
ニューラルネットワークが簡単に(第61回):オフライン強化学習における楽観論の問題

はじめに
近年、オフライン強化学習法が普及しており、様々な複雑さの問題を解決する上で多くの可能性が期待されています。しかし、研究者が直面する主な問題の1つは、学習中に生じうる楽観論です。エージェントは訓練セットのデータに基づいて戦略を最適化し、その行動に対する確信を得ますが、訓練セットは、環境のさまざまな状態や遷移をカバーしきれないことが多いです。確率的な環境では、そのような自信はまったく正当化されないことが判明しました。このような場合、エージェントの楽観的な戦略は、リスクを増大させ、望ましくない結果を招く可能性があります。
この問題を解決するために、自律走行分野の研究に注目する価値があります。この分野のアルゴリズムが、リスクの低減(ユーザーの安全性の向上)とオンライン訓練の最小化を目的としていることは明らかです。そのような手法の1つが、「Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning」(2022年7月)で紹介されたSeparated Latent Trajectory Transformer (SPLT-Transformer)です。
1. SPLT-Transformer方式
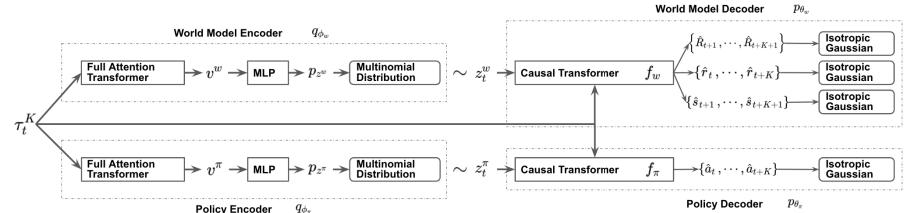
Decision Transformerと同様に、SPLT-TransformerはTransformerアーキテクチャを使用したシーケンス生成モデルです。ただし、前述のDTとは異なり、Actor方策と環境をモデル化するために2つの別々の情報の流れを使用します。
この手法の著者は、主に2つの問題を解決しようとしています。
- モデルは、どのような状況でもエージェントの行動に関する様々な候補を作成するのに役立つべきである
- モデルは、新しい環境状態への潜在的な遷移の異なるモードのほとんどをカバーすべきである
この目標を達成するために、Transformerをベースとした2つのVAEを、Actorの方策と環境モデルに対して訓練します。この手法の著者は、両方のフローについて確率的潜在変数を生成し、計画期間全体にわたって使用します。これにより、指数関数的に分岐を増やすことなく、可能性のあるすべての候補軌道を列挙することができ、テスト中の動作オプションを効果的に探索することができます。
このアイデアは、潜在的な方策変数は、階層的アルゴリズムのスキルに似た、異なるハイレベルな意図に対応すべきであるというものです。同時に、環境モデルの潜在変数は、さまざまな可能性のある傾向と、その状態の最も可能性の高い変化に対応しなければなりません。
方策エンコーダと環境エンコーダは、Transformerを使用した同じアーキテクチャを採用しています。それらは、以前の軌道という形で同じ初期データを受け取ります。しかし、先に説明したアルゴリズムとは異なり、軌跡にはActorの状態と行動のセットしか含まれません。エンコーダの出力では、各次元で限られた数の値を持つ離散潜在変数が得られます。
この方法の著者は、軌跡全体を1つのベクトル表現にまとめるために、全要素のTransformerの出力の平均値を使用することを提案しています。
次に、これらの各出力は、潜在表現の独立したカテゴリー分布を出力する小さな多層パーセプトロンによって処理されます。
方策デコーダは、対応する潜在表現によって補足された同じ元の軌道を入力として受け取ります。方策デコーダの目標は、確率を推定し、軌跡の中で最も可能性の高い次の行動を予測することです。この方法の著者は、Transformerモデルを使用したデコーダを発表しています。
前述したように、報酬はシーケンスから取り除きますが、潜在的な表現を追加します。しかし、潜在的な表現は、各手順でシーケンス要素としての報酬を置き換えるものではありません。この手法の著者は、Transformerアーキテクチャを用いた他のいくつかの研究で用いられている位置エンコーディングと同様に、単一の埋め込みベクトルによって変換された潜在表現を導入しています。
環境モデルデコーダは、方策デコーダと同様のアーキテクチャを持ちます。環境モデルデコーダは、出力のみで、「3つの頭」を持ち、最も可能性の高い後続の状態とそのコスト、および遷移報酬を予測します。
DTと同様に、モデルは教師あり訓練法を用いて訓練セットのデータで訓練されます。モデルは、その後の行動(Actor)、新しい状態への遷移とそのコスト(環境モデル)との軌跡を比較するように訓練されます。
テストと運用の間、最適な行動の選択は、与えられた計画水平線における予測軌道の候補の評価に基づいておこなわれます。計画された1つの候補軌道をコンパイルするために、報酬を伴う行動と状態の逐次生成が計画期間にわたって実行されます。その後、最適な軌道が選択され、最初の行動が実行されます。環境の新しい状態に遷移した後、アルゴリズム全体が繰り返されます。
ご覧のように、アルゴリズムは複数の軌道候補を計画するが、実行されるのは最適軌道の1行動のみです。このやり方は非効率に見えるかもしれませんが、数段階先の計画を立てることでリスクを最小限に抑えることができます。同時に、訪問した各状態を再評価する結果、軌道を時間的に修正することも可能です。
