
Redes neuronales en el trading: Modelo adaptativo multiagente (MASA)

Introducción
La tecnología informática se está convirtiendo en parte integrante del análisis financiero, proporcionando nuevos enfoques para resolver problemas complejos. En los últimos años, el aprendizaje por refuerzo ha demostrado su eficacia en la gestión dinámica de portafolios de inversión en mercados financieros turbulentos. Sin embargo, los métodos existentes con frecuencia se centran en maximizar los beneficios sin prestar mucha atención a la gestión del riesgo, especialmente ante la incertidumbre provocada por pandemias, catástrofes naturales y conflictos regionales.
Para subsanar esta deficiencia, en el artículo "Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management" se propone el framework adaptativo multiagenteMASA (Multi-Agent and Self-Adaptive). Este se basa en una integración única de dos agentes que interactúan entre sí: el primero optimiza los rendimientos mediante el algoritmo TD3, mientras que el segundo minimiza los riesgos usando algoritmos evolutivos u otros métodos de optimización. Además, el MASA integra un observador de mercado que utiliza redes neuronales profundas para analizar las tendencias del mercado y transmitirlas en forma de retroalimentación.
Los autores del MASA probaron el modelo con los datos de los índices CSI 300, Dow Jones Industrial Average(DJIA) y S&P 500 de los últimos 10 años. Sus resultados demuestran la superioridad del MASA sobre los enfoques tradicionales de RL en la gestión de portafolios.
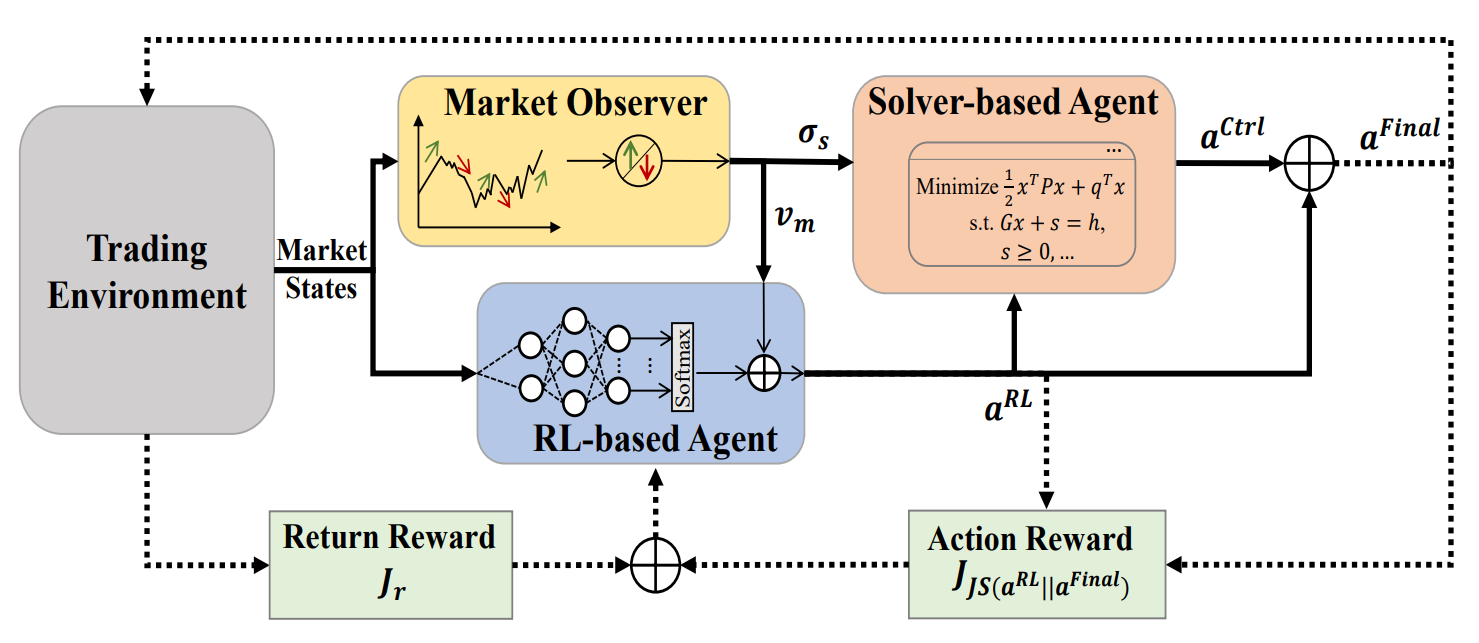
1. Algoritmo MASA
Para superar la trampa de los enfoques basados en RL, que se inclinan hacia la optimización de la rentabilidad de las inversiones, los autores del framework proponen una estructura adaptativa multiagente (MASA), en la que se utilizan dos agentes interactivos y reactivos (uno basado en RL y otro en un algoritmo de optimización alternativo) para aplicar un esquema de RL multiagente fundamentalmente nuevo con el fin de equilibrar de forma dinámica el compromiso entre la rentabilidad total de un portafolio recién revisado y los riesgos potenciales, especialmente en entornos financieros muy turbulentos.
En la arquitectura propuesta por los autores del framework, un agente RL basado en el algoritmo TD3 optimiza el rendimiento total del portafolio de inversión actual. Al mismo tiempo, el agente, basándose en un algoritmo de optimización alternativo, trabaja para adaptar aún más el portafolio de inversión devuelto por el agente de RL con el fin de minimizar sus riesgos potenciales tras considerar la evaluación de la tendencia del mercado ofrecida por el observador del mercado.
En esencia, gracias a la clara separación de la funcionalidad entre los agentes, el modelo aprende y se adapta constantemente al entorno básico del mercado financiero. El esquema MASA multiagente puede lograr portafolios de inversión más equilibrados, tanto por sus rendimientos como por sus riesgos potenciales, en comparación con los portafolios obtenidos mediante enfoques basados únicamente en RL.
Cabe señalar que la estructura MASA adopta un modelo computacional poco acoplado y canalizado entre tres agentes interactuantes e inteligentes. De este modo, el enfoque RL multiagente global resulta más robusto porque el marco global seguirá funcionando cuando falle cualquier agente individual.
Antes de iniciar el proceso iterativo de entrenamiento del modelo, se inicializa toda la información relevante, incluyendo la política de RL, la información sobre el estado del mercado guardada en el agente Market Observer, etc.
En el proceso de aprendizaje, la información sobre el estado actual del mercado Ot (por ejemplo, la tendencia bajista o alcista más reciente del mercado financiero básica en los últimos días de negociación) se recopilará como información básica para su posterior análisis por parte del agente de supervisión del mercado. Además, la recompensa por la acción At−1,Final realizada anteriormente se obtendrá como retroalimentación para el algoritmo RL, y la revisión de la política de comportamiento del agente RL.
A continuación, se llama al agente de supervisión del mercado para que calcule la frontera de riesgo propuesta σs,t y el vector de mercado Vm,t como atributos adicionales para actualizar el agente RL y el Controlador de acuerdo con las últimas condiciones del mercado.
Para mantener la flexibilidad y adaptabilidad de la estructura MASA propuesta, se pueden utilizar diversos enfoques, incluidas redes neuronales algorítmicas o profundas. Y lo que es más importante, cabe señalar que tanto los agentes basados en RL como los basados en algoritmos de optimización alternativos ya están protegidos por la información actual del mercado como la retroalimentación más valiosa del entorno comercial existente. La información proporcionada por el agente de supervisión del mercado sobre las condiciones previstas del mercado, se usa únicamente como información adicional para adaptar y mejorar rápidamente el rendimiento tanto del agente de RL como del agente de supervisión, especialmente cuando las condiciones recientes del mercado son muy volátiles.
En el peor de los casos, cuando las características sugeridas por el agente de supervisión del mercado puedan ser incorrectas debido al "ruido" y engañar a los demás agentes a la hora de determinar las acciones óptimas en determinados días de negociación, la naturaleza adaptativa del mecanismo de recompensa basado en RL permitirá la adaptación al entorno comercial básico durante las iteraciones de aprendizaje posteriores. Además, la capacidad de un agente inteligente de supervisión del mercado para autocorregirse durante el aprendizaje contribuirá a garantizar la condición de que ese ruido engañoso pueda corregirse eficaz y rápidamente durante periodos de negociación más largos.
Curiosamente, según los resultados de los experimentos realizados por los autores del framework, se observan mejoras bastante impresionantes en el rendimiento final de los agentes basados tanto en RL como en optimizadores alternativos, incluso cuando se utiliza un enfoque algorítmico relativamente sencillo para implementar el agente-supervisor del mercado en el marco MASA propuesto sobre conjuntos de datos complejos CSI 300, DJIA y S&P 500 durante los últimos 10 años.
Obviamente, se requiere un análisis exhaustivo en conjuntos de datos más complejos o en otros dominios de aplicación para comprender a fondo el impacto final de la información ofrecida por el agente de supervisión del mercado sobre los otros dos agentes inteligentes a los que se debe aplicar el marco MASA propuesto.
Una vez que se llama al agente de supervisión del mercado, el agente RL se activará para generar la acción At,RL actual como pesos del portafolio que pueden ser revisados posteriormente por el Controlador subsiguiente usando como base un algoritmo de optimización alternativo, tras considerar su propia estrategia de gestión de riesgos y las condiciones de mercado propuestas proporcionadas por el agente de supervisión del mercado. En general, al adoptar este modelo computacional poco acoplado y canalizado, el entorno MASA resultante seguirá funcionando como un sistema MAS robusto y resistente, incluso si falla algún agente individual.
Con la ayuda del mecanismo de guía basado en recompensas adoptado por el marco MASA, diseñado para responder cuidadosamente a un entorno en constante cambio, los agentes de decisión pueden aumentar iterativamente el portafolio de inversión actual tanto con respecto a los objetivos de rentabilidad total como a los riesgos potenciales, después de considerar la valiosa retroalimentación del agente de supervisión del mercado. Al mismo tiempo, el mecanismo de control basado en recompensas utiliza una medida de la divergencia basada en la entropía para promover la diversidad de los conjuntos de acciones generados como estrategia inteligente y adaptable, a fin de satisfacer las necesidades en el entorno altamente volátil de los distintos mercados financieros.
A continuación le mostramos la visualización del marco MASA por parte del autor.
2. Implementación con MQL5
Tras considerar los aspectos teóricos del marco MASA, pasaremos a la parte práctica de nuestro trabajo, en la que implementaremos nuestra propia visión de los enfoques propuestos utilizando herramientas MQL5.
Como ya hemos mencionado, el framework MASA incluye 3 agentes. Para una mayor claridad y legibilidad del código, crearemos un objeto para cada agente, que posteriormente combinaremos en una única estructura.
2.1 Agente de supervisión del mercado
Comenzaremos nuestro trabajo creando un agente de supervisión del mercado. Los autores del framework MASA afirman que es posible utilizar diversos algoritmos para analizar los mercados, desde los planteamientos analíticos más sencillos hasta complejos modelos en profundidad. La principal tarea de un agente de supervisión del mercado consiste en identificar las principales tendencias con el fin de prever el movimiento venidero más probable.
En nuestra aplicación, usaremos un enfoque mixto. En primer lugar, utilizaremos un algoritmo de representación lineal por partes de series temporales para identificar las tendencias actuales. A continuación, analizaremos las dependencias de las tendencias identificadas de secuencias unitarias individuales en el módulo de atención con codificación relativa. Y en la salida del agente, intentaremos predecir el comportamiento más probable del mercado para un horizonte de planificación dado utilizando un MLP.
Crearemos el complejo algoritmo del agente de supervisión del mercado anteriormente mencionado dentro de un nuevo objeto CNeuronMarketObserver. Resumiremos su estructura a continuación.
class CNeuronMarketObserver : public CNeuronRMAT { public: CNeuronMarketObserver(void) {}; ~CNeuronMarketObserver(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMarketObserver; } };
Resulta sencillo ver que el algoritmo que hemos descrito antes tiene una estructura lineal. Por lo tanto, hemos elegido CNeuronRMAT como clase padre de nuestro nuevo objeto, dentro del cual se organizará el proceso de un pequeño modelo lineal. Esto nos permitirá limitarnos a crear una nueva estructura para el agente de supervisión del mercado dentro del método de inicialización Init, mientras que la funcionalidad básica al completo se encontrará ya organizada en los métodos de la clase padre.
En los parámetros del método de inicialización del objeto Init, obtendremos las constantes básicas que definen la arquitectura de nuestro agente de supervisión del mercado. Entre ellas, tenemos:
- window — tamaño del vector de descripción de un elemento de la secuencia (número de series temporales unitarias);
- window_key — dimensionalidad de las entidades internas del bloque de atención (Query, Key, Value);
- units_count — profundidad de la historia analizada:
- heads — número de cabezas de atención;
- layers — número de capas en el bloque de atención;
- forecast — horizonte de previsión del próximo movimiento.
bool CNeuronMarketObserver::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
En el cuerpo del método, llamaremos directamente al método homónimo de la capa básica completamente conectada, que es la clase padre común para todas las capas neuronales de nuestra biblioteca. Dentro del método de la clase padre, organizaremos la inicialización de las interfaces básicas de nuestro objeto.
Le ruego que se fije en dos cosas. En primer lugar, utilizamos el método de inicialización de la clase básica en lugar de la clase padre directa. Al fin y al cabo, la arquitectura de nuestro agente se diferencia notablemente de la arquitectura del objeto padre.
En segundo lugar, cuando llamamos al método de la clase padre, especificamos el tamaño del objeto como el producto del horizonte de planificación por el tamaño del vector de descripción de un elemento de la secuencia. Esta es la clase de tensor que esperamos obtener como resultado de nuestro agente de supervisión del mercado.
A continuación, eliminaremos el array dinámico de punteros a objetos internos.
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
Aquí concluiremos el trabajo preparatorio y pasaremos a organizar directamente la estructura de nuestro agente de supervisión del mercado.
Como entrada al modelo, esperamos recibir una serie temporal multimodal en forma de secuencia de vectores que describan los estados individuales del sistema (en nuestro caso, barras). Por lo tanto, para organizar el trabajo como secuencias unitarias individuales, necesitaremos transponer los datos obtenidos.
//--- Tranpose input data int lay_count = 0; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_count, window, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
Y luego transformaremos las secuencias unitarias obtenidas en una representación lineal por partes.
//--- Piecewise linear representation lay_count++; CNeuronPLROCL *plr = new CNeuronPLROCL(); if(!plr || !plr.Init(0, lay_count, OpenCL, units_count, window, false, optimization, iBatch) || !cLayers.Add(plr)) { delete plr; return false; }
Para analizar las dependencias entre secuencias unitarias individuales, utilizaremos el módulo de atención ya disponible con codificación relativa, en cuyos parámetros especificaremos el número necesario de capas internas.
//--- Self-Attention for Variables lay_count++; CNeuronRMAT *att = new CNeuronRMAT(); if(!att || !att.Init(0, lay_count, OpenCL, units_count, window_key, window, heads, layers, optimization, iBatch) || !cLayers.Add(att)) { delete att; return false; }
A partir de los datos obtenidos de la salida del bloque de atención, trataremos de predecir los próximos valores de cada secuencia unitaria. Aquí, usaremos el bloque de convolución con enlace residual CResidualConv como un MLP para predecir independientemente los valores de cada serie temporal unitaria.
//--- Forecast mapping lay_count++; CResidualConv *conv = new CResidualConv(); if(!conv || !conv.Init(0, lay_count, OpenCL, units_count, forecast, window, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; }
Por último, bastará con realizar una transformación inversa de los datos, para representarlos en la dimensionalidad de los datos de origen.
//--- Back transpose forecast lay_count++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, window, forecast, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
Y para reducir las operaciones de copiado de datos, utilizaremos la tecnología bien probada de sustitución de los punteros a los búferes de interfaces externas de intercambio de información.
if(!SetOutput(transp.getOutput(), true) || !SetGradient(transp.getGradient(), true)) return false; //--- return true; }
A continuación, finalizaremos el método de inicialización devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
Como hemos mencionado anteriormente, la funcionalidad básica completa de esta clase se heredará del objeto padre. Por lo tanto, finalizaremos el agente de supervisión del mercado. Podrá ver el código completo de esta clase en el archivo adjunto.
2.2 El agente RL
A continuación pasaremos a la construcción del agente RL. En el framework MASA funciona en paralelo al agente de supervisión del mercado y realiza un análisis independiente de la situación del mercado con la posterior toma de decisiones según la política de comportamiento aprendida.
Los autores del marco MASA proponen usar como agente RL un modelo entrenado utilizando las aproximaciones del algoritmo TD3. Nos apartaremos ligeramente de la implementación propuesta y utilizaremos una arquitectura de agente RL diferente. Para ello, usaremos el framework PSformer para analizar de forma independiente el estado actual del entorno. Y un pequeño perceptrón con enfoques de optimización SAM se encargará de tomar las decisiones basándose en el análisis.
Luego implementaremos el algoritmo de nuestro agente RL en un nuevo objeto CNeuronRLAgent, cuya estructura se muestra a continuación:
class CNeuronRLAgent : public CNeuronRMAT { public: CNeuronRLAgent(void) {}; ~CNeuronRLAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronRLAgent; } };
Como puede ver, aquí explotamos el mismo enfoque heredando la funcionalidad del modelo lineal del objeto padre CNeuronRMAT. Por lo tanto, solo tendremos que indicar la nueva arquitectura del módulo en el método de inicialización Init.
bool CNeuronRLAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, n_actions, optimization_type, batch)) return false;
La estructura de parámetros del método resulta muy similar a la presentada en la construcción del agente de supervisión del mercado. Pero hay algunos detalles a considerar. Por ejemplo, el horizonte de planificación forecast se sustituirá por el espacio de acción del agente n_actions. Además, hemos añadido parámetros específicos para el número de segmentos (segments) y el factor de área de desenfoque (rho).
Al igual que antes, en el cuerpo del método llamaremos al método homónimo de la clase ancestral (capa básica de completamente conectada), solo que especificaremos el espacio de acción de nuestro agente RL como el tamaño del tensor de resultados del objeto.
Luego vaciaremos el array dinámico de punteros a los objetos internos.
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
Y pasaremos inmediatamente los datos iniciales recibidos como entrada del modelo al PSformer, cuyo número de capas necesario crearemos en el cuerpo del ciclo.
//--- State observation int lay_count = 0; for(uint i = 0; i < layers; i++) { CNeuronPSformer *psf = new CNeuronPSformer(); if(!psf || !psf.Init(0, lay_count, OpenCL, window, units_count, segments, rho, optimization,iBatch)|| !cLayers.Add(psf)) { delete psf; return false; } lay_count++; }
A continuación, nuestro agente RL decidirá la acción óptima pasando los resultados del análisis realizado del estado actual del entorno a través del bloque de decisión, que consta de capas convolucionales y una capa completamente conectada. En primer lugar, la capa de convolución reducirá la dimensionalidad del tensor de datos de origen.
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(n_actions, lay_count, OpenCL, window, window, 1, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(GELU); lay_count++;
Y luego, la capa completamente conectada generará el tensor de acciones.
CNeuronBaseSAMOCL *flat = new CNeuronBaseSAMOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, n_actions, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; } SetActivationFunction(SIGMOID);
Nótese que en este caso no utilizaremos la política estocástica del Actor. Sin embargo, no descartaremos la posibilidad de utilizarla; hablaremos de ello más adelante.
Para el vector de acciones, utilizaremos por defecto una función de activación sigmoidal, restringiendo el rango de valores entre 0 y 1. Sin embargo, la función de activación podrá modificarse desde un programa externo.
Ahora todo lo que deberemos hacer es sustituir los punteros a los búferes de datos de la interfaz y finalizar el método pasando el resultado lógico de las operaciones al programa que realiza la llamada.
if(!SetOutput(flat.getOutput(), true) || !SetGradient(flat.getGradient(), true)) return false; //--- return true; }
Con esto concluye nuestro análisis del objeto de agente RL. Encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
2.3 Controlador
Más arriba, ya hemos construido los objetos de dos agentes de los tres estudiados. Y ahora tendremos que organizar la funcionalidad del tercer agente: el Controlador. Su función consiste en evaluar los riesgos y ajustar las acciones del agente RL basándose en el análisis del entorno realizado por el agente de supervisión del mercado.
Como se ve fácilmente, la principal diferencia de este último agente será la presencia de dos fuentes de datos de entrada. Para ello, tendremos que analizar las dependencias y el impacto de una fuente de datos en los valores de otra. En mi opinión, la estructura del descodificador del Transformer hará frente perfectamente a esta tarea. Sin embargo, en lugar de Self- y Cross-Attention, utilizaremos módulos similares con codificación relativa.
Para implementar este algoritmo, crearemos un nuevo objeto CNeuronControlAgent que heredará la funcionalidad básica del mismo CNeuronRMAT. No obstante, la presencia de dos fuentes de datos nos obligará a hacer un trabajo extra para redefinir los métodos. A continuación, le mostraremos la estructura de la nueva clase.
class CNeuronControlAgent : public CNeuronRMAT { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronControlAgent(void) {}; ~CNeuronControlAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronControlAgent; } };
Al igual que antes, la estructura de los objetos internos de nuestro agente se establecerá en el método de inicialización Init, en cuyos parámetros veremos las conocidas constantes que describen la arquitectura del decodificador del Transformer.
bool CNeuronControlAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- Clear layers' array cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
En el cuerpo del método, de forma similar a los dos casos anteriores, invocaremos el método homónimo de la capa básica completamente conectada, especificando la dimensionalidad de los resultados al nivel del tensor básico de datos de origen. Después de eso, eliminaremos el array dinámico para el almacenamiento de los punteros a los objetos internos.
A continuación, crearemos la arquitectura de nuestro agente-controlador. Y aquí deberemos recordar que a la salida del agente de supervisión del mercado recibiremos una previsión del próximo movimiento del mercado como una serie temporal multimodal que estará representada por una secuencia de vectores que describirán los estados individuales del entorno (en nuestro caso barras).
Aquí podemos considerar 2 enfoques: hacer coincidir las acciones del agente RL con cada barra, o con secuencias unitarias individuales. Al mismo tiempo, deberemos ser conscientes de que el agente de supervisión del mercado solo nos ha proporcionado datos de previsiones cuya probabilidad dista mucho de ser del 100%, así que existe la posibilidad de que se produzcan desviaciones en absolutamente todos los valores.
Vamos a discurrir de forma lógica. ¿Cuánta información nos dará el vector de descripciones de una vela prevista, donde la proporción de desviaciones de diferentes grados en cada elemento es alta? La cuestión resulta controvertida y difícil de responder sin conocer la precisión de las previsiones individuales.
Por otra parte, si observamos una serie unitaria individual, podemos identificar una tendencia de movimiento inminente además de sentidos individuales. Y puesto que la tendencia no está formada por un único valor, sino por su totalidad, resultará lógico esperar su confirmación, aunque algunos elementos se desvíen.
Además, todas las secuencias unitarias de nuestras series temporales multimodales muestran algunas dependencias entre sí. Y cuando la tendencia prevista de una serie temporal unitaria se ve confirmada por los valores de otra, la probabilidad de dicha previsión aumenta.
En vista de lo anterior, hemos decido analizar la dependencia de las acciones del agente respecto a los valores predichos de las secuencias unitarias. Para ello, primero transferiremos los datos de la segunda fuente de datos a una capa neuronal básica especialmente preparada.
int lay_count = 0; CNeuronBaseOCL *flat = new CNeuronBaseOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, window_kv * units_kv, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; }
Y luego la reformatearemos en una representación de secuencias unitarias.
lay_count++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; } lay_count++;
A continuación tendremos que construir la arquitectura de nuestro descodificador, cuyo número de capas se creará en un ciclo, mientras que el número de iteraciones de este ciclo vendrá determinado por los parámetros externos del método de inicialización.
//--- Attention Action To Observation for(uint i = 0; i < layers; i++) { if(units_count > 1) { CNeuronRelativeSelfAttention *self = new CNeuronRelativeSelfAttention(); if(!self || !self.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, optimization, iBatch) || !cLayers.Add(self)) { delete self; return false; } lay_count++; }
Aquí cabe señalar que a la entrada del descodificador del Transformer vainilla, los datos son procesados en primer lugar por el módulo de Self-Attention. Este módulo analizará las dependencias entre elementos individuales de los datos de origen. En nuestra aplicación, lo sustituiremos por otro similar, utilizando un algoritmo de codificación relativa. No obstante, crearemos el módulo anterior solo si hay más de un elemento en la secuencia original. Después de todo, si hay un solo elemento en los datos de origen, no tendremos dónde buscar dependencias. Y el módulo de Self-Attention se volverá redundante.
A continuación crearemos un módulo de atención cruzada que analizará las dependencias entre los elementos de las dos fuentes de datos.
CNeuronRelativeCrossAttention *cross = new CNeuronRelativeCrossAttention(); if(!cross || !cross.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(cross)) { delete cross; return false; } lay_count++;
Y cada capa del decodificador se completará con un bloque FeedForward, en calidad del cual utilizaremos un bloque convolucional con retroalimentación.
CResidualConv *ffn = new CResidualConv(); if(!ffn || !ffn.Init(0, lay_count, OpenCL, window, window, units_count, optimization, iBatch) || !cLayers.Add(ffn)) { delete ffn; return false; } lay_count++; }
Después, pasaremos a la siguiente iteración del ciclo y crearemos una nueva capa del decodificador.
Aquí cabe señalar que, de forma similar a la arquitectura del descodificador del Transformer, la normalización de los datos se realizará a la salida del bloque de convolución con realimentación. Sin embargo, podemos necesitar restringir el espacio de acción del Actor dentro de un rango específico, que normalmente es introducido por la función de activación. Por lo tanto, tras crear el número necesario de capas del decodificador, añadiremos otra capa de convolución especificando la función de activación requerida.
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, lay_count, OpenCL, window, window, window, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } SetActivationFunction(SIGMOID);
De forma similar al agente RL, especificaremos por defecto una función de activación sigmoidea. Aún podemos cambiarlo desde un programa externo.
Al final del método de inicialización, sustituiremos los punteros a los búferes de interfaz y devolveremos el resultado lógico de las operaciones al programa que realiza la llamada.
//--- if(!SetOutput(conv.getOutput(), true) || !SetGradient(conv.getGradient(), true)) return false; //--- return true; }
Una vez finalizado el trabajo de inicialización del objeto, construiremos los algoritmos de pasada directa, que implementaremos en el método feedForward.
bool CNeuronControlAgent::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
En los parámetros del método obtendremos los punteros a los dos objetos de los datos de origen. El flujo principal de datos de origen se representará como una capa neuronal, mientras que los datos adicionales se transferirán en un búfer de datos. Y para que resulte más cómodo trabajar con ambas fuentes de datos, sustituiremos el búfer de datos de los resultados de la capa interna especialmente creada por el objeto obtenido en los parámetros del método.
CNeuronBaseOCL *second = cLayers[0]; if(!second) return false; if(!second.SetOutput(SecondInput, true)) return false;
A continuación, transpondremos el tensor de la segunda fuente de datos para representar la serie temporal multimodal como una secuencia de series unitarias.
second = cLayers[1]; if(!second || !second.FeedForward(cLayers[0])) return false;
Y organizaremos un ciclo de enumeración secuencial del resto de capas neuronales internas con la correspondiente llamada a sus métodos de pasada directa y les transmitiremos los datos de ambas fuentes.
CNeuronBaseOCL *first = NeuronOCL; CNeuronBaseOCL *main = NULL; for(int i = 2; i < cLayers.Total(); i++) { main = cLayers[i]; if(!main || !main.FeedForward(first, second.getOutput())) return false; first = main; } //--- return true; }
Una vez todas las iteraciones del ciclo se hayan ejecutado con éxito, todo lo que tendremos que hacer es devolver el resultado lógico de las operaciones al programa que realiza la llamada y finalizar el método.
Como podemos ver, el algoritmo del método de pasada directa es bastante sencillo. Y lo conseguiremos utilizando bloques estándar para construir arquitecturas más complejas.
Sin embargo, existirá cierta dificultad para construir el método de distribución del gradiente de error debido al uso de una segunda fuente de datos. La cuestión es que en la línea troncal principal, transferiremos secuencialmente los datos de una capa interna a otra. Pero la segunda fuente de datos será la misma para todas las capas del descodificador. Más concretamente, para todos los módulos de atención cruzada. En consecuencia, tendremos que recoger el gradiente de error a la segunda fuente de datos de todos los módulos de atención cruzada. Le sugiero buscar una solución a este problema en el código.
El algoritmo de distribución del gradiente de error se implementará en el método calcInputGradients. En los parámetros de este método, obtendremos los punteros a los objetos de los dos flujos de datos de origen y sus gradientes de error. Nuestra tarea consistirá en distribuir el gradiente de error entre las fuentes de datos de entrada, según su influencia en el resultado.
bool CNeuronControlAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
En el cuerpo del método comprobaremos directamente la relevancia de los punteros obtenidos. Al fin y al cabo, no podemos transferir datos a objetos que no existen.
Al igual que sucede con la pasada directa, la segunda fuente de datos se representará en forma de búferes. Y realizaremos una sustitución de punteros en la capa interna correspondiente.
CNeuronBaseOCL *main = cLayers[0]; if(!main) return false; if(!main.SetGradient(SecondGradient, true)) return false; main.SetActivationFunction(SecondActivation); //--- CNeuronBaseOCL *second = cLayers[1]; if(!second) return false; second.SetActivationFunction(SecondActivation);
Al mismo tiempo, no nos olvidaremos de sincronizar las funciones de activación de la capa interna y de la capa posterior de transposición de datos con la función de activación de los datos de origen. Esto será necesario para transferir correctamente el gradiente de error.
A continuación, nuestra capa interna de transposición desempeñará el papel de segunda fuente de datos. Y para mayor comodidad, almacenaremos los punteros a sus objetos de interfaz en las variables locales.
CBufferFloat *second_out = second.getOutput(); CBufferFloat *second_gr = second.getGradient(); CBufferFloat *temp = second.getPrevOutput(); if(!second_gr.Fill(0)) return false;
Asimismo, nos aseguraremos de limpiar el búfer de gradiente de error de los datos acumulados anteriormente.
Después organizaremos un ciclo de iteración inversa de las capas neuronales internas. Pero tenga en cuenta que en el cuerpo del ciclo solo trabajaremos con los objetos del decodificador.
Recordemos que los dos primeros objetos internos se usan para servir a la segunda fuente de datos.
for(int i = cLayers.Total() - 2; i >= 2; i--) { main = cLayers[i]; if(!main) return false;
En el cuerpo del ciclo, extraeremos del array el puntero al objeto de la capa neuronal correspondiente y comprobaremos directamente la relevancia del puntero obtenido.
Además, deberemos recordar que no todos los objetos del descodificador trabajan con dos fuentes de datos de origen. Por consiguiente, nuestro algoritmo se bifurcará en función del tipo de objeto que transmita el gradiente de error. En el caso del módulo de atención cruzada, primero transferiremos el gradiente de error de la segunda fuente de datos de la capa actual a un búfer de almacenamiento temporal de datos. Y después, sumaremos los valores obtenidos con los acumulados anteriormente.
if(cLayers[i + 1].Type() == defNeuronRelativeCrossAttention) { if(!main.calcHiddenGradients(cLayers[i + 1], second_out, temp, SecondActivation) || !SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
En otros casos, simplemente transmitiremos el gradiente de error por la línea troncal principal. Y pasaremos a la siguiente iteración del ciclo.
else { if(!main.calcHiddenGradients(cLayers[i + 1])) return false; } }
Una vez ejecutadas todas las iteraciones del ciclo, solo nos quedará transmitir el gradiente de error a la capa de datos de origen. Primero trabajaremos en la línea troncal principal y pasaremos el gradiente de error a la primera capa de datos de origen.
if(!NeuronOCL.calcHiddenGradients(main.AsObject(), second_out, temp, SecondActivation)) return false;
Pero aquí deberemos recordar que la primera capa del decodificador puede ser un módulo de Self-Attention o de Cross-Attention. En este último caso, se utilizarán 2 fuentes de datos de origen. En consecuencia, tendremos que comprobar el tipo de objeto que transmite el gradiente de error y, de ser necesario, añadir el gradiente de error de la segunda fuente de datos a los valores acumulados anteriormente.
if(main.Type() == defNeuronRelativeCrossAttention) { if(!SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
Y ahora transmitiremos todo el gradiente acumulado a través de la segunda línea troncal de datos al nivel de la fuente correspondiente.
main = cLayers[0]; if(!main.calcHiddenGradients(second.AsObject())) return false; //--- return true; }
Después finalizaremos el método, devuelto previamente el resultado lógico de las operaciones al programa que realiza la llamada.
El algoritmo del método updateInputWeights para actualizar los parámetros del modelo es bastante sencillo. Solo llamaremos en un ciclo a los métodos de los objetos internos homónimos que contienen los parámetros a entrenar, así que no nos detendremos a analizarlo con detalle. No obstante, recuerde que utilizaremos objetos optimizados con parámetros SAM en la arquitectura de objetos construida. Por lo tanto, la enumeración de los objetos internos deberá hacerse en orden inverso.
Con esto concluirá nuestra revisión de los algoritmos para construir los métodos del agente-controlador. Podrá ver el código completo de la nueva clase y todos sus métodos en el archivo adjunto.
Hoy hemos trabajado duro, pero nuestra tarea aún no ha terminado. Haremos una breve pausa y llevaremos nuestras ideas a su conclusión lógica en el próximo artículo.
Conclusión
Hoy nos hemos familiarizado un enfoque innovador para gestionar portafolios de inversión en mercados financieros volátiles: el marco adaptativo multiagente MASA. El marco propuesto combina con éxito las ventajas de los algoritmos RL para la optimización del rendimiento y los métodos de optimización adaptativa para la minimización del riesgo, e incluye un módulo de supervisión del mercado para analizar las tendencias actuales.
En la parte práctica, hemos implementado cada uno de los agentes propuestos usando MQL5 en forma de módulos independientes. En el próximo artículo, los combinaremos en un marco coherente, además de evaluar la eficacia de las soluciones aplicadas sobre datos históricos reales.
Enlaces
- Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16537
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso