
Нейросети в трейдинге: Модели с использованием вейвлет-преобразования и многозадачного внимания (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспекты фреймворка Multitask-Stockformer, а также начали реализацию предложенных подходов средствами MQL5. Multitask-Stockformer сочетает два мощных инструмента: дискретное вейвлет-преобразование, которое обеспечивает глубокий анализ временных рядов, и многозадачные модели Self-Attention, способные выявлять сложные зависимости финансовых данных. Такой симбиоз позволяет создать универсальный инструмент для анализа и прогнозирования временных рядов.
Основу фреймворка составляют 3 блока. В модуле декомпозиции временных рядов осуществляется разделение анализируемых данных на высоко- и низкочастотные составляющие. Низкочастотные компоненты отражают глобальные тренды и обеспечивают анализ долгосрочных закономерностей. В то же время высокочастотная составляющая фиксирует краткосрочные колебания, включая всплески активности и аномалии. Детальная декомпозиция данных позволяет улучшить качество их обработки, а также облегчает выделение ключевых особенностей, что играет критически важную роль при работе с временными рядами финансовых рынков.
После декомпозиции данные поступают на обработку в двухчастотный пространственно-временной энкодер. Этот блок объединяет несколько модулей и предназначен для анализа выделенных частотных составляющих, а так же их взаимозависимостей. Низкочастотные сигналы обрабатываются механизмом временного внимания. Он фокусируется на долгосрочных трендах и их изменениях. Высокочастотные данные, в свою очередь, проходят через расширенные причинно-следственные сверточные слои, позволяющие выделять мельчайшие изменения и их динамику. Затем обработанные сигналы интегрируются модулями внимания к графам, которые фиксируют пространственно-временные зависимости, отражающие взаимосвязи между различными активами и временными интервалами. Этот процесс позволяет получить многоуровневые графовые представления, которые преобразуются в многомерные эмбединги. Последние объединяются с использованием механизмов сложения и внимания к графам, создавая целостное представление о данных для дальнейшего анализа.
Ключевым этапом обработки является двухчастотный декодер слияния, который играет решающую роль в формировании прогнозных результатов. Декодер интегрирует предикторы, используя механизм Fusion Attention, что позволяет агрегировать данные низкочастотных и высокочастотных сигналов в единое латентное представление. Которое отражает временные паттерны различных масштабов, обеспечивая комплексный подход к анализу данных. На этом этапе модель создает скрытые представления, которые затем обрабатываются специализированными полносвязными слоями. Эти слои позволяют решать сразу несколько задач: прогнозировать доходность активов, определять вероятности изменения трендов и находить другие ключевые характеристики временных рядов. Подход многозадачной обработки делает модель гибкой и адаптируемой к разнообразным рыночным условиям, что особенно важно в условиях высокой волатильности финансовых рынков.
Авторская визуализация фреймворка Multitask-Stockformer представлена ниже.
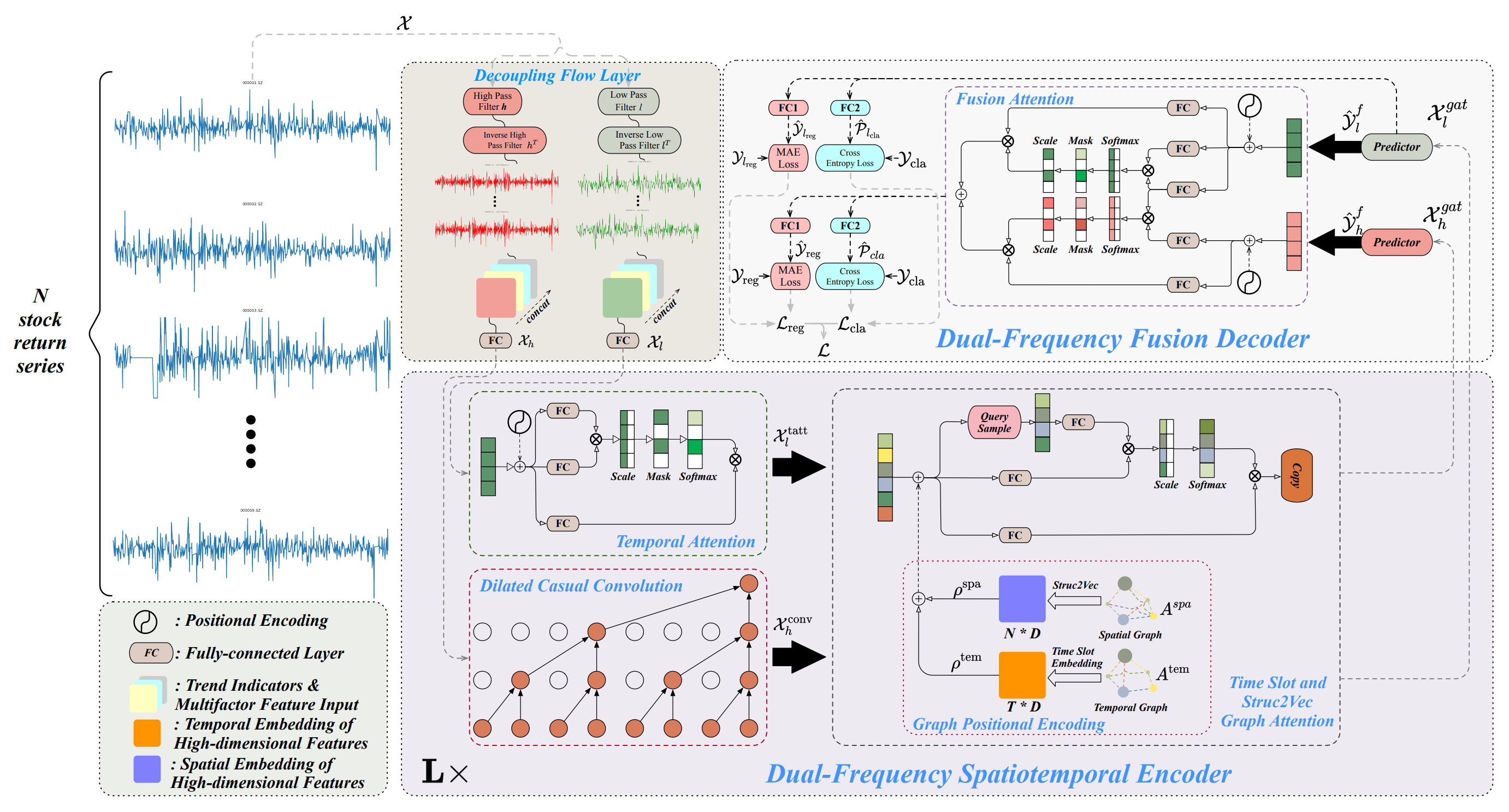
Реализация фреймворка Multitask-Stockformer
Продолжаем нашу работу по реализации подходов, предложенных авторами фреймворка Multitask-Stockformer, средствами MQL5. Что подразумевает практическую реализацию ключевых компонентов системы, направленных на оптимизацию анализа временных рядов.
Одним из базовых элементов фреймворка является модуль декомпозиции временных рядов, реализованный нами в рамках класса CNeuronDecouplingFlow. Этот компонент обеспечивает разделение исходных данных на высоко- и низкочастотные компоненты, что создаёт основу для их дальнейшего анализа. Главной задачей модуля является выделение ключевых структурных характеристик временных рядов с учётом их специфики и потенциальных рыночных трендов. В предыдущей статье нами были рассмотрены архитектурные особенности и алгоритмические решения, лежащие в основе построения класса CNeuronDecouplingFlow.
Следующим этапом обработки данных является их анализ с использованием двухчастотного пространственно-временного энкодера. Как было сказано выше, авторы фреймворка предложили сложную архитектуру энкодера, включающую два независимых потока данных. При этом каждая магистраль имеет свою архитектуру.
Низкочастотные компоненты анализируются с применением механизма временного внимания, основанного на архитектуре Self-Attention. Эта архитектура предоставляет широкие возможности для выявления долгосрочных зависимостей и прогнозирования глобальных рыночных тенденций. Применение Self-Attention обеспечивает глубокое понимание сложных структур данных, минимизируя риски упущения значимых взаимосвязей. В рамках текущей реализации было принято решение использовать один из числа уже существующих в нашей библиотеке модулей внимания с использованием механизма Self-Attention.
Высокочастотные компоненты временных рядов подвергаются обработке с использованием модуля расширенной причинно-следственной свертки, который был реализован в рамках класса CNeuronDilatedCasualConv. Усовершенствованные алгоритмы позволят эффективно выявлять локальные аномалии и всплески активности. Этот компонент играет важную роль в анализе краткосрочной рыночной динамики, включая периоды высокой волатильности. Включение данного модуля в общую архитектуру фреймворка способствует повышению его адаптивности и производительности. Архитектурные решения и локальные изменения авторского фреймворка, которые мы использовали при построении класса CNeuronDilatedCasualConv, обсуждались в предыдущей статье.
После предварительной обработки высоко- и низкочастотной компонент анализируемого сигнала данные направляются в отдельные магистрали слота внимания графов. В основе данного модуля лежит создание двух специализированных графов. Первый граф моделирует временные зависимости, выделяя их последовательную структуру. Этот граф играет важную роль в выявлении трендов, цикличности и других временных характеристик. Второй граф базируется на матрице корреляций цен финансовых активов, обеспечивая глубокую интеграцию информации о взаимосвязях между активами. Это позволяет учитывать влияние одного актива на другой, что особенно важно для финансового моделирования и прогнозирования. Вместе эти графы образуют многоуровневую структуру, которая повышает точность анализа и интерпретации данных.
Для преобразования информации графов в аналитически пригодные представления используется алгоритм Struct2Vec. Этот алгоритм переводит топологические свойства графов в компактные векторные эмбединги, которые затем дополнительно оптимизируются с помощью обучаемых полносвязных слоёв. Такие эмбединги позволяют эффективно интегрировать локальные и глобальные особенности данных, повышая качество анализа временных рядов. После этого обработанные данные направляются в магистрали внимания графов, где они подвергаются дальнейшему изучению с использованием механизмов внимания. Этот этап позволяет выявлять как краткосрочные, так и долгосрочные зависимости.
Авторы фреймворка Multitask-Stockformer предложили довольно сложную архитектуру слота внимания графов. И её реализация требует значительных вычислительных ресурсов и тщательной подготовки данных. В рамках подготовки модели для данной статьи мы применили некоторые упрощения, направленные на повышение практичности использования модели при сохранении её высокой производительности. Первое упрощение заключалось в исключении временной информации об анализируемом состоянии окружающей среды. Этот шаг был сделан на основании предположения, что временная информация на данном этапе, хотя и полезна, не оказывает критическое влияния на общую эффективность нашей модели. В оригинальной версии фреймворка выходом являлся сформированный пакет акций, тогда как в нашей реализации основной целью является создание латентного представления окружающей среды. Это представление используется моделью Актера для принятия торговых решений, который дополнительно получает данные о состоянии счёта и временных меток. Что обеспечивает контекстуальную осведомлённость модели. Таким образом мы просто переносим точку передачи модели временной составляющей.
Однако упрощение, применённое к графу временных зависимостей, не может быть перенесено на граф корреляции активов, так как это привело бы к потере ключевой информации. Вместо этого мы предлагаем альтернативное решение, заменив предложенную структуру на обучаемый слой позиционного кодирования. Этот подход позволяет эффективно обучать эмбединги, минимизируя вычислительную сложность и сохраняя важные взаимосвязи между активами, которые модель самостоятельно извлекает в процессе обучения. Такое улучшение обеспечивает более гибкую архитектуру, способную адаптироваться к различным рыночным условиям.
Кроме того, мы сделали ещё один шаг вперёд, заменив слоты внимания графов на модули адаптивного сглаживания признаков узлов (Node-Adaptive Feature Smoothing — NAFS). Важным преимуществом данного метода является отсутствие обучаемых параметров в модулях NAFS, что не только сокращает вычислительную сложность, но и упрощает процесс настройки и обучения модели.
При использовании NAFS процесс построения эмбедингов становится более гибким и устойчивым, так как методика сглаживания адаптируется к топологии графа и характеристикам его узлов. Это особенно важно при решении задач, где структура данных может быть неоднородной или динамически изменяющейся. Таким образом, применение NAFS обеспечивает создание высококачественных представлений данных, которые одновременно учитывают локальные и глобальные взаимосвязи в графе.
Агрегация двух потоков информации осуществляется в двухчастотном декодере, который интегрирует различные аспекты данных, создавая основу для многомерного анализа. Это позволяет получить более полное представление о динамике изменения сигналов. В основе двухчастотного декодера лежит механизм Fusion Attention, который сочетает два параллельных модуля внимания. Первый из них, основанный на механизме Self-Attention и специализируется на глубокой обработке низкочастотной составляющей, выделяя ключевые долгосрочные зависимости, устойчивые тренды и глобальные закономерности. Благодаря этому модулю становится возможным выявление фундаментальных характеристик временных рядов, которые играют решающую роль в прогнозировании. Второй модуль использует механизм Cross-Attention для интеграции высокочастотной информации, добавляя краткосрочные и детализированные компоненты в анализ. Такая интеграция позволяет значительно обогатить низкочастотные данные деталями, что особенно важно для учёта мелких, но значимых флуктуаций.
Оба модуля внимания работают синхронно, что обеспечивает создание согласованных и взаимодополняющих представлений данных. Их результаты объединяются путем суммирования, после чего передаются на обработку в полносвязные слои (MLP). Такой подход обеспечивает учёт глобальных и локальных особенностей исследуемого сигнала, позволяя учитывать широкий спектр взаимосвязей и влияний.
Предложенная архитектуры Fusion Attention может быть легко реализована уже существующими модулями Cross- и Self-Attention. Более того, её реализация не требует значительных изменений в базовых алгоритмах.
Таким образом, можно сделать вывод о наличии всех ключевых модулей для создания комплексной архитектуры фреймворка Multitask-Stockformer. Это создаёт основу для перехода к следующему этапу разработки — формированию высокоуровневого объекта, который объединит все указанные модули в единый, функционально завершённый алгоритм. Основная задача этого этапа заключается не только в интеграции компонентов, но и в обеспечении их синхронной работы с учётом особенностей каждого модуля. Ниже представлена структура нового объекта CNeuronMultitaskStockformer.
class CNeuronMultitaskStockformer : public CNeuronBaseOCL { protected: CNeuronDecouplingFlow cDecouplingFlow; CNeuronBaseOCL cLowFreqSignal; CNeuronBaseOCL cHighFreqSignal; CNeuronRMAT cTemporalAttention; CNeuronDilatedCasualConv cDilatedCasualConvolution; CNeuronLearnabledPE cLowFreqPE; CNeuronLearnabledPE cHighFreqPE; CNeuronNAFS cLowFreqGraphAttention; CNeuronNAFS cHighFreqGraphAttention; CNeuronDMHAttention cLowFreqFusionDecoder; CNeuronCrossDMHAttention cLowHighFreqFusionDecoder; CNeuronBaseOCL cLowHigh; CNeuronConvOCL cProjection; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultitaskStockformer(void) {}; ~CNeuronMultitaskStockformer(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultitaskStockformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Представленная структура включает множество внутренних объектов, которые напрямую отражают описанные выше модули фреймворка Multitask-Stockformer. Эти компоненты организованы таким образом, чтобы обеспечить высокую степень функциональной интеграции и гибкости в реализации. Мы детально разберём алгоритмы их взаимодействия, а также потоки передачи информации в процессе реализации методов интеграционного объекта.
Все внутренние объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех вновь объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronMultitaskStockformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, neurons_out, optimization_type, batch)) return false;
В параметрах данного метода среди уже известных нам констант мы видим одну новую — neurons_out. В ней указывается величина вектора латентного представления анализируемого состояния окружающей среды, которое пользователь ожидает получить на выходе данного блока Multitask-Stockformer. И именно его мы передаем при вызове одноименного метода родительского класса, в котором осуществляется инициализация базовых интерфейсов обмена данными с внешними нейронными слоями в рамках модели.
После успешного выполнения метода родительского класса мы переходим к инициализации внутренних объектов. Данный процесс мы, как обычно, осуществляем в порядке использования объектов при прямом проходе. Как уже было сказано выше, получаемые исходные данные сначала разделяются на высоко- и низкочастотные компоненты в модуле декомпозиции сигнала CNeuronDecouplingFlow.
uint index = 0; uint wave_window = MathMin(24, units_count); if(!cDecouplingFlow.Init(0, index, OpenCL, wave_window, 2, units_count, filters, window, optimization, iBatch)) return false; cDecouplingFlow.SetActivationFunction(None);
Обратите внимание, что во внешних параметрах нашего метода инициализации интеграционного объекта мы не указали размер и шаг окна дискретного вейвлет-преобразования. Указанные параметры мы зададим фиксированными значениями непосредственно в методе. В рамках данной статьи мы планируем проводить эксперименты на исторических данных таймфрейма H1. Исходя из этого допущения мы ограничим размер окна вейвлет-преобразования одними сутками, что составляет 24 шага анализируемой последовательности. При этом добавим контроль не превышения размера анализируемого мультимодального временного ряда. Шаг окна мы указываем равным 2, что соответствует пропуску одного элемента последовательности.
На выходе модуля декомпозиции данных формируется единый тензор, содержащий высоко- и низкочастотные компоненты анализируемого сигнала. Однако для обработки этих данных в двухчастотном пространственно-временном энкодере предусмотрены два параллельных потока, где каждая из компонент анализируется отдельно. Для реализации такого подхода мы разделяем данные, помещая каждую из компонент в собственный объект. Это обеспечит удобство и гибкость их дальнейшей обработки.
//--- Dual-Frequency Spatiotemporal Encoder uint wave_units_out = cDecouplingFlow.GetUnits(); index++; if(!cLowFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cLowFreqSignal.SetActivationFunction(None); index++; if(!cHighFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cHighFreqSignal.SetActivationFunction(None); index++;
Низкочастотная компонента обрабатывается в модуле временного внимания, основанном на механизме Self-Attention. В оригинальной версии фреймворка Multitask-Stockformer авторы предлагают добавить позиционное кодирование для улучшения обработки последовательностей. Однако мы решили использовать модуль внимания с относительным кодированием, который включает встроенный механизм определения относительных позиций элементов последовательности. Это делает избыточным дополнительное позиционное кодирование, упрощая архитектуру и одновременно повышая её эффективность.
if(!cTemporalAttention.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; cTemporalAttention.SetActivationFunction(None); index++;
Следует отметить, что размерность вектора, описывающего один элемент последовательности, соответствует количеству фильтров, используемых в вейвлет-преобразовании. При этом размерность анализируемой последовательности охватывает все унитарные временные ряды. Такой подход обеспечивает возможность изучения взаимозависимостей трендов во всей мультимодальной последовательности, а не ограничивается анализом её отдельных компонентов.
Анализ высокочастотных зависимостей осуществляется в модуле расширенной причинно-следственной свертки. На этот раз мы напротив используем минимальный размер окна свертки из 2 элементом с аналогичным шагом. Здесь анализ осуществляем исключительно в пределах унитарных последовательностей, что позволяет сосредоточиться на детальном исследовании локальных зависимостей.
if(!cDilatedCasualConvolution.Init(0, index, OpenCL, 2, 2, filters, wave_units_out, window, layers, optimization, iBatch)) return false; index++;
Затем мы добавляем позиционное кодирование обоим компонентам.
if(!cLowFreqPE.Init(0, index, OpenCL, cTemporalAttention.Neurons(), optimization, iBatch)) return false; index++; if(!cHighFreqPE.Init(0, index, OpenCL, cDilatedCasualConvolution.Neurons(), optimization, iBatch)) return false; index++;
Важно отметить, что каждая компонента получает отдельный слой обучаемого позиционного кодирования. Такой подход даёт возможность глубже анализировать и понимать структуру высоко- и низкочастотных составляющих независимо друг от друга.
Завершая работу над двухчастотным энкодером инициализируем модули адаптивного сглаживания узлов, которые применяются отдельно для высоко- и низкочастотных компонент. Оба модуля получают одинаковые параметры, за исключением длины последовательности. Так как для высокочастотной компоненты ожидается уменьшение размера последовательности, обусловленное спецификой работы модуля расширенной причинно-следственной свертки.
if(!cLowFreqGraphAttention.Init(0, index, OpenCL, filters, 3, wave_units_out * window, optimization, iBatch)) return false; index++; if(!cHighFreqGraphAttention.Init(0, index, OpenCL, filters, 3, cDilatedCasualConvolution.Neurons()/filters, optimization, iBatch)) return false; index++;
На следующем этапе мы переходим к инициализации объектов декодера слияния потоков данных. Здесь мы инициализируем два блока внимания: Self-Attention для низкочастотной компоненты и Cross-Attention для добавления высокочастотной составляющей.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; index++; if(!cLowHighFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, filters, cDilatedCasualConvolution.Neurons()/filters, heads, layers, optimization, iBatch)) return false; index++;
Как было сказано выше, результаты работы блоков внимания суммируются. И для записи результатов операции мы создадим объект базового нейронного слоя.
if(!cLowHigh.Init(0, index, OpenCL, cLowFreqFusionDecoder.Neurons(), optimization, iBatch)) return false; CBufferFloat *grad = cLowFreqFusionDecoder.getGradient(); if(!grad || !cLowHigh.SetGradient(grad, true) || !cLowHighFreqFusionDecoder.SetGradient(grad, true)) return false; index++;
С целью исключения излишних операций копирования данных мы синхронизируем указатели на буфер градиентов ошибки 3 последних объектов. Такой подход снижает нагрузку на память и повышает общую эффективность процесса обучения.
Далее нам остается инициализировать объекты MLP генерации латентного представления анализируемого состояния окружающей среды. Здесь мы будем использовать сверточный слой для понижения размерности и полносвязный для генерации представления заданного размера.
Важно отметить, что при создании интеграционного объекта мы использовали базовый полносвязный слой в качестве родительского объекта. Это позволяет нам инициализировать лишь внутренний объект сверточного слоя, указав необходимое количество исходящих связей. А для реализации функционала полносвязного слоя воспользуемся унаследованными средствами родительского класса.
if(!cProjection.Init(Neurons(), index, OpenCL, filters, filters, 3, wave_units_out, window, optimization, iBatch)) return false; //--- return true; }
После успешной инициализации всех внутренних объектов мы завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Завершив работу над методом инициализации объекта мы переходим к построению алгоритма прямого прохода интеграционного объекта в методе feedForward.
bool CNeuronMultitaskStockformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Decoupling Flow if(!cDecouplingFlow.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект исходных данных, который сразу передаем в одноименный метод модуля декомпозиции анализируемого временного ряда.
Получаемый на выходе модуля декомпозиции сводный тензор высоко- и низкочастотных компонент мы разделяем между двумя объектами для последующего анализа в независимых магистралях.
if(!DeConcat(cLowFreqSignal.getOutput(), cHighFreqSignal.getOutput(), cDecouplingFlow.getOutput(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false;
Как и обсуждалось ранее, низкочастотная компонента передается в модуль темпорального внимания. После чего к ней добавляется позиционное кодирование и данные передаются в модуль адаптивного представления графов.
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cTemporalAttention.FeedForward(cLowFreqSignal.AsObject())) return false; if(!cLowFreqPE.FeedForward(cTemporalAttention.AsObject())) return false; if(!cLowFreqGraphAttention.FeedForward(cLowFreqPE.AsObject())) return false;
Высокочастотная компонента проходит по своей магистрали, начиная с модуля расширенной причинно-следственной свертки.
//--- High Frequency Encoder if(!cDilatedCasualConvolution.FeedForward(cHighFreqSignal.AsObject())) return false; if(!cHighFreqPE.FeedForward(cDilatedCasualConvolution.AsObject())) return false; if(!cHighFreqGraphAttention.FeedForward(cHighFreqPE.AsObject())) return false;
Результаты работы двух магистралей поступают на вход двухчастотного декодера слияния. Здесь сначала данные обрабатываются двумя модулями внимания. А их результаты суммируются и нормализуются.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject())) return false; if(!cLowHighFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject(), cHighFreqGraphAttention.getOutput())) return false; if(!SumAndNormilize(cLowFreqFusionDecoder.getOutput(), cLowHighFreqFusionDecoder.getOutput(), cLowHigh.getOutput(), cLowFreqFusionDecoder.GetWindow(), true, 0, 0, 0, 1)) return false;
Теперь нам остается сжать данные сверточным слоем проекции.
if(!cProjection.FeedForward(cLowHigh.AsObject())) return false; //--- return CNeuronBaseOCL::feedForward(cProjection.AsObject()); }
И передать результат в одноименный метод родительского класса для генерации итогового представления анализируемого состояния окружающей среды.
Следующим этапом нашей работы является организация процессов обратного прохода, которые играют ключевую роль в обучении модели. Традиционно, мы начинаем этот процесс с разработки алгоритма распределения градиента ошибки в методе calcInputGradients. Где организовываем поток информации в полном соответствии алгоритму прямого прохода, только в обратном направлении.
bool CNeuronMultitaskStockformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
В параметрах метода мы получаем указатель на объект исходных данных, в буфер которого нам предстоит передать градиент ошибки в соответствии с влиянием исходных данных на конечный результат работы модели. И в теле метода мы проверяем актуальность полученного указателя. Ведь в противном случае передача данных становится невозможной.
Сначала градиент ошибки передаётся на уровень сверточного слоя проекции с использованием функционала родительского класса. А затем направляется в слой суммирования данных, полученных от двух модулей внимания двухчастотного декодера слияния.
if(!CNeuronBaseOCL::calcInputGradients(cProjection.AsObject())) return false; if(!cLowHigh.calcHiddenGradients(cProjection.AsObject())) return false;
Здесь стоит вспомнить, что при инициализации интеграционного объекта была организована подмена указателей на буферы градиентов ошибки, используемые модулями внимания декодера и слоем суммирования их результатов. Это решение гарантирует, что весь передаваемый в слой суммирования градиент ошибки полностью передается соответствующим модулям внимания. Что позволяет нам перейти сразу к распределению градиентов через модули внимания декодера.
Однако следует обратить внимание, что данные низкочастотной компоненты одновременно используются в обоих блоках внимания. Это приводит к необходимости получения градиента ошибки от двух информационных потоков. Вначале мы выполняем операции распределения градиента ошибки через модуль Self-Attention.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqGraphAttention.calcHiddenGradients(cLowFreqFusionDecoder.AsObject())) return false;
А затем осуществляем временную подмену указателя на буфер градиентов ошибки модуля Self-Attention на свободный буфер аналогичного размера и осуществляем операции метода распределения градиента ошибки модуля Cross-Attention.
CBufferFloat *grad = cLowFreqGraphAttention.getGradient(); if(!cLowFreqGraphAttention.SetGradient(cLowFreqGraphAttention.getPrevOutput(), false) || !cLowFreqGraphAttention.calcHiddenGradients(cLowHighFreqFusionDecoder.AsObject(), cHighFreqGraphAttention.getOutput(), cHighFreqGraphAttention.getGradient(), (ENUM_ACTIVATION)cHighFreqGraphAttention.Activation()) || !SumAndNormilize(grad, cLowFreqGraphAttention.getGradient(), grad, 1, false, 0, 0, 0, 1) || !cLowFreqGraphAttention.SetGradient(grad, false)) return false;
Затем суммируем данные двух информационных потоков и возвращаем указатели на буферы данных в исходное состояние.
На данном этапе мы распределили градиент ошибки до высоко- и низкочастотных компонент на уровне результатов работы двухчастотного пространственно-временного энкодера. И далее мы последовательно распределяем градиент по объектам двух независимых магистралей. Сначала низкочастотной.
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cLowFreqPE.calcHiddenGradients(cLowFreqGraphAttention.AsObject())) return false; if(!cTemporalAttention.calcHiddenGradients(cLowFreqPE.AsObject())) return false; if(!cLowFreqSignal.calcHiddenGradients(cTemporalAttention.AsObject())) return false;
А затем высокочастотной.
//--- High Frequency Encoder if(!cHighFreqPE.calcHiddenGradients(cHighFreqGraphAttention.AsObject())) return false; if(!cDilatedCasualConvolution.calcHiddenGradients(cHighFreqPE.AsObject())) return false; if(!cHighFreqSignal.calcHiddenGradients(cDilatedCasualConvolution.AsObject())) return false;
Полученные от двух магистралей градиенты ошибки мы конкатенируем в единый тензор буфера градиентов модуля декомпозиции анализируемых данных.
//--- Decoupling Flow if(!Concat(cLowFreqSignal.getGradient(), cHighFreqSignal.getGradient(), cDecouplingFlow.getGradient(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false; if(!prevLayer.calcHiddenGradients(cDecouplingFlow.AsObject())) return false; //--- return true; }
И спускаем до уровня исходных данных, вызвав одноименный метод модуля декомпозиции данных. После чего завершаем работу метода, передав логический результат выполнения операций вызывающей программе.
Операции метода оптимизации параметров модели updateInputWeights мы выполняем в том же порядке, но только для объектов, содержащих обучаемые параметры. Поэтому я предлагаю оставить указанный метод для самостоятельного изучения. А полный код интеграционного объекта и всех его методов Вы можете найти во вложении.
На этом мы завершаем рассмотрения алгоритмов реализации фреймворка Multitask-Stockformer и переходим к следующему этапу нашей работы — внедрение реализованных подходов в архитектуру обучаемых моделей.
Архитектура моделей
Реализованные выше подходы фреймворка Multitask-Stockformer мы имплементируем в модель энкодера состояния окружающей среды. Надо сказать, что благодаря использованию комплексного объекта реализации фреймворка Multitask-Stockformer архитектура модели получилось довольно краткой и содержит только 3 слоя. Вначале мы традиционно используем слой исходных данных и пакетной нормализации.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В них осуществляется предварительная обработка "сырых" исходных данных, получаемых от окружающей среды. А за ними следует новый слой реализации подходов фреймворка Multitask-Stockformer.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultitaskStockformer; //--- Windows { int temp[] = {BarDescr, 10, LatentCount}; //Window, Filters, Output if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers = 3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
В рамках нашего эксперимента было использовано 10 вейвлет-фильтров. А каждый модуль внимания использует 4 головы и содержит 3 внутренних слоя.
Результаты работы энкодера состояния окружающей среды используются моделями Актера для принятия торгового решения и Критика, который дает оценку операциям, сгенерированным Актером. Архитектура указанных моделей была заимствована из предыдущих работ. Там же мы заимствовали программы взаимодействия с окружающей средой и обучения моделей. С полным описанием архитектуры моделей и кодом программ, используемых при написании статьи, Вы можете ознакомиться во вложении. А мы переходим к заключительному этапу — проверке эффективности реализованных решений на реальных исторических данных.
Тестирование
На протяжении двух статей мы выполнили большую работу по реализации подходов, предложенных авторами фреймворка Multitask-Stockformer, средствами MQL5. И пришло время самого волнительного этапа — проверке эффективности реализованных подходов на реальных исторических данных.
Следует уточнить, что мы оцениваем именно *реализованные* подходы, а не фреймворк Multitask-Stockformer в авторском представлении. Так как в процессе реализации были внесены изменения в оригинальный алгоритм фреймворка.
В ходе тестирования модели обучались на исторических данных за весь 2023 год финансового инструмента EURUSD, таймфрейм H1. Все параметры анализируемых индикаторов использовались на уровне настроек по умолчанию.
Для первого этапа обучения мы использовали обучающую выборку, собранную в рамках предыдущих исследований. В дальнейшем обучающая выборка периодически обновлялась с целью адаптации к текущей политике Актера. После нескольких циклов обучения и обновления выборки, была получена политика, демонстрирующая прибыльность как на обучающей, так и на тестовой выборках.
Тестирование обученной политики проводилось на исторических данных за январь 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
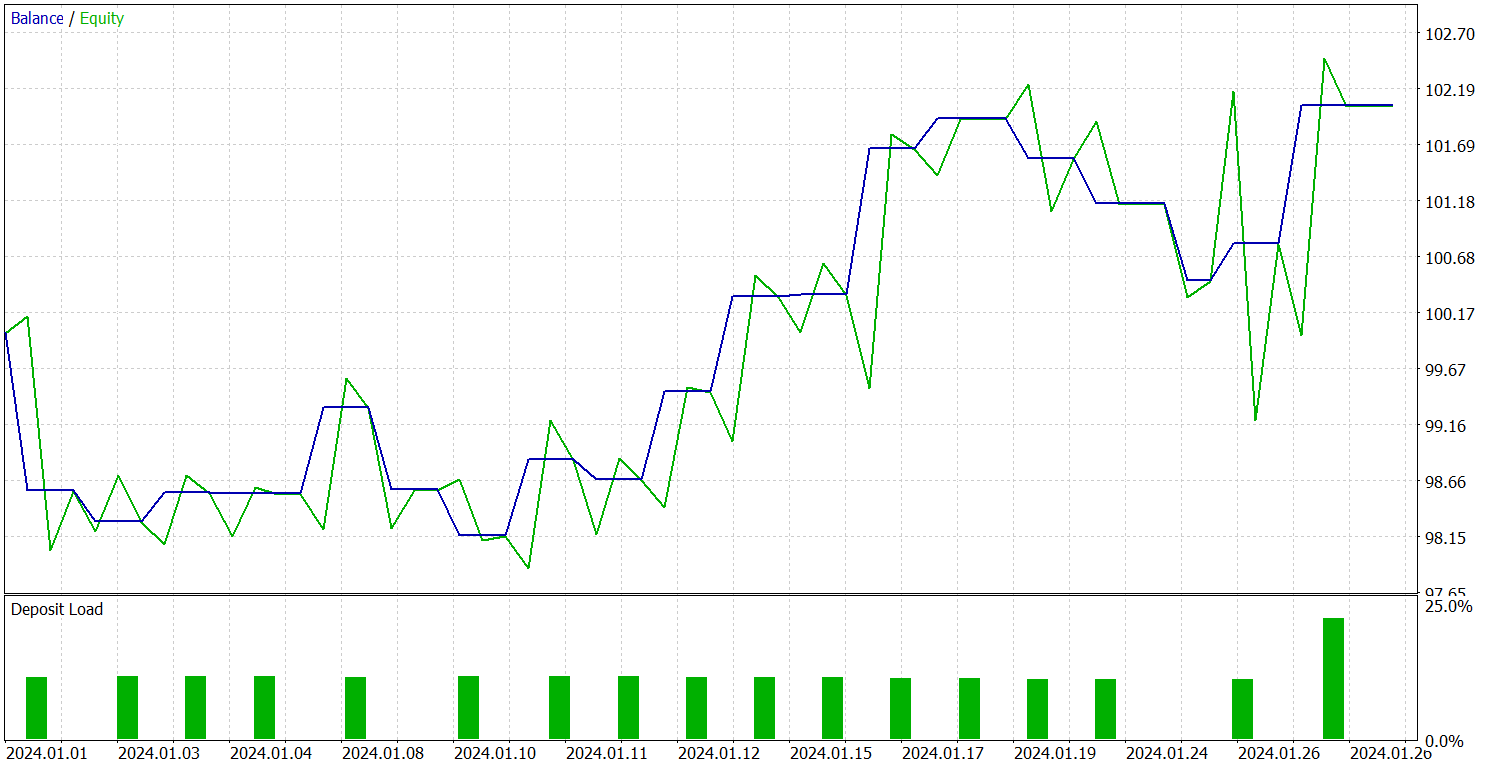
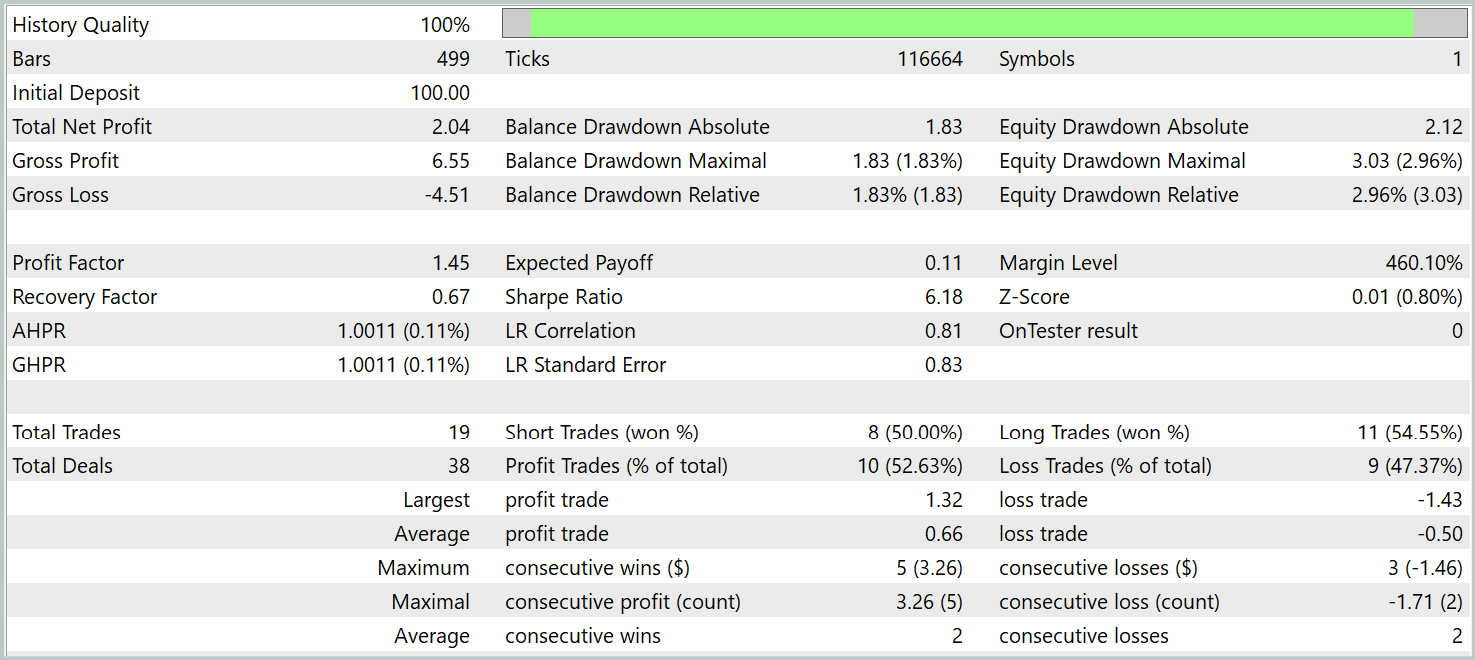
За период тестирования модель совершила 19 торговых операций, 10 из которых были закрыты с прибылью. Что составило чуть более 50%. Однако благодаря превышению средней прибыльной сделки над аналогичным показателем убыточных позиций модель закрыла тестовый период с прибылью, зафиксировав показатель профит-фактор на уровне 1.45.
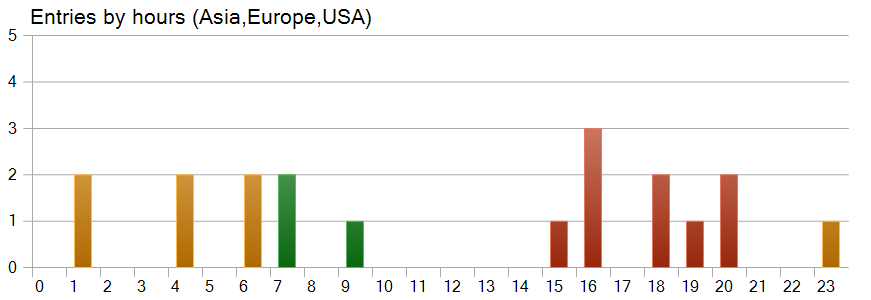
Довольно интересен график времени открытия позиций. Здесь мы видим, что почти половина позиций была открыта в Американскую торговую сессию. И практически не совершались торговые операции в период наибольшей волатильности инструмента.
Заключение
Мы познакомились с фреймворком Multitask-Stockformer, который представляет собой инновационную модель выбора акций, объединяющую дискретное вейвлет-преобразование с мультизадачными модулями Self-Attention. Такой комплексный подход позволяет выявлять временные и частотные особенности рыночных данных, обеспечивая при этом точное моделирование сложных взаимодействий между анализируемыми факторами.
В практической части мы реализовали собственное видение подходов фреймворка средствами MQL5. Внедрили реализованные подходы в модели и провели их обучение на реальных исторических данных. Обученные модели были протестированы в тестере стратегий MetaTrader 5. Результаты наших экспериментов свидетельствуют о потенциале реализованных решений. Однако перед использованием представленных решений в реальной торговле необходимо обучение модели на более репрезентативной обучающей выборке с последующим всесторонним тестированием.
Ссылки
- Stockformer: A Price-Volume Factor Stock Selection Model Based on Wavelet Transform and Multi-Task Self-Attention Networks
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка интерактивного графического пользовательского интерфейса на MQL5 (Часть 1): Создание панели
Разработка интерактивного графического пользовательского интерфейса на MQL5 (Часть 1): Создание панели
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования