
機械学習を用いたフラクタルパターンの検出と分類
はじめに
最初の記事では、多重フラクタル市場理論の基本的な要素について詳しく解説しました。そこでは、価格チャートは外部情報の影響を受けて特定の繰り返し構造を形成する能力を持つことを確認しました。市場参加者は、いわば「記憶」を持つ複雑な動的システムを形成しており、その記憶は市場の対称性(パターン)という形で現れます。これらのパターンは時間とともに変化する場合もあれば、繰り返し出現する場合もあります。フラクタル市場構造は自己相似性を持つため、パターンは異なる時間スケールにわたって表現され得ます。
本記事では、フラクタルパターンを検出し分類するための独自アプローチを提示します。分析にはPythonを用いて、最終的にはモデルをONNX形式でMetaTrader 5ターミナルへエクスポートできるようにします。
開始する前に、必要なパッケージおよびモジュールがすべてインストールされていることを確認してください。なお、インポートされている一部のモジュールは以下のアタッチメントに含まれています。
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from bots.botlibs.export_lib import export_model_to_ONNX
フラクタルパターン検索関数の実装
本記事では、相関を用いて対称的なマルチフラクタル市場構造を検出するシンプルなアプローチを提案します。フラクタルおよびマルチフラクタルパターンはスケール不変性を持ち、異なるサイズで出現し得ます。そのため、設定で指定された複数の時間スケールにわたり、相関を用いてパターンを探索する必要があります。以下に、可変長パターンを考慮したスライディングウィンドウで相関を計算する関数を示します。
@njit def calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size): n = len(data) min_w = max(2, min_window_size) max_w = max(min_w, max_window_size) num_correlations = max(0, n - min_w + 1) if num_correlations == 0: return np.zeros(0, dtype=np.float64), np.zeros(0, dtype=np.int64) correlations = np.zeros(num_correlations, dtype=np.float64) best_window_sizes = np.full(num_correlations, -1, dtype=np.int64) for i in range(num_correlations): max_abs_corr_for_i = -1.0 best_corr_for_i = 0.0 current_best_w = -1 current_max_w = min(max_w, n - i) start_w = min_w if start_w % 2 != 0: start_w += 1 for w in range(start_w, current_max_w + 1, 2): if w < 2 or i + w > n: continue half_window = w // 2 window = data[i : i + w] first_half = window[:half_window] second_half = (window[half_window:] * -1)[::-1] std1 = np.std(first_half) std2 = np.std(second_half) if std1 > 1e-9 and std2 > 1e-9: mean1 = np.mean(first_half) mean2 = np.mean(second_half) cov = np.mean((first_half - mean1) * (second_half - mean2)) corr = cov / (std1 * std2) if abs(corr) > max_abs_corr_for_i: max_abs_corr_for_i = abs(corr) best_corr_for_i =corr current_best_w = w correlations[i] = best_corr_for_i best_window_sizes[i] = current_best_w return correlations, best_window_sizes
Pythonにおけるループ処理(特に類似計算の繰り返し)は遅くなりやすいため、処理高速化のために@njitデコレータを使用します。これはNumbaパッケージによるJITコンパイルを有効にし、計算速度を大幅に向上させるための手法です。
この関数は入力として終値データおよびパターン長の最小値と最大値(ウィンドウサイズ)を受け取ります。たとえば、100バーから200バーの範囲でパターンの相関を計算したい場合、対応する設定を指定します。その後、各参照点および各パターン長に対して、左側と右側(反転させた右側)との相関が計算されます。右半分の反転部分は黄色で強調表示されており、データにおける対称性を検出する上で非常に重要です。
各開始点ごとに得られた絶対相関値の最大値はcorrelations[]配列に格納されます。また、そのときのウィンドウサイズ(つまり最も高い相関を示したパターン長)はbest_window_sizes[]配列に保存されます。つまり、この関数は各開始点に対して、最大相関値とそれに対応するパターンサイズを返すことになります。
検出されたパターンの視覚的確認
すべてのパターンの計算が完了した後、アルゴリズムが適切に機能しているかを視覚的に確認できます。そのために、最も高い絶対ピアソン相関係数に基づいて上位のパターンを表示する別の関数を用意することを提案します。
def plot_best_n_patterns(data, min_window_size, max_window_size, n_best): # 1. Calculate correlations and best window sizes corrs, window_sizes = calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size) # 2. Find N best patterns # Assuming -1 in window_sizes means invalid/not found by the calculation logic valid_calc_mask = window_sizes != -1 if not np.any(valid_calc_mask): print("No suitable patterns found (all window sizes were marked as -1 by calculation).") return filtered_corrs = corrs[valid_calc_mask] filtered_window_sizes = window_sizes[valid_calc_mask] original_indices_all = np.arange(len(corrs)) filtered_start_indices = original_indices_all[valid_calc_mask] if len(filtered_corrs) == 0: print("No suitable patterns found after filtering out -1 window_sizes.") return # Sort by absolute correlation value in descending order sorted_indices_of_filtered = np.argsort(np.abs(filtered_corrs))[::-1] # Determine how many of the top patterns to consider num_to_consider = min(n_best, len(sorted_indices_of_filtered)) if num_to_consider == 0: print("No patterns to plot (either n_best is too small, or no patterns passed the initial filter).") return # Pre-filter these top candidates to find those actually plottable (even window size >= 2) patterns_to_plot_details = [] for i in range(num_to_consider): idx_in_filtered_arrays = sorted_indices_of_filtered[i] # Index within the already filtered (by valid_calc_mask) arrays w_best_candidate = filtered_window_sizes[idx_in_filtered_arrays] actual_data_start_index = filtered_start_indices[idx_in_filtered_arrays] correlation_value = filtered_corrs[idx_in_filtered_arrays] # Check if the window size is valid for plotting (even and sufficiently large) if w_best_candidate >= 2 and w_best_candidate % 2 == 0 : patterns_to_plot_details.append({ "original_rank_in_consider_list": i, # Rank among the num_to_consider items "data_start_index": actual_data_start_index, "correlation": correlation_value, "window_size": int(w_best_candidate) # Ensure it's int }) else: print(f"Info: Top candidate (originally rank {i+1} among considered, " f"Start Index: {actual_data_start_index}) " f"skipped due to invalid window size for plotting: {w_best_candidate} (must be even and >= 2).") num_actually_plotted = len(patterns_to_plot_details) fig, ax = plt.subplots(1, 1, figsize=(10, 5)) # Single axes for combined plot title_fontsize = 12 label_fontsize = 10 legend_fontsize = 8 tick_labelsize = 9 if num_actually_plotted == 0: # This message is shown if, out of the top 'num_to_consider' patterns, none had a valid window size for plotting. print("No patterns with valid window sizes (even, >=2) found among the top candidates to display on the chart.") ax.text(0.5, 0.5, "No valid patterns to display on the chart.", horizontalalignment='center', verticalalignment='center', transform=ax.transAxes, fontsize=title_fontsize, color='red') ax.set_xticks([]) ax.set_yticks([]) fig.suptitle(f"Symmetric