
取引におけるニューラルネットワーク:マルチエージェント自己適応モデル(MASA)

はじめに
コンピュータ技術は金融分析の不可欠な一部となり、複雑な問題を解決するための革新的なアプローチを提供しています。近年、強化学習(RL: Reinforcement Learning)は、変動の激しい金融市場における動的ポートフォリオ管理において高い有効性を示しています。しかし、既存の手法はしばしばリターンの最大化に偏重しており、パンデミックや自然災害、地域紛争などによる不確実性下でのリスク管理に十分配慮していません。
この制約に対応するため、「Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management」という研究では、MASA (Multi-Agent and Self-Adaptive)フレームワークを提案しています。MASAは、相互に作用する2つのエージェントを統合しています。第一のエージェントはTD3アルゴリズムを用いてリターンを最適化し、第二のエージェントは進化的アルゴリズムやその他の最適化手法を用いてリスクを最小化します。さらに、MASAには市場オブザーバー(Market Observer)が組み込まれており、深層ニューラルネットワークを活用して市場トレンドを分析し、フィードバックを提供します。
著者らは、過去10年間のCSI 300、ダウジョーンズ工業株平均(DJIA)、S&P 500指数のデータを用いてMASAをテストしました。その結果、MASAは従来のRLベースのポートフォリオ管理手法よりも優れた成果を示しました。
1. MASAアルゴリズム
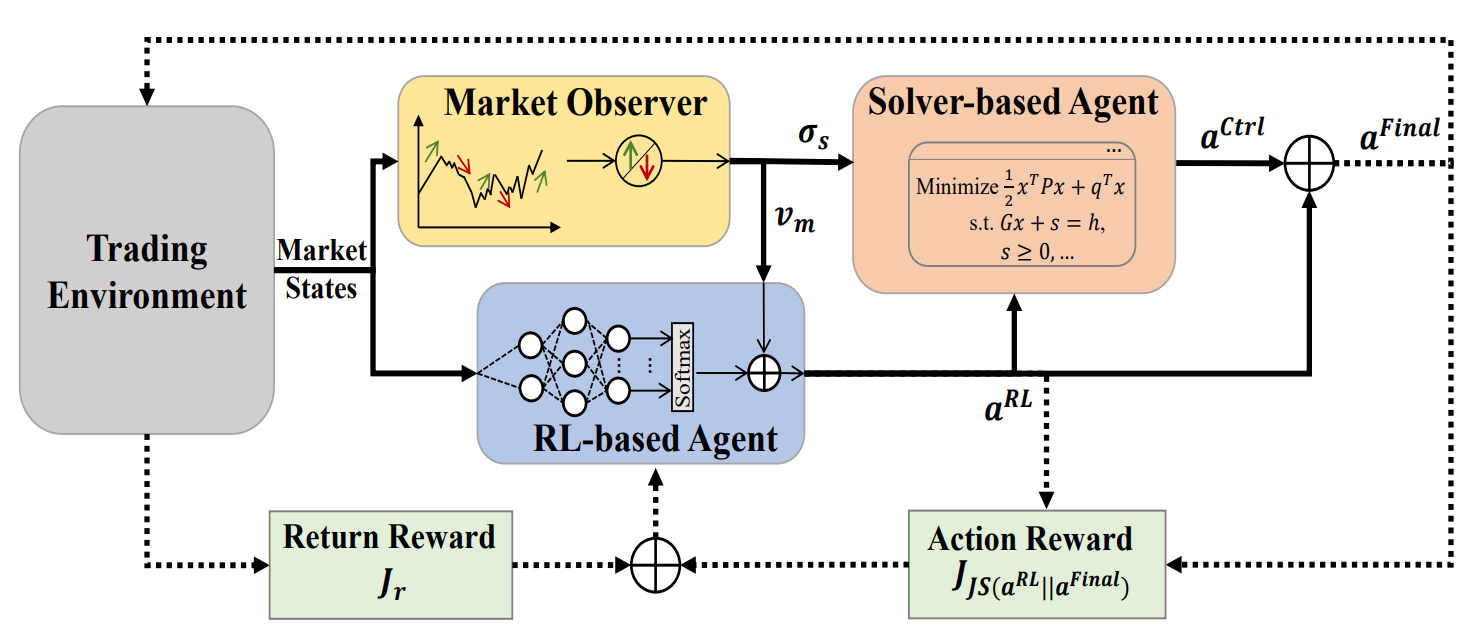
従来の強化学習(RL)アプローチには、リターンの最適化に偏重しがちであるという制約があります。これを克服するために、著者らはマルチエージェント自己適応アーキテクチャ(MASA)を提案しています。本構造では、2つの相互作用するエージェント(ひとつはRLベース、もうひとつは代替最適化アルゴリズムベース)を用いることで、従来とは異なるマルチエージェントRLスキームを構築しています。その目的は、特に変動の大きい市場環境下において、ポートフォリオのリターンと潜在的リスクのトレードオフを動的にバランスさせることです。
このアーキテクチャにおいて、RLエージェントはTD3アルゴリズムを基盤としてポートフォリオ全体のリターンを最適化します。一方、代替最適化エージェントは、RLエージェントによって生成されたポートフォリオを市場オブザーバーが提供する市場トレンドの評価に基づいてリスクを最小化するように適応させます。
この明確な機能分離により、モデルは金融市場の基礎的なダイナミクスに継続的に学習し、適応することができます。その結果、MASAは単独のRLベース手法と比べて、収益性とリスクの両面でよりバランスの取れたポートフォリオを生成します。
さらに、MASAフレームワークは三つの知能エージェント間で緩やかに結合されたパイプライン型の計算モデルを採用しています。そのため、マルチエージェントRLに基づくアプローチとして、エージェントの一部が機能しなくなった場合でもシステム全体が有効に稼働し続ける堅牢性と耐障害性を確保しています。これは重要な点です。
反復学習プロセスの開始前に、RL方策や市場オブザーバーエージェントが保持する市場状態データを含むすべての関連情報が初期化されます。
トレーニング中には、現在の市場状態Ot(直近数営業日における市場の上昇・下落傾向など)が市場オブザーバーによって分析されます。同時に、以前に実行された行動At−1,Finalの報酬は、RLアルゴリズムへのフィードバックとして使用され、RLエージェントの行動方策の改善に役立てられます。
その後、市場オブザーバーがリスク境界σs,tと市場ベクトルVm,tを算出します。これらは、RLエージェントおよびコントローラーが現在の市場条件に応じて更新をおこなう際の追加特徴量として利用されます。
柔軟性と適応性を確保するために、MASAフレームワークは、アルゴリズムモデルや深層ニューラルネットワークなど、さまざまなアプローチを組み込むことが可能です。さらに重要なことに、RLベースエージェントおよび代替最適化エージェントは、常に最新の市場情報にアクセスできることで保護されており、取引環境から最も価値のあるフィードバックを受け取ることができます。市場オブザーバーによって生成される知見は補助情報として使用され、RLエージェントおよびコントローラーの適応速度とパフォーマンスの向上を促します。特に、市場変動が激しい場合に効果的です。
最悪のケースとして、市場オブザーバーが「ノイズ」によって誤った信号を生成し、他のエージェントの意思決定に影響を与える場合でも、RL報酬メカニズムの適応性により、後続のトレーニング反復で基盤となる取引環境に再調整されます。また、市場オブザーバー自体も時間とともに自己修正機能を持つため、誤信号の影響を緩和して、長期的な取引安定性を確保します。
実験結果では、RLベースのエージェントと代替最適化エージェントの両方が、比較的単純なアルゴリズム手法で実装された市場オブザーバーを用いた場合でも、パフォーマンスの大幅な向上を示しました。この結果は、CSI 300、DJIA、S&P 500の10年間の複雑なデータセットでテストした際のMASAの堅牢性を強調しています。
ただし、MASAフレームワークを適用する際には、市場オブザーバーの入力が他の2つのエージェントに与える長期的影響を完全に理解するため、より複雑なデータセットや異なる応用領域におけるさらなる分析が必要です。
市場オブザーバーが起動すると、RLエージェントはポートフォリオウェイト形式で現在の行動At,RLを生成します。これに対して、コントローラーは代替最適化アルゴリズムを適用し、自身のリスク管理戦略およびオブザーバーが識別した市場状況を考慮して重みを修正します。緩やかに結合されたパイプライン型モデルにより、MASAはエージェントの一部が失敗しても運用整合性を維持する堅牢なマルチエージェントシステム(MAS)として機能します。
報酬ベースのメカニズムに導かれ、MASAは継続的に進化する環境にシームレスに適応します。意思決定エージェントは、市場オブザーバーからの有益なフィードバックに基づき、リターンとリスクの両方の目的に対してポートフォリオパフォーマンスを反復的に改善します。同時に、報酬メカニズムは生成される行動集合の多様性を促進するエントロピーに基づく発散指標を組み込み、異なる金融市場の変動に対応するための知的で適応的な戦略を実現します。
MASAフレームワークのオリジナルの可視化を以下に示します。
2. MQL5での実装
MASA手法の理論的な側面を確認した後は、実践部分に移ります。本記事では、提案されたアプローチをMQL5を用いて実装した例を示します。
前述の通り、MASAフレームワークは3つのエージェントで構成されています。可読性とコードの明瞭さを高めるため、それぞれのエージェントを個別のオブジェクトとして作成し、後で統合構造にまとめます。
2.1 市場オブザーバーエージェント
まず、市場オブザーバーエージェントを開発します。MASAの著者らは、市場分析には単純な解析手法から高度な深層学習モデルまで、さまざまなアルゴリズムを適用できることを強調しています。市場オブザーバーの主な役割は、主要な市場トレンドを特定し、最も可能性の高い今後の動きを予測することです。
本実装では、ハイブリッドアプローチを採用しています。まず、現在の市場傾向を把握するために区分線形表現アルゴリズムを適用します。次に、個別の一変量系列のトレンド間の依存関係を、相対位置符号化を用いたアテンションモジュールで分析します。最後に、出力段階でMLPを用いて、定義された予測期間における最も可能性の高い市場の挙動を予測します。
この複合アルゴリズムは、新しいオブジェクトCNeuronMarketObserverにカプセル化されます。その構造を以下に示します。
class CNeuronMarketObserver : public CNeuronRMAT { public: CNeuronMarketObserver(void) {}; ~CNeuronMarketObserver(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMarketObserver; } };
アルゴリズムは線形構造に従います。このような構造には、小規模線形モデルをサポートするCNeuronRMATクラスを親クラスとして利用するのが適しています。これにより、市場オブザーバーの構造は主にInit初期化メソッド内で定義され、基本的な機能は親クラスが提供します。
Initメソッドのパラメータは、市場オブザーバーエージェントのアーキテクチャを定義する定数を指定します。これらは以下の通りです。
- window:個別系列要素を表すベクトルのサイズ(一変量時系列の数)
- window_key:内部アテンションコンポーネント(Query、Key、Value)の次元数
- units_count:分析に使用するデータの履歴深さ
- heads:アテンションヘッドの数
- layers:アテンション層の数
- forecast:今後の予測期間
bool CNeuronMarketObserver::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
メソッド内では、まず親クラスの全結合層初期化メソッドを呼び出します。これはライブラリ内のすべてのニューラル層のルート親クラスです。この親クラスメソッドにより、オブジェクトの基本インターフェースが初期化されます。
重要なポイントは2つあります。まず、直接の親クラスではなく基底クラスの初期化メソッドを呼び出している点です。市場オブザーバーのアーキテクチャは親クラスとは大きく異なるためです。
次に、初期化時にオブジェクトサイズを、予測期間と系列要素ベクトルサイズの積で指定しています。これにより、市場オブザーバーの出力として期待されるテンソルに一致します。
次に、内部オブジェクトへのポインタ配列をクリアします。
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
この段階で準備作業は完了し、市場オブザーバーエージェントの実際の構築に進みます。
モデルは、個別のシステム状態を表すベクトル列として表現されたマルチモーダル時系列を入力として期待します。各一変量系列を適切に扱うため、まず入力データを転置する必要があります。
//--- Tranpose input data int lay_count = 0; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_count, window, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
次に、区分線形表現に変換します。
//--- Piecewise linear representation lay_count++; CNeuronPLROCL *plr = new CNeuronPLROCL(); if(!plr || !plr.Init(0, lay_count, OpenCL, units_count, window, false, optimization, iBatch) || !cLayers.Add(plr)) { delete plr; return false; }
一変量系列間の依存関係を分析するため、相対位置符号化付きアテンションモジュールを使用し、必要な内部層数をパラメータとして設定します。
//--- Self-Attention for Variables lay_count++; CNeuronRMAT *att = new CNeuronRMAT(); if(!att || !att.Init(0, lay_count, OpenCL, units_count, window_key, window, heads, layers, optimization, iBatch) || !cLayers.Add(att)) { delete att; return false; }
アテンションブロックの出力に基づき、各一変量系列の将来値を予測します。ここでは、MLPの代替として残差畳み込みブロック(CResidualConv)を使用しています。
//--- Forecast mapping lay_count++; CResidualConv *conv = new CResidualConv(); if(!conv || !conv.Init(0, lay_count, OpenCL, units_count, forecast, window, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; }
最後に、予測結果を元の入力データの次元に戻します。
//--- Back transpose forecast lay_count++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, window, forecast, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
データコピー操作を最小限にするため、外部インターフェースバッファを用いたポインタ置換手法を適用し、効率的なメモリ管理をおこないます。
if(!SetOutput(transp.getOutput(), true) || !SetGradient(transp.getGradient(), true)) return false; //--- return true; }
メソッドは処理の成功/失敗を呼び出し元に返すことで終了します。
このクラスのコア機能は親オブジェクトから継承されているため、市場オブザーバーエージェントはこれで完成です。このクラスの完全なソースコードは添付資料に記載されています。
2.2 RLエージェント
次にRLエージェントを構築します。MASAフレームワークでは、このエージェントは市場オブザーバーと並行して動作し、独立した市場分析をおこない、学習済み方策に基づいて意思決定をおこないます。
MASAの著者らは、RLエージェントをTD3ベースのモデルで実装することを提案しています。しかし、本実装では異なるRLエージェントアーキテクチャを採用しています。環境の独立分析にはPSformerフレームワークを使用し、分析結果に基づく意思決定は、SAM最適化を強化した軽量パーセプトロンでおこないます。
RLエージェントは、新しいオブジェクトCNeuronRLAgentとして実装されています。その構造は以下のとおりです。
class CNeuronRLAgent : public CNeuronRMAT { public: CNeuronRLAgent(void) {}; ~CNeuronRLAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronRLAgent; } };
市場オブザーバーと同様に、線形モデル基底クラスCNeuronRMATを継承しています。そのため、新モジュールのアーキテクチャはInitメソッド内で指定するだけで実装可能です。
bool CNeuronRLAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, n_actions, optimization_type, batch)) return false;
メソッドのパラメータは市場オブザーバーのものと類似していますが、いくつかの違いがあります。たとえば、予測期間パラメータはエージェントの行動空間(n_actions)に置き換えられています。また、追加のパラメータとしてsegments(セグメント数)やrho(ブラー係数)が含まれます。
メソッド内では、まず基底クラスの全結合層初期化メソッドを呼び出し、RLエージェントの行動空間を出力テンソルサイズとして指定します。
その後、内部オブジェクトポインタの動的配列をクリアします。
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
入力データはまずPSformerに渡され、必要な層数がループ内で生成されます。
//--- State observation int lay_count = 0; for(uint i = 0; i < layers; i++) { CNeuronPSformer *psf = new CNeuronPSformer(); if(!psf || !psf.Init(0, lay_count, OpenCL, window, units_count, segments, rho, optimization,iBatch)|| !cLayers.Add(psf)) { delete psf; return false; } lay_count++; }
次に、RLエージェントは、その分析出力を畳み込み層および全結合層で構成された意思決定ブロックに入力することで、最適行動を決定します。畳み込み層は次元削減をおこないます。
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(n_actions, lay_count, OpenCL, window, window, 1, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(GELU); lay_count++;
全結合層は行動テンソルを生成します。
CNeuronBaseSAMOCL *flat = new CNeuronBaseSAMOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, n_actions, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; } SetActivationFunction(SIGMOID);
本実装では、Actorの確率的方策は使用していません。ただし、将来的には必要に応じて使用する可能性があります。その場合の扱いについては後述します。
デフォルトでは、行動ベクトルにはシグモイド活性化関数を用い、出力値を0~1の範囲に制約しています。必要に応じて、外部プログラム側でこれを上書きすることも可能です。
その後、外部インターフェースのデータバッファに対するポインタ置換をおこない、初期化の成否をBooleanで返すことでInitメソッドは終了します。
if(!SetOutput(flat.getOutput(), true) || !SetGradient(flat.getGradient(), true)) return false; //--- return true; }
これで、RLエージェントオブジェクトが完成します。このクラスおよびそのすべてのメソッドの完全なコードは、添付ファイルにて確認できます。
2.3 コントローラー
3つのエージェントのうち、2つはすでに構築しました。次に3つ目のコンポーネントであるコントローラーエージェントに移ります。このエージェントの役割は、リスクを評価し、市場オブザーバーによる環境状態分析に基づき、RLエージェントの行動を調整することです。
コントローラーの重要な特徴は、2つの入力データソースを処理する点です。それぞれの入力を個別に評価するだけでなく、それらの相互依存関係も考慮する必要があります。このタスクには、Transformerデコーダー構造が非常に適しています。しかし、標準のSelf-AttentionやCross-Attentionモジュールの代わりに、相対位置符号化バリアントを使用しています。
コントローラーは、新しいオブジェクトCNeuronControlAgentとして実装され、再びCNeuronRMATを継承しています。二重入力ストリームを扱うため、いくつかのメソッドは再定義が必要です。新しいクラスの構造体は以下のとおりです。
class CNeuronControlAgent : public CNeuronRMAT { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronControlAgent(void) {}; ~CNeuronControlAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronControlAgent; } };
内部オブジェクトの初期化はInitメソッド内でおこなわれ、Transformerデコーダーのアーキテクチャを指定します。
bool CNeuronControlAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- Clear layers' array cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
Initメソッドでは、まず基底クラスの全結合層初期化メソッドを呼び出し、主入力テンソルの次元に対応する出力サイズを指定します。その後、内部オブジェクトポインタの動的配列をクリアします。
次に、コントローラーエージェントのアーキテクチャ構築に進みます。市場オブザーバーはマルチモーダル時系列、すなわち環境状態(バー)の予測ベクトル列を出力します。
RLエージェントの行動を個々のバーに合わせる方法と、一変量系列に合わせる方法の2つが考えられます。私たちは、市場オブザーバーが提供するのはあくまで予測データに過ぎず、その実現確率は決して100%ではないことを理解しています。また、すべての値に偏差が生じる可能性もあります。
論理的に考えてみましょう。仮に1つの予測ローソク足を表すベクトルが各要素ごとに異なる偏差を持つ場合、そのベクトルからどの程度の有用な情報を得られるでしょうか。この問いに答えるのは、各予測の精度を理解しない限り非常に難しい問題です。
一方で、個別の一変量系列に注目すると、個々の値だけでなく、今後の動きのトレンドを把握することが可能です。トレンドは複数の値の集合で形成されるため、いくつかの値が偏差を持っていても、全体としてトレンドの確認が期待できます。
さらに、マルチモーダル時系列内の全ての一変量系列には、ある程度の相互依存関係があります。そのため、ある一変量系列の予測トレンドが他の系列の値で裏付けられれば、その予測の信頼性は高まります。
この考えを踏まえ、コントローラーエージェントでは、RLエージェントの行動が一変量系列の予測値に依存する関係を分析することにしました。そのため、まず二次データソースを専用のニューラル層に入力します。
int lay_count = 0; CNeuronBaseOCL *flat = new CNeuronBaseOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, window_kv * units_kv, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; }
続いて、それを一変量系列表現に再整形します。
lay_count++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; } lay_count++;
次にデコーダーのアーキテクチャを構築します。必要な層数はループ内で生成されます。ループの反復回数は、Initメソッドの外部パラメータによって決まります。
//--- Attention Action To Observation for(uint i = 0; i < layers; i++) { if(units_count > 1) { CNeuronRelativeSelfAttention *self = new CNeuronRelativeSelfAttention(); if(!self || !self.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, optimization, iBatch) || !cLayers.Add(self)) { delete self; return false; } lay_count++; }
標準的なTransformerデコーダーでは、入力データはまずSelf-Attentionモジュールで処理され、系列内の依存関係を分析します。しかし、本実装では相対位置符号化付きのSelf-Attentionモジュールを使用します。ただし、入力系列が1要素しかない場合は、依存関係が存在しないため、このモジュールは生成されません。この場合、Self-Attentionモジュールは冗長になります。
続いて、2つのデータソース間の依存関係を解析するCross-Attentionモジュールを作成します。
CNeuronRelativeCrossAttention *cross = new CNeuronRelativeCrossAttention(); if(!cross || !cross.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(cross)) { delete cross; return false; } lay_count++;
各デコーダー層は、残差畳み込みブロックを用いたFeedForwardブロックで完了します。
CResidualConv *ffn = new CResidualConv(); if(!ffn || !ffn.Init(0, lay_count, OpenCL, window, window, units_count, optimization, iBatch) || !cLayers.Add(ffn)) { delete ffn; return false; } lay_count++; }
この後、次のループ反復に進み、次のデコーダー層を構築します。
標準のTransformerデコーダーアーキテクチャと同様に、残差畳み込みブロックの出力は正規化されます。また、Actorの行動空間を定義された範囲に制約する必要がある場合は、活性化関数によって制御します。そのため、必要な数のデコーダー層を構築した後、指定の活性化関数を持つ追加の畳み込み層を追加します。
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, lay_count, OpenCL, window, window, window, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } SetActivationFunction(SIGMOID);
デフォルトでは、RLエージェントと同様に、シグモイド関数を使用します。ただし、外部プログラムから上書きするオプションは残しておきます。
最後に、初期化メソッドの末尾で、インターフェースバッファへのポインタを置換し、処理が成功したかどうかを示すBoolean値を呼び出し元のプログラムに返します。
//--- if(!SetOutput(conv.getOutput(), true) || !SetGradient(conv.getGradient(), true)) return false; //--- return true; }
新しいオブジェクトの初期化が完了したら、feedForwardメソッドでフィードフォワードアルゴリズムの構築に進みます。
bool CNeuronControlAgent::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
メソッドのパラメータとして、2つの入力データオブジェクトへのポインタを受け取りますが、一次データストリームはニューラル層として渡され、二次データストリームはデータバッファとして提供されます。利便性のため、特別に作成した内部層の出力バッファを、メソッドの引数として受け取ったオブジェクトで置き換えます。
CNeuronBaseOCL *second = cLayers[0]; if(!second) return false; if(!second.SetOutput(SecondInput, true)) return false;
次に、二次データソースのテンソルを転置し、マルチモーダル時系列を一変量系列のシーケンスとして表現します。
second = cLayers[1]; if(!second || !second.FeedForward(cLayers[0])) return false;
その後、残りの内部ニューラル層を順番に反復処理し、それぞれのフィードフォワードメソッドを呼び出して、一次および二次の両方のデータソースを渡します。
CNeuronBaseOCL *first = NeuronOCL; CNeuronBaseOCL *main = NULL; for(int i = 2; i < cLayers.Total(); i++) { main = cLayers[i]; if(!main || !main.FeedForward(first, second.getOutput())) return false; first = main; } //--- return true; }
すべてのループ反復が正常に完了した後、単純にBoolean値を呼び出し元に返し、処理が正常に実行されたことを通知します。
ご覧の通り、フィードフォワードアルゴリズムは比較的単純です。これは、複雑なアーキテクチャを構築する際に既存のブロックを組み合わせて使用しているためです。
しかし、誤差勾配分配アルゴリズムの実装は、二次データソースを使用するためにより複雑になります。一次データ経路では、情報は内部層を順次通過します。一方で、二次データソースは全デコーダー層、特にすべてのCross-Attentionモジュールで共有されます。その結果、二次データの誤差勾配は全Cross-Attentionモジュールから集約する必要があります。この問題の解決方法は、コード中で確認することをお勧めします。
このロジックは、calcInputGradientsメソッド内で実装されています。メソッドの引数には、2つの入力データストリームとそれぞれの誤差勾配へのポインタが含まれます。私たちの課題は、最終出力に対する貢献度に応じて、2つのデータソース間で誤差勾配を分配することです。
bool CNeuronControlAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
メソッド内では、まず受け取ったポインタの検証をおこないます。存在しないオブジェクトにデータを渡すことはできないためです。
forwardパスと同様に、二次データソースはバッファとして表現されます。そして、対応する内部層のポインタをこのバッファに置き換えます。
CNeuronBaseOCL *main = cLayers[0]; if(!main) return false; if(!main.SetGradient(SecondGradient, true)) return false; main.SetActivationFunction(SecondActivation); //--- CNeuronBaseOCL *second = cLayers[1]; if(!second) return false; second.SetActivationFunction(SecondActivation);
この段階で、内部層と続く転置層の活性化関数を、入力データの活性化関数と同期させます。これにより、勾配の正しい伝播が保証されます。
転置層は、二次データソースとして機能します。利便性のため、そのインターフェースオブジェクトへのポインタをローカル変数に格納します。
CBufferFloat *second_out = second.getOutput(); CBufferFloat *second_gr = second.getGradient(); CBufferFloat *temp = second.getPrevOutput(); if(!second_gr.Fill(0)) return false;
さらに、転置層の勾配バッファに以前に蓄積された値をすべてクリアします。
その後、内部ニューラル層を逆順に反復処理します。このループ内では、デコーダーオブジェクトのみを扱うことに注意してください。
なお、最初の2つの内部オブジェクトは、二次データソースの処理用に予約されています。
for(int i = cLayers.Total() - 2; i >= 2; i--) { main = cLayers[i]; if(!main) return false;
各デコーダー層について、配列からそのポインタを取得し、検証します。
すべてのデコーダーモジュールが2つのデータソースで動作するわけではないため、アルゴリズムはオブジェクトの種類に応じて分岐します。Cross-Attentionモジュールの場合、まず現在の層から二次データソースの誤差勾配を一時的なストレージバッファに渡し、以前に蓄積された値と合算します。
if(cLayers[i + 1].Type() == defNeuronRelativeCrossAttention) { if(!main.calcHiddenGradients(cLayers[i + 1], second_out, temp, SecondActivation) || !SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
その他のモジュールの場合は、誤差勾配を一次経路に沿って単純に伝播させます。そして、ループの次の反復に進みます。
else { if(!main.calcHiddenGradients(cLayers[i + 1])) return false; } }
すべての反復処理が完了した後、蓄積された勾配を入力データソースに伝播させます。まず、一次経路に沿って勾配を最初のデータソースに渡します。
if(!NeuronOCL.calcHiddenGradients(main.AsObject(), second_out, temp, SecondActivation)) return false;
ただし、最初のデコーダー層はSelf-AttentionモジュールかCross-Attentionモジュールのいずれかである可能性があります。後者の場合は両方のデータソースが使用されるため、オブジェクトの種類を確認し、必要に応じて二次データソースの蓄積された勾配を加算します。
if(main.Type() == defNeuronRelativeCrossAttention) { if(!SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
最後に、蓄積された二次経路の勾配を対応する入力ソースに伝播させます。
main = cLayers[0]; if(!main.calcHiddenGradients(second.AsObject())) return false; //--- return true; }
メソッドはこれで終了し、呼び出し元のプログラムに論理結果(成功/失敗)を返します。
updateInputWeightsメソッドで実装されているパラメータ更新アルゴリズムは比較的単純です。学習可能な内部オブジェクトをループで処理し、それぞれの更新メソッドを呼び出します。ここでは詳細には触れません。しかし、重要なのは、このオブジェクト構造ではSAM最適化済みのパラメータを持つモジュールを使用しているため、内部オブジェクトのループは逆順で実行する必要がある点です。
これで、コントローラーエージェントの各メソッドの実装アルゴリズムについての説明を終了します。新しいクラスおよび全メソッドの完全なソースコードは添付資料に記載されています。
本日ここまでで大きな進展がありましたが、作業はまだ完了していません。ここで短い休憩を取り、次回の記事ではプロジェクトを論理的に完結させる予定です。
結論
本稿では、変動の激しい金融市場環境下におけるポートフォリオ管理の革新的手法である、Multi-Agent Self-Adaptive(MASA)フレームワークについて検討しました。本フレームワークは、リターン最適化のためのRLアルゴリズム、リスク最小化のための適応的最適化手法、そしてトレンド分析のための市場オブザーバーモジュールの利点を効果的に組み合わせています。
実践編では、提案された各エージェントをMQL5で独立したモジュールとして実装しました。次回の記事では、これらを統合して完全なシステムを構築し、実際の過去データを用いて実装したソリューションの性能を評価する予定です。
参照文献
- Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
- この連載の他の記事記事
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いた例収集用のEA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16537
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索