
機械学習の限界を克服する(第8回):ノンパラメトリックな戦略選択

前回の自動戦略選択に関する議論では、候補となる戦略のリストから取引戦略を特定するための2つのアプローチを紹介しました。1つ目は行列分解を用いたホワイトボックス手法で、これはシンプルで透明性が高く、直感的な方法です。そして今回は、より複雑なブラックボックスアプローチをどのように改善できるかに焦点を当てます。
収益性のある戦略を特定することは依然として大きな課題です。本記事では、ブラックボックスモデルの構成や設定を改善する方法に注目します。これまでの方法では、各戦略の期待利益を予測する統計モデルを設計し、その予測を基に有望な戦略を見つけようとしていました。これは確かに有効なアプローチですが、もう少しシンプルな考え方もあります。それは、ブラックボックスモデルが最も学習しやすい戦略を見つけ、その戦略を選択するという方法です。 つまり、モデルが「最もうまく予測できるターゲット」を選ぶという考え方です。しかしここには大きな問題があります。
異なる回帰ターゲットに対するモデル性能を比較することは簡単ではありません。分類タスクでは、精度や適合率のような指標によって比較が容易ですが、回帰では将来のリターンのような実数値のターゲットを扱うため、RMSEのような一般的な指標が誤解を招く可能性があります。その理由は、一般的なユークリッド距離に基づく分散指標がスケールに敏感であるということです。つまり、ストキャスティクスや移動平均のような指標はスケールが異なるため、直接比較することができません。この問題に加えて、古典的な教師あり学習の枠組みでは、このような状況に対する明確な指針がほとんど提供されていません。
ここで有効になるのが相互情報量(MI, Mutual Information)です。MIは回帰ターゲットを比較するうえで適した特性を持っています。非パラメトリックであり、単位に依存せず、さらにゼロを基準とするため、意味のある参照点が得られます。要するに、複数のターゲットの中からどれをモデル化するかを選択する際には、MIを最大化するターゲットを選ぶことを推奨します。
MIは2つの変数の依存関係を測定する指標です。今回の文脈では、モデルの予測が実際のターゲットの変化にどれだけ敏感であるかを捉えることが目的です。本連載の最初の記事では、RMSEが平均リターンを予測するだけのモデルによって歪められてしまう可能性があることを示しました。まだ以前の議論を読んでいない読者は、報酬ハッキングに関する解説へのリンクも参照すると理解が深まるでしょう。要するに、MIはこうした操作に対してより頑健であり、複数の回帰ターゲットがある場合に最も情報量の多いターゲットを特定するための、より信頼できる方法です。
必要なデータの取得
以前からの読者にはおなじみのスクリプトですが、新しい読者のためにここでも掲載しています。このスクリプトは、OHLC市場データに加えて、移動平均、RSI、ストキャスティクスなどのテクニカル指標を取得します。//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define HORIZON 5 //--- Forecast horizon //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[]; //--- File name string file_name = Symbol() + " Market Data As Series Indicators.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_main); ArraySetAsSeries(sto_reading_main,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_signal); ArraySetAsSeries(sto_reading_signal,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- MA OHLC "MA O", "MA H", "MA L", "MA C", //--- RSI "RSI", //--- Stochastic Oscilator "Stoch Main", "Stoch Signal" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- RSI rsi_reading[i], //--- Stochastic Oscilator sto_reading_main[i], sto_reading_signal[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE //+------------------------------------------------------------------+
Pythonで始める
データを取得したら、Pythonで分析を開始します。まず、データを読み込むために使用する標準的なPythonライブラリをインポートします。#Import the standard libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
次に、どの程度先の未来まで予測するかを定義します。
HORIZON = 10
それでは、データを読み込みます。
data = pd.read_csv("../EURUSD Market Data As Series Indicators.csv")
次に、データセットにラベルを追加します。報酬ハッキングに関する前述の議論でも触れたように、ある変数の変化量をラベルとして使用すると問題が生じることがあります。というのも、最良の予測が単に学習セットにおける平均変化量になってしまう場合が多いからです。しかし本記事の後半で示すように、ターゲットを差分化することによって生じる課題があるにもかかわらず、ストキャスティクスのメイン指標の変化を学習することは依然として可能であり、実際に利益につながる結果を得ることができました。
data['Price Target'] = data['Close'].shift(-HORIZON) - data['Close'] data['MA C Target'] = data['MA C'].shift(-HORIZON) - data['MA C'] data['Stoch Target'] = data['Stoch Main'].shift(-HORIZON) - data['Stoch Main'] data['RSI Target'] = data['RSI'].shift(-HORIZON) - data['RSI']
グラウンドトゥルースを定義するため、ターゲットをバイナリ分類の形式でもラベル付けします。まず、すべてのラベルを0で初期化します。
data['Price Target 2'] = 0 data['MA C Target 2'] = 0 data['Stoch Target 2'] = 0 data['RSI Target 2'] = 0
次に、実際のターゲット値が上昇していた場合にはラベルを1に設定します。
data.loc[data['Close'].shift(-HORIZON) > data['Close'],'Price Target 2'] = 1 data.loc[data['MA C'].shift(-HORIZON) > data['MA C'],'MA C Target 2'] = 1 data.loc[data['Stoch Main'].shift(-HORIZON) > data['Stoch Main'],'Stoch Target 2'] = 1 data.loc[data['RSI'].shift(-HORIZON) > data['RSI'],'RSI Target 2'] = 1
続いて、バックテスト期間と重なるデータを削除します。今回の議論では、過去3年間の履歴データを切り離し、それをモデル評価のために保持します。
#Drop the last 3 years of historical data data = data.iloc[:-(365*3),:] test = data.iloc[-(365*3):,:]
次に、入力データとターゲットを分離します。
X = data.iloc[:,1:12] y = data.iloc[:,12:-4] y_classif = data.iloc[:,-4:] X_test = test.iloc[:,1:12] y_test = test.iloc[:,12:-4] y_classif_test = test.iloc[:,-4:]
続いて、機械学習に必要な依存ライブラリを読み込みます。
import onnx from sklearn.linear_model import Ridge from sklearn.ensemble import AdaBoostClassifier from sklearn.neural_network import MLPRegressor from skl2onnx.convert import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit,cross_val_score from sklearn.metrics import root_mean_squared_error from sklearn.feature_selection import mutual_info_regression
これまでの慎重なモデリングに関する議論と同様に、ここでも信頼できる分析結果を得るために時系列クロスバリデーションを使用します。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) 同一のモデルの新しいインスタンスを返すメソッドを定義します。
def get_model(): return(Ridge(alpha=1e-3))
利用可能な各ターゲットについて、それぞれモデルを学習させます。
#Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() model_a.fit(X,y.iloc[:,0]) model_b.fit(X,y.iloc[:,1]) model_c.fit(X,y.iloc[:,2]) model_d.fit(X,y.iloc[:,3])
次に、各モデルのテストセットに対する予測を記録します。ただし、テストデータを用いてモデルを学習させてはいけません。
preds_a = model_a.predict(X_test) preds_b = model_b.predict(X_test) preds_c = model_c.predict(X_test) preds_d = model_d.predict(X_test)
まずは、価格の変化を直接予測しようとしたモデルの性能を確認します。以前からの読者にとっては、これから示す内容は見覚えがあるでしょう。x軸はモデルが予測した値を示し、y軸はその予測値の頻度を表します。グラフ内の3本の破線は、学習セットで観測された平均ターゲット値(中央線)と最も極端な値(外側の線)を示しています。赤い線はテストセットで観測された実際のリターンの頻度を表し、黒い線はモデルの予測値を示しています。ご覧のとおり、モデルは学習セットで学習した平均ターゲット値の周辺に予測を集中させており、市場の実際の変動幅を捉えることができていません。
また、MIスコアがRMSEの値と並んで記録されている点にも注目してください。ただし、カーネル密度推定グラフのタイトルにはMIスコアのみが表示されています。価格モデルが達成したMIは0.04233でした。MIスコアが0に近い場合は望ましくありません。これは、モデルの予測が実際の為替レートと独立していることを示しているからです。
score_1 = mutual_info_regression(y_test.iloc[:,[0]],preds_a) score_1_rmse = root_mean_squared_error(y_test.iloc[:,[0]],preds_a) s = 'Forecasting Price Directly Mutual Information: ' + str(score_1[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,0],color='red') sns.kdeplot(preds_a,color='black') plt.axvline(y.iloc[:,0].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].min(),color='black',linestyle=':') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.grid()
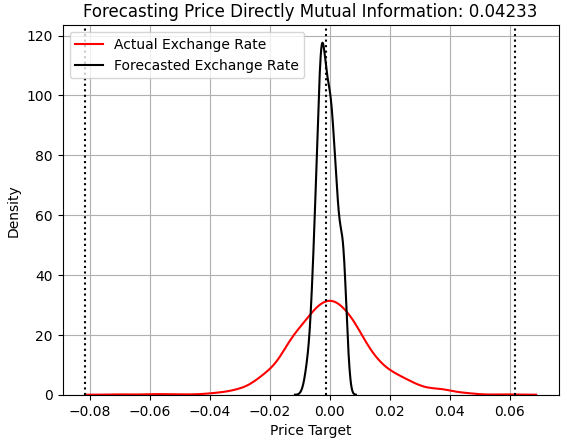
図1:価格を予測するモデルの予測値と、アウトオブサンプルで観測された実際の為替レートの比較
散布図を見ると、この問題はさらに明確になります。モデルの予測値(黒)は、実際の為替レート(赤)の中央付近に並んでいます。これは先に紹介した報酬ハッキングの問題です。従来の「ベストプラクティス」ではRMSEを重視するため、このモデルを実運用の取引に使用することが推奨されてしまう可能性があります。しかしこれから示すように、MIはこの問題を素早く検出し、より堅牢なパフォーマンス指標を提供します。
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,0],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_a,color='black') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Exchange Rate') plt.title(s) plt.grid()

図2:最初のモデルは平均値に張り付く挙動を示しており、これは望ましくない
次に、終値の移動平均指標の変化を予測する統計モデルのパフォーマンスを見てみましょう。グラフの表示形式はすべて同じなので、このモデルも依然としてターゲットの分布の幅を十分に捉えられていないことがすぐに分かります。ただし、MIスコアは0.04から0.1へと100%以上増加しています。しかし図3のKDEプロットだけでは、なぜMIスコアが改善したのかは明確ではありません。
score_2 = mutual_info_regression(y_test.iloc[:,[1]],preds_b) score_2_rmse = root_mean_squared_error(y_test.iloc[:,[1]],preds_b) s = 'Forecasting Moving Average Directly Mutual Information: ' + str(score_2[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,1],color='red') sns.kdeplot(preds_b,color='black') plt.axvline(y.iloc[:,1].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].min(),color='black',linestyle=':') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.grid()
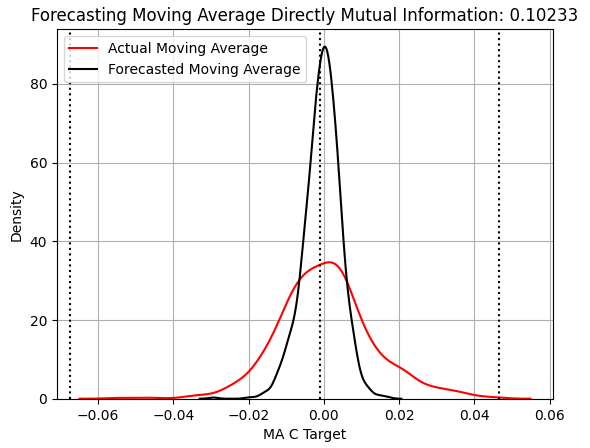
図3:終値移動平均指標の変化を予測する能力の可視化
アウトオブサンプル予測の散布図を見ると、その改善が明確になります。以前は実際の為替レートの中央に細い黒線のように集中していた予測値が、より広い分布に広がり、EURUSD市場の変化に対する感度が高まっていることが分かります。まだ十分とは言えませんが、確実に前進しています。
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,1],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_b,color='black') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title(s) plt.grid()
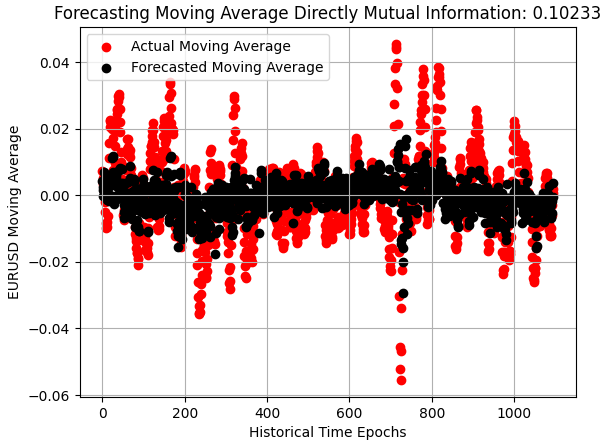
図4:モデルは明確に改善し、市場のボラティリティを捉え始めている
次にストキャスティクス指標を予測するモデルを評価すると、大きな改善が見られます。MIの劇的な上昇を考慮する前でも、このモデルが平均値に張り付かないことが確認できます。このモデルは、テストデータの分布に最も近い形を示しており、市場の分布幅をこれまでのモデルよりもよく捉えています。
score_3 = mutual_info_regression(y_test.iloc[:,[2]],preds_c) score_3_rmse = root_mean_squared_error(y_test.iloc[:,[2]],preds_c) s = 'Forecasting EURUSD Stochastic Directly MI: ' + str(score_3[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,2],color='red') sns.kdeplot(preds_c,color='black') plt.axvline(y.iloc[:,2].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].min(),color='black',linestyle=':') plt.legend(['Actual Stochastic','Forecasted Stochastic']) plt.grid()
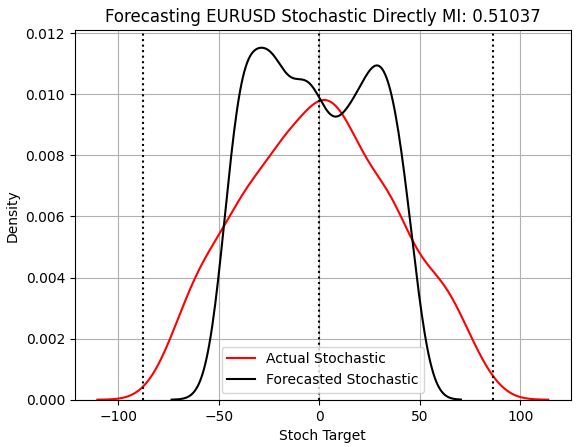
図5:学習から除外していた実際の観測値と対称的な結果が得られ始めている
さらに散布図を見ると、MIが大きく跳ね上がった理由が明確になります。ストキャスティクスモデルはアウトオブサンプルでも非常に良いパフォーマンスを示し、市場のボラティリティをほぼ捉えています。図1と比較すると、なぜMIが回帰ターゲットの自動選択に適しているのかが理解できるでしょう。
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,2],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_c,color='black') plt.ylabel('Growth in The Stochastic Main Indicator') plt.xlabel('Historical Time Epochs') plt.title(s) plt.grid()

図6:ストキャスティクスオシレーターの変化を捉える能力の可視化
次にRSIの予測を検討します。しかし残念ながら、以下に示すようにRSIは移動平均と同様に予測が難しく、MIスコアも再び低下しています。このモデルも市場の分布幅を十分に捉えられていません。ただしテストセットのRSI変化は自然に0付近に集中する傾向があります。それでもモデルはこの割合を過大評価しており、パフォーマンス低下の原因となる可能性があります。
score_4 = mutual_info_regression(y_test.iloc[:,[3]],preds_d) score_4_rmse = root_mean_squared_error(y_test.iloc[:,[3]],preds_d) s = 'Forecasting EURUSD RSI Directly MI: ' + str(score_4[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,3],color='red') sns.kdeplot(preds_d,color='black') plt.axvline(y.iloc[:,3].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].min(),color='black',linestyle=':') plt.grid() plt.legend(['Actual RSI','Forecasted RSI'])
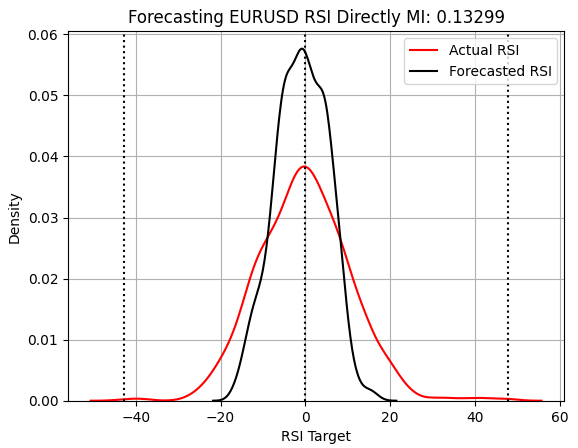
図7:RSIモデルは0付近に集中する予測を過大評価しているように見える
最後に、RSIの予測散布図を確認すると、このモデルは私たちが最初に用いた平均値に張り付くモデルよりは優れていることが分かります。つまり、観測値の中央に沿って単に並ぶだけの挙動ではありません。しかしそれでもなお、ストキャスティクスモデルほどには市場のダイナミクスを捉えることができていません。
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,3],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_d,color='black') plt.legend(['Actual RSI','Forecasted RSI']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title('Visualizing Our Ability To Forecast Change in EURUSD Moving Average') plt.grid()
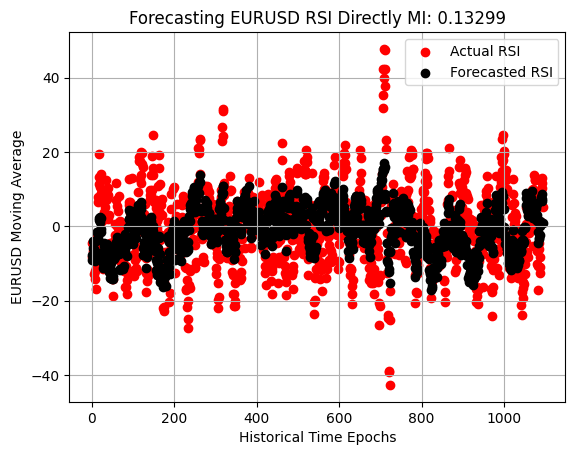
図8:RSIの変化は価格の変化よりは学習できているが、依然として不十分である
これまでの結果から、ストキャスティクスの変化を予測するモデルが、アウトオブサンプルでも最も優れていることは明らかです。散布図を見れば視覚的にも判断できます。そして各ターゲットのMIスコアを棒グラフにすると、明確な勝者が現れます。ただしここで重要なのは、本記事が扱う問題の核心に到達しているという点です。MIスコアだけでなくRMSEも記録しました。RMSEをプロットした場合どうなるのでしょうか。
mi_scores = [score_1,score_2,score_3,score_4] rmse_scores = [score_1_rmse,score_2_rmse,score_3_rmse,score_4_rmse] sns.barplot(mi_scores,color='black') plt.ylabel('Mutual Information Score') plt.xlabel('Target') plt.title('Mutual Information Score') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI'])
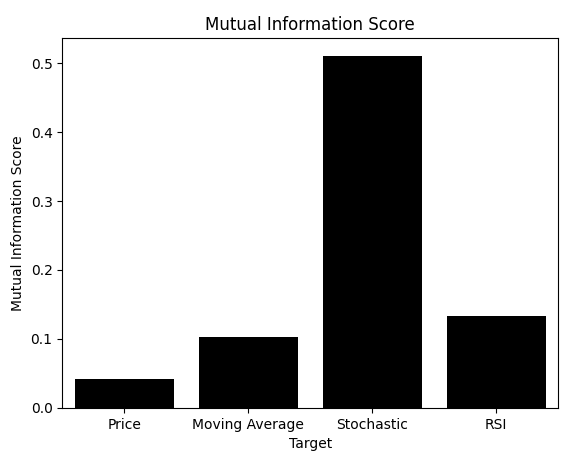
図9:相互情報量はデータのスケールに依存しないため、適切なターゲットを正しく特定できる
示されているように、多くの実務家が依存しているRMSEは、まったく異なる結論を示します。MIとRMSEは解釈が異なることを思い出してください。MIではスコアを最大化するモデルを求めますが、RMSEではスコアを最小化するモデルを選びます。残念ながらRMSEに従うと、視覚的に劣っていることが確認された価格モデルや移動平均モデルを選んでしまう可能性があります。
ここまでの情報を踏まえて、あなたはRMSEとMIのどちらを信頼しますか。すでに問題点がはっきり見えている読者もいるかもしれません。しかし、まだ確信が持てない読者のために、RMSEの弱点をさらに明らかにするもう一つのテストを示します。
sns.barplot(rmse_scores,color='black') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI']) plt.title('RMSE Score ') plt.ylabel('Root Mean Squared Error') plt.xlabel('Target')
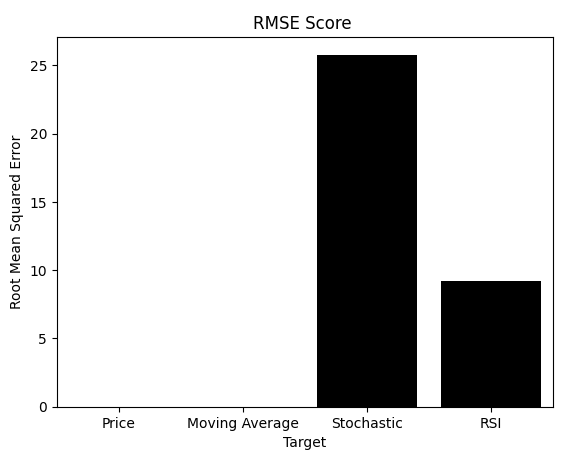
図10:RMSEはストキャスティクスモデルが劣っていると誤って判断させる可能性がある
次に、新しい分類モデルを生成するメソッドを再定義し、各ターゲットの二値変化を分類する場合の精度を比較します。前と同様に同一のモデルを4つ作成し、学習セットでクロスバリデーション精度を測定します。また、学習セットの多数派クラスを単純に予測するだけで得られる精度も追跡しました。これは注意すべき別の報酬ハッキングの形です。結果をプロットすると真実が明らかになります。ストキャスティクスモデルが最も高いパフォーマンスを示しており、MIが先に示していた結論と一致しています。グラフの赤線は報酬ハッキングによって得られる最大精度を示しており、ストキャスティクスモデルのパフォーマンスが本当に有意であることを確認できます。
def get_model(): return(AdaBoostClassifier()) #Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() score = [] score.append(np.mean(cross_val_score(model_a,X,y_classif.iloc[:,0],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_b,X,y_classif.iloc[:,1],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_c,X,y_classif.iloc[:,2],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_d,X,y_classif.iloc[:,3],cv=tscv,scoring='accuracy',n_jobs=-1))) h1 = y_classif.loc[y_classif['Price Target 2'] == 1].shape[0] / y_classif.shape[0] h2 = y_classif.loc[y_classif['MA C Target 2'] == 1].shape[0] / y_classif.shape[0] h3 = y_classif.loc[y_classif['Stoch Target 2'] == 1].shape[0] / y_classif.shape[0] h4 = y_classif.loc[y_classif['RSI Target 2'] == 1].shape[0] / y_classif.shape[0] reward_hacking = [h1,h2,h3,h4] sns.barplot(score,color='black') plt.xticks([0,1,2,3],['Price','MA','Stochastic','RSI']) plt.ylabel('Accuracy Score 100%') plt.xlabel('Potential Target') plt.axhline(np.max(reward_hacking),color='red',linestyle=':') plt.title('Our Accuracy Changes Depending On The Target')
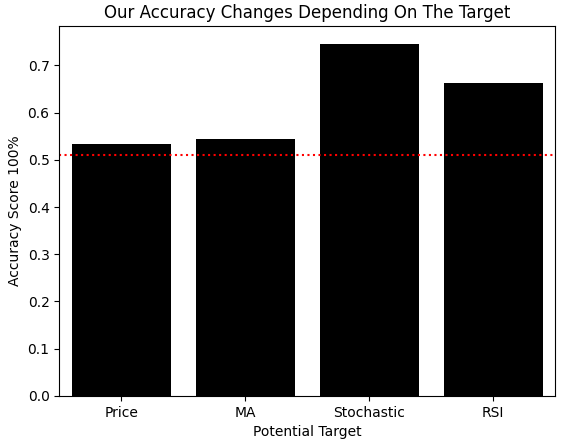
図11:分類問題として設定しても同じ結論に到達する
ブラックボックスモデルが最も学習しやすい戦略を特定できたので、次にデータから直接トレーディングルールを導出できます。たとえば、ストキャスティクスが上昇すると予測された場合、ロングを取るべきでしょうか、それともショートを取るべきでしょうか。その答えを得る一つの方法は、ストキャスティクスのラベルが1だったすべてのケースで平均リターンを計算することです。今回のデータでは平均は0.0052であり、オシレーターが上昇すると予測された場合、ロングポジションを取ることが合理的であると示唆されます。
data.loc[data['Stoch Target 2']==1,'Price Target'].mean()
0.005242425488180883
もちろん、完璧な戦略は存在しません。正のラベルにもかかわらず価格が下落したケースもありました。
data.loc[data['Stoch Target 2']==1,'Price Target'].min()
-0.06370000000000009
しかしこの分析の価値は、直感ではなくデータに基づいて、その戦略が自分のリスク許容度に合っているかを評価できる点にあります。価格とストキャスティクスが同時に上昇した頻度を計算すると、両者は約71%の確率で一致していました。この事前確率は、この戦略に対する信頼をさらに高めてくれます。
print('Price And The Stochastic Rise Together: ',((data.loc[(data['Stoch Target 2']==1 ) & (data['Price Target 2']==1),:].shape[0] / data.loc[data['Price Target 2'] == 1].shape[0])) * 100,'% of the time')
価格とストキャスティクスの上昇が同時に起こる確率: 70.94972067039106%
単純なモデルでもストキャスティクスが学習しやすいことを認識できるのであれば、より柔軟なモデルであるディープニューラルネットワークを適切に設定すれば、この関係をさらにうまく捉えられるはずです。そこで次に、ニューラルネットワークのハイパーパラメータに対してランダムサーチをおこないます。まず評価するすべての入力値をリストアップします。
dist = {
'max_iter':[10,50,100,500,1000,5000,10000,50000,100000],
'activation':['tanh','relu','identity','logistic'],
'alpha':[10e0,10e-1,10e-2,10e-3,10e-4,10-5,10e-6],
'solver':['lbfgs','adam','sgd'],
'learning_rate':['constant','invscaling','adaptive'],
'hidden_layer_sizes':[(11,1),(11,22,33,44,33,22,11,5),(11,4,40,20,2),(11,11),(11,11,11),(11,11,11,11),(11,22,33,44),(11,22,55,22,11),(11,100,11),(11,5,2,5,11),(11,3,9,18,9,3)]
} 続いて、学習中に変更されない固定パラメータを定義します。
#Define the model model = MLPRegressor(shuffle=False,early_stopping=False,random_state=0,verbose=True) #Initialize the randomized search object rscv = RandomizedSearchCV(model,dist,random_state=0,n_iter=40,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1,refit=True) #Perform the search res = rscv.fit(X,y_classif['Stoch Target 2']) res.best_estimator_
ランダムサーチによって最適なモデルを選択したら、それをONNX (Open Neural Network Exchange)形式でエクスポートします。ONNXは広く利用されているオープン標準であり、モデルをフレームワークに依存しない形で移植可能にします。まずモデルが期待する入力と出力の形状を定義します。
initial_types = [('float_input',FloatTensorType([1,X.shape[1]]))] final_types = [('float_output',FloatTensorType([1,1]))]
次に、ONNXモデルをプロトタイプ形式に変換します。これはディスクに保存する前の中間表現として機能します。その後、ONNXの保存関数を使用してモデルを保存します。
onnx_proto = convert_sklearn(model=res.best_estimator_,initial_types=initial_types,final_types=final_types,target_opset=12) onnx.save(onnx_proto,'Unsupervised Strategy Selection Stochastic MLP.onnx')
MQL5でのアプリケーション構築
モデルの準備が整ったので、取引アプリケーションの構築を開始できます。まず、ONNXモデルを読み込み、データ取得と戦略選択の両方でインジケーター計算が一貫しておこなわれるように、システム定数を指定します。//+------------------------------------------------------------------+
//| Automatic Strategy Selection.mq5 |
//| Gamuchirai Ndawana |
//| https://www.mql5.com/ja/users/gamuchiraindawa |
//+------------------------------------------------------------------+
#property copyright "Gamuchirai Ndawana"
#property link "https://www.mql5.com/ja/users/gamuchiraindawa"
#property version "1.00"
//+------------------------------------------------------------------+
//| System resources |
//+------------------------------------------------------------------+
#resource "\\Files\\Unsupervised Strategy Selection Stochastic MLP.onnx" as const uchar onnx_buffer[]; 次に、システム定数を定義します。これにより、テクニカル指標の計算が、データ取得用スクリプトおよび以前の「自動戦略選択」に関する議論で行ったインジケーター計算と一貫するようになります。
//+------------------------------------------------------------------+ //| System definiyions | //+------------------------------------------------------------------+ #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define TOTAL_STRATEGIES 4 //--- Total strategies we have to choose from #define ONNX_INPUTS 11 //--- Total inputs needed by our ONNX model #define ONNX_OUTPUTS 1 //--- Total outputs needed by our ONNX modelまた、市場でのポジション管理を支援するために、Tradeライブラリも必要になります。
//+------------------------------------------------------------------+
//| System libraries |
//+------------------------------------------------------------------+
#include <Trade\Trade.mqh>
CTrade Trade; 取引アプリケーションに必要なグローバル変数として、時間、インジケーターの値、モデル予測を追跡するための変数をいくつか定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_c_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle,atr_handle; double ma_c_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[],atr_reading[]; long onnx_model; vectorf onnx_features,onnx_targets; MqlDateTime ts,tc; MqlTick current_tick;
次に、OnnxCreateFromBufferメソッドを使用してONNXバッファからONNXモデルを作成し、モデルを初期化します。入力と出力の次元を定義してテストし、最終確認をおこない、問題がなければ時間追跡と必要なテクニカル指標を初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the model's inputs and outputs onnx_features = vectorf::Zeros(ONNX_INPUTS); onnx_targets = vectorf::Zeros(ONNX_OUTPUTS); //--- Create the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Define the I/O shape ulong input_shape[] = {1,ONNX_INPUTS}; ulong output_shape[] = {ONNX_OUTPUTS,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Print("Failed to define ONNX input shape"); return(INIT_FAILED); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Print("Failed to define ONNX output shape"); return(INIT_FAILED); } //--- Check if the model is valid if(onnx_model == INVALID_HANDLE) { Print("Failed to create our ONNX model from buffer"); return(INIT_FAILED); } //--- Setup the time TimeLocal(tc); TimeLocal(ts); //---Setup our technical indicators ma_c_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); atr_handle = iATR(_Symbol,PERIOD_CURRENT,14); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //--- return(INIT_SUCCEEDED); }
アプリケーションの使用が終了した場合には、ONNXモデルやテクニカル指標に割り当てられたリソースを解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); IndicatorRelease(rsi_handle); IndicatorRelease(stoch_handle); IndicatorRelease(atr_handle); }
新しい価格が到着するたびに、まず新しい日足ローソク足が形成されたかを確認し、時間とすべてのテクニカル指標の値を更新します。各モデル入力はONNXモデルとの互換性を保つために浮動小数点に変換され、予測を生成します。この予測を市場へのエントリー条件と比較し、適切なポジションを決定します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- TimeLocal(ts); if(ts.day != tc.day) { //--- Update the time TimeLocal(tc); //--- Update Our indicator readings CopyBuffer(ma_c_handle,0,0,1,ma_c_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); CopyBuffer(rsi_handle,0,0,1,rsi_reading); CopyBuffer(stoch_handle,0,0,1,sto_reading_main); CopyBuffer(stoch_handle,0,0,1,sto_reading_signal); CopyBuffer(atr_handle,0,0,1,atr_reading); //--- Set our model inputs onnx_features[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); onnx_features[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); onnx_features[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); onnx_features[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); onnx_features[4] = (float) ma_o_reading[0]; onnx_features[5] = (float) ma_h_reading[0]; onnx_features[6] = (float) ma_l_reading[0]; onnx_features[7] = (float) ma_c_reading[0]; onnx_features[8] = (float) rsi_reading[0]; onnx_features[9] = (float) sto_reading_main[0]; onnx_features[10] = (float) sto_reading_signal[0]; //--- Copy Market Data double close = iClose(Symbol(),PERIOD_CURRENT,0); SymbolInfoTick(Symbol(),current_tick); //--- Place a position if(PositionsTotal() ==0) { if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_features,onnx_targets)) { Comment("Onnx Model Prediction: \n",onnx_targets); //--- Store our result if(LongConditions()) Buy(); else if(ShortConditions()) Sell(); } else { Print("No trading oppurtunities expected."); } } } } //+------------------------------------------------------------------+
市場へのエントリー条件は専用のメソッドで定義されています。ONNXの予測値が0.5を超える場合、ストキャスティクスは上昇すると予測されます。オシレーターが50以上でなお上昇している場合にはロングポジションを取ります。また、オシレーターがクラシカルな30以下の場合もロングエントリーをおこないます。さらに、陽線包み足(bullish engulfing candle)が出現した場合もロング条件として扱います。ショートエントリーについてはその逆となります。
//+------------------------------------------------------------------+ //| The market conditions we require to open short positions | //+------------------------------------------------------------------+ bool ShortConditions(void) { return(((onnx_targets[0] < 0.5) && (sto_reading_main[0]<50)) || (sto_reading_main[0]<80) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)<iOpen(Symbol(),PERIOD_CURRENT,2))); } //+------------------------------------------------------------------+ //| The market conditions we require to open long positions | //+------------------------------------------------------------------+ bool LongConditions(void) { return(((onnx_targets[0] > 0.5) && (sto_reading_main[0]>50)) || (sto_reading_main[0]>30) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)>iOpen(Symbol(),PERIOD_CURRENT,2))); }
ポジションを取る際には、ロング、ショートいずれの場合も、エントリーごとに同じロットサイズを使用し、利確と損切りのレベルを均等に設定します。
//+------------------------------------------------------------------+ //| Enter a long position | //+------------------------------------------------------------------+ void Buy(void) { Trade.Buy(0.01,Symbol(),current_tick.ask,current_tick.ask-(1.5*atr_reading[0]),current_tick.ask+(1.5*atr_reading[0])); } //+------------------------------------------------------------------+ //| Enter a short position | //+------------------------------------------------------------------+ void Sell(void) { Trade.Sell(0.01,Symbol(),current_tick.bid,current_tick.bid+(1.5*atr_reading[0]),current_tick.bid-(1.5*atr_reading[0])); } //+------------------------------------------------------------------+
アプリケーションの終了時には、すべてのシステム定数を解除します。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_PERIOD #undef MA_TYPE #undef RSI_PERIOD #undef STOCH_K #undef STOCH_D #undef STOCH_SLOWING #undef STOCH_MODE #undef STOCH_PRICE #undef TOTAL_STRATEGIES #undef ONNX_INPUTS #undef ONNX_OUTPUTS //+------------------------------------------------------------------+
アプリケーションのセットアップが完了したら、前回のモデル学習で使用せずに取っておいた3年間のバックテスト期間を選択します。バックテスト期間は2022年1月から2025年1月以降までをカバーします。
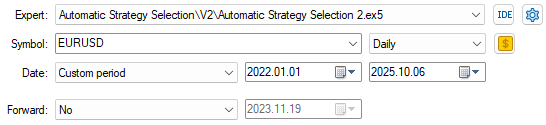
図12:バックテストウィンドウを選択して戦略を評価する
実ティックに基づいたモデル化を、ランダム遅延設定と組み合わせて使用すると、実際の市場環境の信頼性の高いシミュレーションが可能です。
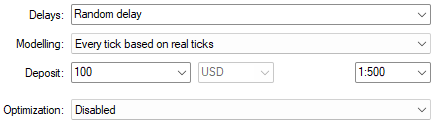
図13:現実的な期待値を学習するためのバックテスト条件を選択する
改良したブラックボックスソリューションによって得られたエクイティカーブは強い上昇傾向を示しており、戦略の健全性を確認できます。また、戦略が一時的に苦戦した期間もありますが、各ドローダウンから回復していることが確認でき、戦略の回復力が示されています。
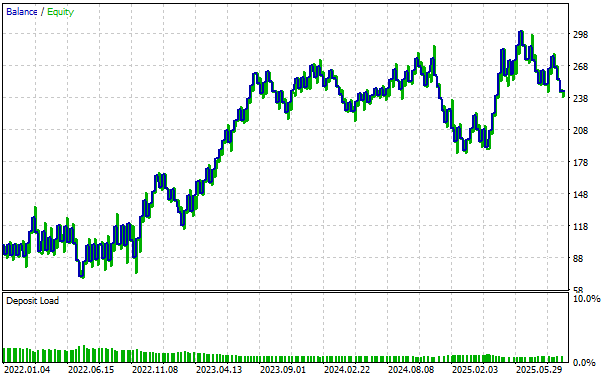
図14:改良した取引戦略に従ったエクイティカーブの可視化により、変更内容の有効性を確認する
最後に、戦略の詳細統計を分析すると、すべての可能な戦略をモデル化しようとした最初の試みと比較して大幅な改善が見られます。戦略は収益性があり、強い回復力と利益ファクターを示しました。
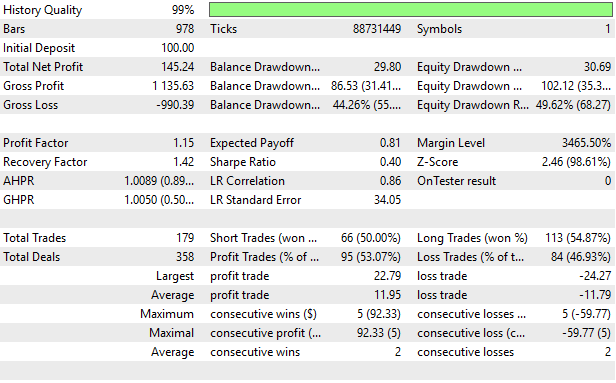
図15:改良されたブラックボックスソリューションによる詳細結果の可視化
結論
これで議論を終える段階に到達しました。本記事では、ブラックボックスソリューションをどのように構成すれば、自動的に有効な戦略を特定できるかを慎重に示しました。前回の議論では、可能なすべての戦略をモデル化した上で、最も利益が期待できる戦略のシグナルだけを取得する方法を試み、バックテスト期間中に38.58ドルの利益を得ました。本記事では、相互情報量を用いて統計モデルが最も効率的に学習できる戦略を素早く特定する方法を提案し、同じバックテスト期間における利益を145.24ドルまで改善しました。ポジションサイズや取引量など、その他の変数はすべて同じ条件で比較しています。
今回提案したソリューションにより、シャープレシオも初期の0.13から0.4へ改善しました。本記事では、数値的手法を用いてブラックボックスソリューションを慎重に構成する方法、そして特に従来の「ベストプラクティス」の盲点を回避する方法、たとえばRMSEに過度に依存した回帰モデルのクロスバリデーションや、モデルが平均値に張り付く挙動を無条件に報酬として評価してしまう傾向に対処する方法を解説しました。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20317
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索