
Untersuchung von Conformal Prediction bei Finanzzeitreihen
Einführung
MAPIE (Model Agnostic Prediction Interval Estimator) ist eine Open-Source-Python-Bibliothek, die zur Quantifizierung von Unsicherheiten und zum Umgang mit Unsicherheit und zur Risikosteuerung beim Einsatz von ML-Modellen entwickelt wurde. Sie ermöglicht die Berechnung von Vorhersageintervallen für Regressionsprobleme sowie Vorhersagemengen für Klassifikationsaufgaben und Zeitreihenanwendungen. Diese Unsicherheitsbewertung wird auf der Grundlage eines speziellen „Kalibrierungsdatensatzes“ von Daten durchgeführt.
Einer der Hauptvorteile von MAPIE ist seine Modellunabhängigkeit. Das bedeutet, dass die Bibliothek mit jedem Modell verwendet werden kann, das mit der API scikit-learn kompatibel ist, einschließlich Modellen, die mit TensorFlow oder PyTorch entwickelt wurden, sofern entsprechende Wrapper verwendet werden. Diese Eigenschaft vereinfacht die Integration in bestehende Analysepipelines erheblich, da Händler je nach Anlageklasse oder Handelsstrategie häufig eine Vielzahl von Modellen des maschinellen Lernens einsetzen, die von traditionellen statistischen Ansätzen bis zu komplexen neuronalen Netzen reichen. Die Möglichkeit, bewährte Modelle nahtlos zur Einbeziehung von Unsicherheitsquantifizierung zu nutzen, senkt die Implementierungskosten erheblich und beschleunigt die Einführung, was in einem dynamischen Finanzumfeld besonders wertvoll ist.
Die Bibliothek ist Teil des scikit-learn-contrib-Ökosystems und basiert auf konformer Vorhersage und verteilungsunabhängiger Inferenz. Es setzt wissenschaftlich begutachtete Algorithmen um, die modell- und anwendungsunabhängig sind und theoretische Garantien bieten, wobei nur minimale Annahmen hinsichtlich der Daten und des Modells getroffen werden. Über die Standardklassifizierung hinaus ist MAPIE auch in der Lage, bei komplexeren Aufgaben eine Risikokontrolle zu ermöglichen, indem probabilistische Garantien für Metriken wie Recall und Präzision bereitgestellt werden.
Die Fähigkeit, Risiken zu steuern und probabilistische Garantien zu liefern, macht MAPIE nicht nur zu einem Instrument zur Quantifizierung von Unsicherheiten, sondern zu einem umfassenden Rahmen für das Risikomanagement. In der Finanzwelt reichen Punktvorhersagen nicht aus, da sie weder das Konfidenzniveau noch das potenzielle Fehlerrisiko widerspiegeln. Eine garantierte Abdeckung, etwa von 95 %, lässt sich direkt in ein quantifizierbares Risiko übersetzen. Dadurch können Risikomanager explizite Risikotoleranzen festlegen.
Wenn das Modell beispielsweise ein Kaufsignal generiert, die konforme Vorhersage (Conformal Prediction, CP) jedoch auf eine hohe Fehlerwahrscheinlichkeit hindeutet, kann der Risikomanager beschließen, die Position zu reduzieren oder den Handel zu unterlassen, wodurch er den potenziellen Verlust direkt begrenzt. Dies ermöglicht eine fundiertere Entscheidungsfindung unter Unsicherheit, die über die reine Vorhersagegenauigkeit hinausgeht.
Grundprinzipien der konformen Vorhersage: modellunabhängige Garantien, unabhängig von der Verteilung
Die konforme Vorhersage ist ein statistisches Verfahren, das Vorhersagemengen für Klassifikationsprobleme oder Vorhersageintervalle für Regressionsprobleme mit garantierten Abdeckungswahrscheinlichkeiten generiert. Das bedeutet, dass bei einem bestimmten Konfidenzniveau, 90 %, der wahre Wert in mindestens 90 % der Fälle innerhalb des vorhergesagten Bereichs oder Intervalls liegt.
Der entscheidende Vorteil von CP liegt darin, dass es „verteilungsunabhängig“ ist: Die Methode stützt sich nicht auf strenge Annahmen hinsichtlich der zugrunde liegenden Verteilung der Daten oder des Modells selbst. Die einzige grundlegende Annahme ist, dass die Daten (Trainings- und Testpunkte) austauschbar sind, das heißt, sie stammen aus derselben Verteilung, und ihre Reihenfolge spielt keine Rolle.
Diese Annahme ist schwächer als die Annahme der Unabhängigkeit und identischen Verteilung (i.i.d.) und lässt sich in der Praxis oft rechtfertigen. Im Gegensatz zu herkömmlichen Vorhersageintervallen, die die Abdeckungsrate nur annähernd bestimmen können, bietet das CP Garantien für endliche Stichproben und stellt sicher, dass die festgelegte Abdeckungsrate auch bei begrenzten Datenmengen erreicht wird.
Die verteilungsunabhängige Garantie der konformen Vorhersage geht direkt auf das grundlegende Problem der Finanzmodellierung ein. Finanzdaten sind bekanntermaßen nicht normalverteilt, weisen „schwere Enden“ auf und verstoßen häufig gegen typische statistische Annahmen wie Homoskedastizität oder Unabhängigkeit der Inkremente.
Herkömmliche Vorhersageintervalle stützen sich häufig auf solche Annahmen, wie etwa normalverteilte Residuen, und bieten daher nur eine ungefähre Abdeckung. Die Fähigkeit des CP, die garantierte Abdeckung ohne solche Annahmen zu gewährleisten, macht CP für Finanzanwendungen robuster und vertrauenswürdiger, bei denen falsch spezifizierte Verteilungen zu einer erheblichen Unterschätzung des Risikos führen können. Das bedeutet, dass die angegebenen Konfidenzniveaus bei komplexen Finanzdatensätzen aus der Praxis zuverlässiger sind.
Bei der konformen Vorhersage wird in der Regel ein trainiertes Modell des maschinellen Lernens verwendet, ein Kalibrierungsdatensatz erstellt (der dem Modell während des Trainings nicht bekannt war), auf diesem Datensatz werden „Konformitätswerte“ berechnet und anschließend anhand des Quantils dieser Werte die Vorhersagemengen bestimmt. Der Übergang von der ungefähren Abdeckung zur garantierten Abdeckung bei endlicher Stichprobengröße verändert die Rahmenbedingungen für die Regulierung und das Risikomanagement von Modellen des maschinellen Lernens im Finanzsektor grundlegend.
In risikoreichen Branchen wie dem Finanzsektor müssen Modelle häufig quantitative Robustheit und die Beherrschung der Fehlerquoten nachweisen. Dies unterscheidet sich von herkömmlichen statistischen Methoden, bei denen ein „90-prozentiges Konfidenzniveau“ möglicherweise nur eine asymptotische Eigenschaft oder eine Annäherung darstellt. Für einen quantitativen Händler bietet dies eine solidere Grundlage für die Begründung von Handelsstrategien oder die Zuweisung von Risikokapital.
Vorhersagemengen im Vergleich zu Punktvorhersagen bei der binären Klassifizierung
Herkömmliche binäre Klassifikationsmodelle geben entweder eine einzelne Vorhersage (z. B. „Kaufen“ oder „Verkaufen“) oder einen Wahrscheinlichkeitswert (z. B. 0,8 für „Kaufen“) aus. Dies sind Punktvorhersagen. Die konforme Vorhersage liefert jedoch eine Vorhersagemenge, die eine Teilmenge der möglichen Klassen darstellt (zum Beispiel {Kaufen}, {Verkaufen} oder {Kaufen, Verkaufen}). Diese Vorhersagemenge enthält mit einer bestimmten Wahrscheinlichkeit garantiert das korrekte Label.
Bei der binären Klassifizierung kann die Vorhersagemenge wie folgt aussehen:
- Eine einzige Klasse (z. B. {Kaufen} oder {Verkaufen}), die auf ein hohes Konfidenzniveau hindeutet.
- Beide Kategorien (z. B. {Kaufen, Verkaufen}), die auf Unsicherheit oder Mehrdeutigkeit hindeuten.
- Eine leere Menge {} (auch wenn dies bei der Verwendung bestimmter Methoden wie APS seltener vorkommt und oft unerwünscht ist), die auf extreme Unsicherheit hinweist oder darauf, dass keine Klasse die Konfidenzschwelle erreicht.
Die „Informativität“ einer Vorhersagemenge ist umgekehrt proportional zu ihrer Größe: Kleinere Vorhersagemengen (z. B. eine Klasse) sind informativer als größere Sätze (z. B. beide Klassen). Die explizite Ausgabe eines Satzes anstelle eines einzelnen Punktes verändert die Entscheidungsfindung bei der binären Klassifizierung im Finanzbereich grundlegend. Anstelle eines einfachen Ja-/Nein- oder Kauf-/Verkaufssignals liefert die Vorhersagemenge einen direkten Maßstab für die Zuverlässigkeit des Modells.
Eine Vorhersagemenge mit nur einer Klasse wie {Kaufen} deutet auf ein starkes Signal hin, während eine Zwei-Klassen-Menge {Kaufen, Verkaufen} auf erhebliche Unklarheit hindeutet. Dies ermöglicht eine differenziertere Handelsstrategie: Bei Signalen mit hoher Zuverlässigkeit werden Trades eingegangen, während bei unklaren Signalen entweder abgewartet, die Positionsgröße reduziert oder weitere Informationen eingeholt werden. Es handelt sich um einen direkten Mechanismus zur Einbeziehung von Unsicherheiten in effektive finanzielle Entscheidungen.
Der „Informationsgehalt“ von Vorhersagesätzen wird zu einem direkten Maßstab für Effizienz und Risikotoleranz im Finanzhandel. Eine breite, wenig aussagekräftige Vorhersagemenge (z. B. {Kaufen, Verkaufen}) für eine Transaktion bedeutet, dass das Modell nicht in der Lage ist, mit der gewünschten Konfidenz zwischen einem Kauf und einem Verkauf zuverlässig zu unterscheiden. Für einen quantitativen Analysten ist dies kein Vorhersagefehler, der korrigiert werden müsste, sondern ein Signal, keine Maßnahmen zu ergreifen oder mit äußerster Vorsicht vorzugehen. Dies ermöglicht ein dynamisches Risikomanagement: Es wird mehr Kapital für Geschäfte mit engen, äußerst zuverlässigen Sätzen bereitgestellt, während Kapital geschont wird, indem das Engagement bei Geschäften mit breiten, unsicheren Sätzen vermieden oder minimiert wird. Dies führt unmittelbar zu einer Optimierung des Risiko-Ertrags-Profils der Handelsstrategie.
Theoretische Garantien: marginale und bedingte Abdeckung
Konforme Prädiktoren sind insofern „automatisch gültig“, als ihre Vorhersagemengen im Durchschnitt über alle Beobachtungen hinweg eine Abdeckungswahrscheinlichkeit aufweisen, die mindestens einem vorgegebenen Konfidenzniveau (1 – α) entspricht. Diese Garantie gilt unabhängig vom zugrunde liegenden Modell oder der Datengenerierung, sofern die Austauschbarkeitsannahme erfüllt ist. Diese Eigenschaft wird als marginale Abdeckung bezeichnet.
Zwar ist eine Mindestabdeckung gewährleistet, es handelt sich jedoch um einen Durchschnittswert. Strengere Konzepte, wie die bedingte Gültigkeit, zielen auf Abdeckungsgarantien ab, die auf bestimmten Dateneigenschaften beruhen (z. B. nach Klasse, nach Objekt, nach Bezeichnung). Induktive konforme Prädiktoren (rechnerisch effiziente Version) steuern in erster Linie die bedingungslose Abdeckungswahrscheinlichkeit. Um bedingte Validität zu erreichen, sind oft methodische Anpassungen erforderlich.
Der Unterschied zwischen marginaler und bedingter Abdeckung ist für die finanzielle binäre Klassifizierung von entscheidender Bedeutung, insbesondere angesichts der in der Finanzwelt häufig anzutreffenden unausgewogenen Datensätze (z. B. viele „No Deal“- oder „Hold“-Signale im Vergleich zu weniger „Buy“- oder „Sell“-Signalen).
Die marginale Abdeckung gewährleistet, dass im Durchschnitt 90 % der Vorhersagen zutreffen. Sind Kaufsignale jedoch selten, kann das Modell eine marginale Abdeckung von 90 % erreichen, wobei es bei Verkaufssignalen sehr genau ist, bei Kaufsignalen jedoch schlecht abschneidet. Dies kann zu erheblichen verpassten Chancen oder Verlusten führen, wenn Kaufsignale entscheidend sind.
Durch bedingte Abdeckung, insbesondere klassenweise Abdeckung, wird sichergestellt, dass für jede Klasse einzeln das gewünschte Konfidenzniveau erreicht wird. Dies ist entscheidend, um die Zuverlässigkeit von Vorhersagen sowohl für Kauf- als auch für Verkaufsgeschäfte zu gewährleisten und systematische Verzerrungen zu vermeiden, die eine Handelsstrategie untergraben können.
Das Streben nach bedingter Validität unter Verwendung von Methoden wie der „Mondrian Conformal Prediction“ adressiert unmittelbar Fragen der Fairness und Zuverlässigkeit bei unterschiedlichen Ergebnisklassen in Finanzanwendungen. In der Finanzwelt können Vorhersagefehler in bestimmten Fällen (z. B. bei einer seltenen, aber äußerst profitablen Kaufgelegenheit oder einem entscheidenden Verkauf zur Vermeidung hoher Verluste) im Vergleich zu Vorhersagefehlern in häufigeren „No-Deal“-Szenarien unverhältnismäßig hohe Kosten verursachen.
Mit bedingter Abdeckung garantiert das System für jede Art von Transaktion ein Mindestmaß an Zuverlässigkeit und nicht nur einen Durchschnittswert. Dies ermöglicht eine gerechtere Behandlung verschiedener Handelssignale und stärkt das Vertrauen in die Fähigkeit des Modells, mit einer Vielzahl von Marktbedingungen und seltenen Ereignissen umzugehen, was für einen robusten algorithmischen Handel unerlässlich ist.
Konformitätswerte: das Herzstück der konformen Vorhersage
Konformitätswerte bilden den Kern der konformen Vorhersage; sie geben an, wie „ungewöhnlich“ oder „abweichend“ ein neuer Datenpunkt im Vergleich zu den Kalibrierungsdaten ist. Die einzige Anforderung an die Bewertungsfunktion ist, dass höhere Werte eine schlechtere Übereinstimmung zwischen den Eingabedaten und ihrer hypothetischen Klassifizierung widerspiegeln sollten. Anhand dieser Schätzwerte wird aus dem Kalibrierungssatz ein Quantil (Grenzwert) berechnet, das dann als Vorhersagemenge für neue Testpunkte dient.
MAPIE verwendet verschiedene Konformitätsmaße, darunter symmetrische (z. B. den absoluten Residualwert für Regressionen) und asymmetrische (z. B. den Gamma-Wert für Regressionen), die Einfluss darauf haben, wie die Grenzen des Vorhersageintervalls berechnet werden. Für die Klassifikation werden spezifische Konformitätsscores wie LAC, APS und RAPS verwendet.
Die Wahl der Konformitätsbewertung ist nicht nur ein technisches Detail, sondern vielmehr eine strategische Entscheidung, die sich auf die praktische Verwendbarkeit und Interpretierbarkeit von Vorhersagemengen auswirkt. Unterschiedliche Konformitätswerte (z. B. LAC, APS) führen zu unterschiedlichen Verhaltensweisen bei der Erstellung von Vorhersagemengen.
Beispielsweise kann LAC bei hoher Unsicherheit leere Mengen erzeugen, was im Finanzbereich unerwünscht sein kann, da dies keine Orientierungshilfe bietet. APS vermeidet von Grund auf leere Mengen, indem es stets eine Reihe plausibler Ergebnisse bereitstellt. Das bedeutet, dass die Wahl des Bewertungsmaßstabs direkten Einfluss darauf hat, wie „schlechte“ Beispiele dargestellt werden und ob das System stets eine brauchbare, wenn auch vage, Antwort liefern kann. Ein quantitativer Trader sollte ein Konformitätsmaß wählen, das dem gewünschten Informationsgehalt und der Risikotoleranz entspricht.
Das Konzept der „Konformität“ ermöglicht es uns, im Rahmen der Vorhersagen eines datengestützten Modells „Ausreißer“ oder „ungewöhnliche“ Beobachtungen zu identifizieren, was für die Erkennung abnormaler Handelsbedingungen von großer Bedeutung ist. An den Finanzmärkten können ungewöhnliche Kursbewegungen, plötzliche Volumensprünge oder unerwartete Nachrichten zu Datenpunkten führen, die erheblich von historischen Mustern abweichen.
Ein hoher Konformitätswert für eine neue Beobachtung würde darauf hindeuten, dass die Beobachtung „nicht zu den in den Kalibrierungsdaten festgestellten Mustern passt“. Dies kann als Frühwarnsystem für Marktanomalien oder Regimewechsel dienen und eine Überprüfung der Handelsstrategie bzw. eine vorübergehende Aussetzung des automatisierten Handels auslösen. Damit stellt es ein wichtiges Instrument des Risikomanagements dar, das über die reine Modellgenauigkeit hinausgeht.
Eine eingehende Betrachtung der für die Klassifizierung relevanten Konformitätswerte
MAPIE bietet verschiedene Konformitätsbewertungen an, die jeweils ihre eigenen Merkmale und Anwendungsbereiche haben.
- Least Ambiguous Set-valued Classifier (LAC):
- Berechnung: Der Konformitätswert ist definiert als 1 – softmax_score_of_the_true_label.
- Eigenschaften: Ein einfacher Ansatz, der theoretisch eine marginale Abdeckung gewährleistet. Dies führt in der Regel zu kleinen Vorhersagemengen.
- Anwendungsbereich/Einschränkungen: Neigt dazu, leere Vorhersagemengen zu bilden, wenn die Modellunsicherheit hoch ist (z. B. in der Nähe von Entscheidungsgrenzen). Dies kann im Finanzbereich problematisch sein, da eine leere Menge keine umsetzbare Handlungsempfehlung liefert.
- Adaptive Vorhersagemengen (APS):
- Berechnung: Die Konformitätswerte werden berechnet, indem die nach Rang geordneten Softmax-Werte jeder Klassifizierung von der höchsten zur niedrigsten addiert werden, bis die tatsächliche Klassifizierung erreicht ist.
- Eigenschaften: Löst das Problem leerer LAC-Mengen; Vorhersagemengen sind per Definition nicht leer. Bietet Garantien für marginale Abdeckung.
- Geltungsbereich: Dies ist für Finanzanwendungen robuster, da dort eine Vorhersage (auch wenn sie unsicher ist) stets einer leeren Menge vorzuziehen ist.
- Regularisierte adaptive Vorhersagemengen (RAPS):
- Berechnung: Ähnlich wie APS, enthält jedoch einen Regularisierungsterm, um die Größe der Vorhersagemengen zu verringern.
- Eigenschaften: Zielt darauf ab, ein Gleichgewicht zwischen Abdeckung und Effizienz herzustellen, indem die Größe der Vorhersagemenge reguliert wird, während die Abdeckungsgarantien beibehalten werden.
- Geltungsbereich: Nützlich in Situationen, in denen die Größe der Vorhersagemenge (Effektivität) ebenso wichtig ist wie die Abdeckung, da kleinere Sätze im Handel effektiver sind.
- Mondrian-Konforme Vorhersage:
- Berechnung: Diese Methode berechnet für jede Klasse einzelne Quantile der Konformitätswerte. Dadurch können klassenbezogene Vorhersagen in die Menge aufgenommen werden.
- Eigenschaften: Bietet für jede Klasse eine bedingte Abdeckung (1 - α), was für unausgewogene Mehrklassen- oder Binärprobleme von entscheidender Bedeutung ist.
- Geltungsbereich: Besonders empfehlenswert für die binäre Klassifizierung im Finanzbereich (Kauf/Verkauf), bei der die Klassen möglicherweise unausgewogen sind (z. B. weniger „Kauf“-Signale als „Halten“- oder „Verkauf“-Signale) oder unterschiedliche Fehlertoleranzen aufweisen. Dadurch wird sichergestellt, dass die Zuverlässigkeit des Kaufsignals unabhängig vom Verkaufssignal gewährleistet ist.
Die Entwicklung der Konformitätswerte von LAC zu APS/RAPS spiegelt den praktischen Bedarf an effektiven und aussagekräftigen Vorhersagemodellen für Anwendungen in der Praxis wider. Obwohl LAC vom Konzept her einfach ist, stellt seine Neigung zur Bildung leerer Mengen einen erheblichen finanziellen Nachteil dar. Eine leere Vorhersagemenge für eine Kauf-/Verkaufsentscheidung bietet keine Orientierungshilfe und bringt den Entscheidungsprozess damit praktisch zum Stillstand. APS und RAPS stellen durch die Gewährleistung nicht leerer Mengen sicher, dass das Modell selbst bei hoher Unsicherheit plausible Ergebnisse liefert, sodass eine Standardentscheidung zum „Beibehalten“ oder „Neubewerten“ getroffen werden kann, anstatt den Prozess vollständig abzubrechen. Dies gewährleistet einen unterbrechungsfreien Betrieb und ein effektives Risikomanagement.
Die Mondrian-Methode stellt einen entscheidenden Fortschritt für die binäre Klassifizierung im Finanzbereich dar und geht direkt auf das Problem unausgewogener Klassen und des unterschiedlichen Einflusses von Fehlern ein. Bei Kauf- und Verkaufsszenarien sind „Kauf“-Signale zwar selten, aber sehr gewinnbringend, während „Verkauf“-Signale zwar häufiger auftreten, einzeln betrachtet jedoch weniger bedeutend sind. Standardmäßige konforme Methoden bieten nur eine marginale Abdeckung, was bedeuten kann, dass die Abdeckung für die seltene „Kauf“-Klasse geringer ist als gewünscht, wenn der Gesamtdurchschnitt erreicht wird. Die Fähigkeit von Mondrian, klassenspezifische Quantile zu berechnen, stellt sicher, dass für jede Klasse das gewünschte Konfidenzniveau gewahrt bleibt.
Dies ist entscheidend, um eine systematische Unterabdeckung kritischer, seltener Ereignisse (wie starke Kaufsignale) zu vermeiden, und führt somit zu zuverlässigeren und potenziell rentableren Handelsstrategien. Dadurch wird sichergestellt, dass die Robustheit des Modells nicht nur ein Durchschnittswert ist, sondern auch für die jeweils betrachtete Transaktionsart gewahrt bleibt.
Schritte zur Bildung konformer Vorhersagemengen für die Klassifizierung
Lassen Sie uns den Ablauf Schritt für Schritt durchgehen:
- Auswahl eines Maßes für die Nichtkonformität (oder einer „Bewertungsfunktion“): Das ist äußerst wichtig. Bei der Klassifizierung wird häufig die Ausgabe eines vortrainierten Klassifikators verwendet (z. B. logistische Regression, Support-Vektor-Maschinen, neuronale Netze oder Random Forest). Sei f(x) die Ausgabe des Klassifikators für die Eingabe x. Wenn f(x) Wahrscheinlichkeiten ausgibt (z. B. aus einer Softmax-Schicht), könnte ein geeigneter Maßstab für die Abweichung eines Datenpunkts (xi, yi) wie folgt lauten:
- 1 – Vorhersagewahrscheinlichkeit der tatsächlichen Klasse: αi = 1 − P^(yi | xi). Hier ist P^(yi ∣xi) die vorhergesagte Wahrscheinlichkeit, dass die Eingabedaten xi die tatsächliche Klassifizierung yi erhalten. Ein kleiner Wert von αi bedeutet, dass das Modell seiner Vorhersage mit hoher Sicherheit vertraut, was auf „Konformität“ hindeutet. Ein hoher αi-Wert bedeutet, dass das Modell weniger zuverlässig ist, was auf eine „Nichtkonformität“ hindeutet.
- Basierend auf der Softmax-Temperaturskalierung: Wenn das Modell Logits ausgibt, kann die Softmax-Funktion angewendet werden, um Wahrscheinlichkeiten zu erhalten. Dann beträgt die Schätzung der Nichtübereinstimmung wieder 1−P(yi ∣xi).
- Abstand zur Entscheidungsgrenze (für SVM): Bei Modellen wie SVM, die einen vorzeichenbehafteten Abstand zur Entscheidungsgrenze ausgeben, kann das Nichtkonformitätsmaß bei korrekt klassifizierten Punkten mit einem negativen Wert dieses Abstands und bei falsch klassifizierten Punkten mit einem positiven Wert dieses Abstands in Verbindung gebracht werden.
- Datenaufteilung für die Kalibrierung: Um Vorhersagen statistisch zuverlässig zu machen, müssen wir unsere Schätzungen der Abweichungen kalibrieren. Dies geschieht in der Regel, indem der ursprüngliche Datensatz in zwei Teile aufgeteilt wird:
- Trainingssatz: Wird zum Trainieren des Basisklassifikators (z. B. neuronales Netz, SVM) verwendet.
- Kalibrierprobe: Ein separater Datensatz, der nicht zum Trainieren des Klassifikators verwendet wird, sondern zur Berechnung von Nichtkonformitätswerten und zur Festlegung der Zuverlässigkeitsschwelle dient.
- Berechnung von Schätzwerten für Abweichungen bei Kalibrierdaten: Für jeden Datenpunkt (xj, yj) in der Kalibrierungsstichprobe wird der Nichtkonformitätswert αj mithilfe eines vortrainierten Klassifikators berechnet.
- Sortieren der Abweichungswerte und Bestimmen des Quantils (1−δ): Alle Abweichungsschätzungen aus der Kalibrierungsstichprobe werden in aufsteigender Reihenfolge sortiert: α(1) ≤ α(2) ≤ ⋯ ≤ α(m), wobei m die Größe der Kalibrierungsstichprobe ist.
Nun wird das gewünschte Signifikanzniveau δ ∈ (0,1) ausgewählt. Dieses δ steht für die Wahrscheinlichkeit, dass die Vorhersagemenge keine echte Markierung enthält. Umgekehrt ist 1−δ die gewünschte Abdeckungswahrscheinlichkeit. Wir müssen das (1−δ)-Quantil dieser Schätzungen ermitteln. Genauer gesagt wird der kleinste Wert von q ermittelt, bei dem mindestens (1−δ) × (m+1) Kalibrierungswerte kleiner oder gleich q sind. Eine gängige Methode zur Berechnung dieses Schwellenwerts: q = α(⌈(m+1)(1−δ)⌉)
Bei endlichen Stichproben ist es jedoch oft zuverlässiger, das für endliche Stichproben angepasste empirische (1−δ)-Quantil zu berücksichtigen, um eine genaue Abdeckung zu gewährleisten. Ein praktischerer Ansatz besteht darin, das kleinste α(k) zu finden, für das k/(m+1) ≥ 1 − δ gilt. Sei dieser Wert q^. - Erstellen einer Vorhersagemenge für einen neuen Testpunkt: Sei xtest die neue Eingabe, für die wir eine Vorhersage treffen wollen. Stellen Sie sich für jedes mögliche Label k aus der Klassenmenge (zum Beispiel 1, 2 …, C bei C Klassen) vor, dass ytest = k ist.
Nun wird der Nichtkonformitätswert von αtest,k für das Paar (xtest, k) unter Verwendung des gewählten Nichtkonformitätsmaßes berechnet (zum Beispiel 1−P^(k∣xtest)).
Die Vorhersagemenge von Ytest für xtest wird gebildet, indem alle k Labels einbezogen werden, für die der Nichtkonformitätswert von αtest,k kleiner oder gleich dem in Schritt 4 bestimmten Schwellenwert q^ ist: Ytest = {k ∈ {1, …, C} | αtest,k ≤ q}
Die wichtigsten Komponenten von MapieClassifier
MapieClassifier ist die Kernklasse in MAPIE zur Erzeugung von Vorhersagemengen bei Klassifizierungsproblemen. Es ist so konzipiert, dass es mit jedem scikit-learn-Estimator (Schätzer) kompatibel ist, der über die Methoden „fit“, „predict“ und „predict_proba“ verfügt. Wird kein Estimator angegeben, wird standardmäßig „LogisticRegression“ verwendet.
Der Parameter „cv“ ermöglicht die Verwendung verschiedener Kreuzvalidierungsstrategien (z. B. „split“, „crossval“, „prefit“) zur Berechnung von Konformitätswerten und beeinflusst damit den Unterschied zwischen der Jackknife- und der CV-Methode. Die Option „prefit“ geht davon aus, dass der Estimator bereits trainiert wurde, und alle bereitgestellten Daten werden verwendet, um die Vorhersagen durch die Berechnung von Bewertungen zu kalibrieren. Der Prozess umfasst die Aufteilung der Daten in Trainings-, Kalibrierungs- und Testdatensätze, das Trainieren eines Basismodells anhand des Trainingsdatensatzes und anschließend die „Konformalisierung“ des Modells anhand des Kalibrierungsdatensatzes mithilfe von MAPIE.
Die Option „cv=‘prefit‘“ ist besonders praktisch für Finanzanwendungen, bei denen Modelle häufig kontinuierlich trainiert oder anhand großer Datensätze neu angepasst werden. Beim Echtzeit- oder Hochfrequenzhandel werden Modelle häufig anhand von Streaming-Daten aktualisiert oder trainiert. Die Möglichkeit, ein vortrainiertes Modell zu verwenden und es anschließend mit einem separaten Datensatz zu kalibrieren, bedeutet, dass der rechenintensive Trainingsschritt für die konforme Vorhersage nicht wiederholt werden muss. Dadurch lässt sich die Unsicherheitsquantifizierung effizient und ohne nennenswerte Verzögerungen in bestehende Hochleistungs-Handelssysteme integrieren.
Der Parameter „method“ (der inzwischen zugunsten von „conformity_score“ veraltet ist) gibt die Methode für die konforme Vorhersage an. Die Entfernung des Parameters „method“ zugunsten von „conformity_score“ stellt einen Schritt in Richtung größerer Modularität und expliziterer Kontrolle über den zugrunde liegenden Mechanismus der konformen Vorhersage dar. Diese architektonische Lösung ermöglicht es den Anwendern, genau zu bestimmen, wie die „Diskrepanz“ für ihr spezifisches Problem gemessen wird. Bei Finanzdaten, bei denen bestimmte Arten von Fehlern oder Unsicherheiten von größerer Bedeutung sein können (z. B. die falsche Einstufung als „Kauf“ statt als „Verkauf“), ermöglicht diese Modularität eine Feinabstimmung des Prozesses zur Quantifizierung von Unsicherheiten, um ihn besser an spezifische Finanzrisikokennzahlen oder Handelsziele anzupassen. Dies ermöglicht fortgeschrittenen Benutzern, die konforme Vorhersage über die vordefinierten Methoden hinaus anzupassen.
Schlussfolgerungen zum theoretischen Teil und Empfehlungen
Die MAPIE-Bibliothek ist ein leistungsstarkes Werkzeug zur Quantifizierung von Unsicherheiten in Modellen des maschinellen Lernens, insbesondere im Zusammenhang mit der konformen binären Klassifizierung für Finanzanwendungen. Die Fähigkeit, verteilungsunabhängige Garantien für die Abdeckung bei endlichen Stichproben zu bieten und „gute“ und „schlechte“ Stichproben eindeutig zu identifizieren, verbessert die Zuverlässigkeit und die Risikobewältigung in risikoreichen Finanzumgebungen erheblich.
Die Fähigkeit von MAPIE, sich in jedes scikit-learn-kompatible Modell zu integrieren, sorgt für Flexibilität und senkt die Hürden für die Einführung in bestehenden Finanzsystemen. Der Übergang von Punktvorhersagen zu Vorhersagensätzen ermöglicht differenziertere und fundiertere Entscheidungen, da der Grad der Modellunsicherheit dabei ausdrücklich berücksichtigt wird. Insbesondere die Unterscheidung zwischen marginaler und bedingter Abdeckung ist für Finanzanwendungen von entscheidender Bedeutung, da dort die Zuverlässigkeit von Vorhersagen für seltene, aber kritische Klassen (z. B. starke Kaufsignale) von überproportionaler Bedeutung sein kann.
Empfehlungen:
- Priorität bei der Konformitätsbewertung: Für die binäre Klassifizierung im Finanzbereich wird empfohlen, einen Konformitäts-Estimator wie APS oder RAPS zu bevorzugen, da diese nicht-leere Vorhersagemengen garantieren. Dies gewährleistet die Kontinuität des Entscheidungsprozesses und liefert selbst bei hoher Unsicherheit stets eine handlungsrelevante Aussage.
- Verwendung der konformen Vorhersage von Mondrian: In Fällen mit unausgewogenen Klassen oder wenn eine bedingte Abdeckung bestimmter Transaktionsarten (z. B. seltener Kaufsignale) von entscheidender Bedeutung ist, sollte die Mondrian-Conformal-Prediction-Methode in Betracht gezogen werden. Diese Methode bietet für jede Klasse einzeln Zuverlässigkeitsgarantien und verhindert eine solche systematische Unterabdeckung wichtiger, aber seltener Ereignisse.
- Strenge Validierung von Zeitreihen: Die Anwendung der konformen Vorhersage auf Finanzzeitreihen erfordert eine sorgfältige Validierung und die Berücksichtigung der Verletzung der Austauschbarkeitsannahme. MAPIE verfügt zwar über spezielle Zeitreihen-Tools wie den MapieTimeSeriesRegressor, diese sollten jedoch mit anderen zeitreihen-spezifischen Methoden und strengen Backtesting-Verfahren kombiniert werden, um die Robustheit gegenüber Nichtstationarität und plötzlichen Marktveränderungen sicherzustellen.
- Entwicklung mehrstufiger Handelsstrategien: Es sollten Handelsstrategien entwickelt werden, die die Interpretierbarkeit von Vorhersagedaten nutzen. Dies ermöglicht eine dynamische Anpassung des Risikoengagements: So können Trades mit hoher Sicherheit (Ein-Klassen-Sets) mit dem gesamten Kapital ausgeführt werden, während bei Trades mit geringer Sicherheit (Mehr-Klassen-Sets) die Positionsgröße reduziert, Absicherungsmaßnahmen ergriffen oder ganz darauf verzichtet werden kann.
Praktische Anwendung der MAPIE-Bibliothek
Die MAPIE-Bibliothek implementiert zwei Methoden zur „Anpassung“ von Modellvorhersagen:
- Geteilte konforme Vorhersagen
- Kreuzkonforme Vorhersagen
Bei der ersten Methode werden die Originaldaten in Trainings- und Validierungsuntergruppen aufgeteilt. Die erste Teilmenge dient zum Trainieren des Basisklassifikators, die zweite zum Kalibrieren und zur Ausgabe von Vorhersagemengen. Bei der zweiten Methode wird der Datensatz in mehrere Folds aufgeteilt, wobei Cross-Training und Kalibrierung zum Einsatz kommen. Wir werden gleich die zweite Variante verwenden, da sie dank Kreuzvalidierung zuverlässiger sein dürfte. Für Leser, die mit der Kreuzvalidierung nicht vertraut sind: Dies entspricht im Grunde genommen der Walk-Forward-Validierung.
Zunächst müssen wir das MAPIE-Paket installieren und das Modul importieren:
pip install mapie from mapie.classification import CrossConformalClassifier
Die unten aufgeführten zusätzlichen Bibliotheken sollten ebenfalls installiert und importiert werden.
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_predict from sklearn.model_selection import StratifiedKFold from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from mapie.classification import CrossConformalClassifier from sklearn.ensemble import RandomForestClassifier
Als Nächstes habe ich eine Testfunktion geschrieben, die die konforme Vorhersage implementiert und anschließend anhand der Vorhersagemengen zuverlässige und unzuverlässige Beispiele ausgibt.
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9): dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract features and target feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels'] mapie_classifier = CrossConformalClassifier( estimator=RandomForestClassifier(n_estimators=n_estimators_rf, max_depth=max_depth_rf), confidence_level=confidence_level, cv=5, ).fit_conformalize(X, y) predicted, y_prediction_sets = mapie_classifier.predict_set(X) y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) # Calculate set sizes (sum across classes for each sample) set_sizes = np.sum(y_prediction_sets, axis=1) # Initialize meta_labels data['meta_labels'] = 0.0 # Mark labels as "good" (1.0) only where prediction set size is exactly 1 data.loc[set_sizes == 1, 'meta_labels'] = 1.0 # Report statistics on prediction sets empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}") # Return the dataset with features, original labels, and meta labels return data[feature_columns + ['labels', 'meta_labels']]
Wir werden den Random Forest aus scikit-learn als Basisklassifikator verwenden, da das MAPIE-Paket alle Klassifikatoren aus diesem Paket unterstützt. Random Forest ist ein recht leistungsstarkes Modell mit flexiblen Einstellungsmöglichkeiten, aber Sie können auch ein anderes Modell verwenden, das Sie für Ihre Aufgaben als geeignet erachten. Dazu sollten wir im markierten Code einen beliebigen anderen Klassifikator als Estimator übergeben. Es ist anzumerken, dass dieser Klassifikator lediglich zur Ausgabe von Vorhersagesätzen verwendet wird, während CatBoost weiterhin als endgültiges Modell trainiert wird.
Schauen wir uns die Funktion meta_learners_mapie() Schritt für Schritt an.
Definition einer Funktion und ihrer Parameter:
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9):
Die Funktion nimmt drei Argumente entgegen:
- n_estimators_rf – Anzahl der Bäume im Random Forest, die als Basismodell verwendet werden sollen.
- max_depth_rf – maximale Tiefe jedes Baums im Random Forest.
- confidence_level – Konfidenzniveau für die konforme Vorhersage (Standardwert 0,9, d. h. 90 %). Dieser Parameter bestimmt, wie „breit“ die Vorhersagesätze sein werden.
Laden und Aufbereiten von Daten:
dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
Zunächst werden die Daten geladen und vorverarbeitet.
Es wird davon ausgegangen, dass es drei Hilfsfunktionen gibt:
- get_prices() – Rohdaten (Preise) laden
- get_features() – Extrahiert oder berechnet Merkmale aus den von get_prices() zurückgegebenen Daten
- get_labels() – Erzeugt Zielbezeichnungen auf der Grundlage der Merkmale und des Parameters „markup“ aus dem Wörterbuch „hyper_params“.
Die Daten werden anschließend nach dem Zeitindex sortiert. Es werden nur die Datensätze beibehalten, deren Index zwischen hyper_params['backward'] und hyper_params['forward'] liegt. Mit .copy() wird eine Kopie des gefilterten DataFrame erstellt, um Probleme mit der „SettingWithCopyWarning“ zu vermeiden.
Extraktion von X Merkmalen und der Zielvariablen y:
feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels']
- feature_columns – Erstellen Sie eine Liste mit Spaltennamen, die als Merkmale verwendet werden sollen. Es werden alle Spalten außer der ersten (Index 0) und den letzten beiden berücksichtigt. Dies gilt speziell für die Struktur „data“.
- X – Erstellen Sie einen DataFrame mit Merkmalen, indem Sie Spalten aus „feature_columns“ auswählen.
- y – Erstelle eine Serie mit Zielbezeichnungen aus der Spalte „labels“.
Initialisierung und Training des konformen MAPIE-Klassifikators:
mapie_classifier = CrossConformalClassifier(
estimator=RandomForestClassifier(n_estimators=n_estimators_rf,
max_depth=max_depth_rf),
confidence_level=confidence_level,
cv=5,
).fit_conformalize(X, y)
- Es wird eine Instanz von „CrossConformalClassifier“ aus der MAPIE-Bibliothek erstellt. Dies ist ein Wrapper, der jedem scikit-learn-kompatiblen Modell Funktionen zur konformen Vorhersage hinzufügt.
- Estimator – Als Basismodell (Estimator) wird der „RandomForestClassifier“ aus scikit-learn verwendet. Sie erhält die von der Funktion ermittelten Parameter n_estimators_rf und max_depth_rf.
- confidence_level – verwende das an die Funktion übergebene Konfidenzniveau. cv=5 – gibt an, dass zur Kalibrierung des konformen Prädiktors eine fünffache Kreuzvalidierung verwendet wird. Dies ist der Standardansatz in MAPIE, um Daten in Trainings- und Kalibrierungssätze aufzuteilen.
- .fit_conformalize(X, y) – Die Methode trainiert einen Basis-RandomForestClassifier anhand der Daten (X, y) und kalibriert gleichzeitig den konformen Prädiktor. Nach diesem Schritt ist mapie_classifier bereit, konforme Vorhersagen zu treffen.
Abrufen von Vorhersagen und Vorhersagemengen:
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
mapie_classifier.predict_set(X) – erzeugt zwei Ausgabewerte für X Eingabewerte:
- vorhergesagt – Punktvorhersagen (eine Klasse pro Beispiel), ähnlich wie bei der Standardmethode .predict().
- y_prediction_sets – Hauptausgabe der konformen Vorhersage. Für jede Datenprobe handelt es sich hierbei um ein Array (oder eine Liste von Arrays), das angibt, welche Klassen mit dem angegebenen Konfidenzniveau in der Vorhersagemenge enthalten sind. Eine Vorhersagemenge ist eine Menge von Klassen, die die tatsächliche Klasse mit einer Wahrscheinlichkeit von mindestens „confidence_level“ enthält. Die übliche Form lautet (n_samples, n_classes, 1) oder (n_samples, n_classes), wobei die Werte boolesch (True/False) oder 0/1 sind und angeben, ob die Klasse in der Menge enthalten ist.
Umgang mit vorhergesagten Sätzen:
y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) set_sizes = np.sum(y_prediction_sets, axis=1)
- np.squeeze(y_prediction_sets, axis=-1): Wenn y_prediction_sets am Ende eine zusätzliche Dimension der Größe 1 aufweist (z. B. (n_samples, n_classes, 1)), entfernt diese Operation diese, was zu (n_samples, n_classes) führt.
- set_sizes = np.sum(y_prediction_sets, axis=1): Für jede Stichprobe (entlang der Achse 0) werden die Werte in y_prediction_sets über alle Klassen hinweg (entlang der Achse 1) summiert. Wenn y_prediction_sets die Werte 0 oder 1 enthält, gibt diese Summe die Anzahl der Klassen an, die in der Vorhersagemenge für jedes Beispiel enthalten sind. Das heißt, set_sizes ist ein Array, das die Größen der Prädiktorsätze für jede Beobachtung enthält.
Meta-Labels generieren:
data['meta_labels'] = 0.0 data.loc[set_sizes == 1, 'meta_labels'] = 1.0
- data['meta_labels'] = 0.0: Dem DataFrame „data“ wird eine neue Spalte „meta_labels“ hinzugefügt und auf Null gesetzt.
- data.loc[set_sizes == 1, 'meta_labels'] = 1.0: ein wichtiger Schritt zur Erstellung von Metakennzeichnungen. In den Fällen, in denen die Größe der Vorhersagemenge (set_sizes) genau 1 beträgt (d. h. das Modell sagt genau eine Klasse mit dem angegebenen Konfidenzwert voraus), wird der Wert in der Spalte „meta_labels“ auf 1,0 gesetzt. Das bedeutet, dass das Modell bei diesen Beispielen sehr sicher in Bezug auf die von ihm vorhergesagte Klasse ist. Ist die Vorhersagemenge leer (Größe 0) oder enthält sie mehrere Klassen (Größe ≥ 2), bleibt das Meta-Label bei 0,0.
Bericht über die Statistik der vorhergesagten Sätze:
empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}")
Es werden folgende Mengen berechnet:
- empty_sets – leere Vorhersagemengen (das Modell kann bei dem angegebenen Konfidenzniveau keine Klasse auswählen).
- single_element_sets – Mengen, die genau eine Klasse enthalten (Vorhersagen mit hoher Konfidenz und meta_labels=1).
- multi_element_sets – Mengen, die zwei oder mehr Klassen enthalten (das Modell ist sich bei einer bestimmten Klasse nicht sicher).
Das Ergebnis zurückgeben:
return data[feature_columns + ['labels', 'meta_labels']]
Die Funktion gibt einen DataFrame zurück, der die ursprünglichen Merkmale (feature_columns), die ursprünglichen Labels („labels“) und die neu generierten Meta-Labels („meta_labels“) enthält. Diese Meta-Labels können dann dazu verwendet werden, ein anderes Modell (Metamodell) zu trainieren oder nur die zuverlässigsten Vorhersagen für weitere Maßnahmen auszuwählen.
Letztlich nutzt die Funktion die konforme Vorhersage, um jene Beobachtungen zu identifizieren, für die das Basismodell (Random Forest) eine Vorhersage mit hoher Konfidenz trifft und dabei genau eine mögliche Klasse angibt. Diese Beobachtungen sind mit einem „Meta-Label“ versehen, dessen Wert 1 ist.
Verbesserung der Funktion für konforme Vorhersagen
Nachdem ich die Funktion getestet und die Ergebnisse ausgewertet hatte, kam ich zu dem Schluss, dass sie einen wesentlichen Nachteil aufweist. Das Basismodell leistet zwar hervorragende Arbeit bei der Ableitung der Vorhersagesätze, auf denen das endgültige Metamodell trainiert wird, wird jedoch weiterhin auf dem ursprünglichen Datensatz trainiert, der möglicherweise viele Fehler enthält, wodurch es sich nur schlecht auf neue Daten übertragen lässt. Das Metamodell korrigiert die Fehler des Basismodells, indem es in Situationen hoher Unsicherheit keine Trades zulässt; aufgrund der schwachen Generalisierungsfähigkeit des Basismodells schneidet das gesamte System in einem nichtstationären Markt jedoch weiterhin schlecht ab.
Erinnern wir uns daran, dass wir nach dem Training des MAPIE-Klassifikators zwei Sätze von Labels erhalten: Modellvorhersagen (die Labels selbst) und Vorhersagesätze.
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
Bei der anfänglichen konformen Vorhersagefunktion werden ausschließlich die Vorhersagesätze zum Trainieren des Metamodells verwendet, während das Basismodell anhand der Labels aus dem ursprünglichen Datensatz trainiert wird. Wir können aber auch die Labels für das Basismodell festlegen und nur diejenigen beibehalten, bei denen der MAPIE-Klassifikator das größte Vertrauen hat.
# Initialize meta_labels column with zeros data['meta_labels'] = 0.0 # Set meta_labels to 1 where predicted labels match original labels # Compare predicted values with the original labels in the dataset data.loc[predicted == data['labels'], 'meta_labels'] = 1.0
Im obigen Code vergleichen wir die vorhergesagten Labels mit den ursprünglichen und erstellen eine neue Spalte „meta_labels“, die Einsen enthält, wenn die Labels übereinstimmen, und Nullen, wenn sie nicht übereinstimmen. Wir trainieren den Basisklassifikator dann nur mit den Beispielen, deren Labels übereinstimmen.
Der erste Teil der Trainingsfunktion für das endgültige Modell sieht nun wie folgt aus:
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = X[X.columns[1:-3]] X_meta = dataset[dataset.columns[1:-3]] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = y[y.columns[-3]] y_meta = dataset['conformal_labels']
Somit liefern beide Modelle nach dem Training, das so weit wie möglich auf nichtstationären Zeitreihen basiert, qualitativ hochwertigere Ergebnisse.
Training und Testen des Algorithmus
Um die Methode zu testen, werden wir 10 Modelle in einem Zyklus auf das Währungspaar EURUSD vom Beginn des Jahres 2020 bis zum Beginn des Jahres 2025 trainieren. Die verbleibenden Daten werden für die Vorwärtsperiode.verwendet
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2025, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learners_mapie(15, 5, confidence_level=0.90, CV_folds=5))) Die Funktion meta_learners_mapie wird mit den folgenden Argumenten aufgerufen:
- 15 Entscheidungsbäume im Random Forest (Basisklassifikator)
- 5 – die Tiefe jedes Entscheidungsbaums
- Das Konfidenzniveau des Modells beträgt 90 %
- Die Anzahl der Folds für die Kreuzvalidierung beträgt fünf
Während des Trainings werden folgende Informationen angezeigt:
Learn 9 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 6715 Multi-element sets (meta_labels=0): 22948 Correct predictions (meta_labels=1): 16638 Incorrect predictions (meta_labels=0): 13025 R2: 0.9931613891107195
- Leere Mengen – die Anzahl der leeren Vorhersagemengen, wenn das Modell bei keiner der Klassen eine ausreichende Sicherheit hat
- Einzelelemente – Anzahl der Vorhersagesätze, die ein einzelnes Element enthalten. Das Modell stuft diese Vorhersagen mit einer Wahrscheinlichkeit von 0,9 als zuverlässig ein
- Mehrkomponentensätze – Anzahl der Vorhersagesätze, die mehrere Klassen enthalten. Das Modell ist bei diesen Beispielen unsicher
- Richtige Vorhersagen – die Anzahl der korrekt vorhergesagten Klassifikationen
- Falsche Vorhersagen – die Anzahl der falsch vorhergesagten Klassifikationen
- R2 – Qualitätsmaß für die Saldenkurve
Aus dem vorgelegten Bericht kann geschlossen werden, dass der Datensatz zahlreiche unbrauchbare Daten enthält: 6.715 zuverlässige Vorhersagen gegenüber 22.948 unzuverlässigen. Unser Modell wird jedoch versuchen, dieses Problem zu beheben, und nur zuverlässige Daten verwenden. Entsprechend ergibt sich im Tester folgende Saldenkurve.
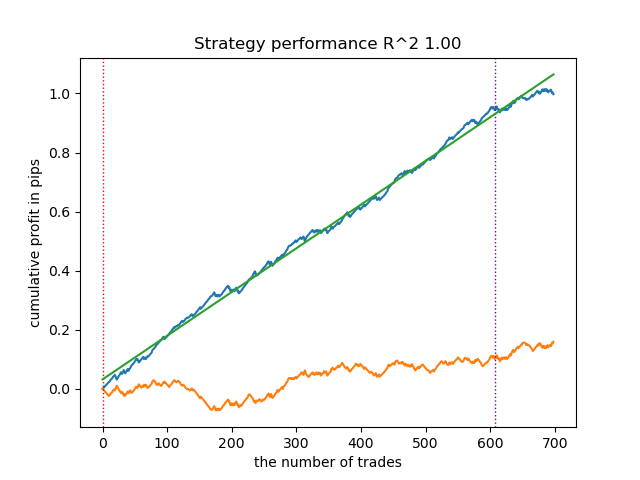
Eine Besonderheit dieses Algorithmus besteht darin, dass beide Modelle (Haupt- und Metamodell) mit hoher Genauigkeit trainiert werden:
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.92, 'Logloss': 0.1990666082064606} >>> models[-1][2].get_best_score()['validation'] {'Accuracy': 0.9647435897435898, 'Logloss': 0.10955056411224594}
Das bedeutet, dass im Vergleich zum ursprünglichen Datensatz, der viele fehlerhafte Daten enthält, ein Großteil der Unsicherheit aus den Modellen beseitigt wurde. Zudem können die endgültigen Modelle kalibriert werden, um zuverlässigere Entscheidungsschwellenwerte zu erhalten; dies würde jedoch den Rahmen dieses Artikels sprengen.
Was passiert, wenn der Konfidenzgrad von 0,9 auf 0,6 gesenkt wird? Wir erhalten mehr Datensätze, die mit einer Wahrscheinlichkeit von 60 % die tatsächliche Klassenbezeichnung enthalten; dies spiegelt sich im Bericht wider.
Learn 8 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 28647 Multi-element sets (meta_labels=0): 991 Correct predictions (meta_labels=1): 16999 Incorrect predictions (meta_labels=0): 12639 R2: 0.9850582205528567
Während im vorigen Beispiel die „Einzelelement-Mengen“ nur wenige Beispiele enthielten, überwiegen diese nun gegenüber den „Mehrfachelement-Mengen“. Das Vertrauen in einen erfolgreichen Ausgang ist jedoch deutlich geringer. Die Saldenkurve spiegelt diese Unsicherheit wider, da sie mehr Drawdowns aufweist.
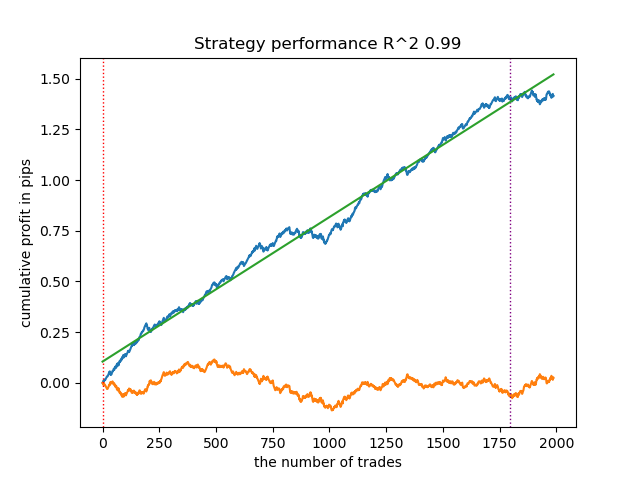
Durch die Anpassung des Konfidenzniveaus des Modells lassen sich somit die Risiken steuern, die mit erfolglosen Handelsgeschäften verbunden sind. Dadurch lässt sich ein Kompromiss zwischen der Anzahl der Transaktionen und der Effizienz des Handels oder der Wahrscheinlichkeit eines „Black Swan“-Ereignisses finden.
Exportieren und Testen von Modellen im MetaTrader 5-Terminal
Das Exportieren von Modellen funktioniert genauso wie in allen vorherigen Artikeln. Lesen Sie diese, um weitere Informationen zu erhalten.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
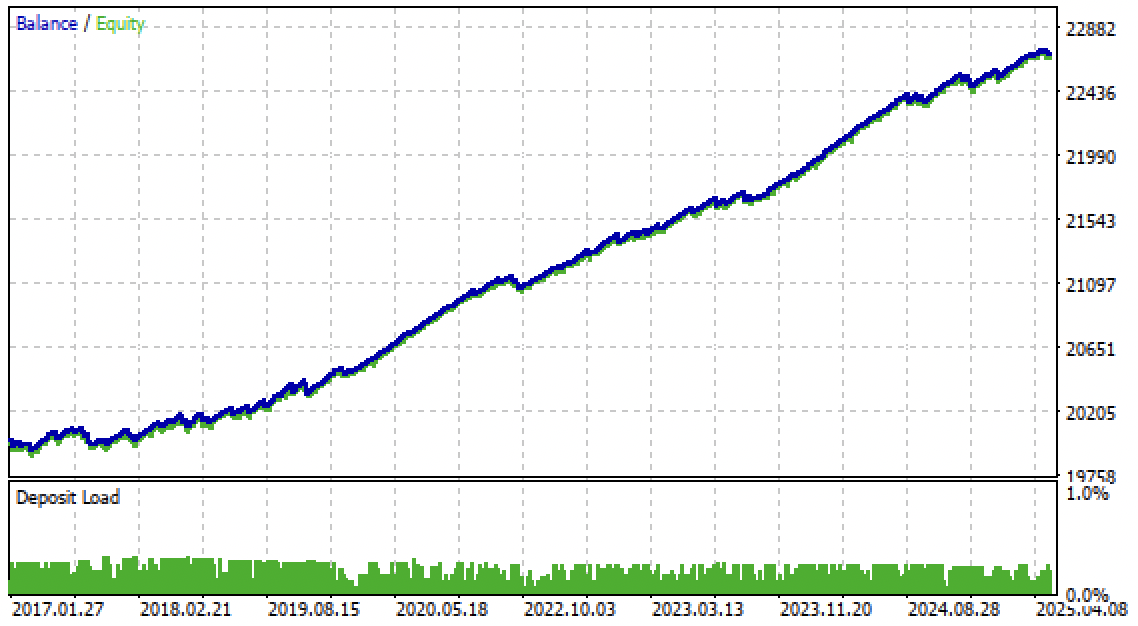
Nun können wir den Algorithmus im MetaTrader 5-Terminal testen. Das Handelssystem erwies sich nicht nur im Vorhersagezeitraum, sondern auch im Rückblickzeitraum von 2017 bis 2020 als stabil.
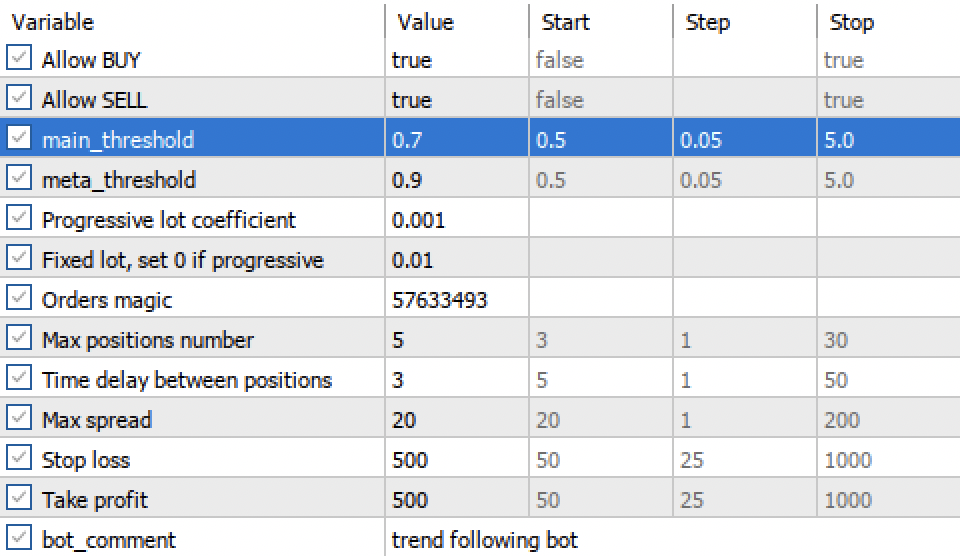
Mit den Einstellungen „Hauptschwellenwert“ und „Meta-Schwellenwert“ können wir nun Modellsignale nach Konfidenz filtern. Je höher der Schwellenwert, desto sicherer der Handel, aber desto weniger Transaktionen.
Schlussfolgerung
In diesem Artikel haben wir konforme Vorhersagen und die MAPIE-Bibliothek vorgestellt, die diese implementiert. Dieser Ansatz gehört zu den modernsten im Bereich des maschinellen Lernens und ermöglicht es uns, uns auf das Risikomanagement für bestehende, vielfältige Modelle des maschinellen Lernens zu konzentrieren. Konforme Vorhersagen sind an sich kein Verfahren zur Erkennung von Mustern in Daten. Sie geben lediglich das Konfidenzniveau bestehender Modelle bei der Vorhersage konkreter Beispiele an und ermöglichen die Filterung zuverlässiger Vorhersagen. Diese wichtige Eigenschaft ermöglicht es, Risiken im Handel zu steuern, indem die Konfidenzschwelle bereits in der Modelltrainingsphase angepasst wird.
Das Archiv Python files.zip enthält die folgenden Dateien für die Entwicklung in der Python-Umgebung:
| Dateiname | Beschreibung |
|---|---|
| mapie causal.py | Das Hauptskript für das Training von Modellen |
| labeling_lib.py | Aktualisiertes Modul mit Handelskennzeichnung |
| tester_lib.py | Aktualisierter nutzerdefinierter Strategietester basierend auf maschinellem Lernen |
| export_lib.py | Modul zum Exportieren von Modellen auf das Terminal |
| EURUSD_H1.csv | Die Datei mit den vom MetaTrader 5-Terminal exportierten Kursen |
Das Archiv MQL5 files.zip enthält Dateien für das MetaTrader 5-Terminal:
| Dateiname | Beschreibung |
|---|---|
| mapie trader.ex5 | Der kompilierte Bot aus dem Artikel |
| mapie trader.mq5 | Der Quellcode des Bots aus dem Artikel |
| Include//Trend following folder | Die ONNX-Modelle und die Header-Datei für die Verbindung mit dem Bot |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18324
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo, ich glaube, du hast vergessen, das Modul „fixing_lib“ anzuhängen. Das Modul wird in der Datei „mapie_causal.py“ importiert.
Tolle Arbeit! Vielen Dank für deinen Beitrag. Ich habe einige Änderungen vorgenommen, und alles funktioniert einwandfrei.