
MQL5でのデータベースの簡素化(第2回):メタプログラミングを使用してエンティティを作成する

はじめに
前回の記事では、MQL5が提供するデータベース機能の基本的な仕組みを確認しました。テーブル作成、レコードの挿入、更新、削除、トランザクション管理、さらにはデータのインポートおよびエクスポートまで、すべてを生のSQLとネイティブ関数を用いて実装しました。これらの作業は、今後どのような抽象化層を構築するにしても欠かすことのできない基礎となるものです。しかし、ここで必然的に「ロジック内でデータを扱うたびに、毎回SQLを手書きする必要があるのか」という問いが生じます。
より複雑で拡張性の高いシステムを想定する場合、その答えは明確に「いいえ」です。生のSQLだけに依存すると、コードは冗長になりやすく、記述の重複も増えます。扱うテーブル数が増加し、リレーションや検証が複雑化するにつれて、コードの保守性は急速に低下し、エラーが発生しやすくなります。そこで重要となるのがORM(オブジェクト関係マッピング)です。オブジェクト指向ベースで記述するMQL5のコードと、データが格納されるリレーショナルデータベースの構造との間に整合性を持った橋渡しをおこなう仕組みであり、その実現の第一歩は、テーブルをMQL5のクラスとして表現する手法を確立することにあります。
本記事では、そのための基盤となる#defineを用いた自動化と標準化の手法を解説します。これにより構造定義の重複を避けることで、エンティティ生成や列メタデータ管理を拡張性高くおこなえるようになります。併せて、テーブルを表現するエンティティクラスおよび列の属性(データ型、主キー、オートインクリメント、必須属性、デフォルト値など)を記述する仕組みの構築にも取り組みます。
今回紹介するアプローチは、後続のリポジトリ、クエリビルダー、テーブルの自動生成といった機能の基盤を形成するものです。すなわち、本記事からは、当初より構想していたMQL5向けORMの具体的な実装に向けた取り組みが本格的に始まります。
#defineとは何か、MQL5ではどのように機能するか
C系言語(MQL5もこの系統に属します)において、#defineはプリプロセッサによって処理される仕組みであり、最終的なコードをコンパイルする前段階で適用されます。#define自体は関数の生成や変数の作成をおこなうものではなく、いわば「ショートカット」あるいはマクロとして、コード内のテキストを賢く置換する機能です。
実際には、同じ記述パターンを一度定義しておくことで、コードの複数箇所で再利用できるため、重複や記述ミスを減らせます。さらに、#defineをメタプログラミング的な手法として活用し、簡潔な定義から複雑な構造、たとえばデータベースエンティティを生成することも可能です。
ここでは、基本的な使い方から高度な活用方法まで順に整理していきます。
1. もっとも単純な#define:別名と直接置換
最も一般的な利用方法は、テキストのショートカットを作る用途です。
#define PI 3.14159 #define AUTHOR "João Pedro" //--- Use int OnInit() { double area = PI * 2 * 2; Print("Code written by", AUTHOR); return(INIT_SUCCEEDED); }
上記の例では、コンパイラは、PIという識別子を見つけると3.14159の値に置き換えます。型チェックや文脈判断は一切ありません。いわば純粋なテキスト置換であり、有用ではあるものの、まだ単純な活用例です。
2. パラメータ付きマクロ
#defineでは、パラメータを受け取るマクロを定義することもできます。
#define SQUARE(x) (x * x) int OnInit() { Print("Square of 5: ", SQUARE(5)); Print("Square of 10: ", SQUARE(10)); }
コンパイル時には、SQUARE(5)が文字通り(5 * 5)に展開されます。このように、繰り返し発生する処理パターンを再利用可能な形にカプセル化できます。
3. #演算子:引数の文字列化
MQL5ではあまり知られていない機能として、#演算子があります。これはマクロの引数をリテラル文字列として展開します。
#define META(name) Print("Variable name: ", #name) int OnInit() { int value = 42; META(value); }
この例が示すように、#nameは変数の内容ではなく「変数名そのもの」を文字列として扱います。この仕組みは、ログ生成やコード識別子からメタデータを組み立てる際に非常に有用です。
4. ##演算子:識別子の連結
もう一つの高度な機能として、##演算子があります。これは2つのトークン(コード片)を結合します。
#define META(name) Print("Concatenated: ", name##Id) int OnInit() { int userId = 7; META(user); }
ここでは、userとIdが結合され、userIdという識別子が生成されます。MQL5では動的に変数名やメソッド名、定数名を構築することは通常不可能ですが、この機能によりコンパイル時に識別子を構築することができます。
5. 別のマクロを引数として受け取るマクロ
ここまで、#defineを単純な置換やパラメータ付き構造として扱ってきました。しかし、さらに重要なのは、マクロが別のマクロを引数として受け取れる点です。これにより、1つの定義から複数のコードブロックを生成する「繰り返しエンジン」のような仕組みを構築できます。
次の例をご覧ください。
// Step 1 - Macro that describes a set of operations #define MATH_OPERATIONS(OP) \ OP(Add, +) \ OP(Sub, -) \ OP(Mul, *) \ OP(Div, /) // Step 2 - Macro that generates functions from the list above #define GENERATE_FUNCTION(name, symbol) \ double name(double a, double b) { return a symbol b; } // Step 3 - Expansion: Creates multiple functions at once MATH_OPERATIONS(GENERATE_FUNCTION) // Step 4 - Use int OnInit() { Print("2 + 3 = ", Add(2,3)); Print("10 - 7 = ", Sub(10,7)); Print("6 * 4 = ", Mul(6,4)); Print("20 / 5 = ", Div(20,5)); return INIT_SUCCEEDED; }
この例では何が起こっているのでしょうか。処理内容を段階的に整理していきましょう。
-
ステップ1:ここでは、単独では意味のあるコードを生成しないマクロを定義しています。Add、Sub、Mul、Divという4つの要素を列挙し、それぞれに対応する演算子を関連付けています。各行はOPマクロを呼び出していますが、その具体的な実装はまだ定義されていません。つまり、このMATH_OPERATIONSはテンプレートとして機能し、どのように展開するかは後から与える「処理ツール」に依存します。
-
ステップ2:GENERATE_FUNCTIONマクロは、nameとsymbolを受け取り、その演算を実行する関数を生成します。たとえば(Add, +)を与えると、次のような関数が生成されます。
double Add(double a, double b) { return a + b; }
Sub、Mul、Divも同様です。
-
ステップ3:ここでMATH_OPERATIONSにGENERATE_FUNCTIONを渡します。これにより、MATH_OPERATIONS内部の各OP呼び出しがGENERATE_FUNCTIONに置き換えられ、最終的には次のようなコードが生成されます。
double Add(double a, double b) { return a + b; } double Sub(double a, double b) { return a - b; } double Mul(double a, double b) { return a * b; } double Div(double a, double b) { return a / b; }
-
ステップ4:コンパイラがマクロ展開によって生成したAdd、Sub、Mul、Div関数をそのまま使用しています。開発者から見ると元から存在する関数のように見えますが、実際にはマクロによって自動生成されたものです。
要約すると
- マクロは要素列挙のテンプレートとして利用できます(MATH_OPERATIONS)。
- 別のマクロは、そのテンプレートを具体的なコードへ変換する処理を担います(GENERATE_FUNCTION)。
- 2つを組み合わせることで、関数、メソッド、プロパティ、クラスなど、繰り返し構造を自動生成することができます。
このように、マクロを他のマクロへ受け渡す技法は、コードの重複を排除し、構造の統一性を確保し、拡張性の高いコードブロックを生成するための強力な手段です。後続の記事では、この仕組みをデータベースのテーブルや列の定義に適用していきますが、ここまでの例から明らかなように、この技法はデータベースに限らず、あらゆるパターン化された処理に利用できます。
テーブルを表すクラス(エンティティ)の生成
エンティティとは、データベースのテーブルをマッピングするクラスのことです。つまり、データベースにAccountというテーブルがありid、number、balance、ownerといった列を持つとき、コード側では各列を表すプロパティを持つAccountクラスを定義します。こうすることで、SQLを逐一扱わずにオブジェクトとしてデータを操作できるようになります。
たとえばAccountテーブルをMQL5で表現する場合、原則的には次のようなクラスを用意します。
class Account { public: ulong id; // unique identifier double number; // account number double balance; // available balance string owner; // account owner Account(void); ~Account(void); //--- Converts the data into a string string ToString(); }; Account::Account(void) { } Account::~Account(void) { } string Account::ToString(void) { return("Account[id="+ (string)id+ ", number="+ (string)number+ ", balance="+ (string)balance+ ", owner="+ (string)owner+ "]"); }
上記の実装は動作しますが、従来型の手書き実装には次の2つの問題点があります。
- 繰り返し:テーブルごとにプロパティやコンストラクタを手作業で書く必要があります。たとえばシステムに20テーブルがある場合、フィールドが異なるだけでほとんど同じクラスが20個できてしまいます。
- 拡張性の低さ:あるテーブルの列が変更された場合(たとえばnumberをaccount_numberに名前変更する等)、データベースとクラスの両方を手作業で修正する必要があり、不整合が発生するリスクがあります。
ここで、#defineを使ったメタプログラミングが有効になります。マクロでエンティティを自動生成するアイデアは前のセクションで見た手法と非常に似ています。列の一覧をマクロとして定義し、その一覧から対応するクラスを自動生成する仕組みを作ります。以下、段階を追って説明します。
ステップ1:マクロで列を定義する#define ACCOUNT_COLUMNS(COLUMN) \ COLUMN(ulong, id, 0) \ COLUMN(double, number, 0.0) \ COLUMN(double, balance, 0.0) \ COLUMN(string, owner, "")
ここでACCOUNT_COLUMNSはAccountテーブルのすべての列を定義しています。各列は型、名前、デフォルト値の3つ組で表されています。
鍵となるのはCOLUMNというパラメータで、後段のマクロに渡されることで各項目に対して何をおこなうかが決定されます。
ステップ2:クラスの属性を生成するマクロを作る#define ENTITY_FIELD(type, name, default_value) type name; #define ENTITY_DEFAULT(type, name, default_value) name = default_value; #define ENTITY_TO_STRING(type, name, default_value) _s += #name+"="+(string)name+", ";
これらのマクロはエンティティの構成要素です。各マクロは型、名称、デフォルト値を受け取り、特定のコード片を生成します。
- ENTITY_FIELD:クラス属性を宣言します。
- 例:ENTITY_FIELD(ulong,id,0)は「ulong id;」を生成します。
- つまり、変数の宣言のみをおこないます。
- ENTITY_DEFAULT:コンストラクタ内で属性をデフォルト値で初期化します。
- 例:ENTITY_DEFAULT(double, balance, 0.0)は、「balance = 0.0;」を生成します。
- これにより、クラスの全インスタンスは一貫した初期値で生成されます。
- ENTITY_TO_STRING:属性の値を表示するための文字列連結コードを生成します。
- 例:ENTITY_TO_STRING(string, owner, "")は「_s += "owner="+(string)owner+", ";」のようなコードを生成します。
- こうして、個別にToStringを手書きすることなく、すべての列を出力する汎用的なToStringを作成することができます。
#define ENTITY(name, COLUMN) \ class name \ { \ public: \ COLUMN(ENTITY_FIELD) \ name(void){COLUMN(ENTITY_DEFAULT)}; \ ~name(void){}; \ string ToString(void) \ { \ string _s = ""; \ COLUMN(ENTITY_TO_STRING) \ _s = StringSubstr(_s,0,StringLen(_s)-2); \ return(#name+ "["+_s+"]"); \ } \ };
ここまでの部品を組み合わせ、クラス全体を構築するマクロを定義します。1行ずつ分解してみましょう。
-
class name {...};
- 指定したnameでクラスを生成します。
- 例:ENTITY(Account, ACCOUNT_COLUMNS) → class Account {...};
-
COLUMN(ENTITY_FIELD)
- 列一覧に対してENTITY_FIELDマクロを適用します
- 結果:すべての属性を宣言します。
-
name(void){COLUMN(ENTITY_DEFAULT)};
- コンストラクタはCOLUMN(ENTITY_DEFAULT)を呼び、すべての属性をデフォルト値で初期化します。
-
~name(void){};
- 明示的な空のデストラクタです。
-
ToString()メソッド
- _sに各列のname=valueを連結します。
- COLUMN(ENTITY_TO_STRING)を各列に利用します。
- 末尾のカンマをStringSubstrで削除します。
- 結果として次のような出力が得られます。
Account[id=1, number=12345, balance=500.0, owner=João]
ENTITY(Account, ACCOUNT_COLUMNS)
この1行は、冒頭で手動で書いたAccountクラスと同等のクラスを自動的に生成し、その後はAccountクラスを通常どおり利用できます。
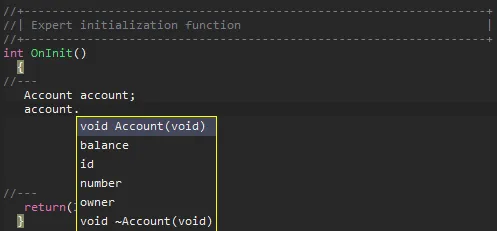
手書きによる実装と#defineを用いた自動生成とでは、拡張性と保守性の面で大きな差があります。新しいエンティティを作成するには、次の2つだけをおこなえばよくなります。
- 列をTABLE_COLUMNSマクロで定義する
- DEFINE_ENTITY(Table, TABLE_COLUMNS)を呼び出す
これにより重複が排除され、更新が容易になり(列名を変更する場合、マクロの定義を変更するだけで済む)、さらに自動コンストラクタ生成、シリアライズ、SQLとの統合など、この概念を拡張するための余地が大きく広がります。
列メタデータ:プロパティのカプセル化
これまで、属性を持つエンティティを作り、さらにはマクロを用いてその値を自動的に出力するところまで実現してきました。しかし、ここには一つ問題があります。これらの属性は依然として「無言」のままなのです。
データを保持することはできますが、自分自身を記述することはできません。たとえば、ある属性に対して「主キー(PK)ですか?」「NULL値を受け入れられますか?」「これはオートインクリメント列ですか?」「データベース上の実際の型(INTEGER、TEXT、REALなど)は何ですか?」のように問い合わせることができません。
このような情報はメタデータと呼ばれ、データについてのデータという位置付けになります。ORMが自動的にSQLを生成できるようにするため(たとえば、テーブル作成や構造の検証など)、エンティティが自分自身を説明できるようにするための追加層が必要となります。
ここで考えるのは、IColumnMetadataというメタデータクラスを作ることです。このクラスは列に関するすべての情報を保持する役割を担います。
- 列名(m_name)
- MQL5上の論理型(m_type)
- データベース型(m_db_type)
- NULL値にできるかどうか(m_nullable)
- オートインクリメントかどうか(m_auto_increment)
- 主キーかどうか(m_primary_key)
- 一意かどうか(m_unique)
このように、エンティティの各列が完全な記述情報を携えるようになり、今後はCREATE TABLE文を自動生成したり、データベースがエンティティと一致しているか検証したり、MQL5とSQLの間で値を適切にマッピングしたりすることが可能になります。
includes内にTickORMという新しいフォルダを作成し、その中にmetadataフォルダを作り、さらにIColumnMetadata.mqhというファイルを作成します。最終的なパスは<MQL5/Includes/TickORM/metadata/ColumnMetadata.mqh>のようになります。次に、以下のクラスを作成します。
//+------------------------------------------------------------------+ //| class abstract : IColumnMetadata | //| | //| [PROPERTY] | //| Name : IColumnMetadata | //| Heritage : No heritage | //| Description : Stores all the information in a column. | //| | //+------------------------------------------------------------------+ class IColumnMetadata { private: //--- Props string m_name; string m_type; string m_db_type; bool m_nullable; bool m_auto_increment; bool m_primary_key; bool m_unique; public: IColumnMetadata(string name, string type,string db_type,bool nullable,bool auto_increment,bool primary_key,bool unique); IColumnMetadata(void); ~IColumnMetadata(void); //--- Get Props string Name(void); string Type(void); string DbType(void); bool Nullable(void); bool AutoIncrement(void); bool PrimaryKey(void); bool Unique(void); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ IColumnMetadata::IColumnMetadata(string name,string type,string db_type,bool nullable,bool auto_increment,bool primary_key,bool unique) { m_name = name; m_type = type; m_db_type = db_type; m_nullable = nullable; m_auto_increment = auto_increment; m_primary_key = primary_key; m_unique = unique; } //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ IColumnMetadata::IColumnMetadata(void) { } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ IColumnMetadata::~IColumnMetadata(void) { } //+------------------------------------------------------------------+ //| Get name | //+------------------------------------------------------------------+ string IColumnMetadata::Name(void) { return m_name; } //+------------------------------------------------------------------+ //| Get type | //+------------------------------------------------------------------+ string IColumnMetadata::Type(void) { return m_type; }; //+------------------------------------------------------------------+ //| Get database type | //+------------------------------------------------------------------+ string IColumnMetadata::DbType(void) { return m_db_type; }; //+------------------------------------------------------------------+ //| Get is nullable | //+------------------------------------------------------------------+ bool IColumnMetadata::Nullable(void) { return m_nullable; }; //+------------------------------------------------------------------+ //| Get is auto increment | //+------------------------------------------------------------------+ bool IColumnMetadata::AutoIncrement(void) { return m_auto_increment; }; //+------------------------------------------------------------------+ //| Get is primary key | //+------------------------------------------------------------------+ bool IColumnMetadata::PrimaryKey(void) { return m_primary_key; }; //+------------------------------------------------------------------+ //| Get is unique | //+------------------------------------------------------------------+ bool IColumnMetadata::Unique(void) { return m_unique; }; //+------------------------------------------------------------------+
このクラスには複雑な処理や高度なロジックはありません。単にテーブル列のデータを保持するだけです。一見するとこの抽象化レベルはやや形式的に見えるかもしれませんが、実際には以下の理由で次のステップへ進むために不可欠なものです。
- エンティティが自分自身のメタデータを公開できるようになる
- ORMがこのメタデータを反復処理し、対応するテーブルをデータベース内に自動生成できるようになる
この層がなければ、テーブルを作成するたびに毎回CREATE TABLE...文を手作業で書く必要があり、まさに排除したい繰り返し作業そのものになります。
たとえば、Tradesというテーブルに次の3つの列があるとします。
- id:integer、primary key、auto_increment
- symbol:必須のstring、NULL不可
- volume:必須のdecimal number
この場合、メタデータクラスを使って次のように記述できます。
IColumnMetadata id("id", "int", "INTEGER", false, true, true, true); IColumnMetadata symbol("symbol", "string", "TEXT", false, false, false, false); IColumnMetadata volume("volume", "double", "REAL", false, false, false, false);
ここで扱っているのは単なる属性ではなく、自分自身を理解し、ルールや制約を説明できるオブジェクトなのです。
もはや単なる属性ではなく、自身のルールや制約を説明できる自己記述的なオブジェクトなのです。
ITableMetadataクラスの作成:エンティティの完全な説明
これまで列レベルで作業してきましたが、ここからは一歩進んで、テーブル全体のレベルで考える必要があります。各テーブル(またはエンティティ)は単なる属性の集合ではなく、固有の名前、主キー、そして複数の列メタデータを持ちます。
言い換えれば、エンティティが持つすべてのIColumnMetadataを保持できる構造が必要になります。IColumnMetadataがフィールドを記述するものであるとすれば、これから作成するITableMetadataはエンティティ全体を記述するものです。これにより、「テーブル名は何か?」「主キーは何か?」「列はいくつあるか?」「各列にはどのようなプロパティがあるか?」のような追加の問いに答えられる必要があります。
さらに、拡張可能である必要があります。つまり、各エンティティは独自のメタデータを持ちますが、共通の基底インターフェイスに従うことができなければなりません。
<MQL5/Include/TickORM/metadata/>ディレクトリにTableMetadata.mqhという新しいファイルを作成します。すでにColumnMetadata.mqhをインポート済みです。
//+------------------------------------------------------------------+ //| Import | //+------------------------------------------------------------------+ #include "PropertyMetadata.mqh" //+------------------------------------------------------------------+ //| class abstract : IEntityMetadata | //| | //| [PROPERTY] | //| Name : IEntityMetadata | //| Heritage : No heritage | //| Description : Stores all the information in a table. | //| | //+------------------------------------------------------------------+ class ITableMetadata { protected: IColumnMetadata *m_properties[]; public: ITableMetadata(void); ~ITableMetadata(void); //--- Add new column void AddColumn(IColumnMetadata *column); IColumnMetadata *Column(int index); int ColumnSize(void); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ ITableMetadata::ITableMetadata(void) { } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ ITableMetadata::~ITableMetadata(void) { int size = ArraySize(m_columns); for(int i=0;i<size;i++) { delete m_columns[i]; } } //+------------------------------------------------------------------+ //| Add new column | //+------------------------------------------------------------------+ void ITableMetadata::AddColumn(IColumnMetadata *column) { int size = ArraySize(m_columns); ArrayResize(m_columns,size+1); m_columns[size] = column; } //+------------------------------------------------------------------+ //| Get property metadata | //+------------------------------------------------------------------+ IColumnMetadata *ITableMetadata::Column(int index) { return(m_columns[index]); } //+------------------------------------------------------------------+ //| Get size columns | //+------------------------------------------------------------------+ int ITableMetadata::ColumnSize(void) { return(ArraySize(m_columns)); } //+------------------------------------------------------------------+
ここでは、列メタデータを保持するためにIColumnMetadataの配列を追加しています。配列の各位置がテーブルの各列に対応します。また、配列を操作するための基本的なメソッドも追加しています。
最後に、2つの仮想メソッドを追加しています。これにより、派生クラスはTableName()とPrimaryKey()を上書きして、自分自身を記述できるようになります。テーブル名を知っているのは派生クラスだけなので、このような設計が必要になります。この問題を回避するため、基底実装ではNULLを返すようにしています。
class ITableMetadata { public: //--- Virtual methods (will be implemented in the child class) virtual string TableName(void); virtual string PrimaryKey(void); }; //+------------------------------------------------------------------+ //| Get table name | //+------------------------------------------------------------------+ string ITableMetadata::TableName(void) { return(NULL); } //+------------------------------------------------------------------+ //| Get is primary key | //+------------------------------------------------------------------+ string ITableMetadata::PrimaryKey(void) { return(NULL); } //+------------------------------------------------------------------+
すべてをつなぐ
ここまでで、2つの基本的なステップを進めてきました。まず、エンティティクラスを手動で作成し、次にマクロメタプログラミングを使ってこれらのクラスを自動生成する方法を確認しました。しかし、まだ重要なピースが不足しています。それは、エンティティとその列の定義を1つの場所に集約することです。この場所は、ネイティブのMQL5型をSQL型へ変換できるだけでなく、テーブルのすべてのメタデータを体系的に記録できなければなりません。
これこそが<MQL5/TickORM/>に配置されるTickORM.mqhファイルの役割です。MQL5で書かれたコードとリレーショナルデータベースモデルをつなぐ「橋」として機能するものです。ロジックはシンプルで、各エンティティに対してITableMetadataを継承したクラスを作り、そこにテーブルのすべての列を自動的に登録するだけです。
これによりORMは、テーブル構造を理解できるだけでなく、作成、検証、列操作をおこなえるようになり、開発者は新しいエンティティごとに同じ変換処理を手動で繰り返す必要がなくなります。
この仕組みの有用性をさらに理解するため、まずはステップバイステップで進めましょう。ここでは、Accountテーブルに対するメタデータクラスを手動で構築します。列は4つのみです。ここではまだマクロは使いません。自動化したい作業内容を明確にするためです。
class AccountMetadata : public ITableMetadata { public: AccountMetadata(void); ~AccountMetadata(void); string TableName(); string PrimaryKey(void); }; AccountMetadata::AccountMetadata(void) { this.AddColumn(new IColumnMetadata("id","ulong","INTEGER",false,true,true,true)); this.AddColumn(new IColumnMetadata("number","ulong","REAL",false,false,false,false)); this.AddColumn(new IColumnMetadata("balance","ulong","REAL",false,false,false,false)); this.AddColumn(new IColumnMetadata("owner","ulong","TEXT",false,false,false,false)); } AccountMetadata::~AccountMetadata(void) { } string AccountMetadata::TableName(void) { return("Account"); } string AccountMetadata::PrimaryKey(void) { int size = ArraySize(m_columns); for(int i=0;i<size;i++) { if(m_columns[i].PrimaryKey()) { return(m_columns[i].Name()); } } return(NULL); }
この実装により、テーブルのメタデータを取得できるようになります。以下のように利用します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- AccountMetadata metadata; int size_cols = metadata.ColumnSize(); Print("table name: ",metadata.TableName()); Print("ptimary key: ",metadata.PrimaryKey()); Print("size columns: ",size_cols); for(int i=0;i<size_cols;i++) { IColumnMetadata *column = metadata.Column(i); Print("==="); Print("Column name: "+column.Name()); Print("Type: "+column.Type()); Print("DbType: "+column.DbType()); Print("Nullable: "+column.Nullable()); Print("PrimaryKey: "+column.PrimaryKey()); Print("Unique: "+column.Unique()); } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
コンソールには、取得されたすべての情報が明確に表示されます。
table name: Account ptimary key: id size columns: 4 === Column name: id Type: ulong DbType: INTEGER Nullable: false PrimaryKey: true Unique: true === Column name: number Type: ulong DbType: REAL Nullable: false PrimaryKey: false Unique: false === Column name: balance Type: ulong DbType: REAL Nullable: false PrimaryKey: false Unique: false === Column name: owner Type: ulong DbType: TEXT Nullable: false PrimaryKey: false Unique: false
ここまでで、テーブルとその列に関するすべての本質的なデータが実行時に取得可能になりました。残されているのは、#defineを使ってこのメタデータクラスの作成を自動化し、各エンティティごとに同じ構造を手動で作らずに済むようにすることです。これは次のステップとなります。
メタデータクラスの作成を自動化する
MQL5のエンティティをデータベースへ接続し始めると、すぐに直面する課題があります。それはデータ型同士が同じ言語を話していないという点です。MQL5のコードではint、double、stringなどを使いますが、データベース側ではINTEGER、REAL、TEXTといった異なる型になります。
明確な変換ルールを作らなければ、各列を毎回手動でマッピングする必要があり、これは手間がかかるうえにエラーも起こりやすくなります。この再作業を避けるため、#defineを使って小さな「変換辞書」を作成しました。
#define MQL5_TO_SQL_int "INTEGER" #define MQL5_TO_SQL_double "REAL" #define MQL5_TO_SQL_float "REAL" #define MQL5_TO_SQL_long "INTEGER" #define MQL5_TO_SQL_ulong "INTEGER" #define MQL5_TO_SQL_datetime "INTEGER" #define MQL5_TO_SQL_string "TEXT" #define MQL5_TO_SQL_bool "INTEGER" #define DB_TYPE_FROM_MQL5(type) MQL5_TO_SQL_##type
仕組みは単純です。エンティティ内で列をintと宣言すると、DB_TYPE_FROM_MQL5マクロが自動的にそれをINTEGERに変換します。これにより、各MQL5型が常に対応するデータベース型へ確実に変換されるようになり、このマッピングを覚えたり手動で繰り返したりする必要がなくなります。
ここで型の問題が解決したので、次に必要になるのは、各テーブルのメタデータを整理する方法です。そのために、name##Metadata(例:AccountMetadata)というクラスを動的に生成します。このクラスはITableMetadataを継承し、主に次の2つの機能を持ちます。
- TableName():エンティティ名(=テーブル名として使用される)を返す
- PrimaryKey():どの列が主キーとして指定されているかを自動的に判定する
#define ENTITY_META_DATA(name, COLUMNS) \ class name##Metadata : public ITableMetadata \ { \ public: \ name##Metadata(void) \ { \ COLUMNS(ENTITY_META_DATA_COLUMNS); \ } \ ~name##Metadata(void){}; \ string TableName() { return(#name); }; \ string PrimaryKey(void) \ { \ int size = ArraySize(m_columns); \ for(int i=0;i<size;i++) \ { \ if(m_columns[i].PrimaryKey()) \ { \ return(m_columns[i].Name()); \ } \ } \ return(NULL); \ } \ };
最後に、完全なエンティティ(クラス + メタデータ)を生成するために2つのマクロを使用します。1つ目は列を定義し、2つ目はエンティティとそのメタデータクラスを自動生成します。
#define ACCOUNT_COLUMNS(COLUMN) \ COLUMN(ulong, id, false, 0, true, true, false) \ COLUMN(double, number, false, 0, false, false, false) \ COLUMN(double, balance, false, 0, false, false, false) \ COLUMN(string, owner, false,"", false, false, false) ENTITY(Account, COLUMNS) ENTITY_META_DATA(Account, COLUMNS)
これにより、わずか数行でAccountテーブルの構造全体を宣言できます。
- idは主キー(primary = true)かつオートインクリメント(auto_inc = true)です。
- numberとbalanceは必須の数値です。
- ownerは必須の文字列です。
つまり、単一の定義箇所だけで、AccountクラスとそのメタデータクラスであるAccountMetadataを生成でき、ORMによってすぐに使用できる状態になるのです。
結論と次のステップ
ORM構築におけるもう一つの段階に到達しました。本記事では、重要なプロセスを順に沿って扱いました。
- MQL5における#defineの仕組みについて、単なる定数ではなくメタプログラミング手法としてどのように機能するかを深く理解しました。
- エンティティ(テーブルを表すクラス)の作成へと進み、マクロを使ってその定義をどのように簡潔化できるかを見ていきました。
- 型、主キー、オートインクリメント、一意性、NULL許可などの属性を表すカラムメタデータを付与することで、エンティティを拡張しました。
- TickORM.mqhファイルにすべてを集約し、MQL5型とSQL型の関連付けやメタデータクラスの自動生成を実現しました。
この基盤は極めて重要です。エンティティが存在するだけでなく、それらの属性に関する完全な記述が揃ったことで、ORMがデータベースを知的かつ自動的に操作するための原動力となります。
次回の記事では、もう一つの決定的なステップとして、リポジトリ層を作成します。この層は、SQLを手書きする必要なくデータを操作する役割を担います。代わりに、accountRepository.Save(account)やordersRepository.FindById(1)のような呼び出しをおこなうだけで、残りはORMが処理します。
言い換えれば、これまでテーブル構造の記述方法を学んできたのに対し、次の記事ではデータをクリーンで整理された、かつ安全な方法で操作する方法を学ぶことになります。
| ファイル名 | 説明 |
|---|---|
| Include/TickORM/metadata/ColumnMetadata.mq5 | 列データを表すインターフェース |
| Include/TickORM/metadata/TableMetadata.mqh | テーブルデータを表すインターフェース |
| Include/TickORM/TickORM.mqh | メインファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/19594
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索