
Métodos de William Gann (Parte III): ¿Funciona la astrología?

Introducción
Los participantes del mercado financiero buscan constantemente métodos cada vez más nuevos de análisis y previsión del mercado. Ni siquiera los conceptos más increíbles quedan fuera. Uno de los enfoques no estándar y completamente únicos es el uso de la astrología en el trading, que fue popularizado por el famoso trader William Gann.
Ya hemos hablado de las herramientas de Gann en nuestros artículos anteriores. Aquí están las partes primera y segunda. Ahora nos centraremos en explorar el impacto de las posiciones planetarias y estelares en los mercados mundiales.
Intentemos combinar las tecnologías más modernas y los conocimientos antiguos. Utilizaremos el lenguaje de programación Python, así como la plataforma MetaTrader 5 para encontrar la conexión entre los fenómenos astronómicos y los movimientos del par EURUSD. Cubriremos la parte teórica de la astrología en las finanzas y nos probaremos en la parte práctica del desarrollo de un sistema de pronóstico.
Además, analizaremos cómo recopilar y sincronizar datos astronómicos y financieros, crearemos una matriz de correlación y visualizaremos los resultados.
Bases teóricas de la astrología en las finanzas
Este tema me ha interesado durante mucho tiempo y hoy quiero compartir mis pensamientos sobre la influencia de la astrología en los mercados financieros. Se trata de un área realmente fascinante, aunque bastante controvertida.
La idea básica de la astrología financiera, tal como la entiendo, es que los movimientos de los cuerpos celestes están de alguna manera relacionados con los ciclos del mercado. Este concepto tiene una larga y rica historia, y fue especialmente popularizado por William Gann, un famoso comerciante del siglo pasado.
He pensado mucho sobre los principios básicos de esta teoría. Por ejemplo, la idea del ciclismo que afirma que los movimientos de las estrellas y los planetas son de naturaleza cíclica, al igual que los movimientos del mercado. En términos de aspectos planetarios, algunos creen que ciertas posiciones planetarias tienen una fuerte influencia en los mercados. ¿Y qué pasa con los signos del zodiaco? Se cree que el paso de los planetas por las diferentes constelaciones del zodíaco también afecta de alguna manera al mercado.
También vale la pena mencionar los ciclos lunares y la actividad solar. He visto opiniones de que las fases de la luna están asociadas con fluctuaciones a corto plazo en el mercado, mientras que las erupciones solares están asociadas con tendencias a largo plazo. Son hipótesis interesantes ¿no?
William Gunn fue un verdadero pionero en este campo. Desarrolló una serie de herramientas, como su famoso cuadrado de 9, basado en la astronomía, la geometría y las secuencias numéricas. Sus obras aún hoy suscitan acalorados debates.
Por supuesto, no se puede ignorar que la comunidad científica en su conjunto es escéptica respecto de la astrología. En muchos países se reconoce oficialmente como pseudociencia. Y, francamente, todavía no hay evidencia estricta de la eficiencia de los métodos astrológicos en las finanzas. A menudo, ciertas correlaciones observadas resultan ser simplemente el resultado de sesgos cognitivos.
A pesar de ello, hay muchos traders que defienden ardientemente las ideas de la astrología financiera.
Por eso decidí hacer mi propia investigación. Me gustaría intentar dar una evaluación objetiva de la influencia de la astrología en los mercados financieros utilizando métodos estadísticos y big data. Quien sabe, quizás descubramos algo interesante. De cualquier manera, será un viaje fascinante al mundo donde las estrellas y los gráficos bursátiles se cruzan.
Descripción general de las bibliotecas de Python aplicadas
Necesitaré todo un arsenal de bibliotecas de Python.
Para empezar, decidí utilizar el paquete Skyfield para obtener datos astronómicos. Pasé mucho tiempo eligiendo la herramienta adecuada y Skyfield me impresionó con su precisión. Con su ayuda, podré recopilar información sobre las posiciones de los cuerpos celestes y las fases de la luna con una precisión muy alta en decimales: todo lo que necesito para mis conjuntos de datos.
En cuanto a los datos de mercado, mi elección recayó en la biblioteca oficial de MetaTrader 5 para Python. Permitirá descargar datos históricos sobre pares de divisas e incluso abrir operaciones si es necesario.
Los pandas se convertirán en nuestro fiel compañero en el trabajo con datos. He utilizado mucho esta biblioteca en el pasado y es simplemente indispensable para trabajar con series de tiempo. Lo utilizaré para el preprocesamiento y la sincronización de todos los datos recopilados.
Para el análisis estadístico, opté por la biblioteca SciPy. Su amplia funcionalidad es impresionante, especialmente las herramientas para el análisis de correlación y regresión. Espero que me ayuden a encontrar patrones interesantes.
Para visualizar los resultados, decidí utilizar a mis viejos amigos: Matplotlib y Seaborn. Me encantan estas bibliotecas por su flexibilidad en la creación de gráficos. Estoy seguro de que ayudarán a visualizar todos los hallazgos.
Todo el conjunto está montado. Es como montar un PC potente con componentes excelentes. Ahora tenemos todo lo que necesitamos para realizar un estudio exhaustivo de la influencia de los factores astrológicos en los mercados financieros. ¡No puedo esperar para sumergirme en los datos y comenzar a probar mis hipótesis!
Recopilación de datos astronómicos
import pandas as pd import numpy as np from skyfield.api import load, wgs84, utc from skyfield.data import mpc from datetime import datetime, timedelta import requests # Loading planet ephemerides planets = load('de421.bsp') earth = planets['earth'] ts = load.timescale() def get_planet_positions(date): t = ts.from_datetime(date.replace(tzinfo=utc)) planet_positions = {} planet_ids = { 'mercury': 'MERCURY BARYCENTER', 'venus': 'VENUS BARYCENTER', 'mars': 'MARS BARYCENTER', 'jupiter': 'JUPITER BARYCENTER', 'saturn': 'SATURN BARYCENTER', 'uranus': 'URANUS BARYCENTER', 'neptune': 'NEPTUNE BARYCENTER' } for planet, planet_id in planet_ids.items(): planet_obj = planets[planet_id] astrometric = earth.at(t).observe(planet_obj) ra, dec, _ = astrometric.radec() planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees} return planet_positions def get_moon_phase(date): t = ts.from_datetime(date.replace(tzinfo=utc)) eph = load('de421.bsp') moon, sun, earth = eph['moon'], eph['sun'], eph['earth'] e = earth.at(t) _, m, _ = e.observe(moon).apparent().ecliptic_latlon() _, s, _ = e.observe(sun).apparent().ecliptic_latlon() phase = (m.degrees - s.degrees) % 360 return phase def get_solar_activity(date): # Get solar activity data from NOAA API url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json" response = requests.get(url) data = response.json() # Convert date to 'YYYY-MM' format target_date = date.strftime("%Y-%m") # Find the closest date in the data closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m"))) return { 'sunspot_number': closest_data.get('ssn', None), 'f10.7_flux': closest_data.get('f10.7', None) } def calculate_aspects(positions): aspects = {} planets = list(positions.keys()) for i in range(len(planets)): for j in range(i+1, len(planets)): planet1 = planets[i] planet2 = planets[j] ra1 = positions[planet1]['ra'] ra2 = positions[planet2]['ra'] angle = abs(ra1 - ra2) % 24 angle = min(angle, 24 - angle) * 15 # Convert to degrees if abs(angle - 0) <= 10 or abs(angle - 180) <= 10: aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition" elif abs(angle - 90) <= 10: aspects[f"{planet1}_{planet2}"] = "square" elif abs(angle - 120) <= 10: aspects[f"{planet1}_{planet2}"] = "trine" return aspects start_date = datetime(2024, 4, 1, tzinfo=utc) end_date = datetime(2024, 5, 31, tzinfo=utc) current_date = start_date astronomical_data = [] while current_date <= end_date: planet_positions = get_planet_positions(current_date) moon_phase = get_moon_phase(current_date) try: solar_activity = get_solar_activity(current_date) except Exception as e: print(f"Error getting solar activity for {current_date}: {e}") solar_activity = {'sunspot_number': None, 'f10.7_flux': None} aspects = calculate_aspects(planet_positions) data = { 'date': current_date, 'moon_phase': moon_phase, 'sunspot_number': solar_activity.get('sunspot_number'), 'f10.7_flux': solar_activity.get('f10.7_flux'), **planet_positions, **aspects } astronomical_data.append(data) current_date += timedelta(days=1) print(f"Processed: {current_date}") # Convert data to DataFrame df = pd.DataFrame(astronomical_data) # Save data to CSV file df.to_csv('astronomical_data_2018_2024.csv', index=False) print("Data saved to astronomical_data_2018_2024.csv")
Este código Python recopila datos astronómicos que usaremos en el futuro para el análisis de mercado.
