
Neuronale Netze leicht gemacht (Teil 62): Verwendung des Entscheidungs-Transformer in hierarchischen Modellen

Einführung
Bei der Lösung realer Probleme stoßen wir häufig auf das Problem stochastischer und sich dynamisch verändernder Umgebungen, was uns zwingt, nach neuen adaptiven Algorithmen zu suchen. In den letzten Jahrzehnten wurden erhebliche Anstrengungen unternommen, um Techniken des Verstärkungslernens (Reinforcement Learning, RL) zu entwickeln, mit denen Agenten trainiert werden können, sich an eine Vielzahl von Umgebungen und Aufgaben anzupassen. Die Anwendung von RL in der realen Welt steht jedoch vor einer Reihe von Herausforderungen, darunter das Offline-Lernen in variablen und stochastischen Umgebungen sowie die Schwierigkeiten bei der Planung und Steuerung in hochdimensionalen Räumen von Zuständen und Aktionen.
Bei der Lösung komplexer Probleme ist es oft am effizientesten, ein Problem in seine einzelnen Teilaufgaben zu zerlegen. Wir haben über die Vorteile dieses Ansatzes bei der Betrachtung hierarchischer Methoden gesprochen. Solche integrierten Ansätze ermöglichen die Erstellung von adaptiveren Modellen.
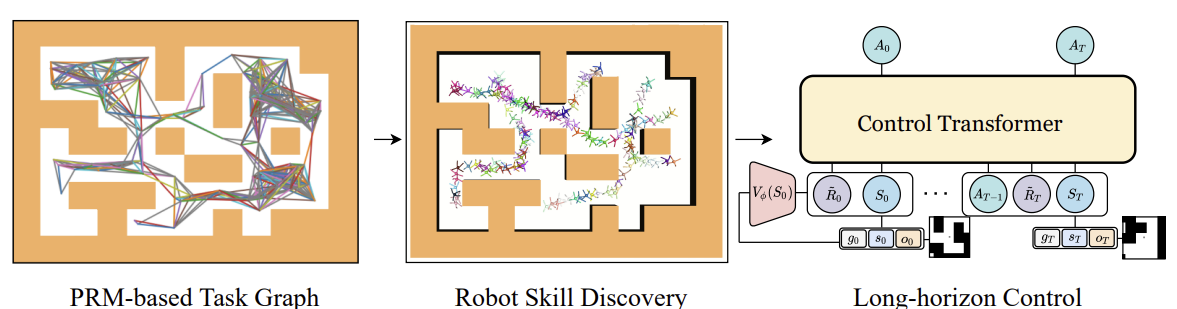
Bisher haben wir uns mit hierarchischen Modellen zur Lösung von Problemen beschäftigt, sozusagen mit dem klassischen Ansatz des Markov-Prozesses. Die Vorteile hierarchischer Ansätze gelten jedoch auch für Probleme der Sequenzanalyse. Ein solcher Algorithmus ist der Kontrolltransformator, der in dem Artikel „Control Transformer: Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling“. Die Autoren der Methode positionieren sie als eine neue Architektur zur Lösung komplexer Kontroll- und Navigationsprobleme auf der Grundlage von Reinforcement Learning. Diese Methode kombiniert moderne Methoden des Verstärkungslernens, der Planung und des maschinellen Lernens, was es uns ermöglicht, adaptive Kontrollstrategien in einer Vielzahl von Umgebungen zu entwickeln.
Control Transformer eröffnet neue Perspektiven für die Lösung komplexer Steuerungsprobleme in der Robotik, dem autonomen Fahren und anderen Bereichen. Ich schlage vor, die Aussichten für die Anwendung dieser Methode bei der Lösung unserer Handelsprobleme zu untersuchen.
1. Algorithmus des Control-Transformers
Der Control-Transformer-Algorithmus ist eine recht komplexe Methode und umfasst mehrere separate Blöcke, was für hierarchische Modelle charakteristisch ist. Es sollte auch erwähnt werden, dass der Algorithmus entwickelt wurde, um das Verhalten von Robotern zu steuern und zu kontrollieren. Daher wird der Algorithmus in diesem Zusammenhang beschrieben.
Um das Problem der Kontrolle über einen langen Planungshorizont zu lösen, schlagen die Autoren der Methode vor, diesen in kleinere Teilaufgaben in Form von bestimmten Segmenten mit begrenztem Abstand zu zerlegen. Die Autoren der Methode verwenden probabilistische Straßenkarten, um G zu erstellen, wobei die Eckpunkte Punkte sind und die Kanten die Möglichkeit anzeigen, sich zwischen verbundenen Punkten mithilfe eines lokalen Planers (scheduler) zu bewegen. Der Graph wird auf der Grundlage einer Stichprobe von n zufälligen Punkten in der Umgebung konstruiert, die anschließend mit benachbarten Punkten in einem Abstand von höchstens d (Hyperparameter) verbunden werden und eine Kante im Graphen bilden, vorausgesetzt, es gibt einen Pfad zwischen den Punkten.
In dem sich ergebenden G-Graphen kann man also jeden beliebigen Zielpunkt Xg von jedem beliebigen Startpunkt X0 aus erreichen. Dazu wird der Graph nach den nächsten Nachbarn des Start- und Zielpunktes durchsucht. Dann erhalten wir eine Folge von Wegpunkten (Trajektorie) mit Hilfe des Algorithmus zur Suche des kürzesten Weges. Danach kann sich der Roboter vom Ausgangszustand zum Ziel bewegen, wobei er die Aktionen der Politik πc der lokalen Steuerung ausführt. Eine Abfolge von Wegpunkten oder ein Plan, an dem sich die Politik πc orientiert, kann festgelegt oder aktualisiert werden, während sich der Roboter fortbewegt.
Um die lokale Politik πc zu trainieren, verwendeten die Autoren der Methode die Methode des zielgerichteten Verstärkungslernens (GCRL). In diesem Fall wird das Problem durch einen Markov-Entscheidungsprozess mit einer auf das Ziel gerichteten Bedingung modelliert. Es wird vorgeschlagen, dass die Planung anhand von Beispielen zur Festlegung von Zielen und zum Training von Strategien genutzt werden kann.
Zu diesem Zweck verwenden wir zunächst probabilistische Straßenkarten, um den Graphen G wie oben beschrieben zu erhalten. Anschließend wird für jede Lernepisode eine Kante aus dem Graphen ausgewählt. Die Kante dient als Anfang und Ziel dieser Episode. Dieser Prozess ist mit jedem zielbasierten Lernalgorithmus kompatibel. Die Autoren verwendeten Soft Actor-Critic in ihren Experimenten mit dichten Belohnungen, die proportional zum Fortschritt in Richtung eines Ziels waren. Low-Level-Strategien können effizient trainiert werden, da der Zustandsraum der Strategien nur Informationen über ihre eigene Position enthält und sie nicht lernen müssen, die Beschränkung zu umgehen.
Nachdem wir die lokale Politik πc trainiert haben, müssen wir einen Prozess einrichten, der sie zur Erreichung des globalen Ziels führt. Mit anderen Worten: Wir müssen ein Modell trainieren, das geplante Trajektorien erzeugt. Die Ziele und Belohnungen dieses Modells werden in Bezug auf das Endziel festgelegt, nicht auf die von πc verfolgten Wegpunkte. Um die globalen Ziele des Modells zu erreichen, sind natürlich mehr Ausgangsdaten erforderlich. Hochdimensionale Beobachtungen und andere verfügbare Informationen werden zu den niedrigdimensionalen lokalen Zustandsdaten hinzugefügt. Es kann zum Beispiel eine lokale Karte sein.
Um ein Modell anhand von Daten zu trainieren, die mit Hilfe eines stichprobenbasierten Designs gesammelt wurden, betrachten wir ein Sequenzmodellierungsproblem, das die Orientierung auf das Erreichen des Ziels beinhaltet. In ihrer Arbeit besprechen die Autoren der Methode auch eine teilweise beobachtbare Multi-Task-Umgebung, in der die Strategie in mehreren Umgebungen mit der gleichen Navigationsaufgabe funktionieren kann, aber mit einer anderen Struktur für jede Umgebung. Obwohl es möglich ist, die autoregressive Handlungsvorhersage auf dieser Sequenz zu lernen, stoßen wir auf einige Probleme. Wie bei DT wird das optimale RTG (Return-To-Go, Zurück auf Los) als konstant angenommen, da wir die optimale anfängliche prädiktive Belohnung nicht kennen, die von der unbekannten Struktur der Umgebung abhängt. Sie kann sich in verschiedenen Episoden ändern. Sie hängt auch von den Ausgangszuständen und Zielpositionen ab. Daher müssen wir Veränderungen erforschen, die es DT ermöglichen, sich auf unbekannte Umgebungen zu verallgemeinern und von jeder Startposition aus zu jedem Ziel zu arbeiten.
Ein Ansatz besteht darin, die vollständige RTG-Verteilung anhand von Offline-Daten zu trainieren. Dann müssen wir während des Betriebs Bedingungen aus dieser Verteilung auswählen. Es ist jedoch schwierig, die vollständige Verteilung von RTGs in einer zielorientierten Aufgabe zu trainieren, sodass man RTGs in unbekannten Umgebungen verallgemeinern und vorhersagen kann. Stattdessen schlagen die Autoren der Methode vor, die Durchschnittswertfunktion für diese Verteilung zu trainieren. Die Funktion schätzt die erwartete Belohnung am Punkt S für ein bestimmtes Ziel g innerhalb der Trajektorie T. Diese Funktion basiert auch nicht auf der Vergangenheit, da wir zu Beginn der Operation die anfänglich erwartete Belohnung R̃0 vorhersagen. Anschließend passen wir das RTG an die tatsächliche Belohnung durch die Umwelt an. Die Wertfunktion wird als separates neuronales Netz parametriert und mit MSE trainiert.
Um ein optimaleres Verhalten zu erreichen, können wir den trainierten Wert um ein bestimmtes konstantes Verhältnis anpassen. Darüber hinaus ist es möglich, die Wertfunktion nur auf den besten Trajektorien zu trainieren oder auf solchen, die eine vordefinierte Bedingung erfüllen.
Im Folgenden wird die Visualisierung der Methode des Steuertransformators durch den Autor vorgestellt.
Eines der häufigsten Probleme beim Offline-Lernen ist die Verschiebung der Verteilung, wenn die trainierte Strategie in die Praxis umgesetzt wird und die tatsächliche Verteilung der Trajektorien nicht mit der Verteilung der Trainingsmenge übereinstimmt. Dies kann dazu führen, dass sich Fehler häufen und die Strategie suboptimal wird. Um dieses Problem zu lösen, schlagen die Autoren der Methode vor, die Trainingsmenge nach der Offline-Trainingsphase mit Hilfe der aktuellen Modellpolitik zu erweitern und die Modelle anschließend offline abzustimmen.
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte der Control-Transformer-Methode gehen wir zu ihrer Implementierung mit MQL5 über. Wie bereits erwähnt, ist der Algorithmus komplex. Daher werden wir während des Umsetzungsprozesses die Entwicklungen aus einer Reihe früherer Artikel nutzen. Zu Beginn unserer Überlegungen zu dieser Methode haben wir ein Diagramm mit möglichen Bewegungen erstellt.
