiva de ações nesta sequência, enfrentamos alguns problemas. Assim como no DT, o RTG ótimo é considerado constante porque não conhecemos a recompensa preditiva inicial ótima, que depende da estrutura desconhecida do ambiente. E isso pode mudar de episódio para episódio. Bem como dos estados iniciais e das posições dos objetivos. Portanto, precisamos investigar as mudanças que permitirão que o DT generalize para ambientes desconhecidos, funcionando de qualquer posição inicial para qualquer objetivo.
Uma das abordagens é aprender a distribuição completa do RTG a partir de dados offline. E então selecionar as condições durante a utilização a partir dessa distribuição. No entanto, é difícil aprender a distribuição completa do RTG em uma tarefa orientada a objetivos, para que possamos generalizar e prever o RTG em ambientes desconhecidos. Em vez disso, os autores do método propõem aprender a função de valor médio para essa distribuição. Que avalia a recompensa esperada no ponto S dado um objetivo g dentro da trajetória T. Esta função também não é condicionada ao histórico passado, pois no momento do início da utilização, prevemos a recompensa esperada inicial R̃0. Em seguida, ajustamos o RTG à recompensa real do ambiente. A função de valor é parametrizada como uma rede neural separada e é treinada usando MSE.
Para obter um comportamento mais ótimo, o valor de valor aprendido pode ser ajustado por um coeficiente constante. Além disso, a função de valor pode ser treinada apenas nas melhores trajetórias ou naquelas que satisfazem alguma condição predefinida.
Abaixo podemos ver uma representação do método Control Transformer criada pelo próprio autor.
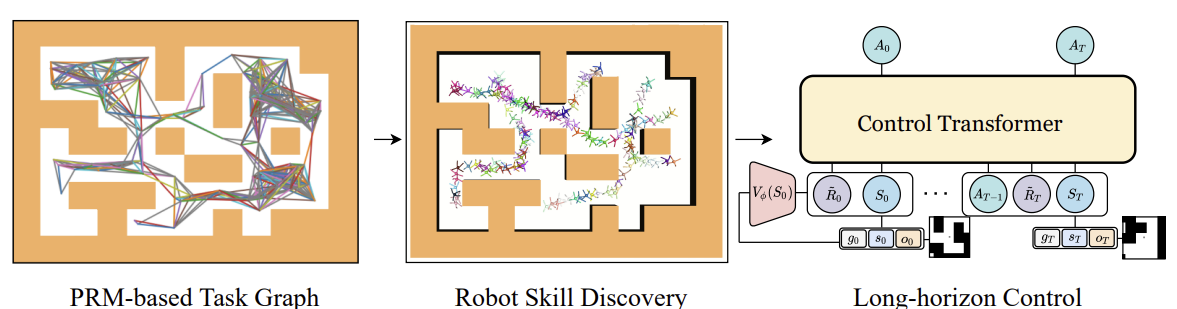
Um dos problemas comuns no treinamento offline é o desvio de distribuição. Quando a estratégia treinada é aplicada na prática, e a distribuição real de trajetórias não corresponde à distribuição da amostra de treinamento. Isso pode causar erros acumulativos e levar a situações em que a estratégia se torna subótima. Para resolver este problema, os autores do método sugerem, após a fase de treinamento offline, expandir a amostra de treinamento usando a política atual do modelo. E então realizar um ajuste fino dos modelos offline.
2. Implementação com MQL5
Após discutir os aspectos teóricos do método Control Transformer, passamos para sua implementação com MQL5. Como já mencionado anteriormente, o algoritmo é complexo. Assim, durante a implementação, vamos utilizar desenvolvimentos de uma série de artigos anteriores. E o primeiro passo que começamos a considerar o método foi a construção de um grafo de possíveis movimentos.
2.1. Coleta de amostra de treinamento
Em nosso caso de um ambiente estocástico e um espaço de ações contínuo, a construção de um grafo semelhante pode ser uma tarefa desafiadora. Decidimos abordar a tarefa pelo outro lado e usar nossos desenvolvimentos do método Go-Explore. Fizemos pequenas correções no EA "...\CT\Faza1.mq5" e coletamos possíveis trajetórias de operações de trading durante o período de treinamento. Selecionamos trajetórias com a maior rentabilidade.
Para isso, adicionamos nos parâmetros externos do EA o número máximo de ações amostradas e o comprimento mínimo da trajetória. A introdução desses parâmetros foi causada pela probabilidade muito baixa (próxima de "0") de amostrar uma trajetória aceitável em todo o intervalo de treinamento em uma única passagem. É muito mais provável amostrar gradualmente pequenos segmentos com transações lucrativas, que depois são compilados em uma sequência de ações lucrativa total.
input int MaxSteps = 48; input int MinBars = 20;
Lembro que neste EA não são usados modelos de redes neurais. Todas as ações são amostradas de uma distribuição uniforme.
No método de inicialização do EA, primeiro inicializamos objetos de indicadores e a classe de operações de trading.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Inicializamos as variáveis necessárias e amostramos a trajetória e o estado inicial para continuar uma trajetória anteriormente salva. Claro, tal amostragem é possível apenas se houver trajetórias previamente salvas.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); AgentResult = vector<float>::Zeros(NActions); //--- int error_code; if(Buffer.Size() > 0 || LoadTotalBase()) { int tr = int(MathRand() / 32767.0 * Buffer.Size()); Loaded = Buffer[tr]; StartBar = MathMax(0,Loaded.Total - int(MathMax(Math::MathRandomNormal(0.5, 0.5, error_code), 0) * MaxSteps)); } //--- return(INIT_SUCCEEDED); }
Na ausência de trajetórias anteriores, o EA começa a amostrar ações desde a primeira barra.
A coleta de dados ocorre na função de processamento de ticks OnTick. Aqui, como antes, verificamos a ocorrência de uma nova barra e, se necessário, carregamos dados históricos do movimento do instrumento e dos indicadores.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- CurrentBar++; int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Transferimos os dados carregados para uma estrutura para gravação no buffer de reprodução de experiências.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Adicionamos informações sobre o estado da conta e a recompensa do ambiente.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(sState.account[1] / PrevBalance - 1.0);
E redefinimos as variáveis internas.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Em seguida, precisamos escolher a ação do Agente. Como mencionado anteriormente, aqui não usamos modelos. Em vez disso, verificamos o início da fase de amostragem. Ao repetir uma trajetória previamente salva, pegamos a ação de nossa trajetória. Se o período de amostragem começou, geramos um vetor de ações de uma distribuição uniforme.
vector<float> temp = vector<float>::Zeros(NActions); if((CurrentBar - StartBar) < MaxSteps) if(CurrentBar < StartBar) temp.Assign(Loaded.States[CurrentBar].action); else temp = SampleAction(NActions);
A ação obtida é executada no ambiente.
//--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
E os resultados da interação são adicionados ao buffer de reprodução de experiências.
//--- int shift = BarDescr * (NBarInPattern - 1); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState) || (CurrentBar - StartBar) >= MaxSteps) ExpertRemove(); //--- }
Aqui também verificamos a realização do número máximo de passos amostrados e, se necessário, iniciamos o encerramento do programa.
Algumas palavras devem ser ditas sobre as mudanças no método de adicionar trajetórias ao buffer de reprodução de experiências. Se anteriormente as trajetórias eram adicionadas pelo método FIFO — primeiro a entrar, primeiro a sair; agora mantemos os passes mais lucrativos. Portanto, após concluir uma passagem, primeiro verificamos o tamanho do nosso buffer de reprodução de experiências.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(total >= MaxReplayBuffer) {
Ao atingir o tamanho limite do buffer, primeiro procuramos por uma passagem com a menor rentabilidade das previamente salvas.
for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Comparamos a rentabilidade da nova passagem com a menor no buffer de reprodução de experiências e, se necessário, registramos a nova passagem em vez da mínima.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
Isso nos permite dispensar a ordenação onerosa dos dados no buffer. Em uma única passagem, determinamos o valor mínimo e a viabilidade de salvar uma nova trajetória.
Se o tamanho limite do buffer de reprodução de experiências ainda não foi atingido, simplesmente adicionamos a nova passagem. E concluímos o trabalho do método.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Com isso, concluímos nossa introdução ao EA de interação com o ambiente. E você pode se familiarizar com seu código completo no anexo.
2.2. Treinamento de habilidades
A próxima etapa será criar um EA para treinamento da política local. Deve-se dizer que a política local atua como um executor que segue as instruções do planejador superior. E aqui, com o objetivo de simplificar o próprio modelo da política local e no espírito dos sistemas hierárquicos, decidimos não alimentar o modelo com o estado atual do ambiente. Na nossa visão de arquitetura, isso será um modelo que possui um conjunto de habilidades. E a escolha da habilidade utilizada fica a cargo do planejador. Enquanto isso, o próprio modelo da política local não analisará o estado do ambiente.
Para o treinamento das habilidades, utilizaremos a arquitetura de um autocodificador e os desenvolvimentos das modelos hierárquicos previamente considerados. Durante o treinamento, vamos alimentar aleatoriamente com uma habilidade o nosso modelo de política local. E o discriminador tentará identificar a habilidade usada.
Aqui, precisamos determinar a quantidade necessária de habilidades treináveis. Neste ponto, também recorremos aos nossos trabalhos anteriores. Ao considerar métodos de agrupamento, determinamos o número ótimo de clusters entre 100 e 500. Para evitar uma escassez de habilidades, especificaremos o tamanho do vetor de dados de entrada da política local como 512 elementos.
#define WorkerInput 512
Abaixo estão apresentadas as arquiteturas dos modelos de política local e do discriminador. Não complicamos muito esses modelos. Na entrada do modelo da política local, esperamos receber um vetor one-hot. Ou um vetor de dados normalizados pela função SoftMax. Por isso, não adicionamos uma camada de normalização em lote após a camada de dados de entrada.
bool CreateWorkerDescriptions(CArrayObj *worker, CArrayObj *descriminator) { //--- CLayerDescription *descr; //--- if(!worker) { worker = new CArrayObj(); if(!worker) return false; } //--- Worker worker.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Em seguida, vêm duas camadas de rede neural totalmente conectadas com diferentes funções de ativação.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Depois disso, reduzimos a dimensão da camada e normalizamos os dados pela função SoftMax no contexto do espaço de ações do nosso Agente.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
E na saída da política local, uma camada de rede neural totalmente conectada do tamanho do vetor de ações do Agente.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
O modelo do discriminador tem uma arquitetura um pouco inversa, no estilo de um decodificador. Alimentamos o modelo com o vetor de ações do Agente, que é gerado pelo modelo da política local. Aqui também não usamos uma camada de normalização em lote.
//--- Descriminator if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } //--- descriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Seguem as mesmas camadas totalmente conectadas que usamos na política local.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Depois disso, alteramos a dimensão para o número de habilidades usadas e normalizamos as probabilidades de uso das habilidades pela função SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Criamos modelos o mais simples possível. Isso nos permitirá maximizar a velocidade de operação tanto no treinamento quanto no de utilização.
Para treinar as habilidades, criaremos o EA "...\CT\StudyWorker.mq5". Não vamos nos deter na análise detalhada de todos os métodos deste EA. Vamos considerar apenas o método direto de treinamento dos modelos, Train.
No corpo deste método, realizamos um ciclo de treinamento dos modelos pelo número de iterações especificado no parâmetro externo do EA. Dentro do ciclo, primeiro formamos um vetor one-hot aleatório do tamanho do número de habilidades.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { Data.BufferInit(WorkerInput, 0); int pos = int(MathRand() / 32767.0 * (WorkerInput - 1)); Data.Update(pos, 1.0f);
Alimentamos com este vetor o modelo da política local e realizamos a propagação. Alimentamos o discriminador com o resultado obtido.
//--- Study if(!Worker.feedForward(Data,1,false) || !Descrimitator.feedForward(GetPointer(Worker),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Não esquecemos de controlar a execução das operações.
Após uma propagação bem-sucedida de ambos os modelos, realizamos a retropropagação com o objetivo de minimizar os desvios entre a habilidade real e a identificada pelo discriminador.
if(!Descrimitator.backProp(Data,(CBufferFloat *)NULL, (CBufferFloat *)NULL) || !Worker.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Em seguida, apenas precisamos informar o usuário sobre o progresso do treinamento e passar para a próxima iteração do ciclo.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Desciminator", iter * 100.0 / (double)(Iterations), Descrimitator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão de todas as iterações do ciclo, limpamos o campo de comentários. Exibimos o resultado do treinamento. E iniciamos o encerramento do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Descriminator", Descrimitator.getRecentAverageError()); ExpertRemove(); //--- }
Este método relativamente simples nos permite treinar uma quantidade necessária de habilidades distintas. Durante a construção de modelos hierárquicos, é muito importante a distinção das habilidades com base nas ações realizadas. Isso ajuda a diversificar o comportamento do modelo e facilita o trabalho do planejador na escolha da habilidade certa no estado específico do ambiente.
2.3. Treinamento da função de custo
Em seguida, passamos para o estudo da função de custo. Espera-se que o modelo treinado possa prever o retorno potencial após analisar o estado atual do ambiente. Essa é essencialmente uma estimativa do estado futuro no RL clássico, que estudamos de alguma forma em todos os modelos. Só que os autores do método propõem considerá-la sem o fator de desconto.
Eu decidi fazer um experimento avaliando o custo não até o final do episódio, mas apenas em um pequeno horizonte de planejamento. Minha lógica era que não planejamos abrir uma posição e mantê-la "até o fim dos tempos". Em condições de estocasticidade de mercado, previsões de longo alcance têm uma probabilidade muito baixa. De resto, a abordagem permaneceu bastante reconhecível. E novamente, não compliquei demais o modelo. A arquitetura do modelo é apresentada abaixo.
Alimentamos o modelo com uma pequena quantidade de dados históricos sobre o estado do ambiente. Neste modelo, avaliaremos apenas a situação de mercado para estimar o potencial básico. Note que, neste caso, não estamos interessados em tendências ou padrões. Nosso foco está na intensidade do mercado. E como usamos dados brutos, neste modelo já utilizamos uma camada de normalização em lote.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Os dados normalizados são processados por uma camada convolucional no contexto das velas, o que nos permite identificar os padrões principais.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = ValueBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; }
Após isso, os dados são processados por um bloco de camadas totalmente conectadas e o resultado é emitido na forma de um vetor de recompensa decomposta.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Para treinar a função de custo, criamos o EA "...\CT\StudyValue.mq5". Aqui também focaremos no método de treinamento do modelo, Train. Para treinar este modelo, precisaremos de uma amostra de treinamento. Portanto, no corpo do ciclo de treinamento, amostramos a trajetória e o estado.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); int check = 0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 * ValueBars)); if(i < 0) { iter--; continue; check++; if(check >= total_tr) break; }
Note que, ao amostrar a trajetória, reduzimos o alcance dos estados possíveis ao dobro da quantidade de ValueBars. Isso se deve ao fato de que, no buffer de reprodução de experiências, cada estado contém apenas a última barra (relacionado ao uso da arquitetura GPT em DT), e precisamos de várias barras de dados históricos para avaliar o potencial. E o segundo ponto, do total acumulado de recompensa até o final do episódio, estaremos descontando a recompensa fora do horizonte de planejamento.
Em seguida, preenchemos o buffer de dados de entrada.
check = 0; //--- History data State.AssignArray(Buffer[tr].States[i].state); for(int state = 1; state < ValueBars; state++) State.AddArray(Buffer[tr].States[i + state].state);
E realizamos a propagação do modelo.
//--- Study if(!Value.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Depois, precisamos preparar os dados alvo para o treinamento do modelo. Pegamos do buffer de reprodução de experiências a recompensa acumulada no momento da avaliação do estado e subtraímos a recompensa acumulada fora do horizonte de planejamento. Carregamos então os resultados da propagação do modelo e, usando o método CAGrad, ajustamos o vetor de valores alvo.
vector<float> target, result; target.Assign(Buffer[tr].States[i + ValueBars - 1].rewards); result.Assign(Buffer[tr].States[i + 2 * ValueBars - 1].rewards); target = target - result*MathPow(DiscFactor,ValueBars); Value.getResults(result); Result.AssignArray(CAGrad(target - result) + result);
O vetor de valores alvo preparado é passado para o modelo e realizamos a retropropagação. Ao fazer isso, não esquecemos de controlar a execução das operações.
if(!Value.backProp(Result, (CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Em seguida, informamos ao usuário sobre o treinamento do modelo e passamos para a próxima iteração do ciclo de treinamento.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Value", iter * 100.0 / (double)(Iterations), Value.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão bem-sucedida de todas as iterações do ciclo, limpamos o campo de comentários no gráfico do instrumento. Registramos no log o resultado do treinamento do modelo. E iniciamos a finalização do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Value", Value.getRecentAverageError()); ExpertRemove(); //--- }
Você pode se familiarizar com o código completo deste EA, assim como todos os programas utilizados no artigo, no anexo.
2.4. Treinamento do Planejador
Agora passamos para a próxima fase do nosso trabalho e criaremos o Planejador do nosso modelo hierárquico. Neste caso, o papel do planejador é desempenhado pelo Decision Transformer, que analisará a sequência de estados visitados e as ações realizadas neles. E na saída do planejador, esperamos obter a habilidade que será usada pelo nosso modelo de política local para gerar ações.
E começaremos com a arquitetura do modelo. Como dados de entrada, usaremos o vetor de descrição de um estado em nossa trajetória, que inclui todas as informações possíveis. Deve-se dizer que as informações são fornecidas sem processamento, por isso usamos uma camada de normalização em lote para o pré-processamento dos dados.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Além disso, os dados no vetor de entrada são coletados de fontes variadas. Consequentemente, têm diferentes dimensões e distribuições. Uma camada de incorporação é aplicada para facilitar seu uso posterior e padronização.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Os dados preparados passam por um bloco de atenção esparsa.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Depois disso, reduzimos a dimensão dos dados com uma camada convolucional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Em seguida, os dados passam por um bloco de tomada de decisão de camadas totalmente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Na saída, reduzimos a dimensão dos dados para o número de habilidades usadas e normalizamos sua probabilidade com a função SoftMax.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Após considerar a arquitetura do modelo, passamos para a construção do EA de treinamento do Planejador "...\CT\Study.mq5". E, seguindo a tradição estabelecida, focaremos apenas no método de treinamento do modelo, Train.
Aqui deve-se dizer que a abordagem para o treinamento do DT praticamente não mudou. No modelo, estabelecemos dependências entre os dados de entrada (incluindo RTG) e a ação realizada pelo Agente. Mas há nuances relacionadas aos princípios de construção do algoritmo considerado:
- O RTG deve ser não até o fim do episódio, mas apenas para o horizonte de planejamento;
- na saída do DT, temos uma habilidade, não ações. Para a transferência do gradiente de erro, é usada o modelo da política local.
Todas essas nuances são refletidas no treinamento do modelo.
No corpo do método Train, fazemos um sistema de ciclos de treinamento de modelos como antes. No corpo do ciclo externo, amostramos a trajetória e o estado inicial para treinamento do modelo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float err=0; int err_count=0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars-ValueBars,MathMin(Buffer[tr].Total,20+ValueBars))); if(i < 0) { iter--; continue; }
O treinamento em si é realizado no corpo do ciclo aninhado. Lembro que, devido às características da arquitetura GPT durante o treinamento, precisamos usar dados históricos estritamente na ordem em que são recebidos.
No buffer de dados de entrada, carregamos sequencialmente indicadores de movimento de preço e de outros indicadores.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - 2 - ValueBars,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Dados sobre o estado da conta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
O rótulo de tempo e a última ação do Agente.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Em seguida, precisamos indicar o RTG. Aqui, usamos a recompensa acumulada real, ajustando-a previamente para o horizonte de planejamento.
//--- Return-To-Go vector<float> rtg; rtg.Assign(Buffer[tr].States[state+1].rewards); Actions.Assign(Buffer[tr].States[state+ValueBars].rewards); rtg=rtg-Actions*MathPow(DiscFactor,ValueBars); State.AddArray(rtg);
Alimentamos o Planejador com os dados coletados dessa maneira e chamamos o método de propagação. A habilidade prevista obtida é passada à entrada do modelo de política local e realizamos sua propagação para prever a ação do Agente.
//--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat *)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A ação do Agente prevista dessa forma é comparada com a ação real do buffer de reprodução de experiências, que gerou a recompensa especificada nos dados de entrada. Para treinar o modelo, precisamos minimizar o desvio entre dois vetores de valores. Passamos o vetor da ação alvo para a saída do modelo de política local e realizamos a retropropagação sequencial de ambos os modelos.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Worker.getResults(rtg); if(err_count==0) err=rtg.Loss(Actions,LOSS_MSE); else err=(err*err_count + rtg.Loss(Actions,LOSS_MSE))/(err_count+1); if(err_count<1000) err_count++; Result.AssignArray(CAGrad(Actions - rtg) + rtg); if(!Worker.backProp(Result,NULL,NULL) || !Agent.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
É importante notar que, neste caso, estamos usando um modelo de política local já treinado. E durante a retropropagação, atualizamos os parâmetros apenas do Planejador. Para isso, precisamos definir a flag de treinamento do modelo de política local como false (Worker.TrainMode(false)). Na implementação apresentada, fiz isso no método de inicialização do EA, para não repetir a operação em cada iteração.
Em seguida, apenas precisamos informar o usuário sobre o treinamento e passar para a próxima iteração do ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), err); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão de todas as iterações do sistema de ciclos, repetimos as operações de finalização do trabalho do EA, que já foram descritas duas vezes acima.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", err); ExpertRemove(); //--- }
Com isso, concluímos a revisão dos algoritmos de treinamento de modelos. Note-se que neste artigo criamos 3 EAs de treinamento de modelos em vez de um, como usado anteriormente. Esta abordagem nos permite paralelizar o treinamento dos modelos. Como se pode notar, o EA de treinamento de habilidades não requer uma amostra de treinamento. E podemos treinar habilidades paralelamente aa coleta da amostra de treinamento. No treinamento do Planejador e da Função de Custo, usamos o buffer de reprodução de experiências. No entanto, esses processos não se sobrepõem e podem ser executados em paralelo, até mesmo em máquinas diferentes.
2.5. EA de teste de modelos
Após o treinamento dos modelos, precisaremos avaliar os resultados obtidos no trading prático. Claro, testaremos o modelo no testador de estratégias. Mas precisamos de um EA que combine todos os modelos considerados anteriormente em um único complexo de tomada de decisão. Essa funcionalidade será implementada no EA "...\CT\Test.mq5". Não vamos analisar todos os métodos do EA. Eu sugiro que nos concentremos apenas na função OnTick, onde o algoritmo principal de tomada de decisão é realizado.
No início do método, verificamos a ocorrência do evento de abertura da nova barra. Como você se lembra, todas as operações de trading são realizadas na abertura de uma nova barra. Enquanto isso, analisamos apenas as velas fechadas.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Nesse momento, se necessário, carregamos os dados históricos do servidor.
Em seguida, precisamos preencher o buffer de dados de entrada para nossos modelos com dados históricos. É importante observar que o modelo da função de custo e o planejador usam dados de diferentes estruturas e profundidades históricas. Primeiro, preenchemos o buffer com dados para a função de custo e realizamos sua propagação.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars-1; b >=0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!Value.feedForward(GetPointer(bState), 1, false)) return;
Então, preenchemos o buffer com dados para o planejador. Note que a sequência de dados deve replicar completamente a sequência de sua alimentação durante o treinamento do modelo. Primeiro, transferimos dados históricos sobre movimento de preços e indicadores.
for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Complementamos com informações sobre o estado da conta.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Em seguida, vem o rótulo de tempo e a última ação do Agente.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
Ao final do buffer, adicionamos o RTG. Este valor é retirado do buffer de resultados da função de custo.
//--- Return to go
Value.getResults(Result);
bState.AddArray(Result);
Após concluir a preparação dos dados, realizamos a propagação do Planejador e do modelo de política local consecutivamente. Durante isso, certamente controlamos a execução das operações.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent), -1, (CBufferFloat *)NULL)) return;
As ações do Agente previstas dessa forma são processadas e executadas no ambiente.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Worker.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Os resultados da interação com o ambiente são salvos no buffer de reprodução de experiências para o ajuste fino adicional do modelo.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Deve-se notar que os dados coletados dessa maneira podem ser usados tanto para o ajuste fino do modelo quanto para o treinamento adicional do modelo durante a operação. Isso nos permite adaptá-lo continuamente às condições mutáveis do ambiente.
3. Teste
Realizamos um trabalho considerável na criação de EAs para coleta de dados e treinamento de modelos. Como já mencionado, dividimos todo o processo em EAs separados para possibilitar a execução de várias tarefas em paralelo. O primeiro passo é lançar o EA de treinamento de habilidades "StudyWorker.mq5", que opera de forma autônoma e não requer uma amostra de treinamento. Enquanto isso, lidamos com a coleta da amostra de treinamento.
Devo dizer que a coleta de uma amostra de treinamento no período histórico dos primeiros 7 meses de 2023 foi bastante trabalhoso. Encontrei o problema de que, mesmo com um pequeno horizonte de amostragem de ações do Agente, a maioria dos passes não atendia aos requisitos de um saldo positivo.
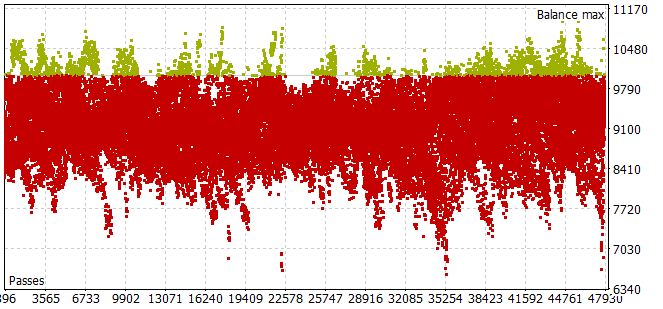
Para escolher o horizonte de planejamento ótimo no modo de otimização do número de iterações por passagem, foi levado a parâmetros otimizáveis.
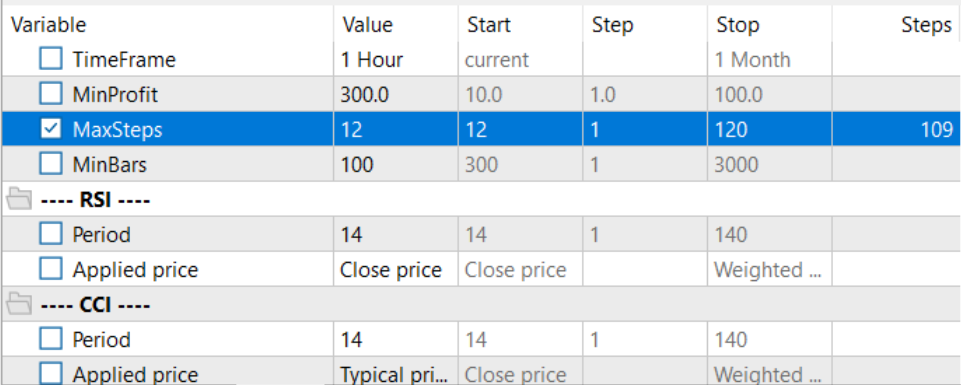
Após a coleta da amostra de treinamento e o treinamento do modelo de política local, iniciei simultaneamente o treinamento do planejador e do modelo de função de custo. Essa abordagem permitiu-me reduzir significativamente o tempo de treinamento dos modelos.
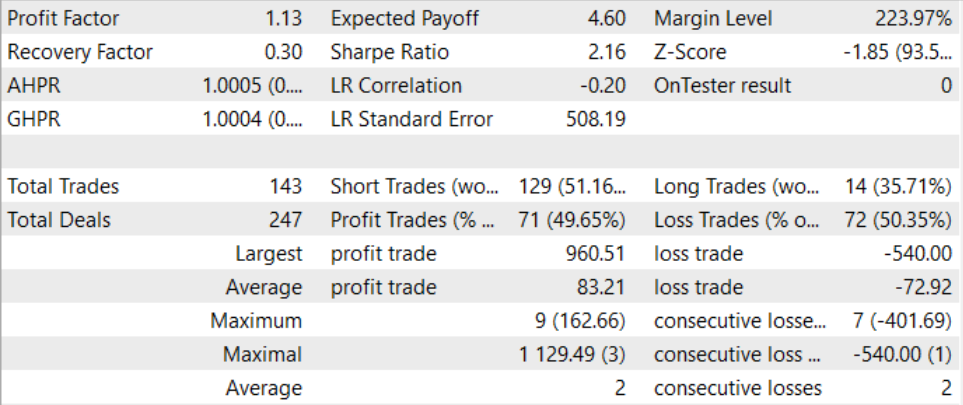
Após um longo e bastante complexo treinamento, conseguimos desenvolver um modelo capaz de gerar lucro além da amostra de treinamento. O modelo treinado foi testado com dados históricos de agosto de 2023. E os resultados do teste deram um fator de lucro de 1.13. Devo dizer que a relação entre posições lucrativas e não lucrativas é próxima de 1:1. E todo o lucro foi alcançado graças ao excedente da média de transações lucrativas sobre a média de perdas.
Considerações finais
Neste artigo, exploramos o método Control Transformer, que apresenta uma arquitetura inovadora para treinamento de estratégias de controle em ambientes complexos e dinamicamente variáveis. Ele combina métodos modernos de aprendizado por reforço, planejamento e aprendizado de máquina, criando estratégias de controle flexíveis e adaptativas.
O Control Transformer abre novas perspectivas para o desenvolvimento de vários sistemas autônomos e robôs. Sua capacidade de se adaptar a ambientes variados, considerar condições dinâmicas e aprender offline o torna uma ferramenta poderosa para criar sistemas inteligentes e autônomos capazes de resolver tarefas complexas de controle e navegação.
Na parte prática do artigo, implementamos nossa visão do método apresentado usando MQL5. Nesta implementação, usamos uma nova abordagem de dividir o treinamento de modelos em EAs separados, o que permite realizar várias tarefas simultaneamente. E isso permite reduzir significativamente o tempo total de treinamento dos modelos.
Durante o treinamento e teste dos modelos, conseguimos criar um modelo capaz de gerar lucro. Isso nos permite falar sobre a eficácia da abordagem considerada e a possibilidade de sua utilização para construir soluções de trading.
E lembro novamente que todos os programas apresentados no artigo são informativos e destinados a demonstrar o algoritmo apresentado. Eles não estão prontos para uso em condições de mercado real.
Referências
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | EA para coleta de exemplos |
| 2 | Study.mq5 | EA | EA para treinamento do Planejador |
| 3 | StudyWorker.mq5 | EA | EA para treinamento do modelo de política local |
| 4 | StudyValue.mq5 | EA | EA para treinamento da função de custo |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de Classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de Classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13674
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso