
Redes neurais de maneira fácil (Parte 61): O problema do otimismo no aprendizado por reforço off-line

Introdução
Recentemente, os métodos de aprendizado por reforço off-line têm encontrado uma ampla acolhida, prometendo muitas perspectivas na resolução de tarefas de complexidade variável. Porém, um dos principais desafios enfrentados pelos pesquisadores é o otimismo que pode surgir durante o treinamento. O Agente otimiza sua estratégia se baseando nos dados da amostra de treinamento e adquire confiança em suas ações. Mas a amostra de treinamento muitas vezes não é capaz de cobrir todos os possíveis estados e transições do ambiente. Dada a estocasticidade do ambiente, tal confiança prova ser nem sempre fundamentada. Em tais casos, uma estratégia otimista do agente pode ocasionar aumento dos riscos e consequências indesejadas.
Quanto à solução para esse problema, seria bom prestar atenção ao aprendizado off-line. Obviamente, os algoritmos dessa área de pesquisa visam reduzir os riscos (aumentar a segurança dos usuários) e minimizar o aprendizado on-line. Um desses métodos é o SeParated Latent Trajectory Transformer (SPLT-Transformer), apresentado no artigo "Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning" (Julho de 2022).
1. Método SPLT-Transformer
O modelo SPLT-Transformer, semelhante ao Decision Transformer, faz parte dos modelos de geração de sequências que usam a arquitetura do Transformer. No entanto, diferentemente do DT mencionado, utiliza dois fluxos de informação separados para modelar a política do Ator e o modelo do ambiente.
Os autores do método tentam resolver duas questões fundamentais:
- Os modelos devem ajudar a criar uma variedade de candidatos para o comportamento do Agente em qualquer situação;
- Os modelos devem cobrir a maioria dos diferentes modos de possíveis transições para um novo estado do ambiente.
Para alcançar esse objetivo, para a política do Ator e o modelo do ambiente são treinados dois VAEs separados baseados em transformadores. Os autores do método geram variáveis latentes estocásticas para ambos os fluxos e as usam em todo o horizonte de planejamento. Isso permite a iteração de todas as possíveis trajetórias-candidatas sem um aumento exponencial na ramificação. E garante uma busca eficiente de variantes de comportamento durante o teste.
A ideia é que as variáveis latentes da política correspondam a diferentes intenções de alto nível, semelhantes às habilidades dos algoritmos hierárquicos. Ao mesmo tempo, as variáveis latentes do modelo do ambiente devem corresponder a diferentes tendências possíveis e a mudança mais provável em seu estado.
Nos codificadores de política e ambiente, é aplicada a mesma arquitetura usando transformadores. Eles recebem os mesmos dados de entrada na forma de uma trajetória anterior. No entanto, diferentemente dos algoritmos discutidos anteriormente, a trajetória inclui apenas um conjunto de estados e ações do Ator. Na saída dos codificadores, obtemos variáveis latentes discretas com um número limitado de valores em cada dimensão.
Os autores do método propõem usar o valor médio das saídas do transformador para todos os elementos, a fim de combinar toda a trajetória em uma única representação vetorial.
Em seguida, cada uma dessas saídas é processada por um pequeno perceptron multicamadas, que produz distribuições categóricas independentes da representação latente.
O decodificador da política recebe a mesma trajetória de entrada, complementada com a representação latente correspondente. O objetivo do decodificador da política é avaliar as probabilidades e prever a ação mais provável a seguir na trajetória. Os autores apresentam o decodificador que usam o modelo do transformador.
Conforme mencionado acima, excluímos a recompensa da sequência, mas adicionamos uma representação latente. No entanto, a representação latente não substitui a recompensa como um elemento da sequência em cada etapa. Os autores do método introduzem uma representação latente que é transformada em um único vetor de inserção, semelhante à codificação posicional, aplicada em alguns outros trabalhos que usam a arquitetura do transformador.
O decodificador do modelo do ambiente tem uma arquitetura semelhante ao decodificador da política. A única diferença é que na saída, o decodificador do modelo do ambiente tem "3 cabeças" para prever o estado subsequente mais provável e seu custo, bem como a recompensa pela transição.
O treinamento dos modelos, assim como no DT, é realizado com dados da amostra de treinamento usando métodos de aprendizado supervisionado. Os modelos são treinados para associar trajetórias com ações subsequentes (Ator), transições para novos estados e seus custos (modelo do ambiente).
Durante o teste e utilização prática, a escolha da ação ótima é feita com base na avaliação das trajetórias-candidatas previstas no horizonte de planejamento definido. Para compor uma única trajetória candidata planejada, é realizada a geração sequencial de ações e estados com recompensas ao longo do horizonte de planejamento. Em seguida, é escolhida a trajetória ótima, e é executada sua primeira ação. Após a transição para um novo estado do ambiente, todo o algoritmo é repetido.
Como pode ser observado, o algoritmo prevê o planejamento de várias trajetórias-candidatas, mas é realizada apenas uma ação da trajetória ótima. Embora tal abordagem possa parecer ineficiente, ela permite minimizar os riscos por meio do planejamento de vários passos à frente. E, ao mesmo tempo, existe a possibilidade de corrigir a trajetória oportunamente, por causa da reavaliação de cada estado visitado.
Abaixo podemos ver uma representação do método criada pelo próprio autor.
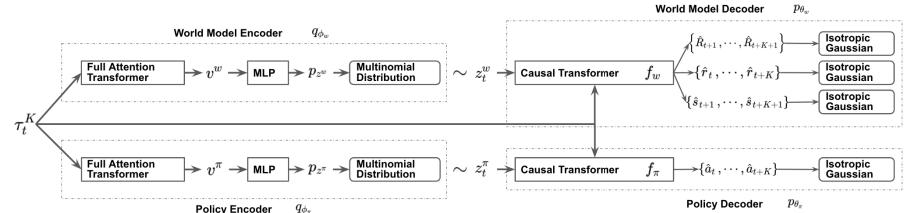
2. Implementação usando MQL5
Após considerar os aspectos teóricos do método SPLT-Transformer, passamos para a implementação das abordagens propostas com MQL5. Gostaria de dizer desde já que nossa implementação estará mais distante do algoritmo do autor do que nunca. E a razão está na minha percepção subjetiva. Toda a experiência desta série de artigos demonstra a dificuldade de criar um modelo de ambiente para os mercados financeiros. Todas as nossas tentativas resultaram em resultados bastante modestos. A precisão das previsões é bastante baixa em uma ou duas etapas. E, com o aumento do horizonte de planejamento, tende a 0. Por isso, decidi não construir trajetórias-candidatas, limitando-me apenas à geração de algumas variantes de ações-candidatas do estado atual.
No entanto, tal abordagem implica uma desconexão entre a ação e sua avaliação. Como pode ser observado na visualização apresentada acima, a política do Ator e o modelo do ambiente recebem os mesmos dados de entrada. Mas as informações adicionais vêm em fluxos paralelos. Consequentemente, ao prever o próximo estado e a recompensa esperada, o modelo do ambiente não sabe nada sobre a ação que o Agente escolherá. Aqui só se pode falar de uma certa suposição com um determinado grau de probabilidade baseada na experiência anterior da amostra de treinamento. E é importante notar que a amostra de treinamento foi criada com base em políticas de Ator diferentes daquela utilizada no momento atual.
Na versão autoral, isso é compensado pela adição da ação do Agente e do estado previsto na trajetória na próxima etapa. No entanto, em nosso caso, considerando a experiência de baixa qualidade no planejamento do próximo estado do ambiente, corremos o risco de adicionar à trajetória estados e ações completamente descoordenados. Isso reduz enormemente o volume de planejamento das próximas etapas na trajetória prevista. Na minha opinião, coloco em dúvida tanto a eficácia desse planejamento como a avaliação dessas trajetórias. Por isso, não gastaremos recursos na previsão de trajetórias-candidatas.
Além disso, precisamos de um mecanismo capaz de correlacionar as ações do Agente com a recompensa esperada. Por um lado, podemos usar o modelo do Crítico, mas isso basicamente quebra o algoritmo e exclui completamente o modelo do ambiente. A menos que, é claro, não o usemos como o Crítico.
No entanto, decidi experimentar com outra abordagem, mais próxima do algoritmo original. Para começar, decidi usar um codificador para ambos os fluxos. Aqui, dois decodificadores são alimentados com o estado latente recuperado que, por sua vez, é adicionado à trajetória. O Ator, com base nos dados de entrada, gera uma ação prevista, enquanto o modelo do ambiente retorna a soma da recompensa futura descontada.
A ideia é que, com mesmos dados de entrada, os modelos retornam resultados consistentes. Para isso, excluímos a estocasticidade tanto no modelo do Ator quanto no modelo do ambiente. E, ao fazer isso, geramos estocasticidade na representação latente, o que nos permite criar várias ações-candidatas e avaliações relacionadas do estado previsto. Com base nessas avaliações, classificaremos as ações-candidatas para escolher a etapa ótima ponderada.
Para otimizar o número de operações realizadas, deve-se prestar atenção a algo mais. Ao alimentar a entrada do Codificador com a mesma trajetória, replicaremos com precisão matemática os resultados de todas as suas camadas internas. As diferenças são formadas apenas na camada do autocodificador variacional quando a amostragem é feita a partir de uma determinada distribuição. Em consequência, para formar ações candidatas, é sensato mover a camada mencionada para fora do Codificador. Isso nos permitirá realizar apenas uma propagação do Codificador a cada iteração. Após uma breve reflexão, movi a camada do autocodificador variacional para o modelo do ambiente.
Fui mais longe na otimização do fluxo de operações. Todos os nossos três modelos utilizam uma única trajetória como dados de entrada. Como você sabe, os elementos da trajetória são heterogêneos. E, antes do processamento, passam por uma camada de Incorporação. Isso me deu a ideia de incorporar dados apenas em um modelo, usando os dados obtidos nos dois restantes. Dessa forma, mantive a camada de incorporação apenas no Codificador.
E mais uma coisa. O modelo do ambiente e o Ator usam como dados de entrada o vetor concatenado da trajetória e da representação latente. Já definimos que a camada do autocodificador variacional, para a formação da representação latente estocástica, foi transferida para o modelo do ambiente. Aqui também realizaremos a união dos vetores. E então, passaremos o resultado obtido como entrada para o Ator.
Agora, colocaremos as ideias expostas no código. Para isso, criaremos a descrição de nossos modelos, que, como sempre, é feita no método CreateDescriptions. Nos parâmetros, o método recebe ponteiros para 3 objetos de descrição de nossos modelos.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *latent, CArrayObj *world) { //--- CLayerDescription *descr;
A descrição da arquitetura, provavelmente, deve começar com o modelo do codificador que é alimentado com os dados não processados da sequência.
//--- latent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Os dados obtidos passam por uma camada de normalização em lote para torná-los comparáveis.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
E passamos os dados já normalizados pela camada de incorporação. Lembre-se desta camada. Será a partir dela que extrairemos os dados para o modelo do ambiente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!latent.Add(descr)) { delete descr; return false; }
Em seguida, passamos a trajetória obtida através de um bloco transformador. Eu usei um bloco de atenção esparsa com 8 cabeças de Self-Attention e 4 camadas no bloco.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = prev_wout; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Após o bloco de atenção, reduziremos um pouco a dimensionalidade com uma camada convolucional e passaremos os dados por um bloco de tomada de decisão de camadas totalmente conectadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Na saída do modelo do Codificador, usamos uma camada neural totalmente conectada sem função de ativação e com um tamanho duas vezes maior que o tamanho da incorporação de um elemento da trajetória. Isso representa as médias e variâncias para a distribuição da representação latente. Isso nos permitirá amostrar a representação latente da distribuição especificada na próxima etapa.
Em seguida, passamos à descrição do modelo do ambiente. Sua camada de dados de entrada é igual à camada de resultados do modelo do Codificador. E depois vem a camada do autocodificador variacional, o que nos permite amostrar imediatamente a representação latente.
//--- World if(!world) { world = new CArrayObj(); if(!world) return false; } //--- world.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; prev_count = descr.count = prev_count / 2; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Em seguida, temos que adicionar o tensor de incorporações da trajetória. Para isso, usaremos a camada de concatenação. A saída desta camada nos fornece os dados de entrada processados para o nosso modelo do ambiente e para o Ator.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.step = 4 * EmbeddingSize * HistoryBars; prev_count = descr.count = descr.step + prev_count; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Passamos os dados através de um bloco Self-Attention esparso. Assim como no codificador, usamos 8 cabeças e 4 camadas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Reduzimos a dimensionalidade dos dados com uma camada convolucional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; }
E processamos os dados obtidos com um perceptron totalmente conectado vindo do bloco de tomada de decisão.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Na saída do modelo, obtemos o vetor de recompensa decomposta.
E na conclusão deste bloco, examinaremos a estrutura do modelo do nosso Ator. Como já mencionado anteriormente, os dados de entrada do modelo são obtidos a partir do estado oculto do modelo do ambiente. Consequentemente, a camada de dados de entrada deve ter o tamanho adequado.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = EmbeddingSize * (4 * HistoryBars + 1); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Os dados obtidos são o resultado do trabalho do modelo e não requerem processamento adicional. Assim sendo, usamos imediatamente o bloco de atenção esparsa. Os parâmetros do bloco são semelhantes aos usados nos modelos discutidos acima. Dessa forma, todos os 3 modelos utilizam a mesma arquitetura de transformador.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Da mesma forma que com o modelo do ambiente, reduzimos a dimensionalidade e processamos os dados em um perceptron totalmente conectado de tomada de decisões.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Na saída do modelo, é formado o vetor de ações do Agente.
É importante notar que para a implementação deste método, será necessário adicionar ao buffer de reprodução de experiência uma entidade adicional na forma da distribuição da representação latente, que é formada na saída do Codificador. Para isso, criaremos um array adicional na estrutura de descrição do estado do ambiente.
struct SState { ....... ....... float latent[2 * EmbeddingSize]; ....... ....... }
O tamanho do novo array é igual a 2 incorporações, pois inclui as médias e variâncias da distribuição.
Além de declarar o array, precisamos adicionar sua manutenção em todos os métodos da estrutura:
- Inicialização com valores iniciais
SState::SState(void) { ....... ....... ArrayInitialize(latent, 0); }
- Limpeza da estrutura
void Clear(void) { ....... ....... ArrayInitialize(latent, 0); }
- Cópia da estrutura
void operator=(const SState &obj) { ....... ....... ArrayCopy(latent, obj.latent); }
- Salvamento da estrutura
bool SState::Save(int file_handle) { ....... ....... //--- total = ArraySize(latent); if(FileWriteInteger(file_handle, total) < sizeof(int)) return false; for(int i = 0; i < total; i++) if(FileWriteFloat(file_handle, latent[i]) < sizeof(float)) return false; //--- return true; }
- Carregamento da estrutura a partir de um arquivo
bool SState::Load(int file_handle) { ....... ....... //--- total = FileReadInteger(file_handle); if(total != ArraySize(latent)) return false; //--- for(int i = 0; i < total; i++) { if(FileIsEnding(file_handle)) return false; latent[i] = FileReadFloat(file_handle); } //--- return true; }
Aprendemos a arquitetura dos modelos treinados e atualizamos a estrutura de dados. O próximo passo será coletar dados para o treinamento deles. Esta funcionalidade é implementada no Expert Advisor ".../SPLT/Research.mq5". E imediatamente devemos notar que o método SPLT-Transformer prevê a geração de trajetórias-candidatas (na nossa implementação, ações-candidatas). O número desses candidatos é um dos hiperparâmetros do modelo, que consideramos como os parâmetros externos do EA.
input int Agents = 5;
Mas lembro que anteriormente usávamos o parâmetro externo "Agents" como auxiliar para indicar o número de agentes paralelos explorando o ambiente no modo de otimização do testador de estratégias. Agora, renomearemos o parâmetro de serviço do EA.
input int OptimizationAgents = 1;
A seguir, não detalharemos todos os métodos do EA para coleta de amostras de treinamento. Seu algoritmo já foi descrito muitas vezes no contexto desta série de artigos. E você pode ver o código completo de todos os programas usados neste artigo no anexo. Vamos considerar apenas o método de interação direta com o ambiente OnTick, no qual as características-chave do algoritmo implementado são feitas.
No início do método, como de costume, verificamos a ocorrência do evento de abertura de uma nova barra e, se necessário, atualizamos os dados históricos do movimento de preços e os valores dos indicadores analisados.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Depois disso, formamos um buffer de dados de entrada para os modelos. Primeiro, inserimos os dados históricos do movimento de preços e os valores dos indicadores analisados.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates(); //--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Em seguida, adicionamos o estado atual da conta e informações sobre posições abertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Depois realizamos a identificação temporal dos dados, adicionando um rótulo de tempo ao nosso buffer de dados.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
E indicaremos as últimas ações do Agente, que nos trouxeram para este estado do ambiente.
//--- Prev action
bState.AddArray(AgentResult);
Os dados coletados sobre a etapa atual são suficientes para a geração de uma representação latente e chamamos o método de propagação do Codificador. Neste processo, controlamos obrigatoriamente a execução de operações. E, se necessário, informamos o usuário.
//--- Latent representation ResetLastError(); if(!Latent.feedForward(GetPointer(bState), 1, false)) { PrintFormat("Error of Latent model feed forward: %d",GetLastError()); return; }
Após a criação bem-sucedida da representação latente, passamos para nossos decodificadores.
Lembro que nesta etapa nos propomos a gerar ações-candidatas. Vamos criá-las em um laço, cujo número de iterações é igual ao número de candidatos necessários e é especificado nos parâmetros externos do Expert Advisor.
Para registrar informações sobre as ações-candidatas geradas, criaremos as matrizes actions e values. Na primeira, registraremos os vetores de ações e na segunda, as recompensas esperadas como resultado da aplicação da política.
Como já mencionado anteriormente, no modelo do Codificador, apenas formamos dados sobre a distribuição da representação latente. A amostragem do vetor da representação latente é realizada no modelo do ambiente. Assim, no corpo do laço, primeiro executamos a propagação do modelo do ambiente. E então chamamos o método de propagação do Agente, que usa os estados ocultos do modelo do ambiente como dados de entrada.
Os resultados das propagações dos modelos são salvos nas matrizes previamente preparadas.
matrix<float> actions = matrix<float>::Zeros(Agents, NActions); matrix<float> values = matrix<float>::Zeros(Agents, NRewards); for(ulong i = 0; i < (ulong)Agents; i++) { if(!World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer) || !Agent.feedForward(GetPointer(World), 2,(CBufferFloat *)NULL)) return; vector<float> result; Agent.getResults(result); actions.Row(result, i); World.getResults(result); values.Row(result, i); }
A utilização de políticas estocásticas se baseia na suposição de igual probabilidade de ocorrência de um dos eventos dentro da distribuição aprendida. Daí que cada ação-candidata amostrada tenha igual probabilidade de receber a recompensa esperada no ambiente. Nosso objetivo é maximizar a lucratividade. Isso significa que, em condições de igual probabilidade, escolhemos a ação com a máxima rentabilidade esperada.
Como você entende, nossas matrizes são correlacionadas linha a linha. Buscamos a linha com a máxima recompensa esperada na matriz values e escolhemos a ação da linha correspondente na matriz actions.
vector<float> temp = values.Sum(1); temp = actions.Row(temp.ArgMax());
A ação escolhida é realizada no ambiente.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
E os resultados da interação com o ambiente são coletados na estrutura previamente preparada e salvos no buffer de reprodução de experiência.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; Latent.getResults(sState.latent); if(!Base.Add(sState)) ExpertRemove(); }
Com isso, concluímos nossa introdução ao EA de interação com o ambiente e coleta de dados para a amostra de treinamento. E você pode ver seu código completo no anexo. O código completo de todos os programas usados no artigo também pode ser encontrado lá. E agora, passamos para o trabalho sobre o EA de treinamento off-line de modelos "...\SPLT\Study.mq5".
No método de inicialização do EA, primeiro carregamos a amostra de treinamento. E sempre controlamos a execução das operações. Para o treinamento off-line dos modelos, esta é a única fonte de dados e sua falta torna impossível todo o restante processo.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Em seguida, tentamos carregar modelos previamente treinados. E, se necessário, criamos novos.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !World.Load(FileName + "Wld.nnw", temp, temp, temp, dtStudied, true) || !Latent.Load(FileName + "Lat.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *latent = new CArrayObj(); CArrayObj *world = new CArrayObj(); if(!CreateDescriptions(agent, latent, world)) { delete agent; delete latent; delete world; return INIT_FAILED; } if(!Agent.Create(agent) || !World.Create(world) || !Latent.Create(latent)) { delete agent; delete latent; delete world; return INIT_FAILED; } delete agent; delete latent; delete world; //--- }
Como você deve ter notado no algoritmo do EA de coleta da amostra de treinamento, é frequentemente utilizada a transferência de dados entre os modelos treinados. Durante o treinamento, o volume de dados transferidos aumenta, pois o fluxo de dados ocorre em duas direções: propagação e retropropagação. Com o objetivo de eliminar operações de cópia de dados desnecessárias entre o contexto do OpenCL e a memória principal, transferiremos todos os modelos para um único contexto do OpenCL.
COpenCL *opcl = Agent.GetOpenCL(); Latent.SetOpenCL(opcl); World.SetOpenCL(opcl);
Em seguida, verificamos que a arquitetura dos modelos treinados é consistente.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Agent does not match the actions count (%d <> %d)", 6, Result.Total()); return INIT_FAILED; } //--- Latent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Latent model doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Latent.Clear();
Após a passagem bem-sucedida por todos os controles, geramos o evento de início do treinamento dos modelos e concluímos o trabalho do método de inicialização do EA.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
O próprio treinamento dos modelos é realizado no método Train. No corpo do método, determinamos o número de trajetórias no buffer de reprodução de experiência e registramos em uma variável local o tempo de início do treinamento. Ele nos servirá de referência para informar periodicamente o usuário sobre o progresso do treinamento dos modelos.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Lembro que nossos modelos usam a arquitetura GPT, que é sensível à sequência dos dados de entrada. Como em casos semelhantes anteriores, para treinar os modelos, usaremos um sistema de laços aninhados. No laço externo, amostramos uma trajetória do buffer de reprodução de experiência e o estado inicial do ambiente.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Em seguida, inicializamos os buffers dos modelos e criamos um laço aninhado, no qual alimentamos sequencialmente o modelo com um fragmento individual dos dados históricos.
Actions = vector<float>::Zeros(NActions); Latent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) {
No corpo do laço aninhado, as operações podem, em parte, lembrar a coleta de dados de treinamento. Nós também preenchemos o buffer de dados de entrada. Mas agora, os dados não são solicitados do ambiente, mas extraídos do buffer de reprodução de experiência. Ao mesmo tempo, mantemos estritamente a sequência de registro dos dados. Primeiro, no buffer de dados de entrada, inserimos informações sobre o movimento de preços e os valores dos indicadores analisados.
//--- History data
State.AssignArray(Buffer[tr].States[state].state);
Depois, vêm os dados sobre o estado da conta e posições abertas.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Que são identificados por um rótulo de tempo.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
E, claro, indicamos as ações do Agente, que nos levaram a este estado.
//--- Prev action
State.AddArray(Actions);
Quero enfatizar novamente a importância de manter estritamente a sequência. Na realidade, os dados no buffer não têm um nome. O modelo avalia os dados de acordo com sua posição no buffer. Uma mudança na sequência é percebida pelo modelo como um estado completamente diferente. O resultado da tomada de decisão será completamente diferente e imprevisível. Por isso, para não confundir o modelo e sempre obter decisões adequadas, precisamos seguir estritamente a sequência de dados em todas as fases de treinamento e utilização do modelo.
Após a coleta do buffer dos dados de entrada, nós primeiramente executamos a propagação do Codificador e da modelo do ambiente.
//--- Latent and Wordl if(!Latent.feedForward(GetPointer(State)) || !World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Note que, durante o treinamento, não geramos ações-candidatas. Além disso, o treinamento do modelo do ambiente e da política do Ator é realizado separadamente. Isso tem a ver com a especificidade do treinamento dos modelos.
A modelo do ambiente é treinada para avaliar a política do Agente com base na trajetória anterior e prever a obtenção de recompensas futuras levando em consideração o estado atual do ambiente e a política utilizada. Simultaneamente, ajustamos a distribuição da representação latente. Para isso, após uma propagação bem-sucedida, realizamos a retropropagação da modelo do ambiente e do codificador, visando minimizar o erro nas previsões da modelo do ambiente e a recompensa real obtida do buffer de reprodução de experiência.
Actions.Assign(Buffer[tr].States[state].rewards); vector<float> result; World.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!World.backProp(Result,GetPointer(Latent),LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL,LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Note que, após a retropropagação da modelo do ambiente, primeiramente realizamos uma retropropagação parcial do Codificador para otimizar os parâmetros de incorporação de acordo com os requisitos da modelo do ambiente. E então realizamos a retropropagação completa do Codificador, durante a qual a distribuição da representação latente é otimizada.
Otimizamos a política do Ator para alinhar o estado latente e a ação executada. Por isso, extraímos do buffer de reprodução de experiência a distribuição da representação latente e alimentamos com ela o modelo do ambiente para reamostrar a representação latente. E realizamos a propagação dos modelos do ambiente e do Ator.
//--- Policy Feed Forward Result.AssignArray(Buffer[tr].States[state+1].latent); Latent.GetLayerOutput(LatentLayer,Result2); if(Result2.GetIndex()>=0) Result2.BufferWrite(); if(!World.feedForward(Result, 1, false, Result2) || !Agent.feedForward(GetPointer(World),2,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Após isso, realizamos a retropropagação do Ator para minimizar o erro entre a ação prevista e a efetivamente realizada a partir do buffer de reprodução de experiência.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result,NULL,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Assim, treinamos a política do Ator tornando-a mais previsível. Simultaneamente, treinamos o modelo do ambiente para avaliar trajetórias anteriores para entender a possibilidade de geração de lucro. Treinamos o Codificador para filtrar as trajetórias de entrada e extrair informações essenciais sobre as tendências do ambiente e a política atual do Ator.
Tudo isso juntos permite criar políticas de Ator bastante interessantes, considerando a estocasticidade do ambiente e as probabilidades de geração de lucro.
Após a atualização dos modelos bem-sucedida, informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do nosso sistema de laços aninhados.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "World", iter * 100.0 / (double)(Iterations), World.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Ao final de todas as iterações do sistema de ciclos, limpamos o campo de comentários. Os resultados do treinamento dos modelos são exibidos no log. E iniciamos a conclusão do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "World", World.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a revisão do EA de treinamento de modelos na nossa interpretação do método SPLT-Transformer. O código completo do EA, assim como todos os programas utilizados no artigo, pode ser consultado no anexo. Lá também está o código do EA de teste dos modelos "...\SPLT\Test.mq5". Não vamos nos deter na análise de seus métodos neste artigo. A estrutura do EA repete a dos EAs semelhantes vistos em artigos anteriores. E as características da implementação do algoritmo apresentado na função OnTick reproduzem completamente a implementação de um método similar no EA de coleta de dados para a amostra de treinamento. Sugiro que você se familiarize com este EA nos arquivos anexos por conta própria.
Avançamos para a próxima etapa, o teste dos modelos usando dados históricos no testador de estratégias do MetaTrader 5.
3. Teste
O treinamento dos modelos, como antes, foi realizado em dados históricos dos primeiros 7 meses do instrumento EURUSD com timeframe H1. Os parâmetros de todos os indicadores são usados conforme configurados por padrão, sem otimização adicional.
Inicialmente, rodamos o EA de coleta de amostra de treinamento no modo de otimização lenta do testador de estratégias. Isso nos permite coletar dados simultaneamente com vários agentes de teste. Dessa forma, aumentamos o número de trajetórias no buffer de reprodução de experiência enquanto minimizamos o tempo gasto na coleta de dados.
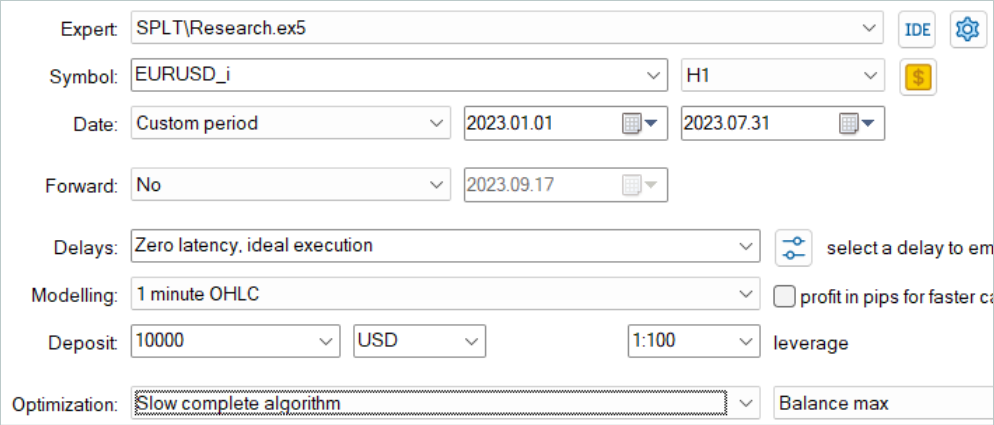
O algoritmo considerado supõe treinamento dos modelos apenas off-line. Por esse motivo, para testar seu desempenho, sugiro maximizar o buffer de reprodução de experiência e preenchê-lo com trajetórias diversas. Mas vale ressaltar que a geração de ações-candidatas é um processo bastante custoso. E com o aumento do número de candidatos, também aumentam os custos de coleta de dados.
Após a coleta de dados, treinei os modelos sem a coleta adicional de trajetórias, como era feito anteriormente. O treinamento do modelo, como sempre, é um processo longo. Como não planejei a coleta adicional de trajetórias, aumentei seu número e deixei que o computador treinasse durante um longo tempo.
Em seguida, o modelo treinado foi testado em dados históricos de agosto de 2023, que não foram incluídos no conjunto de treinamento.
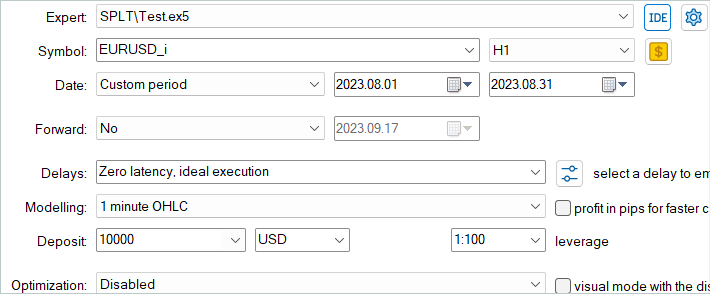
Devo dizer que, com base nos resultados dos testes, o modelo mostrou um pequeno lucro e uma negociação bastante precisa. Lembro que o método SPLT-Transformer foi desenvolvido para funcionar off-line e visa a máxima redução de riscos.
No gráfico do teste, vemos uma tendência de aumento do saldo quase durante todo o mês. Observamos uma série de operações negativas apenas na última semana do mês. No entanto, o lucro acumulado anteriormente foi suficiente para cobrir as perdas. E, em geral, um pequeno lucro foi registrado ao final do mês.

 🐌
🐌
Durante todo o período de teste, o modelo abriu apenas 16 posições com o volume mínimo. A parcela de operações lucrativas foi de apenas 37,5%. No entanto, a operação lucrativa média excede o prejuízo médio em quase 70%. Como consequência, o teste registrou um fator de lucro de 1,02.
Considerações finais
Neste artigo, apresentamos o SPLT-Transformer, que é um método inovador desenvolvido para resolver problemas no aprendizado por reforço off-line, associados ao comportamento otimista do Agente. Com a ajuda de dois modelos separados, representando a política e o modelo do ambiente, é alcançada a construção de políticas de Agente confiáveis e eficazes.
Os componentes principais do SPLT-Transformer, incluindo o algoritmo de geração de trajetórias-candidatas, permitem modelar diversos cenários e tomar decisões considerando um grande número de possíveis resultados futuros. Isso torna o método apresentado altamente adaptável e seguro em diferentes ambientes estocásticos. Os autores do método forneceram resultados experimentais off-line, confirmando o desempenho superior do SPLT-Transformer em comparação com métodos existentes.
Na parte prática do artigo, criamos nossa própria interpretação, um pouco simplificada, do método discutido. Treinamos e testamos os modelos obtidos. Os resultados dos testes demonstraram que o modelo é capaz de exibir comportamento tanto cauteloso quanto otimista, dependendo da situação. Isso o torna uma escolha ideal em momentos críticos.
No geral, o método merece ser mais explorado. Um treinamento mais rigoroso dos modelos, na minha opinião, pode dar melhores resultados.
E, novamente, lembro que todos os programas apresentados nesta série de artigos foram criados apenas para demonstração e teste dos algoritmos discutidos. E não são adequados para trading em contas reais. Antes de usar qualquer modelo em negociações reais, é recomendado realizar um treinamento cuidadoso seguido de testes abrangentes.
Referências
- Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
- Redes neurais de maneira fácil (Parte 58): transformador de decisões (Decision Transformer—DT)
- Redes neurais de maneira fácil (Parte 59): dicotomia do controle (DoC)
- Redes neurais de maneira fácil (Parte 60): transformador de decisões on-line (ODT)
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA de treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13639
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Redes neurais - É simples (Parte 61)
Parte 61, você consegue ver o resultado em termos monetários?
Redes neurais - é simples (Parte 61)
61 partes, você consegue ver o resultado em termos monetários?
Devo agradecer imensamente ao autor, que pega um artigo puramente teórico e explica em linguagem popular como é possível:
Dê uma olhada no artigo original e veja por si mesmo o tipo de trabalho que Dmitry fez - https://arxiv.org/abs/2207.10295.