
市場シミュレーション(第23回):SQL入門(VI)

はじめに
前回の「市場シミュレーション(第22回):SQL入門(V)」では、主キーを外部キーとどのように使用するか、より正確にはどのように関連付けるかについて説明しました。この点がまだ十分に理解できていない場合は、先にこれまでの記事をお読みいただくことをお勧めします。本記事でおこなう内容を正しく理解するためには、その前提知識が必要です。
クエリ結果の理解
前回の記事では、主キーと外部キーの利用方法を説明するために、小規模なデータベースを作成しました。しかし、この構成に対してクエリを実行すると、期待していたものとはかなり異なる結果が返される場合があります。これをより分かりやすくするために、次のコードを使用してデータベースを照会してみます。
SELECT * FROM tb_Quotes;
コード01
結果を以下に示します。
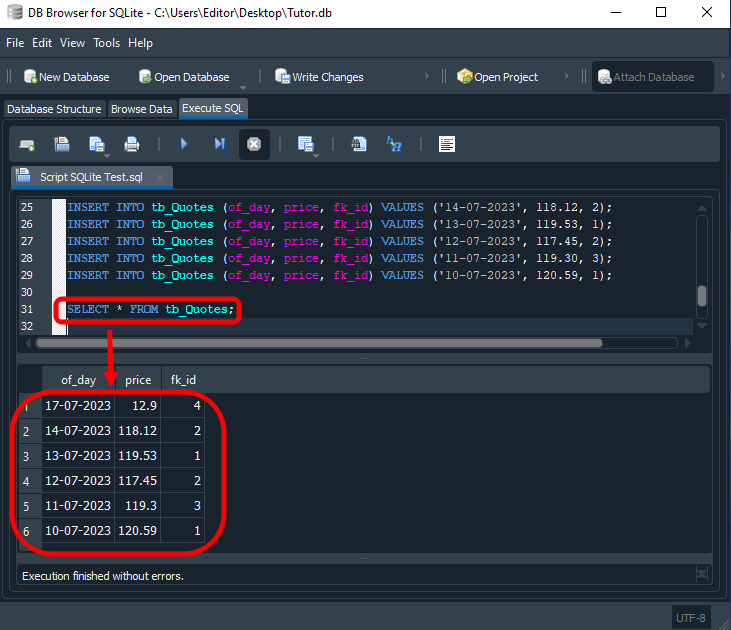
図01
ここで、「何か間違ったことをしたのだろうか」と疑問に思うかもしれません。答えは「何も間違っていません」です。多くの人がデータベースで外部キーを使用しない理由は、まさにこの種のキーの背後にある概念を理解していないためです。その結果、非リレーショナルなデータベースを作ってしまい、保守や設計がかえって複雑になります。また、SQLが処理しなければならない作業量や負荷も増加してしまいます。
SQLの大きな強みの一つは、一見すると独立しているように見えるテーブル同士を関連付けられることです。より正確には、それぞれのテーブルに格納された値同士を関連付けることができます。これにより、SQLが普及する以前から存在していた大きな問題の一つである「データの重複」を回避できます。現時点では、データの重複がデータベースにどれほど悪影響を及ぼすのか実感しにくいかもしれません。しかし実際には、アプリケーション向けのデータベースを構築する際にSQLを利用する最大の利点の一つを失わせてしまうほど深刻な問題となり得ます。
データベースダイアグラムの可視化
データベースダイアグラムを可視化するためのツールは数多く存在し、それぞれ搭載されている機能も異なります。本記事で説明に使用しているDB Browserでは、少なくとも執筆時点では、この種の図を生成することはできません。もっとも、DB Browserはオープンソースであり、GitHubを通じて継続的に更新されているため、本記事をお読みいただく頃には、この機能がすでに利用可能になっているかもしれません。代替手段としては、DBeaverを使用できます。このソフトウェアには無償版が用意されており、比較的簡単にダウンロードして利用できます。DBeaverをインストールしたら、以下の手順に従ってデータベースダイアグラムを表示します。
図02
下記に示すように、新しいウィンドウが開きます。
図03
ここでは、表示するデータベースの種類を選択する必要があります。本記事ではSQLiteを使用していることを思い出してください。以下のようにSQLiteを見つけて選択します。

図04
これで準備は完了です。次の画面が表示されます。
図05
ここでは、開くデータベースのパスとファイル名を入力します。以下の例を参考にしてください。
図06
入力が完了したら、[Finish]をクリックします。すると、最終的な画面が表示されます。
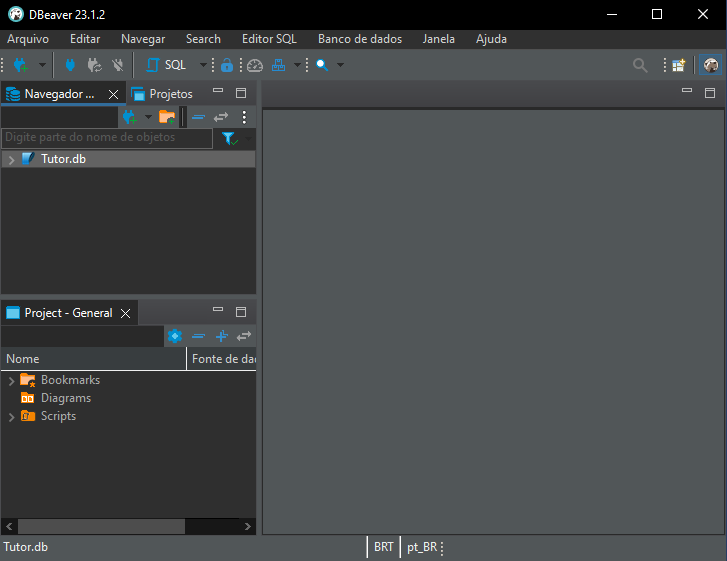
図07
すべての手順が正しく実行されていれば、結果は図07のようになり、データベースが利用可能な状態で表示されます。続いて、以下で強調表示されている項目をクリックして、データベースダイアグラムを開きます。
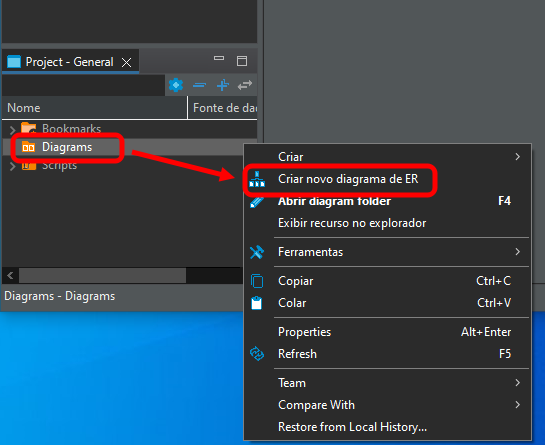
図08
すると、次のウィンドウが表示されます。
図09
図のように新しいダイアグラム名を入力します。名前は何でも構いません。
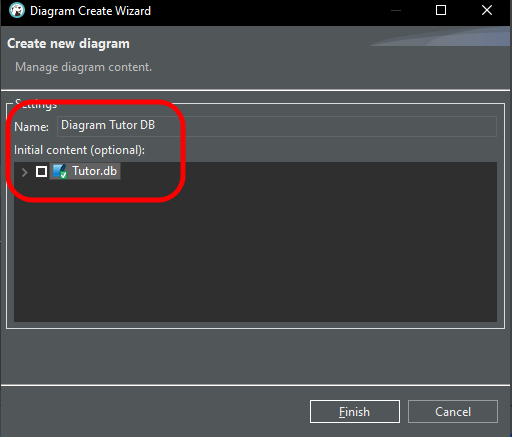
図10
最後に、[Finish]ボタンをクリックすると、次の結果が表示されます。
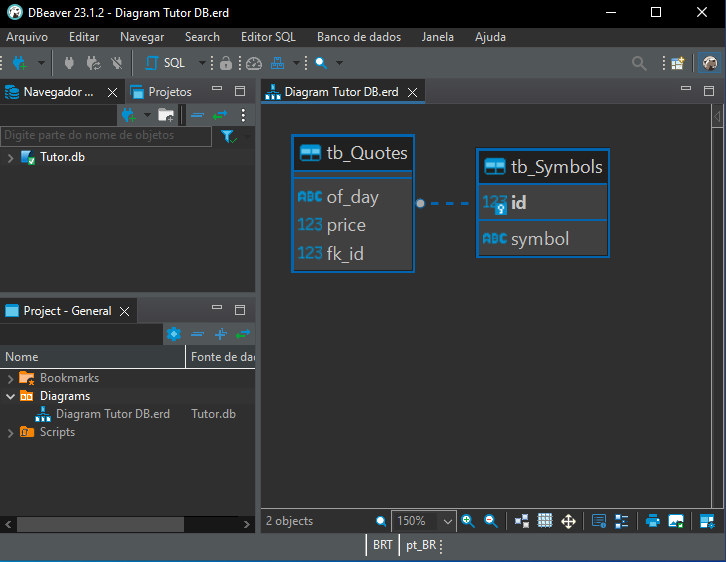
図11
図の解釈
