
初級から中級まで:配列と文字列(III)

はじめに
ここで提示されるコンテンツは、教育目的のみに使用されることを意図しています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを利用することは避けてください。
前回の「初級から中級まで:配列と文字列(II)」では、それまでに紹介した知識をどのように実際に応用できるかを、非常にわかりやすく解説しました。目的は、多くの人がより高度な知識を必要とすると考えがちな2種類のシンプルなソリューションを、実際には誰でも作成可能であることを示すことでした。もちろん、少しの創造力と、これまで紹介してきた概念をしっかりと活用すればの話です。
あの記事で紹介した方法は機能し、比較的簡単に実装できますが、初心者がつまずきやすい落とし穴もあります。そしてそれは、まさにその記事で取り上げたアプリケーションに直結している要素です。
読者の中には、一見すると単純な2つのテキストやフレーズからどうしてパスワードを生成できるのか疑問に感じた方もいるかもしれません。アイデアもコードも理解はできたものの、それが本当に機能する理由には納得がいかなかった、という声もあるでしょう。実際のところ、プログラミングには、プログラマーでない人にとっては理解しづらい側面が存在します。その1つの例が、まさに前回の記事でおこなった、非常に基本的な数学を使ったテキストの操作です。
このような概念はさまざまなプログラミング作業で広く使われているため、「なぜ機能するのか」をより詳しく説明する価値があります。それにより、単なるユーザーではなく、プログラマーのように考える力を身につける助けとなるでしょう。その結果として、今回の主題である配列の話は多少先延ばしになるかもしれませんが、ここでも簡単に配列については触れていきます。それでは、まずは前回紹介した内容がなぜ実際に機能するのかを理解するために、最初のトピックから始めましょう。
値の変換
プログラミングにおける最も一般的なタスクの一つは、情報やデータベースの変換と処理です。プログラミングとは、本質的にこの作業のことを指します。プログラミングを学ぼうとしているにもかかわらず、アプリケーションの目的が「コンピューターが解釈できるデータを作成し、それを人間が理解できる情報へと変換すること」であるという点を理解していないのなら、その方向は間違っています。一度立ち止まって、最初から学び直した方がよいでしょう。なぜなら、実のところ、プログラミングはこの単純な原則の上に完全に成り立っているからです。まず、コンピューターが理解できるように情報を整える必要があり、その後、コンピューターが出力した結果を私たち人間が理解できる形に変換する必要があります。
コンピューターは1と0の処理において非常に優れていますが、それ以外の情報の処理には全く向いていません。同様に、人間は1と0の羅列を解釈するのが苦手ですが、言葉やグラフの意味は直感的に理解できます。
ここで、いくつかの概念についてもう少し噛み砕いて説明しましょう。コンピューターの黎明期、最初期のプロセッサにはOpCodeセットと呼ばれる命令群があり、10進数の値を扱うための命令が含まれていました。そう、初期のプロセッサは「8」や「5」が何を意味するかを理解していたのです。これらの命令はBCD (Binary-Coded Decimal)セットに属しており、バイナリロジックを使って、人間にとって意味のある形で数値を処理できるように設計されていました。
しかし時が経つにつれて、BCD命令は使われなくなっていきました。なぜなら、10進数計算が可能な回路を設計するのは非常に複雑であり、それよりも2進数で計算をおこなってから結果を10進数に変換する方がはるかに合理的だったからです。その結果、こうした「変換」の役割はプログラマーに委ねられることとなりました。
当時、浮動小数点数の扱いは混沌としており、まさに「フルーツサラダ」状態でした。しかしそれについてはまた別の機会に扱うことにしましょう。今の段階で紹介してきたツールや概念だけでは、浮動小数点の仕組みをまだ十分に説明できないからです。その前に、いくつか重要な概念をさらに解説する必要があります。
ここで一つ注記しておきます。BCD方式は、当初のような形ではないにせよ、現在でも利用されています。今後の記事で、このBCDに関連した内容を取り上げる予定です。
さて、本題に戻りましょう。このような背景から、10進数と2進数を相互に変換する最初の変換ライブラリが登場しました。やがて、16進数や8進数といった、特定の用途で一般的に使われる他の基数もサポートされるようになりました。
この流れは、以前の記事でも紹介した内容とつながっています。MQL5には、こうした数値変換を可能にする関数が用意されています。どのケースでも、変換は文字列を基におこなわれます。つまり、入力や出力は人間にとって読みやすい形の文字列であり、その裏で実際のバイナリデータがコンピューターに送られて処理されているというわけです。ただし、これらのライブラリは非常に便利でよく機能しますが、データを直接操作するための基本的な知識の多くを抽象化してしまっています。そのため、一部のプログラミング講座では、実際には「本当の意味でのプログラマー」ではなく、仕組みを理解しないままコードを書けるだけの人材を育ててしまっているケースもあります。
幸い、MQL5ではある程度の創造的な自由が認められており、こうしたライブラリのような機能を自作することも可能です(もちろん教育目的に限ります)。ただし、低レベル言語を使わずに作成されたライブラリは、標準ライブラリよりも高速でも効率的でもないという点には注意が必要です。ここでいう低レベル言語とは、CまたはC++のことです。これらの言語は、純粋なアセンブリコードに非常に近い形で出力を生成できるため、これより速い手段は存在しません。したがって、ここで扱う内容はあくまでも教育を目的としたものになります。
では、基本的な説明を終えたところで、簡単な変換ツールを作ってみましょう。これまでに学んだ知識があれば、それほど難しい作業ではありません。今回のツールでは、まずバイナリ値を16進数または8進数に変換します。これらの変換は比較的簡単で、必要な演算も少ないためです。ということで、以下のコードを出発点として使います。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
コード01
コードスニペット01を実行すると、端末には図01に示された出力が表示されます。ここで使用されているフォーマット指定子に注目してください。異なる指定子を使えば、出力も異なるものになります。後でぜひ試してみて、この種のフォーマット指定がどのように機能するのかを理解してみてください。
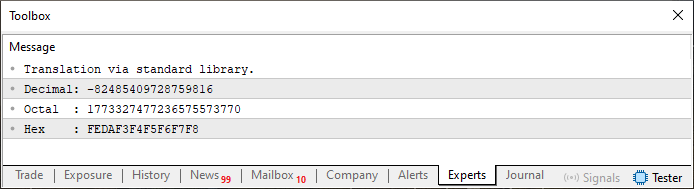
図01
ご覧のとおり、これは非常にシンプルで、実用的かつ直感的です。しかし、標準ライブラリはどうやってこれを実現しているのでしょうか。そう、それがこれから一緒に探っていく「魔法」です、読者の皆さん。とはいえ、その前にもうひとつ重要な概念を理解する必要があります。それは、「表示される情報のフォーマット」です。実は、この出力の背後には明確なフォーマットが存在しているのです。ここでは話をシンプルに保つために、まずある表をインターネットで調べてみてください。その表は非常に一般的なもので、「ASCII表」と呼ばれています。分かりやすくするために、この記事ではその簡易版を図02として示しています。より詳細なバージョンもありますが、ここで扱う内容にはこの程度で十分です。
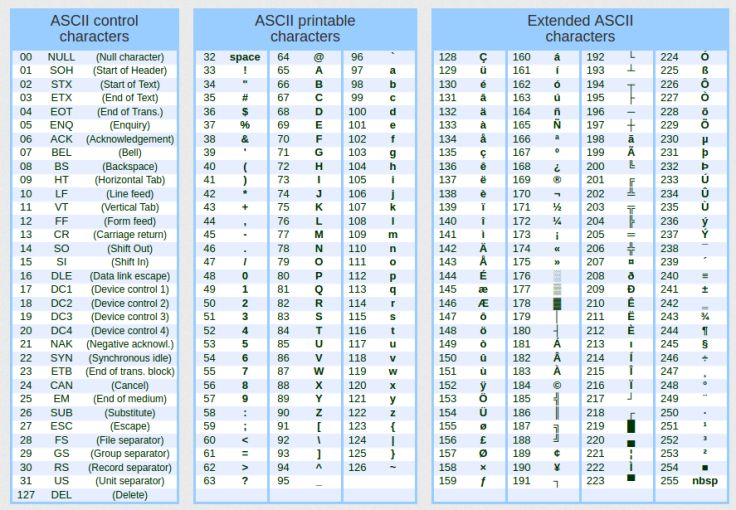
図02
私たちが注目すべきなのは、図02の中央にある「印刷可能な文字」のセクションです。図の左側にあるのは制御文字や特殊文字で、右側の領域は表のバージョンによって異なることがあります。中には、アプリケーションによって独自に定義されている場合もあります。ただし、MQL5ではそういったカスタマイズはできません。なぜなら、そうするにはハードウェアの特定領域にアクセスする必要があり、MQL5を含む多くの高水準言語ではそのようなアクセスが制限されているためです。この種のカスタマイズは通常、CやC++などの低水準言語でのみ可能です。ここでこの点を説明したのは、ASCII表の右側の記号は実装によって変わる可能性があるということを知っておいていただきたいからです。
さて、ではなぜASCII表がMQL5においてこれほど重要なのでしょうか。実のところ、ASCII表はMQL5だけでなく、「データを扱いたいすべての人」にとって必須のツールです。もちろん、UTF-8やUTF-16、ISO 8859といった他の文字コード体系も存在しており、それぞれ異なる用途や記号体系を持っています。しかし、MQL5では、特殊な場面を除いて基本的にASCII表に依存しています。そういった例外については、また別の機会に詳しく説明します。
それでは、情報を変換するということについて、ひとつ重要なポイントを押さえておきましょう。再び図02に注目してください。バイナリ値を16進数に変換するには、数字の「0」から「9」と、アルファベットの「A」から「F」までの文字が必要になります。
ASCII表を見ると、「0」は10進数で48に対応しています。そこから、1文字進むごとに1ずつ加算されていきます。たとえば「6」であれば、48から数えて6つ目、つまり「54」になります。おわかりでしょうか。これはアルファベットでも同様です。大文字の「A」はASCII値65です。これを基準として、「B」は66、「C」は67…と続いていきます。ちなみに、16進数では「A」は10、「B」は11…と続き、「F」は15に相当します。
要点はとてもシンプルです。ただし注意点は、「9」と「A」の間にはASCII表上にいくつかの記号(コロンやセミコロンなど)が存在しており、これらはスキップする必要があるということです。そうしないと、16進数としての文字列に意図しない記号が混ざってしまう可能性があるのです。これは、ASCIIコードを直接数値で扱う場合によくある落とし穴です。とはいえ、今回はこの問題に対して少し違ったアプローチをとることにします。なぜなら、目的は「前回の記事で紹介したコードがなぜ機能するのか」を説明することだからです。
ということで、それを理解するために、新たなコードを見ていきましょう。すぐ下にあります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
コード02
コードスニペット02を実行すると、端末には次のように出力されます。
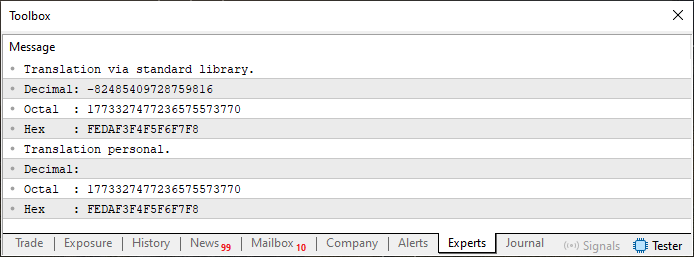
図03
このコードの大部分は、以前の記事の内容を追って学んできた読者にとっては十分理解しやすいものとなっています。したがって、ここでは37行目と41行目で起こっている処理にだけ注目します。これらの行では、特定のビットを取り出すためにAND演算子が使われています。難しそうに見えるかもしれませんが、実際は非常にシンプルです。
まずは37行目に集中して見てみましょう。8進数は0から7までの数字のみを使用します。そして、2進数での7は「111」で表されます。つまり、任意の値に対してビット単位のAND演算を行えば、必ず0から7の範囲内の数値が得られます。同じ理屈が41行目にも当てはまりますが、こちらでは結果が0から15までの範囲になります。
次に26行目を見てください。この行では出力に使われる文字の一覧が定義されています。MQL5における文字列は、特別な形式の配列として扱われます。そのため、37行目や41行目のように文字列にアクセスするとき、実際にはその配列から特定の1文字だけを取り出していることになります。このとき、文字列は通常の文字列としてではなく、配列として参照されています。
インデックスの仕様上、要素のカウントは常に0から始まります。ただし、この0は文字列のサイズを表すのではなく、最初の文字そのものを示します。文字列が空であれば長さは0、何らかの内容があれば長さは1以上となりますが、どんな場合でもインデックスは0から始まる点に注意が必要です。
最初はこの仕組みが直感に反し、分かりにくく感じられるかもしれません。しかし、配列の扱いに慣れてくると、このような考え方は自然と身についていくでしょう。
とはいえ、コードスニペット02にはまだ1つ不足している要素があります。それは10進数への対応です。これを正しく処理するためには、まだ説明していない機能、特にその使い方を理解する必要があります。ただし、きちんとした説明をしないままにしておくのは避けたいので、ここではひとまず単純な仮定を置くことにしましょう。すぐにすべてを完璧にしようとしてコードを複雑化するのは本末転倒です。現在の実装でも、未説明の機能が足りていないとはいえ、最大64ビット幅の整数値であれば、ほぼ正確に変換することが可能です。テンプレートの作成やtypenameの使用といった後のトピックを学べば、より柔軟な変換も実現できるようになります。それまでは、シンプルな部分に焦点を当てて進めましょう。
ここで気をつけたいのが、6行目で使用されている型が符号付き整数であるという点です。本来であれば、値が負であるかどうかを確認する処理が必要になります。しかし、ここでは話をシンプルに保つため、すべての値は符号なしであると仮定しましょう。つまり、負の値は扱わない前提で進めるということです。この仮定のもとでコードを少し改修し、数値が正しく表示されるかどうかを確認してみましょう。そのための実装がこの下に示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
コード03
おまけとして、コードスニペット03では、値を2進数表現に変換する処理も追加しました。これは前回までと同様に非常に簡単です。いずれにせよ、実行するとコード03の出力は以下のようになります。
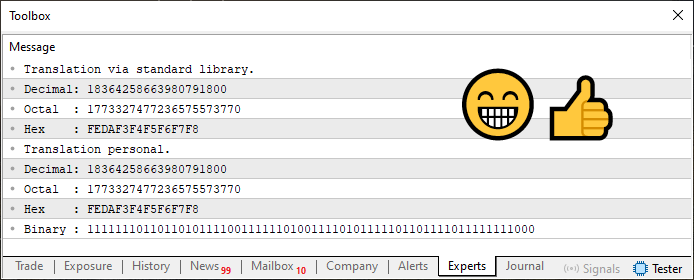
図04
さて、読者の皆さん、ここで起きていることに細心の注意を払ってください。この記事全体で議論・実証された中で、最も重要なポイントかもしれません。コード03とコード02の差はほとんどありませんが、図03と図04を比較すると違いに気づくでしょう。
その違いは、標準ライブラリを使った変換結果の値にあります。特にDECIMALの値をよく見てください。異なっているのがわかるはずです。しかし、6行目はコード03もコード04も同じなので、これは納得できません。では、なぜ予想外の値が表示されたのか、その原因はどこにあるのでしょう。
その答えは、まさに9行目にあります。コード03とコード04の9行目を注意深く比較してください。そのわずかな違いだけで、6行目で宣言した型によれば本来は負の値であるべきものが正の値に反転してしまいます。この問題の解決法は存在しますが、前述の通りまだ説明していない概念が必要です。
それまでは、端末に値を出力するときは細心の注意を払いましょう。小さな見落としが計算結果の誤解を招く恐れがあります。だからこそ、解説内容をしっかり学び、実際に手を動かして理解を深めることが大切です。単にドキュメントや記事を読むだけでは、熟練プログラマーにはなれません。示されているすべての内容を積極的に練習し、身につけてください。
とはいえ、この小さな違いがあっても、値を10進数表現に変換する処理自体は正確です。変換に使う計算も非常にシンプルです。35行目で剰余演算子「%」を使い、10で割った余りを取得してszCharsの該当文字を選びます。36行目ではargを10で割って更新し、次のステップで使います。これがバイナリ値を人間に読みやすい形に変換する方法です。
この説明を踏まえれば、前回の記事で示したコード例もより理解しやすくなるはずです。ただし、さらなる改善も可能です。そのために、前回の記事の最後に示したコードスニペット、より配列を直接的に扱うコードを使いましょう。正しく進めるために、新しいトピックから始めます。
パスワードの長さの設定
コード06(前回の記事で示した)の修正可能な点について議論を始めるには、まずそのコードをここで確認する必要があります。以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
コード04
さて、次の事実から始めましょう。使用できる配列には、静的配列と動的配列の2種類があります。配列が静的か動的かを決定するのは、その宣言方法であり、宣言でstaticキーワードを使うかどうかとは関係ありません。このトピックは一度にすべて説明するのは少し複雑なので、コード04を理解できるように簡単に要約します。
動的配列は15行目に示すように宣言されています。変数名(この場合はpsw)の後に中身のない角括弧[]が続いているのが特徴です。これは動的配列であり、実行時にサイズを定義できるという意味です。実際、割り当てられていない動的配列の要素にアクセスしようとするとエラーとなり、コードは即座に終了します。だからこそ、18行目で配列にデータを格納するのに十分なメモリを割り当てる処理が必要なのです。
覚えておいてください。文字列は特別な種類の配列です。そして、定数として宣言されていない限り、文字列は手動でのメモリ割り当てを必要としない動的配列です。コンパイラが自動的に必要な処理を追加し、ユーザーが直接介入する必要はありません。しかしここで使っているのは文字列ではなく通常の配列なので、必要なメモリ量を明示的に指定しなければなりません。ここに小さいながら重要なポイントがあります。
コード04の18行目の実行時に、生成するパスワードの長さを指定することで、非常に効果的に制御できます。同時に、生成されるパスワードをより適切に管理できるようになります。そのため、コード04にいくつか小さな変更を加える必要があります。これらの変更は以下で確認できます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
コード05
さて、次の事実に注目してください。コード05の8行目では、11行目の関数に新しい引数を渡しています。この同じ引数は18行目でパスワードの文字数を決定するために使われており、今回は8文字です。ただし、コード05を実行しようとすると失敗します。その原因は22行目にあります。6行目で8文字を超える秘密のフレーズを定義しているためです。19行目のループは6行目で宣言された文字列szArg内のNULL文字が見つかるまで続くので、最終的に22行目で無効なメモリにアクセスしようとしてしまいます。これはエラーであり、プログラムはクラッシュします。
しかし、これは本当の問題ではありません。必要なのは、必要な8文字のパスワードを完成させるために6行目のフレーズ全体を使うか、一部だけを使うかを決めることです。この判断によって、最終コードの挙動が多少変わってきます。だからこそプログラミングを学ぶことが重要なのです。あるプログラマーが提案した解決策があなたにとって最適とは限りませんが、コミュニケーションを通じて相互理解を得ることができます。コーディングができれば、他人の決定に依存せず、自分のケースに合った最良の方法を選べるのです。
では、次のように決めましょう。秘密のフレーズ全体を使いますが、同時に13行目の文字列を前回の記事で示した別のものに変更します。これにより、より興味深い内容になります。
ただし、実際にコードを書く前に、前節で示した図02に戻り、6行目で宣言された文字列に対応する表内の各値をよく見てください。このデータについて何か気づいたでしょうか。重要なのは、6行目のフレーズ全体を使う場合、別の工夫が必要になるということです。下記のコードのように変更すると、いくつか問題が起きるからです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
コード06
実際に使用しているのはフレーズ全体ではなく、その一部だけです。正確には、6行目に定義された秘密のフレーズの最後の8文字だけを使用しています。これはコード06を実行し、その結果を、同じフレーズが使用されていた前回の記事の結果と比較することで確認できます。
ただし、コード06を実行しなくても、内容を分析するだけで、たとえ23行目でコードが失敗することがなくなったとしても、その影響はほとんどないことが分かります。というのも、24行目で、常にパスワードの値が「パスワードの制限」として定義された位置に上書きされるようになっているためです。その結果、6行目のフレーズにはたくさんの文字が含まれているにもかかわらず、実際には8文字しか存在していないかのように扱われてしまいます。これでは、秘密のフレーズを作成する際に誤った安心感を持ってしまう恐れがあります。
さて、図02を見れば分かるように、各シンボルはそれぞれ特定の値によって定義されています。したがって、この配列を使ってそれらの値の合計を計算することができます。そうすることで、すべてのシンボルを効果的に活用することが可能になります。しかしここで、読者の皆さんにぜひ注目していただきたい重要な点があります。それは、配列に格納できる最大の値は、その配列に使われている型によって決まるということです。この点については、次回の記事でさらに詳しく説明します。今のところは、以下のようにコードをいくつか調整することで、もう少し改善を加えることができます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
コード07
ついに、秘密のフレーズを完全に活用する形に到達しました。ここで注目してほしいのは、コードには最小限の変更しか加えていないという点です。変更点の一つとして、20行目では配列を特定の値、今回は0で初期化するよう指定しています。もちろん、好みに応じて別の初期値を設定することも可能です。初期値を変えることで、特に秘密のフレーズに重複する文字が含まれている場合、後々影響が出てきます。
同じシンボルが異なる位置において同じ値を持たないようにするための手法はいくつか存在しますが、それについては次回の記事で詳しく取り上げます。とはいえ、今回の核心となるポイントは24行目にあります。ここでは値を加算する処理を行っています。つまり、両方のフレーズを完全に活用していることになるのです。しかし、ひとつ問題があります。これについては、実際にコードを実行してみるとすぐに明らかになるでしょう。
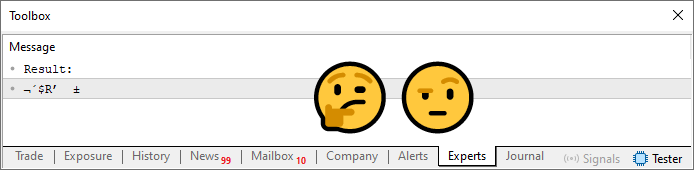
図05
では、このパスワードをどうやって使えばいいのでしょうか。簡単ではありません。ここで起きているのは、配列内に格納された値が合計によって計算されたものであるにもかかわらず、それらの値に制限があるということです。つまり、これらの計算された値が、13行目で宣言された文字列の中のいずれかの文字に正しく対応している必要があります。そのためには、もうひとつループを追加する必要があります。最終的なコードは以下のとおりです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
コード08
ここで、コード08の28行目にあるループを通過した後、以下の図に示すような結果が得られます。
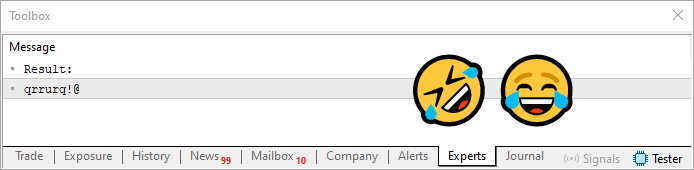
図06
これはもう、まさに「幸運な偶然」と言えるでしょう。ちょうどパスワードに同じ文字が繰り返し含まれる可能性について話していて、それにどう対応するかを考えていたところでした。そしてなんと、出力結果には見事に文字の重複が現れました。本当に運がいいですね(笑)。
最終的な結論
今回の記事では、バイナリ値が他の形式へとどのように変換されるのか、その一端を探りました。また、文字列を配列のように扱うという考え方についても、最初の一歩を踏み出しました。加えて、配列を扱う際によくあるエラーをどう回避するかについても学びました。とはいえ、今回の内容は「幸運な偶然」で締めくくられることになりました。この件については、次回の記事でより詳しく掘り下げていきます。あわせて、今後同じような状況が発生しないようにするにはどうすればよいかも検討していきます。さらに、配列内でのデータ型の扱いについても理解を深めていく予定です。それでは、また次回お会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15461
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索