
金融时间序列中的保形预测探索
引言
MAPIE(模型无关预测区间估计器)是一款开源Python库,用于对机器学习模型进行不确定性量化与风险管理。它可以为回归问题计算预测区间,也能为分类和时间序列任务生成预测集合。这类不确定性评估是基于专门的“校准数据集”完成的。
MAPIE的一大核心优势在于其模型无关特性,这意味着该库可与任何兼容scikit-learn API的模型配合使用,包括通过适配包装器使用TensorFlow或PyTorch构建的模型。这一特性极大地降低了将其集成到现有分析流程的难度,因为交易者通常会根据具体资产类别或交易策略,使用从传统统计方法到复杂神经网络在内的各类机器学习模型。MAPIE能够直接在成熟模型上无缝实现不确定性量化,可显著降低落地成本并加快应用速度,这在瞬息万变的金融环境中尤为重要。
该库属于scikit-learn-contrib生态体系,基于保形预测(conformal forecast)与无分布推断理论构建。它实现了经过同行评审的算法,这些算法与模型和业务场景无关,并在对数据和模型做出极少假设的前提下提供理论保证。除标准分类任务外,MAPIE还可用于更复杂任务的风险控制,例如多分类问题与计算机视觉中的图像分割,通过为召回率、精确率等指标提供概率保证来实现。
MAPIE具备风险控制与概率保障能力,这使其不仅是一款不确定性量化工具,更是一套完整的风险管理框架。在金融领域,单点预测是远远不够的,因为它们无法体现置信水平或潜在误差。提供如95%这样的覆盖率保证,可以直接转化为可量化的风险指标,让风险管理者能够设定明确的风险容忍度。
例如,如果模型发出买入信号,但保形预测显示出错概率较高,风险管理者可选择减仓或放弃交易,直接控制潜在亏损。这使得在不确定性下做出更稳健的决策成为可能,而非仅仅追求预测准确率。
保形预测的基本原理:与分布无关的模型无关保证
保形预测(CP)是一种统计框架,可为分类问题生成预测集合,或为回归问题生成预测区间,并提供覆盖率概率保证。这就意味着在给定置信水平(例如90%)下,真实结果至少有90% 的概率会落在预测集合或区间内。
CP的核心优势在于其“无分布”特性:该方法不依赖对数据或模型底层分布的严格假设。唯一的基本假设是训练点与测试点具有可交换性,即它们可视为来自同一分布,且样本次序不会影响其联合分布。
这一假设弱于独立同分布(i.i.d.)假设,并且在实践中往往可以成立。与传统预测区间只能近似实现覆盖率不同,CP提供有限样本保证,即使在数据量有限的情况下也能达到指定覆盖率。
保形预测的无分布保证,直接解决了金融建模中的根本难题。众所周知,金融数据不服从正态分布,具有厚尾特征,且常常违背同方差、增量独立等典型统计假设。
传统预测区间往往依赖这类假设(如残差正态),因此只能提供近似覆盖率。而CP无需此类假设即可提供保证覆盖率,使其在金融应用中天然更稳健、更可信 —— 因为错误设定分布会导致风险被严重低估。这就意味着在真实复杂的金融数据集上,其给出的置信水平更加可靠。
保形预测通常流程为:使用训练好的机器学习模型,构建校准数据集(模型训练时未见过),在该数据集上计算“一致性分数”(保形评分),再通过这些分数的分位数确定预测集合。从近似覆盖率转向有限样本保证覆盖率,从根本上改变了金融领域机器学习模型的监管与风险管理逻辑。
在金融等高风险行业,模型往往需要证明其量化稳健性并能控制错误率。这与传统的统计方法不同,后者的“90%置信度”可能只是渐近性质或近似结果。对于量化交易者而言,这为论证交易策略或风险资金分配提供了更坚实的基础。
二分类中的预测集合对比单点预测
传统二分类模型输出单个预测标签(如“买入”或“卖出”)或概率分数(如“买入”概率为0.8),这些都属于单点预测。然而,保形预测提供的是预测集合,即可能类别的一个子集(例如 {买入}、{卖出} 或 {买入,卖出})。该集合被保证以指定概率包含真实标签。
对于二分类问题,预测集合可分为以下几种情况:
- 单一类别(如 {买入} 或 {卖出}),表示模型具有较高的置信度;
- 同时包含两个类别(如 {买入,卖出}),表示存在不确定性或信号模糊;
- 空集{}(在APS等部分方法中较少出现,通常也不希望出现),表示极端不确定,或没有任何类别达到置信阈值。
预测集合的“信息量”与其大小成反比:集合越小(如仅包含一个类别),信息量越大;集合越大(如同时包含两个类别),信息量越小。显式输出一个集合而非单一类别结果,从根本上改变了金融二分类场景下的决策方式。预测集合不再是简单的“是/否”或“买入/卖出”信号,而是直接反映了模型自身的置信程度。
像{买入}这样的单类别集合代表强信号,而{买入,卖出}这样的双类别集合则代表信号高度模糊。因此支持更精细化的交易策略:对高置信度信号执行交易,对模糊信号选择观望、减仓或进一步验证信息。这是一种将不确定性直接融入金融决策的有效机制。
预测集合的“信息含量”,可直接作为金融交易中策略效率与风险容忍度的衡量指标。如果某笔交易对应的预测集合宽泛且无信息量(如{买入,卖出}),说明模型在目标置信水平下无法可靠区分多空方向。对量化分析师而言,这不是需要修正的预测错误,而是一个应避免操作或极度谨慎操作的信号。从而实现了动态风险管理:对集合紧凑、可靠性高的交易分配更多资金;对集合宽泛、不确定性高的交易规避敞口或将其降至最低。从而直接优化交易策略的风险收益结构。
理论保证:边际覆盖率与条件覆盖率
保形预测器具有“自动有效性”,即在平均意义上,其预测集合的覆盖概率不低于设定的置信水平 (1 − α)。只要满足可交换性假设,无论底层模型与数据生成方式如何,该保证均成立。这一性质被称为边际覆盖率。
边际覆盖率虽有保证,但它是一个平均指标。更严格的概念,如条件有效性,追求基于具体数据特征(如按类别、按样本、按标签)的覆盖保证。归纳式保形预测器(计算高效版本)主要控制无条件的覆盖概率,而实现条件有效性通常需要对方法进行改进。
边际覆盖率与 条件覆盖率的区别,对金融二分类任务至关重要,尤其在金融领域常见的不平衡数据集上(例如“不交易”或“观望”信号远多于“买入“或“卖出”信号)。
边际覆盖率仅保证平均90%的预测正确性。然而,如果买入信号本身很稀少,模型可能在卖出信号上极准、在买入信号上表现很差,却依然能达到90%的边际覆盖率。如果买入信号至关重要,就会导致严重的机会错失或亏损。
条件覆盖率(尤其是按类别划分的覆盖率)则保证对每个类别单独达到目标置信水平。这对于确保买入、卖出信号预测的可靠性至关重要,可避免系统性偏差破坏交易策略。
通过Mondrian保形预测等方法提高条件有效性,可直接解决金融应用中不同结果类别的公平性与可靠性问题。在金融中,某些类别的预测错误(如罕见但高收益的“买入”机会、避免大额亏损的关键“卖出”信号),其成本远高于常见的“不交易”类错误。
通过提供条件覆盖率,系统能保证每一类交易信号都达到最低可靠水平,而非仅整体平均达标。这使得不同交易信号得到更公平的对待,并增强对模型在各类市场环境与稀有事件中表现的信心,这对稳健的算法交易至关重要。
一致性分数:保形预测的核心
一致性分数是保形预测的核心,用于量化新样本相对于校准集的“异常程度”或“不匹配程度”。评分函数的唯一要求是:分数越高,代表输入数据与其假设标签之间的匹配度越差。这些分数用于在校准集上计算分位数(临界点),进而确定新测试样本的预测集合。
MAPIE实现了多种一致性分数,包括对称型(如回归中的绝对残差分数)和非对称型(如回归中的Gamma分数),它们会影响预测区间上下界的计算方式。分类任务则使用LAC、APS、RAPS等专用评分方法。
对于一致性分数的选择不只是技术细节,更是一项策略决策,其直接影响预测集合的实用价值与可解释性。不同分数(如LAC、APS)会导致生成预测集合时的行为差异。
例如,LAC在高不确定性下可能产生空集,在金融市场因无法提供可执行性的指导,也许并不理想。APS从设计上避免空集,从而始终会给出一些合理的结果。这意味着评分方式的选择直接影响“异常样本”的表示方式,以及系统是否总能给出有效(即便模糊)的结论。量化交易者应选择与目标信息含量、风险容忍度相匹配的评分方式。
“一致性”这一概念可以识别数据驱动模型预测语境下的“异常值”或“罕见值”,对检测异常交易环境极具价值。在金融市场中,异常价格波动、成交量突增或突发新闻,都会产生显著偏离历史模式的数据点。
新样本的高一致性分数,意味着该观测“不符合”校准集中的历史规律。这可作为市场异常或市场状态切换的早期预警系统,提示调整交易策略或暂停自动化交易,从而成为超越单纯模型准确率的关键风险管理工具。
分类任务常用的一致性分数详解
MAPIE提供多种一致性分数,各有特点与适用场景。
- 最小模糊集分类器(LAC):
- 计算方式:一致性分数 = 1 − 真实标签对应的softmax分数。
- 特性:方法简单,理论上保证边际覆盖率,通常会生成较小的预测集合。
- 适用场景/局限性:在模型高度不确定时(如决策边界附近),容易生成空预测集。这在金融场景中存在明显缺陷,因为空集无法提供可执行的交易指导。
- 自适应预测集合(APS):
- 计算方式:将每个标签对应的softmax分数从高到低排序并依次累加,直到包含真实标签为止,以此计算一致性分数。
- 特性:解决了LAC生成空集的问题;从定义上保证预测集合非空,并提供边际覆盖率保证。
- 适用性:在金融应用中更为稳健,因为即便预测存在不确定性,也远好于完全没有输出的空集。
- 正则化自适应预测集合(RAPS):
- 计算方式:与APS类似,但额外引入正则化项以缩小预测集合的大小。
- 特性:在保证覆盖率的同时,通过正则化控制集合大小,实现覆盖率与预测效率的平衡。
- 适用性:适用于预测集合大小(即信号有效性)与覆盖率同等重要的场景,更小的集合在交易中更具实操价值。
- 蒙德安保形预测
- 计算方式:该方法为每个类别单独计算一致性分数的分位数,使预测集合具备类别感知能力。
- 特性:为每个类别提供独立的条件覆盖率 (1 − α),对不平衡的多分类或二分类问题至关重要。
- 适用性:强烈推荐用于金融二分类任务(买入/卖出),尤其当类别不平衡时(例如“买入”信号远少于“持有”或“卖出”信号),或不同类别具备不同错误容忍度时。该方法能保证买入信号的可靠性不受卖出信号表现的影响。
从LAC到APS/RAPS的一致性分数演变,反映了真实场景下对有效且具备信息量的预测集合的实际需求。LAC虽然概念简单,但容易生成空集,这在金融场景中是重大缺陷。在买入/卖出决策中,空预测集无法提供任何指导,会直接导致决策流程中断。APS和RAPS保证非空集合,确保即使在高度不确定的环境下,模型依然能给出一些合理的参考结果,允许交易者采取“持有观望”或“重新评估”等默认操作,而非完全停滞。确保交易与风险管理的连续性。
蒙德安方法是金融二分类任务的关键改进,直接解决了类别不平衡与误差代价差异问题。在买入/卖出交易中,“买入”信号往往稀少但收益极高,而“卖出”信号更频繁但单次影响较小。标准保形方法仅提供边际覆盖率,即便整体平均达标,稀有“买入”类别的覆盖率也可能低于预期。蒙德安方法能够按类别计算专属分位数,确保每个类别都独立达到目标置信水平。
这对于避免关键稀有事件(如强势买入信号)出现系统性覆盖率不足至关重要,进而提升策略可靠性与潜在收益。这样保证模型的稳健性并非仅停留在平均水平,而是对每一类具体交易信号均有效。
分类任务中保形预测集合的构建步骤
让我们分步拆解整个流程:
- 选择非一致性度量(或称 “评分函数”):这一步至关重要。在分类任务中,通常会使用已训练好的分类器输出结果(例如逻辑回归、支持向量机、神经网络或随机森林等)。设f(x)为分类器对输入x的输出。如果f(x)的输出概率(例如来自softmax层),那么对于数据点(xi ,yi),一个合适的非一致性度量可能为:
- 1 - 真实类别的预测概率:αi =1−P^(yi ∣xi ),其中,P^(yi ∣xi ) 是模型对输入xi的真实标签yi给出的预测概率。如果αi取值较小,说明模型对真实类别的预测置信度高,代表该样本“符合规律”。反之,如果αi取值较大:说明模型置信度低,代表该样本“不符合规律”。
- 基于softmax温度缩放方式:如果模型输出的是logits,可以先通过softmax转换为概率,再使用同样的非一致性度量:1−P(yi ∣xi)。
- 到决策边界的距离(适用于SVM):对于SVM这类输出到决策边界有符号距离的模型,非一致性度量可以定义为对正确分类的点取负距离或对错误分类的点取正距离,以此来反映样本的非一致性程度。
- 用于校准的数据划分:为了让预测具备统计上的可靠性,需要对非一致性度量进行校准。通常做法是将原始数据集划分为两部分:
- 训练集:用于训练基础分类器(如神经网络、SVM)。
- 校准集:不用于训练分类器的独立数据,专门用来计算非一致性分数并确定置信阈值。
- 计算校准数据的非一致性分数:对校准集中的每个数据点(xj ,yj),使用已训练好的分类器计算其非一致性分数αj。
- 对非一致性分数排序并确定(1−δ) 分位数:将校准集所有非一致性度量按升序排列,α(1) ≤α(2) ≤⋯≤α(m),其中,m为校准集样本量。
接下来选定显著性水平δ∈(0,1) 。δ表示预测集合不包含真实标签的概率;相应地, 1−δ为目标覆盖概率。我们需要找到这些分数的(1−δ)分位数。更精确地说,找到最小的q,使得至少(1−δ)×(m+1)个校准分数小于等于q。常用阈值计算方式:q=α(⌈(m+1)(1−δ)⌉)
然而,在有限样本下,更可靠的做法通常使用经过有限样本修正的经验分位数以保证准确覆盖。更实用的方式是找到最小的α(k),使其满足:k/(m+1)≥1−δ. 将该值记为q^。 - 为新测试样本构建预测集合:设xtest为待预测的新样本。对类别集合中每一个可能的标签k(例如C分类中 1,2,…,C ),先假设ytest = k。
使用选定的非一致性度量(如1−P^(k∣xtest ))为(xtest ,k)计算非一致性分数αtest,k。
最终,xtest的预测集合Ytest包含所有满足下式的标签k:Ytest ={k∈{1,…,C}∣αtest,k ≤q^ }。
MapieClassifier核心组件
MapieClassifier是MAPIE中用于分类任务生成预测集合的核心类。它兼容所有实现了fit、predict和predict_proba方法的scikit-learn评估器。如果未指定评估器,默认使用逻辑回归。
cv参数支持使用不同的交叉验证策略(如"split"、"crossval"、"prefit")计算一致性分数,区分Jackknife方法与CV方法。"prefit"选项假设评估器已经训练完成,所有传入数据仅用于计算分数并校准预测。整体流程为:将数据划分为训练集、校准集和测试集 ,在训练集上训练基础模型,之后用MAPIE在校准集上对模型进行“保形化”(conformalize)。
cv = "prefit"在金融场景中非常实用,因为真实环境下模型往往在大规模数据集上持续训练与更新。在实时或高频交易中,模型会基于流式数据频繁更新。使用预训练模型和独立数据集校准的方式,意味着无需重复执行计算密集的训练步骤即可实现保形预测。这使得不确定性量化能够高效地接入现有高性能交易系统,而不会产生明显延迟。
method参数(现已弃用,由conformity_score替代)用于指定保形预测方法。弃用method参数而改用conformity_score,是为了提升模块化程度,并让用户更直观地控制底层保形预测机制。这种架构设计允许用户根据具体问题,精确定义如何计算“不匹配度”。在金融数据中,不同类型的误差或不确定性重要程度不同(例如将 “买入”误判为“卖出”的代价极高),这种模块化支持精细调整不确定性量化流程,使其更贴合特定金融风险指标与交易目标。同时也让高级用户可以在预设方法之外自定义保形预测逻辑。
理论部分结论与建议
MAPIE库是量化机器学习模型不确定性的强力工具,尤其适用于金融领域的保形二分类任务。它能够提供无分布依赖、有限样本下的覆盖率保证,并能明确区分“可靠”与“不可靠”样本,显著提升高风险金融环境下的模型可靠性与风险可控性。
MAPIE可与所有兼容scikit-learn的模型集成,具备高度灵活性,降低了在现有金融系统中落地的门槛。从单点预测转向预测集合,能显式体现模型的不确定程度,支持更精细、更理性的决策。特别是边际覆盖率与条件覆盖率的区分,对金融应用至关重要,因为稀有但关键类别的预测可靠性(如强势买入信号)往往具有极高的价值。
建议:
- 优先选择一致性评分方法:对于金融二分类任务,建议优先使用APS或RAPS一致性评分,它们能保证预测集合非空,确保决策流程连续,即使在高度不确定的环境下也能提供可执行的推断。
- 使用蒙德安保形预测:在类别不平衡场景,或特定交易类型(如稀有买入信号)的条件覆盖率至关重要时,应采用蒙德安保形预测。该方法为每个类别单独提供可靠性保证,避免重要稀有事件出现系统性覆盖率不足。
- 严格的时间序列验证:将保形预测应用于金融时间序列时,必须进行严谨验证,并考虑可交换性假设被破坏的问题。虽然MAPIE提供了专用时间序列工具(如MapieTimeSeriesRegressor),但仍需结合其他时间序列专用方法与严格回测,确保模型在非平稳性与市场突发变化下保持稳健。
- 构建多层级交易策略:应基于预测集合的可解释性设计交易策略。实现动态风险敞口调整:对于高置信度信号(单类别集合)满仓执行;对于低置信度信号(多类别集合)减仓、对冲或观望。
MAPIE库的实际应用
MAPIE库实现了两种模型保形预测方法:
- 拆分式保形预测
- 交叉保形预测
第一种方法将原始数据划分为训练集与验证集,训练集用于训练基础分类器,验证集用于校准并生成预测集合。第二种方法将数据集划分为多折,采用交叉训练与校准。我们将直接使用第二种方法,因为交叉验证能带来更高的可靠性。对于不熟悉交叉验证的读者而言,此方法与滚动向前验证的思路相似。
首先,我们需要安装MAPIE库并导入模块:
pip install mapie from mapie.classification import CrossConformalClassifier
同时,还需要安装并导入以下附加库:
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_predict from sklearn.model_selection import StratifiedKFold from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from mapie.classification import CrossConformalClassifier from sklearn.ensemble import RandomForestClassifier
接下来,我编写了一个测试函数,用于实现保形预测,并根据预测集合区分并输出可靠样本与不可靠样本。
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9): dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract features and target feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels'] mapie_classifier = CrossConformalClassifier( estimator=RandomForestClassifier(n_estimators=n_estimators_rf, max_depth=max_depth_rf), confidence_level=confidence_level, cv=5, ).fit_conformalize(X, y) predicted, y_prediction_sets = mapie_classifier.predict_set(X) y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) # Calculate set sizes (sum across classes for each sample) set_sizes = np.sum(y_prediction_sets, axis=1) # Initialize meta_labels data['meta_labels'] = 0.0 # Mark labels as "good" (1.0) only where prediction set size is exactly 1 data.loc[set_sizes == 1, 'meta_labels'] = 1.0 # Report statistics on prediction sets empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}") # Return the dataset with features, original labels, and meta labels return data[feature_columns + ['labels', 'meta_labels']]
我们将使用scikit-learn中的随机森林作为基础分类器,因为MAPIE库支持该库中的所有分类器。随机森林是一种功能强大且参数设置灵活的模型,但您也可以根据任务需求选用其他合适的模型。如需更换模型,只需在代码中把estimator参数替换为其他分类器即可。需要注意的是,该分类器仅用于生成预测集合,最终模型仍会使用CatBoost进行训练。
让我们分步拆解meta_learners_mapie() 函数。
函数定义及其参数说明:
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9):
该函数包含三个参数:
- n_estimators_rf — 基础模型的随机森林中的决策树数量;
- max_depth_rf — 随机森林中每棵树的最大深度;
- confidence_level — 保形预测的置信水平(默认值0.9,即90%),该参数决定了预测集合的区间“宽度”。
数据加载与预处理:
dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
首先,执行数据加载与预处理。
代码中假设已实现三个辅助函数:
- get_prices() — 加载原始数据(价格数据);
- get_features() — 从get_prices()返回的数据中提取或计算特征;
- get_labels() — 根据特征以及hyper_params字典中的markup参数生成目标标签。
随后,数据按照时间索引排序。仅保留索引位于hyper_params['backward']和hyper_params['forward']之间的记录。使用.copy()创建过滤后DataFrame副本,避免出现SettingWithCopyWarning问题。
提取特征矩阵X与目标变量y:
feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels']
- feature_columns — 创建用作特征的列名列表。选取除第一列(索引0)和最后两列之外的所有列。这是针对当前data数据结构的特定处理方式。
- X — 通过选取feature_columns中的列,构建包含特征的DataFrame。
