
Redes neurais de maneira fácil (Parte 60): transformador de decisões on-line (ODT)

Introdução
As últimas 2 partes foram dedicadas ao método transformador de decisões (DT), que modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. E paramos no ponto em que, segundo os resultados de testes práticos dos 2 artigos, foi observado um aumento bastante bom no rendimento segundo os resultados do trabalho do modelo treinado no início do período de teste. Depois, o desempenho do trabalho do modelo diminui, e observa-se uma série de operações negativas, que acarretam perdas. O tamanho das perdas pode exceder o lucro anteriormente obtido.
Em uma situação como essa, é bastante provável que o retreinamento periódico do modelo possa ajudar. No entanto, tal abordagem complica significativamente a utilização prática do modelo. E é bastante razoável considerar a opção de treinamento on-line do modelo. Mas aqui nos deparamos com uma série de desafios que precisamos resolver.
Uma das implementações do treinamento on-line do transformador de decisões é apresentada no artigo "Online Decision Transformer" (fevereiro de 2022). Vale ressaltar desde já que o método proposto utiliza o treinamento off-line primário do DT clássico. O treinamento on-line é aplicado durante o ajuste fino subsequente do modelo. Os resultados dos experimentos apresentados no artigo dos autores demonstram que o ODT é capaz de competir com os líderes em desempenho absoluto na amostra de teste D4RL. Além disso, ele mostra uma melhoria muito mais significativa durante o ajuste.
Vamos considerar o método proposto no contexto de resolver nossas tarefas.
1. Algoritmo ODT
Antes de examinar o algoritmo transformador de decisões on-line, proponho relembrar brevemente o transformador de decisões clássico. O DT processa a trajetória τ como uma sequência de vários tokens de entrada: Return-to-Go (RTG), estados e ações. Em particular, o valor inicial de RTG é igual ao retorno para toda a trajetória. No passo de tempo t, o DT usa os tokens K dos últimos etapas de tempo para gerar a ação At. Neste caso, K é um hiperparâmetro que define o comprimento do contexto para o transformador. É importante notar que durante a utilização prática, o comprimento do contexto pode ser mais curto do que durante o treinamento.
O DT é treinado com uma política determinística π(At|St, RTGt), onde St representa a sequência de K últimos estados de t-K+1 a t. Da mesma forma, RTGt representa os K dos últimos Return-to-Go. Este é um modelo autorregressivo de ordem K-. A política do Agente é treinada para prever ações usando a função de perda padrão MSE (erro quadrático médio).
Durante a utilização prática, especificamos o desempenho desejado RTG e o estado inicial S0. O DT então gera a ação A0. Após a geração da ação At, realizamo-la e observamos o próximo estado St+1, recebendo a recompensa rt. Isso nos dá o próximo RTGt+1.
![]()
Como antes, o DT gera a ação A1 com base na trajetória que inclui A0, S0, S1 e RTG0, RTG1. Esse processo se repete até o término do episódio.
As políticas treinadas apenas com conjuntos de dados off-line geralmente são subótimas devido aos dados limitados da amostra de treinamento. As trajetórias off-line podem ter retornos baixos e cobrir apenas uma parte limitada do espaço de estados e ações. Uma estratégia natural para melhorar o desempenho é o retreinamento de Agentes de RL na interação on-line com o ambiente. No entanto, o método transformador de decisões padrão é insuficiente para o treinamento on-line.
O algoritmo transformador de decisões on-line introduz modificações chave no transformador de decisões para permitir um treinamento on-line eficaz. E o primeiro passo é uma meta de aprendizado probabilística generalizada. Neste contexto, o objetivo é treinar uma política estocástica que maximize a probabilidade de replicação da trajetória.
A principal característica de um algoritmo de RL on-line é a capacidade de equilibrar o compromisso entre pesquisa e exploração. Mesmo com políticas estocásticas, a formulação tradicional do DT não considera a pesquisa. Para resolver esse problema, no método ODT, a pesquisa é definida através da entropia da política, que depende da distribuição dos dados na trajetória. Essa distribuição é estática durante o treinamento off-line preliminar, mas se torna dinâmica durante o ajuste on-line, pois depende de novos dados obtidos durante a interação com o ambiente.
De maneira similar a muitos algoritmos de RL existentes com máxima entropia, como o Soft Actor Critic, os autores do método ODT definem explicitamente um limite inferior para a entropia da política para incentivar a pesquisa.
A diferença da função de perda no ODT em comparação com o SAC e outros métodos clássicos de RL reside no fato de que, no ODT, a função de perda é o logaritmo negativo da verossimilhança, e não o retorno descontado. Em princípio, nos concentramos apenas no treinamento seguindo uma sequência de ações exemplares, em vez da maximização explícita do retorno. E a função objetivo se adapta automaticamente para a política do Ator adequada tanto no treinamento off-line quanto no on-line. Durante o treinamento off-line, a entropia cruzada controla o grau de desajuste da distribuição, e durante o treinamento on-line, ela estimula a política de pesquisa.
Outra diferença importante dos métodos clássicos de RL de entropia máxima é que, no ODT, a entropia da política é definida no nível das sequências, e não das transições. Enquanto o SAC estabelece um limite inferior β para a entropia da política em todos os etapas de tempo, o ODT restringe a entropia média em K etapas de tempo consecutivas. Assim, a restrição exige apenas que a entropia, média ao longo de uma sequência de K etapas de tempo, seja superior ao valor estabelecido β. Portanto, qualquer política que satisfaça a restrição em nível de transição também satisfaz a restrição em nível de sequência. Assim, o espaço de políticas admissíveis é maior quando K > 1. Quando K = 1, a restrição no nível da sequência se reduz à restrição no nível da transição, de forma semelhante ao SAC.
Durante o treinamento de modelos, utiliza-se um buffer de reprodução para registrar experiências anteriores com atualizações periódicas. Para a maioria dos algoritmos de RL existentes, o buffer de reprodução de experiências consiste em transições. Após cada etapa de interação on-line dentro de uma única época, a política do Agente e a função Q são atualizadas usando o gradiente descendente. Então, a política é executada para coletar novas transições e adicioná-las ao buffer de reprodução de experiências. No caso do ODT, o buffer de reprodução de experiências consiste em trajetórias, não transições. Após o treinamento off-line preliminar, inicializamos o buffer de reprodução de experiências com trajetórias de resultados máximos do conjunto de dados off-line. Cada vez que interagimos com o ambiente, completamos um episódio inteiro com a política atual. Depois, atualizamos o buffer de reprodução de experiências usando a trajetória coletada, em ordem FIFO. Assim, atualizamos a política do Agente e executamos um novo episódio. Avaliar a política usando a ação média geralmente acarreta recompensas mais altas, mas é útil empregar ações aleatórias para exploração on-line, pois isso gera trajetórias e padrões de comportamento mais diversos.
Adicionalmente, o algoritmo ODT requer um hiperparâmetro na forma de um RTG inicial para coletar dados on-line adicionais. Vários estudos demonstram que o retorno estimado real do DT off-line tem uma forte correlação com o RTG inicial empiricamente e frequentemente pode extrapolar os valores RTG além dos retornos máximos observados no conjunto de dados off-line. Os autores do ODT descobriram que é melhor configurar esse hiperparâmetro com um pequeno escalonamento fixo a partir dos resultados existentes do especialista. Os autores do método utilizam um escalonamento de duas vezes. O artigo original apresenta resultados de experimentos com valores significativamente maiores, bem como com variações durante o treinamento (por exemplo, quantis do melhor retorno estimado nos conjuntos de dados off-line e on-line). Mas, na prática, eles não se mostraram tão eficazes quanto o RTG escalonado fixo.
Assim como o DT, o Algoritmo ODT utiliza um procedimento de amostragem de dois passos para assegurar uma amostragem uniforme das subtrajetórias de comprimento K no buffer de reprodução. Primeiro, amostramos uma trajetória com probabilidade proporcional ao seu comprimento. Em seguida, selecionamos igualmente uma subtrajetória de comprimento K.
Iremos nos familiarizar com a implementação prática do método na próxima seção deste artigo.
2. Implementação usando MQL5
Após nos familiarizarmos com os aspectos teóricos do método, passamos à sua implementação prática. Esta seção apresentará uma visão própria da implementação das abordagens propostas, complementada pelos trabalhos anteriores. Especificamente, o algoritmo ODT inclui um treinamento de modelo em duas fases:
- Treinamento preliminar off-line.
- Ajuste fino do modelo durante a interação on-line com o ambiente.
Neste artigo, usaremos o modelo pré-treinado do artigo anterior. Assim, omitimos a primeira fase do treinamento off-line, que já foi realizada anteriormente. E passamos diretamente para a segunda parte do treinamento do modelo.
Aqui, vale ressaltar que, ao considerar o método DoC no artigo anterior, construímos e realizamos o treinamento off-line de 2 modelos:
- de geração RTG;
- da política do Ator.
O uso do modelo de geração RTG é diferente do algoritmo ODT original, no qual é sugerido o uso de escalonamento da avaliação de especialista para o RTG inicial com subsequente ajuste do objetivo com base nos resultados efetivamente obtidos.
Ademais, o uso de modelos previamente treinados não nos permite alterar a arquitetura dos modelos. Mas vamos ver até que ponto a arquitetura dos modelos utilizados corresponde ao algoritmo ODT.
Os autores do método sugerem o uso de uma política do Ator estocástica. Foi exatamente isso que usamos nos artigos anteriores. Nesse aspecto, estamos alinhados.
No ODT, sugere-se o uso de um buffer de reprodução de trajetórias em vez de trajetórias individuais. É exatamente com esse buffer que trabalhamos. É aqui que entramos também.
Devo dizer que, no treinamento dos modelos, não utilizamos a componente de entropia da função de perda para estimular a pesquisa do ambiente. Nesta fase, não vamos adicioná-la e aceitamos os possíveis riscos. Esperamos que a política estocástica do Ator e o modelo de geração RTG garantam uma pesquisa suficiente durante a interação on-line com o ambiente.
Outro ponto que excluí da minha implementação diz respeito ao buffer de reprodução de experiência. Os autores do método sugerem selecionar algumas das trajetórias mais lucrativas após o treinamento off-line, que serão usadas nas primeiras fases do treinamento on-line. No entanto, inicialmente limitamos o número de trajetórias no buffer de reprodução de experiência. E, ao passarmos para o treinamento on-line, usaremos todo o buffer de reprodução de experiência disponível, ao qual adicionaremos novas trajetórias durante a interação com o ambiente. Neste processo, não vamos deletar imediatamente as trajetórias mais antigas ao adicionar novas. Vamos limitar o tamanho do buffer usando os meios previamente criados para salvar os dados em um arquivo após a conclusão da passagem.
Assim, considerando a aceitação de possíveis riscos, podemos muito bem usar modelos treinados no âmbito do artigo anterior. E, em seguida, tentaremos aumentar sua eficiência por meio de ajustes finos durante o treinamento on-line dos modelos, utilizando as abordagens ODT.
E aqui enfrentaremos algumas questões construtivas. O processo de trading é, por natureza, condicionalmente infinito. Condicionalmente, porque por uma série de razões ele é, no entanto, finito. Mas a probabilidade de tal evento é tão pequena no futuro previsível que o consideramos infinito. Portanto, realizamos o treinamento adicional não ao final do episódio, como sugerido pelos autores do método, mas com uma certa periodicidade.
E aqui quero lembrar que, em nossa implementação de DT, apenas os dados da última barra são fornecidos à entrada do modelo. Todo o volume do contexto de dados históricos é armazenado no buffer de resultados da camada de incorporação. Essa abordagem nos permitiu reduzir o consumo de recursos com o processamento redundante de dados. Mas isso se torna uma das "pedras no caminho" do treinamento on-line. O fato é que os dados no buffer de incorporação são armazenados em uma sequência histórica estrita. E o uso do modelo durante o treinamento periódico leva ao reenchimento do buffer com dados históricos de outras trajetórias ou da mesma trajetória, mas de uma diferente seção da história. Isso distorcerá os dados ao continuar a interação com o ambiente após o treinamento adicional dos modelos.
Existem, de fato, várias opções de solução para este problema. Todas têm diferentes níveis de complexidade de implementação e consumo de recursos durante a utilização prática. À primeira vista, a mais simples parece ser criar uma cópia do buffer e, antes de continuar a interação com o ambiente, retornar o buffer ao estado anterior ao início do treinamento. No entanto, ao examinar o processo em detalhes, entendemos que, do lado do modelo principal, o trabalho é realizado apenas com a classe de nível mais alto do modelo sem acesso aos buffers individuais das camadas neurais. E, nesse contexto, o simples processo de copiar dados de um buffer do modelo e de volta para o modelo leva a uma série de mudanças construtivas. Isso complica significativamente a implementação desse método.
Praticamente sem fazer alterações construtivas no modelo, podemos, após a conclusão do treinamento adicional, passar sequencialmente para o modelo todo o conjunto de dados históricos novamente. Mas isso leva a um volume significativo de repetições de operações de propagação do modelo. E o volume dessas operações aumenta à medida que o tamanho do contexto cresce. Isso torna tal abordagem ineficaz. O gasto de tempo e recursos computacionais no reprocessamento de dados pode exceder a economia alcançada ao manter o histórico de incorporações no buffer da camada neural.
Outra opção para resolver o problema é o uso de duplicatas dos modelos. Uma para interagir com o ambiente. A outra é usada durante o treinamento adicional. Essa abordagem é mais custosa em termos de recursos de memória, mas resolve completamente o problema com os dados no buffer da camada de incorporação. No entanto, surge a questão da troca de dados entre os modelos. Afinal, após o treinamento adicional, o modelo que interage com o ambiente deve usar a política do Agente atualizada. E o mesmo vale para o modelo de geração RTG. E aqui podemos lembrar o método Soft Actor-Critic com sua atualização suave dos modelos de destino. Por mais estranho que pareça, é exatamente esse mecanismo que nos permitirá transferir os coeficientes de peso atualizados entre os modelos sem alterar os outros buffers. Incluindo o buffer de resultados da camada de incorporação.
Para usar essa abordagem, precisaremos adicionar um método de troca de coeficientes de peso na camada de incorporação, que anteriormente não era utilizado na implementação do SAC.
Aqui, deve-se notar que, ao adicionar o método, fazemos adições apenas diretamente na classe CNeuronEmbeddingOCL, já que todas as APIs necessárias para seu funcionamento já foram previamente estabelecidas por nós e implementadas como um método virtual da classe base da camada neural CNeuronBaseOCL. Também é importante observar que, sem fazer essa modificação específica, a utilização prática do nosso modelo não gerará erros. Afinal, o método da classe pai será usado por padrão. Mas tal trabalho, neste caso, será incompleto e incorreto.
Para manter a sequência e redefinir corretamente os métodos virtuais, declaramos o método com a preservação dos parâmetros. No corpo do método, imediatamente chamamos o método equivalente da classe pai.
bool CNeuronEmbeddingOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(!CNeuronBaseOCL::WeightsUpdate(source, tau)) return false;
Como já dissemos várias vezes, essa abordagem de chamar a classe pai nos permite realizar todos os controles necessários com uma única ação, sem redundância desnecessária, e executar as operações necessárias com os objetos herdados.
Após a execução bem-sucedida das operações do método da classe pai, passamos a trabalhar nos objetos declarados diretamente na nossa classe de incorporação. No entanto, para acessar objetos similares da classe doadora, precisamos redefinir o tipo do objeto recuperado.
//---
CNeuronEmbeddingOCL *temp = source;
Em seguida, precisaremos transferir os parâmetros do buffer WeightsEmbedding. Mas antes de prosseguir com as operações, compararemos os tamanhos dos buffers do objeto atual e do objeto doador.
if(WeightsEmbedding.Total() != temp.WeightsEmbedding.Total()) return false;
E então, teremos que transferir o conteúdo de um buffer para o outro. Mas lembramos que todas as operações com buffers são realizadas no lado do contexto do OpenCL. Portanto, a transferência de dados também será realizada no lado do contexto. Eu uso intencionalmente a frase "transferência de dados", em vez de "cópia". Pois deixo a possibilidade de uma "cópia suave" com um coeficiente, conforme previsto pelo algoritmo SAC para modelos alvo. Os kernels do programa OpenCL foram criados anteriormente. E agora, precisamos apenas configurar sua chamada.
Definimos o espaço de tarefas do kernel com base no tamanho do buffer de coeficientes de peso.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {WeightsEmbedding.Total()};
Em seguida, o algoritmo se ramifica dependendo do algoritmo de atualização de parâmetros usado. A ramificação é necessária porque, no caso do uso do método Adam, precisaremos de mais buffers e hiperparâmetros. Isso leva ao uso de diferentes kernels.
Primeiro, criamos a ramificação do método Adam. Para usá-la, dois requisitos devem ser atendidos:
- a indicação do método de atualização de parâmetros correspondente ao criar o objeto, pois isso determina a criação de objetos com buffers de dados correspondentes;
- o coeficiente de atualização deve ser diferente de 1, caso contrário, é necessária uma cópia completa dos dados, independentemente do método de atualização de parâmetros utilizado.
if(tau != 1.0f && optimization == ADAM) { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, FirstMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, SecondMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
Após isso, enviamos o kernel SoftUpdateAdam para a fila de execução.
Uma operação semelhante é realizada na segunda ramificação do algoritmo, mas para o kernel SoftUpdate.
else { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdate, def_k_su_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdate, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
A tarefa construtiva está resolvida, e podemos passar para a implementação prática do método de treinamento on-line. Geramos a interação com o ambiente e o treinamento contínuo dos modelos no Expert Advisor ".../DoC/OnlineStudy.mq5". Este Expert Advisor é uma espécie de simbiose dos advisors de coleta de dados para treinamento e treinamento off-line de modelos discutidos em artigos anteriores. Ele contém todos os parâmetros externos necessários para a interação com o ambiente. Em particular, os parâmetros dos indicadores. No entanto, adicionamos parâmetros para indicar a periodicidade e o número de iterações de treinamento on-line. No advisor, os dados subjetivos são especificados por padrão. A periodicidade do treinamento eu especifiquei em 120 velas, que no timeframe H1 corresponde aproximadamente a 1 semana (5 dias * 24 horas). Durante a otimização, você pode ajustar os valores que serão mais ótimos para seus modelos.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod= 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int StudyIters = 5; //Iterations to Study input int StudyPeriod = 120; //Bars between Studies
No método de inicialização do advisor, primeiro carregamos o buffer de reprodução de experiência previamente criado. Ações semelhantes foram realizadas nos advisors de treinamento "Study.mql5" para diferentes métodos de treinamento off-line. Só que agora não encerramos o trabalho do advisor em caso de falha no carregamento dos dados. Ao contrário do modo off-line, permitimos o treinamento dos modelos apenas com novos dados que serão coletados durante a interação com o ambiente.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { LoadTotalBase();
Em seguida, prepararemos os indicadores, assim como fizemos anteriormente nos advisors de interação com o ambiente.
if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Carregaremos os modelos e verificaremos a conformidade deles em termos do tamanho das camadas de dados de entrada e resultados. Se necessário, criamos novos modelos com uma arquitetura previamente definida. Isso é um pouco além do treinamento contínuo dos modelos. Mas deixamos a possibilidade para o usuário realizar o treinamento on-line "do zero".
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true) || !AgentStudy.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTGStudy.Load(FileName + "RTG.nnw", dtStudied, true)) { PrintFormat("Can't load pretrained models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent, rtg)) { delete agent; delete rtg; PrintFormat("Can't create description of models"); return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg) || !AgentStudy.Create(agent) || !RTGStudy.Create(rtg)) { delete agent; delete rtg; PrintFormat("Can't create models"); return INIT_FAILED; } delete agent; delete rtg; //--- } //--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } AgentResult = vector<float>::Zeros(NActions); //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear(); RTG.Clear();
Note que carregamos (ou inicializamos) duas cópias de cado modelo. Uma para interagir com o ambiente. E a outra é usada durante o treinamento. Os modelos em treinamento receberam o sufixo Study.
Em seguida, inicializamos as variáveis globais e concluímos o trabalho do método.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
No método de desinicialização do advisor, salvamos os modelos em treinamento e o buffer acumulado de reprodução de experiências.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- AgentStudy.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTGStudy.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; int total = ArraySize(Buffer); printf("Saving %d", MathMin(total + 1, MaxReplayBuffer)); SaveTotalBase(); Print("Saved"); }
Note que salvamos especificamente os modelos em treinamento. Pois seus buffers contêm todas as informações necessárias para o subsequente treinamento e utilização prática dos modelos.
A interação com o ambiente é realizada no método de processamento de ticks OnTick. No início do método, verificamos a ocorrência do evento de abertura de uma nova barra e, se necessário, atualizamos os parâmetros dos indicadores. Também carregamos os dados de movimento de preço.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Preparamos os dados recebidos do terminal para serem enviados ao modelo de interação com o ambiente como dados de entrada.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Complementamos o buffer de dados com informações sobre o estado da conta.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Em seguida, criamos um rótulo de tempo.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
E adicionamos o vetor das últimas ações do Agente, que nos levaram ao estado atual.
//--- Prev action
bState.AddArray(AgentResult);
Os dados coletados são suficientes para a execução da propagação do modelo de geração RTG.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
Na verdade, no nosso vetor de dados de entrada, falta apenas esses dados para prever as ações ótimas do Agente no intervalo de tempo atual. Portanto, após a propagação bem-sucedida do primeiro modelo, adicionamos os resultados obtidos ao buffer de dados de entrada e chamamos o método de propagação do nosso Ator. É essencial verificar o resultado da execução das operações.
RTG.getResults(Result); bState.AddArray(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Após a propagação bem-sucedida dos modelos, deciframos os resultados de seu trabalho e realizaremos a ação escolhida no ambiente. Esse processo está totalmente alinhado com o algoritmo anteriormente examinado em modelos de interação com o ambiente.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Avaliamos a recompensa do ambiente pela transição para o estado atual. E toda a informação coletada é passada para a formação da trajetória atual.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove();
Com isso, conclui-se a interação com o ambiente. Mas antes de sair do método, verificaremos a necessidade de iniciar o treinamento adicional dos modelos. Para fins de verificar a eficácia do método, usei, provavelmente, o controle mais simples. Eu simplesmente verifico a divisibilidade do tamanho do histórico geral do instrumento no timeframe analisado pela periodicidade do treinamento. Em condições de utilização em grande escala, é aconselhável utilizar abordagens mais sofisticadas para deslocar o treinamento adicional para períodos de fechamento do mercado ou de redução de volatilidade do instrumento. Além disso, pode ser útil adiar a atualização dos parâmetros dos modelos até o fechamento de todas as posições. Em geral, para uso em modelos reais, eu recomendaria abordar a escolha da periodicidade e do tempo de treinamento adicional dos modelos de maneira mais ponderada e consciente.
//--- if((Bars(_Symbol, TimeFrame) % StudyPeriod) == 0) Train(); }
Em seguida, voltamos nossa atenção para o método de treinamento dos modelos, Train. Aqui, é importante notar que o treinamento adicional é realizado levando em conta a experiência obtida durante a interação atual com o ambiente. No método de processamento de ticks, coletamos toda a informação recebida do ambiente em uma trajetória separada. No entanto, esta trajetória não é adicionada ao buffer de reprodução de experiência. Anteriormente, realizávamos essa operação apenas ao final do episódio. No entanto, tal abordagem é inaceitável no nosso caso de atualização periódica dos parâmetros. Pois ela nos aproxima do treinamento off-line, quando a política do Agente é treinada apenas em trajetórias fixas de experiências anteriores. E, portanto, antes de iniciar o treinamento, adicionaremos os dados coletados ao buffer de reprodução de experiências.
Com o objetivo de prevenir o armazenamento de trajetórias demasiadamente curtas e não informativas, limitaremos o tamanho mínimo da trajetória a ser salva. No exemplo fornecido, limitei o tamanho mínimo da trajetória ao período de atualização dos parâmetros do modelo.
Se o tamanho da trajetória acumulada atender aos requisitos mínimos, então a adicionamos ao buffer de reprodução de experiências e recalculamos a soma cumulativa de recompensas.
Aqui, é importante notar que a soma cumulativa de recompensas é recalculada apenas para a cópia da trajetória que foi transferida para o buffer de reprodução de experiências. No buffer original de acumulação de informações sobre a trajetória atual, a recompensa deve permanecer não recalculada. Pois, ao interagir subsequentemente com o ambiente, a trajetória será complementada. E, portanto, ao adicionar novamente a trajetória atualizada, o recálculo repetido da soma cumulativa de recompensas levaria à duplicação dos dados. Para evitar isso, no buffer de acumulação de trajetórias, sempre mantemos a recompensa não recalculada.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); if(Base.Total >= StudyPeriod) if(ArrayResize(Buffer, total_tr + 1) == (total_tr + 1)) { Buffer[total_tr] = Base; Buffer[total_tr].CumRevards(); total_tr++; }
Em seguida, devemos lembrar que o tamanho do buffer de acumulação de trajetória é limitado pela constante Buffer_Size. E com o objetivo de prevenir o erro de estouro de array, verificamos a existência de um número suficiente de células livres no buffer de acumulação de trajetórias para registrar os passos até o próximo armazenamento da trajetória. Se necessário, eliminamos alguns dos passos mais antigos.
Note que os dados são removidos no buffer primário de acumulação de trajetórias. Enquanto isso, na cópia da trajetória que salvamos no buffer de reprodução de experiências, essas informações são preservadas.
Ao especificar constantes e parâmetros do modelo, deve-se considerar que o tamanho do buffer de trajetória permita salvar o histórico de pelo menos um período entre os retreinamentos dos modelos.
int clear = Base.Total + StudyPeriod - Buffer_Size; if(clear > 0) Base.ClearFirstN(clear);
Então, eu acrescentei mais um controle adicional, que pode parecer supérfluo. Eu verifico o buffer de reprodução de experiências para a presença de trajetórias curtas e, ao encontrá-las, as removo. À primeira vista, a presença de tais trajetórias é pouco provável devido à existência de um controle similar antes de adicionar a trajetória ao buffer de reprodução de experiências. Mas ainda assim considero a possibilidade de falhas ao ler e salvar trajetórias no arquivo. E para eliminar erros subsequentes, realizamos esta verificação.
//--- int count = 0; for(int i = 0; i < (total_tr + count); i++) { if(Buffer[i + count].Total < StudyPeriod) { count++; i--; continue; } if(count > 0) Buffer[i] = Buffer[i + count]; } if(count > 0) { ArrayResize(Buffer, total_tr - count); total_tr = ArraySize(Buffer); }
Em seguida, preparamos o sistema de laços de treinamento dos modelos. Este processo é em grande parte uma repetição do similar da artigo anterior. O laço externo é configurado de acordo com o número de iterações de treinamento dos modelos, especificado nos parâmetros externos do EA.
No corpo do laço, selecionamos aleatoriamente uma trajetória e um elemento desta trajetória, a partir do qual começaremos a próxima iteração de treinamento dos modelos.
uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < StudyIters && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Então, limpamos os buffers de incorporação dos modelos e o vetor de ações anteriores do Ator.
vector<float> Actions = vector<float>::Zeros(NActions); AgentStudy.Clear(); RTGStudy.Clear();
Neste estágio, concluímos o trabalho preparatório e podemos começar as operações de treinamento direto dos modelos. Executamos o laço aninhado de treinamento.
No corpo do laço, repetimos a preparação do buffer de dados de entrada, similar ao descrito anteriormente no método de processamento de ticks. A sequência de armazenamento de dados no buffer é completamente repetida. A única diferença é que, antes, os dados eram solicitados ao terminal, mas agora os pegamos do buffer de reprodução de experiências.
for(int state = i; state < MathMin(Buffer[tr].Total - 2, int(i + HistoryBars * 1.5)); state++) { //--- History data bState.AssignArray(Buffer[tr].States[state].state); //--- Account description float prevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float prevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); bState.Add((Buffer[tr].States[state].account[0] - prevBalance) / prevBalance); bState.Add(Buffer[tr].States[state].account[1] / prevBalance); bState.Add((Buffer[tr].States[state].account[1] - prevEquity) / prevEquity); bState.Add(Buffer[tr].States[state].account[2]); bState.Add(Buffer[tr].States[state].account[3]); bState.Add(Buffer[tr].States[state].account[4] / prevBalance); bState.Add(Buffer[tr].States[state].account[5] / prevBalance); bState.Add(Buffer[tr].States[state].account[6] / prevBalance); //--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(Actions);
Após a coleta da primeira parte dos dados de entrada, realizamos a propagação do modelo de geração RTG. E imediatamente realizamos a propagação com o objetivo de minimizar o erro em relação à recompensa real obtida. Assim, construímos um modelo autorregressivo para a previsão da recompensa possível com base na trajetória anterior de estados e ações.
//--- Return to go if(!RTGStudy.feedForward(GetPointer(bState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } Result.AssignArray(Buffer[tr].States[state + 1].rewards); if(!RTGStudy.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Para os propósitos de treinamento da política do Agente, no buffer de dados de entrada, em vez do RTG previsto, indicamos a recompensa real obtida e realizamos a propagação.
//--- Policy Feed Forward bState.AddArray(Buffer[tr].States[state + 1].rewards); if(!AgentStudy.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
O treinamento da política do Agente é realizado com o objetivo de minimizar o erro entre a ação prevista e a ação efetivamente realizada, que levou à obtenção de recompensa.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; AgentStudy.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!AgentStudy.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Isso permite construir um modelo autorregressivo para a escolha da ação ótima para obter a recompensa desejada no contexto dos estados visitados anteriormente e das ações realizadas pelo Agente.
Após a conclusão bem-sucedida das iterações de treinamento dos modelos, informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do ciclo de treinamento dos modelos.
Ao final de todas as iterações do sistema de laços aninhados do treinamento dos modelos, limpamos o campo de comentários no gráfico e transferimos os parâmetros dos modelos treinados para os modelos de interação com o ambiente. No exemplo fornecido, copio completamente os dados dos coeficientes de peso. Assim, simulo o uso de um único modelo para treinamento e utilização prática. No entanto, também considero experimentos com diferentes coeficientes de cópia de dados.
Comment(""); //--- Agent.WeightsUpdate(GetPointer(AgentStudy), 1.0f); RTG.WeightsUpdate(GetPointer(RTGStudy), 1.0f); //--- }
Com isso, concluímos a revisão do algoritmo do EA de treinamento on-line do transformador de decisões, e o código completo do EA e de todos os seus métodos pode ser consultado no anexo.
Note que o EA ".../DoC/OnlineStudy.mq5" está localizado no subdiretório "DoC" com os EAs do artigo anterior. Eu não o separei em um subdiretório distinto, já que funcionalmente ele realiza o retreinamento dos modelos que foram treinados off-line pelos EAs do artigo anterior. Assim, mantemos a integridade do conjunto de arquivos de treinamento dos modelos.
Também no anexo, você pode encontrar todos os programas usados tanto no artigo atual quanto nos anteriores.
3. Teste
Acima, exploramos os aspectos teóricos do método transformador de decisões on-line e construímos nossa própria interpretação, um tanto livre, do método proposto. O próximo passo é testar o trabalho realizado. Efetivamente, realizamos o ajuste fino dos modelos do artigo anterior. Para esses propósitos, no testador de estratégias, realizamos um ciclo de execuções únicas do nosso novo EA com base no histórico de dados de treinamento.
Lembro que, no artigo anterior, realizamos o treinamento off-line dos modelos com dados históricos dos primeiros 7 meses de 2023. É neste mesmo período histórico que realizamos o ajuste fino dos modelos.
Durante o ajuste fino, o ODT permitiu aumentar a rentabilidade geral dos modelos. Na amostra de teste de agosto de 2023, o modelo conseguiu gerar cerca de 10% de lucro. O gráfico de rentabilidade não é perfeito, mas já é possível observar algumas tendências.

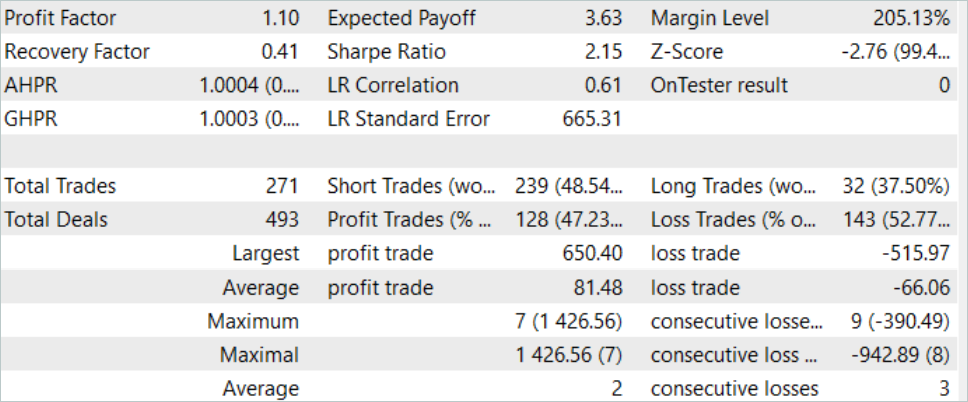
Os resultados do teste realizado com o modelo treinado são apresentados acima. No total, durante o período de teste, foram realizadas 271 transações. E 128 delas foram fechadas com lucro, o que representa mais de 47%. Como se pode ver, a proporção de transações lucrativas é um pouco menor que as perdas. No entanto, a transação mais lucrativa excede a perda máxima em 26%. E a transação lucrativa média excede a transação perdedora média em mais de 20%. Tudo isso permitiu aumentar o fator de lucro do trabalho do modelo para 1.10.
Considerações finais
Neste artigo, continuamos explorando formas de aumentar a eficácia do método Transformer de Decisão (transformador de decisões) e nos familiarizamos com o algoritmo de ajuste fino de modelos no modo de treinamento on-line transformador de decisões on-line (ODT). Este método permite aumentar a eficácia dos modelos treinados em modo off-line e dá aos Agentes a capacidade de se adaptarem ao ambiente em mudança, melhorando assim suas políticas através da interação com o ambiente.
Na parte prática do artigo, implementamos o método usando MQL5 e realizamos o treinamento on-line dos modelos do artigo anterior. É importante notar que a otimização dos modelos foi alcançada apenas pelo uso do método ODT discutido. Durante o treinamento on-line, utilizamos modelos que foram treinados off-line no âmbito do artigo anterior. Não foram feitas quaisquer alterações construtivas na arquitetura dos modelos. Foi realizado apenas o retreinamento on-line. E isso permitiu melhorar a eficácia dos modelos, o que por si só confirma a eficácia do uso do método transformador de decisões on-line.
Quero relembrar que todos os programas apresentados no artigo são destinados apenas para demonstração da tecnologia e não estão prontos para uso no trading real.
Links
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Online Decision Transformer
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Redes neurais de maneira fácil (Parte 34): Função quantil totalmente parametrizada
- Redes neurais de maneira fácil (Parte 58): Transformador de decisões (Decision Transformer—DT)
- Redes neurais de maneira fácil (Parte 59): dicotomia do controle (DoC)
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA para treinamento do agente |
| 3 | OnlineStudy.mq5 | Expert Advisor | EA de pré-treinamento de agentes on-line |
| 4 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13596
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Experimentos com redes neurais (Parte 7): Transferência de indicadores
Experimentos com redes neurais (Parte 7): Transferência de indicadores
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso