
ウィリアム・ギャンの手法(第3回):占星術は効果があるのか

はじめに
金融市場の参加者は、市場分析と予測の新たな手法を常に模索しています。最も驚くべきコンセプトも例外ではありません。非標準的で完全にユニークなアプローチの1つは、有名なトレーダーのウィリアム・ギャンによって普及された、取引における占星術の使用です。
ギャンのツールについてはこれまでの記事ですでに触れました。第1回と第2回はこちらです。今回は、惑星と恒星の位置が世界市場に与える影響に焦点を当てます。
最新のテクノロジーと古代の知識を融合させてみましょう。Pythonプログラミング言語とMetaTrader 5プラットフォームを使用して、天文現象とEURUSDペアの動きの関係を調べます。金融における占星術の理論的な部分をカバーし、予測システムの開発の実践的な部分に挑戦します。
さらに、天文データと金融データの収集と同期、相関行列の作成、結果の視覚化についても検討します。
金融における占星術の理論的基礎
私は長い間このテーマに興味を持っており、今日は占星術が金融市場に与える影響についての私の考えを共有したいと思います。これはかなり物議を醸しているものの、本当に興味深い分野です。
私が理解する限り、金融占星術の基本的な考え方は、天体の動きが何らかの形で市場サイクルに関連しているというものです。この概念には長く豊かな歴史があり、20世紀の著名なトレーダー、ウィリアム・ギャンによって広められました。
私はこの理論の基本原理についてよく考えました。たとえば、市場の動向と同じく、星や惑星の動きも周期的であるという考え方。惑星の配置に関しては、特定の惑星の位置が市場に強い影響を与えると考える人もいます。星座はどうでしょうか。惑星がさまざまな星座を通過することも、市場に何らかの影響を与えると考えられています。
月の周期と太陽の活動についても言及する価値があります。月の満ち欠けは市場の短期的な変動と関連しているが、太陽フレアは長期的な傾向と関連しているという意見を見たことがあります。興味深い仮説ですね。
ウィリアム・ギャンはこの分野の真の先駆者でした。彼は、天文学、幾何学、数列に基づいて、有名な9の平方数などの数多くのツールを開発しました。彼の作品は今でも熱い議論を巻き起こしています。
もちろん、科学界の大半は占星術に懐疑的であることを無視できません。多くの国では、それは疑似科学として公式に認められています。率直に言えば、金融における占星術的手法の有効性を示す厳密な証拠はまだありません。多くの場合、観察された特定の相関関係は、単に認知バイアスの結果であることが判明します。
それにもかかわらず、金融占星術の考え方を熱心に擁護するトレーダーは多くいます。
だからこそ、私は自分で調査してみることにしました。私は統計的手法とビッグデータを用いて、占星術が金融市場に与える影響を客観的に評価してみたいと思います。もしかしたら、何か面白いものが発見できるかもしれません。いずれにせよ、星と株価チャートが交差する世界への魅力的な旅となるでしょう。
適用されたPythonライブラリの概要
Pythonライブラリのフルセットが必要になります。
まず、天文データを取得するためにSkyfieldパッケージを使用することにしました。適切なツールを選ぶのに長い時間を費やしましたが、Skyfieldの精度には感心しました。これを使えば、天体の位置や月の満ち欠けに関する情報を小数点以下の非常に高い精度で収集できるようになります。これは私のデータセットに必要なすべての要素です。
市場データに関しては、Python用の公式MetaTrader 5ライブラリを選択しました。必要に応じて、通貨ペアの履歴データやオープントレードをダウンロードできるようになります。
Pandasは、データを扱う際の忠実な仲間となるでしょう。私は過去にこのライブラリを何度も使用しており、時系列を扱うには欠かせないものとなっています。収集したすべてのデータの前処理と同期に使用します。
統計分析には、SciPyライブラリを使用することにしました。その幅広い機能は印象的で、特に相関分析と回帰分析のツールが優れています。興味深いパターンを見つけるのに役立つことを願っています。
結果を視覚化するために、使い慣れたMatplotlibとSeabornを活用します。これらのライブラリはグラフ作成の柔軟性が高いので気に入っています。これらはすべての調査結果を視覚化するのに役立つと確信しています。
セット全体が組み立てられました。それは、優れたコンポーネントから強力なPCを組み立てるようなものです。占星術的要素が金融市場に与える影響について包括的な研究をおこなうために必要なものはすべて揃いました。データに飛び込んで仮説をテストするのが待ちきれません。
天文データの収集
import pandas as pd import numpy as np from skyfield.api import load, wgs84, utc from skyfield.data import mpc from datetime import datetime, timedelta import requests # Loading planet ephemerides planets = load('de421.bsp') earth = planets['earth'] ts = load.timescale() def get_planet_positions(date): t = ts.from_datetime(date.replace(tzinfo=utc)) planet_positions = {} planet_ids = { 'mercury': 'MERCURY BARYCENTER', 'venus': 'VENUS BARYCENTER', 'mars': 'MARS BARYCENTER', 'jupiter': 'JUPITER BARYCENTER', 'saturn': 'SATURN BARYCENTER', 'uranus': 'URANUS BARYCENTER', 'neptune': 'NEPTUNE BARYCENTER' } for planet, planet_id in planet_ids.items(): planet_obj = planets[planet_id] astrometric = earth.at(t).observe(planet_obj) ra, dec, _ = astrometric.radec() planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees} return planet_positions def get_moon_phase(date): t = ts.from_datetime(date.replace(tzinfo=utc)) eph = load('de421.bsp') moon, sun, earth = eph['moon'], eph['sun'], eph['earth'] e = earth.at(t) _, m, _ = e.observe(moon).apparent().ecliptic_latlon() _, s, _ = e.observe(sun).apparent().ecliptic_latlon() phase = (m.degrees - s.degrees) % 360 return phase def get_solar_activity(date): # Get solar activity data from NOAA API url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json" response = requests.get(url) data = response.json() # Convert date to 'YYYY-MM' format target_date = date.strftime("%Y-%m") # Find the closest date in the data closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m"))) return { 'sunspot_number': closest_data.get('ssn', None), 'f10.7_flux': closest_data.get('f10.7', None) } def calculate_aspects(positions): aspects = {} planets = list(positions.keys()) for i in range(len(planets)): for j in range(i+1, len(planets)): planet1 = planets[i] planet2 = planets[j] ra1 = positions[planet1]['ra'] ra2 = positions[planet2]['ra'] angle = abs(ra1 - ra2) % 24 angle = min(angle, 24 - angle) * 15 # Convert to degrees if abs(angle - 0) <= 10 or abs(angle - 180) <= 10: aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition" elif abs(angle - 90) <= 10: aspects[f"{planet1}_{planet2}"] = "square" elif abs(angle - 120) <= 10: aspects[f"{planet1}_{planet2}"] = "trine" return aspects start_date = datetime(2024, 4, 1, tzinfo=utc) end_date = datetime(2024, 5, 31, tzinfo=utc) current_date = start_date astronomical_data = [] while current_date <= end_date: planet_positions = get_planet_positions(current_date) moon_phase = get_moon_phase(current_date) try: solar_activity = get_solar_activity(current_date) except Exception as e: print(f"Error getting solar activity for {current_date}: {e}") solar_activity = {'sunspot_number': None, 'f10.7_flux': None} aspects = calculate_aspects(planet_positions) data = { 'date': current_date, 'moon_phase': moon_phase, 'sunspot_number': solar_activity.get('sunspot_number'), 'f10.7_flux': solar_activity.get('f10.7_flux'), **planet_positions, **aspects } astronomical_data.append(data) current_date += timedelta(days=1) print(f"Processed: {current_date}") # Convert data to DataFrame df = pd.DataFrame(astronomical_data) # Save data to CSV file df.to_csv('astronomical_data_2018_2024.csv', index=False) print("Data saved to astronomical_data_2018_2024.csv")
このPythonコードは、市場分析のための天文学データを収集し、将来的な活用に備えます。
このコードは、2018年1月1日から2024年5月31日までの期間を用いて、次のようなさまざまなデータを収集します。
- 惑星の位置(金星、水星、火星、木星、土星、天王星、海王星)
- 月の満ち欠け
- 太陽活動
- 惑星の配置(惑星同士の関係)
スクリプトには、ライブラリのインポート、メインループ、およびExcel形式でのデータの保存が含まれています。このコードでは、前述のSkyfieldライブラリを使用して惑星の位置を計算し、データにはPandasを使用し、太陽活動データを取得するためのリクエストを使用します。
注目すべき関数としては、惑星の位置(赤経と赤緯)を取得するためのget_planet_positions()、現在の月の満ち欠けを調べるためのget_moon_phase()、NOAAAPIから太陽活動データを直接配信するためのget_solar_activity()、アスペクト(惑星同士の位置関係)を計算するためのcalculate_aspects()などがあります。
私たちはサイクルの一部として毎日を振り返り、すべてのデータを収集します。その結果、将来使用するためにすべてを1つのExcelファイルに保存します。
MetaTrader 5経由で金融データを取得する
金融データを取得するには、Python用のMetaTrader 5ライブラリを使用します。このライブラリを使用すると、ブローカーから金融データを直接ダウンロードし、あらゆる金融商品の価格の時系列を受け取ることができます。履歴データを読み込むためのコードは次のとおりです。
import MetaTrader5 as mt5
import pandas as pd
from datetime import datetime
# Connect to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set query parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2018, 1, 1)
end_date = datetime(2024, 12, 31)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
# Save data to CSV file
df.to_csv(f'{symbol}_data.csv', index=False)
# Terminate the connection to MetaTrader5
mt5.shutdown()
スクリプトはMetaTrader 5の取引端末に接続し、EURUSDD1のデータを受信し、データフレームを作成して単一のCSVファイルに保存します。
天文データと金融データの同期
天文学に関するデータがあり、EURUSDに関するデータもあります。次に、それらを同期する必要があります。データを日付ごとに結合して、財務情報と天文学情報の両方を含む必要な情報がすべて1つのデータセットに含まれるようにします。
import pandas as pd
# Load data
astro_data = pd.read_csv('astronomical_data_2018_2024.csv')
financial_data = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_data['date'] = pd.to_datetime(astro_data['date'])
financial_data['time'] = pd.to_datetime(financial_data['time'])
# Merge data
merged_data = pd.merge(financial_data, astro_data, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
スクリプトは保存されたデータを読み込み、日付列を日時形式にフォーマットし、データセットを日付ごとに結合します。その結果、将来の分析に必要なすべてのデータを含むCSVファイルが得られます。
相関関係の統計分析
次へ移りましょう。共通のセット、共通のデータセットがあり、天文学と市場の動きの間にデータに何らかの関係があるかどうかを調べるときが来ました。pandasライブラリのcorr()関数を使用します。さらに、両方のコードを1つに結合します。
最終的なスクリプトは次のとおりです。
import pandas as pd
import numpy as np
from skyfield.api import load, wgs84, utc
from skyfield.data import mpc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
# Part 1: Collecting astronomical data
# Loading planetary ephemerides
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Collecting astronomical data
start_date = datetime(2024, 3, 1, tzinfo=utc)
end_date = datetime(2024, 7, 30, tzinfo=utc)
current_date = start_date
astronomical_data = []
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
data = {
'date': current_date,
'moon_phase': moon_phase,
'sunspot_number': solar_activity.get('sunspot_number'),
'f10.7_flux': solar_activity.get('f10.7_flux'),
**planet_positions,
**aspects
}
astronomical_data.append(data)
current_date += timedelta(days=1)
print(f"Processed: {current_date}")
# Convert data to DataFrame and save
astro_df = pd.DataFrame(astronomical_data)
astro_df.to_csv('astronomical_data_2018_2024.csv', index=False)
print("Astronomical data saved to astronomical_data_2018_2024.csv")
# Part 2: Retrieving financial data via MetaTrader5
# Initialize connection to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set request parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2024, 3, 1)
end_date = datetime(2024, 7, 30)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
# Save financial data
financial_df.to_csv(f'{symbol}_data.csv', index=False)
print(f"Financial data saved to {symbol}_data.csv")
# Shutdown MetaTrader5 connection
mt5.shutdown()
# Part 3: Synchronizing astronomical and financial data
# Load data
astro_df = pd.read_csv('astronomical_data_2018_2024.csv')
financial_df = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
# Merge data
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
print("Merged data saved to merged_astro_financial_data.csv")
# Part 4: Statistical analysis of correlations
# Select numeric columns for correlation analysis
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Create lags for astronomical data
for col in numeric_columns:
if col not in ['open', 'high', 'low', 'close', 'tick_volume', 'spread', 'real_volume']:
for lag in range(1, 6): # Create lags from 1 to 5
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Update list of numeric columns
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Calculate correlation matrix
correlation_matrix = merged_data[numeric_columns].corr()
# Create heatmap of correlations
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0)
plt.title('Correlation Matrix of Astronomical Factors (with Lags) and EURUSD Prices')
plt.tight_layout()
plt.savefig('correlation_heatmap_with_lags.png')
plt.close()
# Output the most significant correlations with the closing price
significant_correlations = correlation_matrix['close'].sort_values(key=abs, ascending=False)
print("Most significant correlations with the closing price:")
print(significant_correlations)
# Create a separate correlation matrix for astronomical data with lags and the current price
astro_columns = [col for col in numeric_columns if col not in ['open', 'high', 'low', 'tick_volume', 'spread', 'real_volume']]
astro_columns.append('close') # Add the current closing price
astro_correlation_matrix = merged_data[astro_columns].corr()
# Create heatmap of correlations for astronomical data with lags and the current price
import seaborn as sns
import matplotlib.pyplot as plt
# Increase the header and axis label font
plt.figure(figsize=(18, 14))
sns.heatmap(astro_correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0, cbar_kws={'label': 'Correlation'})
plt.title('Correlation matrix of astronomical factors (with lags) and current EURUSD price', fontsize=24)
plt.xlabel('X-axis Label', fontsize=30)
plt.ylabel('Y-axis Label', fontsize=30)
plt.xticks(fontsize=30)
plt.yticks(fontsize=30)
plt.tight_layout()
plt.savefig('astro_correlation_heatmap_with_lags.png')
plt.close()
print("Analysis completed. Results saved in CSV and PNG files.")
このスクリプトは、データセット内のすべての数値間の相関関係のマップと、ヒートマップ形式でのすべての相関関係の行列を表示し、終値との最も重要な相関関係のリストを生成します。
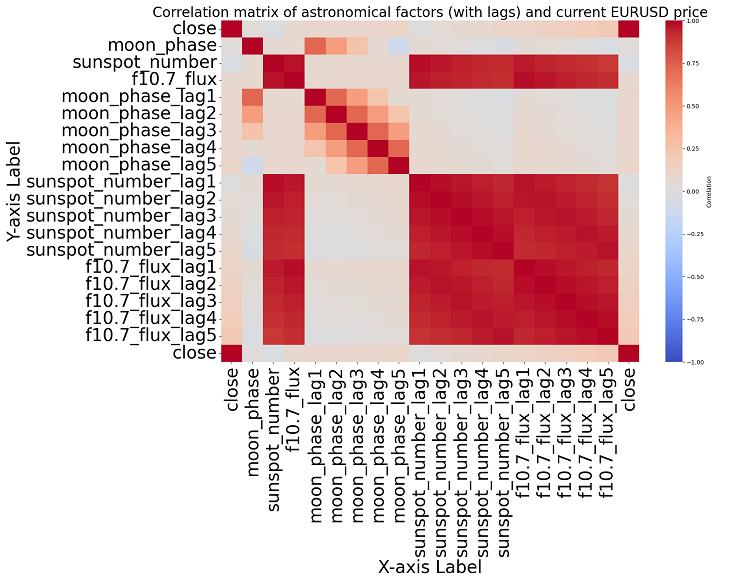
相関関係の有無は因果関係の有無を意味するものではありません。たとえ天文学的データと価格変動の間に強い相関関係が見つかったとしても、これは、一方の要因が他方を決定することを意味しませんし、その逆もまた同じです。相関マップは最も基本的なものに過ぎないので、新たな研究が必要です。
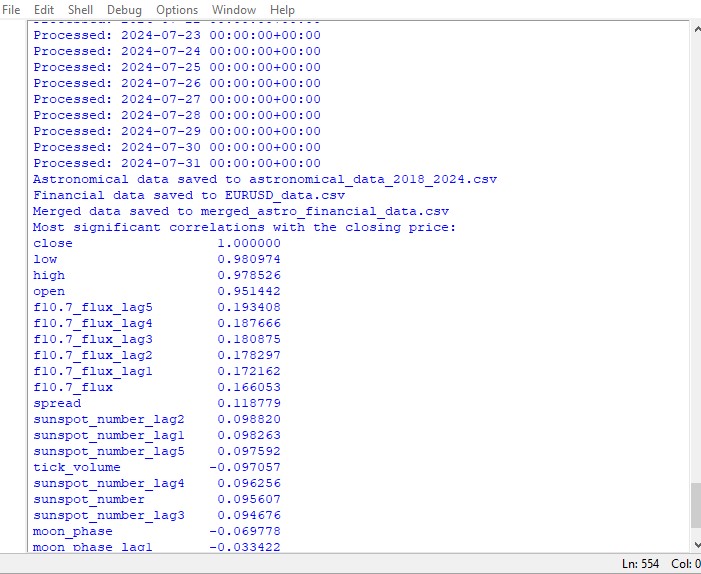
トピックに近づくと、データ内に有意な相関関係は見つかりません。過去の天文学データと市場指標の間には明確な相関関係はありません。
機械学習が救世主
次に何をすべきかを考え、機械学習モデルを適用することにしました。CatBoostライブラリを使用して、データセットのデータを特徴として使用して将来の価格を予測する2つのスクリプトを作成しました。これが最初のモデル、回帰モデルです。
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# Loading data
data = pd.read_csv('merged_astro_financial_data.csv')
# Converting date to datetime
data['date'] = pd.to_datetime(data['date'])
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6): # Creating lags from 1 to 5
data[f'{col}_lag{lag}'] = data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
data[f'{col}_ra'] = data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
data[f'{col}_dec'] = data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6): # Lags from 1 to 5
data[f'{col}_ra_lag{lag}'] = data[f'{col}_ra'].shift(lag)
data[f'{col}_dec_lag{lag}'] = data[f'{col}_dec'].shift(lag)
data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Converting aspects to numerical features
aspect_cols = ['mercury_saturn', 'venus_mars', 'venus_jupiter', 'venus_uranus',
'mars_jupiter', 'mars_uranus', 'jupiter_uranus', 'mercury_neptune',
'venus_saturn', 'venus_neptune', 'mars_saturn', 'mercury_venus',
'mars_neptune', 'mercury_uranus', 'saturn_neptune', 'mercury_jupiter',
'mercury_mars', 'jupiter_saturn']
# Using LabelEncoder for encoding aspects
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
data[col] = label_encoders[col].fit_transform(data[col].astype(str))
# Filling missing values with mean values for numeric columns
numeric_cols = data.select_dtypes(include=[np.number]).columns
data[numeric_cols] = data[numeric_cols].fillna(data[numeric_cols].mean())
# Removing rows with missing values
data = data.dropna()
# Preparing features and target variable
features = [col for col in data.columns if col not in ['date', 'time', 'close']]
X = data[features]
y = data['close']
# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Creating and training the CatBoost model
model = CatBoostRegressor(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
# Evaluating the model
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"Mean Absolute Error: {mae}")
print(f"R-squared Score: {r2}")
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
# Selecting the last row of data
last_data = data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
# Prediction
prediction = model.predict(input_features)
print(f"Prediction for the next closing price: {prediction[0]}")
# Example of using the function to predict the next value
predict_next()

2番目のモデルは分類です。
import pandas as pd
import numpy as np
from skyfield.api import load, utc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import LabelEncoder
# Part 1: Collecting astronomical data
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Part 2: Obtaining financial data through MetaTrader5
def get_financial_data(symbol, start_date, end_date):
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
return None
timeframe = mt5.TIMEFRAME_D1
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
mt5.shutdown()
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
return financial_df
# Part 3: Synchronizing astronomical and financial data
def sync_data(astro_df, financial_df):
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
return merged_data
# Part 4: Training the model and making predictions
def train_and_predict(merged_data):
# Converting aspects to numerical features
aspect_cols = [col for col in merged_data.columns if '_' in col and col not in ['date', 'time']]
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
merged_data[col] = label_encoders[col].fit_transform(merged_data[col].astype(str))
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6):
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
merged_data[f'{col}_ra'] = merged_data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
merged_data[f'{col}_dec'] = merged_data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6):
merged_data[f'{col}_ra_lag{lag}'] = merged_data[f'{col}_ra'].shift(lag)
merged_data[f'{col}_dec_lag{lag}'] = merged_data[f'{col}_dec'].shift(lag)
merged_data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Filling missing values with mean values for numeric columns
numeric_cols = merged_data.select_dtypes(include=[np.number]).columns
merged_data[numeric_cols] = merged_data[numeric_cols].fillna(merged_data[numeric_cols].mean())
merged_data = merged_data.dropna()
# Creating binary target variable
merged_data['price_change'] = (merged_data['close'].shift(-1) > merged_data['close']).astype(int)
# Removing rows with missing values in the target variable
merged_data = merged_data.dropna(subset=['price_change'])
features = [col for col in merged_data.columns if col not in ['date', 'time', 'close', 'price_change']]
X = merged_data[features]
y = merged_data['price_change']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
model = CatBoostClassifier(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
clf_report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(clf_report)
print("Confusion Matrix:")
print(conf_matrix)
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
last_data = merged_data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
prediction = model.predict(input_features)
print(f"Price change prediction (0: will decrease, 1: will increase): {prediction[0]}")
predict_next()
# Main program
start_date = datetime(2023, 3, 1)
end_date = datetime(2024, 7, 30)
astro_data = []
current_date = start_date
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
astro_data.append({
'date': current_date,
'mercury': str(planet_positions['mercury']),
'venus': str(planet_positions['venus']),
'mars': str(planet_positions['mars']),
'jupiter': str(planet_positions['jupiter']),
'saturn': str(planet_positions['saturn']),
'uranus': str(planet_positions['uranus']),
'neptune': str(planet_positions['neptune']),
'moon_phase': moon_phase,
**solar_activity,
**aspects
})
current_date += timedelta(days=1)
astro_df = pd.DataFrame(astro_data)
symbol = "EURUSD"
financial_data = get_financial_data(symbol, start_date, end_date)
if financial_data is not None:
merged_data = sync_data(astro_df, financial_data)
train_and_predict(merged_data) 残念ながら、どちらのモデルも高い精度は提供しません。分類精度は50%をわずかに上回っており、コイントスに基づいて簡単に予測できることを意味します。
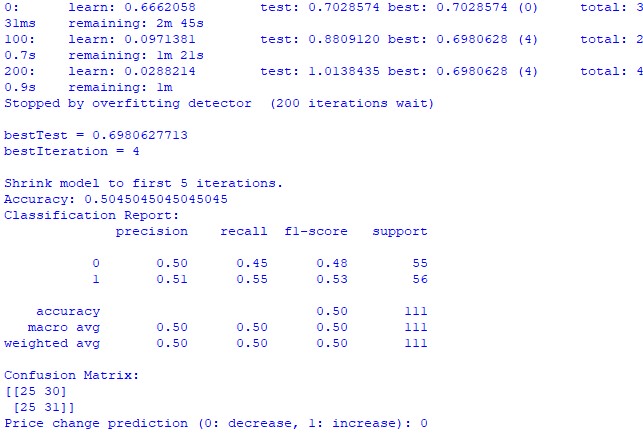
おそらく、回帰モデルはあまり考慮されておらず、実際には惑星の位置や月と太陽の活動を使用して価格を予測することが可能であるため、結果は改善される可能性があります。気が向いたら、このトピックについて別の記事を書きます。
結果
さて、結果をまとめてみましょう。簡単な分析を実施し、2つの予測モデルを作成した後、占星術が市場に及ぼす潜在的な影響に関する研究結果を確認しました。
相関分析: 私たちが得た相関マップでは、惑星の位置とEURUSDの終値の間に強い相関関係は見られませんでした。相関関係はすべて0.3より弱いため、星や惑星の位置は金融市場とまったく関係がないと考える根拠が得られます。
CatBoost回帰モデル: 回帰モデルの最終結果は、天文学的データに基づいて正確な将来の終値を予測する能力が非常に低いことを示しました。
結果として得られるモデルパフォーマンスメトリックス(MSE、MAE、R二乗など)は非常に弱く、データの説明が不十分です。同時に、モデルは、最も重要な特徴は惑星の位置ではなく、ラグと以前の価格値であることを示しています。ということは、価格が太陽系のどの惑星の位置よりも優れた指標であるということでしょうか?
CatBoost分類モデル: 分類モデルは、将来の価格の上昇または下落を予測するのに非常に不向きです。精度はかろうじて50%を超えており、これは天文学が実際の市場では機能しないことを裏付けています。
結論
研究の結果は明確です。占星術の方法や、天文学的データに基づいて実際の市場の価格を予測する試みはまったく役に立たないということです。この話題にはおそらく後で戻るでしょうが、今のところ、ウィリアム・ギャンの教えは、本や取引コースを売るためだけに作られた、機能しない解決策を隠そうとする試みのように見えます。
ギャン角度値、9の平方値、ギャングリッド値も使用した改良モデルの方がパフォーマンスが向上する可能性はあるでしょうか。それはまだ分かりません。この研究の結果は、やや期待外れでした。
しかし、私は依然として、ギャンアングルは何らかの方法で実用的な価格予測を得るために使用できると考えています。価格は何らかの形で角度に影響を与え、それに反応します。これは前回の研究の結果からも明らかです。角度を訓練モデルの作業特徴として使用することも可能です。そのようなデータセットを作成して、結果として何が出てくるかを見てみます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15625
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ガーナの足跡をたどるなら、純粋な経験のために、EURUSDではなく、例えば綿花先物を取るべきだった。そして、楽器はほぼ同じであり、天文学的なサイクルは、結局のところ、農業、その中にあることができます。