
金融時系列における共形予測の考察
はじめに
MAPIE (Model agnostic prediction interval estimator) は、機械学習モデルにおける不確実性の定量化とリスク管理のために設計されたオープンソースのPythonライブラリです。これは、回帰問題に対する予測区間や、分類および時系列に対する予測集合を計算することを可能にします。この不確実性評価は、特別な「キャリブレーションセット」のデータに基づいて実行されます。
MAPIEの主要な利点の一つは、そのモデル非依存的な性質です。これは、このライブラリがscikit-learn APIと互換性のあるあらゆるモデルで使用できることを意味し、適切なラッパーを介することでTensorFlowやPyTorchを用いて開発されたモデルも含まれます。この特性は、既存の分析パイプラインへの統合を大幅に簡素化します。というのも、トレーダーは通常、対象資産クラスや取引戦略に応じて、伝統的な統計的アプローチから複雑なニューラルネットワークまで、さまざまな機械学習モデルを利用しているからです。不確実性の定量化を組み込むために、実績のあるモデルをシームレスに利用できる能力は、実装コストを大幅に削減し、導入を加速させます。これは、特に変化の激しい金融環境において価値があります。
このライブラリはscikit-learn-contribエコシステムの一部であり、共形予測(CP, conformal prediction)と分布非依存推論(distribution-free inference)に基づいています。これは、モデルや用途に依存しない査読済みアルゴリズムを実装しており、データやモデルに対する仮定を最小限に抑えながら理論的保証を提供します。標準的な分類を超えて、MAPIEは、多クラス分類やコンピュータビジョンにおける画像セグメンテーションといった、より複雑なタスクに対するリスク制御も可能です。その際、再現率や適合率などの指標について確率的保証を提供します。
リスクを制御し、確率的保証を提供する能力により、MAPIEは単なる不確実性定量化ツールではなく、包括的なリスク管理フレームワークとして位置付けられます。金融においては、点予測だけでは十分ではありません。なぜなら、それは信頼度や潜在的な誤差の水準を伝えないからです。95%のような被覆保証を備えた予測集合を提供することは、定量化可能なリスクへと直接変換されます。これにより、リスク管理者は明示的なリスク許容度を設定できます。
たとえば、モデルが買いシグナルを生成したとしても、共形予測が高い誤差確率を示している場合、リスク管理者はポジションを縮小する、あるいは取引を見送るという判断を下すことができます。これにより潜在的損失を直接制御できます。これは、単なる予測精度を超えて、不確実性の下でのより堅牢な意思決定を支援します。
共形予測の基本原理:分布に依存しないモデル非依存の保証
共形予測は、分類問題に対して予測集合を、回帰問題に対して予測区間を生成する生成する統計的フレームワークであり、所定の被覆保証を与えます。たとえば、90%の信頼水準においては、真の結果が少なくとも90%の割合で予測集合または予測区間の中に含まれます。
CPの主要な利点は、その「分布非依存」という性質です。この手法は、データの基礎となる分布やモデル自体について厳格な仮定に依存しません。唯一の基本的な仮定は、データ(学習データとテストデータ)が交換可能であることです。つまり、それらが同じ分布から得られており、その順序が重要ではないということです。
この仮定は、独立同分布(i.i.d.)の仮定よりも弱く、多くの場合、実際の応用において正当化することができます。被覆率を近似的にしか提供できない従来の予測区間とは異なり、CPは有限標本に対する保証を提供し、限られたデータしかない場合でも指定された被覆率水準が達成されることを保証します。
共形予測の分布非依存保証は、金融モデリングにおける根本的な問題に直接対処します。金融データは、正規分布に従わないことで知られており、裾の重い分布を示し、さらに分散一定性や増分の独立性といった典型的な統計的仮定にしばしば違反します。
従来の予測区間は、残差の正規性などの仮定に依存することが多く、そのため近似的な被覆率しか提供できません。そのような仮定なしに保証された被覆率を提供できるCPの能力は、分布の誤指定が重大なリスクの過小評価につながる可能性がある金融アプリケーションにおいて、本質的により堅牢で信頼できるものにします。つまり、報告される信頼水準は、現実の複雑な金融データセットにおいてより信頼できます。
共形予測は通常、学習済みの機械学習モデルを使用し、モデルが学習中に見ていないキャリブレーションデータセットを作成し、そのデータセット上で「適合度スコア(conformity scores)」を計算し、そのスコアの分位点を用いて予測集合を決定することを含みます。近似的な被覆率から有限標本における被覆保証への移行は、金融における機械学習モデルの規制およびリスク管理の状況を根本的に変化させます。
金融のような高リスク産業では、モデルはしばしば定量的な頑健性と誤差率の制御を実証する必要があります。これは、「90%の信頼」が漸近的な性質または近似に過ぎない可能性のある従来の統計手法とは異なります。クオンツトレーダーにとって、これは取引戦略やリスク資本配分を正当化するための、より確固とした基盤を提供します。
二値分類における予測集合と点予測
従来の二値分類モデルは、単一の予測ラベル(例:「Buy」または「Sell」)や確率スコア(例:「Buy」に対して0.8)を出力します。これらは点予測です。一方、共形予測は予測集合を提供します。これは、可能なクラスの部分集合です(例:{Buy}、{Sell}、{Buy, Sell})。この集合は、所与の信頼水準に対応する被覆確率で真のラベルを含むことが保証されています。
二値分類の場合、予測集合は次のようになります。
- 単一のクラス(例:{Buy}、{Sell})。これは高い信頼度を示します。
- 両方のクラス(例:{Buy, Sell})。これは不確実性または曖昧さを示します。
- 空集合{}(APSのような一部の手法を使用する場合にはあまり一般的ではなく、しばしば望ましくありません)。これは極端な不確実性、あるいはどのクラスも信頼度の閾値を満たしていないことを示します。
予測集合の「情報量」は、その大きさに反比例します。より小さい集合(たとえば単一クラスの集合)は、より大きい集合(たとえば両方のクラスを含む集合)よりも多くの情報を提供します。単一の点予測ではなく集合を明示的に出力することは、金融における二値分類の意思決定を根本的に変えます。単純なYes/NoやBuy/Sellシグナルではなく、予測集合はモデルの信頼度を直接示します。
{Buy}のような単一クラスの集合は強いシグナルを示唆する一方、{Buy, Sell}のような二クラスの集合は大きな曖昧さを示します。これにより、より洗練された取引戦略が可能になります。すなわち、高い信頼度を持つシグナルに対しては取引をおこない、曖昧なシグナルに対しては取引を見送る、ポジションサイズを縮小する、あるいは追加の情報を求めることができます。これは、不確実性を実際の金融上の意思決定へ直接組み込むための仕組みです。
予測集合の「情報量」は、金融取引における効率性およびリスク許容度の直接的な尺度となります。広くて情報量の少ない予測集合(例:{Buy, Sell})がある取引に対して出力された場合、それはモデルが望ましい信頼水準において買いと売りを信頼性をもって区別できないことを意味します。クオンツアナリストにとって、これは修正すべき予測誤差ではなく、行動を控えるべき、あるいは最大限の慎重さをもって行動すべきことを示すシグナルです。これにより、動的なリスク管理が可能になります。すなわち、狭く信頼性の高い予測集合を持つ取引にはより多くの資本を配分し、広く不確実な予測集合を持つ取引については、取引を回避するかエクスポージャーを最小限に抑えることで資本を保全できます。これは取引戦略のリスクリワード特性の最適化に直接つながります。
理論的保証:周辺被覆率と条件付き被覆率
共形予測器(conformal predictors)は、その予測集合が、データ全体で平均したときに、与えられた信頼水準(1 - α)以上の被覆確率を持つという意味で、「自動的に妥当」です。この保証は、交換可能性仮定が満たされている限り、基礎となるモデルやデータ生成過程に依存せず成立します。この性質は周辺被覆率と呼ばれます。
周辺被覆率は保証されますが、それはあくまで平均的な指標です。条件付き妥当性のような、より厳密な概念では、特定のデータ特性(たとえば、クラスごと、オブジェクトごと、ラベルごと)に基づく被覆保証性を目指します。帰納的共形予測器(Inductive Conformal Predictors)は計算効率の高いバージョンで、主として無条件の被覆率を制御します。条件付き妥当性を達成するためには、多くの場合、手法の修正が必要になります。
周辺被覆率と条件付き被覆率の違いは、金融における二値分類、特に金融でよく見られる不均衡データセット(たとえば、「Buy」や「Sell」のシグナルよりも、「取引しない」あるいは「Hold」のシグナルがはるかに多い場合)において極めて重要です。
周辺被覆率は、平均的に見て予測の90%が正しいことを保証します。しかし、買いシグナルがまれである場合、モデルは売りシグナルに対して非常に高い精度を示しながら、買いシグナルに対しては低い性能しか持たなくても、90%の周辺被覆率を達成できてしまいます。買いシグナルが重要である場合、これは大きな機会損失や損失の発生につながる可能性があります。
条件付き被覆率、特にクラス別被覆率は、望ましい信頼水準が各クラスごとに個別に達成されることを保証します。これは、買い取引と売り取引の両方に対する予測の信頼性を確保し、取引戦略を損なう可能性のある体系的な偏りを防ぐうえで重要です。
Mondrian Conformal Predictionのような手法を用いて条件付き妥当性を目指すことは、金融アプリケーションにおける異なる結果クラス間の公平性と信頼性の問題に直接対処するものです。金融では、特定のクラスにおける予測誤差(たとえば、まれではあるが非常に利益率の高い「買い」の機会や、大きな損失を回避するために重要な「売り」の判断)は、より一般的な「取引なし」のケースにおける予測誤差と比べて、はるかに大きなコストを伴う可能性があります。
条件付き被覆を提供することで、このシステムは平均的な保証ではなく、取引の種類ごとに最低限の信頼性水準を保証します。これにより、異なる取引シグナルをより公平に扱うことが可能となり、また、さまざまな市場状況やまれな事象に対処するモデルの能力に対する信頼を高めることができます。これは、堅牢なアルゴリズム取引を実現するうえで不可欠です。
適合度スコア:共形予測の中核
適合度スコアは共形予測の中核であり、新しいデータ点がキャリブレーションデータと比較してどの程度「異常」であるか、あるいは「適合していない」かを定量化します。スコアリング関数に求められる唯一の要件は、スコアが高いほど、入力データとその仮定上のラベルとの適合度が低いことを表現することです。これらのスコアは、キャリブレーションセットから分位点(カットオフ値)を計算するために用いられ、その値が新しいテストデータに対する予測集合を定義します。
MAPIEはさまざまな適合度スコアを実装しています。これには、対称的なスコア(たとえば回帰におけるAbsolute Residual Score)や、非対称なスコア(たとえば回帰におけるGamma Score)が含まれます。これらは予測区間の境界がどのように計算されるかに影響を与えます。分類問題では、LAC、APS、RAPSなどの適合度スコア(あるいは非適合度スコア)が用いられます。
適合度評価の選択は、単なる技術的な詳細ではなく、予測集合の実用性および解釈可能性に影響を与える戦略的な意思決定です。異なる適合度スコア(例:LAC、APS)は、予測集合を生成する際に異なる振る舞いをもたらします。
たとえば、LACは不確実性が高い状況では空集合を生成することがあります。これは金融分野では望ましくない場合があります。なぜなら、何の指針も与えないからです。一方でAPSは、その設計上、常に何らかのもっともらしい結果の集合を提供するため、空集合を生成しません。つまり、スコアの選択が「望ましくない」サンプルをどのように表現するか、またシステムが常に有効な(たとえ曖昧であっても)回答を提供できるかどうかに直接影響します。クオンツトレーダーは、求める情報量とリスク許容度に合致する評価手法を選択すべきです。
「適合度」という概念は、データ駆動型モデルの予測という文脈において、「外れ値」や「異常な」観測値を識別することを可能にします。これは異常な市場状況の検出において非常に重要です。金融市場では、異常な価格変動、出来高の急増、あるいは予期しないニュースによって、過去のパターンから大きく逸脱したデータ点が発生することがあります。
新しい観測値に対して高い適合度スコアが算出された場合、それはその観測値がキャリブレーションデータで観測されたパターンに「適合していない」ことを示すシグナルとなります。これは市場の異常やレジーム転換に対する早期警告システムとして機能し、取引戦略の見直しや自動売買の一時停止を促すことができます。その結果、単なるモデル精度を超えた、重要なリスク管理ツールとして機能します。
分類における主要な適合度スコアの詳細な考察
MAPIEはさまざまな適合度スコアを提供しており、それぞれに独自の特徴と適用範囲があります。
- Least Ambiguous Set-valued Classifier (LAC)
- 計算: 適合度スコアは、「1 − 真のラベルに対するsoftmaxスコア」として定義されます。
- 特性:周辺被覆率を理論的に保証するシンプルなアプローチです。一般に、小さな予測集合を生成します。
- 適用性/制限:モデルの不確実性が高い場合(たとえば決定境界付近)には、空の予測集合を生成する傾向があります。金融分野では、空集合は実行可能な判断材料を提供しないため、これは問題となる可能性があります。
- Adaptive Prediction Sets (APS)
- 計算方法:適合度スコアは、各ラベルのsoftmaxスコアを高い順に並べ、真のラベルに到達するまで順次加算することで計算されます。
- 特性:LACにおける空集合の問題を克服します。予測集合は定義上、空になりません。また、周辺被覆率の保証性を提供します。
- 適用性:金融アプリケーションにおいては、空集合よりも、たとえ不確実であっても何らかの予測が得られる方が望ましいため、より堅牢な手法です。
- Regularized Adaptive Prediction Sets (RAPS)
- 計算方法:APSと類似していますが、予測集合の大きさを抑えるための正則化項を追加します。
- 特性:被覆保証性を維持しながら、予測集合のサイズを正則化することで、被覆率と効率性のバランスを取ることを目的としています。
- 適用性:予測集合のサイズ(有効性)が被覆率と同じくらい重要な場面で有用です。取引においては、予測集合が小さいほど情報量が多く、有効性が高いためです。
- Mondrian Conformal Prediction
- 計算方法:この手法では、クラスごとに適合度スコアの分位点を個別に計算します。これにより、クラスごとに異なる閾値を用いた予測集合を構成できます。
- 特性:各クラスに対して個別に条件付き被覆(1 - α)を提供します。これは、不均衡な多クラス問題や二値分類問題において極めて重要です。
- 適用性:クラス不均衡(たとえば、「Hold」や「Sell」に比べて「Buy」シグナルが少ない場合)が存在したり、クラスごとに許容される誤差が異なったりする金融の二値分類(Buy/Sell)に特に推奨されます。これにより、Sellシグナルの性能に関係なく、Buyシグナルの信頼性が保証されます。
LACからAPSやRAPSへの適合度スコアの発展は、実世界のアプリケーションにおいて有効かつ情報量の多い予測集合が求められるという実務的な要請を反映しています。LACは概念的には単純ですが、空集合を生成しやすいという点は金融分野において重大な欠点です。Buy/Sellの判断に対して空の予測集合が返された場合、それは何の指針も与えず、意思決定プロセスを事実上停止させてしまいます。APSおよびRAPSは、空でない予測集合を保証することにより、高い不確実性の下であってもモデルが何らかのもっともらしい結果を提示することを保証します。これにより、完全に判断を停止するのではなく、「Hold」あるいは「再評価」といったデフォルトの意思決定をおこなうことが可能になります。これは、継続的な運用とリスク管理を実現するうえで重要です。
Mondrian法は、金融における二値分類に対する重要な進歩であり、クラス不均衡の問題と、誤分類による影響の非対称性という問題に直接対処します。Buy/Sellのシナリオでは、「Buy」シグナルはまれである一方で非常に高い利益をもたらす可能性があり、「Sell」シグナルはより頻繁に発生するものの、個々の重要性は比較的小さい場合があります。標準的な共形予測手法は周辺被覆率しか保証しないため、全体平均の被覆率が達成されていても、まれな「Buy」クラスに対する被覆率が期待より低くなる可能性があります。Mondrian法はクラスごとの分位点を計算できるため、クラスごとに望ましい信頼水準が維持されることを保証します。
これは、重要でまれな事象(たとえば強力な買いシグナル)に対する体系的な被覆率不足を防ぐうえで極めて重要であり、その結果として、より信頼性が高く、潜在的により収益性の高い取引戦略につながります。つまり、モデルの頑健性が単なる平均的な水準で確保されるのではなく、検討対象となる特定の取引タイプごとに維持されることを保証するのです。
分類における共形予測集合の形成手順
このプロセスを段階ごとに見ていきましょう。
- 非適合度の尺度(または「スコアリング関数」)の選択これは極めて重要です。分類では、事前に学習された分類器(たとえばロジスティック回帰、サポートベクターマシン、ニューラルネットワーク、ランダムフォレストなど)の出力がよく利用されます。入力xに対する分類器の出力をf(x)とします。f(x)が確率(たとえばsoftmax層の出力)を返す場合、データ点(xi ,yi)に対する適切な非適合度の尺度として次のものが考えられます。
- 1 - 真のクラスの予測確率:αi =1−P^(yi∣xi)。ここで、P^(yi∣xi)は、入力データxiに対する真のラベルyiの予測確率です。αiが小さい場合は、モデルが真のクラスに対して高い確信を持っていることを意味し、「適合」していることを示します。一方、αiが大きい場合は、モデルの確信度が低く、「非適合」を示します。
- Softmax温度スケーリングに基づく方法:モデルがロジットを出力する場合には、softmaxを適用して確率を得ることができます。その場合も、非適合度スコアは再び1−P(yi∣xi)になります。
- 決定境界までの距離(SVMの場合):SVMのように決定境界からの符号付き距離を出力するモデルでは、非適合度の尺度を、正しく分類された点ではその距離の負の値、誤分類された点ではその距離の正の値と定義できます。
- キャリブレーションのためのデータ分割 :予測を統計的に信頼できるものにするためには、非適合度の評価をキャリブレーションする必要があります。通常は、元のデータセットを次の2つに分割します。
- トレーニングセット:ベース分類器(ニューラルネットワークやSVMなど)の学習に使用します。
- キャリブレーションサンプル:分類器の学習には使用しない独立したデータ集合です。このデータは、非適合度スコアの計算と信頼性閾値の決定に使用されます。
- キャリブレーションデータに対する非適合度スコアの計算: キャリブレーションサンプル中の各データ点(xj, yj)について、学習済み分類器を用いて非適合度スコアαjを計算します。
- 非適合度スコアの並べ替えと(1−δ)分位点の決定: キャリブレーションサンプルから得られたすべての非適合度スコアを昇順に並べます(α(1) ≤α(2) ≤⋯≤α(m))。ここで、mはキャリブレーションサンプルのサイズです。
次に有意水準δ∈(0,1)を選択します。このδは、予測集合が真のラベルを含まない確率を表します。逆に、1−δは望ましい被覆確率です。これらのスコアの(1−δ)分位点を求める必要があります。より正確には、(1−δ)(m+1)個以上のキャリブレーションスコアが、それ以下となる最小の値qを求めます。一般的には「q=α(⌈(m+1)(1−δ)⌉)」のように計算されます
ただし有限標本の場合には、正確な被覆率を保証するため、有限標本補正を考慮した経験分位点(1−δ)を用いる方が信頼性が高いことがよくあります。より実践的には、k/(m+1)≥1−δを満たす最小のα(k)を見つけます。この値をq^とします。 - 新しいテストデータに対する予測集合の構築 :新しい入力xtestに対して予測をおこないたいとします。クラス集合{1,2,…,C}に含まれる各ラベルkについて、ytest =kであると仮定します。
次に、選択した非適合度尺度(例:1−P^(k∣xtest)を用いて、組(xtest ,k)に対する非適合度スコアαtest,kを計算します。
そして、ステップ4で求めた閾値q^以下となるすべてのラベルkを予測集合に含めます。Ytest ={k∈{1,…,C}∣αtest,k ≤q^ }
MapieClassifierの主要コンポーネント
MapieClassifierは、分類問題において予測集合を生成するためのMAPIEの中核クラスです。このクラスは、fit、predict、およびpredict_probaメソッドを備えた任意のscikit-learn推定器と互換性を持つよう設計されています。推定器が指定されない場合は、デフォルトでLogisticRegressionが使用されます。
cvパラメータにより、split、crossval、prefitなどの異なる検証戦略を選択でき、これが適合度スコアの計算方法やjackknife系手法とCV系手法の挙動に影響します。prefitオプションは、推定器がすでに学習済みであることを前提としています。この場合、提供されたすべてのデータは、スコアを計算することで予測をキャリブレーションするために使用されます。処理の流れとしては、まずデータを学習セット、キャリブレーションセット、およびテストセットに分割し、学習セットでベースモデルを学習させます。その後、MAPIEを用いてキャリブレーションセット上でモデルに共形予測を適用します。
cv="prefit"オプションは、特に金融アプリケーションにおいて非常に実用的です。金融分野では、モデルは大規模データセットに対して継続的に学習または再学習されることが多いためです。リアルタイム取引や高頻度取引では、モデルはストリーミングデータに基づいて頻繁に更新または再学習されます。事前学習済みモデルを利用し、その後で別のデータセットを用いてキャリブレーションできるということは、計算コストの高い学習処理を共形予測のために繰り返す必要がないことです。つまり、不確実性の定量化を、既存の高性能な取引システムへ大きな遅延を生じさせることなく効率的に統合できます。
methodパラメータ(現在はconformity_scoreに置き換えられており非推奨)は、共形予測の手法を指定するためのものでした。methodパラメータが廃止され、代わりにconformity_scoreが採用されたことは、共形予測メカニズムに対するより高いモジュール性と、より明示的な制御への移行を意味しています。このアーキテクチャ上の設計により、ユーザーは自身の問題において「不一致」をどのように測定するかを正確に定義できるようになります。金融データでは、異なる種類の誤りや不確実性が異なる重要性を持つことがあります。たとえば、「Buy」を「Sell」と誤分類する場合と、「Sell」を「Buy」と誤分類する場合では、影響が大きく異なる可能性があります。このモジュール性によって、不確実性定量化のプロセスを、特定の金融リスク指標や取引目標により適した形へ細かく調整することが可能になります。高度なユーザーは、あらかじめ定義された手法の範囲を超えて、共形予測を独自の要件に合わせてカスタマイズできるようになります。
理論部分の結論と推奨事項
MAPIEライブラリは、機械学習モデルにおける不確実性を定量化するための強力なツールであり、特に金融アプリケーションにおける共形二値分類の文脈で有効です。その分布非依存性および有限標本における被覆保証性を提供する能力、ならびに「良いサンプル」と「悪いサンプル」を明示的に識別できる能力は、高リスクな金融環境におけるリスクの信頼性と管理可能性を大きく向上させます。
MAPIEはscikit-learn互換のあらゆるモデルと統合可能であるため、既存の金融システムへの導入における柔軟性を高め、導入障壁を低減します。点予測から予測集合への移行は、モデルの不確実性の程度を明示的に考慮することにより、より精緻で情報量の多い意思決定を可能にします。特に、周辺被覆率と条件付き被覆率の区別は、金融応用において極めて重要です。なぜなら、強い買いシグナルのようなまれだが重要なクラスに対する予測の信頼性は、非対称的に高い重要性を持つためです。
推奨事項
- 適合度評価の優先順位: 金融における二値分類では、APSやRAPSといった適合度推定器を優先することが推奨されます。これらは空でない予測集合を保証するため、意思決定プロセスの連続性を維持し、高い不確実性の下でも必ず何らかの実際に活用可能な判断材料を提供します。
- Mondrian Conformal Predictionの使用 :クラス不均衡が存在する場合や、特定の取引タイプ(たとえば希少な買いシグナル)に対する条件付き被覆が重要な場合には、Mondrian Conformal Predictionの使用を検討すべきです。この手法は各クラスごとに信頼性保証を提供し、重要だが希少なイベントに対する体系的な被覆率不足を防ぎます。
- 厳密な時系列検証 :金融時系列への共形予測の適用には、交換可能性仮定の破れを慎重に評価する必要があります。MAPIEにはMapieTimeSeriesRegressorのような時系列向けツールがありますが、それらは非定常性や急激な市場変動に対処するため、他の時系列特化手法および厳密なバックテストと併用されるべきです。
- 多層的取引戦略の設計 :予測集合の解釈可能性を活用する取引戦略を設計することが重要です。これによりリスクエクスポージャーを動的に調整できます。たとえば、単一クラス集合(高信頼度)の取引にはフルポジションでエントリーし、複数クラス集合(低信頼度)の取引にはポジション縮小、ヘッジ、または取引回避といった運用が可能になります。
MAPIEライブラリの実践的応用
MAPIEライブラリは、モデル予測を「共形化」するために、主に2つの手法を実装しています。
- Split Conformal Prediction(分割共形予測)
- Cross conformal prediction(交差共形予測)
最初の手法は、元のデータを学習用サブサンプルと検証用サブサンプルに分割します。前者はベース分類器の学習に使用され、後者はキャリブレーションおよび予測集合の出力に使用されます。二つ目の手法は、データセットを複数のフォールドに分割し、クロス学習とキャリブレーションを用います。クロスバリデーションによって信頼性が高まると考えられるため、最初から二つ目の手法を使用します。クロスバリデーションに馴染みのない読者にとっては、これはウォークフォワード検証と同様の考え方です。
まず、MAPIEパッケージをインストールし、モジュールをインポートします。
pip install mapie from mapie.classification import CrossConformalClassifier
下記にリストされている追加ライブラリもインストールしてインポートします。
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_predict from sklearn.model_selection import StratifiedKFold from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from mapie.classification import CrossConformalClassifier from sklearn.ensemble import RandomForestClassifier
次に、共形予測を実装し、予測セットに基づいて悪い例と良い例を出力するテスト関数を作成します。
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9): dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract features and target feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels'] mapie_classifier = CrossConformalClassifier( estimator=RandomForestClassifier(n_estimators=n_estimators_rf, max_depth=max_depth_rf), confidence_level=confidence_level, cv=5, ).fit_conformalize(X, y) predicted, y_prediction_sets = mapie_classifier.predict_set(X) y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) # Calculate set sizes (sum across classes for each sample) set_sizes = np.sum(y_prediction_sets, axis=1) # Initialize meta_labels data['meta_labels'] = 0.0 # Mark labels as "good" (1.0) only where prediction set size is exactly 1 data.loc[set_sizes == 1, 'meta_labels'] = 1.0 # Report statistics on prediction sets empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}") # Return the dataset with features, original labels, and meta labels return data[feature_columns + ['labels', 'meta_labels']]
ベース分類器としては、scikit-learnのランダムフォレストを使用します。なぜなら、MAPIEパッケージはこのライブラリに含まれるすべての分類器をサポートしているためです。ランダムフォレストは比較的強力で柔軟な設定が可能なモデルですが、タスクに適していると考える他のモデルを使用することもできます。その場合は、該当するコード内でestimatorとして任意の分類器を渡す必要があります。なお、この分類器は予測集合を出力するためだけに使用される点に注意する必要があります。一方で、CatBoostは依然として最終的なモデルとして学習されます。
それでは、meta_learners_mapie()関数を段階ごとに分解していきます。
関数の定義およびそのパラメータ
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9):
この関数は3つの引数を取ります。
- n_estimators_rf:ベースモデルとして使用されるランダムフォレストにおけるツリーの数
- max_depth_rf:ランダムフォレスト内の各ツリーの最大深さ
- confidence_level:共形予測における信頼水準(デフォルトは0.9、すなわち90%)。このパラメータは予測集合がどの程度「広く」なるかを決定します。
データの読み込みと準備
dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
まず、データを読み込み、前処理します。
以下の3つの補助関数が存在することを前提とします。
- get_prices():生データ(価格)を読み込む
- get_features():get_prices()から返されたデータから特徴量を抽出または計算する
- get_labels():hyper_params辞書から特徴量とmarkupパラメータに基づいてターゲットラベルを生成する
その後、データは時系列インデックスに従ってソートされます。さらに、hyper_params['backward']とhyper_params['forward']の間に該当するインデックスを持つレコードのみが保持されます。最後に、SettingWithCopyWarningの問題を回避するために、フィルタリング後のDataFrameに対して.copy()を使用し、明示的にコピーを作成します。
Xの特徴量とyの目的変数の抽出
feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels']
- feature_columns:特徴量として使用する列名のリストを作成します。データ構造に依存した仕様であり、最初の列(インデックス0)と最後の2列を除いたすべての列が使用されます。これはdata構造に固有のものです。
- X:feature_columnsで指定された列を選択し、特徴量としてDataFrameを作成します。
- y:labels列からターゲットラベルを取り出し、Seriesとして作成します。
MAPIE適合分類器の初期化と学習
mapie_classifier = CrossConformalClassifier(
estimator=RandomForestClassifier(n_estimators=n_estimators_rf,
max_depth=max_depth_rf),
confidence_level=confidence_level,
cv=5,
).fit_conformalize(X, y)
- MAPIEライブラリのCrossConformalClassifierのインスタンスを作成します。これは、scikit-learn互換モデルに共形予測機能を追加するためのラッパーです。
- estimator:scikit-learnのRandomForestClassifierをベースモデルとして使用します。このモデルには、関数から渡されたn_estimators_rfおよびmax_depth_rfのパラメータが与えられます。
- confidence_level:関数に渡された信頼水準を使用します。 cv=5:共形予測器をキャリブレーションするために5分割クロスバリデーションを使用することを示します。これは、MAPIEにおける標準的なアプローチであり、データを学習用とキャリブレーション用に分割する役割を果たします。
- .fit_conformalize(X, y):このメソッドは、(X, y)データ上でベースとなるRandomForestClassifierを学習させると同時に、共形予測器のキャリブレーションもおこないます。このステップの完了後、mapie_classifierは共形予測を実行できる状態になります。
予測と予測集合の取得
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
mapie_classifier.predict_set(X)は、入力Xに対して2つの出力を生成します。
- predicted:ポイント予測であり、各サンプルに対して1つのクラスを返します。これは標準的な.predict()メソッドと同様の出力です。
- y_prediction_sets:共形予測の主要な出力です。各データサンプルについて、指定されたconfidence_levelのもとで予測集合に含まれるクラスを示す配列(または配列のリスト)になります。予測集合とは、真のクラスを少なくともconfidence_levelの確率で含むクラス集合のことです。その一般的な形状は(n_samples, n_classes, 1)または(n_samples, n_classes)であり、各値はそのクラスが予測集合に含まれるかどうかを示すブール値(True/False)または0/1となります。
予測集合の処理
y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) set_sizes = np.sum(y_prediction_sets, axis=1)
- np.squeeze(y_prediction_sets, axis=-1):もしy_prediction_setsの末尾にサイズ1の余分な次元(例:(n_samples, n_classes, 1))がある場合、この操作によってその次元が削除され、(n_samples, n_classes)の形状になります。
- set_sizes = np.sum(y_prediction_sets, axis=1):各サンプル(軸0に沿って)について、y_prediction_sets内のクラス方向(軸1)に沿った値を合計します。y_prediction_setsが0/1で構成されている場合、この合計は各サンプルに対して予測集合に含まれるクラス数を意味します。つまりset_sizesは、各観測に対する予測集合のサイズを表す配列になります。
メタラベルの生成
data['meta_labels'] = 0.0 data.loc[set_sizes == 1, 'meta_labels'] = 1.0
- data['meta_labels'] = 0.0:新しい列meta_labelsをDataFrame dataに追加し、すべての値を0で初期化します。
- data.loc[set_sizes == 1, 'meta_labels'] = 1.0::メタラベルを作成するための重要なステップです。予測集合のサイズ(set_sizes)がちょうど1であるサンプル、すなわち与えられた信頼水準のもとでモデルが単一のクラスのみを予測している場合、そのサンプルのmeta_labelsの値を1.0に設定します。つまり、モデルはその予測に対して高い確信を持っています。一方で、予測集合が空(サイズ0)である場合や複数のクラスを含む場合(サイズが2以上)の場合には、meta_labelsは0.0のまま維持されます。
予測集合の統計に関するレポート
empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}")
以下の量が計算されます。
- empty_sets:空の予測集合(モデルが与えられた信頼水準のもとでいかなるクラスも選択できない場合)
- single_element_sets:ちょうど1つのクラスのみを含む集合(高信頼度の予測であり、meta_labels=1に対応)
- multi_element_sets:2つ以上のクラスを含む集合(モデルが特定のクラスを一意に決定できず、不確実性がある場合)
結果を返す
return data[feature_columns + ['labels', 'meta_labels']]
この関数は、特徴量(feature_columns)、元のラベル(labels)、および新たに生成されたメタラベル(meta_labels)を含むDataFrameを返します。これらのメタラベルは、たとえば別のモデル(メタモデル)を学習するため、あるいはさらなるアクションのために最も信頼性の高い予測のみを選択するために利用することができます。
最終的に、この関数は共形予測を用いて、ベースモデル(ランダムフォレスト)が高い信頼度で予測し、かつ取り得るクラスがちょうど1つに絞られている観測値を識別します。これらの観測値には、メタラベルとして1が付与されます。
共形予測関数の改善
関数をテストし、その結果を評価した後、この手法には1つ重大な欠点があると結論づけました。それは、予測集合を推定して最終的なメタモデルを学習するという点では優れているものの、ベースモデル自体は依然として元のデータセット上で学習されているという点です。この元データには多くの誤りが含まれている可能性があり、その結果として新しいデータに対する汎化性能が低下する可能性があります。メタモデルは、不確実性が高い状況での取引を禁止することでベースモデルの誤りを補正しますが、ベースモデル自体の汎化性能が弱い場合、非定常市場においてシステム全体の性能は依然として低いままです。
ここで思い出すべき点として、MAPIE分類器をトレーニングした後には2種類の出力が得られます。
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
初期の共形予測関数では、メタモデルの学習に予測集合のみを使用し、ベースモデルは元データのラベルで学習されていました。しかし、ベースモデルについても、MAPIE分類器が高い信頼を示したサンプルだけを残す形で、学習用ラベルをフィルタリングすることができます。
# Initialize meta_labels column with zeros data['meta_labels'] = 0.0 # Set meta_labels to 1 where predicted labels match original labels # Compare predicted values with the original labels in the dataset data.loc[predicted == data['labels'], 'meta_labels'] = 1.0
上記のコードでは、予測ラベルと元のラベルを比較し、一致している場合には1、そうでない場合には0となる新しいmeta_labels列を作成しています。その後、ベース分類器はラベルが一致しているサンプルのみを用いて学習されます。
最終的なモデル学習関数の冒頭部分は次のようになります。
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = X[X.columns[1:-3]] X_meta = dataset[dataset.columns[1:-3]] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = y[y.columns[-3]] y_meta = dataset['conformal_labels']
このようにして、両モデルは可能な限り「非定常時系列の中でもより品質の高いデータ」のみに基づいて学習されるため、結果としてより安定した出力を返すことが期待されます。
アルゴリズムの学習とテスト
この手法をテストするために、EURUSD通貨ペアを対象として、2020年初頭から2025年初頭までのデータで10個のモデルを循環的に学習させます。残りのデータはフォワード期間として扱います。
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2025, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learners_mapie(15, 5, confidence_level=0.90, CV_folds=5))) meta_leaners_mapie関数は、以下の引数で呼び出されます。
- 15:ランダムフォレストにおける決定木の数(ベース分類器)
- 5:各決定木の最大深さ
- confidence level = 0.90:モデルの信頼水準は90%
- CV_folds = 5:クロスバリデーションの分割数
学習時には下記の情報が表示されます。
Learn 9 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 6715 Multi-element sets (meta_labels=0): 22948 Correct predictions (meta_labels=1): 16638 Incorrect predictions (meta_labels=0): 13025 R2: 0.9931613891107195
- Empty sets:モデルがどのクラスにも確信を持てない場合(空の予測集合)
- Single element sets:1つの要素のみを含む予測集合の数です。この場合、モデルはこれらの予測に対して0.9の信頼水準を有しています。
- Multi-element sets:複数のクラスを含む予測集合の数です。これらのケースではモデルは不確実です。
- Correct predictions:正しく予測されたラベルの数
- Incorrect predictions:誤って予測されたラベルの数
- R2:バランスカーブの品質指標
提供されたレポートに基づくと、このデータセットには多くのジャンクデータが含まれていると結論できます。6,715件の信頼できる予測と、22,948件の信頼できない予測です。しかし、このモデルはこれを修正し、信頼できるもののみを使用します。テスター内のバランスグラフは次のようになります。
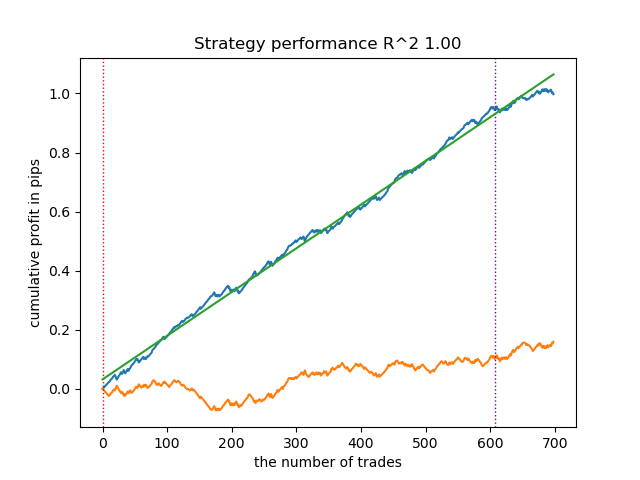
このアルゴリズムの特徴として、メインモデルとメタモデルの両方が高い精度で学習される点が挙げられます。
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.92, 'Logloss': 0.1990666082064606} >>> models[-1][2].get_best_score()['validation'] {'Accuracy': 0.9647435897435898, 'Logloss': 0.10955056411224594}
つまり、元のデータセット(多くのジャンクデータを含むもの)と比較して、モデルから大部分の不確実性が除去されています。さらに、最終モデルはより信頼性の高い決定しきい値を得るためにキャリブレーションすることができますが、これは本記事の範囲外です。
confidence_levelを0.9から0.6に下げた場合、真のクラスラベルを60%の確率で含む集合がより多く得られるようになります。これはレポートにも反映されます。
Learn 8 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 28647 Multi-element sets (meta_labels=0): 991 Correct predictions (meta_labels=1): 16999 Incorrect predictions (meta_labels=0): 12639 R2: 0.9850582205528567
前の例では「Single Element sets」は少数でしたが、現在は「Multi-element sets」を上回るようになります。しかし、成功結果に対する信頼度はより低くなります。この不確実性はバランスチャートにも反映され、より多くのドローダウンが含まれるようになります。
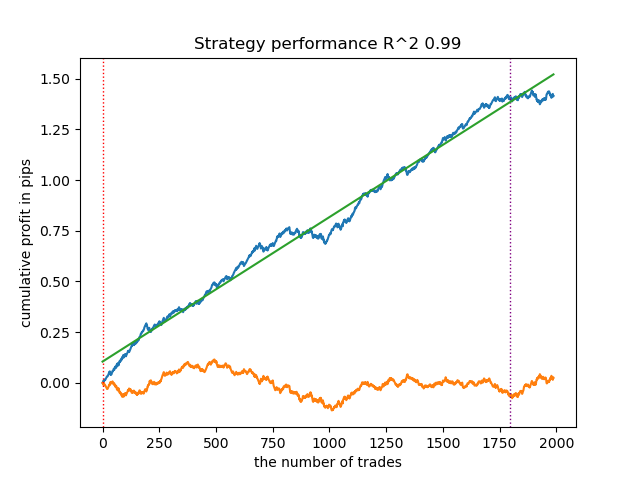
したがって、モデルの信頼水準を調整することで、失敗する取引操作に関連するリスクを制御することが可能になります。これにより、取引回数と取引効率の間の妥協点、あるいはブラックスワンイベントの発生確率とのトレードオフを検討することができます。
MetaTrader 5ターミナルへのモデルのエクスポートとテスト
モデルのエクスポートは、これまでのすべての記事と同様の方法で実装されています。より詳細な情報については、それらの記事を参照してください。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
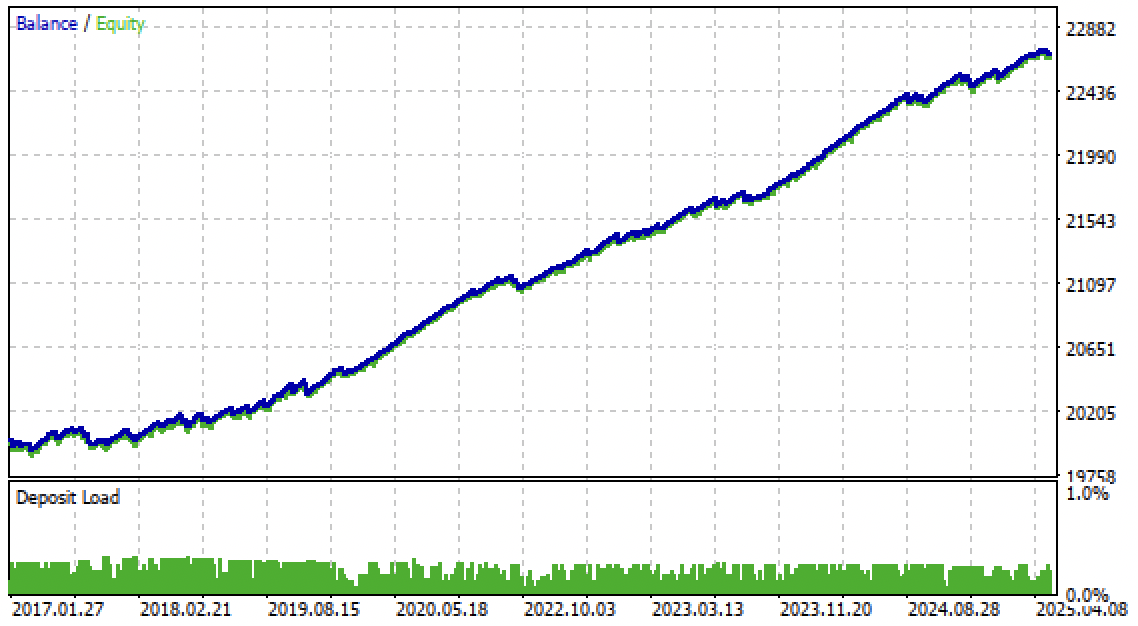
それでは、MetaTrader 5ターミナルでアルゴリズムをテストしてみましょう。この取引システムは、フォワード期間だけでなく、2017年から2020年までの過去期間においても安定性を示しました。
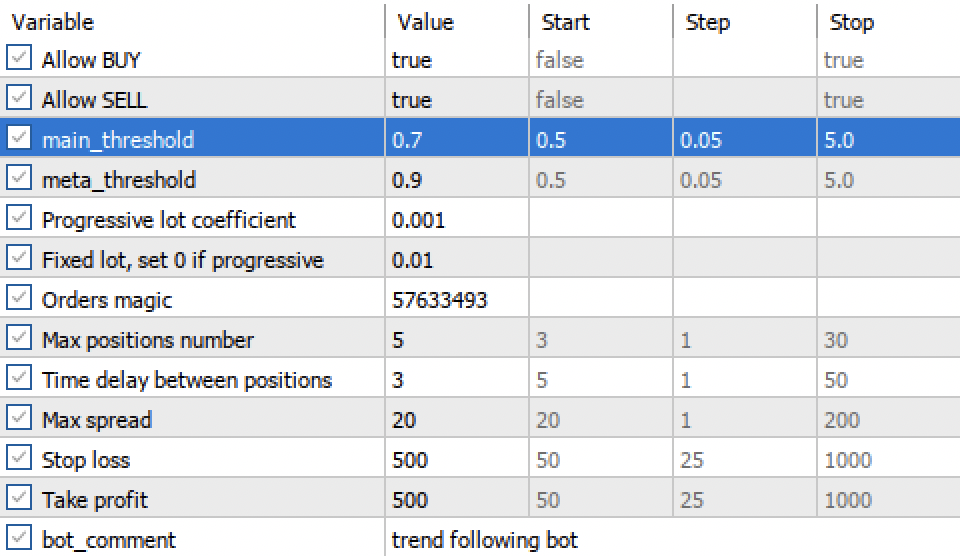
「main threshold」と「meta threshold」の設定により、モデルのシグナルを信頼度でフィルタリングすることができます。閾値を高くするほど取引の信頼性は高くなりますが、取引回数は少なくなります。
結論
本記事では、共形予測およびそれを実装するMAPIEライブラリを紹介しました。このアプローチは機械学習における最も現代的な手法の一つであり、既存のさまざまな機械学習モデルに対するリスク管理に焦点を当てることを可能にします。共形予測それ自体は、データ内のパターンを見つける方法ではありません。これは、既存のモデルが個々のサンプルを予測する際の信頼度を判定するだけであり、信頼性の高い予測を選別できるようにします。この重要な性質により、モデル学習段階で信頼度閾値を調整することで、取引におけるリスク管理が可能になります。
Python files.zipアーカイブには、Python環境向けの開発ファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| mapie causal.py | モデル学習用のメインスクリプト |
| labeling_lib.py | 取引ラベル付けロジックモジュールの更新 |
| tester_lib.py | 機械学習ベースのカスタムストラテジーテスターの更新 |
| export_lib.py | モデルをターミナルにエクスポートするモジュール |
| EURUSD_H1.csv | MetaTrader 5ターミナルからエクスポートしたレートデータ |
MQL5 files.zipアーカイブには、MetaTrader 5ターミナル用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| mapie trader.ex5 | 記事で作成したボットのコンパイル済みファイル |
| mapie trader.mq5 | 記事で使用したボットのソースコード |
| Include//Trend following folder | ONNXモデルおよびボット接続用ヘッダファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18324
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは。fixing_lib モジュールの添付を忘れているようです。このモジュールは mapie_causal.py ファイルでインポートされています。
素晴らしい仕事ですね!ご協力、誠にありがとうございます。いくつか修正を加えたところ、すべて問題なく動作しています。