以下は、筆者によるこの方法を視覚化したものです。
2.MQL5を使用した実装
SPLT-Transformer法の理論的側面を考慮したので、MQL5を使用して提案されたアプローチを実装することに移りましょう。すぐに言いたいのは、私たちの実装は著者のアルゴリズムからこれまで以上に遠くなるということです。理由は私の主観的な認識です。本連載の経験全体が、金融市場の環境モデルを構築することの複雑さを示しています。どの試みも控えめな結果に終わりました。予測の精度は1~2ステップとかなり低いです。計画地平線が大きくなるにつれて、それは0になる傾向があります。そこで、軌跡の候補は作らず、現在の状態からいくつかの行動オプションの候補を生成するにとどめることにしました。
しかし、このアプローチでは、行動とその評価の間にギャップが生じます。上の可視化でわかるように、Actor方策と環境モデルは同じ入力データを受け取りますが、その場合、データはパラレルストリームで流れます。したがって、その後の状態と期待報酬を予測するとき、環境モデルはエージェントが選択する行動について何も知りません。ここでは、訓練サンプルからの過去の経験に基づいて、一定の確率で一定の仮定を語ることができるだけです。訓練サンプルは、現在使用されているものとは異なるActor方策に基づいて作成されていることにご注意ください。
著者のバージョンでは、エージェントの行動と予測状態を次の手順の軌跡に加えることで、これを平準化しています。しかし私たちの場合、その後の環境状態に対する計画の質が低いという経験を考慮すると、軌道にまったく協調していない状態や行動を追加してしまう危険性があります。これは、予測軌道の次の手順を計画する質をさらに低下させることにつながります。私の意見では、このような軌道の計画や評価の効率性は非常に疑わしいです。したがって、候補となる軌道の予測にリソースを浪費することはありません。
同時に、エージェントの行動と期待される報酬を比較できるメカニズムが必要です。一方では、Criticのモデルを使用することもできますが、これはアルゴリズムを根本的に壊してしまい、環境モデルを完全に排除してしまいます。もちろん、Criticとして使用する場合は別です。
しかし、私は本来のアルゴリズムに近い別のアプローチを試すことにしました。まず最初に、両方のストリームに1つのエンコーダを使用することにしました。得られた潜在状態は軌跡に追加され、2つのデコーダの入力に供給されます。Actorは初期データに基づいて予測行動を生成し、環境モデルは未来の割引報酬額を返します。
同じ入力データがあれば、モデルは一貫した結果を返すという考え方です。そのために、Actorモデルと環境モデルから確率を除外します。そうすることで、潜在表現に確率性を持たせ、複数の行動候補とそれに関連する予測状態推定値を生成することができます。これらの推定値に基づいて、候補となる行動をランク付けし、最適な加重手順を選択します。
実行される操作の回数を最適化するためには、もう1つのポイントに注意を払う必要があります。エンコーダの入力に同じ軌跡を与えることで、その内部のすべての層の結果を数学的な精度で繰り返すことができます。差分は、与えられた分布から標本化するときに、変分オートエンコーダ層でのみ形成されます。したがって、行動の候補を生成するには、指定された層をエンコーダの外側に移動させることが望ましくなります。これにより、各反復でエンコーダパスを1回だけ実行できるようになります。考えた末、変分オートエンコーダ層を環境モデルに移しました。
ワークフローを最適化する道をさらに進みました。我々の3つのモデルはすべて、入力データとして同じ軌道を使用します。ご存知のように、軌道の要素は一様ではありません。処理の前に、 埋め込み層を通過します。その結果、1つのモデルだけにデータを埋め込み、残りの2つのモデルでその結果のデータを使用するというアイデアが浮かびました。そのため、エンコーダには 埋め込み層のみを残しました。
もう1つあります。環境モデルとActorは、軌跡と潜在表現の連結ベクトルを入力として使用します。変分オートエンコーダ層が、確率的潜在表現形成のために環境モデルに移されたことはすでに決定しました。ここでは、ベクトルの組み合わせを実行し、すでに得られた結果をActorの入力に渡します。
では、上記のアイデアをコードに移します。モデルの説明を作成しましょう。いつものように、CreateDescriptionsメソッドで形成されます。パラメータで、このメソッドはモデルを記述する3つのオブジェクトへのポインタを受け取ります。
bool CreateDescriptions(CArrayObj *agent, CArrayObj *latent, CArrayObj *world) { //--- CLayerDescription *descr;
アーキテクチャの説明は、未処理のシーケンスデータを入力とするエンコーダのモデルから始めるべきでしょう。
//--- latent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
受信したデータをバッチ正規化層に通し、比較可能な形式にします。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
すでに正規化されたデータを埋め込み層に渡します。この層を覚えておいてください。そして、そこから環境モデルにデータを取り込みます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!latent.Add(descr)) { delete descr; return false; }
次に、得られた軌道をTransformerブロックを通して実行します。8つのSelf-Attentionヘッドを持つスパースなAttentionブロックを使用して、ブロックごとに4つの層を重ねました。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = prev_wout; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Attentionブロックの後、畳み込み層の次元を少し減らし、全結合層から決定ブロックにデータを渡します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
エンコーダモデルの出力には、活性化関数を使わず、1つの軌跡要素の埋め込みサイズの2倍の大きさの全結合ニューラル層を使用します。これは潜在表現分布の平均と分散で、次の手順で与えられた分布から潜在表現を標本化することができます。
次に環境モデルについて説明します。そのソースデータ層はエンコーダモデルの結果層と同じであり、変分オートエンコーダ層がそれに続きます。これにより、潜在的な表現を即座にサンプリングできるようになります。
//--- World if(!world) { world = new CArrayObj(); if(!world) return false; } //--- world.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; prev_count = descr.count = prev_count / 2; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
次に、軌跡埋め込みテンソルを追加しなければなりません。そのために、連結層を使用します。この層の出力で、環境モデルとActorの初期データを受け取ります。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.step = 4 * EmbeddingSize * HistoryBars; prev_count = descr.count = descr.step + prev_count; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
排出されたSelf-Attentionブロックにデータを渡してみましょう。エンコーダと同様、8つのヘッドと4つの層を使用しています。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
畳み込み層を使用してデータの次元を減らします。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; }
受信したデータを、意思決定ブロックの全結合パーセプトロンで処理します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
モデルの出力では、分解された報酬ベクトルが得られます。
このブロックの最後に、Actorモデルの構造を見てみましょう。前述したように、このモデルは環境モデルの隠れた状態から初期データを受け取ります。従って、ソースデータ層には十分な大きさが必要です。
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = EmbeddingSize * (4 * HistoryBars + 1); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
得られたデータはモデルの結果であり、追加の処理は必要ありません。そのため、すぐにスパースなAttentionブロックを使用します。ブロックパラメータは、前述のモデルで使用されたものと同様です。このように、3モデルとも同じTransformerアーキテクチャを採用しています。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
環境モデルと同様に、次元を減らし、全結合決定パーセプトロンでデータを処理します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
モデルの出力では、エージェントの行動のベクトルが形成されます。
また、この方法を実行するには、エンコーダの出力で形成される潜在表現の分布という形で、経験再生バッファに追加のエンティティを追加する必要があることにも注意する必要があります。そのために、環境状態を記述する構造の中に追加の配列を作成します。
struct SState { ....... ....... float latent[2 * EmbeddingSize]; ....... ....... }
新しい配列のサイズは、分布の平均値と分散を含むので、2つの埋め込みに等しくなります。
配列の宣言に加えて、すべての構造体メソッドにそのメンテナンスを追加する必要があります。
- 初期値による初期化
SState::SState(void) { ....... ....... ArrayInitialize(latent, 0); }
- 構造体の清掃
void Clear(void) { ....... ....... ArrayInitialize(latent, 0); }
- 構造体のコピー
void operator=(const SState &obj) { ....... ....... ArrayCopy(latent, obj.latent); }
- 構造体の保存
bool SState::Save(int file_handle) { ....... ....... //--- total = ArraySize(latent); if(FileWriteInteger(file_handle, total) < sizeof(int)) return false; for(int i = 0; i < total; i++) if(FileWriteFloat(file_handle, latent[i]) < sizeof(float)) return false; //--- return true; }
- ファイルから構造体をアップロードする
bool SState::Load(int file_handle) { ....... ....... //--- total = FileReadInteger(file_handle); if(total != ArraySize(latent)) return false; //--- for(int i = 0; i < total; i++) { if(FileIsEnding(file_handle)) return false; latent[i] = FileReadFloat(file_handle); } //--- return true; }
訓練済みモデルのアーキテクチャを理解し、データ構造体を更新しました。次の手順は、訓練のためのデータ収集です。この機能は「...\SPLT\Research.mq5」EAで実行されます。SPLT-Transformer法は、候補軌道(私たちの実装では候補行動)の生成を提供します。このような候補の数は、モデルのハイパーパラメータの1つであり、EAの外部パラメータに含まれます。
input int Agents = 5;
覚えていらっしゃるかもしれませんが、ストラテジーテスターの最適化モードにおいて、並列環境調査エージェントの数を示す補助パラメータとしてAgents外部パラメータを使用しました。ここで、EAサービスパラメータの名前を変更します。
input int OptimizationAgents = 1;
さらに、訓練サンプルを収集するためのすべてのEAのメソッドについて、詳しくは説明しません。そのアルゴリズムについては、この連載ですでに何度も説明してきました。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。ここでは、実装されたアルゴリズムの主要な機能を含み、環境との直接対話するOnTickメソッドだけについて考えてみましょう。
手法の最初に、いつものように、新しいバーを開くイベントの発生を確認し、必要に応じて、価格の動きと分析指標の指標の履歴データを更新します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
その後、モデル用のソースデータのバッファを作成します。まず、価格の動きと分析指標の値に関する過去のデータを入力します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates(); //--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次に、現在の口座状況と未決済ポジションに関する情報を追加します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
次に、データバッファにタイムスタンプを追加することで、データの時間的識別をおこないます。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
私たちをこのような環境に導いたエージェントの最後の行動を示します。
//--- Prev action
bState.AddArray(AgentResult);
現在の手順に関する収集されたデータは、潜在的な表現を生成するのに十分であり、エンコーダのフォワードパス法を呼び出します。同時に、実施された操作の監視も怠りません。必要に応じてユーザーに知らせます。
//--- Latent representation ResetLastError(); if(!Latent.feedForward(GetPointer(bState), 1, false)) { PrintFormat("Error of Latent model feed forward: %d",GetLastError()); return; }
潜在表現の作成に成功したら、デコーダの作成に移ります。
この段階では、候補となる行動を起こさなければならないことを忘れないでください。ループを形成します。その反復回数は、必要な候補の数に等しく、EAの外部パラメータに示されます。
生成された行動候補の情報を保存するために、actions行列とvalues行列を作成します。まず、行動ベクトルを記録します。もう1つは、その方策を適用した結果、期待される報酬を含むことです。
前述したように、エンコーダモデルでは、潜在表現の分布に関するデータのみを生成します。潜在表現ベクトルの標本化は環境モデルでおこなわれます。そのため、ループの本体では、まず環境モデルをフォワードパスします。次に、環境モデルの隠れた状態を入力として使用するエージェントのフォワードパスメソッドを呼び出します。
モデルのダイレクトパスの結果は、あらかじめ用意された行列に保存されます。
matrix<float> actions = matrix<float>::Zeros(Agents, NActions); matrix<float> values = matrix<float>::Zeros(Agents, NRewards); for(ulong i = 0; i < (ulong)Agents; i++) { if(!World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer) || !Agent.feedForward(GetPointer(World), 2,(CBufferFloat *)NULL)) return; vector<float> result; Agent.getResults(result); actions.Row(result, i); World.getResults(result); values.Row(result, i); }
確率的方策の使用は、学習された分布内のいずれかの事象の発生確率が等しいという仮定に基づいています。したがって、標本化された各候補行動は、環境において期待される報酬を受け取る確率が等しくなります。私たちの目標は、最大限の利益を得ることです。つまり、確率が等しい条件下では、期待リターンが最大となる行動を選ぶということです。
お分かりのように、私たちの行列には行相関があります。values行列で最大の期待報酬を持つ行を探し、actions行列の対応する行から行動を選択します。
vector<float> temp = values.Sum(1); temp = actions.Row(temp.ArgMax());
選択された行動は環境でおこなわれます。
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
環境との相互作用の結果は、あらかじめ用意された構造体に集められ、経験再生バッファに保存されます。
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; Latent.getResults(sState.latent); if(!Base.Add(sState)) ExpertRemove(); }
これで、環境と相互作用し、訓練サンプルデータを収集するためのEAの紹介を終了します。すべてのコードは添付ファイルにあります。ここには、記事で使用されているすべてのプログラムの完全なコードもあります。オフラインモデル訓練EA「...\SPLT\Study.mq5」に移ります。
EAの初期化メソッドでは、まず訓練セットをアップロードします。操作を制御することを忘れないでください。オフラインのモデル訓練では、これが唯一のデータ源であり、これがないと残りのプロセスが不可能になります。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
次に、事前に訓練されたモデルを読み込み、必要に応じて新しいモデルを作成します。
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !World.Load(FileName + "Wld.nnw", temp, temp, temp, dtStudied, true) || !Latent.Load(FileName + "Lat.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *latent = new CArrayObj(); CArrayObj *world = new CArrayObj(); if(!CreateDescriptions(agent, latent, world)) { delete agent; delete latent; delete world; return INIT_FAILED; } if(!Agent.Create(agent) || !World.Create(world) || !Latent.Create(latent)) { delete agent; delete latent; delete world; return INIT_FAILED; } delete agent; delete latent; delete world; //--- }
お気づきかもしれませんが、訓練サンプルを収集するためのEAのアルゴリズムは、多くの場合、訓練済みモデル間のデータ転送を使用しています。訓練プロセスでは、データの流れがフォワードパスとリバースパスの2方向におこなわれるため、伝送されるデータ量が増加します。OpenCLコンテキストとメインメモリ間の不要なデータコピー操作を排除するため、すべてのモデルを単一のOpenCLコンテキストに転送します。
COpenCL *opcl = Agent.GetOpenCL(); Latent.SetOpenCL(opcl); World.SetOpenCL(opcl);
次に、訓練済みモデルのアーキテクチャの整合性を確認します。
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Agent does not match the actions count (%d <> %d)", 6, Result.Total()); return INIT_FAILED; } //--- Latent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Latent model doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Latent.Clear();
すべての制御が成功した後、モデル訓練開始のイベントを生成し、EA初期化メソッドの動作を完了します。
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
モデルを訓練する実際のプロセスは、Trainメソッドにまとめられています。メソッドの本体では、経験再生バッファ内の軌跡の数を決定し、訓練の開始時刻をローカル変数に記録します。これは、モデル訓練の進捗状況を定期的にユーザーに知らせるためのガイドとなります。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
私たちのモデルはGPTアーキテクチャを使用しており、ソースデータのシーケンスに敏感であることを思い出してください。これまでと同じように、入れ子式ループシステムを使用してモデルを訓練します。外部ループでは、経験再生バッファと環境の初期状態から軌跡を標本化します。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
次に、モデルバッファを初期化し、ネストされたループを作成します。このループでは、モデル入力として過去のデータの断片を順次投入します。
Actions = vector<float>::Zeros(NActions); Latent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) {
ネストされたループの本体では、訓練データの収集を思わせるような操作ができます。また、ソースデータバッファを埋めます。ただ、環境からデータを要求するのではなく、経験再生バッファからデータを抽出します。同時に、データ記録の順序も厳守します。まず、値動きと分析指標の情報をソースデータバッファに入力します。
//--- History data
State.AssignArray(Buffer[tr].States[state].state);
そして、口座状況と未決済ポジションに関するデータがあります。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
データがタイムスタンプで識別されます。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
この状態に至ったエージェントの行動を必ず示します。
//--- Prev action
State.AddArray(Actions);
もう一度、一貫性の厳守を強調したいと思います。バッファのデータには名前がありません。モデルは、バッファ内の位置に応じてデータを評価します。順序が変わると、モデルはまったく別の状態として認識します。決断の結果はまったく異なり、予測不可能なものになるでしょう。したがって、モデルを混乱させず、常に適切な解を得るためには、モデルの訓練と運用のすべての段階で、データの順序を厳密に守る必要があります。
生データバッファを収集した後、まずエンコーダと環境モデルのフォワードパスを実行します。
//--- Latent and Wordl if(!Latent.feedForward(GetPointer(State)) || !World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
なお、訓練中に候補となる行動は生成しません。さらに、環境モデルとActorの方策の訓練は別々におこなわれます。これはモデル訓練の特殊性によるものです。
環境モデルは、過去の軌跡に基づいてエージェントの方針を推定し、現在の環境状態と使用された方針を考慮して、未来の報酬の受け取りを予測するように訓練されます。同時に、潜在的な表現の分布も調整します。そのためには、フォワードパスが成功した後、環境モデルとエンコーダのバックワードパスを実行し、環境モデルの予測誤差と経験再生バッファからの実際の報酬を最小化することを目指します。
Actions.Assign(Buffer[tr].States[state].rewards); vector<float> result; World.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!World.backProp(Result,GetPointer(Latent),LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL,LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
環境モデルのバックパスの後、まずエンコーダの部分的なバックパスを実行し、環境モデルの要件に合わせて埋め込みパラメータを最適化することにご注意ください。その後、エンコーダのフルリバースパスを実行し、その間に潜在表現の分布が最適化されます。
潜在的な状態と実行された行動を一致させるために、Actor方策を最適化します。そこで、経験再生バッファから潜在表現分布を抽出し、それを環境モデルの入力に与えて潜在表現を再標本化します。次に、環境モデルとActorのダイレクトパスを実行します。
//--- Policy Feed Forward Result.AssignArray(Buffer[tr].States[state+1].latent); Latent.GetLayerOutput(LatentLayer,Result2); if(Result2.GetIndex()>=0) Result2.BufferWrite(); if(!World.feedForward(Result, 1, false, Result2) || !Agent.feedForward(GetPointer(World),2,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次に、Actorのリバースパスを実行し、予測された行動と、経験再生バッファから実際に実行された行動との誤差を最小化します。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result,NULL,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
こうすることで、Actorの方針を訓練し、より予測しやすくするのです。同時に、収益性を理解するために、環境モデルを訓練して過去の軌跡を評価します。エンコーダを訓練し、入ってくる軌跡を抽出して、環境の傾向やActorの現在の方針に関する基本的な情報を抽出します。
これらすべてを組み合わせることで、環境の確率性と利益を上げる確率を考慮した、非常に興味深いActor方策を作成することができます。
モデルの更新操作が正常に完了すると、訓練の進捗状況をユーザーに通知し、ネストされたループシステムの次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "World", iter * 100.0 / (double)(Iterations), World.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
ループシステムのすべての反復が完了したら、コメント欄を消去します。モデルの訓練結果はジャーナルに表示されます。EAを終了します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "World", World.getRecentAverageError()); ExpertRemove(); //--- }
以上で、SPLT-Transformer法の解釈に関するモデル訓練EAの考察を終えます。EAのすべてのコードと記事で使用したすべてのプログラムは、添付ファイルにあります。また、「...\SPLT\Test.mq5」モデルテストEAのコードもあります。この記事ではその方法については触れません。EAの構造は、以前の記事で取り上げた同様のEAを繰り返しています。OnTick関数における提示アルゴリズムの実装機能は、訓練サンプルのデータ収集EAにおける同様の方法の実装を完全に繰り返します。添付ファイルにあるこのEAをよく理解することをお勧めします。
MetaTrader 5のストラテジーテスターで履歴データを使用したモデルのテストです。
3.テスト
モデルはEURUSD H1の最初の7ヶ月間の履歴データで訓練されました。すべての指標のデフォルトパラメータは、追加の最適化なしに使用されます。
まず、ストラテジーテスターの低速最適化モードで訓練サンプル収集EAを起動します。これにより、複数のテストエージェントが並行してデータを収集することができます。こうして、データ収集に費やす時間を最小限に抑えながら、経験再生バッファ内の軌跡の数を増やします。
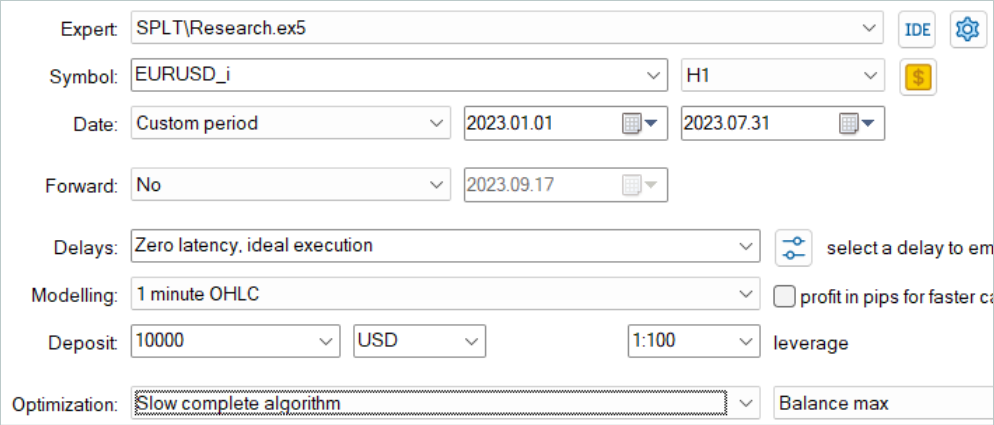
考慮されているアルゴリズムは、モデルがオフラインでのみ訓練されることを想定しています。したがって、その性能をテストするには、経験再生バッファを最大にし、さまざまな軌道でそれを満たすことを提案します。しかし、候補となる行動の生成は、かなりコストのかかるプロセスであることは注目に値します。候補の数が増えれば、データ収集のコストも増えます。
データを収集した後、前回と同様に軌跡を追加収集することなくモデルを訓練しました。モデルを訓練するのは、いつものように長いプロセスです。軌跡の追加収集は予定していなかったので、軌跡の数を増やし、コンピューターに長期訓練を任せました。
次に、訓練したモデルを、訓練セットに含まれていない2023年8月の過去のデータでテストしました。
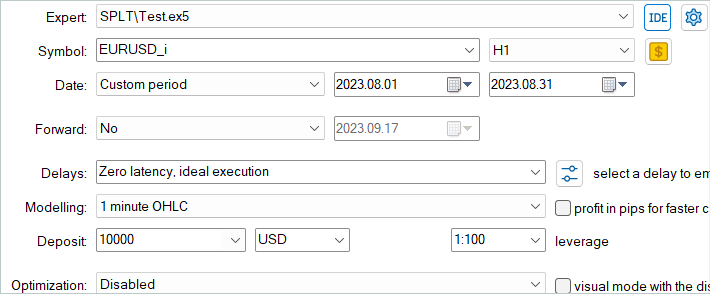
テスト結果によると、このモデルはわずかな利益とかなり正確な取引を示しました。SPLT-Transformer方式は自律走行のために開発されたものであり、最大限のリスク低減を提供するものであることを思い出してください。
テストのグラフでは、ほぼ全月を通じて残高が増加する傾向が見られます。不採算取引の連続は、月の最終週にのみ観察されます。しかし、それまでに累積された利益は損失をカバーするのに十分でした。全体として、月末にはわずかな利益が計上されました。


全テスト期間中、このモデルは最小量のポジションを16回しか開けませんでした。利益が出ている取引の割合は37.5%に過ぎません。しかし、平均的な勝ちトレードは平均的な負けトレードよりも70%近く大きいです。その結果、テスト結果によれば、プロフィットファクターは1.02となりました。
結論
この記事では、楽観的なエージェントの行動に関連するオフライン強化学習の問題を解決するために開発された革新的な手法であるSPLT-Transformerを紹介しました。信頼性が高く効率的なエージェント方策の構築は、方策とワールドモデルを表す2つの別々のモデルを用いて実現されます。
候補軌道生成アルゴリズムを含むSPLT-Transformerのコアコンポーネントは、さまざまなシナリオをシミュレートし、未来起こりうるさまざまな結果を考慮に入れて決定を下すことを可能にします。このため、提示された方法は、様々な確率的環境において高度に適応的で安全です。この手法の著者らは、自律走行分野での実験結果を提供し、既存の手法と比較してSPLT-Transformerの優れた性能を確認しました。
この記事の実践編では、議論されている方法を少し簡略化した独自の解釈を作成しました。その結果得られたモデルを訓練し、テストしました。テストの結果、モデルは状況に応じて慎重な行動と楽観的な行動の両方を示すことができることが実証されました。このため、ミッションクリティカルなシステムには理想的な選択肢となります。
全体として、この方法はさらなる発展に値します。モデルをもっと徹底的に訓練すれば、より良い結果が得られると私は思います。
この連載で紹介したプログラムはすべて、問題のアルゴリズムを実証しテストするためだけに作成されたものであることを、もう一度お断りしておきます。実際の口座での取引には適していません。実際の取引で特定のモデルを使用する前に、徹底的に訓練し、テストすることをお勧めします。
リンク
- Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
- ニューラルネットワークが簡単に(第58回):Decision Transformer (DT)
- ニューラルネットワークが簡単に(第59回):コントロールの二分法(DoC)
- ニューラルネットワークが簡単に(第60回):Online Decision Transformer (ODT)
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13639
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ニューラルネットワーク - それはシンプルだ(第61回)
第61回、結果は金額で見える?
ニューラルネットワーク - それはシンプルだ(第61回)
61の部分、結果を金額で見ることができるだろうか?
この著者は、純粋に理論的な論文を取り上げ、それがどのように可能かを一般的な言葉で説明している:
元記事を見て、ドミトリーがどのような仕事をしたのか自分の目で確かめてください -https://arxiv.org/abs/2207.10295。