
Teoría de categorías en MQL5 (Parte 19): Inducción cuadrática de la naturalidad
Introducción:
En esta serie de artículos, analizaremos la aplicación de la teoría de categorías para clasificar datos discretos y mostraremos, a través de varios ejemplos, cómo los algoritmos comerciales, principalmente los que gestionan los trailing stops, pero también los que gestionan las señales de entrada y el tamaño de las posiciones, pueden incorporarse perfectamente a un asesor para implementar algunos de sus conceptos. El wizard MQL5 en el IDE resultó muy útil con esto, ya que todo el código fuente común debe compilarse usando el wizard para obtener un sistema comprobable.
En este artículo veremos cómo utilizar los cuadrados de la naturalidad, cuyo concepto presentamos en el último artículo. Demostraremos sus beneficios potenciales usando el ejemplo de tres pares de divisas que pueden vincularse mediante transacciones de arbitraje. Asimismo, buscaremos una clasificación para los datos de cambio de precio de uno de los pares para evaluar la viabilidad del desarrollo de un algoritmo de señales de entrada para este par.
Los cuadrados de la naturalidad son una extensión de las transformaciones naturalesdel diagrama conmutativo. Por lo tanto, si tenemos dos categorías separadas con más de un funtor entre ellas, entonces podremos evaluar la relación entre dos o más objetos en una categoría de codominio y usar este análisis no solo para correlacionar con otras categorías similares, sino también para hacer predicciones dentro de la categoría observada si los objetos están en la serie temporal.
Comprendiendo el entorno:
Nuestras dos categorías en este artículo tendrán una estructura similar a la vista en el artículo anterior, ya que habrá dos funtores entre ellas. Pero esta será la principal similitud, ya que en este caso tendremos varios objetos en ambas categorías, mientras que en el caso anterior teníamos dos objetos en la categoría de dominio y solo cuatro en la categoría de codominio.
Por ello, en una categoría de dominio que contenga una serie temporal, cada punto de precio de esta serie se representará como un objeto. Estos "objetos" estarán vinculados en orden cronológico con la ayuda de morfismos que simplemente los incrementarán al periodo de tiempo del gráfico al que está vinculado el script. Además, como estamos tratando con series temporales, esto significa que nuestra categoría no estará relacionada y, por lo tanto, no tendrá cardinalidad. Y nuevamente, como en artículos anteriores, no nos interesará tanto el tamaño general y el contenido de las categorías/objetos, sino los morfismos y, más específicamente, los funtores de estos objetos.
En la categoría de codominio tenemos dos series temporales de precios para otros dos pares de divisas. No olvide que para trabajar en el arbitraje triangular se necesitan al menos tres pares de divisas. Podemos tener más, pero en nuestro caso utilizaremos el mínimo para mantener una relativa simplicidad en la implementación. Por lo tanto, la categoría de dominio contendrá las series de precios para el primer par, que será USDJPY. Los otros dos pares que se incluirán en el codominio como series de precios serán EURJPY y EURUSD.
Los morfismos que conectan los “objetos” de precios en la segunda categoría solo estarán dentro de una serie concreta, ya que en la etapa inicial no tendremos un solo objeto de conexión en cada serie.
Cuadrados de la naturalidad e inducción:
Así, el concepto de cuadrados de naturalidad en el marco de la teoría de categorías enfatiza la propiedad conmutativa, que en nuestro último artículo se utilizó como medio para verificar la clasificación. Como ejemplo tenemos el siguiente diagrama, que muestra cuatro objetos en la categoría de codominio:
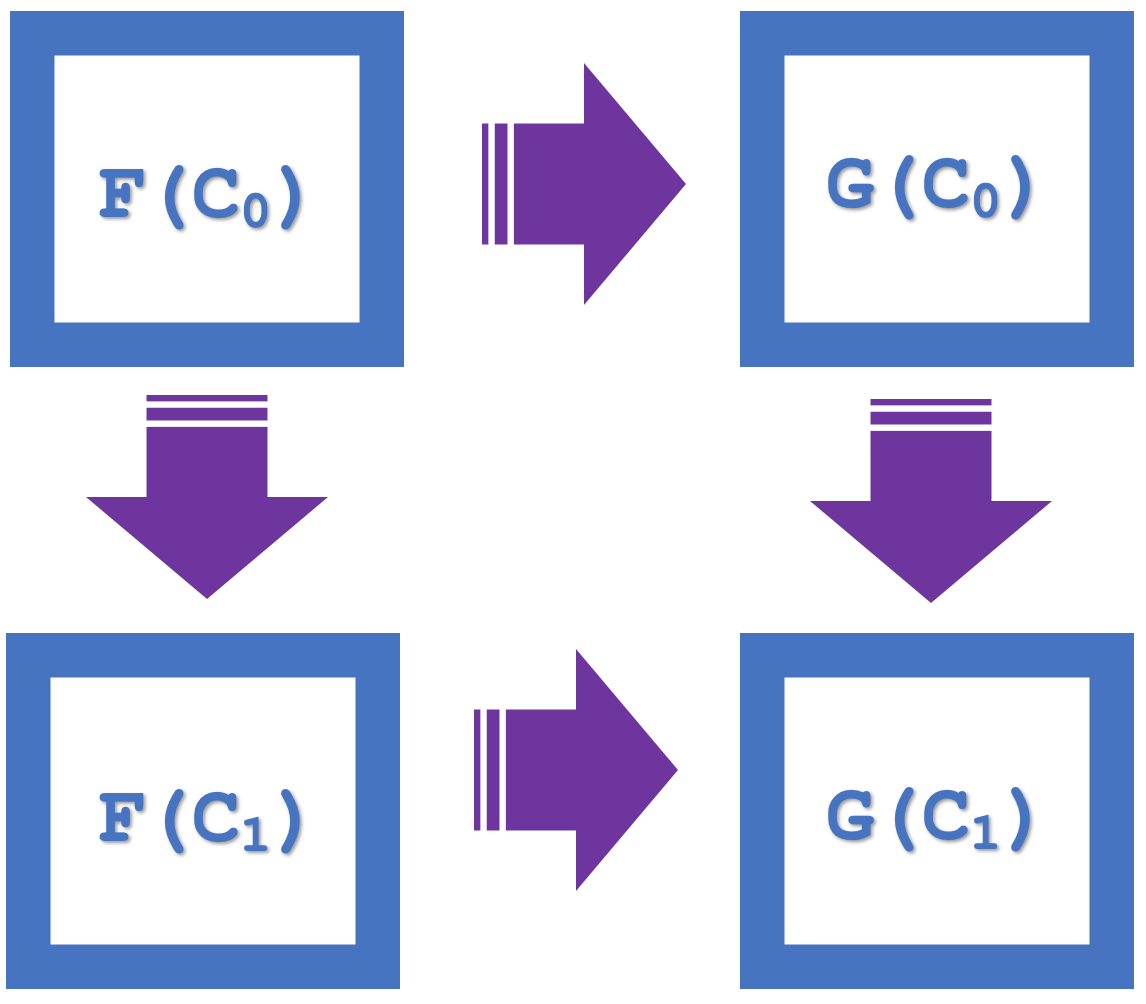
Podemos ver que hay una conmutación F(C 0 ) - G(C 0 ) y luego G(C 1 ), equivalente a F(C 0 ) - F(C 1 ) y luego G(C 1 ).
El concepto de inducción introducido en este artículo enfatiza la posibilidad de conmutar series de varios cuadrados, lo cual simplifica el diseño y ahorra recursos computacionales. Si consideramos el siguiente diagrama, en el que se enumeran n cuadrados:
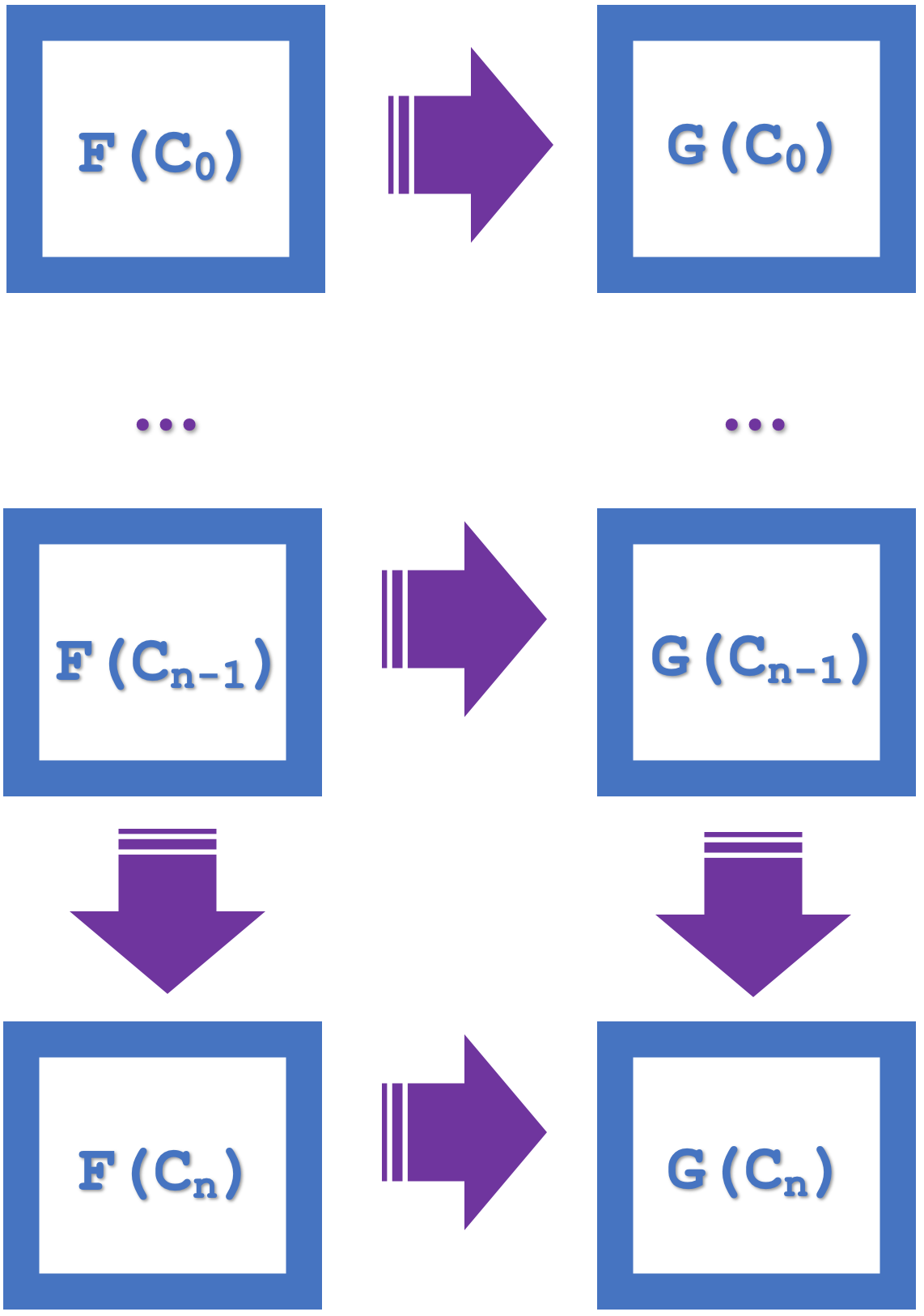
Si los pequeños cuadrados de naturalidad conmutan, entonces deduciremos que el mayor rectángulo también conmutará. Esta gran conmutación implicará morfismos y funtores con un paso 'n'. Por lo tanto, nuestros dos funtores pertenecerán a la serie USDJPY, pero se conectarán a series EURJPY y EURUSD distintas. Por lo tanto, se realizarán conversiones naturales de EURJPY a EURUSD. Dado que para la clasificación, como en el artículo anterior, utilizaremos el cuadrado de la naturalidad, las previsiones serán para el codominio de las transformaciones naturales, que es el EURUSD. La inducción permitirá considerar estos pronósticos en varias barras, y no en una, como era el caso en el artículo anterior. En el artículo anterior, intentar hacer pronósticos sobre múltiples barras resultaba computacionalmente costoso porque debíamos utilizar muchos bosques de decisión aleatorios. Con la ayuda de la inducción ahora podemos comenzar la clasificación con un retraso de n barras.
A continuación le mostramos una representación visual de estos cuadrados de la naturalidad como un solo rectángulo:
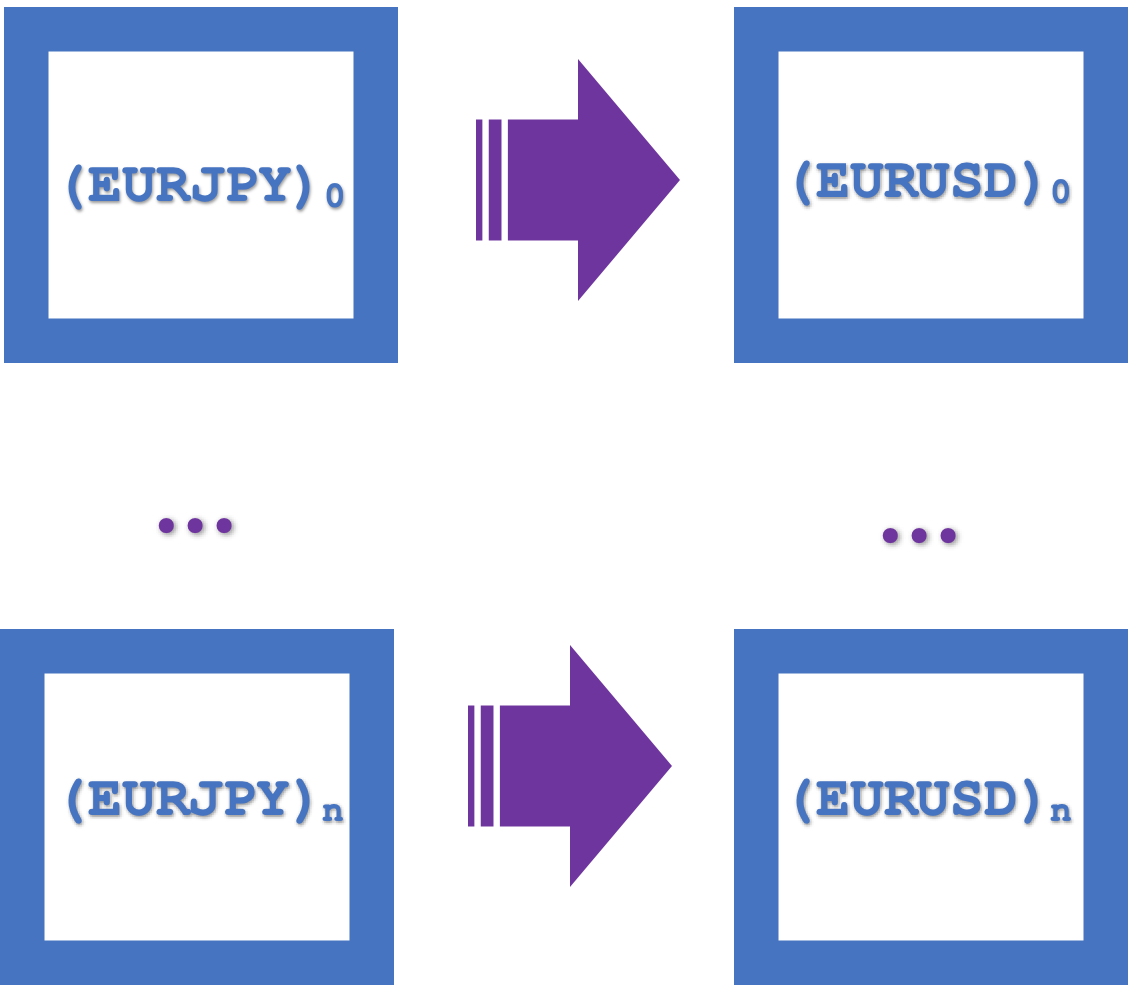
Los funtores juegan un papel importante en este proceso:
Como ya hemos visto los funtores, este párrafo servirá para resaltar cómo los aplicamos al trabajar con cuadrados de la naturalidad. En el artículo anterior utilizamos perceptrones multicapa para determinar el mapeo de nuestros funtores, pero en este artículo analizaremos bosques de decisión aleatorios con el mismo propósito.
Decision Forests es un clasificador que usa múltiples métodos de aprendizaje (bosques) para mejorar la predicción. Al igual que el perceptrón multicapa (MLP), resulta relativamente complejo y a menudo se le denomina método de aprendizaje conjunto. Implementar esto desde los primeros principios resultaría demasiado tedioso para nuestros propósitos, así que es bueno que Alglib ya tengamos clases de implementación disponibles en la biblioteca MQL5, en la carpeta 'Include\Math'.
Por lo tanto, un mapeo que use Random Decision Forests (RDFs) se determinará especificando el tamaño del bosque y asignando pesos a los distintos árboles y las ramas correspondientes del bosque. No obstante, para facilitar la descripción, podemos pensar en los RDFs como en un equipo de pequeños tomadores de decisiones, donde cada uno de ellos supone un árbol que sabe cómo observar un conjunto de datos y tomar una decisión. Todos recibirán la misma pregunta (datos) y cada uno ofrecerá una respuesta (solución). Cuando todos los equipos hayan elegido, se realizará una votación para seleccionar la solución que más guste. Lo más interesante de este proceso es que aunque a todos los equipos (árboles) se les han dado los mismos datos, los equipos han extraído conocimientos de diferentes partes porque el muestreo ha sido aleatorio. ¡Las decisiones que se toman en base a esto suelen resultar inteligentes y precisas!
Hemos intentado hacer nuestra propia implementación desde cero y este algoritmo, aunque se puede describir de forma sencilla, resulta bastante complejo. Sin embargo, esto se puede lograr usando Alglib en varios formatos. El más simple de ellos requiere solo dos parámetros de entrada: el número de bosques y un parámetro de entrada de tipo double R, que especificará el porcentaje del conjunto de entrenamiento utilizado para construir los árboles. Para nuestros propósitos, usaremos precisamente este. Existen otros requisitos, como el número de variables independientes y el número de variables dependientes (también conocidos como clasificadores), pero son comunes a la mayoría de los modelos de aprendizaje automático.
Implementación de scripts en lenguaje MQL5:
Para codificar todo lo presentado en esta serie, usaremos exclusivamente el entorno de desarrollo MQL5. Merece la pena enfatizar que además de indicadores personalizados, asesores y scripts MQL5, en este entorno podemos codificar/desarrollar servicios, bibliotecas, bases de datos e incluso scripts en Python.
En este artículo, simplemente utilizaremos un script para demostrar la clasificación según los cuadrados de la naturalidad en inducción. La opción ideal sería un ejemplar de la clase de señal del experto, y no solo un script; sin embargo, la implementación de una clase de señal multidivisa, aunque posible, no resulta tan conveniente como se muestra en este artículo, por lo tanto, en condiciones no optimizadas, mostraremos los cambios previstos y reales en el precio de cierre del par EURUSD y utilizaremos dichos resultados para confirmar o refutar nuestra tesis de que los cuadrados de la naturalidad con inducción son útiles para hacer predicciones.
Entonces, nuestro script comenzará creando un ejemplar de categoría de dominio para almacenar una serie de cambios en el precio de cierre de USDJPY. Esta categoría se puede usar para el entrenamiento y estará etiquetada como tal. Aunque el entrenamiento con él establecerá los pesos para los funtores que van desde él a la categoría de codominio (nuestros dos funtores), estos pesos no serán de importancia crítica para nuestras predicciones (como discutimos en el artículo anterior), pero los mencionaremos aquí para tener perspectiva.
//create domain series (USDJPY-rates) in first category for training CCategory _c_a_train;_c_a_train.Let(); int _a_size=GetObject(_c_a_train,__currency_a,__training_start,__training_stop);
Luego crearemos el ejemplar de categoría codomain que, como ya hemos mencionado, representará dos series temporales: EURJPY y EURUSD. Dado que cada punto de precio representa un objeto, deberemos tener cuidado de "almacenar" dos series dentro de una categoría añadiendo objetos secuencialmente para cada serie. Los designaremos como b y c.
//create 2 series (EURJPY and EURUSD rates) in second category for training CCategory _c_bc_train;_c_bc_train.Let(); int _b_trains=GetObject(_c_bc_train,__currency_b,__training_start,__training_stop); int _c_trains=GetObject(_c_bc_train,__currency_c,__training_start,__training_stop);
Así, nuestras predicciones, al igual que en el artículo anterior, se centrarán en los objetos de codominio que forman el cuadrado de la naturalidad. Mostraremos los morfismos que conectan cada serie junto con las transformaciones naturales que vinculan los objetos entre series como RDF.
Nuestro script tendrá un parámetro de entrada para el número de inducciones, con el que escalaremos el cuadrado y haremos proyecciones más allá de la siguiente barra. Así, nuestros cuadrados de la naturalidad por n inducciones formarán un solo cuadrado, que tomaremos como los ángulos A, B, C y D, siendo AB y CD nuestras transformaciones, y AC y BD los morfismos.
Al implementar este mapeo, podremos usar tanto MLP como RDF para, por ejemplo, las transformaciones y morfismos, respectivamente. Dejaremos que el lector explore esta cuestión, ya que ya hemos visto cómo se puede utilizar los MLP. No obstante, en el futuro, necesitaremos poblar nuestros modelos de entrenamiento de RDF con datos, lo cual se logrará mediante una matriz. Los cuatro RDF para cada mapeo de AB a CD tendrán su propia matriz, que se rellenará con el siguiente listado:
//create natural transformation, by induction across, n squares..., cpi to pmi //mapping by random forests int _training_size=fmin(_c_trains,_b_trains); int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CDFReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(_training_size,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(_training_size,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(_training_size,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(_training_size,1+1); double _a=0.0,_b=0.0,_c=0.0,_d=0.0; CElement<string> _e_a,_e_b,_e_c,_e_d; string _s_a="",_s_b="",_s_c="",_s_d=""; for(int i=0;i<_training_size-__n_inductions;i++) { _s_a="";_e_a.Let();_c_bc_train.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); _s_b="";_e_b.Let();_c_bc_train.domain[i+_b_trains].Get(0,_e_b);_e_b.Get(1,_s_b);_b=StringToDouble(_s_b); _s_c="";_e_c.Let();_c_bc_train.domain[i+__n_inductions].Get(0,_e_c);_e_c.Get(1,_s_c);_c=StringToDouble(_s_c); _s_d="";_e_d.Let();_c_bc_train.domain[i+_b_trains+__n_inductions].Get(0,_e_d);_e_d.Get(1,_s_d);_d=StringToDouble(_s_d); if(i<_training_size-__n_inductions) { _xy_ab[i].Set(0,_a); _xy_ab[i].Set(1,_b); _xy_bd[i].Set(0,_b); _xy_bd[i].Set(1,_d); _xy_ac[i].Set(0,_a); _xy_ac[i].Set(1,_c); _xy_cd[i].Set(0,_c); _xy_cd[i].Set(1,_d); } }
Una vez que los conjuntos de datos estén listos, podremos declarar ejemplares de modelo para cada RDF y comenzar a entrenar cada uno individualmente. Esto se hará como se muestra a continuación:
CDForest _forest; CDecisionForest _rdf_ab,_rdf_cd; CDecisionForest _rdf_ac,_rdf_bd; _forest.DFBuildRandomDecisionForest(_xy_ab,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ab,_rdf_ab,_report_ab); _forest.DFBuildRandomDecisionForest(_xy_bd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_bd,_rdf_bd,_report_bd); _forest.DFBuildRandomDecisionForest(_xy_ac,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ac,_rdf_ac,_report_ac); _forest.DFBuildRandomDecisionForest(_xy_cd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_cd,_rdf_cd,_report_cd);
Los resultados de cada entrenamiento, que necesitamos evaluar, estarán en el valor entero del parámetro 'info'. Al igual que ocurre con el MLP, este valor deberá ser positivo. Si todos nuestros parámetros de "información" son positivos, entonces podremos comenzar a realizar pruebas.
Tenga en cuenta que los parámetros de entrada de nuestro script incluirán 3 fechas: la fecha de inicio del entrenamiento, la fecha de finalización del entrenamiento y la fecha de finalización de la prueba. De manera ideal, estos valores deberían verificarse antes de usarlos para asegurarnos de que estén en orden ascendente en el orden que los especifiqué. Además, falta la fecha de inicio de la prueba porque la fecha de finalización del entrenamiento también es la fecha de inicio de la prueba. Por consiguiente, implementaremos una prueba directa utilizando el siguiente listado:
// if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { //create 2 objects (cpi and pmi) in second category for testing CCategory _c_cp_test;_c_cp_test.Let(); int _b_test=GetObject(_c_cp_test,__currency_b,__training_stop,__testing_stop); ... ... MqlRates _rates[]; ArraySetAsSeries(_rates,true); if(CopyRates(__currency_c,Period(), 0, _testing_size+__n_inductions+1, _rates)>=_testing_size+__n_inductions+1) { ArraySetAsSeries(_rates,true); for(int i=__n_inductions+_testing_size;i>__n_inductions;i--) { _s_a="";_e_a.Let();_c_cp_test.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); double _x_ab[],_y_ab[]; ArrayResize(_x_ab,1); ArrayResize(_y_ab,1); ArrayInitialize(_x_ab,0.0); ArrayInitialize(_y_ab,0.0); // _x_ab[0]=_a; _forest.DFProcess(_rdf_ab,_x_ab,_y_ab); ... double _x_cd[],_y_cd[]; ArrayResize(_x_cd,1); ArrayResize(_y_cd,1); ArrayInitialize(_x_cd,0.0); ArrayInitialize(_y_cd,0.0); // _x_cd[0]=_y_ac[0]; _forest.DFProcess(_rdf_cd,_x_cd,_y_cd); double _c_forecast=0.0; if((_y_bd[0]>0.0 && _y_cd[0]>0.0)||(_y_bd[0]<0.0 && _y_cd[0]<0.0))//abd agrees with acd on currency c change { _c_forecast=0.5*(_y_bd[0]+_y_cd[0]); } double _c_actual=_rates[i-__n_inductions].close-_rates[i].close; if((_c_forecast>0.0 && _c_actual>0.0)||(_c_forecast<0.0 && _c_actual<0.0)){ _strict_match++; } else if((_c_forecast>=0.0 && _c_actual>=0.0)||(_c_forecast<=0.0 && _c_actual<=0.0)){ _generic_match++; } else { _miss++; } } // ... } }
Recuerde que nos interesa la previsión de los cambios en el tipo de cambio EURUSD, que en nuestro cuadrado se representará como D. Al comprobar nuestras previsiones en el test forward, registraremos los valores que coincidan estrictamente en cuanto a su dirección, los valores que podrían coincidir en dicha dirección, dado que tenemos ceros involucrados, y finalmente también fijaremos los espacios libres. Todo esto se reflejará en el listado anterior.
Entonces, para resumir nuestro escenario, comenzaremos declarando las categorías de entrenamiento, una de las cuales será muy necesaria para el preprocesamiento y el entrenamiento de los datos. Utilizaremos USDJPY, EURJPY y EURUSD como pares de divisas de arbitraje. Luego mapearemos nuestros objetos de categoría de codominio utilizando un RDF, que ejercerá como morfismos en las series y las transformaciones naturales en las series para construir predicciones sobre los datos de prueba, que se definirán por la fecha de finalización del entrenamiento y la fecha de finalización de la prueba.
Resultados y análisis:
Si ejecutamos el script adjunto al final del artículo, que implementa la fuente general anteriormente ofrecida, obtendremos los siguientes registros con inducciones de 1 en el gráfico diario USDJPY:
2023.09.01 13:39:14.500 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 45, strict matches: 61, & generic matches: 166, for strict pct (excl. generic): 0.58, & generic pct: 0.83, with inductions at: 1
Sin embargo, si aumentamos el número de inducciones a 2, obtendremos esto:
2023.09.01 13:39:55.073 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 56, strict matches: 63, & generic matches: 153, for strict pct (excl. generic): 0.53, & generic pct: 0.79, with inductions at: 2
Existe una ligera disminución, aunque significativa, pero positiva, ya que hay más aciertos que errores estrictos. Podemos crear un registro del número de entradas según los aciertos y errores. Esto se muestra en el gráfico siguiente:
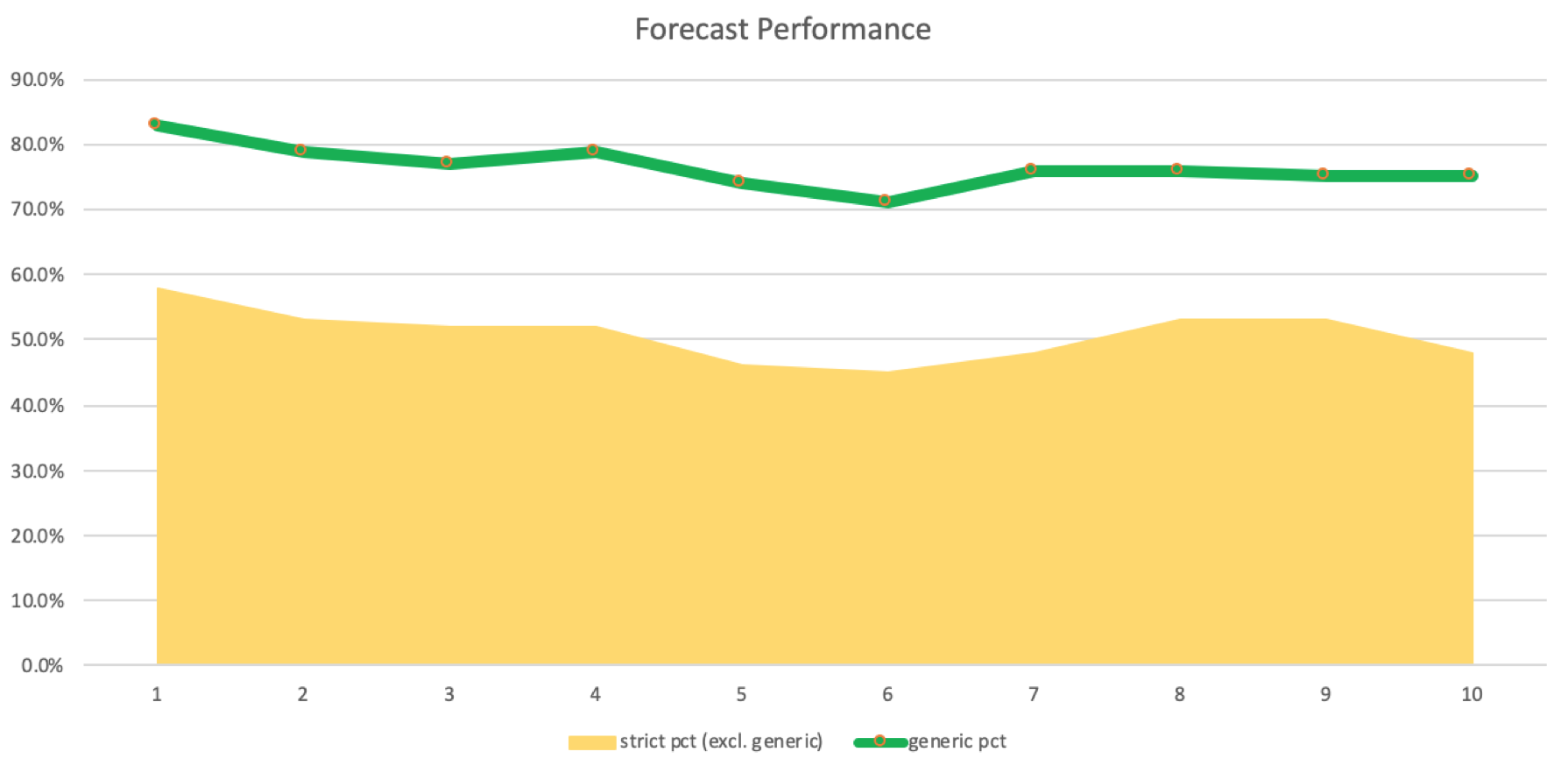
La precisión de estos pronósticos y coincidencias deberá verificarse en un sistema comercial real que ejecute pasadas con diferentes retrasos de inducción para probar o refutar su efectividad. Muy a menudo, los sistemas pueden ser rentables con un porcentaje de beneficios más bajo, por lo que no podemos decir definitivamente que el uso de retrasos de inducción de 5 a 8 sea ideal para nuestro sistema. Esto lo confirmaremos haciendo pruebas con un asesor que pueda manejar múltiples divisas.
El principal problema con esta implementación es la incapacidad del wizard MQL5 para probar las señales como una clase de asesor. Por defecto, el wizard de plantillas inicia los indicadores y búferes de precio para un solo símbolo: el símbolo del gráfico. Podemos solucionar este problema para dar cabida a varios símbolos, pero para ello necesitaremos crear nuestra propia clase que herede de la clase CExpert y realizarle algunos cambios. En mi opinión, este punto resulta demasiado amplio para el presente artículo, por lo que el lector podrá estudiar el tema por su cuenta.
Comparación con los métodos tradicionales:
En comparación con los métodos "tradicionales" que utilizan indicadores simples como la media móvil, nuestro enfoque basado en la inducción del cuadrado de la naturalidad parece complejo y quizás confuso si solo leemos su descripción. Aún tengo la esperanza de que con la abundancia de bibliotecas de código (como Alglib) disponibles en Internet y en la biblioteca MQL5, el lector se haga una idea de cómo un enfoque o idea aparentemente compleja se puede convertir fácilmente en código con menos de 200 líneas. Esto permitirá explorar, aceptar o refutar nuevas ideas. MQL5 IDE es un paraíso para los amantes del aprendizaje.
Las principales ventajas de este sistema son su adaptabilidad y su precisión potencial.
Aplicaciones reales:
Si exploramos la aplicación práctica de nuestro sistema de pronóstico con pares de arbitraje, será solo en el intento de explotar oportunidades de arbitraje dentro de tres pares. Todo el mundo sabe que cada bróker tiene su propia política de spreads para los pares en el mercado Fórex, y si existen oportunidades de arbitraje, es solo porque uno de los tres pares tiene un precio tan incorrecto que la brecha excede el spread del par. Estas posibilidades existían antes, pero con el paso de los años, cuando la latencia para la mayoría de los brókeres ha disminuido, se han vuelto muy reales. Además, algunos brókeres incluso prohíben esta práctica.
Por lo tanto, si practicamos arbitraje, será de una pseudoforma en la que “no notaremos” el spread y, en cambio, miraremos los precios brutos más el pronóstico de nuestros cuadrados de la naturalidad. Así, por ejemplo, un sistema simple para entrar en una posición larga buscará asegurar que el precio de arbitraje del tercer par, en nuestro caso EURUSD, sea mayor que el precio cotizado actual y el pronóstico también sea de crecimiento del precio. Recordemos que el precio de arbitraje del par EURUSD en nuestro caso se obtendrá de la forma siguiente:
EURJPY / USDJPY
La incorporación de un sistema de este tipo al que teníamos en el escenario anterior provocará inevitablemente una disminución en el número de transacciones desde el momento de la confirmación. Para cada señal se requerirá un precio de arbitraje más alto o más bajo para posiciones largas y cortas, respectivamente. Trabajar con la clase de señal experta para crear una ejemplar de la clase que codifique esto será el enfoque preferido, y como el soporte para múltiples divisas en las clases del wizard MQL5 aún no es tan sólido, solo podremos mencionarlo aquí y sugerir al lector que modifique una clase de expertos como la anterior, o que pruebe un enfoque diferente que le permita probar este enfoque multidivisa con los expertos reunidos por el wizard.
Repito que probar ideas con la ayuda de asesores creados por wizards en MQL5 nos permite no solo armar algo con menos código, sino también combinar otras señales de salida con aquello en lo que estamos trabajando y ver si hay algún peso relativo que se adapte a nuestros propósitos. Entonces, por ejemplo, si en lugar del script incluido al final, pudiéramos implementar múltiples divisas y proporcionar un archivo de señal viable, entonces este archivo podría combinarse con otros archivos de señal de la biblioteca (como Awesome Oscillator, RSI, etc.) o incluso con otro archivo de señales personalizado para desarrollar un nuevo sistema comercial con resultados más significativos o equilibrados que un solo archivo de señales.
El método de inducción de cuadrados de la naturalidad, además de la obtención potencial de un archivo de señal, se puede utilizar para aumentar la eficiencia de la gestión de riesgos y la optimización del portafolio si, en lugar de un archivo de señal, se codifica un ejemplar personalizado de la clase expert money. Con este enfoque, aunque rudimentario, podríamos, dentro de ciertas limitaciones, ubicar nuestras posiciones en proporción a la magnitud del movimiento de precios previsto.
Conclusión:
Para resumir las principales conclusiones de este artículo, analizaremos cómo los cuadrados de la naturalidad, cuando se extienden por inducción, simplifican el diseño y ahorran recursos computacionales al clasificar los datos y, en consecuencia, pronosticar el futuro.
Una previsión precisa de las series nunca debería ser el único y último objetivo de un sistema comercial. Muchos métodos comerciales producen constantemente beneficios con pequeños porcentajes de ganancia, por lo que nuestra incapacidad para probar estas ideas como una clase de señales expertas resulta desalentadora y claramente hace que los resultados obtenidos aquí no sean concluyentes con respecto al papel y el potencial de la inducción.
Por ello, animamos a los lectores a probar más a fondo el código adjunto en entornos que proporcionen soporte multidivisa a los asesores para sacar conclusiones más precisas sobre qué retrasos de inducción funcionan y cuáles no.
Enlaces:
Wikipedia, según los enlaces generales del artículo.
Aplicación: Snippets de código MQL5
Adjuntamos un script (ct_19_r1.mq5). Para ejecutarlo deberá compilarlo en el IDE y luego adjuntar su archivo *.ex5 al gráfico en el terminal MetaTrader 5. Podrá ejecutarlo con diferentes configuraciones y diferentes pares de arbitraje, además de los ofrecidos por defecto. El segundo archivo adjunto muestra algunas de las clases teóricas recogidas en esta etapa de la serie. Como siempre, debería estar en la carpeta include.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13273
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso