
Dominando los registros (Parte 1): Conceptos fundamentales y primeros pasos en MQL5

Introducción
¡Bienvenidos al comienzo de otro viaje! Este artículo abre una serie especial donde crearemos, paso a paso, una librería para el manejo de logs, adaptada para quienes desarrollan en el lenguaje MQL5. La idea es simple, pero ambiciosa: ofrecer una herramienta robusta, flexible y de alta calidad, capaz de hacer del registro y análisis de logs en Expert Advisors (EAs) algo más práctico, eficiente y potente.
Hoy en día, contamos con los registros nativos de MetaTrader 5, que incluso cumplen su función de monitorear lo básico: inicio del terminal, conexiones al servidor, detalles del entorno. Pero seamos honestos, estos registros no fueron diseñados para las particularidades del desarrollo de EA. Cuando queremos entender el comportamiento específico de un EA en ejecución, aparecen limitaciones. Falta precisión, control y esa personalización que marca la diferencia.
Aquí es donde entra la propuesta de esta serie: ir más allá. Construiremos un sistema de registro personalizado desde cero, completamente personalizable. Imagine tener control total sobre qué registrar: eventos críticos, seguimiento de errores, análisis de rendimiento o incluso almacenar información específica para futuras investigaciones. Todo ello, por supuesto, de forma organizada y con la eficacia que el escenario exige.
Pero no es sólo cuestión de código. Esta serie va más allá del teclado. Exploraremos los fundamentos del registro, comprenderemos el "por qué" antes del "cómo", analizaremos las mejores prácticas de diseño y juntos construiremos algo que no solo sea funcional, sino también elegante e intuitivo. Después de todo, crear software no se trata sólo de resolver problemas, también es un arte.
¿Qué son los registros?
Funcionalmente, los registros son registros cronológicos de eventos que los sistemas y aplicaciones generan constantemente. Son como relatos de testigos presenciales de cada solicitud realizada, de cada error cometido y de cada decisión tomada por el asesor experto. Si un desarrollador quiere averiguar por qué se interrumpió un flujo, los registros son su punto de partida. Sin ellos, interpretar lo que sucede equivaldría a explorar un laberinto en la oscuridad.
Lo cierto es que estamos cada vez más rodeados de un universo digital donde los sistemas no son sólo herramientas, sino engranajes esenciales en un mundo que respira código. Piense en las comunicaciones instantáneas, en transacciones financieras en fracciones de segundo o en el control automatizado de una planta industrial. La confiabilidad aquí no es un lujo sino un requisito previo. Pero... ¿qué pasa cuando las cosas van mal? ¿Dónde comienza la búsqueda de lo que se rompió? Los registros son la respuesta. Son los ojos y los oídos dentro de la caja negra que llamamos sistemas.
Imagine lo siguiente: un asesor experto, en una negociación automatizada, comienza a fallar en el envío de solicitudes masivas al servidor. De repente, aparecen los rechazos. Sin registros estructurados, uno se limita a lanzar hipótesis al aire: ¿está sobrecargado el servidor? ¿Quizás la configuración del asesor experto sea incorrecta? Con registros bien diseñados, no sólo se puede encontrar el "pajar", sino también localizar la aguja exacta, un error de autenticación, un tiempo de espera o incluso un volumen excesivo de solicitudes.
Pero no todo es perfecto en los registros. Utilizarlas sin criterio puede acabar siendo un tiro en el pie: se acumulan datos irrelevantes, los costes de almacenamiento se disparan y, en el peor de los casos, puede filtrarse información sensible. Además, no basta con tener registros, es necesario saber configurarlos claramente e interpretarlos con precisión. De lo contrario, lo que debería ser un mapa se convierte en ruido caótico, más confusión que solución.
Ver los registros en profundidad es comprender que no son sólo herramientas. Son socios silenciosos que revelan, en el momento adecuado, lo que los sistemas tienen que decir. Y como en toda buena relación, el valor está en saber escuchar.
De una manera un poco más práctica, los registros consisten en líneas de texto que documentan eventos específicos dentro de un sistema. Pueden contener información como:
- Fecha y hora del evento: Para rastrear cuándo sucedió algo.
- Tipo de evento: Error, advertencia, información, depuración, entre otros.
- Mensaje descriptivo: Explicación de lo sucedido.
- Contexto adicional: Detalles técnicos, como valores de las variables en el momento, datos sobre el gráfico, como el marco temporal o el símbolo, o incluso algún valor de un parámetro que se utilizó.
Ventajas de usar registros
A continuación, detallamos algunas de las principales ventajas que ofrece el uso de logs, destacando cómo pueden optimizar las operaciones y garantizar la eficiencia de los asesores expertos.
1. Depuración y solución de problemas
Con registros bien estructurados, todo cambia. No solo proporcionan una visión de lo que salió mal, sino también del por qué y el cómo. Un error, que antes parecía una sombra fugaz, se convierte en algo que puedes rastrear, comprender y corregir. Es como tener una lupa que magnifica cada detalle crítico del momento en que ocurrió el problema.
Imaginemos, por ejemplo, que una solicitud falla inesperadamente. Sin registros, el problema podría atribuirse al azar y la solución quedaría en manos de la conjetura. Pero con registros claros, el escenario cambia. El mensaje de error aparece como una baliza, acompañada de datos valiosos sobre la solicitud en cuestión: parámetros enviados, respuesta del servidor o incluso un tiempo de espera inesperado. Este contexto no sólo revela el origen del error sino que también ilumina el camino para solucionarlo.
Ejemplo práctico de un registro de errores:
[2024-11-18 14:32:15] ERROR : Limit Buy Trade Request Failed - Invalid Price in Request [10015 | TRADE_RETCODE_INVALID_PRICE]
Este registro revela exactamente cuál fue el error, el intento de enviar una solicitud al servidor, mostrando que el código de error fue 10015, lo que representa un error de precio inválido en la solicitud, por lo que el desarrollador del asesor experto puede saber exactamente en qué orden está el error, en este ejemplo es al enviar una orden de compra limitada.
2. Auditoría y cumplimiento
Los registros desempeñan un papel esencial en lo que respecta a la auditoría y el cumplimiento de las normas y políticas de seguridad. En sectores que manejan datos sensibles, como el financiero, la exigencia de registros detallados va más allá de la mera organización: es una cuestión de estar alineado con las leyes y regulaciones que rigen la operación.
Sirven como un rastro confiable que documenta cada acción relevante: quién accedió a la información, a qué hora y qué se hizo. Esto no sólo aporta transparencia al entorno, sino que también se convierte en una herramienta poderosa en la investigación de incidentes de seguridad o prácticas cuestionables. Con registros bien estructurados, identificar actividades irregulares deja de ser un desafío nebuloso y se convierte en un proceso directo y eficiente, fortaleciendo la confianza y la seguridad en el sistema.
3. Monitoreo del rendimiento
El uso de registros también es crucial para la supervisión del rendimiento de los sistemas. En entornos de producción, donde el tiempo de respuesta y la eficiencia son cruciales, los registros le permiten realizar un seguimiento del estado de su asesor experto en tiempo real. Los registros de rendimiento pueden incluir información sobre el tiempo de respuesta del pedido, el uso de recursos (como CPU, memoria y disco) y las tasas de error. A partir de ahí, se pueden tomar acciones correctivas, como la optimización del código.
Ejemplo de registro de rendimiento:
[2024-11-18 16:45:23] INFO - Server response received, EURUSD purchase executed successfully | Volume: 0.01 | Price: 1.01234 | Duration: 49 ms
4. Automatización y alertas
La automatización se destaca como una de las grandes ventajas de los registros, especialmente cuando se integran con herramientas de monitoreo y análisis. Con la configuración adecuada, los registros pueden activar alertas automáticas tan pronto como se detectan eventos críticos, lo que garantiza que el desarrollador sea informado inmediatamente sobre fallos, errores o incluso pérdidas importantes generadas por el Asesor Experto.
Estas alertas van más allá de simples avisos: pueden enviarse por correo electrónico, SMS o integrarse en plataformas de gestión, lo que permite una reacción rápida y precisa. Este nivel de automatización no solo protege al sistema contra problemas que pueden escalar rápidamente, sino que también le da al desarrollador el poder de actuar de manera proactiva, minimizando los impactos y garantizando la estabilidad del entorno.
Ejemplo de un registro con una alerta:
[2024-11-18 19:15:50] FATAL - CPU usage exceeded 90%, immediate attention required.
En resumen, los beneficios de utilizar registros van mucho más allá de simplemente registrar información sobre lo que sucede en su Asesor Experto. Proporcionan una poderosa herramienta para la depuración, la supervisión del rendimiento, la auditoría de seguridad y la automatización de alertas, lo que los convierte en un componente indispensable para gestionar eficientemente la infraestructura de sus expertos.
Definición de los requisitos de la biblioteca
Antes de iniciar el desarrollo, es fundamental establecer una visión clara de lo que queremos conseguir. De esta manera evitamos reelaboraciones y garantizamos que la biblioteca satisfaga las necesidades reales de quienes la utilizarán. Con esto en mente, he enumerado las principales características que esta biblioteca de manejo de registros debería ofrecer:
-
Singleton
La biblioteca debe implementar el patrón de diseño Singleton para garantizar que todas las instancias accedan al mismo objeto de registro. Esto garantiza la coherencia en la gestión de registros en las diferentes partes del código y evita la duplicación innecesaria de recursos. En el próximo artículo abordaré esto con más detalle.
-
Almacenamiento de bases de datos
Quiero que todos los registros se almacenen en una base de datos, lo que permite realizar consultas sobre los datos. Esta es una característica clave para analizar el historial, las auditorías e incluso identificar patrones de comportamiento.
-
Diferentes salidas
La biblioteca debe ofrecer flexibilidad para mostrar registros de diversas maneras, como:
- Consola
- Terminal
- Archivos
- Base de datos
Esta diversidad permite acceder a los registros en el formato más conveniente para cada situación.
-
Niveles de registro
Deberíamos admitir diferentes niveles de registro para clasificar los mensajes según su gravedad. Los niveles incluyen:
- DEBUG : Mensajes detallados para la depuración.
- INFO : Información general sobre el funcionamiento del sistema.
- ALERT : Alertas para situaciones que requieren atención, pero que no son críticas.
- ERROR : Errores que afectan a partes del sistema, pero permiten la continuidad.
- FATAL : Problemas graves que interrumpen la ejecución del sistema.
-
Formato de registro personalizado
Es importante permitir que el formato de los mensajes de registro sea personalizable. Un ejemplo sería:
([{timestamp}] {level} : {origin} {message})Esto proporciona flexibilidad para adaptar el resultado a las necesidades específicas de cada proyecto.
-
Registro rotatorio
Para evitar el crecimiento descontrolado de los archivos de registro, la biblioteca debe implementar un sistema de rotación, guardando los registros en archivos diferentes cada día o después de alcanzar un tamaño determinado.
-
Columnas de datos dinámicos
Una característica esencial es la capacidad de almacenar metadatos dinámicos en formato JSON. Estos datos pueden incluir información específica del Asesor Experto en el momento en que se registró el mensaje, enriqueciendo el contexto de los registros.
-
Notificaciones automáticas
La biblioteca debería poder enviar notificaciones en niveles de gravedad específicos, como FATAL. Estas alertas pueden ser enviadas por:
- Correo electrónico
- Mensajes de texto (SMS)
- Alertas de terminal
Esto garantiza que las partes responsables estén informadas inmediatamente sobre cuestiones críticas.
-
Medición de la longitud del código
Por último, es esencial incluir una función para medir la longitud de los fragmentos de código. Esto nos permitirá identificar cuellos de botella en el rendimiento y optimizar los procesos.
Estos requisitos serán la base para el desarrollo de esta biblioteca. A medida que avancemos con la implementación, exploraremos cómo se construirá e integrará cada funcionalidad en el conjunto. Este enfoque estructurado no solo nos ayuda a mantenernos enfocados, sino que también garantiza que el producto final sea sólido, flexible y adaptable a las necesidades de los desarrolladores de Expert Advisor en el entorno MQL5.
Estructuración de la base del proyecto
Ahora que tenemos los requisitos bien definidos, el siguiente paso es empezar a estructurar la base de nuestro proyecto. La organización correcta de archivos y carpetas es crucial para mantener el código modular, fácil de entender y mantener. Con esto en mente, comencemos a crear la estructura inicial de directorios y archivos para nuestra biblioteca de registros.
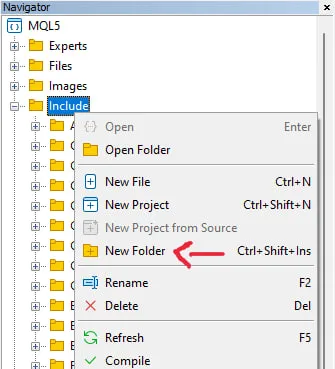
El primer paso es crear una nueva carpeta dentro de la carpeta Includes, que será la encargada de almacenar todos los archivos relacionados con la biblioteca de registros. Para ello, simplemente haga clic derecho en la carpeta Incluye en la pestaña de navegación como se muestra en la imagen y seleccione la opción “Nueva carpeta”:
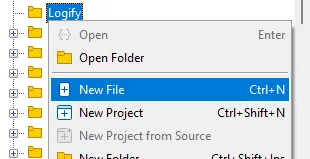
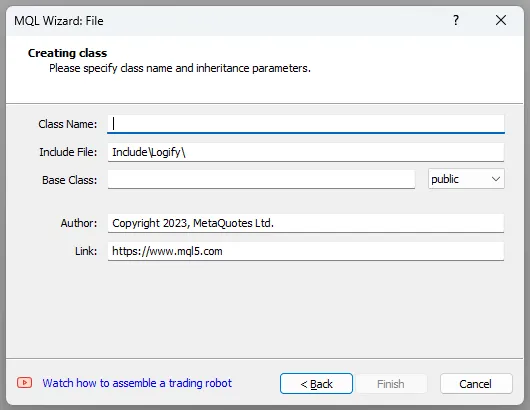
Aparecerá una ventana con las opciones para el nuevo archivo, selecciona la opción “Nueva clase” y presiona “Siguiente”, al hacer esto verás esta ventana:
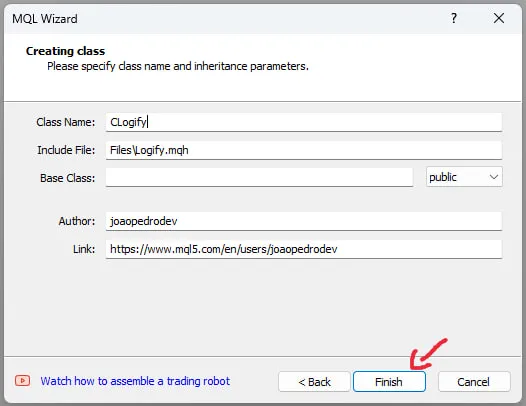
Complete los parámetros, el nombre de la clase será CLogify, luego cambié el nombre del autor y el enlace, pero estos parámetros no son relevantes para la clase. Al final se verá así:
//+------------------------------------------------------------------+ //| Logify.mqh | //| joaopedrodev | //| https://www.mql5.com/en/users/joaopedrodev | //+------------------------------------------------------------------+ #property copyright "joaopedrodev" #property link "https://www.mql5.com/en/users/joaopedrodev" #property version "1.00" class CLogify { private: public: CLogify(); ~CLogify(); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLogify::CLogify() { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLogify::~CLogify() { } //+------------------------------------------------------------------+
Siguiendo este mismo paso a paso, crea otros dos archivos:
- LogifyLevel.mqh → Define una enumeración con los niveles de registro que se utilizarán.
- LogifyModel.mqh → Estructura de datos para almacenar información detallada sobre cada registro.
Al final tendremos esta estructura de carpetas y archivos:
|--- Logify |--- Logify.mqh |--- LogifyLevel.mqh |--- LogifyModel.mqh
Con la estructura básica y los archivos iniciales creados, tendremos un esqueleto funcional de la biblioteca de registros.
Creación de niveles de gravedad
Aquí utilizaremos el archivo LogifyLevel.mqh, este archivo define los diferentes niveles de severidad que puede tener un log, encapsulado en un enum. Este es el código de la enumeración que se utilizará:
enum ENUM_LOG_LEVEL { LOG_LEVEL_DEBUG = 0, // Debug LOG_LEVEL_INFOR, // Infor LOG_LEVEL_ALERT, // Alert LOG_LEVEL_ERROR, // Error LOG_LEVEL_FATAL, // Fatal };
Explicación
- Enumeración: Cada valor de la enumeración representa un nivel de gravedad para los registros, que va desde LOG_LEVEL_DEBUG (el menos grave) hasta LOG_LEVEL_FATAL (el más grave).
- Usabilidad: Esta enumeración se utilizará para clasificar los registros en diferentes niveles, lo que facilitará el filtrado o la realización de acciones específicas en función de la gravedad.
Creación del modelo de datos
Ahora, creemos una estructura de datos para almacenar la información de registro que manejará la biblioteca. Esta estructura se almacenará en el archivo LogifyModel.mqh y servirá como base para almacenar todos los registros capturados por el sistema.
A continuación se muestra el código para definir la estructura MqlLogifyModel, que se encargará de almacenar los datos esenciales de cada entrada del registro, como la marca de tiempo (fecha y hora del evento), la fuente (desde donde se generó el registro), el mensaje del registro y cualquier metadato adicional.
//+------------------------------------------------------------------+ //| LogifyModel.mqh | //| joaopedrodev | //| https://www.mql5.com/en/users/joaopedrodev | //+------------------------------------------------------------------+ #property copyright "joaopedrodev" #property link "https://www.mql5.com/en/users/joaopedrodev" //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ #include "LogifyLevel.mqh" //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ struct MqlLogifyModel { ulong timestamp; // Date and time of the event ENUM_LOG_LEVEL level; // Severity level string origin; // Log source string message; // Log message string metadata; // Additional information in JSON or text MqlLogifyModel::MqlLogifyModel(void) { timestamp = 0; level = LOG_LEVEL_DEBUG; origin = ""; message = ""; metadata = ""; } MqlLogifyModel::MqlLogifyModel(ulong _timestamp,ENUM_LOG_LEVEL _level,string _origin,string _message,string _metadata) { timestamp = _timestamp; level = _level; origin = _origin; message = _message; metadata = _metadata; } }; //+------------------------------------------------------------------+
Explicación de la estructura de datos
- timestamp: Un valor ulong que almacena la fecha y la hora del evento. Este campo se rellenará con la marca de tiempo del registro en el momento en que se creó la entrada del registro.
- level: Nivel de gravedad del mensaje.
- origin: Un campo de cadena (string) que identifica el origen del registro. Esto puede ser útil para determinar qué parte del sistema generó el mensaje de registro (por ejemplo, el nombre del módulo o la función).
- message: El mensaje de registro en sí, también de tipo cadena, que describe el evento o la acción que se produjo en el sistema.
- metadata: Un campo adicional que almacena información adicional sobre el registro. Este puede ser un objeto JSON o una cadena de texto simple que contiene datos adicionales relacionados con el evento. Esto es útil para almacenar información contextual, como parámetros de ejecución o datos específicos del sistema.
Constructores
- El constructor predeterminado inicializa todos los campos con valores vacíos o cero.
- El constructor parametrizado le permite crear una instancia de MqlLogifyModel rellenando directamente los campos con valores específicos, como la marca de tiempo, la fuente, el mensaje y los metadatos.
Implementando la clase principal CLogify
Ahora implementaremos la clase principal de la biblioteca de registro, CLogify , que servirá como núcleo para gestionar y mostrar los registros. Esta clase incluye métodos para diferentes niveles de registro y un método genérico llamado Append que es utilizado por todos los demás métodos.
La clase se definirá en el archivo Logify.mqh y contendrá los siguientes métodos:
//+------------------------------------------------------------------+ //| class : CLogify | //| | //| [PROPERTY] | //| Name : Logify | //| Heritage : No heritage | //| Description : Core class for log management. | //| | //+------------------------------------------------------------------+ class CLogify { private: public: CLogify(); ~CLogify(); //--- Generic method for adding logs bool Append(ulong timestamp, ENUM_LOG_LEVEL level, string message, string origin = "", string metadata = ""); //--- Specific methods for each log level bool Debug(string message, string origin = "", string metadata = ""); bool Infor(string message, string origin = "", string metadata = ""); bool Alert(string message, string origin = "", string metadata = ""); bool Error(string message, string origin = "", string metadata = ""); bool Fatal(string message, string origin = "", string metadata = ""); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CLogify::CLogify() { } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CLogify::~CLogify() { } //+------------------------------------------------------------------+Los métodos de clase se implementarán para mostrar los registros en la consola, utilizando la función Print. Más adelante, estos registros pueden dirigirse a otras salidas, como archivos, bases de datos o gráficos.
//+------------------------------------------------------------------+ //| Generic method for adding logs | //+------------------------------------------------------------------+ bool CLogify::Append(ulong timestamp,ENUM_LOG_LEVEL level,string message,string origin="",string metadata="") { MqlLogifyModel model(timestamp,level,origin,message,metadata); string levelStr = ""; switch(level) { case LOGIFY_DEBUG: levelStr = "DEBUG"; break; case LOGIFY_INFO: levelStr = "INFO"; break; case LOGIFY_ALERT: levelStr = "ALERT"; break; case LOGIFY_ERROR: levelStr = "ERROR"; break; case LOGIFY_FATAL: levelStr = "FATAL"; break; } Print("[" + TimeToString(timestamp) + "] [" + levelStr + "] [" + origin + "] - " + message + " " + metadata); return(true); } //+------------------------------------------------------------------+ //| Debug level message | //+------------------------------------------------------------------+ bool CLogify::Debug(string message,string origin="",string metadata="") { return(this.Append(TimeCurrent(),LOG_LEVEL_DEBUG,message,origin,metadata)); } //+------------------------------------------------------------------+ //| Infor level message | //+------------------------------------------------------------------+ bool CLogify::Infor(string message,string origin="",string metadata="") { return(this.Append(TimeCurrent(),LOG_LEVEL_INFOR,message,origin,metadata)); } //+------------------------------------------------------------------+ //| Alert level message | //+------------------------------------------------------------------+ bool CLogify::Alert(string message,string origin="",string metadata="") { return(this.Append(TimeCurrent(),LOG_LEVEL_ALERT,message,origin,metadata)); } //+------------------------------------------------------------------+ //| Error level message | //+------------------------------------------------------------------+ bool CLogify::Error(string message,string origin="",string metadata="") { return(this.Append(TimeCurrent(),LOG_LEVEL_ERROR,message,origin,metadata)); } //+------------------------------------------------------------------+ //| Fatal level message | //+------------------------------------------------------------------+ bool CLogify::Fatal(string message,string origin="",string metadata="") { return(this.Append(TimeCurrent(),LOG_LEVEL_FATAL,message,origin,metadata)); } //+------------------------------------------------------------------+
Ahora que tenemos la estructura principal y los métodos para mostrar registros básicos, el siguiente paso será crear pruebas para asegurar que funcionen correctamente. Nuevamente, agregaremos soporte para diferentes tipos de salida más adelante, como archivos, bases de datos y gráficos.
Pruebas
Para realizar pruebas en la biblioteca Logify, crearemos un Asesor Experto dedicado. Primero, cree una nueva carpeta llamada Logify dentro del directorio de expertos, que contendrá todos los archivos de prueba. Luego, crea el archivo LogifyTest.mq5 con la estructura inicial: //+------------------------------------------------------------------+ //| LogifyTest.mq5 | //| Copyright 2023, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- } //+------------------------------------------------------------------+
Incluya el archivo de la biblioteca principal y cree una instancia de la clase CLogify:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ #include <Logify/Logify.mqh> CLogify logify;
En la función OnInit, agregue llamadas de registro para probar todos los niveles disponibles:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- logify.Debug("RSI indicator value calculated: 72.56", "Indicators", "Period: 14"); logify.Infor("Buy order sent successfully", "Order Management", "Symbol: EURUSD, Volume: 0.1"); logify.Alert("Stop Loss adjusted to breakeven level", "Risk Management", "Order ID: 12345678"); logify.Error("Failed to send sell order", "Order Management", "Reason: Insufficient balance"); logify.Fatal("Failed to initialize EA: Invalid settings", "Initialization", "Missing or incorrect parameters"); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
Al ejecutar el código, los mensajes esperados en la terminal MetaTrader 5 se mostrarán de la siguiente manera:
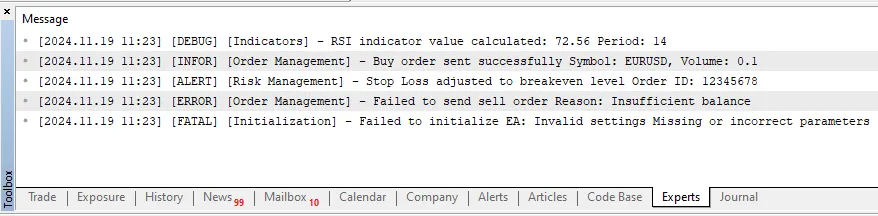
Conclusión
La biblioteca Logify se ha probado con éxito y muestra correctamente los mensajes de registro para todos los niveles disponibles. Esta estructura básica permite una gestión de registros organizada y ampliable, lo que proporciona una base sólida para futuras mejoras, como la integración con bases de datos, archivos o gráficos.
Con una implementación modular y métodos fáciles de usar, Logify ofrece flexibilidad y claridad en la gestión de registros en aplicaciones MQL5. Los próximos pasos pueden incluir la creación de salidas alternativas y la adición de configuraciones dinámicas para personalizar el comportamiento de la biblioteca. ¡Nos vemos en el próximo artículo!
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16447
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso