
Estudiamos la predicción conformal de series temporales financieras
Introducción
MAPIE o "Model agnostic prediction interval estimator", es una biblioteca de Python de código abierto diseñada para cuantificar la incertidumbre y gestionar el riesgo en modelos de aprendizaje automático. Permite calcular intervalos de predicción para problemas de regresión, así como conjuntos de predicciones para la clasificación y las series temporales. Esta evaluación de incertidumbre se realiza usando como base un "conjunto de calibración conformal" especial de datos.
Una de las principales ventajas de MAPIE es su naturaleza independiente del modelo, lo cual significa que la biblioteca se puede utilizar con cualquier modelo compatible con la API scikit-learn, incluidos los modelos desarrollados con TensorFlow o PyTorch a través de envoltorios correspondientes. Esta propiedad simplifica enormemente la integración en los procesos analíticos existentes, ya que los traders suelen utilizar una amplia variedad de modelos de aprendizaje automático, desde enfoques estadísticos tradicionales hasta redes neuronales complejas, dependiendo de la clase de activo o la estrategia de trading específica. La capacidad de usar sin problemas modelos probados para incorporar la cuantificación de la incertidumbre reduce significativamente los costos de implementación y acelera la adopción, lo cual resulta particularmente valioso en un entorno financiero dinámico.
La biblioteca forma parte del ecosistema scikit-learn-contrib y se centra en las áreas de predicción conformal e inferencia independiente de la distribución. Implementa algoritmos revisados por pares que son independientes del modelo y del caso de uso, y tienen garantías teóricas con suposiciones mínimas sobre los datos y el modelo. Más allá de la clasificación estándar, MAPIE también es capaz de controlar riesgos para tareas más complejas, como la clasificación de múltiples clases y la segmentación de imágenes en visión artificial, ofreciendo garantías probabilísticas sobre métricas como el recall y la precisión.
La capacidad de controlar riesgos y ofrecer seguridad probabilística posiciona a MAPIE no simplemente como una herramienta para cuantificar la incertidumbre, sino como un marco integral de gestión de riesgos. En finanzas, los pronósticos puntuales son insuficientes porque no transmiten el nivel de confianza o el error potencial. Ofrecer tasas de error garantizadas (como una cobertura del 95%) se traduce directamente en un riesgo cuantificable, lo cual permite a los administradores de riesgos establecer tolerancias de riesgo explícitas.
Por ejemplo, si el modelo genera una señal de compra, pero el pronóstico conformal indica una alta probabilidad de error, el gestor de riesgos puede decidir reducir la posición o abstenerse de la operación, controlando directamente la pérdida potencial. Esto promueve una toma de decisiones más fiable en condiciones de incertidumbre, yendo más allá de la simple precisión del pronóstico.
Principios básicos de la previsión conformal: garantías independientes del modelo y de la distribución
La predicción conformal (CP) es un marco estadístico que genera conjuntos de predicciones para problemas de clasificación o intervalos de predicción para regresión con probabilidades de cobertura garantizadas. Esto significa que, con un nivel de confianza determinado, digamos del 90%, el resultado verdadero se encontrará en el conjunto o intervalo previsto al menos el 90% del tiempo.
La principal ventaja del CP es su "independencia de distribución": el método no se basa en suposiciones estrictas sobre la distribución subyacente de los datos o del modelo en sí. El único supuesto fundamental es que los datos (puntos de entrenamiento y de prueba) son intercambiables, es decir, se extraen de la misma distribución, y su orden no importa.
Este supuesto es más débil que el supuesto de independencia y distribución idéntica (iid) y a menudo puede justificarse en la práctica. A diferencia de los intervalos de predicción tradicionales, que solo pueden aproximar la cobertura, la CP ofrece garantías de muestras finitas, lo que garantiza que se logre el nivel de cobertura especificado incluso con datos limitados.
La garantía de independencia de la distribución de la previsión conformal aborda directamente el problema fundamental del modelado financiero. Los datos financieros están notoriamente no distribuidos normalmente, presentan colas pesadas y a menudo infringen supuestos estadísticos típicos como la homocedasticidad o la independencia de los incrementos.
Los intervalos de predicción tradicionales con frecuencia se basan en estos supuestos, como los residuos normales, y por lo tanto solo ofrecen una cobertura aproximada. La capacidad de las CP de proporcionar cobertura garantizada sin tales suposiciones las hace inherentemente más sólidas y fiables para aplicaciones financieras donde distribuciones mal especificadas pueden llevar a una subestimación significativa del riesgo. Esto significa que los niveles de confianza informados son más fiables en conjuntos de datos financieros complejos del mundo real.
El proceso de pronóstico conformal generalmente implica el uso de un modelo de aprendizaje automático entrenado, la creación de un conjunto de datos de calibración (que el modelo no ve durante el entrenamiento), el cálculo de "puntajes de conformidad" en este conjunto y luego el uso del cuantil de estos puntajes para determinar los conjuntos de predicción. El cambio de una cobertura aproximada a una cobertura de muestra finita garantizada cambia fundamentalmente el panorama regulatorio y de gestión de riesgos para los modelos de aprendizaje automático en las finanzas.
En industrias de alto riesgo, como las finanzas, los modelos a menudo necesitan mostrar solidez cuantitativa y control sobre las tasas de error. Esto difiere de los métodos estadísticos tradicionales, donde un "90% de confianza" puede ser solo una propiedad asintótica o una aproximación. Para un trader cuantitativo, esto ofrece una base más sólida para justificar estrategias de trading o la asignación de capital de riesgo.
Conjuntos de predicciones vs. predicciones puntuales en la clasificación binaria
Los modelos de clasificación binaria tradicionales generan una única etiqueta predicha (por ejemplo, "Comprar" o "Vender") o una puntuación de probabilidad (por ejemplo, 0,8 para "Comprar"), y estos son pronósticos puntuales. Sin embargo, la previsión conformal ofrece un conjunto de predicciones que supone un subconjunto de las clases posibles (por ejemplo, {Comprar}, {Vender} o {Comprar, Vender}). Este conjunto contiene de forma garantizada la etiqueta verdadera con una probabilidad determinada.
Para la clasificación binaria, el conjunto de predicción puede ser:
- Una sola clase (por ejemplo, {Comprar} o {Vender}), que indica un alto grado de confianza.
- Ambas clases (por ejemplo {Comprar, Vender}), lo cual indica incertidumbre o ambigüedad.
- Un conjunto vacío {} (aunque esto es menos común cuando se usan algunos métodos como APS, y a menudo no resulta deseable), lo cual indica una incertidumbre extrema o que ninguna clase cumple con el umbral de confianza.
La "informatividad" de un conjunto de predicciones es inversamente proporcional a su tamaño: los conjuntos más pequeños (por ejemplo, una clase) resultan más informativos que los conjuntos más grandes (por ejemplo, ambas clases). Inferir explícitamente un conjunto de puntos en lugar de uno solo cambia fundamentalmente el proceso de toma de decisiones en la clasificación binaria para las finanzas. En lugar de una simple señal de "sí/no" o de "comprar/vender", el conjunto de pronósticos proporciona una medida directa de la confianza del modelo.
Un conjunto de una clase como {Comprar} sugiere una señal fuerte, mientras que un conjunto de dos clases {Comprar, Vender} indica una ambigüedad significativa. Esto permite llevar una estrategia de trading más matizada: realizar operaciones con señales de alta confianza y luego esperar, reducir el tamaño de la posición o buscar más información en busca de señales ambiguas. Se trata de un mecanismo directo para integrar la incertidumbre en decisiones financieras efectivas.
El "contenido informativo" de los conjuntos de pronósticos se convierte en una medida directa de la eficacia y la tolerancia al riesgo en las transacciones financieras. Un conjunto de predicciones amplio y poco informativo (por ejemplo, {Comprar, Vender}) para una transacción significa que el modelo no puede distinguir de forma fiable entre compra y venta con el nivel de confianza deseado. Para un analista cuantitativo, esto no supone un error de pronóstico que deba corregirse, sino una señal para no actuar o para actuar con extrema cautela. Esto permite gestionar el riesgo de manera dinámica: asignar más capital a operaciones con conjuntos estrechos y altamente fiables y preservar el capital evitando o minimizando la exposición a operaciones con conjuntos amplios e inciertos. Esto conduce directamente a la optimización del perfil riesgo-recompensa de la estrategia de trading.
Garantías teóricas: cobertura marginal y condicional
Los predictores conformales son "automáticamente válidos" en el sentido de que sus conjuntos de predicciones tienen una probabilidad de cobertura igual o mayor que un nivel de confianza dado (1 - α) en promedio sobre todos los datos. Esta garantía resulta válida independientemente del modelo subyacente o del proceso de generación de datos, siempre que se cumpla el supuesto de intercambiabilidad. Esta propiedad se conoce como cobertura marginal.
Si bien la cobertura marginal está garantizada, se trata de una cifra promedio. Conceptos más rigurosos, como la validez condicional, buscan garantías de cobertura condicionales a propiedades concretas de los datos (por ejemplo, por clase, por objeto, por etiqueta). Los predictores conformales inductivos (la versión computacionalmente eficiente) controlan principalmente la probabilidad de cobertura incondicional. Para lograr la validez condicional con frecuencia es necesario modificar el método.
La distinción entre cobertura marginal y condicional es de importancia primordial para la clasificación financiera binaria, especialmente con conjuntos de datos desequilibrados comunes en finanzas (por ejemplo, muchas señales de "no hay operación" o "mantener" en comparación con menos señales de "compra" o "venta").
La cobertura marginal garantiza que, en promedio, el 90% de los pronósticos serán correctos. Sin embargo, si las señales de compra son poco frecuentes, el modelo puede lograr una cobertura marginal del 90%, resultando muy preciso en las señales de venta pero con un rendimiento deficiente en las señales de compra. Esto puede dar lugar a pérdidas importantes, así como a la omisión de oportunidades, si las señales de compra son críticas.
La cobertura condicional, especialmente la cobertura específica de cada clase, garantiza que se logre el nivel de confianza deseado para cada clase individualmente. Esto resulta crucial para garantizar la fiabilidad de los pronósticos tanto para las operaciones de compra como de venta, evitando sesgos sistemáticos que puedan socavar una estrategia de trading.
La búsqueda de validez condicional a través de métodos como la predicción conformal de Mondrian aborda directamente la cuestión de la imparcialidad y la fiabilidad en diferentes clases de resultados en aplicaciones financieras. En finanzas, los errores de pronóstico en ciertas clases (por ejemplo, una oportunidad de "compra" poco común pero muy rentable o una "venta" crítica para evitar grandes pérdidas) pueden tener costos desproporcionadamente altos en comparación con los errores de pronóstico en escenarios más comunes de "no hay operación".
Ofreciendo una cobertura condicional, el sistema garantiza un nivel mínimo de fiabilidad para cada tipo de transacción, no solo en promedio. Esto permite un tratamiento más justo de las diferentes señales comerciales y aumenta la confianza en la capacidad del modelo para procesar una amplia variedad de condiciones de mercado y eventos raros, lo cual resulta esencial para un trading algorítmico sólido.
Evaluaciones de conformidad: el núcleo de la predicción conformal
Los puntajes de conformidad son el núcleo de la predicción conformal; estos cuantifican qué tan "inusual" o "fuera de lugar" es un nuevo punto de datos en comparación con los datos de calibración. El único requisito para la función de puntuación es que las puntuaciones más altas codifiquen una peor coincidencia entre los datos de entrada y su hipotética etiqueta. Estas estimaciones se usan para calcular un cuantil (punto de corte) del conjunto de calibración, que luego define un conjunto de predicción para nuevos puntos de prueba.
El MAPIE implementa una variedad de puntajes de conformidad, incluidos los simétricos (por ejemplo, puntaje residual absoluto para la regresión) y asimétricos (por ejemplo, puntaje gamma para la regresión), que afectan la forma en que se calculan los límites del intervalo de predicción. Para la clasificación se usan evaluaciones específicas como LAC, APS y RAPS.
La elección del puntaje de conformidad no es solo un detalle técnico, sino una decisión estratégica que afecta la utilidad práctica y la interpretabilidad de los conjuntos de predicciones. Diferentes puntajes de conformidad (por ejemplo, LAC, APS) generan distintos comportamientos al generar conjuntos de predicciones.
Por ejemplo, LAC puede producir conjuntos vacíos en condiciones de alta incertidumbre, lo cual puede ser indeseable en finanzas ya que no proporciona ninguna orientación. APS por su diseño evita los conjuntos vacíos y proporciona siempre algún conjunto de resultados plausibles. Esto significa que la elección de la puntuación influye directamente en cómo se representan las muestras "malas" y en si el sistema siempre puede ofrecer una respuesta efectiva (aunque vaga). Un trader cuantitativo debe elegir una valoración que coincida con el nivel deseado de contenido de información y tolerancia al riesgo.
El concepto de "conformidad" permite identificar una observación "atípica" o "inusual" en el contexto de las predicciones de un modelo basado en datos, lo cual resulta muy relevante para detectar condiciones comerciales anormales. En los mercados financieros, los movimientos de precios inusuales, los aumentos repentinos en el volumen o las noticias inesperadas pueden generar puntos de datos que se desvíen significativamente de los patrones históricos.
Una puntuación de conformidad alta para una nueva observación indicaría que la observación "no se corresponde" con los patrones observados en los datos de calibración. Esto puede servir como un sistema de alerta temprana para anomalías del mercado o cambios de modo de mercado, impulsándonos a una revisión de la estrategia de trading o a una suspensión temporal del trading automatizado, y actuando así como una herramienta crítica de gestión de riesgos que va más allá de la simple precisión del modelo.
Análisis detallado de las evaluaciones de conformidad relevantes para la clasificación
MAPIE ofrece varias evaluaciones de conformidad, cada una con sus propias características y aplicabilidad.
- Least Ambiguous Set-valued Classifier (LAC):
- Cálculo : la puntuación de conformidad se define como 1 - softmax_score_of_the_true_label.
- Propiedades : enfoque simple, teóricamente garantiza una cobertura marginal. Generalmente da como resultado pequeños conjuntos de predicciones.
- Aplicabilidad/Limitaciones: tiende a producir conjuntos de predicciones vacíos cuando la incertidumbre del modelo es alta (por ejemplo, cerca de los límites de decisión). Esto puede resultar problemático en finanzas, ya que un conjunto vacío no ofrece orientación práctica.
- Conjuntos de predicción adaptativa (APS):
- Cálculo: los puntajes de conformidad se calculan sumando los puntajes softmax clasificados de cada etiqueta, del más alto al más bajo, hasta alcanzar la etiqueta real.
- Propiedades: supera el problema de conjuntos vacíos de LAC; los conjuntos de predicción son, por definición, no vacíos. Ofrece garantías de cobertura marginal.
- Aplicabilidad : Más robusto para aplicaciones financieras donde alguna forma de predicción (incluso si es incierta) siempre es preferible a un conjunto vacío.
- Regularized Adaptive Prediction Sets (RAPS):
- Cálculo: similar a APS, pero incluye un término de regularización para reducir el tamaño de los conjuntos de predicciones.
- Propiedades: busca equilibrar cobertura y eficiencia regularizando el tamaño del conjunto manteniendo las garantías de cobertura.
- Aplicabilidad: resulta útil en escenarios donde el tamaño del conjunto de pronóstico (efectividad) es tan importante como la cobertura, ya que los conjuntos más pequeños son más efectivos en el comercio.
- Mondrian Conformal Prediction:
- Cálculo: este método calcula para cada clase cuantiles aparte de puntuaciones de conformidad. Esto permite incluir predicciones considerando la clase en el conjunto.
- Propiedades: proporciona cobertura condicional (1 - α) para cada clase, lo cual resulta vital para problemas binarios o de múltiples clases desequilibrados.
- Aplicabilidad: resulta muy recomendable para la clasificación binaria financiera (comprar/vender) donde las clases pueden estar desequilibradas (por ejemplo, menos señales de "comprar" que de "mantener" o "vender") o tener diferentes tolerancias de error. Esto garantiza que la fiabilidad de la señal "comprar" esté garantizada independientemente de la señal "vender".
La evolución de los puntajes de conformidad de LAC a APS/RAPS refleja la necesidad práctica de conjuntos de predicciones eficientes e informativos en aplicaciones del mundo real. Si bien el LAC es conceptualmente simple, su tendencia a crear conjuntos vacíos constituye un inconveniente financiero importante. Un pronóstico vacío establecido para una decisión de compra/venta no ofrece orientación y detiene efectivamente el proceso de toma de decisiones. APS y RAPS, al garantizar conjuntos no vacíos, aseguran que incluso bajo alta incertidumbre el modelo ofrezca algunos resultados plausibles, lo que permite tomar una decisión predeterminada de "mantener" o "reevaluar" en lugar de detenerse por completo. Esto garantiza la continuidad de las operaciones y la gestión de riesgos.
El método Mondrian supone un avance fundamental para la clasificación binaria financiera y aborda directamente el problema de las clases desequilibradas y los efectos de error diferencial. En escenarios de compra/venta, las señales de "comprar" pueden ser raras pero muy rentables, mientras que las señales de "vender" pueden ser más frecuentes pero menos significativas individualmente. Los métodos conformales estándar ofrecen una cobertura marginal, lo que puede significar que la cobertura para la rara clase de "comprar" sea menor que la deseada si se alcanza el promedio general. La capacidad de Mondrian para calcular cuantiles específicos de cada clase garantiza que se mantenga el nivel de confianza deseado para cada clase.
Esto resulta crucial para evitar la subcobertura sistemática de eventos críticos y raros (como fuertes señales de compra) y, por lo tanto, conduce a estrategias de trading más fiables y potencialmente más rentables. Esto garantiza que la robustez del modelo no sea simplemente un promedio, sino que se mantenga para el tipo concreto de transacción bajo consideración.
Etapas de formación de conjuntos predictivos conformales para la clasificación
Vamos a analizar el proceso paso a paso:
- Selección de una medida de no conformidad (o "función de puntuación"): Esto es muy importante. La clasificación a menudo usa la salida de un clasificador previamente entrenado (por ejemplo, la regresión logística, las máquinas de vectores de soporte, la red neuronal o el bosque aleatorio). Digamos que f(x) es la salida del clasificador para los datos de entrada x. Si f(x) genera probabilidades (por ejemplo, de una capa softmax), una buena medida de no conformidad para un punto de datos (xi,yi) podría ser:
- 1 - Probabilidad predicha de la clase verdadera: αi =1−P^(yi ∣xi ). Aquí P^(yi ∣xi ) es la probabilidad prevista de la etiqueta verdadera yi para los datos de entrada xi . Un valor pequeño de αi significa que el modelo confía en su predicción para la clase verdadera, lo cual indica "conformidad". Un αi grande significa que el modelo es menos fiable, lo que indica "no conformidad".
- Usando como base la escala de temperatura softmax: si el modelo produce logits, se puede aplicar softmax para obtener probabilidades. Entonces la estimación de no conformidad será nuevamente 1−P(yi ∣xi ).
- Distancia a la superficie separadora (para SVM): para modelos como SVM que generan una distancia firmada a la superficie separadora, la medida de no conformidad se puede vincular con un valor negativo de esta distancia para puntos clasificados correctamente o un valor positivo de esta distancia para puntos clasificados incorrectamente.
- División de datos para la calibración: para que las predicciones sean estadísticamente fiables, necesitamos calibrar nuestras estimaciones de no conformidad. Esto generalmente se hace dividiendo el conjunto de datos original en dos partes:
- Conjunto de entrenamiento: se usa para entrenar el clasificador básico (por ejemplo, red neuronal, SVM).
- Conjunto de calibración: un conjunto separado de puntos de datos que no se utiliza para entrenar el clasificador, pero que se usa para calcular puntuaciones de no conformidad y determinar el umbral de confianza.
- Cálculo de puntuaciones de no conformidad para datos de calibración: para cada punto de datos (xj,yj) en la muestra de calibración, su puntuación de no conformidad αj se calcula usando un clasificador previamente entrenado.
- Clasificación de las estimaciones de no conformidad y determinación del cuantil (1−δ): todas las estimaciones de no conformidad de la muestra de calibración se clasifican en orden ascendente: α(1) ≤α(2) ≤⋯≤α(m), donde m es el tamaño de la muestra de calibración.
Ahora se selecciona el nivel de significancia deseado δ∈(0,1). Este δ representa la probabilidad de que el conjunto predictivo no contenga la etiqueta verdadera. Por el contrario, 1−δ será la probabilidad de cobertura deseada. Necesitamos encontrar el (1−δ)-ésimo cuantil de estas estimaciones. En concreto, se encuentra el valor más pequeño de q tal que al menos (1−δ)×(m+1) estimaciones de calibración sean menores o iguales a q. Una forma común de calcular este umbral es: q=α(⌈(m+1)(1−δ)⌉)
No obstante, para muestras finitas, para garantizar una cobertura precisa, a menudo es más fiable considerar el cuantil empírico (1−δ) ajustado para muestras finitas. Un enfoque más práctico sería encontrar el α(k) más pequeño tal que k/(m+1)≥1−δ. Digamos que este valor es q^ . - Formación de un conjunto de predicciones para un nuevo punto de prueba: digamos que xtest es la nueva entrada para la que queremos hacer una predicción. Para cada etiqueta posible k en el conjunto de clases (por ejemplo, 1,2,…,C para las clases C), imaginaremos que ytest =k.
Ahora podemos calcular la puntuación de no conformidad αtest,k para el par (xtest ,k) utilizando la medida de no conformidad elegida (por ejemplo, 1−P^(k∣xtest )).
El conjunto predictivo Ytest para xtest se forma incluyendo todas las etiquetas k para las cuales el puntaje de no conformidad αtest,k es menor o igual que el umbral q^ determinado en el paso 4: Ytest ={k∈{1,…,C}∣αtest,k ≤q^ }
Componentes clave de MapieClassifier
MapieClassifier es la clase principal de MAPIE para generar conjuntos de predicciones en problemas de clasificación. Está diseñado para ser compatible con cualquier estimador de scikit-learn con métodos fit, predict y predict_proba. Si no se ofrece ningún estimador, se utilizará LogisticRegression de forma predeterminada.
El parámetro cv permite usar diferentes estrategias de validación cruzada (por ejemplo, "split", "crossval", "prefit") para calcular los puntajes de conformidad, lo cual influye en la diferencia entre los métodos jackknife y CV. La opción "prefit" supone que el estimador ya ha sido entrenado y todos los datos ofrecidos se utilizan para calibrar las predicciones calculando puntajes. El proceso implica dividir los datos en conjuntos de entrenamiento, calibración y prueba, entrenar un modelo de referencia en el conjunto de entrenamiento y luego usar MAPIE para "conformar" el modelo con el conjunto de calibración.
La opción cv="prefit" resulta muy práctica para aplicaciones financieras donde los modelos suelen entrenarse o reajustarse continuamente con grandes conjuntos de datos. En el trading en tiempo real o de alta frecuencia, los modelos se actualizan o entrenan frecuentemente con datos transmitidos. La capacidad de usar un modelo previamente entrenado y luego calibrarlo con un conjunto de datos aparte significa que no es necesario repetir el paso de entrenamiento computacionalmente intensivo para la conformalización. Esto permite que la cuantificación de la incertidumbre se integre de forma eficiente en los sistemas de trading de alto rendimiento existentes sin retrasos significativos.
El parámetro de método (ahora obsoleto en favor de conformity_score) indica el método de predicción conformal. La eliminación del parámetro de método en favor de conformity_score supone un avance hacia una mayor modularidad y control explícito sobre el mecanismo de predicción conformal subyacente. Esta solución arquitectónica permite a los usuarios definir con precisión cómo se mide el "incumplimiento" de su problema particular. En el caso de los datos financieros, donde distintos tipos de errores o incertidumbres pueden resultar más críticos (por ejemplo, clasificar erróneamente una "compra" frente a una "venta"), esta modularidad permite ajustar el proceso de cuantificación de la incertidumbre para que se adapte mejor a métricas de riesgo financiero o objetivos comerciales específicos. Esto ofrece a los usuarios avanzados la capacidad de personalizar el proceso de conformación más allá de los métodos predefinidos.
Conclusiones sobre la parte teórica y recomendaciones
La biblioteca MAPIE es una herramienta poderosa para cuantificar la incertidumbre en modelos de aprendizaje automático, sobre todo en el contexto de la clasificación binaria conformal para aplicaciones financieras. Su capacidad de ofrecer garantías de cobertura para muestras finitas e independientes de la distribución e identificar explícitamente muestras "buenas" y "malas" mejora sustancialmente la fiabilidad y la capacidad de gestión de los riesgos en entornos financieros de alto riesgo.
La capacidad de MAPIE para integrarse con cualquier modelo compatible con scikit-learn ofrece flexibilidad y reduce las barreras de adopción en los sistemas financieros existentes. Pasar de pronósticos puntuales a conjuntos de pronósticos permite tomar decisiones más matizadas e informadas al considerar explícitamente el grado de incertidumbre del modelo. En particular, la distinción entre cobertura marginal y condicional resulta crucial para las aplicaciones financieras, donde la fiabilidad de los pronósticos para clases raras pero críticas (por ejemplo, señales de compra intensas) puede ser de importancia desproporcionada.
Recomendaciones:
- Prioridad de estimadores de conformidad: para la clasificación binaria en finanzas, se recomienda priorizar estimadores de conformidad como APS o RAPS, ya que garantizan conjuntos de pronósticos no vacíos, lo que asegura la continuidad del proceso de toma de decisiones y siempre ofrece alguna forma de inferencia procesable, incluso bajo alta incertidumbre.
- Uso de la predicción conformal de Mondrian: en escenarios con clases desequilibradas o cuando la cobertura condicional para tipos específicos de transacciones (por ejemplo, señales de compra raras) resulta crítica, se debe considerar el uso de la predicción conformal de Mondrian. Este método ofrece garantías de fiabilidad para cada clase individualmente, lo cual evita la subcobertura sistemática de eventos importantes pero raros.
- Validación cuidadosa de series temporales: la aplicación de pronósticos conformales a series temporales financieras requiere una validación cuidadosa y considerar la infracción del supuesto de intercambiabilidad. Si bien MAPIE cuenta con herramientas de series temporales especializadas, como MapieTimeSeriesRegressor, estas deben combinarse con otros métodos concretos de series temporales y pruebas retrospectivas rigurosas para garantizar la solidez frente a la no estacionariedad y los cambios repentinos del mercado.
- Desarrollo de estrategias de trading de múltiples niveles: se deben desarrollar estrategias de trading que aprovechen la interpretabilidad de los conjuntos de pronósticos. Esto permitirá realizar un ajuste dinámico de la exposición al riesgo: por ejemplo, ejecutar operaciones de alta confianza (conjuntos de una sola clase) con capital completo, y para operaciones de baja confianza (conjuntos de múltiples clases) reducir el tamaño de la posición, aplicar cobertura o abstenerse.
Aplicación práctica de la biblioteca MAPIE
La biblioteca MAPIE implementa dos métodos para "conformizar" las predicciones del modelo:
- Split conformal predictions
- Cross conformal predictions
El primer método divide los datos originales en submuestras de entrenamiento y validación. El primero se usa para entrenar el clasificador básico y el segundo se utiliza para calibrar y generar conjuntos de predicciones. El segundo método divide el conjunto de datos en múltiples pliegues y usa entrenamiento cruzado y calibración. Utilizaremos directamente el segundo, ya que debería ser más fiable debido a la validación cruzada. Este es el equivalente en aprendizaje automático del walk-forward: una explicación para aquellos que no están familiarizados con la validación cruzada.
Primero debemos instalar el paquete MAPIE e importar el módulo:
pip install mapie from mapie.classification import CrossConformalClassifier
También debemos instalar e importar las bibliotecas adicionales, enumeradas a continuación.
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_predict from sklearn.model_selection import StratifiedKFold from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from mapie.classification import CrossConformalClassifier from sklearn.ensemble import RandomForestClassifier
A continuación, escribimos una función de prueba que implementa el proceso de conformación y luego genera ejemplos buenos y malos según los conjuntos de predicciones.
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9): dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract features and target feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels'] mapie_classifier = CrossConformalClassifier( estimator=RandomForestClassifier(n_estimators=n_estimators_rf, max_depth=max_depth_rf), confidence_level=confidence_level, cv=5, ).fit_conformalize(X, y) predicted, y_prediction_sets = mapie_classifier.predict_set(X) y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) # Calculate set sizes (sum across classes for each sample) set_sizes = np.sum(y_prediction_sets, axis=1) # Initialize meta_labels data['meta_labels'] = 0.0 # Mark labels as "good" (1.0) only where prediction set size is exactly 1 data.loc[set_sizes == 1, 'meta_labels'] = 1.0 # Report statistics on prediction sets empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}") # Return the dataset with features, original labels, and meta labels return data[feature_columns + ['labels', 'meta_labels']]
Utilizaremos el bosque aleatorio de scikit-learn como clasificador básico, ya que el paquete MAPIE admite todos los clasificadores de este paquete. El bosque aleatorio es un modelo bastante potente con configuraciones flexibles, pero podemos usar otro modelo que consideremos apropiado para nuestras tareas. Para hacer esto, debemos pasar cualquier otro clasificador como estimador en el código resaltado. Vale la pena señalar que este clasificador solo se usará para generar conjuntos predictivos, mientras que CatBoost aún se entrenará como los modelos finales.
Vamos a analizar la función meta_learners_mapie() paso a paso.
Definición de la función y sus parámetros:
def meta_learners_mapie(n_estimators_rf: int, max_depth_rf: int, confidence_level: float = 0.9):
La función toma tres argumentos:
- n_estimators_rf: número de árboles en el bosque aleatorio que se utilizarán como modelo base.
- max_depth_rf: profundidad máxima de cada árbol en el bosque aleatorio.
- confidence_level: nivel de confianza para la predicción conformal (valor predeterminado 0,9, es decir, 90%). Este parámetro determina cómo de "amplios" serán los conjuntos predictivos.
Carga y preparación de datos:
dataset = get_labels(get_features(get_prices()), markup=hyper_params['markup']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
Primero se cargan y preprocesan los datos.
Se supone que existen tres funciones auxiliares:
- get_prices(): carga los datos sin procesar (precios)
- get_features(): extrae o calcula características de los datos devueltos por get_prices()
- get_labels(): genera etiquetas de destino basadas en las características y el parámetro de marcado del diccionario hyper_params.
Luego los datos se filtran según el índice de tiempo. Solo se conservarán aquellos registros cuyo índice esté entre hyper_params['backward'] y hyper_params['forward']. .copy() se utiliza para crear una copia del DataFrame filtrado para evitar problemas con SettingWithCopyWarning.
Extracción de características de X y la variable objetivo y:
feature_columns = list(data.columns[1:-2]) X = data[feature_columns] y = data['labels']
- feature_columns: crea una lista de nombres de columnas que se usarán como características. Se toman todas las columnas salvo la primera (índice 0) y las dos últimas. Esto es específico de la estructura de datos.
- X: crea un DataFrame con características seleccionando columnas de feature_columns.
- y: crea una serie con etiquetas de destino de la columna 'labels'.
Inicialización y entrenamiento del clasificador conformal MAPIE:
mapie_classifier = CrossConformalClassifier(
estimator=RandomForestClassifier(n_estimators=n_estimators_rf,
max_depth=max_depth_rf),
confidence_level=confidence_level,
cv=5,
).fit_conformalize(X, y)
- Se crea una instancia de CrossConformalClassifier de la biblioteca MAPIE. Este es un contenedor que agrega capacidades de predicción conformal a cualquier modelo compatible con scikit-learn.
- Estimador: el RandomForestClassifier de scikit-learn se utiliza como modelo básico (estimador). Luego se transmiten los parámetros n_estimators_rf y max_depth_rf recibidos por la función.
- confident_level: se utiliza el nivel de confianza transmitido a la función. cv=5: Indica el uso de validación cruzada de 5 veces para calibrar el predictor conformal. Este es el enfoque estándar en MAPIE para dividir los datos en conjuntos de entrenamiento y calibración.
- .fit_conformalize(X, y): el método entrena un RandomForestClassifier básico en los datos (X, y) y simultáneamente calibra el predictor conformal. Después de este paso, mapie_classifier estará listo para realizar predicciones conformales.
Obtención de predicciones y conjuntos de predicciones:
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
mapie_classifier.predict_set(X): este método genera dos salidas para los datos de entrada X:
- predicted: predicciones puntuales (una clase por ejemplo), similares al método estándar .predict().
- y_prediction_sets: este es el resultado clave de la predicción conformal. Para cada muestra de datos, se trata de una matriz (o lista de matrices) que indica qué clases están incluidas en el conjunto predictivo con el nivel de confianza dado. Un conjunto predictivo es un conjunto de clases que contiene la clase verdadera con una probabilidad al menos de nivel de confianza. Su forma suele ser (n_samples, n_classes, 1) o (n_samples, n_classes), donde los valores son booleanos (True/False) o 0/1 indicando la inclusión de la clase en el conjunto.
Procesamiento de conjuntos predichos:
y_prediction_sets = np.squeeze(y_prediction_sets, axis=-1) set_sizes = np.sum(y_prediction_sets, axis=1)
- np.squeeze(y_prediction_sets, axis=-1): si y_prediction_sets tiene una dimensión adicional de tamaño 1 al final (por ejemplo, forma (n_samples, n_classes, 1)), esta operación la eliminará, dando como resultado forma (n_samples, n_classes).
- set_sizes = np.sum(y_prediction_sets, axis=1): para cada muestra (a lo largo del eje 0), los valores en y_prediction_sets se suman en todas las clases (a lo largo del eje 1). Si y_prediction_sets contiene 0/1, entonces esta suma dará la cantidad de clases incluidas en el conjunto de predicción para cada ejemplo. Es decir, set_sizes es un array de tamaños de conjuntos de predictores para cada observación.
Generación de metaetiquetas:
data['meta_labels'] = 0.0 data.loc[set_sizes == 1, 'meta_labels'] = 1.0
- data['meta_labels'] = 0.0: se agrega una nueva columna 'meta_labels' a los datos del DataFrame y se inicializa a cero.
- data.loc[set_sizes == 1, 'meta_labels'] = 1.0: este es el paso clave para crear metaetiquetas. Para aquellos ejemplos donde el tamaño del conjunto de predicción (set_sizes) es exactamente 1 (es decir, el modelo predice exactamente una clase con la confianza dada), el valor en la columna 'meta_labels' se establece en 1.0. Esto significa que, para estos ejemplos, el modelo tiene mucha confianza en su única clase prevista. Si el conjunto predictivo está vacío (tamaño 0) o contiene múltiples clases (tamaño >= 2), la metaetiqueta permanecerá 0.0.
Informe de estadísticas de conjuntos previstos:
empty_sets = np.sum(set_sizes == 0) single_element_sets = np.sum(set_sizes == 1) multi_element_sets = np.sum(set_sizes >= 2) print(f"Empty sets (meta_labels=0): {empty_sets}") print(f"Single element sets (meta_labels=1): {single_element_sets}") print(f"Multi-element sets (meta_labels=0): {multi_element_sets}")
La cantidad se calcula:
- empty_sets: conjuntos de predicción vacíos (el modelo no puede seleccionar ninguna clase con la confianza dada).
- single_element_sets: conjuntos que contienen exactamente una clase (predicciones de alta confianza para las que meta_labels=1).
- multi_element_sets: conjuntos que contienen dos o más clases (el modelo no está seguro acerca de una clase en particular).
Resultado de retorno:
return data[feature_columns + ['labels', 'meta_labels']]
La función retorna un DataFrame que contiene las características originales (feature_columns), las etiquetas originales ('labels') y las metaetiquetas recién generadas ('meta_labels'). Estas metaetiquetas se pueden usar, por ejemplo, para entrenar otro modelo (metamodelo) o para seleccionar solo las predicciones más fiables para futuras acciones.
En última instancia, la función usa la predicción conformal para identificar aquellas observaciones para las que el modelo de referencia (Random Forest) realiza una predicción con alta confianza, especificando exactamente una clase posible. Estas observaciones están etiquetadas con una "metaetiqueta" igual a 1.
Refinamiento de la función de conformación
Tras probar la función y evaluar los resultados, llegué a la conclusión de que tiene un inconveniente importante. Si bien hace un gran trabajo al inferir los conjuntos predictivos en los que se entrena el metamodelo final, el modelo básico todavía se entrena en el conjunto de datos original, que puede contener muchos errores, lo que lo hace poco generalizable a nuevos datos. El metamodelo corrige los errores del modelo básico al prohibirle negociar en situaciones de alta incertidumbre, pero debido a la débil generalización del modelo básico, el sistema completo aún funciona mal en un mercado no estacionario.
Recordemos que después de entrenar el clasificador MAPIE, obtenemos dos conjuntos de etiquetas: predicciones del modelo (las etiquetas en sí) y conjuntos predictivos.
predicted, y_prediction_sets = mapie_classifier.predict_set(X)
La función de conformación inicial usa solo los conjuntos predictivos para entrenar el metamodelo, mientras que el modelo base se entrena con las etiquetas del conjunto de datos original. Pero también podemos fijar las etiquetas del modelo básico, dejando solo aquellas en las que el clasificador MAPIE tiene más confianza.
# Initialize meta_labels column with zeros data['meta_labels'] = 0.0 # Set meta_labels to 1 where predicted labels match original labels # Compare predicted values with the original labels in the dataset data.loc[predicted == data['labels'], 'meta_labels'] = 1.0
En el código anterior, comparamos las etiquetas previstas con las originales y formamos una nueva columna 'meta_labels', que contiene unos si las etiquetas coinciden y ceros si no coinciden. Luego entrenaremos el clasificador básico solo en aquellos ejemplos cuyas etiquetas coincidan.
La primera parte de la función de entrenamiento del modelo final ahora se verá así:
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = X[X.columns[1:-3]] X_meta = dataset[dataset.columns[1:-3]] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = y[y.columns[-3]] y_meta = dataset['conformal_labels']
De esta forma, ambos modelos devolverán estimaciones de buena calidad tras el entrenamiento, en la medida de lo posible, en series temporales no estacionarias.
Entrenamiento y prueba del algoritmo
Para probar el método, entrenaremos 10 modelos en un ciclo en el par de divisas EURUSD desde principios de 2020 hasta principios de 2025. Los datos restantes corresponden al periodo forward.
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2025, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learners_mapie(15, 5, confidence_level=0.90, CV_folds=5))) La función meta_leaners_mapie se llamará con los siguientes argumentos:
- 15 árboles de decisión en Random Forest (clasificador básico)
- 5: la profundidad de cada árbol de decisión
- El nivel de confianza del modelo es del 90%
- El número de pliegues para la validación cruzada es de cinco
Durante el proceso de entrenamiento se muestra la siguiente información:
Learn 9 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 6715 Multi-element sets (meta_labels=0): 22948 Correct predictions (meta_labels=1): 16638 Incorrect predictions (meta_labels=0): 13025 R2: 0.9931613891107195
- Conjuntos vacíos: número de conjuntos predictivos vacíos cuando el modelo no confía en ninguna de las clases
- Conjuntos de elementos individuales: número de conjuntos predictivos que contienen un solo elemento. El modelo confía en estas predicciones con una probabilidad de 0,9.
- Conjuntos de múltiples elementos: número de conjuntos predictivos que contienen múltiples clases. El modelo no confía en estos ejemplos.
- Predicciones correctas: número de etiquetas predichas correctamente
- Predicciones incorrectas: número de etiquetas predichas incorrectamente
- R2: estimación de la curva de equilibrio
Usando como base el informe proporcionado, podemos concluir que el conjunto de datos contiene una gran cantidad de datos basura: 6715 predicciones fiables frente a 22948 no fiables. Pero nuestro modelo intentará solucionar esto y solo utilizará las que sean fiables. Como resultado, el gráfico de equilibrio en el simulador se verá así.
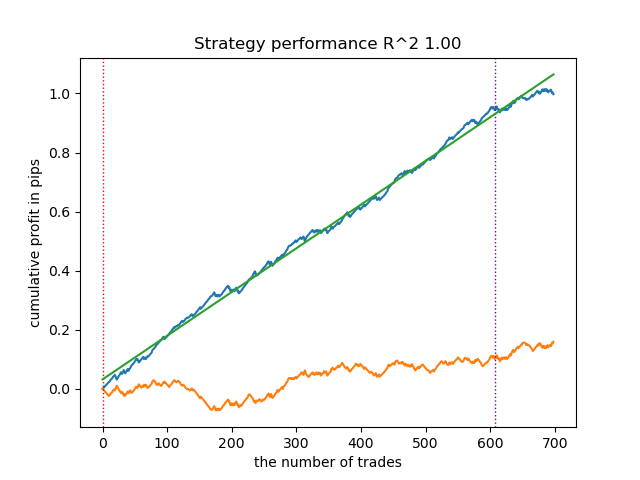
Una característica distintiva de este algoritmo es que ambos modelos (principal y meta) se entrenan con alta precisión:
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.92, 'Logloss': 0.1990666082064606} >>> models[-1][2].get_best_score()['validation'] {'Accuracy': 0.9647435897435898, 'Logloss': 0.10955056411224594}
Esto significa que ahora se ha eliminado gran parte de la incertidumbre de los modelos en comparación con el conjunto de datos original, que contenía una gran cantidad de datos basura. Además, los modelos finales se pueden calibrar para obtener umbrales de decisión más fiables, lo cual está más allá del alcance de este artículo.
¿Qué sucede si el nivel de confianza se reduce de 0,9 a 0,6? Obtendremos más conjuntos que contengan la etiqueta de clase verdadera con un 60% de probabilidad, esto se muestra en el informe.
Learn 8 model Empty sets (meta_labels=0): 0 Single element sets (meta_labels=1): 28647 Multi-element sets (meta_labels=0): 991 Correct predictions (meta_labels=1): 16999 Incorrect predictions (meta_labels=0): 12639 R2: 0.9850582205528567
Mientras que en el ejemplo anterior los conjuntos de un solo elemento contenían pocos ejemplos, ahora su número prevalece sobre los conjuntos de varios elementos, pero la confianza en un resultado exitoso es mucho menor. El gráfico de balance refleja esta incertidumbre porque contiene más caídas.
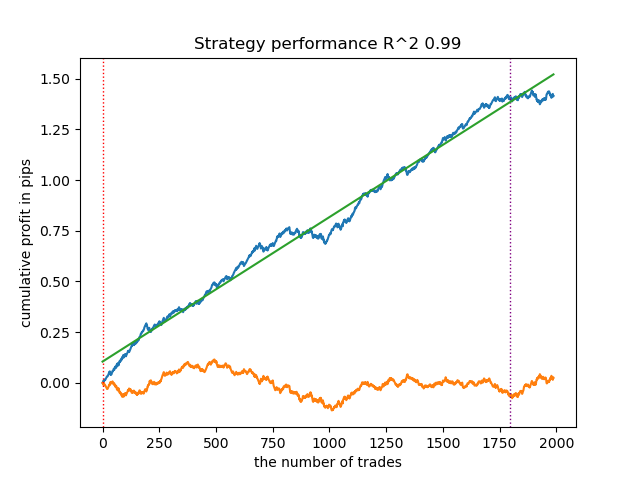
De esta forma, ajustando el nivel de confianza del modelo, podemos controlar los riesgos asociados a operaciones comerciales fallidas. Esto permite buscar un compromiso entre el número de transacciones y la eficiencia del trading, o la probabilidad de un evento cisne negro.
Exportación y prueba de modelos en el terminal Meta Trader 5
La exportación de modelos se implementa exactamente de la misma forma que en todos los artículos anteriores. Para obtener información más detallada, le recomiendo leerlos.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
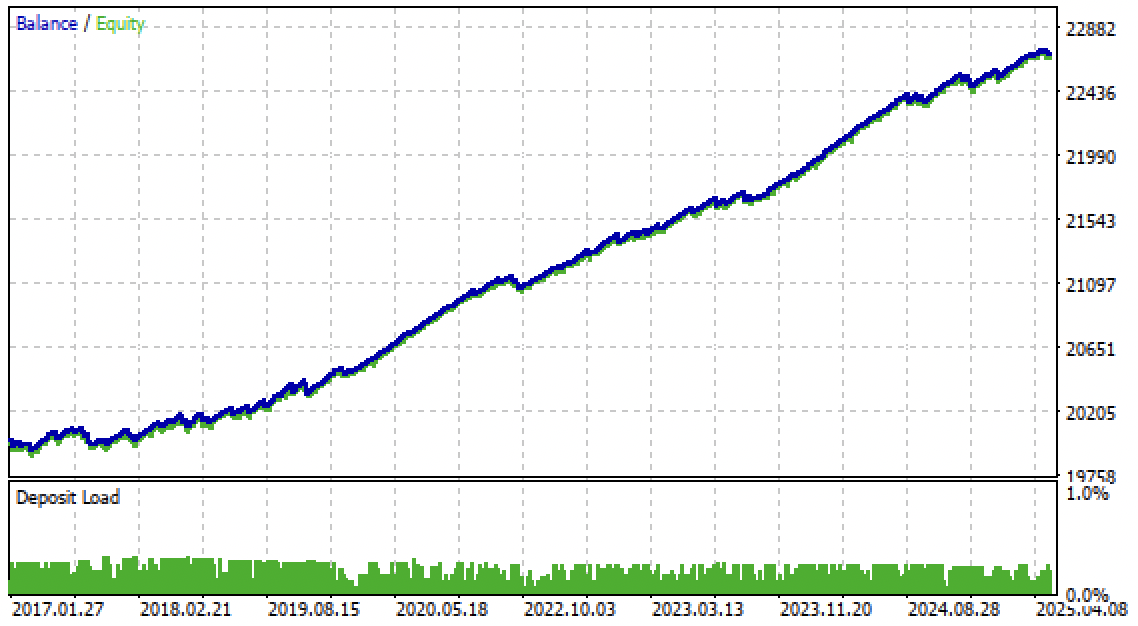
Ahora puede probar el algoritmo en el terminal Meta Trader 5. El sistema comercial ha demostrado ser estable no solo en el periodo forward, sino también en el periodo pasado, de 2017 a 2020.
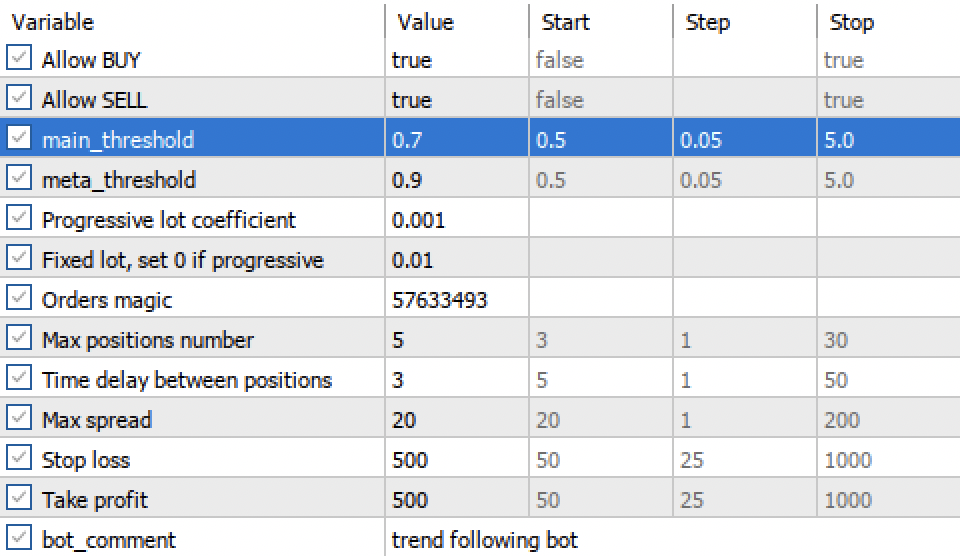
Las configuraciones de umbral principal y umbral meta ahora permiten filtrar las señales del modelo por confianza. Cuanto más alto sea el umbral, más seguro será el trading, pero habrá menos transacciones.
Conclusión
En este artículo, presentamos las predicciones conformales y la biblioteca MAPIE que las implementa. Este enfoque es uno de los más modernos en aprendizaje automático y nos permite centrarnos en la gestión de riesgos para modelos de aprendizaje automático existentes y diversos. Las predicciones conformales, por sí mismas, no suponen una forma de encontrar patrones en los datos. Solo determinan el grado de confianza de los modelos existentes para predecir ejemplos específicos y permiten filtrar las predicciones fiables. Esta importante propiedad permite controlar el riesgo en el trading ajustando el umbral de confianza en la etapa de entrenamiento del modelo.
El archivo Python files.zip contiene los siguientes archivos para desarrollar en el entorno Python:
| Nombre del archivo | Descripción |
|---|---|
| mapie causal.py | Script básico para el entrenamiento de modelos |
| labeling_lib.py | Módulo actualizado con marcadores de transacciones |
| tester_lib.py | Simulador personalizado actualizado para estrategias basadas en aprendizaje automático |
| export_lib.py | Módulo de exportación de modelos al terminal |
| EURUSD_H1.csv | Archivo con las cotizaciones exportadas desde el terminal MetaTrader 5 |
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5:
| Nombre del archivo | Descripción |
|---|---|
| mapie trader.ex5 | Bot recopilado de este artículo |
| mapie trader.mq5 | Bot fuente del artículo |
| carpeta Include//Trend following | Asimismo, encontrará los modelos ONNX y el archivo de encabezado para conectarse al bot |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18324
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola, creo que has olvidado adjuntar el módulo fixing_lib. El módulo está siendo importado en el archivo mapie_causal.py
Buen trabajo. Muchas gracias por su contribución. He hecho algunos cambios y todo funciona bien.