図11には、tb_Quotesテーブルとtb_Symbolsテーブルの関係が明確に示されています。最初は、これが1対1の関係であり、tb_Symbolsの各レコードに対してtb_Quotesに対応するレコードが1件だけ存在すると考えるかもしれません。実際、そのようなケースも存在します。しかし、図の中にある点に注目してください。小さな違いですが非常に重要です。以下の図では、注目すべき箇所を示しています。
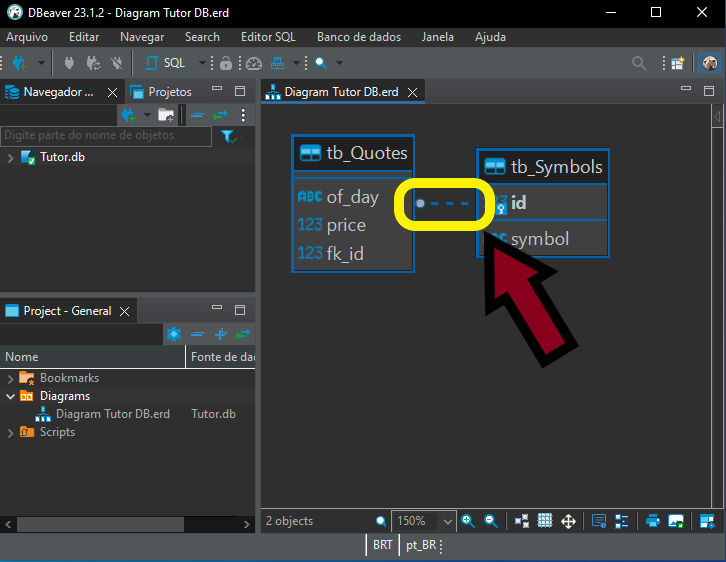
図12
一方の端には小さな円があり、もう一方にはそのような印はありません。この違いに注意してください。これは何を意味しているのでしょうか。これは、両テーブルが1対多の関係にあることを示しています。つまり、円が付いている側では、反対側のテーブルの1件のレコードに対して複数のレコードを関連付けることができます。この関係を正しく読み取れるようになると、より適切なSQLクエリを作成できるようになります。また、データベース構造の変更も容易になり、ミスを減らすことができます。
これは非常に重要です。なぜなら、あるテーブルのレコードが他のテーブルから何度も参照される可能性がある場合、新しいデータの追加、レコードの削除、あるいはデータベース情報の更新を行うためのトリガーを、より適切に設計できるようになるからです。ただし、この話題については別の機会に詳しく取り上げます。現時点では、この種のリレーションシップがデータベースの内容を正しく把握するうえでどのように役立つのかを理解することが重要です。
SQLでデータを扱う
ここまでは、データベースダイアグラムの作成について見てきました。ここからはDB Browserに戻ります。なお、MetaEditorを使用しても、ここで示すものと同じ結果を得ることができます。ただし、データベースを照会するためのコードは若干異なります。今回使用するコードは以下のとおりです。
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes, tb_Symbols;
コード02
ところが、このスクリプトを実行するとSQLは24件のレコードを返します。なぜでしょうか。その理由を見ていきましょう。以下の図に示されている出力結果を確認してください。
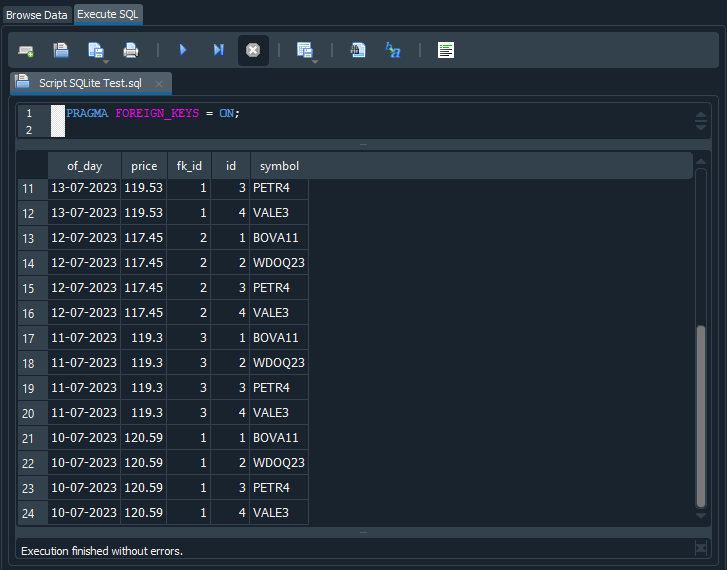
図13
17行目から20行目にかけて、同じ価格の値と日付が繰り返し表示されていることが分かります。つまり、SQLはこのSELECT文を、tb_Quotesとtb_Symbolsの内容を組み合わせるよう求める命令として解釈したのです。その結果、tb_Quotes側の値は繰り返し表示される一方で、tb_Symbols側の値は変化しています。tb_Quotesには6件のレコードがあり、tb_Symbolsには4件のレコードが存在するため、両テーブルを単純に組み合わせると24件のレコードが生成されます。これで、なぜSQLが24件のレコードを返すのか理解できたのではないでしょうか。
ここで、図13をもう少し注意深く見てみましょう。一部の行では、fk_idの値がidの値と一致しています。興味深い現象ですね。なぜこのようなことが起こるのでしょうか。fk_idに格納されている値は、どのレコードを参照すべきかを示しています。図12に戻ると、idはtb_Symbolsに属しており、fk_idはtb_Quotesに属していることが分かります。
ここで必要になるのが、エイリアスと呼ばれる仕組みです。つまり、各テーブルに別名を付けることで、一方のテーブルともう一方のテーブルを関連付けられるようにします。これにより、SQLに結果セットをどのように組み立てるべきかを明示的に伝えることができます。エイリアスを使用する際には、予約語の使用は避けてください。SQLの実装によっては問題なく扱える場合もありますが、一般的には他のSQLプログラマの混乱を避けるためにも、予約語をエイリアスとして使用しないことが推奨されます。新しいコードは以下の通りです。
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * 32. FROM tb_Quotes AS tq, tb_Symbols AS ts 33. WHERE tq.fk_id = ts.id;
コード03
このコードを実行すると、以下の図に示すような結果が得られます。
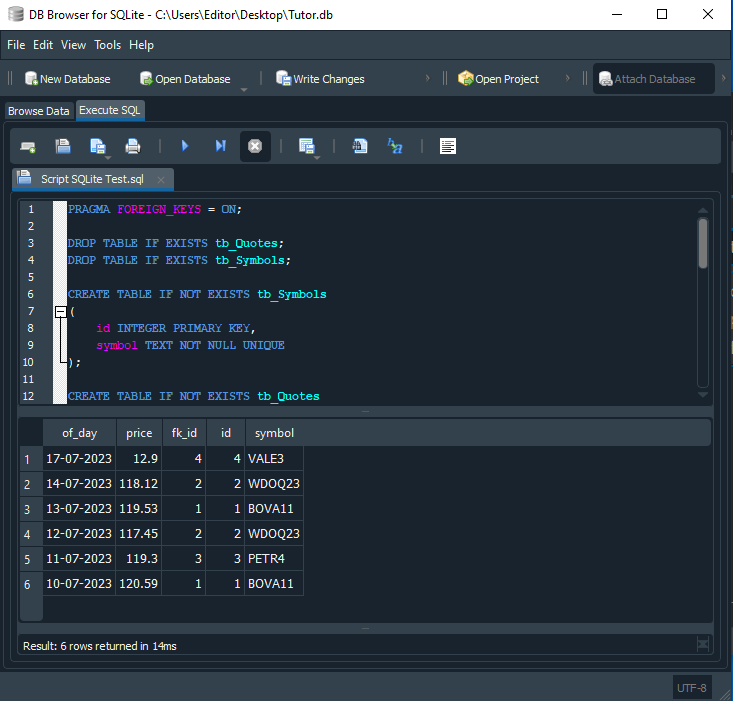
図14
まるで魔法のように、今度は期待どおりの結果が返されます。つまり、銘柄名、日付、価格を含む6件の価格レコードが表示されます。では、なぜこのような結果になるのかを見ていきましょう。スクリプトの32行目では、各テーブル名の後ろにエイリアスを追加しています。
33行目では、2つのテーブルをどのように関連付けて正しい結果を返すかをSQLに指示しています。ここで使用しているWHERE句は、結果セットを絞り込むための条件を定義しています。この例では、tb_Quotesのfk_idの値とtb_Symbolsのidの値が一致した場合、その行を結果に含めるよう指定しています。そのため、SELECT文では先ほど説明した組み合わせが候補になりますが、WHERE句によるフィルタリングによって、SQLは実際に必要な行だけを返すようになります。
ここで、先ほどの説明について少し補足しておきます。厳密に言えば、SQLが必ずしもすべての行の組み合わせを物理的に順番に走査しているわけではありません。実際には、SQLエンジンはクエリを実行するためのより効率的な実行計画を選択します。もし単純な方法ですべての組み合わせを調べていたら、システム全体の性能はあっという間に低下してしまうでしょう。実際には、SQLは一方のテーブルを起点として処理を開始し、その後、比較や照合に必要なフィールドをもう一方のテーブルから参照します。この仕組みによって、クエリははるかに効率的に実行されます。
さらに、SQLクエリの出力結果はもっと改善できます。列名は見づらかったり分かりにくかったりすることがあり、また、図14で確認したように、SQLが不要な列まで返してしまう場合もあります。では、この余分な情報を取り除くにはどうすればよいのでしょうか。方法は非常に簡単です。必要な列だけをSQLに指定し、それぞれに表示したい名前を与えればよいのです。そこで、次のスクリプトを見ていきましょう。
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Quote Date', 32. tq.price AS 'Current Price', 33. ts.symbol AS 'Asset Name' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id;
コード04
結果は以下のとおりです。
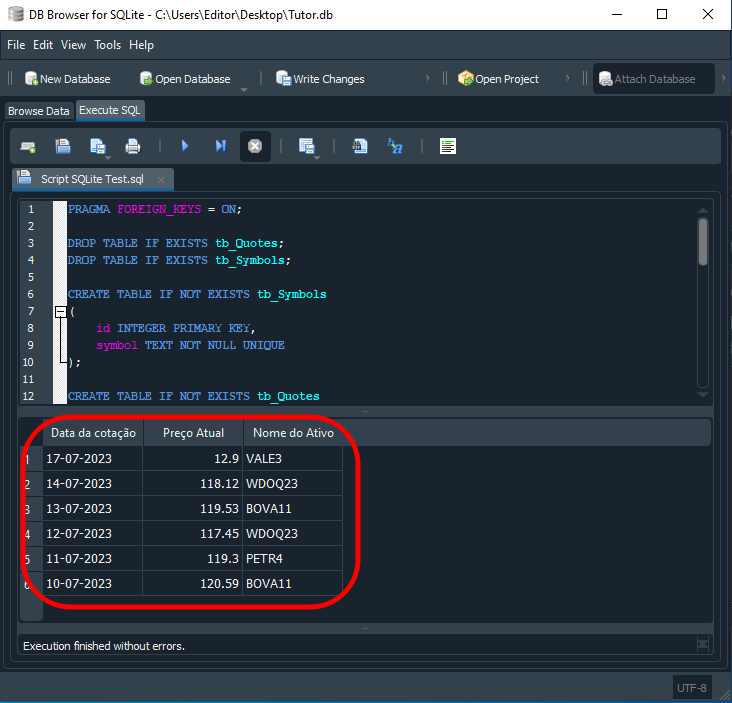
図15
「なるほど。SQLは思っていたものとはかなり違うのですね。ただ意味のない命令を並べたものだと思っていましたが、実際にはとても興味深いものだと分かってきました。」もっとも、ここまでの内容はまだほんの導入にすぎません。多くの人は、取得したデータをさらに加工するには外部プログラムが必要だと考えています。しかし実際には、そのような処理の多くをSQLの中で直接おこなうことができます。たとえば、データを価格の高い順に並べ替え、最後に価格の低いものが来るようにしたいとします。その場合は、次のようなコードを使用できます。
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Quote Date', 32. tq.price AS 'Current Price', 33. ts.symbol AS 'Asset Name' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id 36. ORDER BY price DESC;
コード05
SQLでコード05を実行した結果を以下に示します。
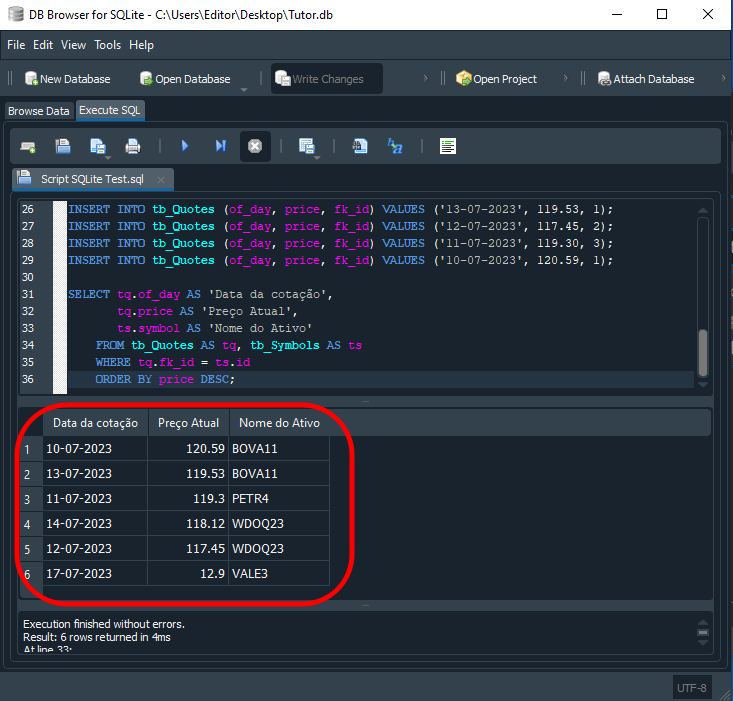
図16
レコードを扱う際の注意点
「市場シミュレーション(第19回):SQL入門(II)」では、UPDATE文やDELETE文を使用してレコードを変更または削除する方法について説明しました。これらの方法は確かに機能します。しかし、リレーショナルデータベースを扱ううえでは、必ずしも最適な方法とは言えません。なぜなら、複数のテーブルが相互に関連付けられている場合、このような方法はエラーの原因になりやすいからです。この問題を理解するために、再びコード05に戻ってみましょう。29行目までは、データベースを作成し、その中にデータを挿入しています。ここではデータの内容が正しいかどうかは重要ではありません。目的は単純にデータベースを作成することです。その後、31行目のSELECTクエリを実行すると、次のような結果が得られます。
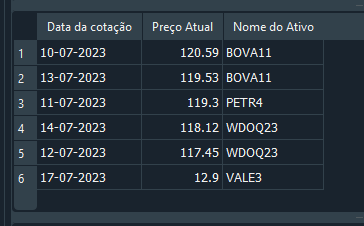
図17
ここで、あるレコードに誤った情報が含まれていることに気付きます。データベース全体を作り直したり、該当レコードを削除したりする代わりに、UPDATE文を使用して値を修正することにしましょう。これは次のようにおこないます。
1. UPDATE tb_Quotes SET price = 29.58 WHERE fk_id = 3; 2. 3. SELECT tq.of_day AS 'Quote Date', 4. tq.price AS 'Current Price', 5. ts.symbol AS 'Asset Name' 6. FROM tb_Quotes AS tq, tb_Symbols AS ts 7. WHERE tq.fk_id = ts.id 8. ORDER BY price DESC;
コード06
そして、以下のような結果が得られました。
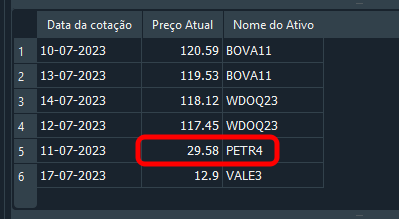
図18
これでレコードは更新されました。SQLの扱い方はもう理解できた、と満足しているかもしれません。しかし、データベースへデータを挿入しているコード05を見直してみると、PETR4に対応するレコードは1件しか存在していないことが分かります。この場合、その情報は簡単に変更したり削除したりできます。では、少し考えてみましょう。もしPETR4ではなく、WDOQ23のレコードを変更する必要があるとしたらどうでしょうか。どうすればよいでしょうか。おそらく、多くの人はすぐに次のように答えるでしょう。「簡単です。次のコマンドを使えばよいでしょう。」
01. UPDATE tb_Quotes 02. SET price = 119 03. WHERE fk_id = 2 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Quote Date', 07. tq.price AS 'Current Price', 08. ts.symbol AS 'Asset Name' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
コード07
今回も正解です。結果は以下のようになります。この方法が機能したのは、fk_idとof_dayの両方を条件として使用し、対象となる行を絞り込んだからです。
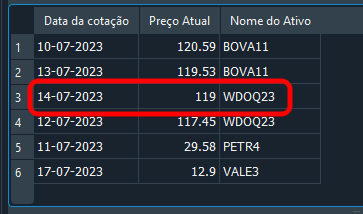
図19
リレーショナルデータベースにおけるレコードの更新
リレーショナルデータベースを編集する方法は一つではありませんが、その中でも有効な方法の一つは、それぞれのSQLコマンドが何をおこなうのかを正確に理解することです。別の言い方をすると、SQLコマンドを理解していないと、SQLは非常に制約の多いものだと考えてしまうかもしれません。しかし、その仕組みを理解すれば、実に多くのことが実現できます。ここで言う「多くのこと」とは、本当に多くのことです。私はこれまで、SQLだけで処理できる問題を解決するために、わざわざ外部プログラムのコードを書いている人を数多く見てきました。そうしたケースの多くは、SQLの仕組みを十分に理解していないことが原因です。それでは、前のセクションと同じ更新処理を、今度はfk_idの値を手動で入力することなく実現する方法を見ていきましょう。
ここで、「では、非リレーショナルなテーブル構造を使うのか」と思われるかもしれません。いいえ、その必要はありません。引き続きリレーショナルデータベースの考え方を使用します。前のセクションと同じ目的を達成するために、コード07を以下のように更新します。
01. UPDATE tb_Quotes 02. SET price = 4985.5 03. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Quote Date', 07. tq.price AS 'Current Price', 08. ts.symbol AS 'Asset Name' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
コード08
「ずいぶん大胆な書き方ですが、本当に動くのでしょうか。こんなやり方は見たことがありません。」そう思うのも無理はありません。しかし、結果は以下のとおりです。
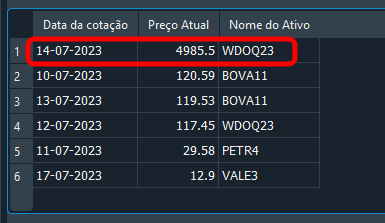
図20
ここでは、動作確認のためにあえて少し異なる値を使用しています。では、ここで疑問が生まれます。このコードは一体どのように動作しているのでしょうか。このコードでは、fk_idや参照先のIDを一切指定していません。それにもかかわらず、正しいレコードが更新されています。私たちは銘柄名と対応する日付のみを指定しています。ここが重要なポイントです。各レコードには固有の日付が存在しますが、現実的に考える必要があります。同じ日付であっても、データベース内には異なる銘柄と異なる価格を持つ複数のレコードが存在し得ます。そのため、日付と銘柄の両方でフィルタリングすることで条件をより正確に絞り込めるため、目的のレコードを正確に取得できるようになります。
気づかなかったかもしれませんが、ここまででこのコードの動作原理はすでに説明されています。もし完全に理解できていなくても心配する必要はありません。こうした概念は最初は難しいものです。それでは、コード08の処理を丁寧に見ていきましょう。このUPDATE文は複数行に分割されています。これは意図的なものであり、処理内容を分かりやすく説明するためです。
まず01行目では、tb_Quotesテーブルのレコードを更新することを宣言しています。もしここでUPDATEではなくDELETEを使用していた場合、そのレコードはテーブルから削除されることになります。したがって、この説明は削除処理にもそのまま適用できます。02行目では、どの列を更新するのか、そして更新後にどの値を設定するのかを指定しています。ここまでは比較的理解しやすい部分です。03行目では、予約語WHEREを使用してフィルタ条件を定義し、SQLに対象レコードの特定方法を指示しています。ここは特に重要であり、多くの初心者が混乱するポイントです。
各コマンドはある意味で関数のように振る舞い、値を返します。その返される値は単一の値の場合もあれば、複数のフィールドを含むテーブル状の結果の場合もあります。たとえばSELECT文は、この例のように単一の値を返すこともできますし、06行目のように複数の値を含むテーブル形式の結果を返すこともできます。
フィルタ条件が十分に具体的であり、かつ適切なテーブルに対して適用されている場合、SELECT文は一意の値を返します。その結果は、ほとんど変数のように扱うことが可能になります。「しかし、SQLiteでは変数を使用できないんですよね?」確かにその通りです。しかし、SQL全体の観点で見れば、値を変数のように扱う方法は存在します。SQLiteに限らずSQLの仕組みを理解すれば、このような扱いは実質的に可能になります。ただし、この点は後ほどさらに明確になります。関連テーブルを扱う場合、データベースの整合性を保つために追加の手順が必要になるからです。
話を戻しましょう。03行目では、銘柄名としてWDOQ23を指定しています。これによりSQLはtb_Symbolsテーブルを参照することになります。では何を探しているのでしょうか。それはts.idの値です。つまり、クエリ実行後、SELECT文は銘柄名がWDOQ23である行のidを返します。そしてSQLは、その値を別のテーブルの更新対象レコードを特定するために使用します。これがすべてでしょうか。はい、これがまさにここでおこなっていることです。そしてミスを起こす可能性ははるかに低くなります。
しかし、すべてが完璧というわけではありません。銘柄名として存在しないものを指定してしまう可能性があります。これは一見すると異常なケースのように思えるかもしれませんが、実際にはそのような状況は実務では非常に一般的です。その結果、コード08はこの状況を正しく処理できません。より明確に言うと、SQLはエラーや、コマンドが意図と異なる形で解釈されたことを必ずしも通知しません。単に、すべてが正常に処理されたと思い込んでしまう可能性があります。なぜなら、私たちが目にする唯一の出力は06行目のSELECT文の結果だからです。
この段階では、なぜこれが問題なのか分からないかもしれません。もし実装がエラーを報告しなければ、すべてが正しく動作しているという錯覚に陥る可能性があります。しかし後になってデータを検索したり利用しようとしたとき、期待していた状態ではないことに気づくかもしれません。そしてその時には、問題を特定し修正するために必要な情報がすでに失われている場合もあります。
レコードが更新されたかどうかの確認
SQLiteには、更新したいと考えていたレコードの値が実際に更新されたかどうかを比較的簡単に確認する方法が用意されています。そのためには、小さなコードが必要になります。ただしコードに進む前に、考えておくべきことがあります。データベースに対してレコードを更新した後、あるいは追加した後に、SELECT文を実行してすべてが正しくおこなわれたかを確認する、という方法は一般的によく知られています。この方法には小さな問題があります。データベースが小さい場合、あるいは変更が少ない場合には、SELECTを使って更新内容を確認することは確かに合理的です。しかし、特に複数人で共有されるデータベースでは、更新された複数のレコードをSELECTで逐一確認することは必ずしも簡単ではありません。
幸いなことに、共有データベースは通常サーバ上で動作するため、そのような用途でSQLiteが使われることは、一般にはあまり多くありません。それでもSQLiteであっても、数百、数千単位のレコードを更新する必要がある場合はあります。そのような状況を想像してみてください。SELECTを使って一件ずつ確認し、正しく更新されたかを確認する作業は非常に大きな負担になります。そのため、ここでは少し異なるアプローチが必要になります。個々のレコードをSELECTで確認する方法は、データベースに小さな変更を加える場合にのみ適しています。
一方で、処理量や操作数が増えるにつれて、別の方法が必要になります。これから紹介する方法に加えて、ほぼ同等の別の方法も存在しますが、それについては後ほど説明します。ここではまず、SQLiteで「要求したレコード更新が実行されたかどうか」をどのように確認するかに集中しましょう。
比較的シンプルな解決方法があります。ただし誤った使い方をすると問題が発生する可能性があるため注意が必要です。デモコードは以下の通りです。
1. UPDATE tb_Quotes 2. SET price = 4987.5 3. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 4. AND of_day = '14-07-2023'; 5. 6. SELECT changes() 'Updated Records';
コード09
このコードを実行すると、次の結果が表示されます。
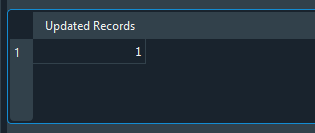
図21
結果が「1」という値になっていることに注目してください。なぜでしょうか。それはUPDATE文がデータベース内で1件の更新、つまり1件の変更を実行したためです。もし数百、あるいは数千件の更新を実行した場合には、この表示値はUPDATE文によって変更された行数に対応します。しかし、次の点を考えてみてください。もし以下のようにコードが変更されていた場合、結果は異なります。同じ図の中で確認できます。
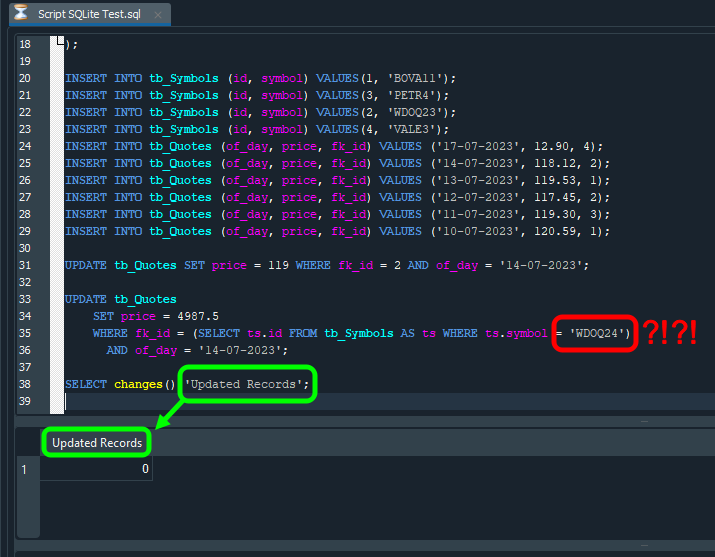
図22
この図では、前のバージョンからの変更点が赤で強調されています。銘柄名だけが変更されていることに注目してください。この銘柄は存在しないため、SELECT文は使用すべきidを特定することができません。その結果、UPDATE文は一行も更新しません。その後、変更された行数を確認するためにSELECTを実行すると、期待した値とは異なる結果が返されます。この場合の値は0です。つまり、UPDATEは実行されましたが、更新対象の行が存在しなかったため、実際には何も変更されていません。
また、上図にはもう一つ重要な点があります。緑で強調されている部分です。SQLが返す列名は、SELECT文で指定した情報そのものになっています。この仕組みを知らないと、より複雑な処理をおこなおうとしてしまう可能性があります。しかし実際には、このように単純に制御できる部分もあります。
ただし先ほど述べた通り、このコマンドは直前のUPDATE文によって変更された行数を確認するためのものです。SQLiteはローカルでユーザーが管理するデータベースを構築できるため、これとはまったく異なるアプローチも可能です。
知らない方のために補足すると、SQLiteはGitHubリポジトリから直接ダウンロードすることができ、そのソースコードを改変して標準とは少し異なる動作をさせることも可能です。本連載記事の目的はその方法を説明することではないため、ここでは事実として触れるにとどめます。使用しているSQLiteの実装によっては、更新や挿入時のエラー処理がここで示した方法とは大きく異なる場合があります。つまり最適な方法を選択するためには、使用している実装のドキュメントを確認する必要があります。
次のトピックに進む前に、今回使用した更新確認の方法についてもう少し詳しく見ておきましょう。この場合、SELECT changes()は直前のUPDATE文の結果のみを返します。次のコード断片を考えてみます。
1. UPDATE tb_Quotes SET price = 119 WHERE fk_id = 2 AND of_day = '14-07-2023'; 2. 3. UPDATE tb_Quotes SET price = 4987.5 WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ24') AND of_day = '14-07-2023'; 4. 5. SELECT changes() 'Updated Records';
コード10
ここでは2つのUPDATE文を実行しています。当然ながら、同じスクリプト内で両方が実行されているため、累積結果のようなものを期待するかもしれません。しかし実際にはそうはなりません。03行目を注意深く見ると、画像22のコードと一致していることが分かります。新しく追加されたのは01行目だけです。したがって、03行目のUPDATE文は実行されているものの、実際には一行も影響を与えていません。これは確実にそうなるでしょう。そのため05行目を実行したときに、非ゼロの値が返されると予想するかもしれません。しかし実際にコードを実行すると、SQLは0を返します。いったい何が間違っていたのでしょうか。01行目と03行目の両方が失敗したのでしょうか。いいえ、そうではありません。01行目は1行を変更しており、03行目のUPDATE文も実行されていますが、影響を与えた行はありません。
なぜでしょうか。それは、01行目の結果を確認する前に、03行目で別のSQLリクエストを送信してしまったからです。そのため、SQLに「何が起きたのか」を問い合わせると、直近のUPDATE文の結果だけが報告されます。つまり、03行目が実行されたが影響を与えた行は0である、という結果だけが返されるのです。このため、スクリプトが期待どおりに動作する理由、あるいは動作しない理由を長時間考え込んでしまう人がいます。最終的に問題となるのは、たいていの場合「仮定を置いてしまっていること」です。プログラミングにおいて仮定は良い結果をもたらすことはほとんどありません。つまり、何かが起こると想定するのではなく、それが実際に起こったことを必ず確認すべきです。したがって、仮定に頼ってはいけません。すべてが正しく動作していることを確認し、その後で他のすべてを責めるようにしてください。
最後に
いずれにせよ、関連するデータベースやテーブルを使用する際には、対処すべき別の問題があります。たとえば、私たちのシステムでは、あるテーブルに銘柄名を保存し、別のテーブルに価格データを保存しています。このようなスキーマは、複数の密接に関連したテーブル間で多くの関係を持つため、さらに複雑になる可能性があります。これらはすべて主キーと外部キーによって処理されます。
問題の大きさ、あるいは今後の難しさをイメージするために、次のシナリオを考えてください。将来的に、ある銘柄を使用する価値がなくなったため、その銘柄の使用を停止することにしたとします。このような決定は早かれ遅かれ下される可能性があります。主な問題、そしてまさに困難が始まる点は次の通りです。その銘柄のレコードをデータベースからどのように削除するのか、ということです。多くの人は、その解決策は簡単だと言うでしょう。ループを作るか、SQLクエリを実行してレコードを削除すればよい、と。確かにそれは、1つの巨大なレコードテーブルで構成されたデータベースで作業している場合にはおおよそその通りです。しかしそれは、私の考えでは完全に無謀です。ただし、それは問題ではありません。自分が何をしているのかを理解しているのであれば問題ありません。
特定の銘柄のすべてのレコードを削除するSQLクエリを書くことは非常に簡単です。必要なのはDELETEコマンドだけであり、その構文はUPDATEと非常によく似ています。この点は些細なため、ここでは扱いません。しかし、データベースが1つのテーブルではなく、複数の関連テーブルで構成されている場合はどうでしょうか。その場合、特定の銘柄に関連するすべてのレコードをどのように削除するのでしょうか。ここで状況は少し複雑になります。
ここで、私たちが使用しているスキーマについて考えてください。もしtb_Symbolsから銘柄名を削除した場合、以下のコマンドで返される結果には必ず影響が出ます。
SELECT tq.of_day AS 'Quote Date', tq.price AS 'Current Price', ts.symbol AS 'Asset Name' FROM tb_Quotes AS tq, tb_Symbols AS ts WHERE tq.fk_id = ts.id ORDER BY price DESC;
コード11
| ファイル | 説明 |
|---|---|
| Experts\Expert Advisor.mq5 | Chart TradeとEAの連携を示す(Mouse Studyが必要) |
| Indicators\Chart Trade.mq5 | 送信する注文を設定するウィンドウを作成する(Mouse Studyが必要) |
| Indicators\Market Replay.mq5 | リプレイ/シミュレーションサービスとやり取りするためのコントロールを作成する(Mouse Studyが必要) |
| Indicators\Mouse Study.mq5 | グラフィカルコントロールとユーザー間の操作を提供する(再生/シミュレーションシステムと実運用時の市場取引の両方に必要) |
| Services\Market Replay.mq5 | 市場リプレイ/シミュレーションサービス(システム全体のメインファイル)を作成および維持する |
| Code VS C++\Servidor.cpp | C++で開発されたサーバーソケット(ミニチャット版)を作成および維持する |
| Code in Python\Server.py | MetaTrader 5とExcel間の通信用のPythonソケットを作成および維持する |
| Indicators\Mini Chat.mq5 | インジケーターを介してミニチャットを実装できるようにする(動作にはサーバーが必要) |
| Experts\Mini Chat.mq5 | EAを介してミニチャットを実装できるようにする(動作にはサーバーが必要) |
| Scripts\SQLite.mq5 | MQL5でSQLスクリプトを使用する方法を示す |
| Files\Script 01.sql | 外部キーを持つシンプルなテーブルを作成する方法を示す |
| Files\Script 02.sql | テーブルに値を追加する方法を示す |
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/12987
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索