
Trabajamos con archivos ZIP con los medios de MQL5, sin usar bibliotecas ajenas

Índice
- Introducción
- Capítulo 1. Formato del archivo ZIP y métodos de guardado de datos en el mismo
- Capítulo 2. Estudio general de la clase CZip y sus algoritmos
- Capítulo 3. Ejemplos de uso de la clase CZip, medición de la productividad
- Capítulo 4. Documentación de las clases para trabajar con los archivos ZIP
- Conclusión
Introducción
Historia de la cuestión
Cierta vez, al autor de este artículo le llamó la atención un peculiaridad interesante de la función CryptDecode, que era precisamente la posibilidad de descomprimir la matriz ZIP trasmitida a ella. Este modificador fue introducido por los desarrolladores de la plataforma comercial MetaTrader 5 para que fuese posible descomprimir la respuesta de ciertos servidores, usando la función estándar WebRequest. Sin embargo, debido a ciertas peculiaridades del formato ZIP, no resultaba posible usarla directamente.
Era necesaria una autenticación adicional: para descomprimir un archivo, resultaba necesario saber su suma hash antes de la compresión: Adler-32, que, como era natural, no existía. Sin embargo, al discutir este problema, los desarrolladores simplificaron el asunto y cargaron de nuevo CryptDecode y CryptEncode, su gemelo opuesto, con una bandera especial que ignoraba el hash Adler32 al descomprimir los datos transmitidos. Para los usuarios inexpertos en el plano técnico, esta novedad se puede explicar de forma sencilla: gracias a ella es posible un trabajo funcionalmente pleno con los archivos ZIP. El artículo describe detalladamente el formato del archivo ZIP, las peculiaridades de guardado en el mismo, y propone para el trabajo con el archivo una cómoda clase CZip orientada a objetos.
Para qué se necesita
La compresión de datos es una de las tecnologías más importantes, y está especialmente difundida en el entorno Web. Gracias a la compresión se economizan recursos imprescindibles para la transmisión, guardado y procesamiento de información. La compresión de datos se usa prácticamente en todas las esferas de las comunicaciones y ha penetrado en todas las tareas con las que nos encontramos al trabajar con una computadora.
La esfera económica tampoco es una excepción: gigabytes de historia de tics, flujos de cotizaciones, incluyendo los moldes de la profundidad de mercado (datos Level2), todo ello es impensable que se pueda guardar en bruto, sin comprimir. Muchos servidores, incluidos los que proporcionan información analítica, interesante para el comercio, también guardan datos en archivos ZIP. Antes no se creía posible recibir estos datos de forma automática, usando las herramientas MQL5 estándar. Ahora la situación ha cambiado.
Con la ayuda de la función WebRequest se pueden descargar archivos ZIP y descomprimir sus datos sobre la marcha en la memoria operativa de la computadora. Todas estas posibilidades son importantes y, a buen seguro, muy requeridas por muchos tráders. La compresión de datos se puede usar incluso para ahorrar la memoria operativa de la computadora. Veremos cómo se hace en el apartado 3.2 del artículo. Y por último, saber trabajar con los archivos ZIP abre acceso a la formación de documentos del tipo Microsoft Office según el estándar Office Open XML, lo que hace posible, a su vez, la creación de archivos sencillos de Excel o Word directamente desde MQL5, sin usar tampoco bibliotecas DLL ajenas.
Como podemos ver, el uso del archivado ZIP es muy amplio, y una clase creada por nosotros hará muy buen servicio a todos los usuarios de MetaTrader.
En el primer capítulo del presente artículo, describiremos detalladamente el propio formato del fichero ZIP y comprenderemos de qué bloques de datos consta. Este artículo será interesante no solo para aquellos que estudian MQL, sino que también resultará un material formativo muy útil para aquellos que se dedican al estudio de cuestiones relacionadas con el archivado y guardado de datos. El segundo capítulo está dedicado a las clases CZip, CZipFile y CZipDirectory, estas clases constituyen los principales elementos orientados a objetos para el trabajo con archivos. El tercer capítulo describe ejemplos prácticos, relcionados con el uso del archivado. El cuarto capítulo abarca la documentación para las clases propuestas.
Bien, precedamos al estudio de este tipo de archivado, que es el más extendido.
Capítulo 1. Formato del archivo ZIP y métodos de guardado de datos en el mismo
1.1. Estructura del archivo ZIP
El formato ZIP fue creado por Phil Katz en el año 1989, y se implementó por primera vez en el programa PKZIP para MS-DOS, lanzado por la compañía PKWARE, cuyo fundador era el propio Katz. Este formato de archivo usa la mayoría de las veces el algoritmo de compresión de datos DEFLATE. Los programas de uso más extendido para el trabajo con estos formatos en el entorno Windows son WinZip y WinRAR.
Es importante comprender que el formato de los archivos ZIP se ha disgregado con el tiempo, ahora tiene varias versiones. En la creación de una clase para trabajar con un archivo ZIP, nos apoyaremos en la especificación oficial del formato de la versión 6.3.4, ubicado en la página de la compañía PKWARE en la dirección: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT. Esta es la última especificación del formato, fechada el 1 de octubre 2014. La propia especificación del formato es bastante amplia, e incluye la descripción de multitud de matices.
En este artículo vamos a partir de la ley del mínimo esferzo y vamos a crear un instrumento que usará solo los datos imprescindibles para descomprimir con éxito los ficheros y crear archivos nuevos. Esto significa que, en cierta medida, el trabajo con los ficheros ZIP estará limitado, la compatibilidad de formatos no está garantizada, y esto significa que no tendremos que hablar sobre el carácter plenamente "omnívoro" de los archivos. Es plenamente posible que ciertos archivos ZIP, creados por medios ajenos a lo habitualmente previsto, no puedan ser descomprimidos con la ayuda del instrumento propuesto.
Cada archivo ZIP es un fichero binario que contiene una secuencia ordenada de bytes. Por otra parte, en el archivo ZIP cada fichero tiene nombre, atributos (por ejemplo, la hora de modificación del archivo) y otras propiedades que estamos acostumbrados a ver en el sistema de ficheros de cualquier sistema operativo. Por eso, aparte de datos comprimidos, cada archivo ZIP guarda el nombre del fichero comprimido, sus atributos y otra información accesoria. Esta información accesoria se ubica en un orden muy estricto y tiene una estructura regular. Por ejemplo, si en el archivo se contienen dos ficheros (File#1 y File#2), entonces el archivo tendrá el siguiente aspecto:
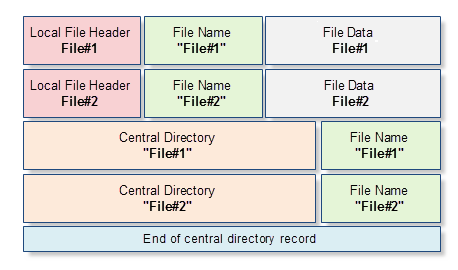
Fig. 1. Representación esquemática de un archivo ZIP que contiene dos ficheros: File#1 y File#2
Más tarde descompondremos detalladamente cada bloque del esquema dado, pero ahora vamos a dar una breve descripción de estos bloques:
- Local File Header — este bloque de datos contiene la información principal sobre el fichero comprimido: el tamaño del fichero antes y después de la compresión, la hora de modificación del fichero, la suma de verificación CRC-32 y el indicador local al nombre del fichero. Además, este bloque contiene la versión del archivador necesaria para la descompresión del fichero.
- File Name — secuencia de bytes de longitud arbitraria, que forma el nombre del fichero comprimido. Al mismo tiempo, la longitud del nombre del fichero no debe superar los 65 536 símbolos.
- File Data — contenido comprimido del fichero en forma de matriz de bytes de longitud arbitraria. Si el fichero está vacío o constituye un catálogo, entonces esta matriz no se usa, y justo detrás del nombre del fichero o directorio va el encabezamiento Local File Header, que describe el siguiente fichero.
- Central Directory — contiene una representación ampliada de datos en Local File Header. Aparte de los datos contenidos en Local File Header, este contiene los atributos del fichero, el enlace local a la estructura Local File Header y cierta información adicional que no se usa en la mayoría de los casos.
- End of central directory record — esta estructura está representada en cada archivo en un único ejemplar, y se guarda al final del archivo. Los datos más interesantes que contiene son la cantidad de anotaciones en el archivo (o la cantidad de ficheros o catálogos) y los enlaces locales al inicio del bloque Central Directory.
Podemos representar cada bloque de este sistema, o bien en forma de estructura regular, o bien en forma de matriz de bytes de longitud arbitraria. Cada una de las estructuras puedes ser descrita, a su vez, con ayuda de una construcción unidimensional de programación en MQL, la estructura.
La estructura siempre ocupa una cantidad de bytes estrictamente determinada, por eso no puede contener dentro de sí misma matrices de longitud arbitraria y líneas. Sin embargo, puede contener índices a estos objetos. Por eso precisamente, los nombres de los ficheros en el archivo están sacados de los límites de la estructura, gracias a lo cual, pueden tener longitud arbitraria. Lo mismo se puede decir de los datos comprimidos de los ficheros, su tamaño es arbitrario, por eso precisamente se contienen más allá de los límites de la estructura. De esta forma, se puede decir que un archivo ZIP constituye una secuencia de estructuras, líneas y datos comprimidos.
El formato del archivo ZIP, aparte de lo dicho más arriba, describe una estructura adicional, llamada Data Descriptor. Esta estructura se usa solo en el caso de que, por algún motivo, no se haya logrado formar la estructura Local File Header, y la parte de los datos necesaria para Local File Header esté disponible ya después de la compresión de los datos. En la práctica, se trata de una situación muy exótica, por eso esta estructura no se usa casi nunca, y en nuestra clase, para trabajar con archivos, este bloque de datos no tiene soporte.
| Preste atención al hecho de que, de acuerdo con el formato del archivo ZIP, cada fichero se comprime independientemente de los otros. Por una parte, esto permite localizar la aparición de errores: un archivo "perjudicado" se puede restablecer eliminando el fichero con el contenido incorrecto y dejando sin cambios todo el resto del contenido del archivo. Por otra parte, al comprimir cada fichero por separado, se reduce la eficacia de la compresión, en especial si cada uno de los ficheros ocupa poco espacio. |
|---|
1.2. Estudiando el archivo ZIP en el editor hexadecimal
Ahora, armados con los conocimientos imprescindibles, podemos ver qué se encuentra dentro del típico archivo ZIP. Para ello, usaremos uno de los editores hexadecimales, WinHex. Si por algún motivo no dispone de WinHex, usted puede usar cualquier otro editor hexadecimal. Y es que debemos recordar que cualquier archivo es un fichero binario que puede ser abierto como una secuencia simple de bytes. Para el experimento, crearemos un archivo ZIP sencillo, que contendrá en su interior un único fichero de texto, con la frase "HelloWorld!" ("¡Hola, mundo!"):

Fig. 2. Creación de un fichero de texto en el bloc de notas
A continuación, usaremos cualquier archivador ZIP, y con su ayuda crearemos un archivo. En nuestro ejemplo, el archivador de este tipo será WinRAR. En él será necesario elegir el fichero que acabamos de crear y archivarlo en el formato ZIP:
Fig. 3. Creación del archivo con ayuda del archivador WinRAR
Después de terminar el archivado en el disco duro de la computadora, en el directorio correspondiente aparecerá un fichero nuevo, llamado "HelloWorld.zip". La primera peculiaridad que salta a la vista en este fichero es su tamaño, 135 bytes, bastante superior al tamaño del fichero inicial de origen, en 11 bytes. Esto está relacionado con que, aparte de los propios datos comprimidos, el archivo ZIP contiene información accesoria. Por eso, para los datos de pocas dimensiones que solo ocupan varios centenares de bytes, el archivado no tiene sentido.
Ahora, cuando tenemos un esquema de ubicación de datos, un archivo que conste de un conjunto de bytes ya no nos asustará. Lo abrimos con ayuda del editor hexadecimal WinHex. En la figura de abajo se muestra la matriz de bytes del archivo con cada zona iluminada según lo descrito en el esquema 1:
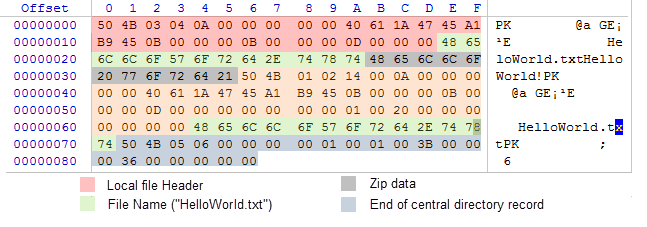
Fig. 4. Contenido interno de un archivo ZIP que contiene el fichero HelloWorld.txt
En resumidas cuentas, la frase "HelloWorld!" está contenida en el diapasón 0x2B por 0x35 bytes y ocupa solo 11 bytes. Preste atención al hecho de que el algoritmo de compresión ha decidido no comprimir la frase de origen, y en el archivo ZIP está presente en la forma original. Esto ha sucedido porque la compresión de un mensaje tan corto no es efectiva, y la matriz comprimida puede resultar incluso menos comprimida.
| Un archivo ZIP no contiene datos comprimidos en todos los casos. A veces, los datos en el archivo se ubican en su estado original, sin descomprimir, incluso si al crear el archivo se indicase claramente que hay que comprimir los datos al archivar. Esta situación surge en el caso cuando el tamaño de los datos no es significativo, y la compresión de los datos no es efectiva. |
|---|
Gracias a la figura 4, se comprende mejor cómo se guardan los diferentes bloques de datos en el archivo obtenido, y dónde se contienen precisamente los datos del fichero. Ahora ha llegado el momento de examinar por separado cada uno de los bloques de datos.
1.3. Estructura de Local File Header
Cada archivo ZIP comienza con la estructura Local File Header. Esta contiene los metadatos del fichero que le sigue en forma de matriz de bytes comprimida. Cada estructura en el archivo, de acuerdo con la especificación del formato, tiene su identificador de cuatro bytes único. Esta estructura tampoco es una excepción, su identificador único es igual a 0x04034B50.
Es importante tener en cuenta que los procesadores compatibles con x86 cargan los datos de los ficheros binarios en la memoria operativa en orden inverso. Las cifras, además, se ubican al revés: el último byte ocupa el lugar del primero, y viceversa. El método de guardado de datos en el fichero se determina por el formato del propio fichero, y para los ficheros en el formato ZIP también se realiza en orden inverso. Se puede leer información más detallada sobre la sucesión de bytes en el artículo de Wikipedia: "Endianness". Para nosotros esto no significa que el identificador de la estructura estará grabado en forma de cifra 0x504B0304 (del valor 0x04034B50, vuelto del revés). Cualquier archivo ZIP comienza precisamente con esta secuencia de bytes.
Dado que la estructura es una secuencia de bytes está estrictamente determinada, la podemos imaginar en forma de estructura análoga en el lenguaje de programación MQL5. La descripción de la estructura Local File Header en MQL5 sería la siguiente:
//+------------------------------------------------------------------+ //| Local file header based on specification 6.3.4: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // ZIP local header, always equals 0x04034b50 ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compression method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC-32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
Esta estructura se usa para el trabajo real con archivos ZIP, por eso, aparte de los propios campos de datos, contiene métodos adicionales que permiten convertir la estructura en un conjunto de bytes (la matriz de bytes uchar) y al revés, crear una estructura a partir de un conjunto de bytes. Vamos a mostra el contenido de los métodos ToCharArray y LoadFromCharArray, que permiten realizar tal transformación:
//+------------------------------------------------------------------+ //|Private struct for convert LocalHeader to uchar array | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // Size of ZipLocalHeader }; //+------------------------------------------------------------------+ //| Convert ZipHeader struct to uchar array. | //| RETURN: | //| Numbers of copied elements. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| Init local header structure from char array | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
Describimos los campos de las estructuras (enumeradas en el orden de la secuencia):
- header — identificador de estructura único, para File Local Header es igual a 0x04034B50;
- version — versión mínima para la descompresión del fichero;
- bit_flag — bandera de bit, tiene el identificador 0x02;
- comp_method — tipo de descompresión utilizado. Como norma, siempre se usa el método de compresión DEFLATE, este tipo de compresión tiene el identificador 0x08.
- last_mod_time — hora de la última modificación del fichero. Contiene las horas, minutos y segundos de la modificación del fichero en el formato MS-DOS. Este formato está descrito en la página de la compañía Microsoft.
- last_mod_date —fecha de la última modificación del fichero. Contiene el día del mes, el número del mes en el año y el año de modificación del fichero en el formato MS-DOS.
- crc_32 — suma de verificación CRC-32. Se usa con los programas de trabajo con los archivos de determinación de errores del contenido del fichero. Si este campo no está relleno, el archivador ZIP se negará a descomprimir el fichero comprimido, objetando que se trata de un fichero dañado.
- comp_size — tamaño en bytes de los datos comprimidos;
- uncomp_size — tamaño en bytes de los datos de origen;
- filename_length — longitud del nombre del fichero;
- extrafield_length — campo especial para el guardado de los atributos adicionales de los datos. No se usa casi nunca, y es igual a cero.
Al guardar esta estructura, en el archivo se crea una secuencia de bytes que guarda los valores de los campos correspondientes de esta estructura. Cargamos de nuevo nuestro archivo ZIP con el fichero HelloWorld.txt en el editor hexadecimal y examinamos la matriz de bytes de esta estructura de una forma ya más detallada:

Fig. 5. Esquema de bytes de la estructura Local File Header en el archivo HelloWorld.zip
Por el esquema podemos ver qué bytes ocupan unos u otros campos de la estructura. Para comprobar los datos en la estructura, prestamos atención al campo "File Name length", este ocupa dos bytes y es igual al valor 0x0D00. Tras volver esta cifra del revés y ponerla en el formato decimal, obtenemos el valor 13, que es precisamente la cantidad de símbolos que ocupa el nombre del fichero "HelloWorld.txt". Lo mismo podemos hacer con el campo que indica el tamaño de los datos comprimidos. Es igual a 0x0B000000, lo cual corresponde a 11 bytes. En realidad, la frase "HelloWorld!" se guarda sin descomprimir en el archivo, y ocupa 11 bytes.
Justo después de la estructura van los datos comprimidos, y a continuación comienza una nueva estructura: Central Directory, la describiremos con más detalle en el siguiente apartado.
1.4. Estructura de Central Directory
La estructura Central Directory constituye una representación de datos ampliada, que se encuentra en Local File Header. En esencia, para el trabajo principal con los archivos ZIP, es suficiente con los datos de Local File Header. Así y con todo, el uso de la estructura Central Directory es obligatorio, y sus valores deberán ser rellenados correctamente. Esta estructura tiene su indicador único 0x02014B50. Su representación en MQL5 sería la siguiente:
//+------------------------------------------------------------------+ //| Central directory structure | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // Central directory header, always equals 0x02014B50 ushort made_ver; // Version made by ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compressed method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data ushort file_comment_length; // Length of comment file ushort disk_number_start; // Disk number start ushort internal_file_attr; // Internal file attributes uint external_file_attr; // External file attributes uint offset_header; // Relative offset of local header bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
Como se puede ver, contiene ya más datos. Sin embargo, la mayor parte de ellos dobla los datos de Local File Header. De la misma forma que la estructura anterior, contiene métodos de servicio para convertir su contenido en una matriz de bytes y viceversa.
Describimos sus campos:
- header — identificador único de estructura, igual a 0x02014B50;
- made_ver — versión del estándar de archivado usado al archivar;
- version — versión mínima del estándar para la descomprimir el fichero con éxito;
- bit_flag — bandera de bits, tiene el identificador 0x02;
- comp_method — tipo de descompresión utilizado. Como norma, siempre se usa el método de compresión DEFLATE, este tipo de compresión tiene el identificador 0x08.
- last_mod_time — hora de la última modificación del fichero. Contiene las horas, minutos y segundos de la modificación del fichero en el formato MS-DOS. Este formato está descrito en la página de la compañía Microsoft.
- last_mod_date —fecha de la última modificación del fichero. Contiene el día del mes, el número del mes en el año y el año de modificación del fichero en el formato MS-DOS.
- crc_32 — suma de verificación CRC-32. Se usa con los programas de trabajo con los archivos de determinación de errores del contenido del fichero. Si este campo no está relleno, el archivador ZIP se negará a descomprimir el fichero comprimido, objetando que se trata de un fichero dañado.
- comp_size — tamaño en bytes de los datos comprimidos;
- uncomp_size — tamaño en bytes de los datos de origen;
- filename_length — longitud del nombre del fichero;
- extrafield_length — campo especial para el guardado de los atributos adicionales de los datos. No se usa casi nunca, y es igual a cero.
- file_comment_length — longitud del comentario al fichero;
- disk_number_start — número del disco en el que se guarda el archivo. Prácticamente siempre es igual a cero.
- internal_file_attr — atributos del fichero en formato MS-DOS;
- external_file_attr — atributos ampliados del fichero en formato MS-DOS;
- offset_header — dirección en la que se ubica el inicio de la estructura Local File Header.
Al guardar esta estructura en el archivo se crea una secuencia de bytes que guarda los valores de sus campos. Mostramos el esquema de ubicación de los bytes de esta estructura, de forma similar a la figura 5:

Fig. 6. Esquema de bytes de la estructura Central Directory en el archivo HelloWorld.zip
A diferencia de Local File Header, las estructuras Central Directory van consecutivamente una tras otra. La dirección del principio de la primera de ellas está indicada en el bloque especial de datos en el cierre, es la estructura ECDR. Describiremos más detalladamente esta estructura en el siguiente apartado.
1.5. Estructura de End of Central Directory Record (ECDR)
La estructura End of Central Directory Record (o simplemente ECDR) da término al fichero ZIP. Su identificador único es igual a 0x06054B50. En cada archivo está contenida en un único ejemplar. ECDR guarda la cantidad de ficheros y directorios que se encuentran en el archivo, así como la dirección del comienzo de la secuecnia de las estructuras Central Directory y su tamaño total. Aparte de esto, el bloque de datos guarda también otra información. Mostramos la descripción completa de ECDR en MQL5:
//+------------------------------------------------------------------+ //| End of central directory record structure | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // Header of end central directory record, always equals 0x06054b50 ushort disk_number; // Number of this disk ushort disk_number_cd; // Number of the disk with the start of the central directory ushort total_entries_disk; // Total number of entries in the central directory on this disk ushort total_entries; // Total number of entries in the central directory uint size_central_dir; // Size of central directory uint start_cd_offset; // Starting disk number ushort file_comment_lengtt; // File comment length string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
Vamos a describir los campos de la estructura con más detalle:
- header — identificador único de estructura, igual a 0x06054B50;
- disk_number — número del disco;
- disk_number_cd — número del disco desde el que comienza Central Directory;
- total_entries_disk — número total de entradas en la sección Central Directory (cantidad de ficheros y directorios);
- total_entries — entradas totales (cantidad de ficheros y directorios);
- size_central_dir — tamaño de la sección Central Directory;
- start_cd_offset — dirección de bytes del comienzo de la sección Central Directory;
- çfile_comment_length — longitud del comentario al archivo.
Al guardar esta estructura en el archivo se crea una secuencia de bytes que guarda los valores de sus campos. Mostramos el esquema de ubicación de los bytes de esta estructura:

Fig. 7. Esquema de bytes de la estructura ECDR
Este bloque de datos lo usaremos al determinar la cantidad de elementos en la matriz.
Capítulo 2. Estudio general de la clase CZip y sus algoritmos
2.1. Estructura de los ficheros comprimidos en el archivo, las clases CZipFile y CZipFolder
Bien, en el primer capítulo examinamos con detalle el formato de un archivo ZIP. Estudiamos de qué tipos de datos consta, y describimos estos tipos en las estructuras correspondientes. Al determinar estas estructuras, implementamos la clase especial de alto nivel CZip, con ayuda de la cual se podrán finalizar fácil y sencillamente las siguientes acciones con un archivo ZIP:
- Crear un nuevo archivo;
- Abrir un archivo creado con anterioridad en el disco duro;
- Cargar un archivo desde un servidor remoto;
- Añadir nuevos ficheros al archivo;
- Eliminar ficheros desde el archivo;
- Descomprimir un archivo, tanto de forma completa, como sus ficheros por separado.
La clase CZip asume la tarea de rellenar correctamente las estructuras necesarias en el archivo, proporcionándonos el habitual interfaz de alto nivel para trabajar con la colección de ficheros del archivo. Las posibilidades que proporciona la clase, son más que suficientes para la inmensa mayoría de las tareas relacionadas con el archivado.
Resulta obvio que el contenido de un archivo ZIP se puede dividir en carpetas y ficheros. Ambos tipos de contenido disponen de un amplio conjunto de propiedades: nombre, tamaño, atributos del fichero, hora de creación etcétera. Algunas de estas propiedades son comunes tanto para las carpetas, como para los ficheros, y algunas otras, como por ejemplo los datos comprimidos, no. Por eso, la decisión óptima para trabajar con un archivo será proporcionar las clases accesorias especiales: CZipFile y CZipDirectory. Precisamente estas clases mostrarán los ficheros y las carpetas de forma correspondiente. Más abajo mostramos un esquema con la clasificación convencional del contenido en el archivo.
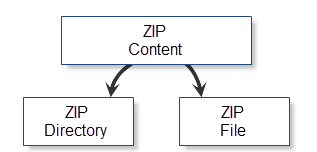
Fig. 8. Clasificación convencional de objetos en el archivo
De esta forma, para añadir un fichero al archivo CZip, es necesario crear en primer lugar un objeto del tipo CZipFile, y a continuación añadir este objeto al archivo. Como ejemplo, crearemos el fichero de texto "HelloWorld.txt", que contiene el texto homónimo "HelloWorld!" y lo añadiremos al archivo:
//+------------------------------------------------------------------+ //| Create file with 'HelloWorld' message | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // creamos un archivo ZIP vacío uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // grabamos en la matriz de bytes la frase "HelloWorld!" CZipFile* file = new CZipFile("HelloWorld.txt",content); // creamos un fichero ZIP con el nombre "HelloWorld.txt" // matriz de bytes que contiene "HelloWorld!" zip.AddFile(file); // añadimos el fichero ZIP al archivo zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // guardamos el archivo en el disco con el nombre "HelloWorld.zip" printf("Size: "+(string)zip.Size()); }
Después de ejecutar este código en el disco de la computadora aparecerá un nuevo archivo ZIP, que contendrá un único fichero de texto "HelloWorld.txt" con una frase homónima. Si quisiéramos crear una carpeta en lugar del fichero, entonces, en lugar de CZipFile, necesitaríamos un ejemplar de la clase CZipFolder. Para crearlo, sería suficiente con indicar solo el nombre.
Como ya hemos dicho con anterioridad, las clases CZipFile y CZipFolder tienen mucho en común. Por eso, ambas clases se heredan de su progenitor común, CZipContent. Esta clase contiene métodos y datos comunes para trabajar con el contenido del archivo.
2.2. Creación de ficheros comprimidos con ayuda de CZipFile
La creación de un fichero ZIP comprimido se identifica con la creación de un ejemplar CZipFile. Como ya sabemos, para crear un fichero, es necesario indicar su nombre y contenido. Por eso, el constructor CZipFile también necesita que los parámetros correspondientes sean indicados con claridad:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
En el apartado 2.1 se ha mostrado la invocación de este constructor precisamente.
Además, a veces es necesario no crear el fichero, sino cargar un fichero ya existente desde el disco. Para este caso, en la clase CZipFile existe un segundo constructor, que premite crear un fichero ZIP sobre la base de un fichero normal en el disco duro:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
Todo el trabajo en este constructor se delega en el método privado AddFile. Su algoritmo de funcionamiento es el siguiente:
- Se abre el fichero indicado para su lectura, su contenido se calcula en la matriz de bytes.
- La matriz de bytes obtenida se comprime con el método AddFileArray y se guarda en una matriz dinámica especial del tipo uchar.
El método AddFileArray es el "corazón" de todo el sistema de clases para trabajar con archivos. Y es que precisamente en este método se encuentra la función de sistema más importante, CryptEncode. Mostramos el código fuente de este método:
//+------------------------------------------------------------------+ //| Add file array and zip it. | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
En color amarillo se indica la configuración de la función CryptEncode con el posterior archivado de la matriz de bytes. De esta forma, se puede extraer la conclusión de que la compresión del fichero tiene lugar en el momento de la creación del objeto CZipFile, y no en el momento de la creación o guardado del propio archivo ZIP, como se podría pensar. Gracias a esta propiedad, todos los datos transmitidos a la clase CZip se comprimen de forma automática, lo que significa que necesitan menos memoria operativa a la hora de guardarlos.
Preste atención a que en todos los casos, se usa en calidad de datos la matriz de bytes sin signos uchar. En realidad, todos los datos con los que operamos en la computadora se pueden representar como una secuencia de bytes. Por eso, para crear un contenedor verdaderamente universal de datos comprimidos, que es lo que en realidad constituye CZipFile, se ha elegido la matriz sin signos uchar.
| El usuario necesita convertir por sí mismo en la matriz sin signos uchar[] los datos a guardar en el archivo. Esta matriz, a su vez, también se deberá transmitir por enlace como contenido del fichero para la clase CZipFile. Gracias a esta peculiaridad, en el archivo ZIP se puede ubicar absolutamente cualquier tipo de fichero, tanto cargado desde el disco, como creado en el proceso de funcionamiento de programas MQL. |
|---|
La descompresión de datos es una tarea más trivial. Para descomprimir los datos a la matriz de bytes original file_array, se usa el método GetUnpackFile, que en esencia es un método-cubierta para la función de sistema CryptDecode:
//+------------------------------------------------------------------+ //| Get unpack file. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. Recordamos MS-DOS. Formato de hora y fecha en el archivo ZIP
El formato de datos ZIP se creó a finales de los 80 del siglo pasado para la plataforma MS-DOS, cuyo "sucesor" fue Windows. Dado que los recursos para el guardado de datos eran limitados, OS MS-DOS guardaba la fecha y la hora por separado: dos bytes (o una palabra para los procesadores de 16 bits de aquel tiempo) se reservaban para la fecha, y dos bytes para la hora. Además, la fecha más temprana que se podía representar en ese formato era el 1 de enero de 1980 (01.01.1980). Los minutos, horas, días, meses y años ocupaban determinados diapasones de bits en la palabra computacional, y para extraerlos o guardarlos se debía recurrir a las operaciones con bits, como venía siendo habitual.
Las especificaciones de este formato se muestran en la página de Microsoft en el siguiente enlace: https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx.
Mostraremos ahora el formato de guardado de la fecha en el campo de dos bytes correspondiente:
| № bits | Descripción |
|---|---|
| 0-4 | Día del mes (0-31) |
| 5-8 | Número de mes (1 — enero, 2 — febrero, etcétera) |
| 9-15 | Número del año, comenzando por 1980 |
Recuadro 1. Formato de guardado de fecha en el campo de dos bytes
De manera análoga, mostramos el formato de guardado de la hora en el campo de dos bytes correspondiente
| № bits | Descripción |
|---|---|
| 0-4 | Segundos (precisión de guardado +/- 2 segundos) |
| 5-10 | Minutos (0-59) |
| 11-15 | Horas en el formato de 24 horas |
Recuadro 2. Formato de guardado de hora en el campo de dos bytes
Conociendo la especificación de este formato y sabiendo trabajar con operaciones de bits, es posible escribir las funciones correspondientes, que convierten una fecha y hora en el formato MQL al formato MS-DOS. Asimismo, es posible escribir los procedimientos inversos. Estos métodos de conversión son generales tanto para las carpetas presentadas en CZipFolder, como para los ficheros presentados en CZipFile. Estableciendo la fecha y la hora de esta forma en un formato MQL acostumbrado para ellos, convertimos este tipo de datos al formato MS-DOS "entre bambalinas". Los métodos DosDate, DosTime, MqlDate y MqlTime se ocupan de esta conversión. Los mostraremos en su código fuente.
Conversión de la fecha del formato MQL al formato de fecha MS-DOS:
//+---------------------------------------------------------------------------------+ //| Get data in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::RjyDosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
Conversión de la fecha del formato MS-DOS al formato MQL:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
Conversión de la hora del formato MS-DOS al formato de hora MQL:
//+---------------------------------------------------------------------------------+ //| Get Time in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
Conversión de la hora del formato MS-DOS al formato de hora MQL:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
Estos métodos usan las variables internas para guardar la fecha y la hora: m_directory.last_mod_time y m_directory.last_mod_date, donde m_directory es una estructura del tipo Central Directory.
2.4. Generación de la suma de verificación CRC-32
Una peculiaridad interesante del formato del archivo ZIP es el guardado, aparte de los datos accesorios, de la información especial de recuperación, que en ciertos casos ayuda a restablecer datos dañados. Para comprender si los datos obtenidos están enteros o dañados, el archivo ZIP contiene un campo adicional especial, que guarda el valor de dos bytes del hash especial CRC-32. Se trata de la suma de verificación, que se calcula para los datos antes de la compresión. El archivador, tras descomprimir los datos del archivo, calcula de nuevo esta suma de verificación, y si no coincide, considera que los datos están dañados y no pueden ser presentados al usuario.
De esta forma, nuestra clase CZip necesita tener su propio algoritmo de cálculo CRC-32. En caso contrario, los archivos creados por nuestra clase se negarán a leer medios ajenos para trabajar con ellos, por ejemplo WinRAR dará un error de advertencia sobre datos dañados:
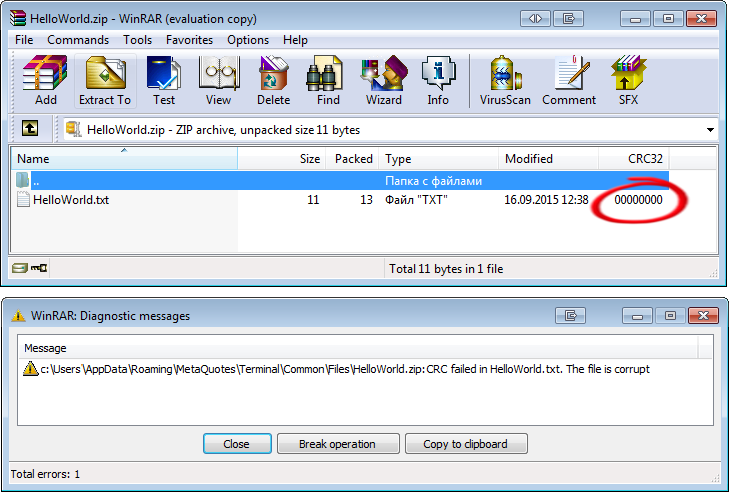
Fig. 9. Advertencia del archivador WinRAR sobre el daño presente en los datos del fichero "HelloWorld.txt"
Dado que la suma de verificación CRC-32 se exige solo para los ficheros, el método que calcula esa suma se presenta solo en la clase CZipFile. El método se implementa basándose en el lenguaje de programación C, expuesto en el artículo con la dirección: https://ru.wikibooks.org:
//+------------------------------------------------------------------+ //| Return CRC-32 sum on source data 'array' | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
Para asegurarnos de que el método funciona correctamente, basta con abrir un archivo creado con la ayuda de CZip en el archivador WinRAR. Cada fichero dispondrá de su código CRC-32 único:

Fig. 10. Suma de verificación CRC-32 en la ventana del archivador WinRAR
Los ficheros con un hash CRC-32 correcto son descomprimidos por el archivador en el modo convencional, sin que aparezcan los mensajes de advertencia correspondientes.
2.5. Lectura y guardado de archivos
Lo último que vamos a examinar serán los métodos de lectura y guardado del propio archivo ZIP. Resulta obvio que si disponemos de una colección, por ejemplo CArrayObj, que consta de los elementos CZipFile y CZipFolder, la tarea de formación del propio archivo será trivial. Bastará con convertir cada elemento en una secuencia de bytes y guardarla en un archivo. De estas tareas se ocupan los métodos siguientes:
- SaveZipToFile — abre el fichero indicado y graba en él la matriz de bytes del archivo que se ha generado.
- ToCharArray — crea la estructura de bytes correspondiente del archivo. Genera la estructura final ECDR.
- ZipElementsToArray —transforma un elemento del tipo CZipContent en una secuencia de bytes.
La única complicación consiste en que cada elemento del archivo que se haya presentado con el tipo CZipContent, se guarda en dos partes diferentes del fichero, en las estructuras Local File Header y Central Directory. Por eso es necesario usar la invocación especial del método ZipElementsToArray, que, dependiendo del modificador ENUM_ZIP_PART que se le haya transmitido, genera o bien una matriz de bytes del tipo Local File Header, o bien Central Directory.
Ahora, teniendo en cuenta esta peculiaridad, deberemos ser capaces de comprender el contenido de estos tres métodos, cuyo código fuente mostramos más abajo:
//+------------------------------------------------------------------+ //| Return uchar array with ZIP elements | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| Generate ZIP archive as uchar array. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| Save ZIP archive in file zip_name | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
La carga del archivo tiene también ciertos matices. Es obvio que la carga de un archivo es la operación inversa al guardado. Si al guardar un archivo los elementos del tipo CZipContent se transforman en una secuencia de bytes, entonces al cargar el archivo la secuencia de bytes se transforma en elementos del tipo CZipContent. Y una vez más, debido a que cada elemento en el archivo se guarda en dos partes diferentes del fichero, Local File Header y Central Directory, el elemento CZipContent no se puede crear en una lectura de datos.
Es necesario usar la clase-contenedor intermedia CSourceZip, en la que al principio se añaden los elementos necesarios de forma consecutiva, y a continuación, sobre su base, se forma el tipo necesario de datos: CZipFile o CZipFolder. Precisamente por eso, estas dos clases disponen de un constructor extra, que adopta como parámetro de enlace el índice a un elemento del tipo CSourceZip. Este tipo de incialización, como la propia clase CSourceZip, fue creado exclusivamente para el uso accesorio con la clase CZip, y no es recomendable usarlo en su forma llana.
De la carga en sí misma son responsables tres métodos de clase CZip:
- LoadZipFromFile — abre el fichero indicado y lee su contenido en la matriz de bytes.
- LoadHeader — carga según la dirección propuesta la estructura Local File desde la matriz de bytes del archivo.
- LoadDirectory — carga según la dirección propuesta la estructura Central Directory desde la matriz de bytes del archivo.
Bien, ahora mostraremos el código fuente de estos métodos:
//+------------------------------------------------------------------+ //| Load Local Header with name file by offset array. | //| RETURN: | //| Return address after local header, name and zip content. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy local header uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //Copy header file name ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //Copy zip array ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+------------------------------------------------------------------+ //| Load Central Directory with name file by offset array. | //| RETURN: | //| Return adress after CD and name. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy central directory uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //Copy directory file name ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+------------------------------------------------------------------+ //| Load ZIP archive from HDD file. | //+------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
Capítulo 3. Ejemplos de uso de la clase CZip, medición de la productividad
En el capítulo anterior ya estudiamos la clase CZip y el formato de datos del archivo Z propiamente. Ahora, conociendo la construcción del archivo, así como los principios generales del trabajo con la clase CZip, podemos pasar al análisis de tareas prácticas relacionadas con el archivado. En este capítulo se estudian en profundidad tres ejemplos de diferente naturaleza, que abarcan al máximo todo el espectro de tareas de esta clase.
3.1. Creación de un archivo ZIP con cotizaciones de todos los símbolos elegidos
La primera tarea que se suele tener que resolver con frecuencia es el guardado de datos obtenidos con anterioridad. Con frecuencia, se obtienen en el mismo terminal MetaTrader. Estos datos pueden ser una secuencia de ticks acumulados o cotizaciones en formato OHLCV. Vamos a estudiar la tarea en la que necesitamos guardar las cotizaciones en ficheros CSV especiales, cuyo formato será el siguiente:
Date;Time;Open;High;Low;Close;Volume 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
Se trata de un formato de texto de los datos. Se utiliza con frecuencia para transmitir datos entre diferentes sistemas del análisis estadístico. El formato de los ficheros de texto, por desgracia, posee un exceso de guardado de datos, dado que en cada byte se usa solo una cantidad muy limitada de signos. Normalmente, suelen ser signos de puntuación, cifras, letras iniciales y minúsculas del alfabeto. Además, muchos valores en este formato se repiten con frecuencia, por ejemplo, la fecha o el precio de apertura es, normalmente, la misma para una gran matriz de datos. Por eso la compresión de este tipo de datos deberá ser efectiva.
Bien, vamos a escribir nuestro script, que carga los datos necesarios desde el terminal. Su algoritmo será el siguiente:
- De manera consecutiva se eligen los instrumentos que se ubican en la ventana de Market Watch.
- Para cada instrumento elegido, se solicitan las cotizaciones para cada uno de los 21 marcos temporales.
- La cotizaciones del marco temporal elegido se convierten en una matriz de líneas CSV.
- La matriz de líneas CSV se convierte en una matriz de bytes.
- Se crea un fichero ZIP (CZipFile), que contiene una matriz de bytes de cotizaciones, después de lo cual, se añade al archivo.
- Después de crear todos los ficheros de cotizaciones, el archivo CZip se guarda en el disco de la computadora en el fichero Quotes.zip.
El código fuente del script que ejecuta estas acciones se muestra más abajo:
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // Create empty ZIP archive. //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| Create ZIP with quotes from market watch | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
La carga de datos puede ocupar un tiempo considerable, por eso en la ventana Market Watch se han elegido solo cuatro símbolos. Además, cargamos solo las cien últimas barras conocidas. Esto también deberá acortar el tiempo de ejecución del script. Después de su ejecución, en la carpeta de ficheros generales de MetaTrader ha aparecido el archivo Quotes.zip. Su contenido se puede ver en cualquier programa de trabajo con archivos, por ejemplo, WinRAR:
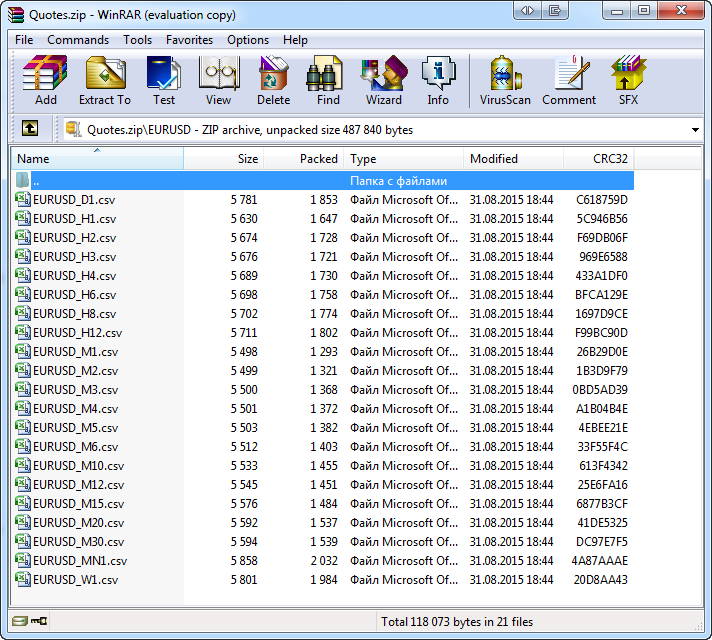
Fig. 11. Ficheros guardados de las cotizaciones, visualizados en el archivador WinRAR
El archivo creado está el triple de comprimido, en comparación con el tamaño original. Sobre esto nos informará el propio archivador WinRAR:
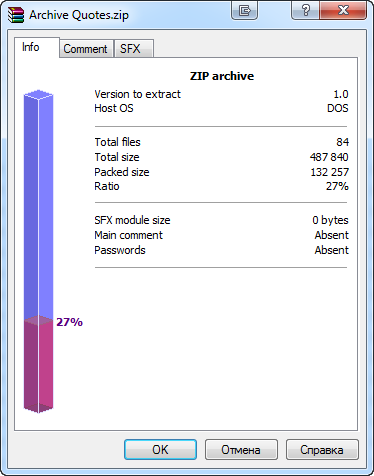
Fig. 12. Nivel de compresión del archivo generado en la ventana informativa de WinRAR
Se trata de buen resultado de compresión. Sin embargo, se conseguiría aún mejor coeficiente de compresión en los ficheros mayores y menos numerosos.
Un ejemplo de un script que crea cotizaciones y las guarda en un archivo zip se encuentra adjunto a este artículo bajo el nombre ZipTask1.mq5, y se encuentra en la carpeta Scripts.
3.2. Cargar un archivo desde un servidor remoto, usando como ejemplo MQL5.com
La siguiente tarea a estudiar será de red. Nuestro ejemplo demostrará cómo se pueden cargar archivos ZIP desde servidores remotos. Como ejemplo, vamos a realizar la carga del indicador Alligator, que se encuentra en la base de códigos fuente Code Base en la dirección https://www.mql5.com/es/code/9:
Para cada indicador, asesor, script o biblioteca que esté publicado en Code Base, existe una versión de archivo donde todos los códigos fuente del producto están comprimidos en un archivo único. Precisamente esta versión de archivo es la que vamos a descargar y descomprimir en la computadora local. Pero antes de hacer esto, es necesario permitir anticipadamente el acceso a mql5.com, para lo cual, en la ventana Servicio --> Ajustes --> Asesores, es necesario escribir la dirección "https://www.mql5.com" en la lista de servidores permitidos.
La clase CZip posee su propio método de carga de archivos desde los recursos de internet. Pero en vez de usarlo, vamos a escribir nuestro propio script, que realizará esa carga:
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/es/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("Unable to download ZIP archive from "+mql_url+". Check request and permissions EA."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("Loaded bad ZIP archive. Check results array."); return; } printf("Archive successfully loaded. Total files: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
Como puede ver, el código fuente del script es bastante sencillo. En primer lugar, invocamos WebRequest con la dirección del archivo ZIP remoto. WebRequest descarga la matriz de bytes del archivo a la matriz resultante zip_array, después de lo cual, se carga en la clase CZip mediante el método CreateFromCharArray. Este método permite crear un archivo directamente desde la secuencia de bytes, lo que a veces resulta imprescindible al trabajar de forma interna con los archivos.
Aparte del método CreateFromCharArray, CZip contiene el método especial LoadZipFromUrl para cargar archivos a través de un enlace de internet. Funciona más o menos de igual manera que nuestro anterior script. Vamos a mostrar su código fuente:
//+------------------------------------------------------------------+ //| Load ZIP archive from url | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
El resultado del funcionamiento de este método será análogo: pasado cierto tiempo, se creará un archivo ZIP, cuyo contendio se descargará desde un servidor remoto.
Un ejemplo de un script capaz de cargar un archivo desde CodeBase se encuentra adjunto a este artículo bajo el nombre ZipTask2.mq5 y se ubica en la carpeta Scripts.
3.3. Compresión de los datos accesorios de un programa en la memoria operativa de la computadora
La compresión de los datos internos del programa en la memoria operativa del computador es un método no trivial del uso del archivado. Este método se puede usar cuando los datos a procesar son demasiados como para ubicarlos en la memoria operativa. Sin embargo, al usar este enfoque, la productividad general del programa se reduce, porque se necesitan acciones adicionales de archivado/desarchivado de estructuras o datos accesorios.
Supongamos que un programa MQL necesita guardar una colección de órdenes históricas. Cada orden se describirá con una estructura especial Order, que contendrá todas sus propiedades: el identificador, el tipo de orden, la hora de ejecución, el volumen, etcétera. Describimos esta estructura:
//+------------------------------------------------------------------+ //| History order | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // Ticket order datetime time_setup; // Time setup order ENUM_ORDER_TYPE type; // Type order ENUM_ORDER_STATE state; // State order datetime time_exp; // Expiration time datetime time_done; // Time done or canceled order long time_setup_msc; // Time setup in msc long time_done_msc; // Time done in msc ENUM_ORDER_TYPE_FILLING filling; // Type filling ENUM_ORDER_TYPE_TIME type_time; // Type living time ulong magic; // Magic of order ulong position_id; // ID position double vol_init; // Volume init double vol_curr; // Volume current double price_open; // Price open double sl; // Stop-Loss level double tp; // Take-Profit level double price_current; // Price current double price_stop_limit; // price stop limit string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| Init by ticket | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| Return comment of order | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| Return symbol of order | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| Set comment order | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| Set symbol order | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| Converter for uchar array. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| Convert order structure to uchar array | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
Al invocar el operador sizeof se ve que esta estructura ocupa 200 bytes. De esta forma, el guardado de la colección de órdenes históricas ocupa una cantidad de bytes que se calcula mediante la fórmula: sizeof(Order) * cantidad de órdenes históricas. Por consiguiente, para una colección que cuente con 1000 órdenes históricas, se necesitará una memoria de 200 * 1000 = 200 000 bytes o casi 200 Kbytes. Es poco según las medidas actuales, sin embargo, cuando el tamaño de la colección supere las decenas de miles de elementos, el volumen de memoria ocupada será significativo.
Así y con todo, se puede desarrollar un contenedor especial para guardar estas órdenes, que permitiría comprimir su contenido. Este contenedor, aparte de los métodos habituales de añadido y eliminación de nuevos elementos Order, también contendrá los métodos Pack y Unpack, que comprimen el contenido de las estructuras del tipo Order. Mostramos el código fuente de este contenedor:
//+------------------------------------------------------------------+ //| Container of orders. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| Add new order. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| Return order at index. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| Return total orders. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| Delete order by index. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| Return orders size. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
La idea es que el usuario pueda añadir nuevos elementos al contenedor, así como, en caso de necesidad, comprimir su contenido directamente en la memoria operativa de la computadora. Veamos cómo funciona esto. Escribimos un script demostrativo:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="Unpack size: "+(string)unpack_size+"bytes; "+ "Pack size: "+(string)pack_size+" bytes ("+per+" percent compressed. "+ "Pack execute msc: "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("First id ticket: "+(string)first.ticket); } } //+------------------------------------------------------------------+
Hemos destacado en amarillo el momento de la compresión de la colección. Iniciado en una de las cuentas, que contaba con 858 órdenes históricas, este script dio los siguientes resultados:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) Unpack size: 171600 bytes; Pack size: 1521 bytes (0.89 percent compressed. Pack execute microsec.: 2534
Como se puede ver, el tamaño de la colección sin comprimir era de 171 600 bytes. Después de la compresión, el tamaño de la colección es igual a 1 521 bytes. ¡El nivel de compresión ha superado las cien veces! La explicación es que muchos campos de la estructura contienen datos parecidos. Asimismo, muchos campos tienen valores vacíos, a los que, así y con todo, se les asigna memoria.
Para asegurarnos de que la compresión funciona de verdad correctamente, basta con elegir cualquier orden de la colección e imprimir sus propiedades. Hemos elegido la primera orden y su identificador único. Después de la compresión, el identificador de la orden se ha representado correctamente.
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) First id ticket: 10279280
El algoritmo descrito, en caso de recurrir a su colección, descomprime los datos anteriormente comprimidos. Esto reduce la productividad. Por eso, hay que comprimir los datos solo después de que se hayan finalizado sus trabajos de formación. Para que el nivel de compresión sea mejor, todos los datos se reunen en una única matriz, y después se comprimen. Para descomprimir, tiene lugar el proceso inverso.
Resulta interesante que la compresión de 858 elementos ocupe solo 2.5 milisegundos en una computadora bastante potente. La descompresión de estos mismos datos tiene lugar a mayor velocidad y ocupa alrededor de 0.9 milisegundos. De esta forma, en un ciclo de compresión/descompresión de una matriz que consta de miles de elementos, se invierten aproximadamente 3.5-4.0 milisegundos. Al mismo tiempo, se logra un ahorro de memoria de cien veces. Estas características impresionan lo suficiente como para usar la compresión ZIP para organizar grandes matrices de datos.
Un ejemplo de un script capaz de comprimir datos en la memoria operativa se encuentra adjunto a este artículo bajo el nombre ZipTask3.mq5 y se ubica en la carpeta Scripts. Para que funcione es igualmente necesario el fichero Orders.mqh, ubicado en la carpeta Include.
Capítulo 4. Documentación de las clases para trabajar con los archivos ZIP
4.1. Documentación de la clase CZipContent
En este capítulo se describen los métodos y enumeraciones utilizados en las clases para trabajar con los archivos ZIP. A nivel de usuario, la clase CZipContent no se usa directamente, pero todos sus métodos abiertos se delegan en las clases CZipFile y CZipFolder, de esta forma, las propiedades y métodos descritos en ella se extienden también a estas clases.
Método ZipType()
El método ZipType retorna el tipo del elemento actual en el archivo. Los tipos de elementos guardados en un archivo son dos: carpeta (directorio) y fichero. El tipo de carpeta está representado por la clase CZipDirectory, y el tipo de fichero está representado por la clase CZipFile. Se puede leer con mayor detalle sobre los tipos de archivos ZIP en el apartado 2.1 del presente capítulo: "Estructura de los archivos comprimidos en el archivo, las clases CZipFile y CZipFolder".
ENUM_ZIP_TYPE ZipType(void);Valor devuelto
Retorna la enumeración ENUM_ZIP_TYPE, que describe a qué tipo pertenece el ejemplar actual CZipContent.
Método Name(void)
Retorna el nombre de la carpeta o fichero en el archivo.string Name(void);
Valor devuelto
Nombre del fichero o carpeta.
Método Name(string name)
Establece el nombre de la carpeta o fichero actual en el archivo. Se usa en los casos cuando hay que cambiar el nombre de la carpeta o fichero actual.
void Name(string name);
Parámetros:
- [in] name — nuevo nombre de la carpeta o fichero. El nombre debe ser único y no coincidir con nombres de carpetas o ficheros en el archivo.
Método CreateDateTime(datetime date_time)
Establece una nueva fecha de cambio de la carpeta o fichero en el archivo.
void CreateDateTime(datetime date_time);
Parámetros:
- [in] date_time — fecha y hora que se deben establecer para la carpeta o fichero actual.
Observación:
La fecha y la hora se convierten al formato MS-DOS y se guardan en las estructuras del tipo ZipLocalHeader y ZipCentralDirectory. Se describen con más detalle los métodos de conversión y representación de este formato en el apartado 2.3 de este artículo: "Recordamos MS-DOS. Formato de hora y fecha en el archivo ZIP".
Método CreateDateTime(void)
Devuelve la fecha y hora de cambio de la carpeta o fichero actual.
datetime CreateDateTime(void);
Valor devuelto
Fecha y hora de cambio de la carpeta o fichero actual.
Método CompressedSize()
Retorna el tamaño de los datos comprimidos en el fichero. Para los directorios, el tamaño de los datos comprimidos es siempre igual a cero.
uint CompressedSize(void);
Valor devuelto
Tamaño de los datos comprimidos en bytes.
Método UncompressedSize()
Retorna el tamaño de los datos de origen sin comprimir en el archivo. Para los directorios, el tamaño de los datos comprimidos es siempre igual a cero.
uint UncompressedSize(void);
Valor devuelto
Tamaño de los datos de origen en bytes.
Método TotalSize()
Retorna el tamaño total del elemento del archivo. Cada fichero o directorio en el archivo, aparte de su nombre y contenido (para los archivos), guarda estructuras accesorias adicionales, cuyo tamaño también se tiene en cuenta al calcular el tamaño total del elemento del archivo.
int TotalSize(void);
Valor devuelto
Tamaño total del elemento actual del archivo, teniendo en cuenta los datos accesorios adicionales.
Método FileNameLength()
Retorna la longitud del nombre del directorio o fichero, expresado como cantidad de símbolos usados.
ushort FileNameLength(void);
Valor devuelto
Longitud del nombre del directorio o fichero, expresado como cantidad de símbolos usados.
Método UnpackOnDisk()
Descomprime el contenido del elemento y lo guarda en un fichero con el nombre del elemento en el disco duro de la computadora. Si se descomprime un directorio, entonces en lugar del fichero se crea la carpeta correspondiente.
bool UnpackOnDisk(string folder, int file_common);
Parámetros
- [in] folder — nombre de la carpeta raíz, en la que es necesario descomprimir la carpeta o fichero actual. Si el elemento se debe descomprimir sin crear una carpeta de archivo, entonces este valor se debe dejar vacío, igual a "".
- [in] file_common — este modificador indica en qué sección del sistema de ficheros de los programas MetaTrader se debe descomprimir el elemento. Establezca este parámetro igual a FILE_COMMON, si quiere realizar la descompresión en el apartado general de ficheros de todos los terminales MetaTrader 5.
Valor devuelto
Retorna verdadero si la descompresión del fichero o carpeta al disco duro a tenido éxito. Retorna falso en caso contrario.
4.2. Documentación de la clase CZipFile
La clase CZipFile se hereda desde CZipContent y se utiliza para guardar los ficheros en el archivo. CZipFile guarda el contenido del fichero solo de forma comprimida. Esto significa que al transmitirle el fichero para el guardado, tiene lugar la compresión automática de su contenido. La descompresión del fichero también sucede en el modo automático, al invocar el método GetUnpackFile. Aparte de la serie de métodos soportados CZipContent, CZipFile también ofrece soporte a métodos especiales para trabajar con ficheros. A continuación, se describen estos métodos.
Método AddFile()
Añade un fichero desde el disco duro al elemento actual CZipFile. Para añadir un fichero a un archivo del tipo CZip, primero hay que crear un ejemplar de la clase CZipFile, indicando al crearlo el nombre del fichero y el camino hasta él. Después de que el ejemplar de la clase esté creado, habrá que añadirlo a la clase CZip, invocando el método correspondiente. La compresión real del contenido transmitido tiene lugar en el momento en que se añada (invoque este método).
bool AddFile(string full_path, int file_common);
Parámetros
- [in] full_path — nombre completo del fichero, incluyendo el camino hasta él con respecto al catálogo central de ficheros de programas MQL.
- [in] file_common — este modificador indica en qué sección del sistema de ficheros de programas MetaTrader es necesario descomprimir el elemento. Establezca este parámetro igual a FILE_COMMON, si quiere realizar la descompresión en el apartado general de ficheros de todos los terminales MetaTrader 5.
Valor devuelto
Retorna verdadero si se ha añadido el fichero con éxito. Retorna falso en caso contrario.
Método AddFileArray()
Añade en calidad de contenido CZipFile una matriz de bytes del tipo uchar. Este método se usa en caso de creación dinámica del contenido del fichero. La compresión real del contenido transmitido tiene lugar en el momento en que se añada (invoque este método).
bool AddFileArray(uchar& file_src[]);
Parámetros
- [in] file_src — matriz de bytes que debe ser añadida.
Valor devuelto
Retorna verdadero si se ha añadido el fichero con éxito. Retorna falso en caso contrario.
Método GetPackFile()
Retorna el contenido comprimido del fichero.
void GetPackFile(uchar& file_array[]);
Parámetros
- [out] file_array — matriz de bytes en la que se debe recibir el contenido comprimido del fichero.
Método GetUnpackFile()
Retorna el contenido descomprimido del fichero. El contenido se descomprime en el momento en que se recurra al método.
void GetUnpackFile(uchar& file_array[]);
Parámetros
- [out] file_array — matriz de bytes en la que se debe recibir el contenido descomprimido del fichero.
4.3. Documentación de la clase CZip
La clase CZip implementa el trabajo principal con los archivos del tipo ZIP. La clase constituye un archivo ZIP general, al que se pueden añadir elementos ZIP de dos tipos: elementos que representan una carpeta (CZipDirectory), y elementos que representan ficheros ZIP (CZipFile). Aparte de todo esto, la clase CZip permite cargar archivos ya existentes, tanto desde el disco duro de la computadora, como en forma de secuencias de bytes.
Método ToCharArray()
Convierte el contenido de un archivo ZIP en una secuencia de bytes del tipo uchar.
void ToCharArray(uchar& zip_arch[]);
Parámetros
- [out] zip_arch — matriz de bytes en la que se debe recibir el contenido del archivo ZIP.
Método CreateFromCharArray()
Carga un archivo ZIP desde una secuencia de bytes.
bool CreateFromCharArray(uchar& zip_arch[]);
Parámetros
- [out] zip_arch — matriz de bytes desde la que se debe cargar el contenido del archivo ZIP.
Valor devuelto
Será verdadero si la creación del archivo desde una secuencia de bytes se ha realizado con éxito, y falso en caso contrario.
Método SaveZipToFile()
Guarda en el fichero indicado el archivo ZIP actual con su contenido.
bool SaveZipToFile(string zip_name, int file_common);
Parámetros
- [in] zip_name — nombre completo del fichero, incluyendo el camino hasta él con respecto al catálogo central de ficheros de programas MQL.
- [in] file_common — este modificador indica en qué sección del sistema de ficheros de programas MetaTrader es necesario descomprimir el elemento. Establezca este parámetro igual a FILE_COMMON, si quiere realizar la descompresión en el apartado general de ficheros de todos los terminales MetaTrader 5.
Valor devuelto
Será verdadero si el guardado del archivo en el fichero se ha realizado con éxito, y falso en caso contrario.
Método LoadZipFromFile()
Carga el contenido del archivo desde un fichero en el disco duro de la computadora.
bool LoadZipFromFile(string full_path, int file_common);
Parámetros
- [in] full_path — nombre completo del fichero, incluyendo el camino hasta él con respecto al catálogo central de ficheros de programas MQL.
- [in] file_common — este modificador indica en qué sección del sistema de ficheros de programas MetaTrader es necesario descomprimir el elemento. Establezca este parámetro igual a FILE_COMMON, si quiere realizar la descompresión en el apartado general de ficheros de todos los terminales MetaTrader 5.
Valor devuelto
Será verdadero si la carga del archivo desde el fichero se ha realizado con éxito, y falso en caso contrario.
Método LoadZipFromUrl()
Carga el contenido del archivo a través de un enlace de internet url. Para que este método funcione correctamente, es necesario generar un permiso de acceso al recurso solicitado. El funcionamiento de este método se describe con más detalle en el apartado 3.2 del presente artículo: "Cargar un archivo desde un servidor remoto usando como ejemplo la página MQL5.com"
bool LoadZipFromUrl(string url);
Parámetros
- [in] url — enlace al archivo.
Método UnpackZipArchive()
Descomprime todos los ficheros y directorios del archivo actual en el catálogo propuesto.
bool UnpackZipArchive(string folder, int file_common);
Parámetros
- [in] folder — carpeta en la que se debe descomprimir el archivo actual. Si no es necesario crear una carpeta para el archivo, en calidad de parámetro se debe transmitir el valor vacío "".
- [in] file_common — este modificador indica en qué sección del sistema de ficheros de programas MetaTrader es necesario descomprimir el elemento. Establezca este parámetro igual a FILE_COMMON, si quiere realizar la descompresión en el apartado general de ficheros de todos los terminales MetaTrader 5.
Valor devuelto
Será verdadero si la descompresión del archivo se ha realizado con éxito, y falso en caso contrario.
Método Size()
Retorna el tamaño del archivo en bytes.
int Size(void);Valor devuelto
Tamaño del archivo en bytes.
Método TotalElements()
Retorna la cantidad de elementos en el archivo. O bien un directorio, o bien un fichero comprimido pueden ser un elemento del archivo.
int TotalElements(void);
Valor devuelto
Cantidad de elementos en el archivo.
Método AddFile()
Añade un nuevo fichero ZIP al archivo actual. El fichero debe presentarse en forma de CZipFile y ser creado de antemano, antes de añadirse al archivo.
bool AddFile(CZipFile* file);Parámetros
- [in] file — fichero ZIP que debe ser añadido al archivo.
Valor devuelto
Será verdadero si la adición al archivo se ha realizado con éxito, y falso en caso contrario.
Método DeleteFile()
Elimina un fichero del tipo CZipFile según el índice index del archivo.
bool DeleteFile(int index);
Parámetros
- [in] index — índice del fichero que debe ser eliminado del archivo.
Valor devuelto
Verdadero si se ha eliminado el fichero del archivo con éxito. Falso en caso contrario.
Método ElementAt()
Obtiene un elemento del tipo CZipFile, ubicado según el índice index.
CZipContent* ElementAt(int index)const;
Parámetros
- [in] index — índice del fichero que debe ser obtenido del archivo.
Valor devuelto
Elemento del tipo CZipFile, que se ubica según el índice index.
4.4. Estructura de ENUM_ZIP_ERROR y obtención de información ampliada sobre errores
En el proceso de trabajo con las clases CZip, CZipFile y CZipDirectory pueden surgir diferentes errores, por ejemplo, el error que aparece al intentar acceder a un fichero inexistente, etcétera. La mayoría de métodos presentados en estas clases retornan la bandera correspondiente del tipobool, que señaliza que la operación se ha finalizado con éxito. En caso de que se retorne el valor negativo (false), se puede obtener información adicional sobre los motivos del fallo. Los motivos del fallo pueden ser tanto estándares, por ejemplo, errores de sistema, como errores específicos que surjan en el proceso de funcionamiento del archivo ZIP. Para transmitir los errores específicos, se usa un mecanimso de transmisión de errores de usuario con la ayuda de la función SetUserError. Los códigos de los errores de usuario se establecen mediante la enumeración ENUM_ZIP_ERROR:
Enumeración ENUM_ZIP_ERROR
| Significado | Descripción |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | El fichero transmitido para su compresión está vacío. |
| ZIP_ERROR_BAD_PACK_ZIP | Error del compresor/descompresor interno. |
| ZIP_ERROR_BAD_FORMAT_ZIP | El formato del fichero ZIP transmitido no se corresponde con el estándar, o bien está dañado. |
| ZIP_ERROR_NAME_ALREADY_EXITS | El nombre con el que el usuario intenta guardar el fichero ya está siendo utilizado en el archivo. |
| ZIP_ERROR_BAD_URL | El enlace transmitido no conduce al archivo ZIP, o bien el acceso al recurso de internet indicado está prohibido por los ajustes del terminal. |
Al recibir un error de usuario, es necesario pasarlo con claridad a la enumeración ENUM_ZIP_ERROR y procesarlo de la forma correspondiente. Presentamos más abajo, en forma de script, un ejemplo de los errores que aparecen durante el trabajo con las clases de archivado:
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf("Error de sistema al cargar el archivo. Número de error: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("Ha aparecido un error de procesamiento del archivo en el momento de cargarlo: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
4.5. Descripción de los archivos adjuntos al artículo
Más abajo se muestra una breve descripción de los ficheros adjuntos al artículo:
- Zip\Zip.mqh — contiene la clase principal para trabajar con los archivos CZip.
- Zip\ZipContent.mqh — contiene la clase básica CZipContent para las clases principales de los elementos del archivo: CZipFile y CZipDirectory.
- Zip\ZipFile.mqh — contiene la clase para trabajar con los ficheros ZIP del archivo.
- Zip\ZipDirectory.mqh — contiene la clase paratrabajar con las carpetas ZIP del archivo.
- Zip\ZipHeader.mqh — en el fichero se da una descripción de las estructuras File Local Header, Central Directory y End Central Directory Record.
- Zip\ZipDefines.mqh — se enumeran las definiciones, constantes y códigos de los errores usados al trabajar con las clases de archivado.
- Dictionary.mqh — clase auxiliar que posibilita el control de exclusividad de los nombres de los ficheros y directorios añadidos al archivo. El algoritmo de funcionamiento de esta clase se describe con detalle en el artículo "Recetas de MQL5 - implementamos el array asociativo o el diccionario para el acceso rápido a los datos".
Todos los ficheros mostrados en el artículo deben ser ubicados con respecto al catálogo interno <catálogo_de_datos_del_terminal>\MQL5\Include. Para comenzar a trabajar con la clase se debe incluir el fichero Zip\Zip.mqh en el proyecto. Vamos a describir como ejemplo un script que crea un archivo ZIP y guarda en él un fichero de texto con el mensaje "test":
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // Activamos todas las clases necesarias para trabajar con el archivo ZIP //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // Creamos un archivo ZIP vacío uchar array[]; // Creamos una matriz de bytes array vacía StringToCharArray("test", array); // Convertimos el mensaje "test" en la matriz de bytes array CZipFile* file = new CZipFile("test.txt", array); // Creamos un nuevo fichero ZIP 'file', en base a la matriz array con el nombre "test.txt" Zip.AddFile(file); // Añadimos el recién creado fichero ZIP 'file' al archivo ZIP Zip.SaveZipToFile("Test.zip", FILE_COMMON); // Guardamos el archivo ZIP en el disco bajo el nombre "Test.zip". } //+------------------------------------------------------------------+
Tras su ejecución, en el disco duro de la computadora, en el catálogo central de ficheros para MetaTrader 5, aparecerá un nuevo archivo ZIP con el nombre Test.zip, que contiene un fichero de texto con la anotación "test".
| El archivo adjunto al presente artículo ha sido creado con ayuda del archivador MQL CZip, descrito aquí. |
|---|
Conclusión
Hemos estudiado al detalle la estructura del archivo ZIP y hemos creado clases que realizan el trabajo con este tipo de archivos. Este formato de archivado fue desarrollado ya a finales de los 80 del siglo pasado, pero esto no le estorba a la hora de seguir siendo el formato de compresión de datos más popular. El conjunto de datos de las clases puede ofrecer una ayuda incalculable al desarrollador de sistemas comerciales. Con su ayuda, se pueden guardar de forma ahorrativa los datos recopilados, ya sea una historia de ticks u otra información comercial. Con frecuencia se nos proporciona diversa información analítica de forma comprimida. En este caso, saber trabajar con esta información, incluso de forma comprimida, puede resultar muy útil.
Las clases descritas ocultan muchos aspectos técnicos del trabajo con archivos, proporcionando a nivel de usuario métodos sencillos y comprensibles para trabajar con ellos, semejantes a aquellas operaciones que están acostumbrados a realizar los usuarios con los programas de archivado: añadir y extraer ficheros de archivos, crear nuevos archivos y cargar archivos ya existentes, incluidos los ubicados en servidores remotos ajenos. Estos medios resuelven por completo la mayoría de tareas relacionadas con el archivado, y hacen de la programación en el entorno MetaTrader algo todavía más sencillo y funcional.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/1971
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Dibujando niveles de ruptura horizontales utilizando fractales
Dibujando niveles de ruptura horizontales utilizando fractales
 Revisión de la gestión del dinero
Revisión de la gestión del dinero
 Probando Asesores Expertos en marcos temporales no estándar
Probando Asesores Expertos en marcos temporales no estándar
 Tercera generación de neuroredes: "Neuroredes profundas"
Tercera generación de neuroredes: "Neuroredes profundas"
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Me encontré con un archivo que CZip no pudo descomprimir. Sin embargo, 7ZIP y el archivador de Windows lo descomprimieron sin problemas.
...
Puedo enviarte el archivo en un mensaje privado si estás interesado en resolverlo.Por favor, envíeme el archivo en un mensaje privado.
Por favor, envíeme el archivo en un mensaje privado.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-01-18_BTCUSDT_ob500.data.zip
aquí en el cuerpo del archivo (no en la cabecera) hay cdheader = 0x504b0102;
En el archivo siguiente por fecha también. Creo que se encuentra a menudo.
header = 0x504b0304; está en cada archivo en el encabezado, es decir, los primeros 4 caracteres.
Pero también se reunió y en el cuerpo del archivo, rara vez. Voy a buscar ahora.
Aquí https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-03-15_BTCUSDT_ob500.data.zip.
Creo que es necesario buscar estas cabeceras sólo entre los cuerpos de archivos.
Y también hay un enlace a un archivo grande que no se puede descomprimir correctamente. Pongo el tamaño para ellos a 0, y entonces el programa que llama entiende por este 0 que hay un error y es necesario usar otro archivador.
Quizás se te ocurra algo mejor en vez de 0.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip
He ordenado los ficheros (descomprimidos) que superan un determinado volumen (para diferentes ficheros desde 1,7Gb hasta 2136507776 - es decir, casi hasta MAX_INT=2147483647, y los arrays no pueden tener más elementos) y que se cortan a la salida. Resultó que todos ellos fueron marcados como erróneos en:
Es decir, valor de salida = 0.
Pero CZIP no controla esto. Hice la puesta a cero del tamaño de la matriz de salida.
Así en mis funciones puedo determinar con 100% de garantía que el archivo es desempaquetado con éxito.
Antes comprobaba el final correcto del archivo JSON }\r\n - pero esta solución no es universal y parece que varios archivos de ~1000 fueron cortados accidentalmente por una línea intermedia y fueron aceptados como descomprimidos con éxito, pero los datos en ellos no están completos.
Nueva versión de la función:
La nueva está resaltadaen amarillo .
Quizás los desarrolladores también deberían poner a cero el array, porque los datos recortados casi nadie los necesita. Y puede dar lugar a errores difíciles de ver.
Y también hay un enlace a un archivo grande que no se puede descomprimir correctamente. Yo pongo el tamaño para ellos a 0, y entonces el programa que llama entiende por este 0 que hay un error y es necesario usar otro archivador.
Quizás se te ocurra algo mejor en lugar de 0.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip