
MQL5の圏論(第19回):自然性の正方形の帰納法
はじめに
圏論の離散データの分類への応用について、これらの連載を通して取り上げてきました。また、取引アルゴリズム(主にトレーリングストップを管理するものだが、エントリシグナルやポジションサイジングを扱うものもある)が、どのようにエキスパートアドバイザー(EA)にシームレスに組み込まれ、その概念のいくつかを実装できるかを、多くの例を挙げて紹介してきました。IDEのMQL5ウィザードは、テスト可能なシステムを構築するために、すべての共有ソースコードをウィザードで組み立てる必要があるため、これに役立っています。
今回は、前回紹介した帰納法の概念である自然性の正方形をどのように活用するかに焦点を当てます。裁定取引に連動可能な3つのFXペアを用いて、その潜在的な適用可能性を示します。そのペアのエントリシグナルアルゴリズムを開発できるかどうかを評価する目的で、いずれかのペアの価格変動データを分類します。
自然性の正方形は、自然変換を可換図式に拡張したものです。そのため、2つ以上の関手を持つ別々の圏がある場合、終域の圏にある2つ以上のオブジェクト間の関係を評価し、この分析を他の類似の圏との関係だけでなく、オブジェクトが時系列にある場合、観察対象の圏内での予測にも使用することができます。
セットアップを理解する
この記事で取り上げる2つの圏は、その間に2つの 関手を持つという点で、前回の記事で考えたものと似た構造を持ちます。しかし、これが主な類似点になります。この場合、両方の圏に複数のオブジェクトがありますが、前の例では始域に2つのオブジェクトがあり、終域には4つのオブジェクトしかありませんでした。
つまり、単一の時系列を特徴とする始域では、基本的にこの時系列の各価格ポイントをオブジェクトとして表現しています。これらの「オブジェクト」は、スクリプトが接続されているチャートの時間枠に単純にインクリメントする射によって、時系列にリンクされます。加えて、ここでは時系列を扱っています。つまり、圏は非拘束であり、基数を持ちません。繰り返しになりますが、この連載で焦点をあててきたように、圏やオブジェクトの全体的なサイズや内容そのものに興味があるのではなく、これらのオブジェクトからの射、より具体的には関手に興味があるのです。
終域には、他の2つのFXペアの2つの価格時系列があります。三角裁定取引には、少なくとも3つのFXペアが必要であることを思い出してください。もっと多くてもよいですが、ここでは実装を比較的シンプルに保つために最小限のものを使っています。したがって、始域の圏には、最初のペアであるUSDJPYの価格系列があります。価格系列として終域の圏に含まれる他の2つのペアは、EURJPYとEURUSDです。
2番目の圏の価格帯「オブジェクト」を結ぶ射は、特定の系列内でのみ存在します。開始時には各系列のオブジェクトをリンクしていないためです。
自然性の正方形と帰納法
圏論における自然性の正方形という概念は、交換法則を強調します。これは、前回の記事では分類を検証する手段として用いられました。終域の圏の4つのオブジェクトを表した下の図を考えてみましょう。
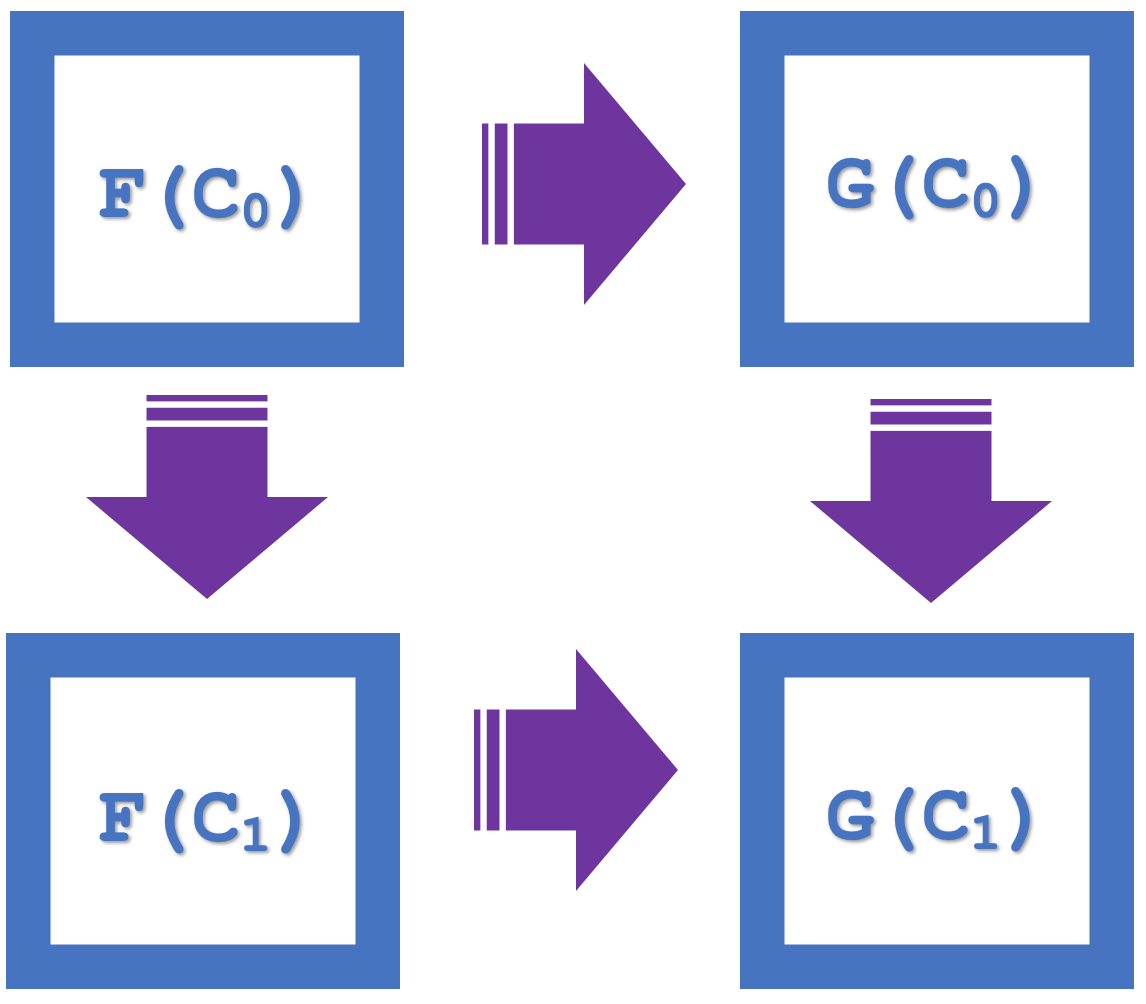
F(C0)からG(C0)、その後G(C1)への変換が存在することがわかります。これは、F(C0)からF(C1)、その後G(C1)への変換と同等です。
この記事で紹介する帰納法の概念は、設計を簡素化し、計算資源を節約する、複数の正方形の系列上で可換でする能力を強調しています。n個の正方形を並べた下図を考えてみましょう。
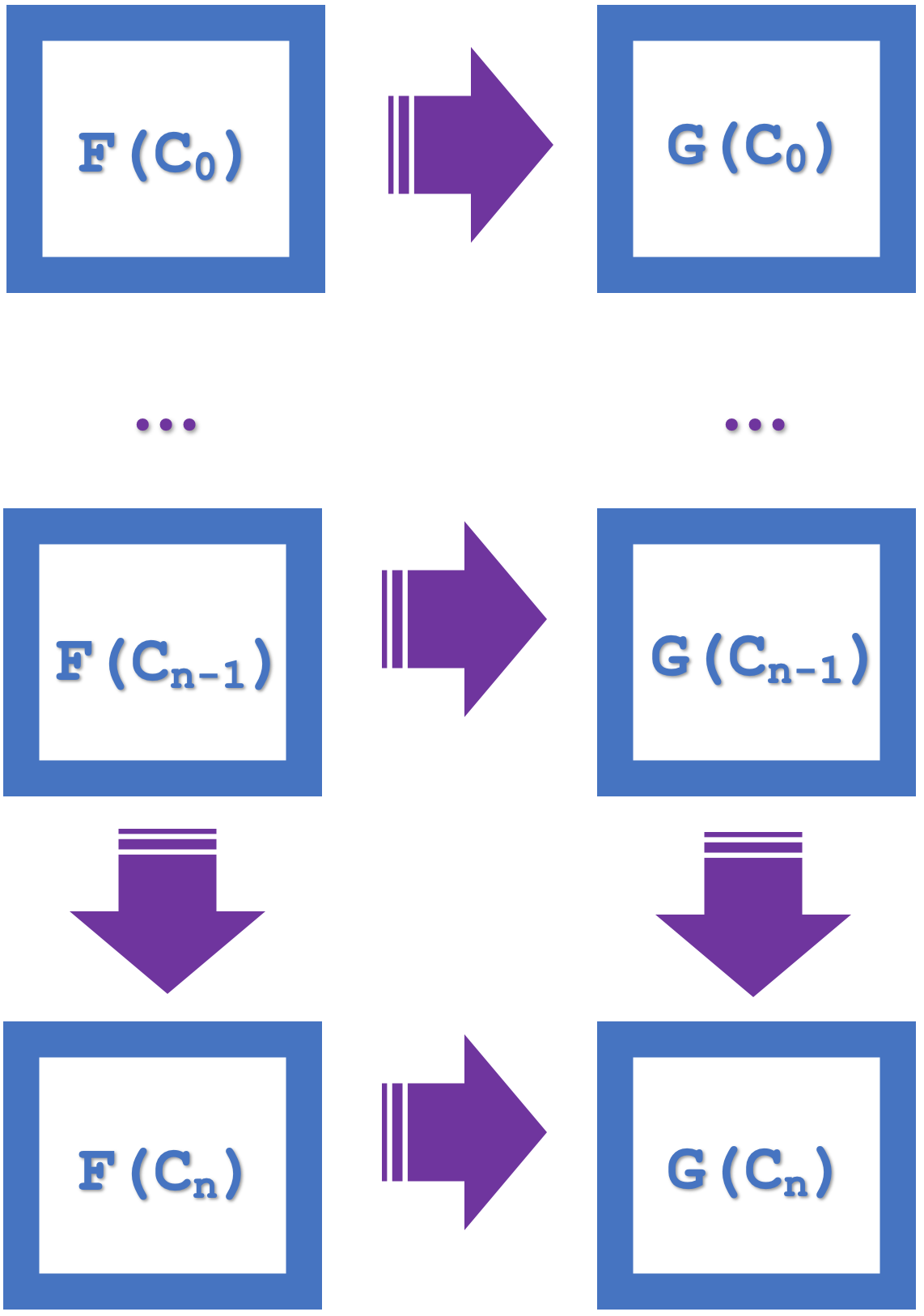
小さな自然性の正方形が可換であるなら、大きな長方形も同様に可換であることになります。このより大きな可換性は、n間隔での射と関手を含意します。したがって、この2つの関手は、両方ともUSDJPY系列からのものですが、EURJPYとEURUSDの異なる系列に接続します。従って、自然変換はEURJPYからEURUSDになります。前回の記事と同様に、分類のために自然性の正方形を使用しているので、私たちの予測は自然変換の終域のものとなり、これはEURUSDです。帰納法を使えば、前回のように1つのバーだけでなく、複数のバーでこれらの予測を見ることができます。前回の記事で、複数のバーを予測することは、採用しなければならないランダム決定森が多いことから、計算集約的でした。帰納法を使えば、nバー遅れで分類を始めることができます。
これらの自然性の正方形を、統合された1つの長方形として視覚的に表現したのが以下の図です。
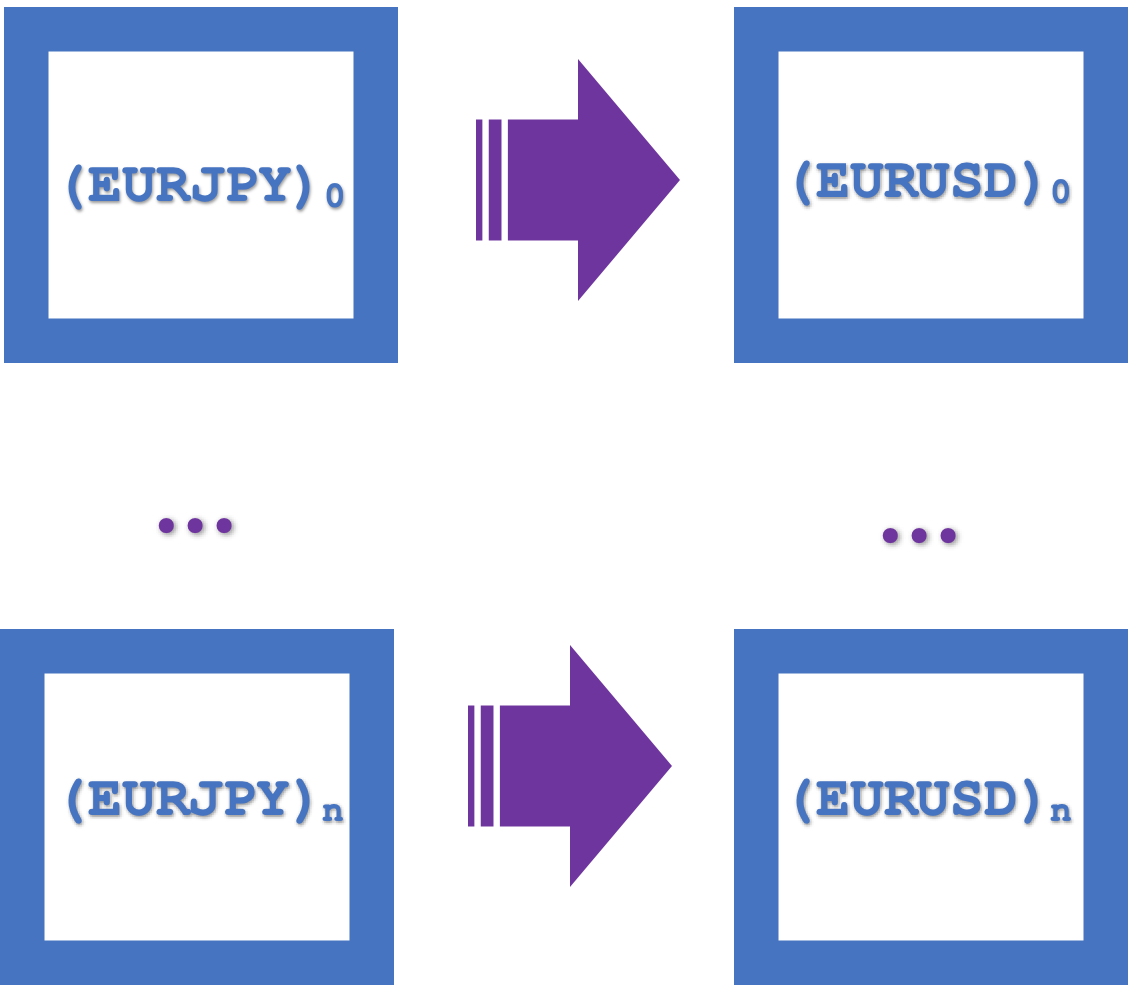
関手の役割
関手についてはすでに紹介したので、この段落では、この自然性の正方形でどのように適用するかを強調します。前回の記事では、 関手の写像を定義するために多層パーセプトロンを使いましたが、今回は同じ目的でランダム決定森を使うことにします。
ランダムフォレストは、複数の学習方法(森)を用いて予測を改善する分類器です。多層パーセプトロン(MLP)と同様、比較的複雑で、アンサンブル学習法と呼ばれることも多いです。私たちの目的のためにこれを第一原理から実装するのは面倒すぎるので、Alglibにすでに実装クラスがあるのは良いことです。これは、MQL5ライブラリの「Include\Math」フォルダにあります。
そのため、ランダム決定森(RDF)による写像は、フォレストのサイズを設定し、さまざまな木と森のそれぞれの枝に重みを割り当てることで定義されます。RDFをわかりやすく説明すると、RDFは小さな意思決定者のチームであり、各決定者はデータセットを見て選択をする方法を知っている木です。全員が同じ質問(データ)を受け、それぞれが答え(決定)を出します。全チームが選択を終えると、最も気に入った決定を選ぶために投票をおこないます。このプロセスのよいところは、すべてのチーム(木)に同じデータが与えられたにもかかわらず、ランダムにサンプリングしたため、それぞれが異なる部分から学んだということです。そこからの決定は、しばしばスマートで正確です。
自分なりに一から実装してみましたが、このアルゴリズムは簡単に説明できるものの、かなり複雑です。Alglibでこれをおこなうには、いくつかの形式があります。その中で最も単純なものは、森の数と、木の構築に使用される訓練セットの割合を設定するRと呼ばれるdoubleタイプの入力パラメータという2つの入力を主に必要とするだけです。私たちの目的では、これを使うことにします。独立変数の数や従属変数(別名分類子)の数といった要件は他にもありますが、これらはほとんどの機械学習モデルに共通するものです。
MQL5スクリプトの実装
これまで、この連載で紹介するすべてのコードをMQL5のIDEを使って厳密にコーディングしてきました。カスタム指標、EA、MQL5スクリプト以外にも、このIDE内でサービス、ライブラリ、データベース、さらにはPythonスクリプトをコーディング/開発できることを強調しておくと役立つでしょう。
この記事では、帰納法における自然性の正方形による分類を実証するためのスクリプトを使うだけです。単なるスクリプトではなく、EAのシグナルクラスのインスタンスがあれば理想的です。ただし、多通貨シグナクラスの実装は、可能ではありますが、この記事のように実現可能ではありません。したがって、最適化されていない設定で、EURUSDの終値の予想と実際の変化を出力し、その結果を使用して、帰納法と自然性の正方形が予測をおこなう上で有用であるという命題を支持または反論します。
そこでスクリプトは、一連のUSDJPY終値の変化を保持するために、始域の圏のインスタンスを作成することから始めます。この圏は訓練に使用される可能性があり、そのようにラベル付けされています。この 関手を使った訓練では、 関手から終域の圏(2つの関手)への重みが設定されます。これらの重み付けは(前回の記事で述べたように)ここでの予想にとって重要なものではありませんが、見通しのために触れておきます。
//create domain series (USDJPY-rates) in first category for training CCategory _c_a_train;_c_a_train.Let(); int _a_size=GetObject(_c_a_train,__currency_a,__training_start,__training_stop);
次に、すでに述べたように2つの時系列、EURJPYとEURUSDを特徴とする終域の圏のインスタンスを作成します。各価格帯はオブジェクトを表すので、各系列のオブジェクトを順次追加することで、圏内の2つの系列を「保持」するように注意する必要があります。それらをbとcと呼びます。
//create 2 series (EURJPY and EURUSD rates) in second category for training CCategory _c_bc_train;_c_bc_train.Let(); int _b_trains=GetObject(_c_bc_train,__currency_b,__training_start,__training_stop); int _c_trains=GetObject(_c_bc_train,__currency_c,__training_start,__training_stop);
前回の記事のように、予想は、自然性の正方形を形成する終域のオブジェクトを中心におこなうことになります。各系列をつなぐ射と、系列間のオブジェクトをつなぐ自然変換が、RDFとして写像するものです。
スクリプトには帰納法適用回数の入力パラメータがあります。これは、正方形を拡大し、次の1バーを超える予測をおこなう方法です。つまり、n回帰納法を適用した自然性の正方形は、角A、B、C、Dを持つ1つの正方形を形成し、ABとCDが変換となり、ACとBDが射となります。
この写像を実装する際、MLPとRDFの両方をそれぞれ変換と射に使用することも可能です。MLPがどのように組み込まれるかはすでに見たとおりなので、読者に探求してもらうことにしましょう。次に、RDFの学習モデルをデータで満たす必要がありますが、これは行列でおこないます。ABからCDへの各写像に対応する4つのRDFは、それぞれ独自の行列を持ち、以下に示すコードによって入力されます。
//create natural transformation, by induction across, n squares..., cpi to pmi //mapping by random forests int _training_size=fmin(_c_trains,_b_trains); int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CDFReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(_training_size,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(_training_size,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(_training_size,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(_training_size,1+1); double _a=0.0,_b=0.0,_c=0.0,_d=0.0; CElement<string> _e_a,_e_b,_e_c,_e_d; string _s_a="",_s_b="",_s_c="",_s_d=""; for(int i=0;i<_training_size-__n_inductions;i++) { _s_a="";_e_a.Let();_c_bc_train.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); _s_b="";_e_b.Let();_c_bc_train.domain[i+_b_trains].Get(0,_e_b);_e_b.Get(1,_s_b);_b=StringToDouble(_s_b); _s_c="";_e_c.Let();_c_bc_train.domain[i+__n_inductions].Get(0,_e_c);_e_c.Get(1,_s_c);_c=StringToDouble(_s_c); _s_d="";_e_d.Let();_c_bc_train.domain[i+_b_trains+__n_inductions].Get(0,_e_d);_e_d.Get(1,_s_d);_d=StringToDouble(_s_d); if(i<_training_size-__n_inductions) { _xy_ab[i].Set(0,_a); _xy_ab[i].Set(1,_b); _xy_bd[i].Set(0,_b); _xy_bd[i].Set(1,_d); _xy_ac[i].Set(0,_a); _xy_ac[i].Set(1,_c); _xy_cd[i].Set(0,_c); _xy_cd[i].Set(1,_d); } }
データセットの準備ができたら、各RDFのモデルインスタンスを宣言し、それぞれの学習を進めることができます。これは以下のようにおこなわれます。
CDForest _forest; CDecisionForest _rdf_ab,_rdf_cd; CDecisionForest _rdf_ac,_rdf_bd; _forest.DFBuildRandomDecisionForest(_xy_ab,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ab,_rdf_ab,_report_ab); _forest.DFBuildRandomDecisionForest(_xy_bd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_bd,_rdf_bd,_report_bd); _forest.DFBuildRandomDecisionForest(_xy_ac,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ac,_rdf_ac,_report_ac); _forest.DFBuildRandomDecisionForest(_xy_cd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_cd,_rdf_cd,_report_cd);
infoパラメータの整数値で評価する必要がある各訓練からの出力は、MLPの場合と同様、正でなければなりません。すべてのinfoパラメータがプラスであれば、ウォークフォワードテストに進むことができます。
スクリプトの入力パラメータには、訓練開始日、訓練停止日、テスト停止日の3つの日付が含まれていることに注意してください。これらの値を使用する前に、私が記述した順序で昇順になっていることを確認するために検証するのが理想的です。また、訓練の終了日がテストの開始日としても機能するため、テスト開始日が欠けています。そこで、以下のコードでフォワードテストを実施します。
// if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { //create 2 objects (cpi and pmi) in second category for testing CCategory _c_cp_test;_c_cp_test.Let(); int _b_test=GetObject(_c_cp_test,__currency_b,__training_stop,__testing_stop); ... ... MqlRates _rates[]; ArraySetAsSeries(_rates,true); if(CopyRates(__currency_c,Period(), 0, _testing_size+__n_inductions+1, _rates)>=_testing_size+__n_inductions+1) { ArraySetAsSeries(_rates,true); for(int i=__n_inductions+_testing_size;i>__n_inductions;i--) { _s_a="";_e_a.Let();_c_cp_test.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); double _x_ab[],_y_ab[]; ArrayResize(_x_ab,1); ArrayResize(_y_ab,1); ArrayInitialize(_x_ab,0.0); ArrayInitialize(_y_ab,0.0); // _x_ab[0]=_a; _forest.DFProcess(_rdf_ab,_x_ab,_y_ab); ... double _x_cd[],_y_cd[]; ArrayResize(_x_cd,1); ArrayResize(_y_cd,1); ArrayInitialize(_x_cd,0.0); ArrayInitialize(_y_cd,0.0); // _x_cd[0]=_y_ac[0]; _forest.DFProcess(_rdf_cd,_x_cd,_y_cd); double _c_forecast=0.0; if((_y_bd[0]>0.0 && _y_cd[0]>0.0)||(_y_bd[0]<0.0 && _y_cd[0]<0.0))//abd agrees with acd on currency c change { _c_forecast=0.5*(_y_bd[0]+_y_cd[0]); } double _c_actual=_rates[i-__n_inductions].close-_rates[i].close; if((_c_forecast>0.0 && _c_actual>0.0)||(_c_forecast<0.0 && _c_actual<0.0)){ _strict_match++; } else if((_c_forecast>=0.0 && _c_actual>=0.0)||(_c_forecast<=0.0 && _c_actual<=0.0)){ _generic_match++; } else { _miss++; } } // ... } }
興味があるのは正方形でDとして表されるEURUSDへの変更への予測であることを思い出してください。フォワードテストでの予測値を確認する際、方向が厳密に一致する値、ゼロが含まれていることから方向が一致する可能性がある値、そして最後に一致しなかった値も記録します。これはすべて、上に示したコードに収められています。
このスクリプトを要約してみます。まず訓練の圏を宣言します。この圏はデータの前処理と訓練に絶対に必要です。裁定取引に使用するFXペアはUSDJPY、EURJPY、EURUSDです。訓練停止日とテスト停止日で定義されるテストデータで予測をおこなうために、系列内の射として機能するRDFと系列間の自然変換を使用して、終域のオブジェクト間で写像をおこないます。
結果と分析
上記の共有ソースを実装したスクリプト(この記事の最後に添付)を実行して1で帰納法を適用すると、USDJPYの日足チャートで以下のログが得られます。
2023.09.01 13:39:14.500 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 45, strict matches: 61, & generic matches: 166, for strict pct (excl. generic): 0.58, & generic pct: 0.83, with inductions at: 1
しかし、2に増やすと、こうなります。
2023.09.01 13:39:55.073 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 56, strict matches: 63, & generic matches: 153, for strict pct (excl. generic): 0.53, & generic pct: 0.79, with inductions at: 2
厳密な一致は不一致よりも多いため、わずかな減少ではありますが、それでもプラスです。一致と不一致に対する適用回数のログを作成することができます。これをグラフにすると以下のようになります。
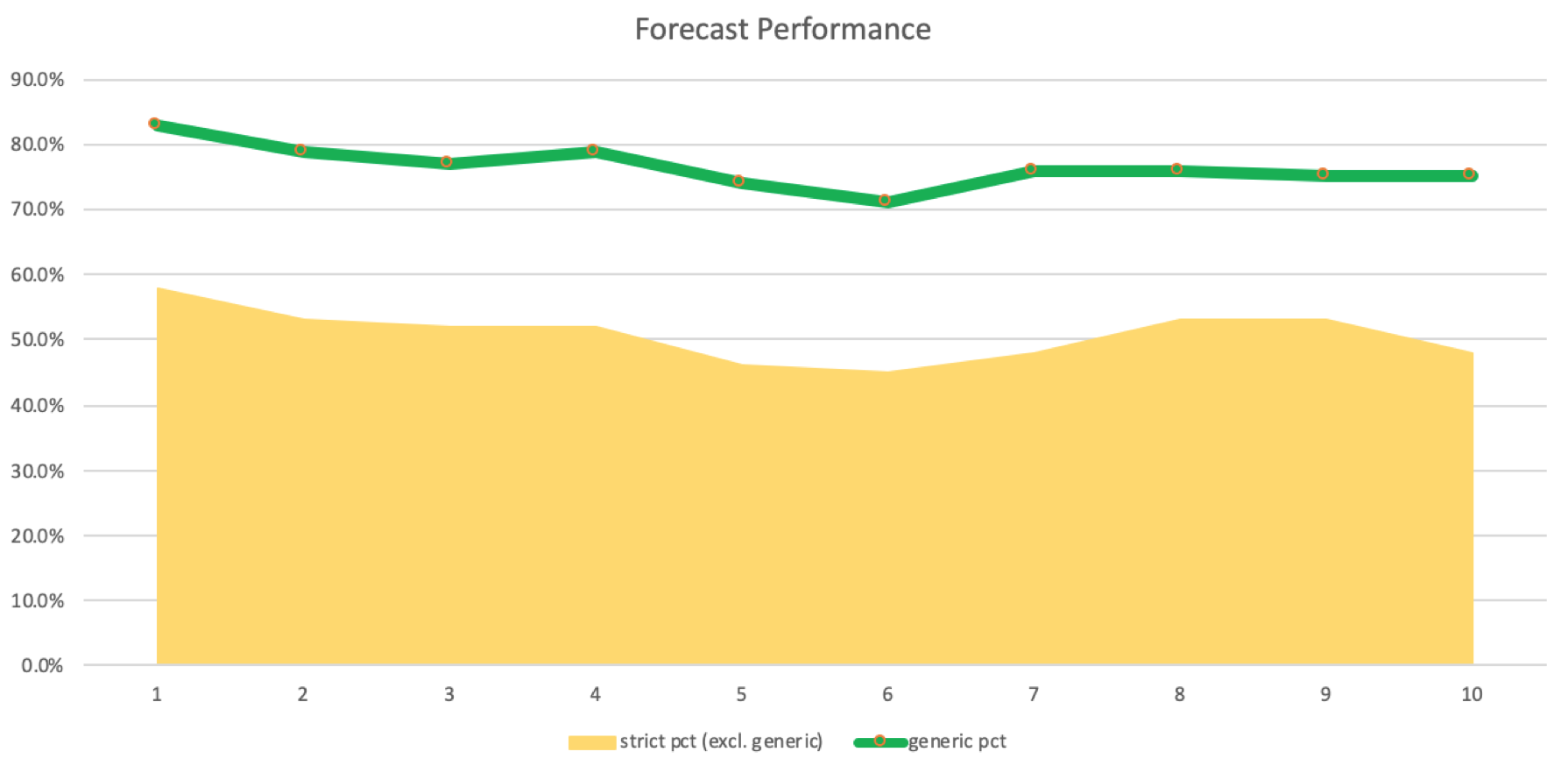
これらの予測とログに記録された一致の精度は、パフォーマンスを証明または反証するために、さまざまな帰納法適用のラグを伴う実行を行う実際の取引システムで確認する必要があります。つまり、5から8までの帰納法適用のラグを使用することが私たちのシステムにとって理想的であると結論づけることはできません。多通貨に簡単に対応できるEAのセットアップでテストすれば、検証できるでしょう。
この実装で直面した主な課題は、MQL5ウィザードEAのEAシグナルクラスとしてテストできないことです。ウィザードアセンブリはデフォルトで、1つの銘柄(チャート銘柄)に対してのみ指標と価格バッファを開始します。これを回避して複数の銘柄に対応することは可能ですが、CExpertクラスを継承したカスタムクラスを作成し、いくつかの変更を加える必要があります。この記事で書くには長すぎると思いますので、ご自分で調べてください。
従来の方法との比較
移動平均線のような単純な指標を使う「従来」の手法と比べると、私たちの自然性正方形帰納法は、その説明を読むだけなら複雑で、おそらく入り組んでいるように見えます。しかし、オンラインやMQL5のライブラリで利用できるコードライブラリ(Alglibなど)の多さを考えると、一見複雑に見えるアプローチやアイデアが、200行以下で簡単にコード化できることを読者が感じ取ってくれることを願っています。シームレスな方法で新しいアイデアを探求し、採用し、あるいは反論できるようにします。MQL5のIDEは、学ぶことが好きな人にとって楽園です。
このシステムの特筆すべき長所は、その適応性と潜在的な精度です。
実世界での応用
アービトラージペアを使った予測システムの実用的な応用を検討するとすれば、3つのペアの中でアービトラージの機会を利用しようという文脈の中ででしょう。裁定取引の機会が存在するとすれば、それは、3つのペアのうちの1つが、そのペアのスプレッドよりもギャップが大きくなるような十分なミスプライスになっているからです。このようなチャンスは何年か前まではありましたが、何年もかけてほとんどのブローカーで待ち時間が短縮されたため、かなり少なくなっています。実際、一部のブローカーはこの行為を禁じています。
したがって、裁定取引をおこなうとすれば、スプレッドを「見過ごし」、代わりに生価格と自然性の正方形の予測を見るという擬似的な形になるでしょう。したがって、例えば買いを出す単純なシステムでは、3つ目のペア(この例ではEURUSD)のアービトラージ価格が現在の気配値を上回り、予測も価格が上昇することに注目します。EURUSDのアービトラージ価格を要約すると、ここでのケースでは次のようになります。
EURJPY / USDJPY
このようなシステムを上記のスクリプトから得たものと組み入れると、必然的に取引回数が減ります。各シグナルは、売買のアービトラージ価格がそれぞれ高いか低いかによって要求されるからです。これをコード化するクラスのインスタンスを生成するためにEAシグナルクラスで作業することは好ましいアプローチです。MQL5ウィザードクラス内の多通貨サポートはまだそれほど堅牢でないので、ここではそれを言及して読者に上記のようにEAクラスを修正してもらうか、ウィザードで組み立てられたEAでこの多通貨アプローチをテストできる別のアプローチを試してもらうしかありません。
MQL5ウィザードで作られたEAを使って繰り返しアイデアをテストすると、単に少ないコードで何かをまとめることができるだけではなく、私たちが取り組んでいることに他の終了シグナルを組み合わせ結果目標を満たすシグナル間の相対的な重み付けがあるかどうかを確認できるようになります。そのため、例えば、最後に添付したスクリプトを提供するのではなく、多通貨を実装し、実行可能なシグナルファイルを提供できた場合、このファイルを他のライブラリのシグナルファイル(Awesome Oscillator、RSIなど)、あるいは読者による別のカスタムシグナルファイルと組み合わせることで、単一のシグナルファイルよりも意味のある、あるいはバランスの取れた結果を持つ新しい取引システムを開発することができます。
自然性の正方形に帰納法を使うアプローチは、シグナルファイルを提供する可能性があるほか、シグナルファイルの代わりにEAマネークラスのカスタムインスタンスをコード化すれば、リスク管理とポートフォリオの最適化を強化するためにも使用できます。このアプローチでは、初歩的ではありますが、予想される値動きの大きさに比例してポジションを大きくすることができます。
結論
この記事から得られた重要なことを要約すると、帰納法によって拡張された自然性の正方形が、データを分類する際にいかに設計を単純化し、計算リソースを節約し、その結果、将来予測が可能になるかがわかったということです。
正確な系列予測は、決して取引システムの唯一無二の目的であってはなりません。そのため、EAシグナルクラスとしてこれらのアイデアをテストすることができないのは残念であり、帰納法の役割と可能性について、ここでの結果は明らかに結論が出ません。
読者には、どのような帰納法のラグが機能し、何が機能しないかについてより良い結論を得るために、EAが多通貨をサポートできる設定で、添付のコードをさらにテストすることが推奨されます。
参照文献
記事中のウィキペディアの共有リンクの通り。
付録MQL5コードスニペット
添付のスクリプト(ct_19_r1.mq5)を実行するには、IDEでコンパイルし、MetaTrader 5ターミナルのチャートに*.ex5ファイルを添付する必要があります。複数の設定と、デフォルトで提供されている以外の異なる裁定取引ペアで実行することができます。2つ目の添付ファイルは、この系列を通して組み立てられたパート圏論のクラスを参照するものです。いつものように、インクルードフォルダーに入れてください。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13273
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索