- y — 从 labels 列提取目标标签,生成 Series 序列。
MAPIE保形分类器的初始化与训练:
mapie_classifier = CrossConformalClassifier(
estimator=RandomForestClassifier(n_estimators=n_estimators_rf,
max_depth=max_depth_rf),
confidence_level=confidence_level,
cv=5,
).fit_conformalize(X, y)
- 创建MAPIE库中的CrossConformalClassifier实例。这是一个包装器,可为任何兼容scikit-learn的模型添加保形预测能力。
- estimator — 使用scikit-learn中的RandomForestClassifier作为基础模型(评估器),并传入函数接收的n_estimators_rf和max_depth_rf参数。
- confidence_level — 使用传入函数的置信水平。cv=5 — 指定采用5折交叉验证对保形预测器进行校准,这是MAPIE中将数据划分为训练集与校准集的标准方式。
- .fit_conformalize(X, y) — 该方法在数据(X, y)上训练基础随机森林模型,同时完成保形预测器的校准。执行此步骤后,mapie_classifier即可用于生成保形预测。
获取预测结果与预测集合:
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
mapie_classifier.predict_set(X) — 为输入 X 生成两项输出:
- predicted — 单点预测结果(每个样本对应一个类别),与标准.predict()方法输出一致。
- y_prediction_sets — 保形预测的核心输出。对每个数据样本,它返回一个数组(或数组列表),标明在设定置信水平下,哪些类别被纳入预测集合。预测集合指的是以至少置信水平的概率包含真实类别的类别集合。其常见形状为:(n_samples, n_classes, 1) 或 (n_samples, n_classes),值为布尔型(True/False)或0/1,用于表示对应类别是否被纳入集合。
预测集合处理:
y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) set_sizes = np.sum(y_prediction_sets, axis=1)
- 如果y_prediction_sets在末尾多出一个大小为1的冗余维度(例如形状为(n_samples, n_classes, 1)),该操作会将其移除,最终得到形状为(n_samples, n_classes)的数组。
- set_sizes = np.sum(y_prediction_sets, axis=1):对每个样本(沿0轴),按类别(沿1轴)对y_prediction_sets中的值求和。如果y_prediction_sets由0/1组成,那么求和结果就是每个样本的预测集合所包含的类别数量。也就是说,set_sizes是一个记录每条数据预测集合大小的数组。
生成元标签
data['meta_labels'] = 0.0 data.loc[set_sizes == 1, 'meta_labels'] = 1.0
- data['meta_labels'] = 0.0:在DataFrame中新增一列meta_labels,并全部初始化为0。
- data.loc[set_sizes == 1, 'meta_labels'] = 1.0:核心步骤是创建元标签。对于预测集合大小恰好等于1的样本(即在指定置信度下模型只给出一个类别),将其元标签设置为1.0。表示模型对这些样本的单一预测结果高度自信。如果预测集合为空(大小为0)或包含多个类别(大小≥2),元标签保持为0.0。
预测集合统计报告:
empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}")
接下来计算以下统计指标:
- empty_sets — 空预测集合(模型在指定置信度下无法选出任何类别);
- single_element_sets — 仅包含一个类别的集合(高置信度预测,对应元标签meta_labels=1);
- multi_element_sets — 包含两个及以上类别的集合(模型无法确定唯一类别)。
返回结果:
return data[feature_columns + ['labels', 'meta_labels']]
函数返回一个DataFrame,其中包含:原始特征(feature_columns)、原始标签(labels)和新生成的元标签(meta_labels)。这些元标签可用于训练元模型(meta model),或筛选最可靠的用于后续交易决策的预测结果。
最终,该函数通过保形预测识别出:基础模型(随机森林)能够高置信度、唯一确定类别的样本,并将它们标记为“元标签”1。
优化保形预测函数
测试函数并评估结果后,我发现它存在一个重大缺陷:虽然该函数能很好地推断出用于训练最终元模型的预测集合,但基础模型仍然是在原始数据集上训练的,而原始数据往往包含大量噪声/错误,导致基础模型泛化能力差,难以适应新数据。元模型虽然能通过禁止高不确定性场景下的交易来修正基础模型的误差,但由于基础模型泛化能力弱,整个系统在非平稳市场中表现依然很差。
让我们回顾一下,在训练完MAPIE分类器后,会得到两组标签:模型预测值(标签本身)和预测集合。
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
初始的保形预测函数仅利用预测集合来训练元模型,而基础模型则是基于原始数据集的标签进行训练的。但我们也可以修正基础模型的训练标签,只保留MAPIE分类器置信度最高的那些标签。
# Initialize meta_labels column with zeros data['meta_labels'] = 0.0 # Set meta_labels to 1 where predicted labels match original labels # Compare predicted values with the original labels in the dataset data.loc[predicted == data['labels'], 'meta_labels'] = 1.0
在上述代码中,我们将模型预测标签与原始真实标签进行对比,并生成一个新的meta_labels列,当标签一致时记为1,不一致时记为0。随后,我们只在标签一致的样本上训练基础分类器。
最终模型训练函数的第一部分代码如下所示:
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = X[X.columns[1:-3]] X_meta = dataset[dataset.columns[1:-3]] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = y[y.columns[-3]] y_meta = dataset['conformal_labels']
因此,两个模型都会尽可能在非平稳时间序列上完成训练,从而输出更高质量的结果。
算法的训练与测试
为了测试该方法,我们将循环训练10个模型,使用的是2020年初至2025年初的欧元兑美元(EURUSD)货币对数据。剩余的数据则作为未来预测期。
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2025, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learners_mapie(15, 5, confidence_level=0.90, CV_folds=5))) 我们将使用以下参数调用meta_learners_mapie函数:
- 随机森林(基础分类器)的决策树数量为15;
- 每棵决策树的最大深度为5;
- 模型置信水平为90%;
- 交叉验证折数为5。
训练过程中会输出以下信息:
Learn 9 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 6715 Multi-element sets (meta_labels=0): 22948 Correct predictions (meta_labels=1): 16638 Incorrect predictions (meta_labels=0): 13025 R2: 0.9931613891107195
- 空集数量 — 模型对所有类别都缺乏置信度,从而生成空预测集合的数量。
- 单类别集合数量 — 仅包含单个类别的预测集合数量,模型对这类预测的置信概率为0.9(90%)。
- 多类别集合数量 — 包含多个类别的预测集合数量,模型对这类样本缺乏置信度。
- 正确预测数 — 标签预测正确的样本数量。
- 错误预测数 — 标签预测错误的样本数量。
- 平衡曲线质量指标(R2)— 用于评估资金平衡曲线拟合效果的指标。
根据提供的报告可知,该数据集包含大量噪声数据:可靠预测共6715条,而不可靠预测多达22948条。但我们的模型会解决这一问题,只使用可靠的预测结果。最终,测试器中的资金平衡曲线会呈现如下效果。
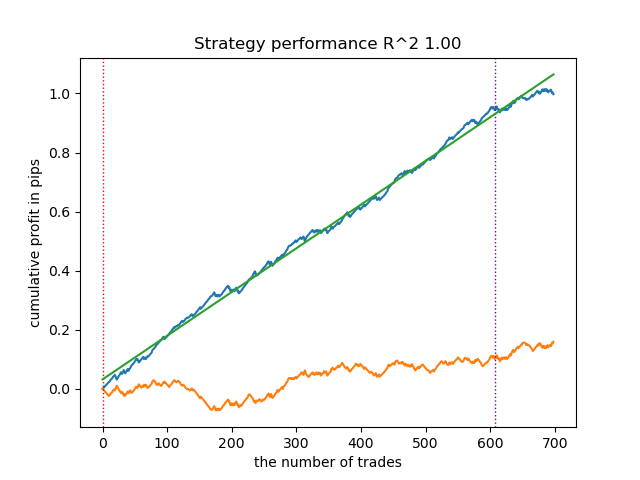
该算法的一个显著特点是:主模型与元模型均以高准确率完成训练。
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.92, 'Logloss': 0.1990666082064606} >>> models[-1][2].get_best_score()['validation'] {'Accuracy': 0.9647435897435898, 'Logloss': 0.10955056411224594}
这就意味着与包含大量噪声数据的原始数据集相比,模型现在已经剔除了绝大部分的不确定性。此外,最终模型还可以进一步校准,以获得更可靠的决策阈值,这部分内容不在本文讨论范围内。
如果将置信水平从0.9降低到0.6,会发生什么?我们会得到更多包含真实标签的预测集合(置信概率为60%),这一点会在报告中体现出来。
Learn 8 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 28647 Multi-element sets (meta_labels=0): 991 Correct predictions (meta_labels=1): 16999 Incorrect predictions (meta_labels=0): 12639 R2: 0.9850582205528567
在上一个案例中,单类别预测集合的样本数量较少,而如今其数量已经超过了多类别集合。但此时交易获利的置信度大幅下降。资金净值曲线也体现出这种不确定性,出现了更多回撤。
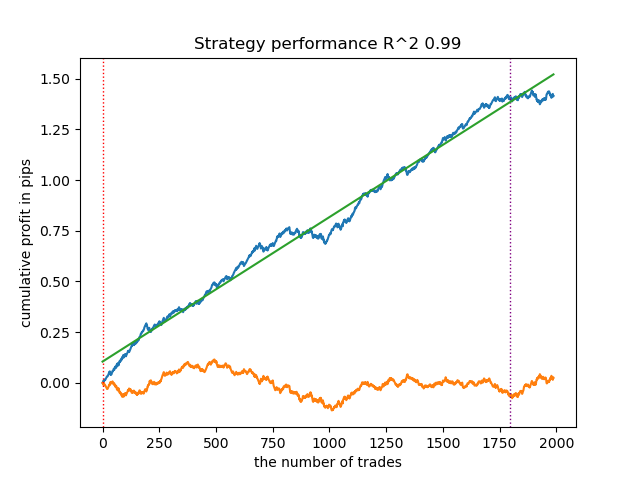
因此,通过调整模型的置信水平,能够管控交易失利带来的各类风险。我们可以在交易频次、交易收益以及黑天鹅事件发生概率之间找到平衡。
在MetaTrader 5终端中导出并测试模型
模型导出的操作方式与此前所有文章介绍的完全一致,如需了解详细步骤可参阅往期内容。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
现在,我们在MetaTrader 5终端中测试该算法。这套交易系统不仅在样本外预测区间表现稳定,在 2017至2020年的历史行情中同样运行良好。
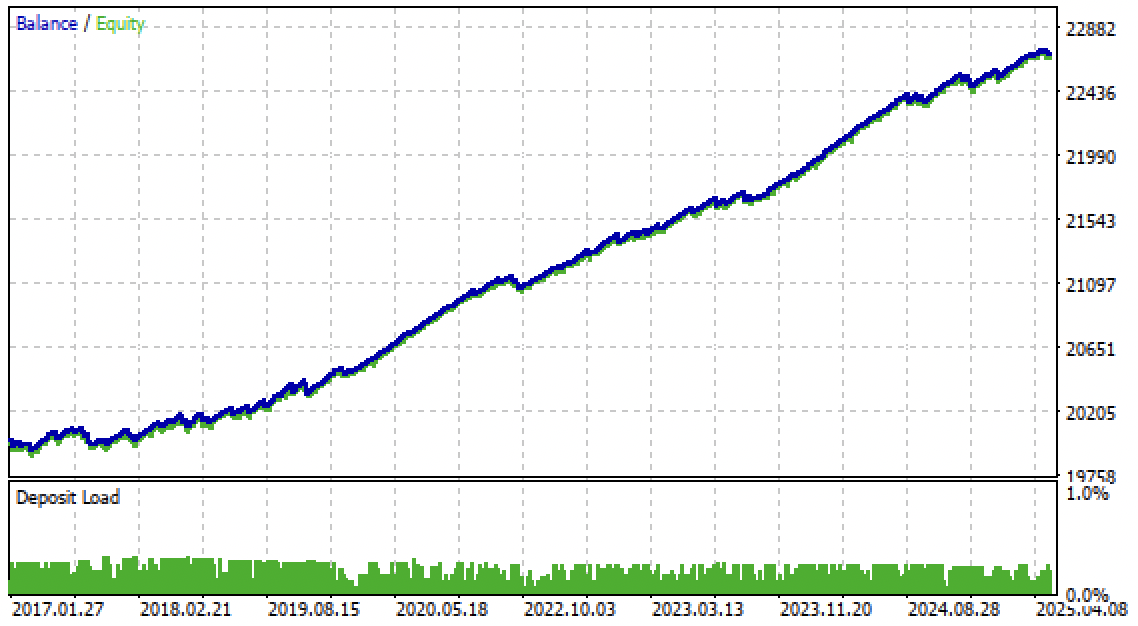
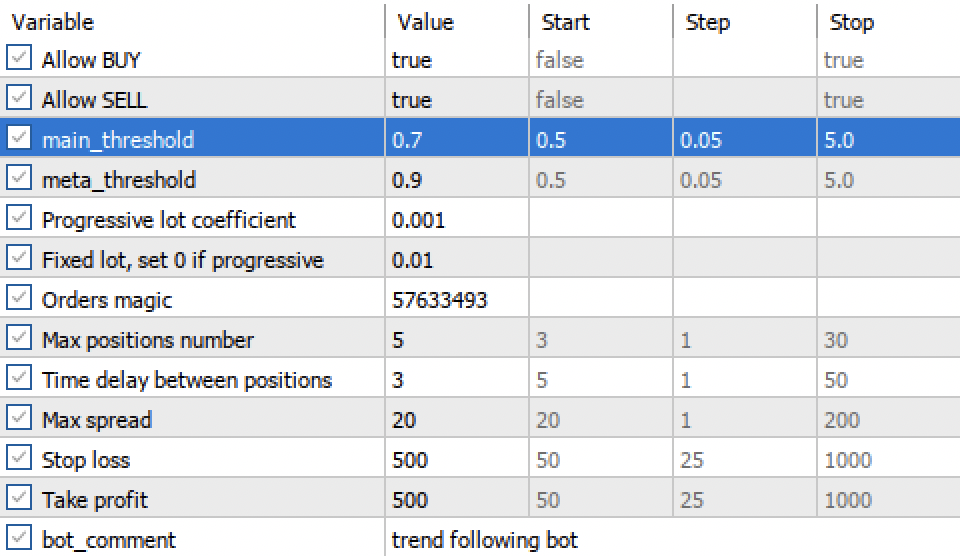
现有的主阈值与元阈值设置,可依据置信度筛选模型交易信号。阈值设置越高,交易的确定性越强,但对应的交易次数也会随之减少。
结论
本文介绍了保形预测以及实现该算法的MAPIE库。这是一种较新的机器学习方法,重点不在于发现数据规律,而在于为现有模型提供风险管理与不确定性量化能力。保形预测本身并非用于挖掘数据中的规律,而仅用于评估现有模型对特定样本预测的置信度,并筛选出可靠的预测结果。这一重要特性,让我们能够在模型训练阶段通过调整置信阈值来管控交易风险。
Python files.zip压缩包内包含以下适用于Python环境开发的文件:
| 文件名 | 描述 |
|---|---|
| mapie causal.py | 训练模型的主脚本 |
| labeling_lib.py | 更新版交易标签模块 |
| tester_lib.py | 基于机器学习的更新版自定义策略测试器 |
| export_lib.py | 将模型导出至交易终端的模块 |
| EURUSD_H1.csv | 由MetaTrader 5终端导出的报价文件 |
MQL5 files.zip压缩包内含适用于MetaTrader 5终端的相关文件:
| 文件名 | 描述 |
|---|---|
| mapie trader.ex5 | 来自本文的编译后的EA |
| mapie trader.mq5 | 来自本文的EA源代码 |
| Include//Trend following folder | ONNX模型以及用于连接EA的头文件 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18324
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
你好,我想你忘了附加 fixing_lib 模块。该模块已在 mapie_causal.py 文件中导入。
干得好非常感谢你的贡献。我做了一些改动,现在一切正常。