2.1. Sammlung von Trainingssätzen
In unserem Fall einer stochastischen Umgebung und eines kontinuierlichen Aktionsraums kann die Konstruktion eines solchen Graphen eine nicht-triviale Aufgabe sein. Wir beschlossen, das Problem von der anderen Seite her anzugehen und die bei der Entwicklung der Methode Go-Explore gewonnenen Erfahrungen zu nutzen. Wir haben kleinere Anpassungen am EA „...\CT\Faza1.mq5“ vorgenommen und mögliche Trajektorien von Handelsoperationen innerhalb des Trainingszeitraums gesammelt. Dabei haben wir Trajektorien mit maximaler Rentabilität ausgewählt.
Zu diesem Zweck haben wir die maximale Anzahl der gesampelten Aktionen und die minimale Trajektorienlänge in die externen Parameter des EA aufgenommen. Das Auftreten dieser Parameter ist darauf zurückzuführen, dass die Wahrscheinlichkeit, eine akzeptable Trajektorie über das gesamte Trainingsintervall in einem Durchgang zu erfassen, eher gering ist (nahe bei „0“). Viel wahrscheinlicher ist es, dass nach und nach kleine Bereiche mit gewinnbringenden Transaktionen ausgewählt werden, die dann zu einer gemeinsamen gewinnbringenden Abfolge von Aktionen zusammengefasst werden.
input int MaxSteps = 48; input int MinBars = 20;
Ich möchte Sie gleich daran erinnern, dass der EA keine neuronalen Netzwerkmodelle verwendet. Alle Aktionen werden aus einer Gleichverteilung entnommen.
In der EA-Initialisierungsmethode werden zunächst die Objekte der Klassen Indikator und Handelsoperation initialisiert.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Wir initialisieren die erforderlichen Variablen und nehmen die Trajektorie und den Anfangszustand auf, um die zuvor gespeicherte Trajektorie fortzusetzen. Eine solche Stichprobe ist natürlich nur möglich, wenn zuvor gespeicherte Trajektorien vorhanden sind.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); AgentResult = vector<float>::Zeros(NActions); //--- int error_code; if(Buffer.Size() > 0 || LoadTotalBase()) { int tr = int(MathRand() / 32767.0 * Buffer.Size()); Loaded = Buffer[tr]; StartBar = MathMax(0,Loaded.Total - int(MathMax(Math::MathRandomNormal(0.5, 0.5, error_code), 0) * MaxSteps)); } //--- return(INIT_SUCCEEDED); }
Wenn es keine zuvor durchlaufenen Bahnen gibt, beginnt der EA mit dem ersten Balken, um Aktionen zu testen.
Die direkte Datenerfassung erfolgt in der Tick-Handling-Funktion OnTick. Auch hier wird geprüft, ob das Eröffnungsereignis eines neuen Balkens eingetreten ist, und gegebenenfalls werden historische Daten über die Bewegung des Instruments und der Indikatorparameter geladen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- CurrentBar++; int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Wir übertragen die geladenen Daten in die Struktur zum Einstellen in den Erlebniswiedergabepuffer.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Fügen wir die Informationen über den Kontostatus und Belohnungen aus der Umgebung hinzu.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(sState.account[1] / PrevBalance - 1.0);
Neudefinition der internen Variablen.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Als Nächstes müssen wir die Aktion des Agenten auswählen. Wie bereits erwähnt, verwenden wir hier keine Modelle. Stattdessen wird geprüft, ob die Stichprobenphase begonnen hat. Wenn wir eine zuvor gespeicherte Trajektorie wiederholen, übernehmen wir die Aktion aus unserer Trajektorie. Wenn der Stichprobenzeitraum erreicht ist, erzeugen wir einen Aktionsvektor aus einer Gleichverteilung.
vector<float> temp = vector<float>::Zeros(NActions); if((CurrentBar - StartBar) < MaxSteps) if(CurrentBar < StartBar) temp.Assign(Loaded.States[CurrentBar].action); else temp = SampleAction(NActions);
Die daraus resultierende Aktion wird in der Umgebung durchgeführt.
//--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Die Ergebnisse der Interaktion werden dem Wiedergabepuffer für das Erlebnis hinzugefügt.
//--- int shift = BarDescr * (NBarInPattern - 1); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState) || (CurrentBar - StartBar) >= MaxSteps) ExpertRemove(); //--- }
Hier wird geprüft, ob die maximale Anzahl der abgetasteten Schritte erreicht ist, und gegebenenfalls die Beendigung des Programms eingeleitet.
Ein paar Worte zu den Änderungen in der Methode zum Hinzufügen von Trajektorien zum Erfahrungswiedergabepuffer. Während früher Trajektorien nach der FIFO-Methode (first in, first out) hinzugefügt wurden, speichern wir jetzt die profitabelsten Durchgänge. Deshalb überprüfen wir nach Abschluss des nächsten Durchgangs zunächst die Größe unseres Erfahrungswiedergabepuffers.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(total >= MaxReplayBuffer) {
Wenn die Puffergröße erreicht ist, suchen wir zunächst die Passage mit der geringsten Rentabilität aus den zuvor gespeicherten Passagen.
for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Wir vergleichen die Rentabilität des neuen Durchgangs mit dem minimalen Durchgang im Erfahrungswiedergabepuffer und setzen gegebenenfalls einen neuen Durchgang anstelle des minimalen Durchgangs.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
Damit entfällt die aufwändige Sortierung der Daten im Puffer. In einem Durchgang bestimmen wir den Mindestwert und die Durchführbarkeit der Speicherung der neuen Trajektorie.
Wenn die Grenzgröße des Erfahrungswiedergabepuffers noch nicht erreicht ist, fügen wir einfach einen neuen Durchgang hinzu und schließen den Vorgang der Methode ab.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Damit ist unsere Einführung in die Umweltinteraktion EA abgeschlossen. Den vollständigen Code finden Sie im Anhang.
2.2. Training von Fertigkeiten
Der nächste Schritt ist die Einrichtung einer lokalen EA-Training. Die lokale Richtlinie spielt die Rolle eines Executors, der die Anweisungen eines übergeordneten Planers ausführt. Zur Vereinfachung des lokalen Politikmodells selbst und im Sinne hierarchischer Systeme haben wir beschlossen, den aktuellen Zustand der Umgebung nicht als Input für das Modell zu verwenden. In unserer Vision wird es sich um ein Modell handeln, das über eine Reihe von Fähigkeiten verfügt. Die Wahl der zu verwendenden Fertigkeit bleibt dem Planer überlassen. Gleichzeitig wird das lokale Politikmodell selbst nicht den Zustand der Umwelt analysieren.
Für das Training von Fähigkeiten werden wir die Architektur des Auto-Encoders und die Entwicklungen der zuvor diskutierten hierarchischen Modelle nutzen. Während des Trainings wird eine Fähigkeit nach dem Zufallsprinzip in die Eingabe unseres lokalen Politikmodells eingegeben. Der Diskriminator wird versuchen, die verwendete Fähigkeit zu identifizieren.
Hier müssen wir die erforderliche Anzahl der auszubildenden Fähigkeiten bestimmen. Auch hier verweisen wir auf unsere früheren Arbeiten. Bei der Betrachtung von Clustermethoden haben wir die optimale Anzahl von Clustern im Bereich von 100-500 ermittelt. Um einen Fachkräftemangel zu vermeiden, legen wir die Größe des Eingabevektors für die lokale Politik auf 512 Elemente fest.
#define WorkerInput 512
Die Architekturen der lokalen Politik- und Diskriminatormodelle werden im Folgenden vorgestellt. Wir haben diese Modelle nicht übermäßig verkompliziert. Wir erwarten einen One-Hot-Vektor oder einen durch die SoftMax-Funktion normalisierten Datenvektor als Eingabe für das lokale Politikmodell. Aus diesem Grund haben wir nach der Quelldatenebene keine Batch-Normalisierungsebene hinzugefügt.
bool CreateWorkerDescriptions(CArrayObj *worker, CArrayObj *descriminator) { //--- CLayerDescription *descr; //--- if(!worker) { worker = new CArrayObj(); if(!worker) return false; } //--- Worker worker.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Darauf folgen zwei vollständig verbundene neuronale Schichten mit unterschiedlichen Aktivierungsfunktionen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Danach reduzieren wir die Dimension der Schicht und normalisieren die Daten mit der SoftMax-Funktion im Kontext des Aktionsraums unseres Agenten.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Die Ausgabe der lokalen Strategie ist eine vollständig verbundene neuronale Schicht, deren Größe dem Aktionsvektor des Agenten entspricht.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Das Diskriminatormodell hat eine etwas umgekehrte Architektur, ähnlich wie der Decoder. Der Modelleingang erhält den Aktionsvektor des Agenten, der vom lokalen Politikmodell generiert wird. Auch hier wird die Schicht der Stapelnormalisierung nicht verwendet.
//--- Descriminator if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } //--- descriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Als Nächstes folgen die gleichen vollständig verbundenen Schichten, die wir in der lokalen Politik verwendet haben.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Dann ändern wir die Dimension auf die Anzahl der verwendeten Fähigkeiten und normalisieren die Wahrscheinlichkeiten der Verwendung der Fähigkeiten mit der SoftMax-Funktion.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Wir haben die Modelle so entwickelt, dass sie so einfach wie möglich sind. Dadurch können wir ihre Arbeit sowohl in der Training als auch im Betrieb so weit wie möglich beschleunigen.
Um Fähigkeiten zu trainieren, werden wir den EA „...\CT\StudyWorker.mq5“ erstellen. Wir werden uns nicht lange mit einer detaillierten Untersuchung aller EA-Methoden aufhalten. Betrachten wir nur die Methode des direkten Trainings von Train-Modellen.
Im Hauptteil dieser Methode wird eine Schleife von Trainingsmodellen entsprechend der im externen Parameter EA angegebenen Anzahl von Iterationen angeordnet. Innerhalb der Schleife erzeugen wir zunächst einen zufälligen One-Hot-Vektor, dessen Größe der Anzahl der Fähigkeiten entspricht.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { Data.BufferInit(WorkerInput, 0); int pos = int(MathRand() / 32767.0 * (WorkerInput - 1)); Data.Update(pos, 1.0f);
Die Eingabe des lokalen Politikmodells erhält den Vektor, und es wird ein Vorwärtsdurchlauf durchgeführt. Das erhaltene Ergebnis wird an den Diskriminatoreingang weitergeleitet.
//--- Study if(!Worker.feedForward(Data,1,false) || !Descrimitator.feedForward(GetPointer(Worker),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Denken Sie daran, die Vorgänge zu kontrollieren.
Nach einem erfolgreichen Vorwärtsdurchlauf beider Modelle führen wir einen Rückwärtsdurchlauf der Modelle durch, um die Abweichungen zwischen der tatsächlichen und der durch den Diskriminator ermittelten Fähigkeit zu minimieren.
if(!Descrimitator.backProp(Data,(CBufferFloat *)NULL, (CBufferFloat *)NULL) || !Worker.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Alles, was wir tun müssen, ist, den Nutzer über den Trainingsfortschritt zu informieren und mit der nächsten Trainingsiteration fortzufahren.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Desciminator", iter * 100.0 / (double)(Iterations), Descrimitator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen der Schleife abgeschlossen sind, wird das Kommentarfeld gelöscht. Anzeige des Trainingsergebnisses. Initiieren Sie das Herunterfahren des Programms.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Descriminator", Descrimitator.getRecentAverageError()); ExpertRemove(); //--- }
Diese relativ einfache Methode ermöglicht es uns, die erforderliche Anzahl von unterschiedlichen Fähigkeiten zu trainieren. Bei der Erstellung von hierarchischen Modellen ist die Unterscheidung von Fähigkeiten auf der Grundlage der ausgeführten Tätigkeiten sehr wichtig. Dies trägt dazu bei, das Verhalten des Modells zu diversifizieren und die Arbeit des Planers im Hinblick auf die Auswahl der richtigen Fähigkeit in einem bestimmten Umweltzustand zu erleichtern.
2.3. Ausbildung der Kostenfunktion
Als Nächstes werden wir die Kostenfunktion untersuchen. Es wird erwartet, dass das trainierte Modell in der Lage sein wird, die mögliche Rentabilität vorherzusagen, nachdem es den aktuellen Zustand des Umfelds analysiert hat. Im Wesentlichen handelt es sich dabei um eine Schätzung des zukünftigen Zustands im Standard-RL, den wir in der einen oder anderen Form in fast allen Modellen untersuchen. Die Autoren der Methode schlagen jedoch vor, sie ohne einen Abzinsungsfaktor zu betrachten.
Ich beschloss, ein Experiment mit Kostenschätzungen nicht bis zum Ende der Episode, sondern nur über einen kurzen Planungshorizont durchzuführen. Meine Logik war, dass wir nicht vorhaben, eine Position zu eröffnen und sie „bis zum Ende der Zeit“ zu halten. In einem stochastischen Markt sind solch weitreichende Prognosen zu unwahrscheinlich. Ansonsten bleibt der Ansatz gut erkennbar. Auch hier habe ich das Modell nicht übermäßig verkompliziert. Die Architektur des Modells wird im Folgenden vorgestellt.
Wir füttern das Modell mit einer kleinen Menge historischer Daten, die den Zustand der Umwelt beschreiben. In diesem Modell werden wir nur die Marktsituation bewerten, um die wichtigsten möglichen Potenziale zu beurteilen. Bitte beachten Sie, dass wir in diesem Fall nicht an Trends interessiert sind. Stattdessen konzentrieren wir uns auf die Marktintensität. Da wir Rohdaten verwenden, wenden wir in diesem Modell bereits eine Batch-Normalisierungsschicht an.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden von einer Faltungsschicht im Zusammenhang mit Kerzen verarbeitet, die es uns ermöglicht, die wichtigsten Muster zu erkennen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = ValueBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; }
Danach werden die Daten von einem Block vollständig verbundener Schichten verarbeitet, und das Ergebnis wird in Form eines zerlegten Belohnungsvektors erzeugt.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Um die Wertfunktion zu trainieren, erstellen wir den EA „...\CT\StudyValue.mq5“. Hier werden wir uns auch auf die Trainingsmethode des Models Train konzentrieren. Um dieses Modell zu trainieren, benötigen wir bereits eine Trainingsstichprobe. Daher nehmen wir im Hauptteil der Trainingsschleife eine Stichprobe der Trajektorie und des Zustands.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); int check = 0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 * ValueBars)); if(i < 0) { iter--; continue; check++; if(check >= total_tr) break; }
Bitte beachten Sie, dass wir beim Sampling einer Trajektorie den Bereich der möglichen Zustände um den doppelten ValueBars-Wert reduzieren. Dies ist darauf zurückzuführen, dass im Erfahrungswiedergabepuffer jeder Zustand nur den letzten Balken enthält (aufgrund der Verwendung der GPT-Architektur in DT), und wir mehrere Balken historischer Daten benötigen, um das Potenzial zu bewerten. Außerdem ziehen wir die Belohnung, die über den Planungshorizont hinausgeht, von der gesamten akkumulierten Belohnung bis zum Ende der Episode ab.
Als Nächstes wird der Quelldatenpuffer gefüllt.
check = 0; //--- History data State.AssignArray(Buffer[tr].States[i].state); for(int state = 1; state < ValueBars; state++) State.AddArray(Buffer[tr].States[i + state].state);
Führen wir den direkten Durchlauf des Modells durch.
//--- Study if(!Value.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Als Nächstes müssen wir die Zieldaten für das Training des Modells vorbereiten. Wir nehmen die kumulierte Belohnung aus dem Erfahrungswiedergabepuffer zum Zeitpunkt der Zustandsbewertung und subtrahieren die kumulierte Belohnung außerhalb des Planungshorizonts. Dann laden wir die Ergebnisse eines direkten Durchlaufs durch das Modell und verwenden die CAGrad-Methode, um den Vektor der Zielwerte zu korrigieren.
vector<float> target, result; target.Assign(Buffer[tr].States[i + ValueBars - 1].rewards); result.Assign(Buffer[tr].States[i + 2 * ValueBars - 1].rewards); target = target - result*MathPow(DiscFactor,ValueBars); Value.getResults(result); Result.AssignArray(CAGrad(target - result) + result);
Wir übergeben den vorbereiteten Vektor der Zielwerte an das Modell und führen einen Rückwärtsdurchlauf durch. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
if(!Value.backProp(Result, (CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Anschließend informieren wir den Nutzer über das Modelltraining und gehen zur nächsten Iteration des Trainingszyklus über.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Value", iter * 100.0 / (double)(Iterations), Value.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem wir alle Iterationen der Schleife erfolgreich abgeschlossen haben, löschen wir das Kommentarfeld auf dem Instrumentenplan. Ausdruck des Ergebnisses des Modelltrainings im Protokoll. Initiieren der Beendigung des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Value", Value.getRecentAverageError()); ExpertRemove(); //--- }
Den vollständigen Code dieses EA und alle im Artikel verwendeten Programme finden Sie im Anhang.
2.4. Training des Planers
Wir gehen zum nächsten Schritt unserer Arbeit über, der Entwicklung eines Planers für unser hierarchisches Modell. In diesem Fall spielt der Entscheidungs-Transformer (Decision Transformer) die Rolle des Planers, der die Abfolge der besuchten Zustände und der darin durchgeführten Aktionen analysiert. Am Ausgang des Planers erwarten wir eine Fähigkeit, die unser lokales Politikmodell zur Generierung von Aktionen verwenden wird.
Wir beginnen mit der Modellarchitektur. Als Ausgangsdaten verwenden wir einen Vektor, der einen Zustand in unserer Trajektorie beschreibt, der alle möglichen Informationen enthält. Die Daten werden im Rohzustand geliefert, sodass wir sie mit der Batch-Daten-Normalisierungsschicht vorverarbeiten.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Darüber hinaus werden die Daten im Quelldatenvektor aus verschiedenen Quellen gesammelt. Dementsprechend haben sie auch unterschiedliche Dimensionen und Verteilungen. Eine Einbettungsschicht wird verwendet, um ihre weitere Verwendung zu erleichtern und sie in eine vergleichbare Form zu bringen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Die aufbereiteten Daten durchlaufen den Sparse-Transformer-Block.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Danach wird die Dimensionalität der Daten mit Hilfe einer Faltungsschicht reduziert.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Anschließend durchlaufen die Daten einen Entscheidungsblock aus vollständig verbundenen Schichten.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Am Ausgang reduzieren wir die Dimension der Daten auf die Anzahl der verwendeten Fähigkeiten und normalisieren ihre Wahrscheinlichkeit mit der SoftMax-Funktion.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Nachdem wir die Architektur des Modells betrachtet haben, gehen wir zur Erstellung des Trainings des Planers „...\CT\Study.mq5“ EA über. Wie üblich werden wir uns nur auf die Trainingsmethode des Models Train konzentrieren.
Das Konzept der DT-Training ist praktisch unverändert geblieben. In dem Modell werden Abhängigkeiten zwischen den Quelldaten (einschließlich RTG) und den vom Agenten durchgeführten Aktionen hergestellt. Aber es gibt Nuancen, die mit den Prinzipien der Konstruktion des betreffenden Algorithmus zusammenhängen:
- RTG sollte nicht das Ende der Episode erreichen, sondern nur den Planungshorizont;
- wir haben eine Fähigkeit, keine Aktion, am DT-Ausgang. Das lokale Politikmodell wird verwendet, um den Fehlergradienten zu vermitteln.
All diese Nuancen spiegeln sich im Prozess der Modellbildung wider.
Im Hauptteil der Train-Methode organisieren wir, wie zuvor, ein System von Modell-Trainingsschleifen. In der äußeren Schleife werden die Trajektorie und der Anfangszustand erfasst, um das Modell zu trainieren.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float err=0; int err_count=0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars-ValueBars,MathMin(Buffer[tr].Total,20+ValueBars))); if(i < 0) { iter--; continue; }
Der eigentliche Trainingsprozess wird im Hauptteil der verschachtelten Schleife durchgeführt. Wie Sie sich vielleicht erinnern, müssen wir aufgrund der Besonderheiten der GPT-Architektur historische Daten in strikter Übereinstimmung mit ihrem Erhalt während der Training verwenden.
Wir laden nacheinander historische Indikatoren der Preisbewegung und Indikatoren in den Quelldatenpuffer.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - 2 - ValueBars,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Daten zum Kontostatus.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Zeitstempel und letzte Aktion des Agenten.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Als Nächstes müssen wir RTG spezifizieren. Hier verwenden wir die tatsächlich angesammelte Belohnung. Aber passen wir sie zunächst an den Planungshorizont an.
//--- Return-To-Go vector<float> rtg; rtg.Assign(Buffer[tr].States[state+1].rewards); Actions.Assign(Buffer[tr].States[state+ValueBars].rewards); rtg=rtg-Actions*MathPow(DiscFactor,ValueBars); State.AddArray(rtg);
Wir geben die so gesammelten Daten in den Input des Planers ein und rufen die Forward-Pass-Methode auf. Wir übertragen die resultierende Vorhersagefähigkeit auf den Input des lokalen Politikmodells und führen dessen direkten Durchlauf durch, um die Aktionen des Agenten vorherzusagen.
//--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat *)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Vergleichen Sie die auf diese Weise vorhergesagte Aktion des Agenten mit der tatsächlichen Aktion aus dem Erfahrungswiedergabepuffer, die die in den Quelldaten angegebene Belohnung ergab. Um das Modell zu trainieren, müssen wir die Abweichung zwischen zwei Wertvektoren minimieren. Wir füttern den Zielaktionsvektor mit dem Ausgang des lokalen Politikmodells und führen einen sequentiellen Rückwärtsdurchlauf durch beide Modelle durch.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Worker.getResults(rtg); if(err_count==0) err=rtg.Loss(Actions,LOSS_MSE); else err=(err*err_count + rtg.Loss(Actions,LOSS_MSE))/(err_count+1); if(err_count<1000) err_count++; Result.AssignArray(CAGrad(Actions - rtg) + rtg); if(!Worker.backProp(Result,NULL,NULL) || !Agent.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
In diesem Fall verwenden wir das bereits trainierte lokale Politikmodell. Während des Rückwärtsdurchlaufs aktualisieren wir nur die Parameter des Planers. Dazu müssen wir das Flag für das Training des lokalen Richtlinienmodells auf false setzen (Worker.TrainMode(false)). In der vorliegenden Implementierung habe ich dies in der EA-Initialisierungsmethode getan, um den Vorgang nicht bei jeder Iteration zu wiederholen.
Alles, was wir tun müssen, ist, den Nutzer über den Trainingsfortschritt zu informieren und mit der nächsten Trainingsiteration fortzufahren.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), err); Comment(str); ticks = GetTickCount(); } } }
Nach Abschluss aller Iterationen des Schleifensystems wiederholen wir die oben bereits zweimal beschriebenen Vorgänge zum Beenden des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", err); ExpertRemove(); //--- }
Damit ist das Thema Modellbildungsalgorithmen abgeschlossen. In diesem Artikel haben wir drei Modell-Trainings-EAs erstellt, anstatt des bisher verwendeten einen. Mit diesem Ansatz können wir die Trainingsmodelle parallelisieren. Wie Sie sehen können, ist der EA für das Training der Fähigkeiten keine Trainingsprobe erforderlich. Wir können Fertigkeiten parallel zur Erhebung einer Trainingsprobe trainieren. Beim Training des Planers und der Kostenfunktion verwenden wir den Erfahrungswiedergabepuffer. Gleichzeitig überschneiden sich die Prozesse nicht und können parallel gestartet werden, auch auf verschiedenen Rechnern.
2.5. Der EA für das Modeltraining
Nach dem Training der Modelle müssen wir die im Handel erzielten Ergebnisse bewerten. Natürlich werden wir das Modell mit dem Strategietester testen. Wir brauchen jedoch einen EA, der alle oben genannten Modelle zu einem einzigen Entscheidungskomplex zusammenfasst. Wir werden diese Funktionalität in den EA „...\CT\Test.mq5“ implementieren. Wir werden nicht alle EA-Methoden berücksichtigen. Ich schlage vor, sich nur auf die Funktion OnTick zu konzentrieren, in der der Hauptentscheidungsalgorithmus angeordnet ist.
Zu Beginn der Methode wird geprüft, ob das Ereignis der Öffnung eines neuen Balkens eingetreten ist. Wie Sie sich erinnern, führen wir alle Handelsoperationen durch, wenn ein neuer Balken geöffnet wird. In diesem Fall analysieren wir nur geschlossene Kerzen.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Hier laden wir bei Bedarf historische Daten vom Server herunter.
Als Nächstes müssen wir die Quelldatenpuffer für unsere Modelle mit historischen Daten füllen. Hier ist anzumerken, dass das Kostenfunktionsmodell und der Scheduler Daten verwenden, die sich in Struktur und Tiefe der Historie unterscheiden. Zunächst füllen wir den Puffer mit Daten für die Kostenfunktion und führen ihren Vorwärtsdurchlauf durch.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars-1; b >=0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!Value.feedForward(GetPointer(bState), 1, false)) return;
Dann füllen wir den Puffer mit Daten für den Planer. Bitte beachten Sie, dass die Datenfolge die Reihenfolge ihrer Darstellung beim Training des Modells vollständig wiederholen sollte. Zunächst übertragen wir historische Daten über Kursbewegungen und Indikatorwerte.
for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Ergänzen wir sie mit Informationen über den Kontostand.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Danach folgen der Zeitstempel und die letzte Aktion des Agenten.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
Fügen wir das RTG am Ende des Puffers hinzu. Diesen Wert entnehmen wir dem Ergebnispuffer der Kostenfunktion.
//--- Return to go
Value.getResults(Result);
bState.AddArray(Result);
Nach Abschluss der Datenaufbereitung führen wir nacheinander einen Vorwärtsdurchlauf des Planers und des lokalen Politikmodells durch. Gleichzeitig achten wir darauf, dass die durchgeführten Maßnahmen überwacht werden.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent), -1, (CBufferFloat *)NULL)) return;
Die auf diese Weise vorhergesagten Aktionen des Agenten werden in der Umgebung verarbeitet und ausgeführt.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Worker.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Die Ergebnisse der Interaktion mit der Umwelt werden im Erfahrungswiedergabepuffer gespeichert, um eine spätere Feinabstimmung des Modells zu ermöglichen.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Es sei darauf hingewiesen, dass die auf diese Weise gesammelten Daten sowohl für die Feinabstimmung des Modells als auch für ein späteres zusätzliches Training des Modells während des Betriebs verwendet werden können. Auf diese Weise können wir sie ständig an die sich ändernden Umweltbedingungen anpassen.
3. Test
Wir haben viel Arbeit in die Erstellung von EAs zur Datenerfassung und Modelltraining gesteckt. Wie bereits erwähnt, haben wir den gesamten Prozess in separate EAs aufgeteilt, um mehrere Aufgaben parallel zu erledigen. Der erste Schritt besteht darin, den EA „StudyWorker.mq5“ zu starten, der eigenständig arbeitet und keine Übungsbeispiele benötigt. Gleichzeitig sammeln wir eine Trainingsstichprobe.
Die Erhebung einer Trainingsprobe für den historischen Zeitraum in den ersten 7 Monaten des Jahres 2023 erwies sich als recht arbeitsintensiv. Ich bin auf das Problem gestoßen, dass selbst bei einem kleinen Stichprobenhorizont von Agentenaktionen die meisten Durchläufe die Anforderung eines positiven Saldos nicht erfüllten.
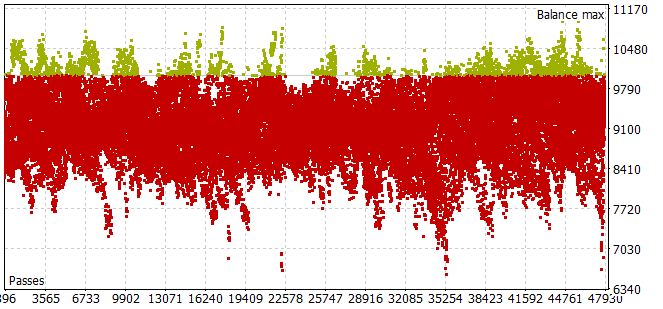
Um den optimalen Planungshorizont im Optimierungsmodus zu wählen, wurde die Anzahl der Iterationen pro Durchlauf an die optimierten Parameter angepasst.
Nach dem Sammeln der Trainingsmenge und dem Training des lokalen Richtlinienmodells habe ich das Training des Planers und des Kostenfunktionsmodells parallel durchgeführt. Auf diese Weise konnte ich den Zeitaufwand für das Training der Modelle erheblich reduzieren.
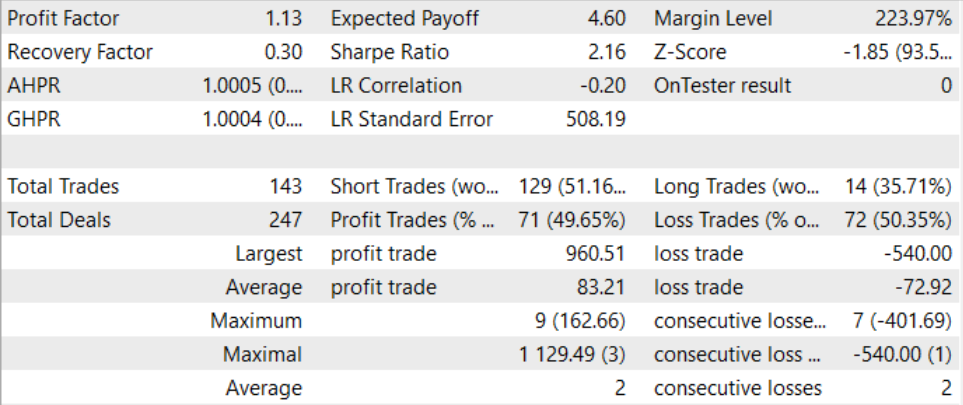
Nach einem langwierigen und recht komplexen Trainingsprozess ist es uns gelungen, ein Modell zu entwickeln, das auch außerhalb des Trainingssatzes Gewinne erzielen kann. Das trainierte Modell wurde mit historischen Daten für August 2023 getestet. Den Testergebnissen zufolge lag der Gewinnfaktor bei 1,13. Das Verhältnis zwischen gewinnbringenden und unrentablen Positionen liegt nahe bei 1:1. Der gesamte Gewinn ergibt sich aus dem Überschuss der durchschnittlich gewinnbringenden Transaktion gegenüber dem durchschnittlichen Verlust.
Schlussfolgerung
In diesem Artikel stellen wir die Entscheidungs-Transformer-Methode vor, die eine innovative Architektur für das Training von Kontrollstrategien in komplexen und sich dynamisch verändernden Umgebungen bietet. Control Transformer kombiniert fortschrittliche Techniken des Reinforcement Learning, der Planung und des maschinellen Lernens, um flexible und adaptive Steuerungsstrategien zu entwickeln.
Control Transformer eröffnet neue Perspektiven für die Entwicklung von verschiedenen autonomen Systemen und Robotern. Seine Fähigkeit, sich an unterschiedliche Umgebungen anzupassen, dynamische Bedingungen zu berücksichtigen und offline zu trainieren, macht es zu einem leistungsstarken Werkzeug für die Entwicklung intelligenter und autonomer Systeme, die komplexe Kontroll- und Navigationsprobleme lösen können.
Im praktischen Teil des Artikels haben wir unsere Vision der vorgestellten Methode mit MQL5 umgesetzt. In dieser Implementierung haben wir einen neuen Ansatz verwendet, bei dem die Modelltraining in separate, nicht miteinander verbundene EAs aufgeteilt wird, was es uns ermöglicht, mehrere Aufgaben parallel durchzuführen. Auf diese Weise können wir die Gesamttrainingszeit der Modelle erheblich reduzieren.
Durch das Trainieren und Testen von Modellen ist es uns gelungen, ein Modell zu entwickeln, das Gewinne erwirtschaften kann. Der Ansatz kann daher als effizient angesehen werden. Es kann zum Aufbau von Handelslösungen verwendet werden.
Ich möchte Sie noch einmal daran erinnern, dass alle in diesem Artikel vorgestellten Programme informativen Charakter haben und zur Demonstration des vorgestellten Algorithmus dienen sollen. Sie sind nicht für den Einsatz unter realen Marktbedingungen gedacht.
Links
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Faza1.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Training des Planer EAs |
| 3 | StudyWorker.mq5 | Expert Advisor | EA für das Training des lokalen Politikmodells |
| 4 | StudyValue.mq5 | Expert Advisor | Kostenfunktion des Trainings-EAs |
| 5 | Test.mq5 | Expert Advisor | Der EA für das Modeltraining |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13674
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.