El código utiliza el período del 1 de enero de 2018 al 31 de mayo de 2024 y recopila una variedad de datos como:
- Posiciones de los planetas: Venus, Mercurio, Marte, Júpiter, Saturno, Urano y Neptuno
- Fases lunares
- Actividad solar
- Aspectos planetarios (cómo se alinean los planetas entre sí)
El script incluye importaciones de biblioteca, el bucle principal y el guardado de datos en formato Excel. El código utiliza la biblioteca Skyfield ya mencionada para calcular las posiciones de los planetas, Pandas para los datos y solicitudes para obtener datos de actividad solar.
Las funciones más destacadas son get_planet_positions() para obtener las posiciones de los planetas (ascensión recta y declinación), get_moon_phase() para conocer la fase lunar actual, get_solar_activity() para obtener directamente los datos de actividad solar de la API de la NOAA, y calculate_aspects() para calcular los aspectos, es decir, las posiciones de los planetas entre sí.
Recorremos cada día como parte del ciclo y recopilamos todos los datos. Como resultado, guardamos todo en un archivo Excel para uso futuro.
Obtención de datos financieros a través de MetaTrader 5
Para obtener datos financieros, utilizaremos la biblioteca MetaTrader 5 para Python. La biblioteca nos permitirá descargar datos financieros directamente del broker y recibir series temporales de precios para cualquier instrumento. Aquí está nuestro código para cargar datos históricos:
import MetaTrader5 as mt5
import pandas as pd
from datetime import datetime
# Connect to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set query parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2018, 1, 1)
end_date = datetime(2024, 12, 31)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
# Save data to CSV file
df.to_csv(f'{symbol}_data.csv', index=False)
# Terminate the connection to MetaTrader5
mt5.shutdown()
El script se conecta a la terminal comercial, recibe datos sobre EURUSD D1, luego crea un marco de datos y lo guarda en un solo archivo CSV.
Sincronización de datos astronómicos y financieros
Entonces, tenemos datos sobre astronomía y también tenemos datos sobre el EURUSD. Ahora tenemos que sincronizarlos. Combinemos los datos por fechas para que un único conjunto de datos contenga toda la información necesaria, tanto financiera como astronómica.
import pandas as pd
# Load data
astro_data = pd.read_csv('astronomical_data_2018_2024.csv')
financial_data = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_data['date'] = pd.to_datetime(astro_data['date'])
financial_data['time'] = pd.to_datetime(financial_data['time'])
# Merge data
merged_data = pd.merge(financial_data, astro_data, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
El script carga todos los datos guardados, formatea las columnas de fecha en formato de fecha y hora y combina conjuntos de datos por fecha. Como resultado, obtenemos un archivo CSV que contiene todos los datos que necesitamos para el análisis futuro.
Análisis estadístico de correlaciones
Sigamos adelante. Tenemos un conjunto común, un conjunto de datos común, y es hora de descubrir si existen relaciones en los datos entre la astronomía y los movimientos del mercado. Utilizaremos las funciones corr() de la biblioteca pandas. Además, combinaremos ambos códigos en uno.
Aquí está el script final:
import pandas as pd
import numpy as np
from skyfield.api import load, wgs84, utc
from skyfield.data import mpc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
# Part 1: Collecting astronomical data
# Loading planetary ephemerides
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Collecting astronomical data
start_date = datetime(2024, 3, 1, tzinfo=utc)
end_date = datetime(2024, 7, 30, tzinfo=utc)
current_date = start_date
astronomical_data = []
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
data = {
'date': current_date,
'moon_phase': moon_phase,
'sunspot_number': solar_activity.get('sunspot_number'),
'f10.7_flux': solar_activity.get('f10.7_flux'),
**planet_positions,
**aspects
}
astronomical_data.append(data)
current_date += timedelta(days=1)
print(f"Processed: {current_date}")
# Convert data to DataFrame and save
astro_df = pd.DataFrame(astronomical_data)
astro_df.to_csv('astronomical_data_2018_2024.csv', index=False)
print("Astronomical data saved to astronomical_data_2018_2024.csv")
# Part 2: Retrieving financial data via MetaTrader5
# Initialize connection to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set request parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2024, 3, 1)
end_date = datetime(2024, 7, 30)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
# Save financial data
financial_df.to_csv(f'{symbol}_data.csv', index=False)
print(f"Financial data saved to {symbol}_data.csv")
# Shutdown MetaTrader5 connection
mt5.shutdown()
# Part 3: Synchronizing astronomical and financial data
# Load data
astro_df = pd.read_csv('astronomical_data_2018_2024.csv')
financial_df = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
# Merge data
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
print("Merged data saved to merged_astro_financial_data.csv")
# Part 4: Statistical analysis of correlations
# Select numeric columns for correlation analysis
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Create lags for astronomical data
for col in numeric_columns:
if col not in ['open', 'high', 'low', 'close', 'tick_volume', 'spread', 'real_volume']:
for lag in range(1, 6): # Create lags from 1 to 5
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Update list of numeric columns
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Calculate correlation matrix
correlation_matrix = merged_data[numeric_columns].corr()
# Create heatmap of correlations
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0)
plt.title('Correlation Matrix of Astronomical Factors (with Lags) and EURUSD Prices')
plt.tight_layout()
plt.savefig('correlation_heatmap_with_lags.png')
plt.close()
# Output the most significant correlations with the closing price
significant_correlations = correlation_matrix['close'].sort_values(key=abs, ascending=False)
print("Most significant correlations with the closing price:")
print(significant_correlations)
# Create a separate correlation matrix for astronomical data with lags and the current price
astro_columns = [col for col in numeric_columns if col not in ['open', 'high', 'low', 'tick_volume', 'spread', 'real_volume']]
astro_columns.append('close') # Add the current closing price
astro_correlation_matrix = merged_data[astro_columns].corr()
# Create heatmap of correlations for astronomical data with lags and the current price
import seaborn as sns
import matplotlib.pyplot as plt
# Increase the header and axis label font
plt.figure(figsize=(18, 14))
sns.heatmap(astro_correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0, cbar_kws={'label': 'Correlation'})
plt.title('Correlation matrix of astronomical factors (with lags) and current EURUSD price', fontsize=24)
plt.xlabel('X-axis Label', fontsize=30)
plt.ylabel('Y-axis Label', fontsize=30)
plt.xticks(fontsize=30)
plt.yticks(fontsize=30)
plt.tight_layout()
plt.savefig('astro_correlation_heatmap_with_lags.png')
plt.close()
print("Analysis completed. Results saved in CSV and PNG files.")
Este script muestra un mapa de las correlaciones entre todos los números del conjunto de datos, y también una matriz de todas las correlaciones en formato de mapa de calor, además de producir una lista de las correlaciones más significativas con los precios de cierre.
La presencia o ausencia de una correlación no implica la presencia o ausencia de una relación causal. Incluso si encontráramos fuertes correlaciones entre datos astronómicos y movimientos de precios, esto no significaría que un factor determine al otro, y viceversa. Se necesitan nuevas investigaciones, ya que el mapa de correlación es sólo lo más básico.
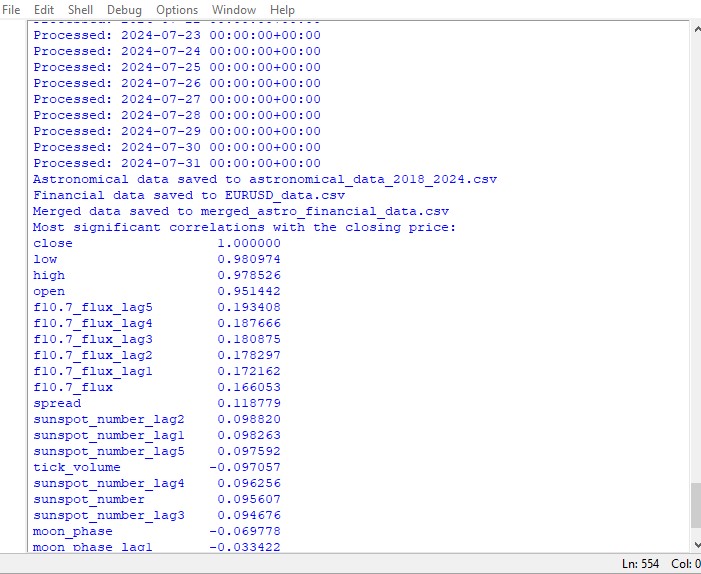
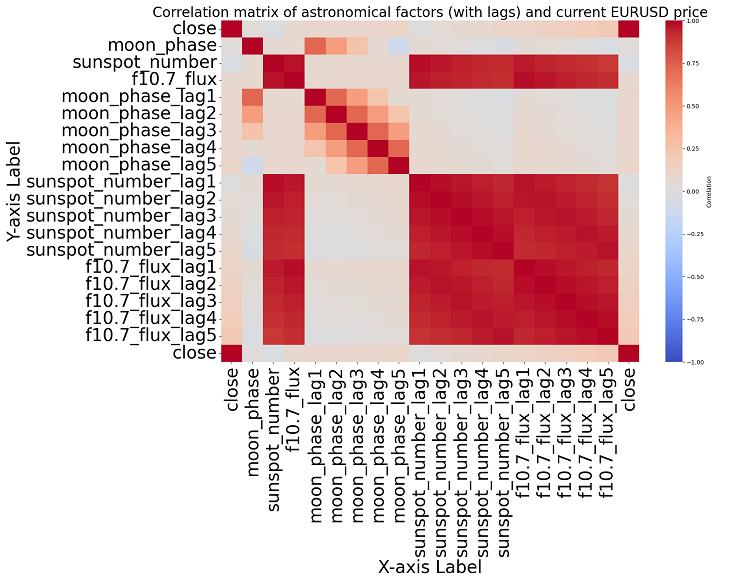
Si nos acercamos al tema, no podemos encontrar ninguna correlación significativa en los datos. No existen correlaciones claras entre los datos astronómicos pasados y los indicadores del mercado.
El aprendizaje automático al rescate
Pensé en qué hacer a continuación y decidí aplicar un modelo de aprendizaje automático. Hice dos scripts usando la biblioteca CatBoost que intentan predecir precios futuros usando datos del conjunto de datos como características. Aquí está el primero de los modelos, uno de regresión:
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# Loading data
data = pd.read_csv('merged_astro_financial_data.csv')
# Converting date to datetime
data['date'] = pd.to_datetime(data['date'])
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6): # Creating lags from 1 to 5
data[f'{col}_lag{lag}'] = data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
data[f'{col}_ra'] = data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
data[f'{col}_dec'] = data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6): # Lags from 1 to 5
data[f'{col}_ra_lag{lag}'] = data[f'{col}_ra'].shift(lag)
data[f'{col}_dec_lag{lag}'] = data[f'{col}_dec'].shift(lag)
data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Converting aspects to numerical features
aspect_cols = ['mercury_saturn', 'venus_mars', 'venus_jupiter', 'venus_uranus',
'mars_jupiter', 'mars_uranus', 'jupiter_uranus', 'mercury_neptune',
'venus_saturn', 'venus_neptune', 'mars_saturn', 'mercury_venus',
'mars_neptune', 'mercury_uranus', 'saturn_neptune', 'mercury_jupiter',
'mercury_mars', 'jupiter_saturn']
# Using LabelEncoder for encoding aspects
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
data[col] = label_encoders[col].fit_transform(data[col].astype(str))
# Filling missing values with mean values for numeric columns
numeric_cols = data.select_dtypes(include=[np.number]).columns
data[numeric_cols] = data[numeric_cols].fillna(data[numeric_cols].mean())
# Removing rows with missing values
data = data.dropna()
# Preparing features and target variable
features = [col for col in data.columns if col not in ['date', 'time', 'close']]
X = data[features]
y = data['close']
# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Creating and training the CatBoost model
model = CatBoostRegressor(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
# Evaluating the model
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"Mean Absolute Error: {mae}")
print(f"R-squared Score: {r2}")
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
# Selecting the last row of data
last_data = data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
# Prediction
prediction = model.predict(input_features)
print(f"Prediction for the next closing price: {prediction[0]}")
# Example of using the function to predict the next value
predict_next()

El segundo modelo es la clasificación:
import pandas as pd
import numpy as np
from skyfield.api import load, utc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import LabelEncoder
# Part 1: Collecting astronomical data
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Part 2: Obtaining financial data through MetaTrader5
def get_financial_data(symbol, start_date, end_date):
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
return None
timeframe = mt5.TIMEFRAME_D1
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
mt5.shutdown()
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
return financial_df
# Part 3: Synchronizing astronomical and financial data
def sync_data(astro_df, financial_df):
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
return merged_data
# Part 4: Training the model and making predictions
def train_and_predict(merged_data):
# Converting aspects to numerical features
aspect_cols = [col for col in merged_data.columns if '_' in col and col not in ['date', 'time']]
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
merged_data[col] = label_encoders[col].fit_transform(merged_data[col].astype(str))
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6):
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
merged_data[f'{col}_ra'] = merged_data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
merged_data[f'{col}_dec'] = merged_data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6):
merged_data[f'{col}_ra_lag{lag}'] = merged_data[f'{col}_ra'].shift(lag)
merged_data[f'{col}_dec_lag{lag}'] = merged_data[f'{col}_dec'].shift(lag)
merged_data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Filling missing values with mean values for numeric columns
numeric_cols = merged_data.select_dtypes(include=[np.number]).columns
merged_data[numeric_cols] = merged_data[numeric_cols].fillna(merged_data[numeric_cols].mean())
merged_data = merged_data.dropna()
# Creating binary target variable
merged_data['price_change'] = (merged_data['close'].shift(-1) > merged_data['close']).astype(int)
# Removing rows with missing values in the target variable
merged_data = merged_data.dropna(subset=['price_change'])
features = [col for col in merged_data.columns if col not in ['date', 'time', 'close', 'price_change']]
X = merged_data[features]
y = merged_data['price_change']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
model = CatBoostClassifier(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
clf_report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(clf_report)
print("Confusion Matrix:")
print(conf_matrix)
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
last_data = merged_data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
prediction = model.predict(input_features)
print(f"Price change prediction (0: will decrease, 1: will increase): {prediction[0]}")
predict_next()
# Main program
start_date = datetime(2023, 3, 1)
end_date = datetime(2024, 7, 30)
astro_data = []
current_date = start_date
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
astro_data.append({
'date': current_date,
'mercury': str(planet_positions['mercury']),
'venus': str(planet_positions['venus']),
'mars': str(planet_positions['mars']),
'jupiter': str(planet_positions['jupiter']),
'saturn': str(planet_positions['saturn']),
'uranus': str(planet_positions['uranus']),
'neptune': str(planet_positions['neptune']),
'moon_phase': moon_phase,
**solar_activity,
**aspects
})
current_date += timedelta(days=1)
astro_df = pd.DataFrame(astro_data)
symbol = "EURUSD"
financial_data = get_financial_data(symbol, start_date, end_date)
if financial_data is not None:
merged_data = sync_data(astro_df, financial_data)
train_and_predict(merged_data) Desafortunadamente ninguno de los dos modelos proporciona gran precisión. La precisión de la clasificación es ligeramente superior al 50%, lo que significa que podemos hacer predicciones con la misma facilidad con solo lanzar una moneda.
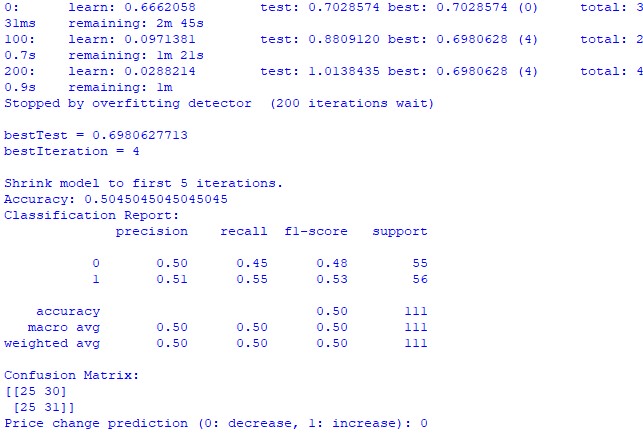
Tal vez el resultado se pueda mejorar, ya que se le ha prestado poca atención al modelo de regresión y, de hecho, es posible predecir los precios utilizando las posiciones planetarias y la actividad de la Luna y el Sol. Haré otro artículo sobre este tema si estoy de humor.
Resultados
Así pues, es hora de resumir los resultados. Después de realizar un análisis simple y escribir dos modelos de predicción, vemos los resultados del estudio sobre el impacto potencial de la astrología en el mercado.
Análisis de correlación. El mapa de correlación que obtuvimos no reveló ninguna correlación fuerte entre las posiciones planetarias y el precio de cierre del EURUSD. Todas nuestras correlaciones son inferiores a 0,3, lo que nos da motivos para creer que la posición de las estrellas o los planetas no está relacionada en absoluto con los mercados financieros.
Modelo de regresión CatBoost. Los resultados finales del modelo de regresión mostraron una capacidad muy pobre para predecir con precisión los precios de cierre futuros basándose en datos astronómicos.
Las métricas de rendimiento del modelo resultantes, como MSE, MAE y R cuadrado, son muy débiles y explican muy mal los datos. Al mismo tiempo, el modelo muestra que las características más importantes son los rezagos y los valores de precios anteriores, más que las posiciones planetarias. Entonces, ¿eso significa que el precio es un mejor indicador que la posición de cualquier planeta en nuestro sistema solar?
Modelo de clasificación CatBoost. El modelo de clasificación es extremadamente pobre a la hora de predecir futuras subidas o bajadas de precios. La precisión apenas supera el 50%, lo que también confirma que la astronomía no funciona en el mercado real.
Conclusión
Los resultados del estudio son bastante claros: los métodos de la astrología y los intentos de predecir los precios en el mercado real basándose en datos astronómicos son completamente inútiles. Quizás vuelva sobre este tema, pero por ahora las enseñanzas de William Gann parecen intentos de disfrazar soluciones que no funcionan, creadas únicamente para vender libros y cursos de trading.
¿Podría ser que un modelo mejorado que también utilizara los valores del ángulo de Gann, los valores del cuadrado de 9 y los valores de la cuadrícula de Gann funcionara mejor? Todavía no lo sabemos. Estoy un poco decepcionado con los resultados del estudio.
Pero sigo pensando que los ángulos de Gann se pueden utilizar de una forma u otra para obtener previsiones de precios funcionales. El precio afecta a los ángulos de una forma u otra, reacciona a ellos, lo cual es evidente a partir de los resultados del estudio anterior. También es posible que los ángulos se puedan utilizar como características de trabajo para los modelos de entrenamiento. Intentaré crear un conjunto de datos de este tipo y veré qué resulta.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15625
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Siguiendo los pasos de Ghana, en aras de la pureza de la experiencia, debería haber tomado no EURUSD, pero, por ejemplo, los futuros del algodón. Y el instrumento es aproximadamente el mismo y ciclos astronómicos puede estar en él, después de todo, la agricultura.