Patterns Overlaid", fontsize=title_fontsize) # Generic title else: # Generate distinct colors for each pattern that will actually be plotted plot_colors = plt.cm.viridis(np.linspace(0, 1, num_actually_plotted)) for plot_idx, pattern_info in enumerate(patterns_to_plot_details): actual_data_start_index = pattern_info["data_start_index"] correlation_value = pattern_info["correlation"] w_best = pattern_info["window_size"] half_window = w_best // 2 # Ensure indices are within data bounds if actual_data_start_index + w_best > len(data): print(f"Warning: Pattern P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}) extends beyond data length {len(data)}. Skipping.") continue left_part_data = data[actual_data_start_index : actual_data_start_index + half_window] right_part_data = data[actual_data_start_index + half_window : actual_data_start_index + w_best] x_indices = np.arange(w_best) # X-axis relative to pattern start current_color = plot_colors[plot_idx] # Plot left part ax.plot(x_indices[:half_window], left_part_data, color=current_color, linestyle='-', label=f"P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}, C:{correlation_value:.2f})") # Plot right part ax.plot(x_indices[half_window:], right_part_data, color=current_color, linestyle='--') # Add a vertical line to mark the split point for this pattern ax.axvline(x=half_window - 0.5, color=current_color, linestyle=':', linewidth=1, alpha=0.6) ax.set_xlabel("Index within Pattern Window", fontsize=label_fontsize) ax.set_ylabel("Data Value", fontsize=label_fontsize) ax.tick_params(axis='both', which='major', labelsize=tick_labelsize) ax.grid(True) ax.legend(fontsize=legend_fontsize, loc='best') # Add a text note to explain line styles fig.text(0.99, 0.01, 'Solid: Left Part, Dashed: Right Part (Original)', horizontalalignment='right', verticalalignment='bottom', fontsize=legend_fontsize - 1, color='dimgray', transform=fig.transFigure) fig.suptitle(f"Top {num_actually_plotted} Symmetric Patterns Overlaid", fontsize=title_fontsize) plt.tight_layout(rect=[0, 0.03, 1, 0.96]) # Adjust rect for suptitle and fig.text plt.show()
この関数はやや長くなりますが、コードの大部分はパターンのソート処理とプロット処理に割かれています。まずパターンそのものを計算し、その後に相関係数の値に基づいてソートします。各パターンが価格履歴のどの位置に対応しているかを特定し、それをグラフ上に描画します。この関数の実行結果を以下に示します。
最初の図では、絶対値の相関が最も高い単一のパターンを確認できます。このパターンは局所的または大局的なピークに類似しており、トレンド転換を示唆する形状となっています。点線の縦線は系列を2つの等しい区間に分割する位置を示しています。右半分は符号を反転させたうえでミラーリングされています。ただし、図中には反転後の右側ではなく、元の価格系列のみが表示されています。その後、左側と右側の区間間で相関が計算されます。
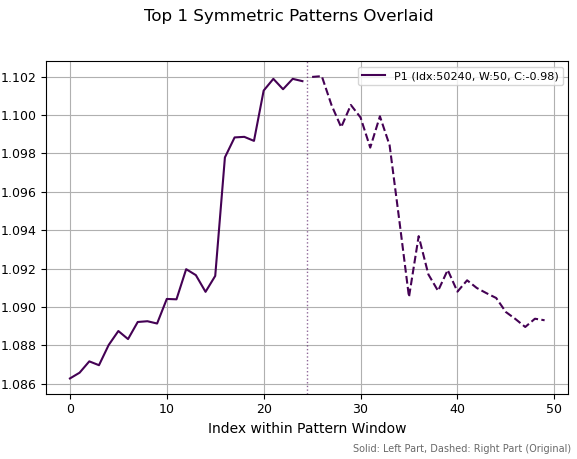
図1:期間50、相関-0.98の最良パターン
次の図では、期間50における上位5つのパターンを表示しています。これら5つのうち、3つは天井形成に類似し、2つは底形成に類似しています。またそのうち1つは、上昇トレンドの継続局面にも見えます。左側のスケールは、これらのパターンが対応する過去の価格水準を示しています。
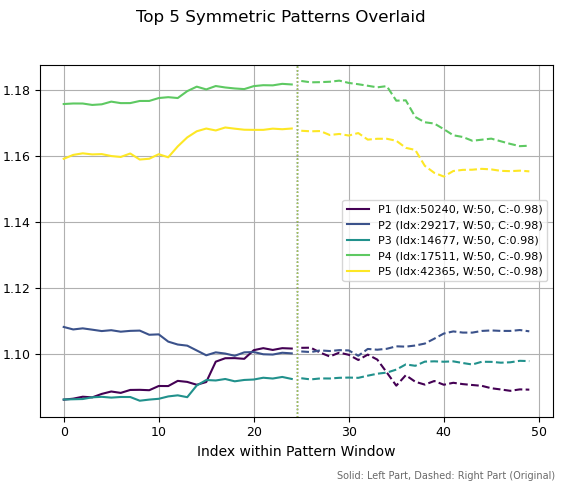
図2:期間50の上位5パターン
パターンの期間を150バーに拡大すると、まったく異なる構造が観察されます。類似した3つのパターン(天井形状)が検出されています。これは、過去データ内のわずかなシフトによって同一構造が繰り返し検出されたためです。一方で、残りの2つのパターンは互いに異なる形状を示しています。
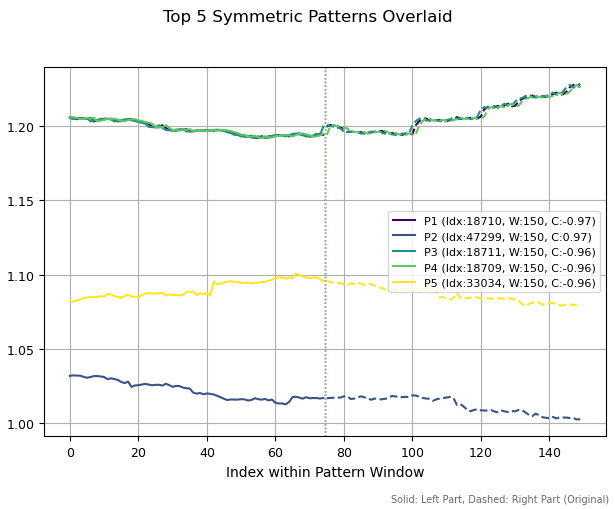
図3:期間150の上位5パターン
さらにパターン計算ウィンドウを250に拡張すると、同じパターンが再び上位に出現しますが、これは履歴上の位置がわずかにずれているためです。また、相関が負であることから、反転型のトレンド転換パターンも確認できます。
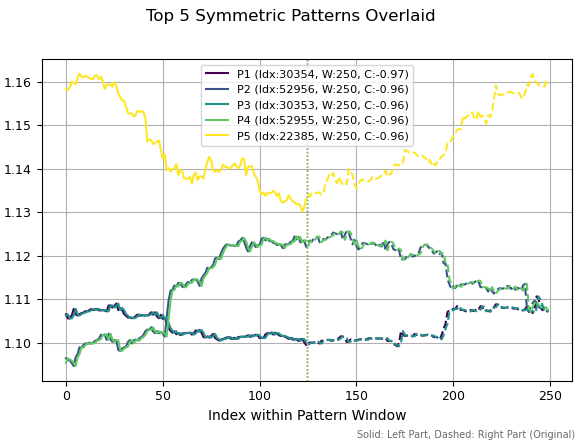
図4:期間250の上位5パターン
これらの図は、自己アフィン(自己相似)的な市場構造が非常に多様であることを示しています。理論的には、この多様性は解析対象となる時系列の長さによってのみ制限されます。このような状況では、どのパターンが予測力を持ち、どのパターンが持たないのかを判別することは容易ではありません。各構造を個別に検証するには数ヶ月単位の時間が必要になる可能性があります。この点において機械学習は有効であり、すべてのパターンを一括で分類することを可能にします。
なお、相関による構造探索は必ずしも最適とは限らず、より精度の高い推定手法を検討する余地があります。しかし、この手法は直感的で、今後の研究の出発点として適しています。次に必要なのは、これらの市場フラクタルをどのように解析し、機械学習を用いた取引システムへと発展させるかを整理することです。
対称構造に基づく取引ラベリング
対称構造の検出関数は、ある意味でデータマイニングの関数といえます。ここでは、自己相似なフラクタル構造という明確な探索条件をデータに対して設定しています。次のステップでは、得られた情報を収集し分類する必要があります。しかしそれだけでは不十分であり、このデータに基づいて取引をどのようにラベリングするかという設計も必要になります。本セクションではその方法を扱います。
以下に、取引を分類のためにラベリングする方法を提案します。この方法は唯一のものではなく、著者の考える実装例の一つです。このテーマについてはさらなる研究が必要だと考えられますが、現時点ではこのラベリング手法に限定して議論を進めます。
@njit def generate_future_outcome_labels_for_patterns( close_data_len, # Total length of the original close_data correlations_at_window_start, # Correlation array window_sizes_at_window_start, # Array of window sizes source_close_data, # Full close_data array correlation_threshold, min_future_horizon, # Minimum horizon for determining the future price max_future_horizon, # Maximum horizon markup_points # "Markup" for determining a significant price change ): labels = np.full(close_data_len, 2.0, dtype=np.float64) # 2.0: no signal/neutral/no pattern num_potential_windows = len(correlations_at_window_start) for idx_window_start in range(num_potential_windows): corr_value = correlations_at_window_start[idx_window_start] w = window_sizes_at_window_start[idx_window_start] # Condition 1: The correlation should be strong enough if abs(corr_value) < correlation_threshold: continue # Condition 2: A valid window should be found if w < 2: continue # The point in time (index) when the correlation pattern is fully formed signal_time_idx = idx_window_start + w - 1 if signal_time_idx >= close_data_len: # Theoretically, this should not happen continue # Array for storing labels for the entire pattern (both left and right parts) pattern_labels = [] # Calculate individual marks for all points of the pattern for point_idx in range(idx_window_start, signal_time_idx + 1): # Current price for this particular point current_price = source_close_data[point_idx] # Define the forecast horizon current_horizon = min_future_horizon if max_future_horizon > min_future_horizon: current_horizon = random.randint(min_future_horizon, max_future_horizon) # Index of future price relative to the current point future_price_idx = point_idx + current_horizon if future_price_idx >= close_data_len: continue future_price = source_close_data[future_price_idx] # Define a label for the current point current_label = 2.0 # Neutral by default if future_price > current_price + markup_points: current_label = 0.0 # Price increased elif future_price < current_price - markup_points: current_label = 1.0 # Price fell # Add the label to the array if it is not neutral if current_label != 2.0: pattern_labels.append(current_label) # If there are no significant marks in the pattern, move on to the next pattern if len(pattern_labels) == 0: continue # Calculate the average mark for all points of the pattern avg_label = 0.0 for l in pattern_labels: avg_label += l avg_label /= len(pattern_labels) # Define a common label for the entire pattern pattern_label = 0.0 if avg_label < 0.5 else 1.0 # Assign this label to all points of the pattern for i in range(idx_window_start, signal_time_idx + 1): labels[i] = pattern_label return labels
generate_future_outcome_labels_for_patterns()関数は、以下の機能を実装しています。
- 入力として、元の価格配列、相関の配列、そして各データポイントにおいて最も高い相関に対応するパターン長の配列を受け取ります。また、予測ホライズンの最小値および最大値(バー単位)も引数として指定します。
- 初期状態では、すべての取引は2.0(取引しない)としてラベル付けされます。
- ループ処理では、時系列の各ポイントにおける相関値を確認します。相関がcorrelation_thresholdを超えている場合、その観測値は追加の処理対象となります。閾値を下回る場合、そのサンプルのラベルは2.0のまま維持されます。
- その後、その時点における最大相関によって決定されたパターン長全体にわたり、将来の価格変動に基づいて取引が計算されます。各ポイントについて、価格が上昇していれば0(買い)、下落していれば1(売り)として分類されます。その後、取引結果の平均値が算出され、その平均値に基づいて、パターン全体に対する共通ラベル(0または1)が決定され、当該パターン内の各観測値に付与されます。
このアプローチの思想は、強い相関を持つ構造は初期条件に対する「記憶」を保持しており、ある程度の規則性を示すという点にあります。つまり、その内部に含まれる観測値はより予測可能である一方で、過学習を防ぐために平均化されたラベルを付与します。逆に、相関の弱い構造は規則性が低く、予測が困難であるため、信頼性の低いサンプルとして扱われます。
結果として、以下のような二段階の学習戦略を採用します。一つ目のモデルは「現在のパターンが取引に適しているか(品質評価)」を判定し、もう一つのモデルは「取引方向(買い・売り)」を予測します。機械学習は、あらゆるパターンおよび取引方向の近似を担うことになります。
次に必要となるのは、これらを統合し、ラベリング処理を直接実行するオーケストレーター関数です。
フラクタルパターンに基づく最終的な取引ラベリング関数
すべてを統合し、実用可能な取引ラベリングツールを実装する段階に入ります。
def get_fractal_pattern_labels_from_future_outcome( dataset, min_window_size=6, max_window_size=60, correlation_threshold=0.7, min_future_horizon=5, max_future_horizon=5, markup_points=0.00010, ): if 'close' not in dataset.columns: raise ValueError("Dataset must contain a 'close' column.") close_data = dataset['close'].values n_data = len(close_data) if min_window_size < 2: min_window_size = 2 if max_window_size < min_window_size: max_window_size = min_window_size if min_future_horizon <= 0: raise ValueError("min_future_horizon must be > 0") if max_future_horizon < min_future_horizon: raise ValueError("max_future_horizon must be >= min_future_horizon") correlations_at_start, best_window_sizes_at_start = calculate_symmetric_correlation_dynamic( close_data, min_window_size, max_window_size, ) labels = generate_future_outcome_labels_for_patterns( n_data, correlations_at_start, best_window_sizes_at_start, close_data, correlation_threshold, min_future_horizon, max_future_horizon, markup_points ) result_df = dataset.copy() result_df['labels'] = pd.Series(labels, index=dataset.index) return result_df
get_fractal_pattern_labels_from_future_outcome()関数は、データセットに対して直接ラベリングをおこなうために呼び出されます。
- 入力はデータフレームであり、終値を含むclose列とオプションの特徴量が含まれている必要があります。
- また、取引のラベリングに使用するパターン長の最小値および最大値を指定します。
- さらに、パターンの信頼度(精度)を調整するための相関閾値も設定します。
- 加えて、取引のポジション保有期間(バー単位)の最小値および最大値も指定する必要があります。
- 必要に応じて、ラベリング処理の詳細な設定もカスタマイズ可能です。
この関数は終値データを含むデータセットを受け取り、フラクタルパターンに基づいて取引のラベル付けをおこない、その結果をlabels列としてデータフレームに追加します。
フラクタルラベリングに基づく機械学習モデルの学習
ここまでで準備が整い、実験を開始できる状態になりました。ソースデータとしては、2010年以降のEURUSDの1時間足(H1)データを使用します。
特徴量としては、異なる期間のスライディングウィンドウにおける標準偏差を採用することにしました。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
次に、モデルのハイパーパラメータを正しく設定する必要があります。
# set hyper parameters hyper_params = { 'symbol': 'EURUSD_H1', 'export_path': '/Users/dmitrievsky/Library//drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/', 'model_number': 0, 'markup': 0.00010, 'stop_loss': 0.00500, 'take_profit': 0.00500, 'periods': [i for i in range(15, 300, 30)], 'backward': datetime(2010, 1, 1), 'forward': datetime(2024, 1, 1), }
- ストップロスおよびテイクプロフィットは同一条件とし、それぞれ500ポイント(5桁表示のポイント)に設定します。
- 次に、学習済みモデルを出力するための保存先パスを指定する必要があります。
- 特徴量として使用する標準偏差の計算期間は、15から300までの範囲で、ステップ幅30で設定します。これにより合計10個の特徴量が生成されます。
- 学習期間は2010年から2024年までとし、それ以降のデータは学習対象外とします。
メインの学習ループでは、複数のモデルを同時に学習させることが可能です。また、ハイパーパラメータを走査しながら最適な組み合わせを探索するように設計されています。
# fit the models models = [] for i in range(10): print('Learn ' + str(i) + ' model') dataset = get_features(get_prices()) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() data = get_fractal_pattern_labels_from_future_outcome(data, 100, 100, 0.9, 15, 25, 0.00010) models.append(fit_final_models(data))
ループ処理の中では、まず価格データと特徴量を取得し、次にモデルを学習させる対象期間を決定します。
get_fractal_pattern_labels_from_future_outcome()関数では、以下のパラメータを渡します。
- 価格と特徴量を含む元のデータフレーム
- 相関計算に使用するウィンドウの最小値
- 相関計算に使用するウィンドウの最大値
- パターン抽出に用いる相関係数の閾値(デフォルトは0.9)
- 予測ホライズンの最小値(バー単位)
- 予測ホライズンの最大値(バー単位)
- マークアップ(ポイント単位)
その後、ラベル付けされたデータは、2つの分類器を学習させるための関数へと入力されます。
def fit_final_models(dataset: pd.DataFrame) -> list: feature_columns = dataset.columns[1:-1] # 1. Data for the main model # Filter the dataset: only those examples where 'labels' are equal to 0 or 1 are used for the main model. main_model_df = dataset[dataset['labels'].isin([0, 1])].copy() X = main_model_df[feature_columns] y = main_model_df['labels'].astype('int16') # 2. Data for the meta model X_meta = dataset[feature_columns] # Modify labels for the meta model: if 'labels' contains 1 or 0, then the new label is 1, if 2, then 0. y_meta = dataset['labels'].apply(lambda label_val: 1 if label_val in [0, 1] else 0).astype('int16') # For the main model train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) # For the meta model train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # Train the main model model = CatBoostClassifier(iterations=1000, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', ) # Check if the samples are empty after splitting (unlikely if X is large enough) if not train_X.empty and not test_X.empty: model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) elif not train_X.empty: # If the test sample is empty, but the training sample exists print("Warning: The test sample (test_X) for the main model is empty. The model is trained without eval_set.") model.fit(train_X, train_y, early_stopping_rounds=15, plot=False) # use_best_model may not work correctly without eval_set else: # If the training set is empty print("Error: The training set (train_X) for the main model is empty. The model cannot be trained.") # In this case, test_model will most likely throw an error later. # Return R2=-1 and the untrained model, the meta model will also not make sense without the main one. print("R2 is fixed at -1.0, models are not trained.") return [-1.0, model, None] # model - instance, but not trained # Meta model training meta_model = CatBoostClassifier(iterations=1000, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', ) if not train_X_m.empty and not test_X_m.empty: meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=25, plot=False) elif not train_X_m.empty: print("Warning: The test sample (test_X_m) for the meta model is empty. The meta model is trained without eval_set.") meta_model.fit(train_X_m, train_y_m, early_stopping_rounds=25, plot=False) else: print("Error: The training set (train_X_m) for the meta model is empty. The meta model cannot be trained.") print("R2 fixed as -1.0.") return [-1.0, model, meta_model] # meta_model - instance, but not trained data_for_test = get_features(get_prices()) R2 = test_model(data_for_test, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 fixed as -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
特に注意すべき点は太字で強調されています。メインモデルは0または1のラベルのみを予測するように学習されている一方で、追加のメタモデルは「取引するかしないか」を判定する役割を持ちます。
テストおよび最終結果
まず最初に述べておくべき点として、このアルゴリズムはEURUSDのみに対して検証されています。新しいデータ上で最も良好に機能するパターンウィンドウサイズは100であることが確認されました。アルゴリズムの最適パラメータはすでにコード内に設定されているため、再現実験が可能です。
学習データおよびテストデータにおける残高推移グラフは以下のようになります。
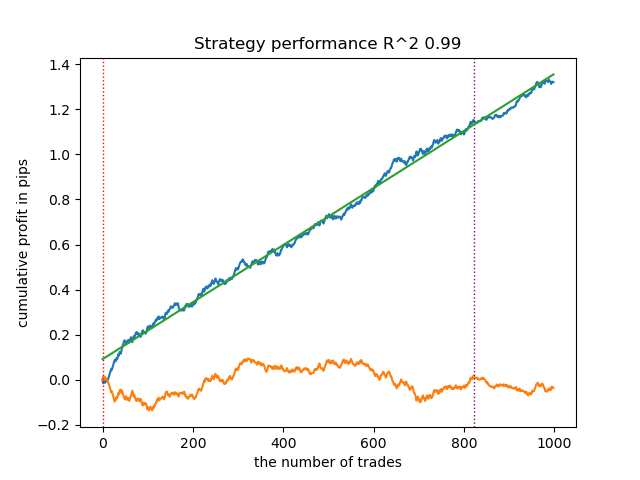
図5:フラクタルラベリングに基づくアルゴリズムのテスト結果
相関閾値と新規データにおける取引結果の間には明確な関係が存在します。たとえば、閾値を0.7に設定した場合、残高曲線には明確な過学習の兆候が現れます。これは、時系列の2区間間の相関が弱い場合、その依存関係もまた弱くなることを意味します。その結果、信頼できるパターンと不安定なパターンが混在し、正しい分類が困難になります。
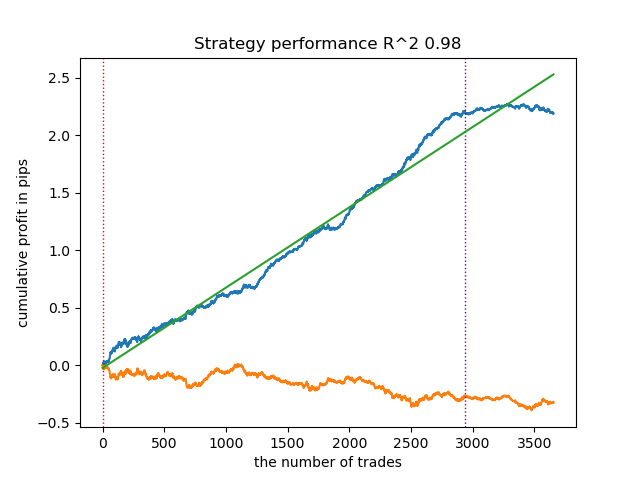
図6:相関閾値0.7でのアルゴリズムテスト結果
このことから、正確なパターン認識が極めて重要であることが示唆されます。フラクタル構造の探索方法については、さらなる研究と改善の余地があります。
また、特徴量の質と量も分類結果に大きく影響します。たとえば、標準偏差の代わりに価格の増分を使用した場合、残高曲線は異なる形状を示します。
さらに、検出されたパターンに基づく取引ラベリング手法についても、合理的な検証と批判的検討が必要です。
CatBoostモデルのエラー分析からは、モデルが比較的低い誤差で学習されていることが確認されています。
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.9700523560209424, 'Logloss': 0.17002244404784328} >>> models[-1][2].get_best_score()['validation'] {'Logloss': 0.25629795409043277, 'F1': 0.8455473098330242} >>>
MetaTrader 5ターミナルでのモデルのエクスポートとテスト
モデルをエクスポートするには、次の関数を呼び出す必要があります。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
モデルをエクスポートし、EAをコンパイルした後、以下の結果が得られました。
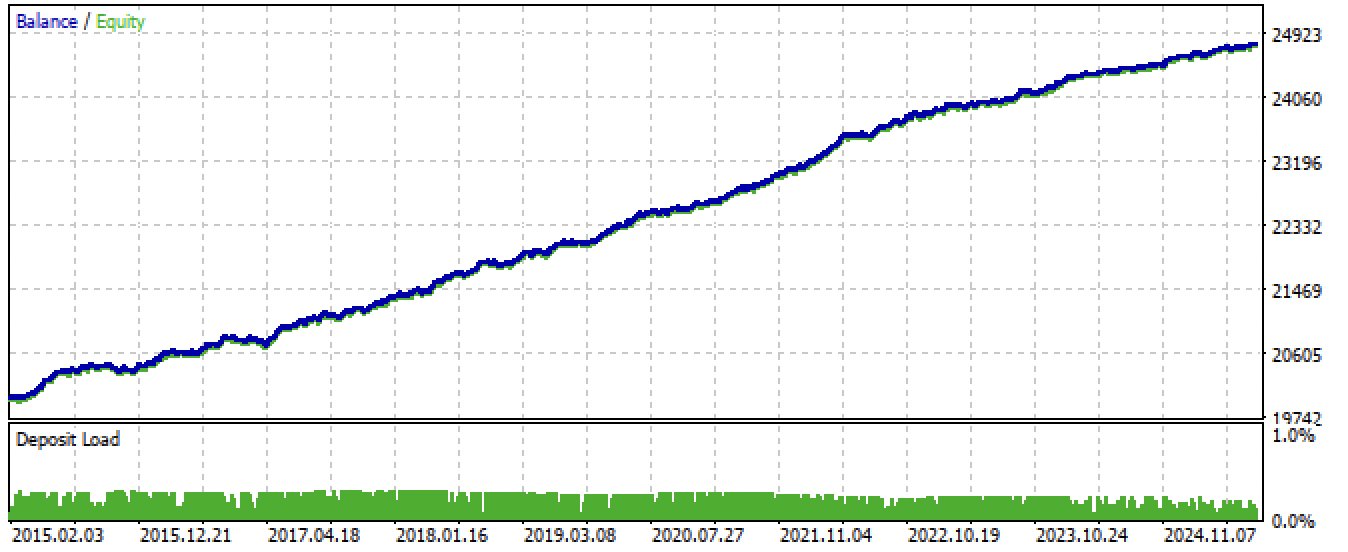
図7:EAの全期間にわたるテスト結果
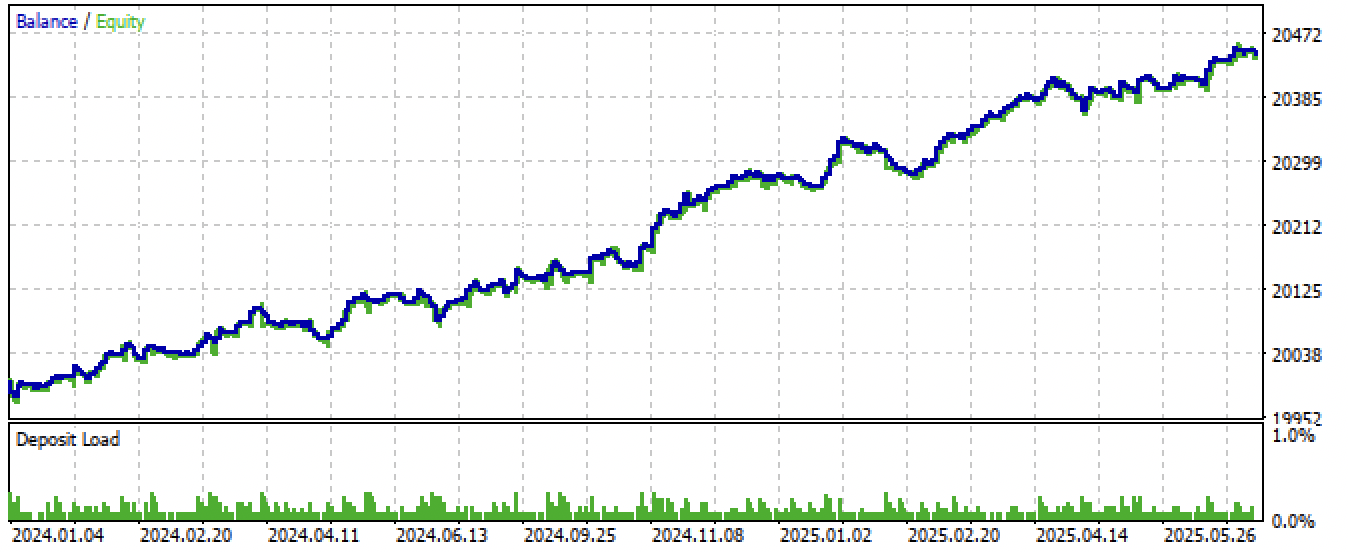
図8:新規データにおけるEAのテスト結果
結論
本記事では、フラクタル解析と機械学習を用いた市場予測という興味深いテーマを取り上げました。これらは、金融価格チャート上に形成される多様なフラクタル構造を探究するための第一歩に過ぎません。
なお、相関に基づく探索手法は、過去と未来の価格系列間の関係性を完全に捉えられているとは限らず、この点についてはさらなる研究が必要です。たとえば、相関分析よりも回帰分析の方が適している可能性もあります。一方で、本アルゴリズムは適切に調整することで一定の予測能力を示し得て、金融時系列にフラクタル的な自己相似構造が存在することを示唆しています。
Python files.zipアーカイブには、Python環境向けの開発ファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| fractal patterns.py | モデル学習用のメインスクリプト |
| labeling_lib.py | 更新された取引ラベリングモジュール |
| tester_lib.py | 更新された機械学習ベースのカスタムストラテジーテスター |
| export_lib.py | モデルをターミナルにエクスポートするモジュール |
| EURUSD_H1.csv | MetaTrader 5からエクスポートされた価格データ |
MQL5 files.zipアーカイブには、MetaTrader 5ターミナル用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| fractal trader.ex5 | 記事で作成したボットのコンパイル済みファイル |
| fractal trader.mq5 | 記事で使用したボットのソースコード |
| Include//Trend following folder | ONNXモデルおよびボット接続用ヘッダファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18566
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
私が言いたいのは、この記事のことだけではありません。この記事は、主流の枠内では悪くないものです。私が言いたいのは別のことです。
「時間経過に伴うフラクタルの変動性をどのように考慮すべきか、まだ考えがまとまっていない」――ところが、これはあらゆる予測の精度を左右する重要なパラメータなのだ。
しかも、これはあなただけの問題ではなく、世界的な問題だ――時間とともに変動する変数におけるすべての係数の変化である。
この問題の本質を理解するためには、一歩引いて、基本的な概念を再考する必要がある。 例えば、フラクタルの大部分は自己相似性を持ちません。2000年の1ドルは2025年の1ドルとは等しくありません(つまり、1は1に等しくないのです)。
他にも多くの例を挙げることができます。社会(経済)ではガウス分布ではなくパレート分布が支配的であるため、統計手法の多くは市場分析などに適用できません。
サイモンズの成功は、この問題には解決策があることを示唆しているが、それを探すには別の場所を見なければならない。
彼のケースは、どうやらアービトラージに関するもののようだ。多くのアービトラージ戦略も、時間の経過とともに機能しなくなる。
彼の場合は、どうやらアービトラージに関するもののようだ。多くのアービトラージ戦略も、時間が経つにつれて効果がなくなってしまう。
彼には多次元空間がある。
彼には多次元空間がある。
ギルベルト家?
そもそも、サイモンズの投資手法に関する詳細な情報はほとんど存在せず、それは当然のことだ。しかし、彼が毎年資産を倍増させ、生涯の終わりにはその資産が200億以上と評価されていたことは知られている。
しかし、重要なのは彼自身ではなく、その「公式」を見つけ出す可能性そのものである。多次元空間とは、ピタゴラス派の思想を現代的に表現した用語である。これは非常に深遠なテーマだ。 マルチフラクタル性もまた、多重元空間の原始的なアナログとして捉えることができ、そこでは頂点やグラフが、隠された動きのグラフへの投影となります。 もしこのテーマにご興味があれば、私の考察や研究成果を共有することもできますが、個別メールでのやり取りの方が良いでしょう。
そもそも、サイモンズの投資手法に関する詳細な情報はほとんど存在しないが、それも当然のことだ。しかし、彼が毎年資産を倍増させていたこと、そして生涯の終わりにはその資産が200億以上と評価されていたことは知られている。
しかし、重要なのは彼自身ではなく、その「公式」を見つけ出す可能性そのものです。多次元空間とは、ピタゴラス派の思想を現代的に表現した用語です。これは非常に深遠なテーマです。 マルチフラクタル性もまた、多重元空間の原始的なアナログとして捉えることができ、そこでは頂点やグラフが、隠された動きのグラフへの投影となります。 もしこのテーマにご興味があれば、私の考察や研究成果を共有することもできますが、個別のご連絡をいただければ幸いです。
前回の記事では、まさに外部条件の影響下での隠れたアトラクタ(自己組織化)の形成について記述されていたようです。これは、特徴の多次元空間を通じて定義することができます。