
ニューラルネットワークが簡単に(第62回):階層モデルにおけるDecision Transformerの使用

はじめに
現実の問題を解決していると、確率的で動的に変化する環境の問題にしばしば遭遇します。そのため、新しい適応アルゴリズムを探す必要があります。ここ数十年、様々な環境やタスクに適応するようにエージェントを訓練できる強化訓練(RL、reinforcement learning)技術の開発に多大な努力が払われてきました。しかし、実世界におけるRLの応用は、変動的で確率的な環境におけるオフライン学習や、高次元の状態行動空間における計画制御の困難さなど、多くの課題に直面しています。
複雑な問題を解決するとき、最も効率的な方法は、1つの問題をその構成要素であるサブタスクに分割することです。階層的な方法を考慮する場合のこのアプローチの利点について話しました。このような統合的なアプローチによって、より適応性の高いモデルを作成することができます。
これまでは、いわばマルコフ過程の古典的なアプローチで問題を解くための階層モデルを考えてきました。ただし、階層的アプローチを用いる利点は、配列解析問題にも当てはまります。「Control Transformer「Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling」で紹介されているControl Transformerがそのようなアルゴリズムの1つです。この手法の著者は、強化学習に基づいて複雑な制御とナビゲーションの問題を解決するために設計された新しいアーキテクチャと位置づけています。この手法では、強化学習、計画、機械学習といった最新の手法を組み合わせることで、さまざまな環境における適応的な制御戦略を作り出すことができます。
Control Transformerは、ロボット工学、自律走行、その他の分野における複雑な制御問題の解決に新たな展望を開きます。取引の問題を解決するために、この方法を使用する可能性について考えてみたいと思います。
1. Control Transformerアルゴリズム
Control Transformerアルゴリズムは、かなり複雑な手法であり、いくつかの独立したブロックを含んでいます。また、このアルゴリズムはロボットのナビゲーションと行動制御のために開発されたものであることも忘れてはなりません。したがって、アルゴリズムの説明はこの文脈でおこなわれます。
長期間の計画に対するコントロールの問題を解決するために、この手法の著者は、限られた距離の特定のセグメントという形で、より小さなサブタスクに分解することを提案しています。この方法の作成者は、確率的ロードマップを使用してGを構築します。ここでは、頂点は点であり、エッジは局所的スケジューラを使用して接続された点間を移動する能力を示しています。グラフは、環境内のn個の無作為な点のサンプルに基づいて構築され、その後、点間にパスが存在する場合に限り、d(ハイパーパラメータ)以下の距離で隣接する点に接続され、グラフ内のエッジを形成します。
したがって、出来上がったGグラフでは、どのX0始点からでも、どのXg目標点にも到達できます。これは、始点と目標点の最近傍のグラフを検索することによって達成されます。次に、最短経路探索アルゴリズムを使用してウェイポイントのシーケンス(軌跡)を求めます。その後、ロボットは、πc局所的コントローラ方針の行動を実行しながら、初期状態からゴールまで移動することができます。πc方針のガイドとなるウェイポイントのシーケンスまたはプランは、ロボットの進行に応じて固定または更新することができます。
πc局所的方針の訓練には、目標達成を目的とした強化訓練法(GCRL)を用いました。この場合、問題はゴールに向けられた条件を持つマルコフ意思決定過程を用いてモデル化されます。目標を設定し、戦略を訓練するために、サンプルベースの計画を使用することが提案されています。
そのために、まず確率的ロードマップを使用して、前述のようにGグラフを求めます。次に、学習エピソードごとに、グラフからエッジを選択します。エッジはこのエピソードの始まりであり、ゴールでもあります。このプロセスは、どのような目標ベースの学習アルゴリズムとも互換性があります。著者らはSoft Actor-Criticを使用して、ゴールへの進捗に比例した報酬を密に与える実験をおこないました。低レベルの戦略は、戦略の状態空間には自身の位置に関する情報しか含まれておらず、制約を回避するための訓練が必要ないため、効率的に訓練することができます。
πc局所的方針を訓練した後は、全域的ゴールを達成するように導くプロセスをアレンジする必要があります。つまり、計画された軌道を生成するモデルを訓練しなければなりません。このモデルのゴールと報酬は、πcがたどるウェイポイントではなく、最終ゴールに関連して設定されます。モデルの全域的な最目標を達成するためには、より多くの初期データが必要なのは明らかです。高次元の観測値と他の利用可能な情報は、低次元の局所的状態データに加えられます。例は、局所的な地図です。
標本化ベースデザインで収集されたデータでモデルを訓練するために、ゴール達成への方向性を含むシーケンスモデリング問題を考えます。また、この手法の著者は、部分的に観測可能なマルチタスク環境も考慮しています。この環境では、戦略は同じナビゲーションタスクを持つ複数の環境で働くことができますが、環境ごとに異なる構造を持ちます。このシーケンスに対して自己回帰的な行動予測を学習することは可能ですが、いくつかの問題が発生します。DTと同様、最適な初期予測報酬がわからないため、最適なRTGは一定であると仮定されます。それは環境の未知の構造に依存します。エピソードによって変わるかもしれません。また、初期状態やゴール位置にも左右されます。したがって、DTが未知の環境に汎化し、どのようなスタート位置からどのようなゴールに向かっても作業できるような変化を探る必要があります。
1つのアプローチは、オフラインデータから完全なRTG分布を訓練することです。そして、この分布の中から運用中に条件を選択する必要があります。しかし、未知の環境におけるRTGを一般化して予測できるように、目標指向タスクにおけるRTGの完全な分布を訓練することは難しいです。その代わりに、著者はこの分布の平均値関数を訓練することを提案しています。この関数は、T軌跡の中で与えられたゴールgに対するS点での期待報酬を推定します。この関数も過去の履歴に基づくものではありません。というのも、運用開始の時点で、最初の期待報酬R̃0を予測するからです。次に、RTGを環境からの実際の報酬に合わせます。価値関数は、別のニューラルネットワークとしてパラメータ化され、MSEを用いて訓練されます。
より最適な動作を得るために、ある一定の比率で訓練値を調整することができます。さらに、最良の軌跡や事前に定義された条件を満たす軌跡に対してのみ価値関数を訓練することも可能です。
筆者によるControl Transformer方式の可視化を以下に示します。
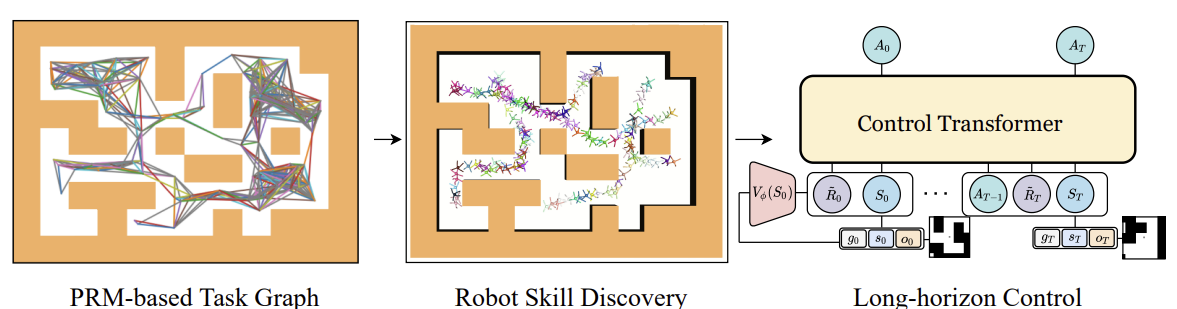
オフライン訓練でよくある問題の1つは、訓練された戦略を実践したときに、実際の軌道の分布が訓練セットの分布と一致しない場合の分布のずれです。そのため、エラーが累積し、戦略が最適でなくなる事態を招く可能性があります。この問題を解決するために、この手法の著者は、現在のモデル方針を使用してオフライン訓練段階後に訓練セットを拡張し、その後にオフラインでモデルを微調整することを提案しています。
2.MQL5を使用した実装
Control Transformer法の理論的側面を検討した後、MQL5を使用した実装に移ります。先に述べたように、アルゴリズムは複雑です。従って、実施プロセスにおいては、過去の多くの記事から発展したものを使用することになります。まず、可能性のある動きのグラフを作成することから方法を検討し始めました。
2.1.訓練セットの収集
確率的な環境と連続的な行動空間の場合、このようなグラフを構築するのは自明な作業ではないかもしれません。反対側からこの問題にアプローチし、Go-Explore方式を開発する際に得た経験を活用することにしました。「...\CT\Faza1.mq5」EAを微調整し、訓練期間内の取引操作の可能な軌跡を収集しました。そうしながら、収益性が最大となる軌道を選択しました。
そのために、EAの外部パラメータに最大標本化行動数と最小軌道長を追加しました。このようなパラメータが現れるのは、1回のパスで訓練区間全体にわたって許容可能な軌道を標本化できる確率がかなり低い(0に近い)ためです。それよりも、収益性の高い取引のある小領域を徐々に標本化し、それを共通の収益性の高い一連の行動に集めていく方がはるかに可能性が高くなります。
input int MaxSteps = 48; input int MinBars = 20;
このEAはニューラルネットワークモデルを使用していません。すべての行動は一様分布から標本化されます。
EAの初期化メソッドでは、まず指標と取引操作クラスのオブジェクトを初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
必要な変数を初期化し、軌道と初期状態を標本化して、以前に保存した軌道を継続します。もちろん、このような標本化が可能なのは、過去に保存された軌跡がある場合に限られます。
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); AgentResult = vector<float>::Zeros(NActions); //--- int error_code; if(Buffer.Size() > 0 || LoadTotalBase()) { int tr = int(MathRand() / 32767.0 * Buffer.Size()); Loaded = Buffer[tr]; StartBar = MathMax(0,Loaded.Total - int(MathMax(Math::MathRandomNormal(0.5, 0.5, error_code), 0) * MaxSteps)); } //--- return(INIT_SUCCEEDED); }
過去に通過した軌跡がない場合、EAは最初のバーから行動の標本化を開始します。
直接的なデータ収集は、OnTickティック処理関数でおこなわれます。ここでは、前回と同様に、新しいバーのオープニングイベントの発生を確認し、必要であれば、商品と指標のパラメータの動きに関する履歴データを読み込みます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- CurrentBar++; int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
読み込まれたデータを構造体に転送し、経験再生バッファにセットします。
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
口座のステータスや報酬に関する情報を環境から追加します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(sState.account[1] / PrevBalance - 1.0);
内部変数を再定義します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
次にエージェントの行動を選択します。前述したように、ここではモデルは使用しません。その代わりに、標本化フェーズの開始を確認します。以前に保存した軌跡を繰り返すときは、軌跡から行動を取ります。標本化期間が到来していれば、一様分布から行動ベクトルを生成します。
vector<float> temp = vector<float>::Zeros(NActions); if((CurrentBar - StartBar) < MaxSteps) if(CurrentBar < StartBar) temp.Assign(Loaded.States[CurrentBar].action); else temp = SampleAction(NActions);
その結果、環境内で行動が実行されます。
//--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
インタラクションの結果は、経験再生バッファに追加されます。
//--- int shift = BarDescr * (NBarInPattern - 1); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState) || (CurrentBar - StartBar) >= MaxSteps) ExpertRemove(); //--- }
ここでは、標本化された手順の最大数に達したかどうかを確認し、必要であればプログラムの終了を開始します。
経験再生バッファに軌跡を追加する方法の変更について、少し述べておく必要があります。以前はFIFO(先入れ先出し)方式で軌跡を追加していたが、現在は最も収益性の高いパスを保存しています。したがって、次のパスが完了したら、まず経験再生バッファのサイズを確認します。
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(total >= MaxReplayBuffer) {
バッファサイズの上限に達すると、まず、以前に保存されたものの中から、収益性が最小となる通路を探します。
for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
新しいパスの収益性を経験再生バッファの最小値と比較し、必要であれば最小値の代わりに新しいパスを設定します。
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
これにより、コストのかかるバッファ内のデータの並べ替えを省くことができます。一回のパスで、最小値と新しい軌道の保存の可否を判断します。
再生バッファの限界サイズにまだ達していない場合は、単に新しいパスを追加し、メソッド操作を完了します。
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
これで環境相互作用EAの紹介は終わりです。すべてのコードは添付ファイルにあります。
2.2.スキル訓練
次の手順は、局所的方策訓練EAを作成することです。局所的方針は、上位のスケジューラの指示を実行するエクゼキュータの役割を果たします。局所的方針モデル自体を単純化するため、また階層システムの精神に則り、モデルへの入力として環境の現在の状態を提供しないことにしました。私たちのビジョンでは、それは一定のスキルを持ったモデルになります。どのスキルを使用するかはスケジューラー次第です。同時に、局所的方策モデル自体が環境の状態を分析することはありません。
スキルの訓練には、オートエンコーダのアーキテクチャと、先に説明した階層的モデルの開発を利用します。訓練中、無作為に1つのスキルを局所的方針モデルの入力に投入します。識別器は、使用されているスキルを識別しようとします。
ここで、訓練すべきスキルの必要数を決定しなければなりません。ここで、過去の仕事も参照します。クラスタリングの方法を検討しながら、最適なクラスタ数を100~500の範囲で決定しました。スキル不足を避けるため、局所的方針の入力ベクトルのサイズは512要素としました。
#define WorkerInput 512
局所的方針と識別モデルのアーキテクチャを以下に示します。これらのモデルは複雑にしすぎませんでした。局所的方針モデルへの入力として、ワンホットベクトルか、SoftMax関数で正規化されたデータベクトルを受け取ることを期待しています。したがって、ソースデータ層の後ではバッチ正規化層を追加しませんでした。
bool CreateWorkerDescriptions(CArrayObj *worker, CArrayObj *descriminator) { //--- CLayerDescription *descr; //--- if(!worker) { worker = new CArrayObj(); if(!worker) return false; } //--- Worker worker.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
続いて、異なる活性化関数を持つ2つの完全接続ニューラル層が続きます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
その後、層の次元を減らし、エージェントの行動空間のコンテキストでSoftMax関数を使用してデータを正規化します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
局所的方針の出力は、エージェントの行動ベクトルに等しいサイズを持つ完全接続ニューラル層です。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
識別器モデルは、デコーダと似たやや逆のアーキテクチャを持ちます。モデル入力は、局所的方策モデルによって生成されたエージェントの行動ベクトルを受け取ります。ここでもバッチ正規化層は使用しません。
//--- Descriminator if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } //--- descriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
次に来るのは、局所的方針で使用したのと同じ全結合層です。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
次に、次元を使用スキル数に変更し、SoftMax関数でスキル使用確率を正規化します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- return true; }
可能な限りシンプルなモデルを開発しました。これによって、訓練中も作戦行動中も、彼らの作業を可能な限りスピードアップさせることができます。
スキルを訓練するため、「....\CT\StudyWorker.mq5」EAを作成します。すべてのEA方式の詳細な検証については、詳しくは触れません。Trainモデルを直接訓練する方法だけを考えてみましょう。
このメソッドの本体は、EA外部パラメータで指定された反復回数に従って、訓練モデルのループを配置します。ループの中では、まずスキルの数に等しいサイズの無作為なワンホットベクトルを生成します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { Data.BufferInit(WorkerInput, 0); int pos = int(MathRand() / 32767.0 * (WorkerInput - 1)); Data.Update(pos, 1.0f);
局所的方針モデルの入力はベクトルを受け取り、フォワードパスが実行されます。得られた結果は識別器の入力に渡されます。
//--- Study if(!Worker.feedForward(Data,1,false) || !Descrimitator.feedForward(GetPointer(Worker),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
操作を制御することを忘れないでください。
両方のモデルのフォワードパスが成功した後、実際のスキルと識別器によって決定されたスキルとの間の偏差を最小化するために、モデルのバックワードパスを実行します。
if(!Descrimitator.backProp(Data,(CBufferFloat *)NULL, (CBufferFloat *)NULL) || !Worker.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
しなければならないのは、訓練の進捗状況をユーザーに知らせ、次の訓練反復に移ることだけです。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Desciminator", iter * 100.0 / (double)(Iterations), Descrimitator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
ループをすべて繰り返したら、コメント欄をクリアします。訓練結果を表示します。プログラムのシャットダウンを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Descriminator", Descrimitator.getRecentAverageError()); ExpertRemove(); //--- }
この極めてシンプルなメソッドで、必要な数の明確なスキルを訓練することができます。階層モデルを構築する際、実行された動作に基づくスキルの区別は非常に重要です。これは、モデルの挙動を多様化し、特定の環境状態において適切なスキルを選択するという点で、スケジューラーの作業を容易にするのに役立ちます。
2.3.コスト関数の訓練
次にコスト関数の研究に移ります。訓練されたモデルは、環境の現状を分析した上で、可能性のある収益性を予測することができると期待されています。基本的に、これは標準的なRLにおける未来の状態の推定であり、ほとんどすべてのモデルで何らかの形で研究されています。ただし、この方法の著者は、ディスカウントファクターなしで検討することを提案しています。
このエピソードの最後までではなく、短い計画期間のみでコスト見積もりの実験をおこなうことにしました。私の論理は、ポジションを建てて「時の終わりまで」保有するつもりはないというものでした。確率的な市場では、このような遠大な予測はありえません。そうでなければ、このアプローチは非常にわかりやすいものです。繰り返しになりますが、私はモデルを複雑にはしすぎませんでした。モデルのアーキテクチャを以下に示します。
モデルには、環境の状態を記述する少量の履歴データを与えます。このモデルでは、主な可能性を評価するために、市場の状況のみを評価します。この場合、トレンドには興味はありません。その代わりに、市場の強度に注目します。生データを使用するため、このモデルではすでにバッチ正規化層を適用しています。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
正規化されたデータは、ローソク足の文脈で畳み込み層によって処理され、主なパターンを特定することができます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = ValueBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; }
その後、データは全結合層のブロックによって処理され、結果は分解された報酬ベクトルの形で生成されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
値関数を訓練するために、「...\CT\StudyValue.mq5」EAを作成します。ここでは、Trainモデルの訓練方法にも焦点を当てます。このモデルを訓練するには、すでに訓練サンプルが必要です。したがって、訓練ループの本体では、軌道と状態を標本化します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); int check = 0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 * ValueBars)); if(i < 0) { iter--; continue; check++; if(check >= total_tr) break; }
軌跡を標本化するとき、ValueBarsの値を2倍にすることで可能な状態の範囲を狭めます。これは、(DTでGPTアーキテクチャを使用しているため)経験再生バッファでは、各状態には最後のバーしか含まれておらず、可能性を評価するためには数バーの履歴データが必要であるという事実によるものです。また、エピソードが終了するまでの累積報酬から、計画地平を超えた報酬を取り崩します。
次に、ソースデータバッファを埋めます。
check = 0; //--- History data State.AssignArray(Buffer[tr].States[i].state); for(int state = 1; state < ValueBars; state++) State.AddArray(Buffer[tr].States[i + state].state);
モデルのダイレクトパスを実行します。
//--- Study if(!Value.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次に、モデルを訓練するための対象データを準備しなければなりません。状態評価時の経験再生バッファから累積報酬を取り出し、計画期間外の累積報酬を差し引きます。次に、モデルのダイレクトパスの結果を読み込み、CAGrad法を使用して目標値のベクトルを補正します。
vector<float> target, result; target.Assign(Buffer[tr].States[i + ValueBars - 1].rewards); result.Assign(Buffer[tr].States[i + 2 * ValueBars - 1].rewards); target = target - result*MathPow(DiscFactor,ValueBars); Value.getResults(result); Result.AssignArray(CAGrad(target - result) + result);
用意された目標値のベクトルをモデルに渡し、リバースパスを実行します。操作の実行を制御することを忘れないでください。
if(!Value.backProp(Result, (CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次に、モデルの訓練をユーザーに知らせ、訓練サイクルの次の反復に移ります。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Value", iter * 100.0 / (double)(Iterations), Value.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
ループのすべての反復が正常に完了したら、商品チャートのコメント欄をクリアします。モデルの訓練結果をログに表示します。EAのを終了します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Value", Value.getRecentAverageError()); ExpertRemove(); //--- }
このEAの完全なコードと記事で使用されているすべてのプログラムは添付ファイルにあります。
2.4.スケジューラー訓練
次の段階として、階層モデルのスケジューラーを開発します。この場合、Decision Transformerがスケジューラーの役割を果たし、訪問した状態のシーケンスとそこで実行された行動を分析します。スケジューラーの出力では、局所的方針モデルが行動を生成するために使用するスキルを受け取ることが期待されます。
まずはモデルアーキテクチャからです。初期データとして、軌跡の1つの状態を記述するベクトルを使用します。データは生の状態で提供されるので、バッチデータ正規化層を使用して前処理をおこないます。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
さらに、ソースデータベクトルのデータは異なるソースから収集されます。従って、両者は異なる次元と分布を持っています。埋め込み層は、それらをさらに便利に使用し、同等の形にするために使用されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
準備されたデータはスパースなTransformerブロックを通過します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
その後、畳み込み層を使用してデータの次元を減らします。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
次に、データは全結合層から意思決定ブロックを通過します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
出力では、データの次元を使用されたスキルの数に減らし、SoftMax関数でそれらの確率を正規化します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
モデルのアーキテクチャを検討した後、Scheduler訓練「...\CT\Study.mq5」EAの構築に移ります。いつものように、Trainモデルの訓練方法のみに焦点を当てます。
DTを育成するアプローチはほとんど変わっていません。モデルでは、ソースデータ(RTGを含む)とエージェントが実行する行動の間に依存関係を構築します。しかし、問題のアルゴリズムを構築する原理にはニュアンスの違いがあります。
- RTGはエピソードの最後まで到達してはなりません。
- DTの出力には、行動ではなくスキルがあります。誤差の勾配を伝えるために、局所的方針モデルが使用されます。
こうしたニュアンスはすべて、モデルの訓練過程に反映されます。
Trainメソッドの本体では、前回と同様に、モデル訓練ループのシステムを編成します。外側のループ本体では、モデルを訓練するために軌道と初期状態を標本化します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float err=0; int err_count=0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars-ValueBars,MathMin(Buffer[tr].Total,20+ValueBars))); if(i < 0) { iter--; continue; }
訓練処理自体は、ネストされたループ本体の中でおこなわれます。覚えていらっしゃるかもしれませんが、GPTアーキテクチャの特殊性により、訓練中に受け取った過去のデータを厳密に使用する必要があります。
過去の値動きと指標を順次ソースデータバッファに読み込みます。
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - 2 - ValueBars,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
次は、口座のステータスデータです。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
次は、タイムスタンプとエージェントの最後の行動です。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
次にRTGを指定します。ここでは、実際に累積された報酬を使用しますが、その前に計画期間に合わせましょう。
//--- Return-To-Go vector<float> rtg; rtg.Assign(Buffer[tr].States[state+1].rewards); Actions.Assign(Buffer[tr].States[state+ValueBars].rewards); rtg=rtg-Actions*MathPow(DiscFactor,ValueBars); State.AddArray(rtg);
こうして収集したデータをスケジューラーの入力に送り、フォワードパスメソッドを呼び出します。その結果得られた予測スキルを局所的方策モデルの入力に渡し、エージェントの行動を予測するためのダイレクトパスを実行します。
//--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat *)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
このようにして予測されたエージェントの行動と、ソースデータで指定された報酬を与えた経験再生バッファからの実際の行動を比較します。モデルを訓練するには、2つの値ベクトル間の偏差を最小化する必要があります。目標行動ベクトルを局所的方針モデルの出力に与え、両方のモデルを順次リバースパスします。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Worker.getResults(rtg); if(err_count==0) err=rtg.Loss(Actions,LOSS_MSE); else err=(err*err_count + rtg.Loss(Actions,LOSS_MSE))/(err_count+1); if(err_count<1000) err_count++; Result.AssignArray(CAGrad(Actions - rtg) + rtg); if(!Worker.backProp(Result,NULL,NULL) || !Agent.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
この場合、すでに訓練済みの局所的方針モデルを使用します。バックワードパスでは、スケジューラーのパラメータだけを更新します。そのためには、局所的方針モデルの訓練フラグをfalse (Worker.TrainMode(false))に設定する必要があります。今回の実装では、EAの初期化メソッドの中でこれをおこない、各反復で操作を繰り返さないようにしました。
しなければならないのは、訓練の進捗状況をユーザーに知らせ、次の訓練反復に移ることだけです。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), err); Comment(str); ticks = GetTickCount(); } } }
ループシステムのすべての反復が完了したら、EAを終了する操作を繰り返します。これについてはすでに上で2回説明しました。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", err); ExpertRemove(); //--- }
これでモデル訓練アルゴリズムの話題は終わりです。この記事では、これまで使用していた1つのEAに代えて、3つのモデル訓練EAを作成しました。このアプローチにより、モデルの訓練を並列化することができます。ご覧の通り、スキル訓練EAには訓練サンプルは必要ありません。訓練サンプルの収集と並行して、スキルを訓練することができます。スケジューラーとコスト関数の訓練では、経験再生バッファを使用します。同時に、プロセスは重ならず、異なるマシン上でも並行して起動できます。
2.5. モデルテストEA
モデルを訓練した後は、取引で得られた結果を評価する必要があります。もちろん、ストラテジーテスターでモデルをテストしますが、EAが必要です。EAは、上述したすべてのモデルを1つの意思決定複合体に統合します。この機能を「...\CT\Test.mq5」EAに実装します。すべてのEAメソッドを検討するわけではありません。ここでは、主要な意思決定アルゴリズムが配置されているOnTick関数だけに焦点を当てることにします。
メソッドの最初に、新しいバーが開くイベントの発生を確認します。ご記憶の通り、新しいバーが開いたときにすべての取引操作を実行します。この場合、閉じられたローソク足だけを分析します。
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
ここでは、必要に応じてサーバーから過去のデータをダウンロードします。
次に、モデルのソースデータバッファを履歴データで満たす必要があります。ここで注目すべきは、コスト関数モデルとスケジューラーは、構造と履歴の深さが異なるデータを使用するということです。まず、コスト関数のデータでバッファを満たし、フォワードパスを実行します。
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars-1; b >=0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!Value.feedForward(GetPointer(bState), 1, false)) return;
次に、バッファをスケジューラー用のデータで埋めます。データシーケンスは、モデルの訓練時に提示されたシーケンスを完全に繰り返す必要があります。まず、値動きと指標値に関する過去のデータを転送します。
for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
口座状況に関する情報を補足します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
次に、タイムスタンプとエージェントの最後の行動が表示されます。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
バッファの最後にRTGを追加します。コスト関数の結果バッファからこの値を取ります。
//--- Return to go
Value.getResults(Result);
bState.AddArray(Result);
データの準備が完了したら、スケジューラーと局所的方針モデルのフォワードパスを順次実行します。同時に、実施された操作の監視も怠りません。
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent), -1, (CBufferFloat *)NULL)) return;
このようにして予測されたエージェントの行動は、環境内で処理され実行されます。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Worker.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
環境との相互作用の結果は、その後のモデルの微調整のために経験再生バッファに保存されます。
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
このようにして収集されたデータは、モデルの微調整にも、その後の運転中のモデルの追加訓練にも使用できることに留意すべきです。これにより、変化する環境条件に常に適応させることができます。
3.検証
データ収集とモデル訓練のEAを作成するために、かなり多くの作業をおこなってきました。上述したように、いくつかのタスクを並行して実行するために、プロセス全体を別々のEAに分割しました。最初の手順は、自律的に動作し、訓練サンプルを必要としないスキル訓練EA「StudyWorker.mq5」を起動することです。同時に、訓練サンプルを収集します。
2023年の最初の7ヶ月間の歴史的な期間の訓練サンプルを集めるには、かなり手間がかかることが判明しました。エージェント行動の小さな標本化でも、ほとんどのパスが正バランスの要件を満たさないという問題にぶつかりました。
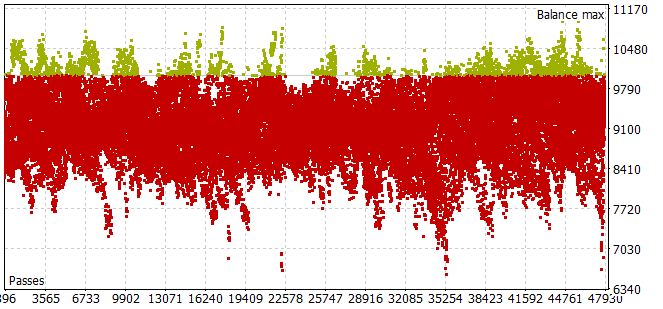
最適化モードで最適な計画期間を選択するために、1パスあたりの反復回数を最適化されたパラメータに合わせて調整しました。
訓練セットを収集し、局所的方針モデルを訓練した後、スケジューラーとコスト関数モデルの訓練を並行して実行しました。このアプローチによって、モデルの訓練に費やす時間を大幅に短縮することができました。
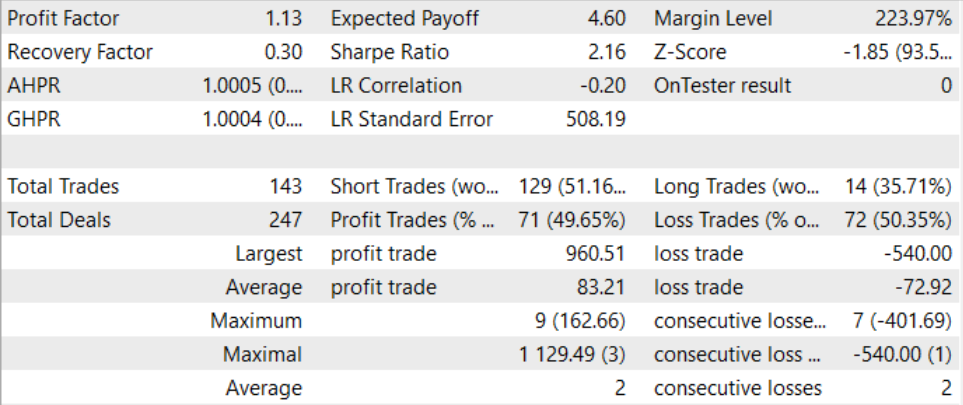
長く複雑な訓練プロセスを経て、我々は訓練セット外でも利益を生み出すことができるモデルを得ることに成功しました。訓練済みモデルは、2023年8月の過去データでテストされました。テスト結果によると、プロフィットファクターは1.13でした。利益を上げているポジションと利益を上げていないポジションの比率は1:1に近いです。すべての利益は、平均的な利益が平均的な損失を上回る取引によって達成されます。
結論
この記事では、複雑でダイナミックに変化する環境における制御戦略を訓練するための革新的なアーキテクチャを提供するControl Transformer法を紹介しました。Control Transformerは、高度な強化学習、スケジューリング、機械学習技術を組み合わせて、柔軟で適応性のある制御戦略を作成します。
Control Transformerは、さまざまな自律システムやロボットの開発に新たな展望を開きます。多様な環境に適応し、動的な条件を考慮し、オフラインで訓練する能力により、複雑な制御やナビゲーションの問題を解決できるインテリジェントな自律システムを構築するための強力なツールとなります。
本稿の実践部では、MQL5を使用して、構想した方法を実装しました。今回の実装では、モデル訓練を関連性のない別々のEAに分割するという新しいアプローチを採用し、複数のタスクを並行して実行できるようにしました。これにより、モデルの全体的な訓練時間を大幅に短縮することができます。
モデルを訓練し、テストしながら、利益を生み出せるモデルを作り上げることができました。したがって、このアプローチは効率的であると考えられます。取引ソリューションの構築に利用できます。
この記事で紹介されているプログラムはすべて、参考のためのものであり、紹介されているアルゴリズムを実証するためのものであることを、もう一度お断りしておきます。実際の市場環境で使用するためのものではありません。
リンク
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | スケジューラー訓練 EA |
| 3 | StudyWorker.mq5 | EA | 局所的方策モデル訓練EA |
| 4 | StudyValue.mq5 | EA | コスト関数訓練EA |
| 5 | Test.mq5 | EA | モデルテストEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13674
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索