
Neuronale Netze leicht gemacht (Teil 61): Optimismusproblem beim Offline-Verstärkungslernen

Einführung
In jüngster Zeit sind Methoden des Offline-Verstärkungslernens weit verbreitet, was viele Perspektiven für die Lösung von Problemen unterschiedlicher Komplexität verspricht. Eines der Hauptprobleme, mit denen die Forscher konfrontiert sind, ist jedoch der Optimismus, der beim Lernen entstehen kann. Der Agent optimiert seine Strategie auf der Grundlage der Daten aus dem Trainingssatz und gewinnt Vertrauen in seine Handlungen. Allerdings ist die Trainingsmenge oft nicht in der Lage, die gesamte Vielfalt der möglichen Zustände und Übergänge der Umgebung abzudecken. In einem stochastischen Umfeld erweist sich dieses Vertrauen als nicht ganz gerechtfertigt. In solchen Fällen kann die optimistische Strategie des Agenten zu erhöhten Risiken und unerwünschten Folgen führen.
Auf der Suche nach einer Lösung für dieses Problem lohnt es sich, der Forschung im Bereich des autonomen Fahrens Aufmerksamkeit zu schenken. Es liegt auf der Hand, dass die Algorithmen in diesem Bereich darauf abzielen, Risiken zu verringern (Erhöhung der Nutzersicherheit) und die Online-Schulung zu minimieren. Eine solche Methode ist SeParated Latent Trajectory Transformer (SPLT-Transformer), die in dem Artikel „Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning“ (Juli 2022) vorgestellt wurde.
1. SPLT-Transformator-Methode
Ähnlich wie Decision Transformer ist SPLT-Transformer ein Modell zur Erzeugung von Sequenzen unter Verwendung der Transformer-Architektur. Im Gegensatz zu der genannten DT verwendet es jedoch zwei getrennte Informationsflüsse, um die Politik des Akteurs und die Umgebung zu modellieren.
Die Autoren der Methode versuchen, 2 Hauptprobleme zu lösen:
- Modelle sollten dazu beitragen, eine Vielzahl von Kandidaten für das Verhalten des Agenten in jeder Situation zu schaffen;
- Die Modelle sollten die meisten der verschiedenen Arten möglicher Übergänge zu einem neuen Umgebungzustand abdecken.
Um dieses Ziel zu erreichen, trainieren wir 2 separate VAEs auf der Grundlage des Transformers für Actor-Politik und Umgebungsmodell. Die Autoren der Methode erzeugen stochastische latente Variablen für beide Ströme und verwenden sie über den gesamten Planungshorizont. Auf diese Weise können wir alle möglichen Trajektorien aufzählen, ohne dass die Verzweigungen exponentiell ansteigen, und wir können während des Tests effektiv nach Verhaltensoptionen suchen.
Die Idee ist, dass latente Politikvariablen verschiedenen hochrangigen Absichten entsprechen sollten, ähnlich wie die Fähigkeiten hierarchischer Algorithmen. Gleichzeitig sollten die latenten Variablen des Umgebungsmodells den verschiedenen möglichen Trends und den wahrscheinlichsten Veränderungen des Zustands entsprechen.
Die Politik- und Umgebungs-Encoder verwenden dieselbe Architektur mit Transformers. Sie erhalten die gleichen Ausgangsdaten in Form einer früheren Trajektorie. Im Gegensatz zu den zuvor diskutierten Algorithmen umfasst die Trajektorie jedoch nur eine Reihe von Zuständen und Aktionen des Actors. Am Ausgang der Kodierer erhalten wir diskrete latente Variablen mit einer begrenzten Anzahl von Werten in jeder Dimension.
Die Autoren der Methode schlagen vor, den Durchschnittswert der Transformatorausgänge für alle Elemente zu verwenden, um die gesamte Trajektorie in einer Vektordarstellung zu kombinieren.
Anschließend wird jede dieser Ausgaben von einem kleinen mehrschichtigen Perzeptron verarbeitet, das unabhängige kategoriale Verteilungen der latenten Repräsentation ausgibt.
Der Politik-Decoder erhält dieselbe ursprüngliche Trajektorie als Eingabe, ergänzt um die entsprechende latente Darstellung. Das Ziel eines Politik-Decoders ist es, Wahrscheinlichkeiten zu schätzen und die wahrscheinlichste nächste Aktion in einer Trajektorie vorherzusagen. Die Autoren der Methode stellen einen Decoder vor, der das Transformer-Modell verwendet.
Wie oben erwähnt, entfernen wir die Belohnung aus der Sequenz, fügen aber eine latente Darstellung hinzu. Die latente Darstellung ersetzt jedoch nicht bei jedem Schritt die Belohnung als Sequenzelement. Die Autoren der Methode führen eine latente Repräsentation ein, die durch einen einzigen Einbettungsvektor transformiert wird, ähnlich der Positionskodierung, die in einigen anderen Arbeiten mit der Transformer-Architektur verwendet wird.
Der Umgebungsmodell-Decoder hat eine ähnliche Architektur wie der Policy-Decoder. Nur am Ausgang hat der Decoder des Umgebungsmodells „drei Köpfe“, um den wahrscheinlichsten Folgezustand und dessen Kosten sowie die Übergangsbelohnung vorherzusagen.
Wie bei DT werden die Modelle mit Hilfe von überwachten Lernmethoden auf Daten aus dem Trainingssatz trainiert. Die Modelle werden trainiert, um Trajektorien der nachfolgenden Aktionen (Akteur), Übergängen zu neuen Zuständen und deren Kosten (Umgebungsmodell) zu vergleichen.
Beim Testen und im Betrieb erfolgt die Auswahl der optimalen Maßnahme auf der Grundlage der Bewertung der in Frage kommenden Vorhersagetrajektorien für einen bestimmten Planungshorizont. Um eine geplante Trajektorie eines Kandidaten zu erstellen, werden über den Planungshorizont sequenziell Aktionen und Zustände mit Belohnungen generiert. Dann wird die optimale Trajektorie ausgewählt und ihre erste Aktion ausgeführt. Nach dem Übergang zu einem neuen Zustand der Umgebung wird der gesamte Algorithmus wiederholt.
Wie Sie sehen können, plant der Algorithmus mehrere mögliche Trajektorien, aber nur eine Aktion der optimalen Trajektorie wird ausgeführt. Obwohl dieser Ansatz ineffizient erscheinen mag, können die Risiken durch die Planung mehrerer Schritte im Voraus minimiert werden. Gleichzeitig ist es möglich, die Trajektorie im Laufe der Zeit zu korrigieren, indem jeder besuchte Zustand neu bewertet wird.
Im Folgenden wird die Visualisierung der Methode durch den Autor vorgestellt.
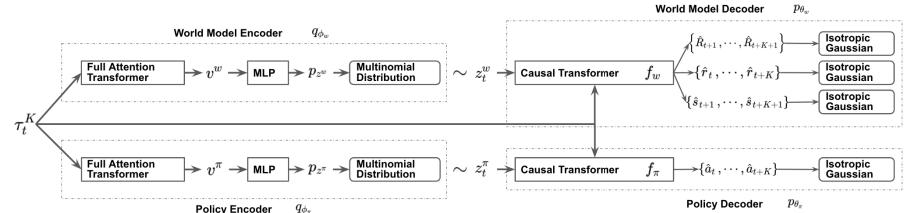
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte der SPLT-Transformator-Methode gehen wir nun zur Implementierung der vorgeschlagenen Ansätze mit MQL5 über. Ich möchte gleich anmerken, dass unsere Implementierung weiter denn je vom Algorithmus des Autors entfernt sein wird. Der Grund dafür ist meine subjektive Wahrnehmung. Die gesamte Erfahrung in dieser Artikelserie zeigt, wie komplex die Erstellung eines Umgebungsmodells für die Finanzmärkte ist. Alle unsere Versuche führten zu eher bescheidenen Ergebnissen. Die Genauigkeit der Prognosen ist mit 1-2 Schritten recht gering. Mit zunehmendem Planungshorizont tendiert er gegen 0. Daher habe ich mich entschieden, keine Kandidaten-Trajektorien zu erstellen, sondern mich darauf zu beschränken, nur mehrere mögliche Handlungsoptionen aus dem aktuellen Zustand zu generieren.
Dieser Ansatz bringt jedoch eine Lücke zwischen der Maßnahme und ihrer Bewertung mit sich. Wie Sie in der obigen Visualisierung sehen können, erhalten die Akteurspolitik und das Umgebungsmodell die gleichen Eingabedaten. Aber dann fließen die Daten in parallelen Strömen. Daher weiß das Umgebungsmodell bei der Vorhersage des späteren Zustands und der erwarteten Belohnung nichts über die Handlung, die der Agent wählen wird. Hier kann man nur von einer bestimmten Annahme sprechen, die mit einer gewissen Wahrscheinlichkeit auf früheren Erfahrungen aus der Trainingsstichprobe beruht. Es sei darauf hingewiesen, dass die Trainingsstichprobe auf der Grundlage einer anderen Akteurspolitik als der derzeit verwendeten erstellt wurde.
In der Version des Autors wird dies ausgeglichen, indem die Aktion des Agenten und der prognostizierte Zustand im nächsten Schritt zur Trajektorie hinzugefügt werden. In unserem Fall besteht jedoch die Gefahr, dass wir angesichts der Erfahrungen mit der minderwertigen Planung für den späteren Zustand der Umgebung völlig unkoordinierte Zustände und Aktionen in die Trajektorie einfügen. Dies führt zu einer noch stärkeren Verschlechterung der Qualität der Planung der nächsten Schritte in der Prognosekurve. Meines Erachtens ist die Effizienz einer solchen Planung und Bewertung der Flugbahnen sehr zweifelhaft. Daher werden wir keine Ressourcen für die Vorhersage der Trajektorien der Kandidaten verschwenden.
Gleichzeitig brauchen wir einen Mechanismus, der in der Lage ist, die Handlungen des Agenten mit der erwarteten Belohnung zu vergleichen. Einerseits können wir das Modell des Kritikers verwenden, aber dies bricht den Algorithmus grundlegend und schließt das Umgebungsmodell vollständig aus. Es sei denn, wir verwenden ihn als Kritiker.
Ich habe jedoch beschlossen, mit einem anderen Ansatz zu experimentieren, der dem ursprünglichen Algorithmus näher kommt. Zunächst habe ich beschlossen, einen Encoder für beide Streams zu verwenden. Der sich daraus ergebende latente Zustand wird zur Trajektorie hinzugefügt und an den Eingang von 2 Decodern geleitet. Der Akteur erstellt auf der Grundlage der Ausgangsdaten eine vorausschauende Handlung, und das Umgebungsmodell liefert den Betrag der zukünftigen abgezinsten Belohnung.
Die Idee ist, dass die Modelle bei gleichen Eingabedaten konsistente Ergebnisse liefern. Zu diesem Zweck schließen wir die Stochastik in den Akteurs- und Umgebungsmodellen aus. Auf diese Weise schaffen wir Stochastizität in der latenten Repräsentation, die es uns ermöglicht, mehrere Handlungskandidaten und damit verbundene prädiktive Zustandsschätzungen zu generieren. Auf der Grundlage dieser Schätzungen werden wir eine Rangfolge der in Frage kommenden Maßnahmen aufstellen, um den optimalen gewichteten Schritt auszuwählen.
Um die Anzahl der durchgeführten Operationen zu optimieren, sollten wir einen weiteren Punkt beachten. Indem wir dem Encoder-Eingang dieselbe Trajektorie zuführen, wiederholen wir die Ergebnisse aller seiner internen Schichten mit mathematischer Genauigkeit. Differenzen werden nur in der Variations-Autocodierer-Schicht gebildet, wenn aus einer bestimmten Verteilung gesampelt wird. Daher ist es ratsam, die angegebene Ebene außerhalb des Encoders zu verschieben, um mögliche Aktionen zu generieren. Dies ermöglicht es uns, bei jeder Iteration nur einen Encoder-Durchgang auszuführen. Nach einigem Nachdenken habe ich die Variations-Autocodierer-Ebene in das Umgebungsmodell verschoben.
Ich ging weiter auf dem Weg der Optimierung des Arbeitsablaufs. Alle drei Modelle verwenden dieselbe Trajektorie als Eingabedaten. Wie Sie wissen, sind die Elemente der Trajektorie nicht einheitlich. Vor der Verarbeitung durchlaufen sie eine Einbettungsebene. Dies brachte mich auf die Idee, die Daten in nur ein Modell einzubetten und die daraus resultierenden Daten in den beiden anderen zu verwenden. Daher habe ich die Einbettungsebene nur im Encoder belassen.
Es gibt noch eine weitere Sache. Das Umgebungsmodell und der Akteur verwenden den verketteten Vektor der Trajektorie und der latenten Repräsentation als Eingabe. Wir haben bereits festgestellt, dass die Variations-Autocodierer-Schicht zur Bildung einer stochastischen latenten Repräsentation auf das Umgebungsmodell übertragen wurde. Hier werden wir die Kombination von Vektoren durchführen und das bereits erhaltene Ergebnis an den Eingang des Akteurs übergeben.
Codieren wir nun die obigen Ideen. Wir erstellen eine Beschreibung unserer Modelle. Sie wird wie immer in der Methode CreateDescriptions gebildet. In den Parametern erhält die Methode Zeiger auf drei Objekte, die unsere Modelle beschreiben.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *latent, CArrayObj *world) { //--- CLayerDescription *descr;
Die Beschreibung der Architektur sollte wahrscheinlich mit einem Modell eines Encoders beginnen, dessen Eingang mit unbearbeiteten Sequenzdaten versorgt wird.
//--- latent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Wir leiten die empfangenen Daten durch eine Batch-Normalisierungsschicht, um sie in eine vergleichbare Form zu bringen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Wir leiten die bereits normalisierten Daten durch die Einbettungsschicht und merken uns diese Ebene. Anschließend werden wir die Daten in das Umgebungsmodell übernehmen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!latent.Add(descr)) { delete descr; return false; }
Danach führen wir die resultierende Trajektorie durch den Transformer-Block. Ich habe einen spärlichen Aufmerksamkeitsblock mit 8 Self-Attention-Köpfen und 4 Schichten pro Block verwendet.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = prev_wout; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Nach dem Aufmerksamkeitsblock wird die Dimensionalität der Faltungsschicht leicht reduziert und die Daten werden durch einen Entscheidungsblock aus voll verknüpften Schichten geleitet.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Am Ausgang des Encoder-Modells verwenden wir eine voll verknüpfte neuronale Schicht ohne Aktivierungsfunktion und mit einer Größe, die doppelt so groß ist wie die Einbettungsgröße eines Trajektorienelements. Dies sind die Mittelwerte und Varianzen für die Verteilung der latenten Repräsentation, die es uns ermöglichen, die latente Repräsentation im nächsten Schritt aus einer gegebenen Verteilung zu entnehmen.
Als Nächstes wird das Umgebungsmodell beschrieben. Die Quelldatenschicht entspricht der Ergebnisschicht des Encoder-Modells, gefolgt von der Variations-Auto-Encoder-Schicht, die es uns ermöglicht, die latente Repräsentation unmittelbar zu erfassen.
//--- World if(!world) { world = new CArrayObj(); if(!world) return false; } //--- world.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; prev_count = descr.count = prev_count / 2; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Als Nächstes müssen wir den Trajektorieneinbettungstensor hinzufügen. Zu diesem Zweck wird eine Verkettungsebene verwendet. Am Ausgang dieser Schicht erhalten wir verarbeitete Ausgangsdaten für unser Umgebungsmodell und den Akteur.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.step = 4 * EmbeddingSize * HistoryBars; prev_count = descr.count = descr.step + prev_count; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Leiten wir nun die Daten durch den entladenen Self-Attention-Block. Wie beim Encoder verwenden wir 8 Köpfe und 4 Schichten.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Reduzieren wir die Dimensionalität der Daten mithilfe einer Faltungsschicht
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; }
und verarbeiten die empfangenen Daten mit einem vollständig verbundenen Perzeptron des Entscheidungsblocks.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells erhalten wir einen dekomponierten Belohnungsvektor.
Am Ende dieses Blocks werden wir uns die Struktur unseres Akteursmodells ansehen. Wie bereits erwähnt, erhält das Modell seine Ausgangsdaten aus dem verborgenen Zustand des Umgebungsmodells. Dementsprechend sollte die Quelldatenschicht eine ausreichende Größe haben.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = EmbeddingSize * (4 * HistoryBars + 1); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Die erhaltenen Daten sind das Ergebnis des Modells und bedürfen keiner weiteren Bearbeitung. Daher verwenden wir sofort den spärlichen Aufmerksamkeitsblock (sparse attention block). Die Blockparameter ähneln denen, die in den oben genannten Modellen verwendet werden. Alle drei Modelle verwenden also die gleiche Transformatorarchitektur.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Ähnlich wie beim Umgebungsmodell reduzieren wir die Dimensionalität und verarbeiten die Daten in einem vollständig verknüpften Entscheidungs-Perceptron.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Am Ausgang des Modells wird ein Vektor von Agentenaktionen gebildet.
Wir müssen auch beachten, dass wir zur Umsetzung dieser Methode eine zusätzliche Einheit in Form einer Verteilung der latenten Repräsentation, die am Ausgang des Encoders gebildet wird, zum Erfahrungswiedergabepuffer hinzufügen müssen. Zu diesem Zweck wird ein zusätzliches Array in der Struktur zur Beschreibung des Umgebungszustands erstellt.
struct SState { ....... ....... float latent[2 * EmbeddingSize]; ....... ....... }
Die Größe des neuen Arrays entspricht zwei Einbettungen, da es die Durchschnittswerte und Varianzen der Verteilung enthält.
Zusätzlich zur Deklaration des Arrays müssen wir seine Wartung zu allen Strukturmethoden hinzufügen:
- Initialisierung mit Anfangswerten
SState::SState(void) { ....... ....... ArrayInitialize(latent, 0); }
- Freimachen der Struktur
void Clear(void) { ....... ....... ArrayInitialize(latent, 0); }
- Kopieren der Struktur
void operator=(const SState &obj) { ....... ....... ArrayCopy(latent, obj.latent); }
- Speichern der Struktur
bool SState::Save(int file_handle) { ....... ....... //--- total = ArraySize(latent); if(FileWriteInteger(file_handle, total) < sizeof(int)) return false; for(int i = 0; i < total; i++) if(FileWriteFloat(file_handle, latent[i]) < sizeof(float)) return false; //--- return true; }
- Laden der Struktur aus der Datei
bool SState::Load(int file_handle) { ....... ....... //--- total = FileReadInteger(file_handle); if(total != ArraySize(latent)) return false; //--- for(int i = 0; i < total; i++) { if(FileIsEnding(file_handle)) return false; latent[i] = FileReadFloat(file_handle); } //--- return true; }
Wir haben uns mit der Architektur der trainierten Modelle vertraut gemacht und die Datenstruktur aktualisiert. Der nächste Schritt ist die Sammlung von Daten für das Training. Diese Funktion wird in dem EA „...\SPLT\Research.mq5“ ausgeführt. Die SPLT-Transformer-Methode ermöglicht die Generierung von Kandidaten-Trajektorien (oder Kandidaten-Aktionen in unserer Implementierung). Die Anzahl solcher Kandidaten ist einer der Hyperparameter des Modells, den wir in die externen Parameter des EA aufnehmen.
input int Agents = 5;
Wie Sie sich vielleicht erinnern, haben wir früher den externen Parameter Agenten als Hilfsparameter verwendet, um die Anzahl der parallelen Agenten der Umgebungserkundung im Optimierungsmodus des Strategietesters anzugeben. Jetzt benennen wir den Parameter des EA-Dienstes um.
input int OptimizationAgents = 1;
Im Folgenden werden wir nicht näher auf alle EA-Methoden zur Erhebung einer Trainingsstichprobe eingehen. Ihr Algorithmus wurde bereits mehrfach in dieser Serie beschrieben. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar. Betrachten wir nur die OnTick-Methode der direkten Interaktion mit der Umgebung, die die wichtigsten Merkmale des implementierten Algorithmus enthält.
Zu Beginn der Methode überprüfen wir wie üblich das Eintreten des Ereignisses der Eröffnung eines neuen Balkens und aktualisieren gegebenenfalls die historischen Daten der Preisbewegung und der analysierten Indikatoren.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Danach erstellen wir einen Puffer mit Quelldaten für die Modelle. Zunächst geben wir historische Daten über die Kursentwicklung und die Werte der analysierten Indikatoren ein.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates(); //--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Dann fügen wir den aktuellen Kontostand und Informationen über offene Positionen hinzu.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Als Nächstes führen wir eine zeitliche Identifizierung der Daten durch, indem wir einen Zeitstempel zu unserem Datenpuffer hinzufügen.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Geben Sie die letzten Handlungen des Agenten an, die uns in diesen Zustand der Umgebung gebracht haben.
//--- Prev action
bState.AddArray(AgentResult);
Die gesammelten Daten über den aktuellen Schritt reichen aus, um eine latente Darstellung zu erzeugen, und wir rufen die Methode für den Vorwärtsdurchgang des Encoders auf. Gleichzeitig achten wir darauf, dass die durchgeführten Maßnahmen überwacht werden und informieren den Nutzer, falls erforderlich.
//--- Latent representation ResetLastError(); if(!Latent.feedForward(GetPointer(bState), 1, false)) { PrintFormat("Error of Latent model feed forward: %d",GetLastError()); return; }
Nachdem wir die latente Repräsentation erfolgreich erstellt haben, gehen wir zu unseren Decodern über.
Ich möchte Sie daran erinnern, dass wir in dieser Phase Aktionen für die Kandidaten entwickeln müssen. Wir werden sie in einer Schleife bilden. Die Anzahl der Iterationen entspricht der Anzahl der erforderlichen Kandidaten und wird in den externen Parametern des EA angegeben.
Um Informationen über die generierten Kandidatenaktionen zu speichern, werden wir die Matrizen der Aktionen und der Werte erstellen. In der ersten werden wir Aktionsvektoren aufzeichnen. Die zweite besteht darin, den erwarteten Nutzen aus der Anwendung der Politik zu ermitteln.
Wie bereits erwähnt, erzeugen wir im Encoder-Modell nur Daten über die Verteilung der latenten Repräsentation. Das Sampling des latenten Repräsentationsvektors wird im Umgebungsmodell durchgeführt. Daher führen wir im Hauptteil der Schleife zunächst einen Vorwärtsdurchlauf durch das Umgebungsmodell durch. Dann rufen wir den Vorwärtsdurchlauf des Agenten auf, die die verdeckten Zustände des Umgebungsmodells als Eingabe verwendet.
Die Ergebnisse der direkten Durchläufe der Modelle werden in vorbereiteten Matrizen gespeichert.
matrix<float> actions = matrix<float>::Zeros(Agents, NActions); matrix<float> values = matrix<float>::Zeros(Agents, NRewards); for(ulong i = 0; i < (ulong)Agents; i++) { if(!World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer) || !Agent.feedForward(GetPointer(World), 2,(CBufferFloat *)NULL)) return; vector<float> result; Agent.getResults(result); actions.Row(result, i); World.getResults(result); values.Row(result, i); }
Die Verwendung stochastischer Strategien basiert auf der Annahme, dass die Wahrscheinlichkeit des Auftretens eines der Ereignisse innerhalb der gelernten Verteilung gleich ist. Daher ist die Wahrscheinlichkeit, die erwartete Belohnung in der Umgebung zu erhalten, für jeden Handlungskandidaten, der in die Stichprobe aufgenommen wird, gleich groß. Unser Ziel ist es, eine maximale Rentabilität zu erreichen. Das bedeutet, dass wir unter Bedingungen gleicher Wahrscheinlichkeit die Aktion mit dem höchsten erwarteten Ertrag wählen.
Wie Sie verstehen, sind unsere Matrizen zeilenkorreliert. Wir suchen die Zeile mit der höchsten erwarteten Belohnung in der Wertematrix und wählen eine Aktion aus der entsprechenden Zeile der Aktionenmatrix.
vector<float> temp = values.Sum(1); temp = actions.Row(temp.ArgMax());
Die ausgewählte Aktion findet in der Umgebung statt.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Die Ergebnisse der Interaktion mit der Umgebung werden in einer vorbereiteten Struktur gesammelt und im Erfahrungswiedergabepuffer gespeichert.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; Latent.getResults(sState.latent); if(!Base.Add(sState)) ExpertRemove(); }
Damit ist unsere Einführung in den EA für die Interaktion mit der Umgebung und die Erfassung von Trainingsdaten abgeschlossen. Den vollständigen Code finden Sie im Anhang. Dort finden Sie auch den vollständigen Code aller in diesem Artikel verwendeten Programme. Wir fahren mit dem ES für das Offline-Modelltraining „...\SPLT\Study.mq5“ fort.
Bei der EA-Initialisierungsmethode laden wir zunächst die Trainingsmenge hoch. Achten Sie auf die Kontrolle der Vorgänge. Für die Offline-Modellschulung ist dies die einzige Datenquelle, und ihr Fehlen macht den Rest des Prozesses unmöglich.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Als Nächstes versuchen wir, die vortrainierten Modelle zu laden und gegebenenfalls neue zu erstellen.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !World.Load(FileName + "Wld.nnw", temp, temp, temp, dtStudied, true) || !Latent.Load(FileName + "Lat.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *latent = new CArrayObj(); CArrayObj *world = new CArrayObj(); if(!CreateDescriptions(agent, latent, world)) { delete agent; delete latent; delete world; return INIT_FAILED; } if(!Agent.Create(agent) || !World.Create(world) || !Latent.Create(latent)) { delete agent; delete latent; delete world; return INIT_FAILED; } delete agent; delete latent; delete world; //--- }
Wie Sie vielleicht bemerkt haben, verwendet der Algorithmus des EA für die Erhebung einer Trainingsstichprobe häufig einen Datentransfer zwischen trainierten Modellen. Während des Trainingsprozesses steigt das Volumen der übertragenen Daten, da der Datenfluss in zwei Richtungen erfolgt: vorwärts und rückwärts. Um unnötige Datenkopiervorgänge zwischen dem OpenCL-Kontext und dem Hauptspeicher zu vermeiden, werden wir alle Modelle in einen einzigen OpenCL-Kontext übertragen.
COpenCL *opcl = Agent.GetOpenCL(); Latent.SetOpenCL(opcl); World.SetOpenCL(opcl);
Als Nächstes überprüfen wir die Konsistenz der Architektur der trainierten Modelle.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Agent does not match the actions count (%d <> %d)", 6, Result.Total()); return INIT_FAILED; } //--- Latent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Latent model doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Latent.Clear();
Nach erfolgreichem Abschluss aller Kontrollen erzeugen wir ein Ereignis für den Beginn des Modelltrainings und schließen die Operation der EA-Initialisierungsmethode ab.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Der eigentliche Prozess des Trainings von Modellen ist in der Methode Train geregelt. Im Hauptteil der Methode bestimmen wir die Anzahl der Trajektorien im Erfahrungswiedergabepuffer und zeichnen die Startzeit des Trainings in einer lokalen Variablen auf. Sie wird uns als Leitfaden dienen, um den Nutzer regelmäßig über den Fortschritt der Modellschulung zu informieren.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Ich möchte Sie daran erinnern, dass unsere Modelle die GPT-Architektur verwenden, die auf die Reihenfolge der Quelldaten reagiert. Wie in ähnlichen Fällen üblich, werden wir ein verschachteltes Schleifensystem verwenden, um Modelle zu trainieren. In der externen Schleife werden die Trajektorie aus dem Erfahrungswiedergabepuffer und der Anfangszustand der Umgebung abgerufen.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Dann initialisieren wir die Modellpuffer und erstellen eine verschachtelte Schleife, in der wir nacheinander ein separates Fragment historischer Daten als Modelleingabe eingeben.
Actions = vector<float>::Zeros(NActions); Latent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) {
Im Hauptteil einer verschachtelten Schleife können die Operationen ein wenig an die Erfassung von Trainingsdaten erinnern. Wir füllen auch den Quelldatenpuffer. Nur dass wir jetzt keine Daten aus der Umgebung anfordern, sondern sie aus dem Erfahrungswiedergabepuffer extrahieren. Gleichzeitig halten wir die Reihenfolge der Datenerfassung strikt ein. Zunächst geben wir Informationen über die Preisbewegung und die Indikatoren der analysierten Indikatoren in den Quelldatenpuffer ein.
//--- History data
State.AssignArray(Buffer[tr].States[state].state);
Dann gibt es Daten über den Kontostand und offene Positionen.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Die Daten sind durch einen Zeitstempel gekennzeichnet.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Achten Sie darauf, die Handlungen des Agenten anzugeben, die uns zu diesem Zustand geführt haben.
//--- Prev action
State.AddArray(Actions);
Ich möchte noch einmal betonen, dass ich mich strikt an die Konsistenz halte. Die Pufferdaten werden nicht benannt. Das Modell wertet die Daten entsprechend ihrer Position im Puffer aus. Eine Änderung der Reihenfolge wird vom Modell als ein völlig anderer Zustand wahrgenommen. Das Ergebnis der Entscheidung wird völlig unterschiedlich und unvorhersehbar sein. Um das Modell nicht zu verwirren und stets adäquate Lösungen zu erhalten, muss die Reihenfolge der Daten in allen Phasen des Trainings und des Betriebs des Modells strikt eingehalten werden.
Nach der Erfassung des Rohdatenpuffers führen wir zunächst einen Vorwärtsdurchlauf des Encoders und des Umgebungsmodells durch.
//--- Latent and Wordl if(!Latent.feedForward(GetPointer(State)) || !World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Beachten Sie, dass wir während des Trainings keine Kandidatenaktionen generieren. Außerdem werden das Umgebungsmodell und die Politik des Akteurs getrennt geschult. Dies ist auf die Besonderheiten der Modellschulung zurückzuführen.
Das Umgebungsmodell wird so trainiert, dass es die Politik des Agenten auf der Grundlage der vorherigen Trajektorie abschätzt und den Erhalt der Belohnung in der Zukunft vorhersagt, wobei der aktuelle Zustand der Umgebung und die verwendete Politik berücksichtigt werden. Gleichzeitig passen wir die Verteilung der latenten Repräsentation an. Dazu führen wir nach einem erfolgreichen Vorwärtsdurchlauf einen Rückwärtsdurchlauf des Umgebungsmodells und des Encoders durch, um den Vorhersagefehler des Umgebungsmodells und der tatsächlichen Belohnung aus dem Erfahrungswiedergabepuffer zu minimieren.
Actions.Assign(Buffer[tr].States[state].rewards); vector<float> result; World.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!World.backProp(Result,GetPointer(Latent),LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL,LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Bitte beachten Sie, dass wir nach dem Umgebungsmodell-Backpass zunächst einen partiellen Encoder-Backpass durchführen, um die Einbettungsparameter entsprechend den Anforderungen des Umgebungsmodells zu optimieren. Anschließend führen wir einen vollständigen Rückwärtsdurchlauf des Encoders durch, bei dem die Verteilung der latenten Repräsentation optimiert wird.
Wir optimieren die Akteurspolitik, um den latenten Zustand und die ausgeführte Aktion abzugleichen. Daher extrahieren wir die Verteilung der latenten Repräsentation aus dem Erfahrungswiedergabepuffer und speisen sie in den Input des Umgebungsmodells ein, um die latente Repräsentation neu zu erfassen. Als Nächstes führen wir einen direkten Durchlauf der Umgebungsmodelle und des Akteurs durch.
//--- Policy Feed Forward Result.AssignArray(Buffer[tr].States[state+1].latent); Latent.GetLayerOutput(LatentLayer,Result2); if(Result2.GetIndex()>=0) Result2.BufferWrite(); if(!World.feedForward(Result, 1, false, Result2) || !Agent.feedForward(GetPointer(World),2,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Dann führen wir einen umgekehrten Durchlauf des Akteurs durch, um den Fehler zwischen der vorhergesagten Aktion und der tatsächlich durchgeführten Aktion aus dem Erfahrungswiedergabepuffer zu minimieren.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result,NULL,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Auf diese Weise trainieren wir die Politik des Akteurs und machen sie berechenbarer. Gleichzeitig trainieren wir ein Umgebungsmodell, um frühere Entwicklungen zu bewerten und die Rentabilität zu verstehen. Wir trainieren den Encoder, die eingehenden Trajektorien zu destillieren, um grundlegende Informationen über Umgebungtrends und die aktuelle Politik des Akteurs zu erhalten.
All dies zusammen ermöglicht es uns, recht interessante Akteurspolitiken zu entwickeln, die die Stochastizität der Umgebung und die Gewinnwahrscheinlichkeit berücksichtigen.
Sobald die Modellaktualisierung erfolgreich abgeschlossen ist, informieren wir den Nutzer über den Trainingsfortschritt und fahren mit der nächsten Iteration unseres verschachtelten Schleifensystems fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "World", iter * 100.0 / (double)(Iterations), World.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Wenn alle Iterationen des Schleifensystems abgeschlossen sind, löschen wir das Kommentarfeld. Die Ergebnisse der Modellschulung werden in einem Journal angezeigt. Initiieren der Beendigung des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "World", World.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist die Betrachtung des Model Training EA für unsere Interpretation der SPLT-Transformer-Methode abgeschlossen. Der vollständige Code des EA und aller im Artikel verwendeten Programme ist im Anhang verfügbar. Dort finden Sie auch den Code für den Modell-Test EA „...\SPLT\Test.mq5“. Wir werden in diesem Artikel nicht näher auf die Methoden eingehen. Die EA-Struktur wiederholt die bereits besprochenen ähnlichen EAs aus früheren Artikeln. Die Implementierungsmerkmale des vorgestellten Algorithmus in der OnTick-Funktion entsprechen vollständig der Implementierung einer ähnlichen Methode in der Datenerfassung EA für die Trainingsstichprobe. Ich empfehle Ihnen, sich mit diesem EA in den angehängten Dateien vertraut zu machen.
Wir gehen zur nächsten Phase über - dem Testen von Modellen anhand historischer Daten im MetaTrader 5 Strategie-Tester.
3. Tests
Die Modelle wurden anhand historischer Daten für die ersten 7 Monate des EURUSD H1 trainiert. Für alle Indikatoren werden die Standardparameter ohne zusätzliche Optimierung verwendet.
Als erstes starten wir den Trainingsmuster-Sammel-EA im langsamen Optimierungsmodus des Strategietesters. Auf diese Weise können wir mit mehreren Testagenten parallel Daten sammeln. Auf diese Weise erhöhen wir die Anzahl der Trajektorien im Erfahrungswiedergabepuffer und minimieren gleichzeitig die für die Datenerfassung aufgewendete Zeit.
Der betrachtete Algorithmus geht davon aus, dass die Modelle nur offline trainiert werden. Um die Leistung zu testen, schlage ich daher vor, den Erfahrungswiedergabepuffer zu maximieren und ihn mit einer Vielzahl von Trajektorien zu füllen. Es ist jedoch anzumerken, dass die Erstellung von Aktionskandidaten ein recht kostspieliger Prozess ist. Mit zunehmender Zahl der Bewerber steigen auch die Kosten der Datenerhebung.
Nach der Datenerfassung habe ich die Modelle trainiert, ohne zusätzlich Trajektorien zu sammeln, wie es zuvor gemacht wurde. Die Training eines Modells ist, wie immer, ein langer Prozess. Da ich nicht vorhatte, weitere Trajektorien zu sammeln, habe ich die Anzahl der Trajektorien erhöht und meinen Computer für ein Langzeittraining verlassen.
Als Nächstes wurde das trainierte Modell an historischen Daten für August 2023 getestet, die nicht im Trainingssatz enthalten waren.
Auf der Grundlage der Testergebnisse zeigte das Modell einen kleinen Gewinn und einen ziemlich genauen Handel. Ich möchte Sie daran erinnern, dass die SPLT-Transformer-Methode für das autonome Fahren entwickelt wurde und eine maximale Risikominderung vorsieht.
Das Testdiagramm zeigt eine Tendenz, dass der Saldo fast den ganzen Monat über wächst. Nur in der letzten Woche des Monats ist eine Reihe von unrentablen Handelsgeschäften zu beobachten. Die zuvor aufgelaufenen Gewinne reichten jedoch aus, um die Verluste zu decken. Insgesamt wurde am Ende des Monats ein kleiner Gewinn erzielt.


Während des gesamten Testzeitraums öffnete das Modell nur 16 Positionen mit einem Mindestvolumen. Der Anteil der gewinnbringenden Geschäfte beträgt nur 37,5 %. Allerdings ist der durchschnittliche Gewinn um fast 70 % höher als der durchschnittliche Verlust. Infolgedessen beträgt der Gewinnfaktor gemäß den Testergebnissen 1,02.
Schlussfolgerung
In diesem Beitrag stellen wir SPLT-Transformer vor, eine innovative Methode, die entwickelt wurde, um Probleme beim Offline Reinforcement Learning im Zusammenhang mit optimistischem Agentenverhalten zu lösen. Die Konstruktion zuverlässiger und effizienter Agentenpolitiken wird mit Hilfe von zwei separaten Modellen erreicht, die die Politik und das Weltmodell darstellen.
Die Kernkomponenten von SPLT-Transformer, einschließlich des Algorithmus zur Generierung von Trajektoriekandidaten, ermöglichen es uns, eine Vielzahl von Szenarien zu simulieren und Entscheidungen unter Berücksichtigung einer Vielzahl möglicher zukünftiger Ergebnisse zu treffen. Dies macht die vorgestellte Methode sehr anpassungsfähig und sicher in verschiedenen stochastischen Umgebungen. Die Autoren der Methode haben experimentelle Ergebnisse im Bereich des autonomen Fahrens vorgelegt, die die überlegene Leistung von SPLT-Transformer im Vergleich zu bestehenden Methoden bestätigen.
Im praktischen Teil des Artikels haben wir unsere eigene, leicht vereinfachte Interpretation der besprochenen Methode entwickelt. Wir haben die resultierenden Modelle trainiert und getestet. Die Testergebnisse haben gezeigt, dass das Modell in der Lage ist, je nach Situation sowohl vorsichtiges als auch optimistisches Verhalten zu zeigen. Dies macht ihn zu einer idealen Wahl für unternehmenskritische Systeme.
Insgesamt verdient die Methode eine weitere Entwicklung. Eine gründlichere Training der Modelle kann meines Erachtens zu besseren Ergebnissen führen.
Ich erinnere Sie noch einmal daran, dass alle in dieser Artikelserie vorgestellten Programme nur zur Demonstration und zum Testen der betreffenden Algorithmen erstellt wurden. Sie sind nicht für den Handel auf echten Konten geeignet. Bevor ein bestimmtes Modell im realen Handel eingesetzt wird, empfiehlt es sich, es gründlich zu trainieren und zu testen.
Links
- Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
- Neuronale Netze leicht gemacht (Teil 58): Decision Transformer (DT)
- Neuronale Netze sind einfach (Teil 59): Dichotomie der Kontrolle (DoC)
- Neuronale Netze leicht gemacht (Teil 60): Online-Entscheidungstransformator (ODT)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13639
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuronale Netze - Es ist ganz einfach (Teil 61)
Teil 61, können Sie das Ergebnis in Geldwerten sehen?
Neuronale Netze - Es ist ganz einfach (Teil 61)
61 Teile, können Sie sich das Ergebnis in Geld ausdrücken?
Ich muss ein großes Dankeschön an den Autor sagen, der einen rein theoretischen Artikel nimmt und in populärer Sprache erklärt, wie es geht:
Werfen Sie einen Blick auf den Originalartikel und sehen Sie selbst, was für eine Arbeit Dmitry geleistet hat - https://arxiv.org/abs/2207.10295.