
MQL5でのZIPアーカイブの扱い

コンテンツ表
- イントロダクション
- チャプター1. ZIPのフォーマットとデータ保存
- チャプター2. CZipクラスの概要とアルゴリズム
- チャプター3. CZipクラスの例とパフォーマンス測定
- チャプター4. ZIPアーカイブのオペレーションクラスのドキュメント
- 結論
イントロダクション
この記事の背景
かつてこの記事の著者はCryptDecode関数を添付しました。特にZIP配列をデコンプレスする方法は興味深いものでした。この修正はMetaTrader5の開発者によって、標準WebRequest関数を使っていくつかのサーバーからデータを抽出する方法として紹介されました。しかし、ZIPファイルのフォーマットの特性により、直接的に行うことは不可能でした。
さらなる情報が実現には必要でした。: アーカイブを開く以前にアーカイブを圧縮する方法を知る必要があり、 - Adler-32 そしてそれはかつて不可能でした。しかし、 この問題に関して議論した際、CryptDecode と CryptEncodeをオーバーロードするリクエストにぶつかりました。転送データを開く際に、Adler32ハッシュを無視することができる特別なフラグです。技術的な経験がないユーザーのために、この技術革新は、簡単に説明することができます:それはZIPアーカイブの全機能を有効にします。この記事では、ZIPファイル形式、データストレージのその詳細を記述し、アーカイブを操作するのに便利なオブジェクト指向のCZipクラスを提供しています。
何故必要なのか
データ圧縮は、Web上で特に普及し、最も重要な技術の一つです。圧縮は、データの伝送、記憶及び処理のために必要なリソースを節約するのに役立ちます。データ圧縮は、通信のすべての分野で使用され、ほとんどすべてのコンピュータ関連のタスクで利用されています。
金融分野も例外ではありません:生の非圧縮形式で格納することができない市場(レベル2データ)の板情報、ダニの歴史のギガバイト、引用符の流れなどがそれに当たります。取引のための分析情報や有用提供も含め、多くのサービスでZIPアーカイブにデータを格納することがあります。以前までは自動的にMQL5の標準ツールを使用してこの情報を得ることは不可能でした. しかし、状況は変わりました。
ZIPアーカイブをダウンロードして、すぐにコンピュータ上でそれを復元できるWebリクエスト機能を使用することができます。これらのすべての機能は重要であり、間違いなく多くのトレーダーに必要になります. データ圧縮は、コンピュータのメモリを最適化するためにも使用することができます. これがどのように行われるかは、この資料のセクション3.2で説明します。最後に、ZIPアーカイブを扱える機能は、Microsoft Officeの標準 Office Open XMLへのアクセスを可能にします。これは、DLLの代わりにMQL5から直接エクセルやワードを生成することができるということです。
ご覧の通り、ZIPアーカイブアプリケーションは広範囲であり、我々が作成しているクラスは、すべてのメタトレーダーのユーザーに有効です。
この記事の最初の章では、ZIPファイルのフォーマットを記述し、データブロックに何を入れるかという考え方について扱います。この章では、MQLを研究する人にだけでなく、アーカイブとデータストレージに関与している人のための良い教材としての役割を果たすでしょう。第二章では、アーカイブで動作する主要なオブジェクト指向の要素であるCZip、CZipFile、CZipDirectoryクラスを扱います。第三章では、アーカイブの使用に関連する実用的な例を説明します. 第四章では、提案されたクラスに関連するドキュメントです。
それでは、最も一般的なアーカイブのタイプに進みましょう。
チャプター1. ZIPのフォーマットとデータ保存
1.1. ZIPファイルの構造
ZIP形式は、1989年にフィル・カッツによって作成され、最初のMS-DOSで PKZIPプログラムで実装されました。 カッツが設立した PKWARE社によってリリースされました。アーカイブのこの形式は、頻繁に DEFLATEデータ圧縮アルゴリズムを使用していました。この形式で、Windowsで動作する最も一般的なプログラムは、WinZipのとWinRARです。
ZIPアーカイブ形式は、時間をかけて開発され、いくつかのバージョンがあることを理解することが重要です。ZIPアーカイブで動作するクラスを作成するには、PKWARE社のウェブサイト上に配置されたバージョン6.3.4の正式なフォーマットの仕様に準拠する必要があります。: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT. これは汎用性があり、多数の説明が含まれる、2014年10月1日付けの最新フォーマットの仕様です。
この記事では、最小限の努力でできる方法で行い、新しいアーカイブの成功ファイルの抽出および作成のために必要なデータを使用するツールを作成します。これは、ZIPファイルでの動作がある程度限定されることを意味します。 - フォーマットの互換性は保証されるものではないので、アーカイブの完全な"雑食性"を言及する必要はありません。サードパーティの資金によって作成されたいくつかのZIPアーカイブは、機器によって抽出することができない可能性があります。
各ZIPアーカイブバイトの順序付けられたシーケンスを含むバイナリファイルです。言い変えれば、ZIPアーカイブのすべてのファイルは、名前、特性、プロパティがあります。(ファイルの修正時間)したがって、圧縮されたデータに加えて、その属性、およびその他のサービス情報の名前を格納します。サービス情報は、非常に特異的な様式で配置され、かつ、規則的な構造をしています。たとえば、アーカイブに2つのファイルが含まれている場合 (File#1 と File#2), それは以下のスキームを有します:
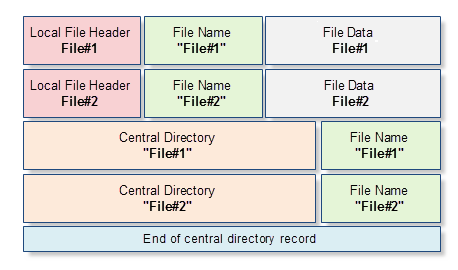
図1. 2つのファイルを含むZIPアーカイブの略図: File#1 と File#2
後の段階で、私たちは、このスキームの各ブロックの詳細を見ますが、現時点では、簡単な説明で行います:
- Local File Header — ファイル名のファイルサイズ前と圧縮後、ファイルの変更時間、CRC32チェックサムとローカルポインタ:このデータ・ブロックは、圧縮されたファイルに関する基本的な情報が含まれています。それに加えて、このブロックには、ファイルを解凍するために必要なアーカイブのバージョンが含まれています.
- File Name 圧縮されたファイル名を構成する任意の長さのバイトのシーケンス。ファイル名の長さは65536文字を超えてはなりません。
- File Data任意の長さのバイト配列の形式で圧縮されたファイルの内容。ファイルが空であるか、またはディレクトリを含む場合、この配列は使用されません。
- Central Directory ローカルファイルヘッダの拡張データビューを示す。ローカルファイルのヘッダに含まれるデータに加えて、ファイル属性、ローカルファイルヘッダと他の大部分の未使用情報の構造へのローカル参照を有しています.
- 中央ディレクトリレコードの終了 - この構造は、すべてのアーカイブ内のテンプレートとされ、アーカイブの最後に書かれます. 最も興味深いデータは中央ディレクトリブロックの開始とローカル参照(ファイルやディレクトリの数)のアーカイブのレコードの数です.
この方式の各ブロックは、規則的な構造のいずれかを提示し、または任意の長さをバイト配列としてすることができます。各構造は、structureと記述することができます。 MQLと同じ名前です。
構造体は常に固定数バイトをとります。それゆえ、任意の長さの配列や行を含めることはできません。しかし、オブジェクトへのポインタを持つことができます。これは、アーカイブ・ファイル名が構造の外側に配置されていて、任意の長さであるためです。同じことが、圧縮されたデータファイルにも言えます。 - サイズは構造体の外に保持されます。このように、ZIPアーカイブのパターン、ラインおよび圧縮データの配列によって提示されると結論付けることができます。
ZIPファイル形式では、上記に加えて、< データ記述子と呼ばれる構造体をs追加します。. この構造は、何らかの理由でローカルファイルヘッダの構造を形成することができない場合に使用され、ローカルファイルヘッダに必要なデータの一部は、データ圧縮後に使用可能となります。実際には、現在の状況は非常に固有なので、この構造が使われることはありません。我々のクラスでは、このデータブロックがサポートされていないアーカイブで動作するために使用されません。
| ZIPアーカイブフォーマットに従って、各ファイルは残りの部分とは別に圧縮されていることに注意してください。一方、エラーの発生を見つけることがでた"壊れた"アーカイブには、間違った内容のファイルを削除し、変更することなく、残りの内容を残すことによって復元することができます。個別のファイルを圧縮したときに、各ファイルは少しだけスペースを取る一方、圧縮効率は、十分に低減されます。 |
|---|
1.2. 16進数エディタでのZIPファイルの分析
我々には典型的なZIPアーカイブ内に何があるかを見ることができる知識があります。このために、16進エディタWinHexを使用します。何らかの理由でWinHexがない場合は、他の進エディタで代用することができます。結局のところ、すべてのアーカイブは単純なバイトのシーケンスとして開くことができます。実験として、"Hello World!のフレーズを持つ単一のテキストファイルが含まれる、単純なZIPアーカイブを作成しましょう。:

図2. メモ帳でテキストファイルの作成
その後、アーカイブを作成するために、任意のZIPアーカイブを使用します。今回のケースでは、WinRARが、このようなアーカイバとなります。先ほど作成したファイルを選択して、ZIP形式でそれをアーカイブする必要があります。
図3. WinRARのアーカイバを使用すると、アーカイブが作成されます。
コンピュータのハードディスク上のアーカイブで終了した後、新しいファイル "HelloWorld.zip"は、対応するディレクトリに表示されます。このファイルの特徴は、135バイトのサイズが11バイトのソーステキストファイルよりもかなり大きいということです。これは、圧縮されたデータの他に、ZIPアーカイブがサービス情報を含むことによるものです。したがって、アーカイブは数百バイトだけの少量のデータには無意味です。
今、データレイアウトスキームを持っているという、バイトの集合からなるアーカイブの性質は、重要ではありません。16進エディタWinHexで開きます。下の図は、スキーム1に記載の各エリアの強調表示条件とアーカイブのバイト配列を示しています。
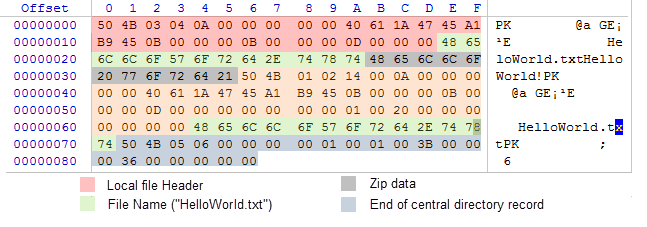
図4. HelloWorld.txtファイルを含むZIPアーカイブの内容
実際に、語句"HelloWorldの!"は、0x35から0x2Bの範囲で11バイトを使っています。圧縮アルゴリズムは、オリジナルのフレーズを圧縮しないことに注意してください。ZIPアーカイブでは、元の形で存在しています。このような短いメッセージの圧縮は非効率的であり、かつ圧縮された配列は、非圧縮のときよりも重くなることがあります。
| ZIPアーカイブには、常に圧縮されたデータが含まれている訳ではありません。アーカイブが作成されたとき、明らかにアーカイブ中にデータを圧縮するために述べられた場合でも、稀に、アーカイブされたデータがオリジナルの非圧縮形式になることがあります。データ量がわずかである場合に、この状況が発生し、データ圧縮が非効率的になります。 |
|---|
図4を見ると、データブロックが圧縮されたアーカイブに格納する方法とは明確に異なり、ファイルのデータが正確に保持されています。今、個別に各データブロックを分析してみましょう。
1.3. ローカルファイルヘッダ構造
各ZIPアーカイブは、ローカルファイルヘッダの構造から始まります。これには、圧縮されたバイト配列として、それを次のファイルのメタデータが含まれています。フォーマット仕様に従ってアーカイブの各構造体は、そのユニークな4バイトの識別子を持っています。この構造は例外ではありません、そのユニークな識別子は、<S0>0x04034B50</ S0>に等しくなります。
x86ベースのプロセッサは、バイナリファイルからRAMに逆の順序でロードすることに注意する必要があります。番号は裏返しに配置されています。最後のバイトが最初のバイトとその逆の代わりをします。ファイルにデータを書き込む方法は、ファイルのフォーマットによって決定され、ZIPファイルは、逆の順序で行われます。バイトシーケンスの詳細についてはウィキペディアの記事をお読みください - "エンディアン"意味構造識別子の図のように書き込まれます。0x504B0304(0x04034B50内側)。任意のZIPアーカイブは、このバイト列から始まります。
この構造体は厳密に定義されたバイト列であるので、MQL5プログラミング言語の同様の構造として提示することができます。MQL5上のローカルファイルヘッダの構造の説明は以下の通りです:
//+------------------------------------------------------------------+ //| 仕様6.3.4に基づいた、ローカルファイルヘッダ: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // ZIPローカルヘッダは、常に0x04034b50等しい ushort version; // 抽出するための最小バージョン ushort bit_flag; // ビットフラグ ushort comp_method; // 圧縮方法(0 - 非圧縮、8 - デフレート) ushort last_mod_time; // ファイルの修正時刻 ushort last_mod_date; // ファイル変更日時 uint crc_32; // CRC-32 hash uint comp_size; // 圧縮サイズ uint uncomp_size; // 非圧縮サイズ ushort filename_length; // ファイル名の長さ ushort extrafield_length; // 追加データと長さフィールド bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
この構造体は、ZIPアーカイブでの実際の動作に使用されるため、データフィールドのほかに、バイトのセットから構成するために、逆バイトのセット(バイト配列TCHAR)に構造を変換することを可能にする追加のメソッドが含まれています。ここで、ToCharArray及びLoadFromCharArrayメソッドを使います。
//+------------------------------------------------------------------+ //|Private struct for convert LocalHeader to uchar array | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // ZipLocalHeaderのサイズ }; //+------------------------------------------------------------------+ //| Convert ZipHeader struct to uchar array. | //| RETURN: | //| Numbers of copied elements. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| Init local header structure from char array | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
フィールドの構造(順にリストされている)について説明します。:
- header —ユニークな構造識別子、ファイルのローカルヘッダが等しい0x04034B50;
- version — ファイルを解凍するための最小バージョン;
- bit_flag — バイトフラグは、識別子0x02</ s1>を保持;
- comp_method — 圧縮タイプを使用通常の圧縮方法は、0x08が使用されている識別子とDEFLATEメソッド。
- last_mod_time — 最後のファイルの修正時刻. 時間、分、MS-DOS形式のファイル変更の秒が含まれています。このフォーマットは、マイクロソフト社のWebページに記載されています。
- last_mod_date — 最後のファイルの変更日。月の日付が含まれている、年の月の数とMS-DOS形式のファイル変更の年。
- crc_32 — チェックサムCRC32。ファイルの内容のエラーを見つけるために、アーカイブでの作業プログラムによって使用されています。このフィールドが入力されていない場合、ZIPのアーカイバは、破損したファイルを参照する圧縮ファイルを解凍することを拒否します。
- comp_size — バイト単位で圧縮されたデータのサイズ;
- uncomp_size —バイト単位で元データのサイズ;
- filename_length — ファイル名の長さ;
- extrafield_length — 追加のデータ属性を記述するための特別なフィールド. まず使われることはありません。
アーカイブ内のこのような構造を保存するとき、この構造体に対応するフィールドの値を保持するバイトのシーケンスが作成されます。徹底的にこの構造体のバイト配列を分析します。この時に、ファイルHelloWorld.txtでZIPアーカイブをリロードします。

図5. HelloWorld.zipアーカイブ内のローカルファイルヘッダ構造のバイトチャート
チャートは、構造体のフィールドを埋めるバイトを示しています。そのデータを検証するためには、フィールド"ファイル名の長さ"に注意を払います。2バイトを取り、0x0D00に等しい値です。また、ファイル"HelloWorld.txt"は持っているシンボルの数で - 10進形式でそれを裏返しにこの番号を回して配置することにより、13の値を取得します。同じことを、圧縮データのサイズを示すフィールドを用いて行うことができます。これは、0x0B00000011バイトに対応しています。実際には、語句の "Hello World!"は、アーカイブ非圧縮で保存され、11バイトを占有しています。
構造体は圧縮されたデータに続き、新しい構造体が開始されます -次のセクションで、より多くの詳細をカバーするセントラルディレクトリを扱います。
中央ディレクトリの構造は、ローカルファイルヘッダの拡張データの表現です。実際には、基本的なことは、ローカルファイルヘッダからのZIPアーカイブデータで十分です。しかし、中央ディレクトリ構造の使用は必須であり、その値は正しく記入されなければなりません。この構造は、ユニークな識別子0x02014B50を持ちます。MQL5では、次のようになります。
//+------------------------------------------------------------------+ //| Central directory structure | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // 中央ディレクトリのヘッダは、常に0x02014B50に等しい ushort made_ver; // バージョン ushort version; // 抽出するための最小バージョン ushort bit_flag; // ビットフラグ ushort comp_method; // 圧縮方法(0 - 非圧縮、8 - デフレート) ushort last_mod_time; // ファイルの修正時刻 ushort last_mod_date; // ファイル変更日時 uint crc_32; // CRC32 ハッシュ uint comp_size; // 圧縮サイズ uint uncomp_size; // 非圧縮サイズ ushort filename_length; // ファイル名の長さ ushort extrafield_length; // 追加データと長さフィールド ushort file_comment_length; // コメントファイルの長さ ushort disk_number_start; // ディスク番号開始 ushort internal_file_attr; // 内部のファイル属性 uint external_file_attr; // 外部ファイルの属性 uint offset_header; // 相対ローカルヘッダのオフセット bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
ご覧のように、既に多くのデータは、ローカルファイルヘッダのデータの複製が含まれています。ただ、その前の構造のように、バイト配列に、その内容を変換するために、サービスのメソッドが含まれています。
フィールドについて説明します。
- header — 0x02014B50</ s1>に等しいユニークな構造識別子、;
- made_ver — アーカイブ標準バージョンはアーカイブに使用されます;
- version — ファイルの解凍に成功した最低限の標準バージョン;
- bit_flag — バイトフラグは、識別子0x02を持っています;
- comp_method — 圧縮タイプを使用通常、DEFLATE圧縮方法が使用され、圧縮タイプ識別子0x08を有します。
- last_mod_time — 最後のファイルの修正時刻. 時間、分、MS-DOS形式のファイル変更の秒が含まれています。このフォーマットは、マイクロソフト社のWebページに記載されています。
- last_mod_date — 最後のファイルの変更日。月の日付が含まれている、年の月の数とMS-DOS形式のファイル変更の年。
- crc_32 — チェックサムCRC32。ファイルの内容のエラーを見つけるために、アーカイブでの作業プログラムによって使用されています。このフィールドが入力されていない場合、ZIPのアーカイバは、破損したファイルを参照する圧縮ファイルを解凍することを拒否します。
- comp_size — バイト単位で圧縮されたデータのサイズ;
- uncomp_size —バイト単位で元データのサイズ;
- filename_length — ファイル名の長さ;
- extrafield_length — 追加のデータ属性を記述するための特別なフィールド. まず使われることはありません。
- file_comment_length —ファイルコメントの長さ;
- disk_number_start — アーカイブが書き込まれているディスクの数. ほとんど常にゼロに等しいです。
- internal_file_attr —MS-DOSフォーマットの属性;
- external_file_attr — 拡張ファイルのMS-DOSフォーマットの属性;
- offset_header — ローカルファイルヘッダ構造の始まり
アーカイブにこの構造体を保存する場合、そのフィールドの値を格納するバイトのシーケンスが作成されます。この構造体のバイトのレイアウトは、図5のようになります。

図6. アーカイブHelloWorld.zipのセントラルディレクトリ構造のバイトチャート
ローカルファイルヘッダとは異なり、中央ディレクトリ構造は、連続した順序を持っています。ECDR構造 - 第1の先頭アドレスは、特別な最終データブロックに指定されています。構造に関するより詳細な情報は、次のセクションで行います。
1.5. ECDR(End of Central Directory Record)の構造
セントラルディレクトリレコード(または単にECDR)の終わりの構造で、ZIPファイルを完了します。ユニークな識別子は、0x06054B50に等しいです。各アーカイブには、構造の単一のコピーが含まれています。ECDRは、アーカイブにあるファイルやディレクトリの数だけでなく、中央ディレクトリ構造の始まりの配列のアドレスとその合計サイズを格納します。また、データブロックは、他の情報を格納します。ここでMQL5上のEMDRの完全な記述を載せます。
//+------------------------------------------------------------------+ //| End of central directory record structure | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // エンド中央ディレクトリレコードのヘッダーは、常に0x06054b50等しい ushort disk_number; // このディスクの数 ushort disk_number_cd; // 中央ディレクトリの開始とディスクの番号 ushort total_entries_disk; // このディスク上の中央ディレクトリ内のエントリの総数 ushort total_entries; // 中央ディレクトリ内のエントリの総数 uint size_central_dir; // 中央ディレクトリのサイズ uint start_cd_offset; // 起動ディスク番号 ushort file_comment_lengtt; // ファイルコメントの長さ string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
より詳細に、この構造体のフィールドを記述しましょう。
- header — ユニークな構造識別子は、0x06054B50に等しい;
- disk_number — ディスクの数;
- disk_number_cd — ディスクの数は、中央ディレクトリから開始されます;
- total_entries_disk — 中央ディレクトリ(ファイルやディレクトリの数)のエントリの合計数。
- total_entries — すべてのエントリ(ファイルやディレクトリの数);
- size_central_dir — 中央ディレクトリセクションのサイズ;
- start_cd_offset — 中央ディレクトリセクションのバイトアドレスから始まります;
- file_comment_length — アーカイブのコメントの長さ。
アーカイブにこの構造体を保存する場合、そのフィールドの値を格納するバイトのシーケンスが作成されます。ここで、構造体のバイト」レイアウトがあります:

図7. ECDR構造のバイトチャート
配列内の要素の数を決定するために、このデータブロックを使用します。
チャプター2. CZipクラスの概要とアルゴリズム
2.1. CZipFile及び CZipFolder クラスのアーカイブ内の圧縮ファイルの構造
最初の章では、ZIPアーカイブの形式を見てきました。それにより構成されたデータの種類を分析し、関連性の高い構造の型を説明しました。これらのタイプを定義したら、ZIPアーカイブを簡単かつ迅速に操作できるようにするため、高レベルの専門クラス CZipを実装します:
- 新しいアーカイブの作成;
- ハードドライブ上で以前に作成したアーカイブを開く、
- リモートサーバーからアーカイブをダウンロードする
- アーカイブに新しいファイルを追加する;
- アーカイブからファイルを削除する;、
- 別々にアーカイブまたはそのファイルを解凍する。
CZipクラスは、正しくファイルアーカイブコレクションを操作するための通常の高レベルインタフェースを提供することにより、アーカイブの必要な構成の完了に使用できます。このクラスは、アーカイブに関連するほとんどのタスクに適しています。
明らかに、ZIPアーカイブの内容は、フォルダやファイルに分割することができます。コンテンツの両方のタイプには、機能の拡張セットがあります。: 名前, サイズ, ファイルfile アトリビュート, 生成時間 など。これらのプロパティは、圧縮データとしてのフォルダやファイル、および一部の、両方に共通しているものではありません。特別なサービスクラスのアーカイブを使用する最適なソリューション: ZipファイルとGZipディレクトリ これらの特定のクラスは、それぞれ、ファイルやフォルダを提供します。アーカイブのコンテンツの条件付き分類は以下のチャートに表示されます。
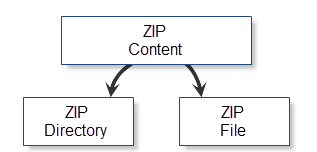
図8. アーカイブオブジェクトの条件付きの分類
このように、最初にgzipファイルの種類のオブジェクトを作成し、アーカイブにこのオブジェクトファイルを追加する必要があります。そして、CZiparchiveにファイルを追加します。"!HelloWorld"の一例として、同じ名前のテキストを含むテキストファイル" HelloWorld.txt"を作成し、アーカイブに追加します。
//+------------------------------------------------------------------+ //| Create file with 'HelloWorld' message | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // 空のZIPアーカイブを作成 uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // 語句の書き込みに "Hello World!"のバイト配列 CZipFile* file = new CZipFile("HelloWorld.txt",content); // 名前でZIPファイルを作成する"HelloWorld.txt" // バイト配列が含まれる"Hello World!" zip.AddFile(file); // アーカイブするZIPファイルを追加 zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // ディスク上にアーカイブを保存し、呼び出す "HelloWorld.zip" printf("Size: "+(string)zip.Size()); }
コンピュータのディスク上でこのコードを実行した後、同じ名前のフレーズを持つ単一のテキストファイル"HelloWorld.txt"を含む新しいZIPアーカイブが表示されます。フォルダの代わりにファイルを作成したい場合は、かわりにZIPファイルのCZipFolderクラスのコピーを作成する必要があります。名前だけを指定すれば十分です。
既に述べたように、ZipファイルとCZipFolderクラスは共通点が多いです。GZIPコンテンツ - 両方のクラスは、それらの共通のルーツから由来します。このクラスには、アーカイブの内容を操作するための汎用的な方法とデータが含まれています。
2.2. CZipFileでの圧縮ファイルの生成
圧縮されたZIPファイルを作成することと、ZIPファイルのコピーを作成することは同じです。既に知られているように、ファイルを作成するためには、名前と内容を指定する必要があります。したがって、Zipファイルビルダーはまた、関連するパラメータの明示的な指示を必要とします。
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
セクション2.1でこの構造のコールが示されています。
それに加え、ファイルを作成しても、ディスクから既存のファイルをダウンロードする必要はありません。この場合、ハードディスクの通常のファイルに基づいて、ZIPファイルを作成することができるZipFileクラスの第二のビルダーがあります:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
このビルダー内のすべての作業はAddFileプライベートメソッドに委譲されています。そのアルゴリズムは次のとおりです。
- 指定されたファイルを読み込み用にオープンされ、その内容がバイト配列に読み取られています。
- 得られたバイト配列はAddFile配列メソッドを使用して圧縮され、char型の特殊なダイナミックアレイに格納されます。
AddFielderrorメソッドは、アーカイブを扱うためのクラス全体システムの「中心部」です。このメソッドが、最も重要なシステム機能を有しています - CryptEncode. このメソッドのソースコードは次のとおりです。
//+------------------------------------------------------------------+ //| Add file array and zip it. | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
クリプトエンコード機能の設定は、バイト配列のその後のアーカイブと黄色でマークされています。したがって、ファイル圧縮は、ZIPアーカイブ自体の作成ではんく、ZipFileのオブジェクトの作成の時点で発生していると結論付けることができます。この性質により、CZipクラスに送信されたすべてのデータは自動的に圧縮され、記録上、より少ないメモリを必要とします。
すべての場合において、符号なしバイト配列uncharがデータとして使用されていることに注意してください。実際には、コンピュータ上で動作するすべてのデータは、特定のバイト列として表すことができます。したがって、unsigned char型の配列を選択したzipファイルを、圧縮されたデータ用にコンテナを作成します。
| ユーザーは、順番にZIPファイルクラスのファイルの内容などの参照を経由して渡さなければならないUchar[]符号なし配列自身で、アーカイブするデータを変換する必要があります。そのため、この機能のファイルの絶対的に任意のタイプ、ディスクからのダウンロードやMQL-プログラム動作の過程で作成されたいずれかの、ZIPアーカイブ内に配置することができます。 |
|---|
データを抽出するのは、簡単な作業です。元のバイト配列のデータを抽出するには、file_arrayの GetUnpackFileメソッドが使用されています。基本的にCryptDecodeシステム関数のラッパー・メソッドです:
//+------------------------------------------------------------------+ //| Get unpack file. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. MS-DOSのリメンバZIPアーカイブ内の時間とデータフォーマット
データストレージのZIP形式は、前世紀の80年代後半に、"法的な後継者"のWindowsになったMS-DOSプラットフォームに作成されました。当時のデータストレージはリソースが限られていたので、MS-DOSオペレーティングシステムの日付と時刻は、別々に保存されました:2バイト(またはその時間の16ビットプロセッサのための語)がデータに割り当てられました。また、この形式で表すことができた最も古い日付は1980年1月1日(1980年1月1日)です。データを書き込むために、分、時間、日、月、年を一言で特定のバイト範囲を占有することが要求されました。
https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(V= VS.85).aspxの:このフォーマットの仕様はMicrosoftのWebサイトで提供されています。
ここで対応する2バイトのフィールド内のデータ・ストレージ・フォーマットは次のとおりです。
| N バイト | 説明 |
|---|---|
| 0-4 | 月の日 (0-31) |
| 5-8 | 月号 (1 — January, 2 — February etc.) |
| 9-15 | 1980からの年数 |
テーブル1. 2バイトのフィールドの日付ストレージのフォーマット
同様に、対応する2バイトのフィールドで時間保存形式を示します:
| N バイト | 説明 |
|---|---|
| 0-4 | 秒(保存の精確性 +/- 2 seconds) |
| 5-10 | 分 (0-59) |
| 11-15 | 24時間形式の時刻 |
表2. 2バイトのフィールドで時間記憶のフォーマット
このフォーマットの仕様を知り、バイト操作で作業することができるれば、MS-DOS形式にMQL形式で日付と時刻を変換し、対応する関数を記述することができます。逆を記述することも可能です。このような変換技術は、ZIPファイルで提供された両方のZipフォルダが提供するフォルダ、およびファイルに共通です。通常のMQL形式でそれらのデータと時刻を設定することにより、"舞台裏"で MS-DOSフォーマットにこのタイプのデータを変換することができます。DosDate、DosTime、MQLの日付と時刻はこのような変換に関与しています。以下がそのソースコードです。
MS-DOSの日付形式にMQL形式のデータ変換:
//+---------------------------------------------------------------------------------+ //| Get data in MS-DOS format. : | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::RjyDosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
MYSQL形式へMS-DOS形式のデータ変換:
//+---------------------------------------------------------------------------------+ //| MYSQL形式のデータを取得 | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
MYSQLの時間形式にMS-DOSフォーマットの時間変換:
//+---------------------------------------------------------------------------------+ //| MS-DOS形式で時刻を取得. | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
MYSQLの時間形式にMS-DOSフォーマットの時間変換:
//+---------------------------------------------------------------------------------+ //| MYSQL形式のデータを取得: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
これらのメソッドは、データと時間を格納するための内部変数を使用します。m_directory.last_mod_time とm_directory.last_mod_date, m_directoryは中央ディレクトリ型の構造です。
2.4. CRC-32チェックサムの生成
ZIPアーカイブ形式の興味深い特徴として、サービスデータを格納するだけでなく、あるケースで破損したデータを復元するのに役立ちます。受信したデータが破損しているかどうかを調べるために、ZIPアーカイブに2バイトのハッシュ値CRC32を保持している特別な余分なフィールドが含まれています。これは、圧縮する前のデータに対して計算されるチェックサムです。アーカイブからのアーカイブの非圧縮データの後に、チェックサムを再計算し、それが一致しない場合、データが破損しているとみなされ、ユーザに提供することができません。
したがって、私たちのCZipクラスは、独自の計算アルゴリズムCRC-32を持っている必要があります。そうでなければ、私たちのクラスで作成されたアーカイブは、破損したデータについての警告エラーを与えるWinRARのように、サードパーティ製のツールが読むことを拒否します:
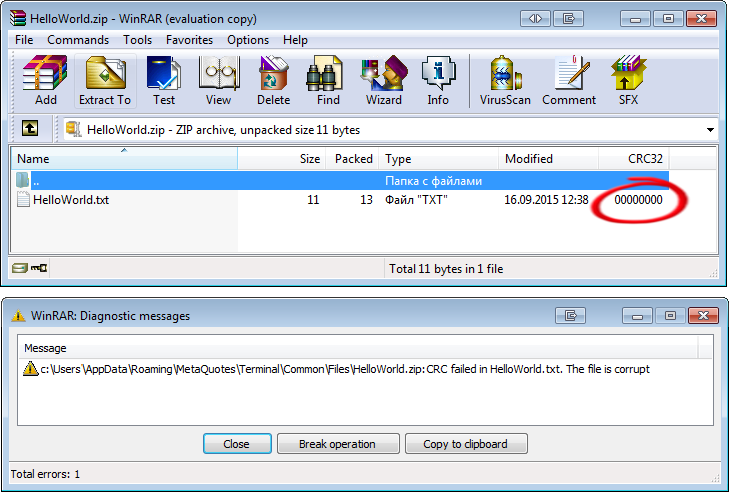
図9. WinRARの、"HelloWorld.txt"ファイルのデータ損傷に関する警告。
CRC-32チェックサムは、ファイルのみに必要とされるので、合計を算出する方法は、単にZIPファイルクラスで提供されます。この方法は、次のリンクで入手可能なCプログラミング言語の例に基づいて実装されます。 https://ru.wikibooks.org:
//+------------------------------------------------------------------+ //| Return CRC-32 sum on source data 'array' | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
正しいメソッドの動作を保証するためには、CZipを経由してWinRARのアーカイバで作成されたアーカイブを開けば十分です。各ファイルは、ユニークなCRC32コードを持っています。

図10. WinRARのアーカイバのウィンドウ内のチェックサムCRC32
アーカイブでは有効なCRC-32ハッシュと通常モードにファイルを解凍し、警告メッセージが表示されません。
2.5. アーカイブの読み込みと書き込み
最後に、ZIPアーカイブの読み込みと書き込む方法を扱います。要素CZipFileとCZipFolderで構成されるCArrayObjのコレクションがある場合は、明らかに、アーカイブ形成が重要になります。バイト列に各要素を変換し、ファイルにそれを書けば十分です。以下の方法は、このようなタスクの対処です:
- SaveZipToFile — 示されたファイルを開き、生成されたアーカイブのバイト配列を書き込む。
- ToCharArray — 対応するアーカイブのバイトの構造体を作成する。最終ECDR構造を生成する。
- ZipElementsToArray — バイトの配列に要素型でCZipContentに変換します。
難しい点は、CZipContentを提示すべてのアーカイブの要素が構造ローカルファイルヘッダーと中央ディレクトリに、2つの異なるファイルに格納されていることです。ENUM_ZIP_PART修飾子に応じて、ローカルファイルヘッダーまたは中央ディレクトリ型のバイト配列を提供する特別なZipElementsToArrayメソッドを呼び出すことが必要です。
中心部でこの機能を有するには、ソースコードに提示されている3つの方法すべての内容をよく理解している必要があります。
//+------------------------------------------------------------------+ //| Return uchar array with ZIP elements | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| Generate ZIP archive as uchar array. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| Save ZIP archive in file zip_name | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
アーカイブの読み込みは、考慮すべきいくつかのニュアンスを持っています。明らかに、保存する操作と逆です。アーカイブを保存するときに、CZipContentの要素がバイト列に変換されている場合は、アーカイブをロードしたとき、バイト列がCZipContentの要素に変換されます。この場合も各アーカイブの要素は、2つの異なるファイル部分に格納されているという事実により、 - ヘッダーとローカル中央ディレクトリファイル、CZipContentの要素はただ一つのデータ読み取り後に作成することができません。
最初に必要な要素は、データの種類を順次追加され、中間コンテナクラスCSourceZipを使用する必要があります。 - ZIPファイルまたはCZipFolderを、それに基づいて形成します。これは、これら2つのクラスが参照パラメータとして要素型CSourceZipへのポインタを受け取り、追加のコンストラクタを持っているためです。CSourceZipクラスと一緒に、このタイプの初期化は、CZipクラスのためだけに作成されており、明確な形で使用することはお勧めしません。
ロードの3つのCZipクラスのメソッド:
- LoadZipFromFile — 指定されたファイルを開いて、バイト配列にその内容を読み込む。
- LoadHeader — アドレス上のアーカイブのバイト配列からローカルファイル構造をロードする。
- LoadDirectory — アドレス上のアーカイブのバイト配列から中央ディレクトリ構造をロードする。
以下にこれらのメソッドのソースコードを参照してください。
//+------------------------------------------------------------------+ //| オフセット配列によって名前のファイルにローカルヘッダをロード。 | //| RETURN: | //| ローカルヘッダ、名前とジップコンテンツの後にアドレスを返します。 | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //コピーローカルヘッダ uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //コピーヘッダーファイル名 ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //コピージップ・アレイ ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+------------------------------------------------------------------+ //| オフセット配列によって名前のファイルを使用して中央ディレクトリをロード。 | //| RETURN: | //| CDと名前の後にアドレスを返します。 | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //コピー中央ディレクトリ uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //コピーしたディレクトリのファイル名 ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+------------------------------------------------------------------+ //| Load ZIP archive from HDD file. | //+------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
チャプター3. CZipクラスの例とパフォーマンス測定
前の章では、CZipクラスおよびZIPアーカイブのデータフォーマットを解析しました。アーカイブの構造とCZipクラスの一般的な原則が分かったので、アーカイブにリンクされた実用的作業を進めることができます。この章では、このクラスのタスクの全範囲をカバーする3の異なる例を分析します。
3.1. 選択肢したシンボルのZIPアーカイブの生成
解決する必要がある最初のタスクは、以前に取得したデータを保存することです。多くの場合、データはトレーダー端末で得られます。このようなデータが蓄積ティックとOHLCV形式の引用符の配列であり得ます。引用符の形式は以下のようになります。特別なCSV-ファイルに保存されなければならない状況になります:
Date;Time;Open;High;Low;Close;Volume 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
これはテキストデータ形式です。しばしば、統計解析システム間でデータを転送するために使用されます。使用する文字に制限があるので、残念ながら、テキストファイルのフォーマットはデータストレージの大きな冗長性を有しています。通常、これらは句読点、数字、大文字とアルファベットの小文字です。また、この形式で多くの値は頻繁に起こります。たとえば、日付を開いたり、価格は通常、大規模なデータ配列についても同様です。したがって、データ圧縮のこのタイプは、効果的でなければなりません。
それでは、端末から必要なデータをダウンロードするスクリプトを書いてみましょう。アルゴリズムは次のようになります。
- マーケットウォッチウィンドウに特徴づけられた機器が順次選択されます。
- 選択された各機器は、すべての21の期間に要求されたクオートを持っています。
- 選択した時間枠のクオートは、CSVラインアレイに変換されます。
- CSV形式のラインアレイは、バイト配列に変換されます。
- クオートのバイト配列を含むZIPファイル(Zipファイル)が作成され、その後アーカイブに追加されます。
- すべてのクオートファイルを作成した後、CZipはQuotes.zipファイル内のコンピュータのディスクに保存されます。
以下は、これらのアクションを実行するスクリプトのソースコードです。
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // 空のZIPアーカイブを作成. //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| Create ZIP with quotes from market watch | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
データのロードは、かなりの時間がかかることがあります。したがって、4つのシンボルのみ選択しました。加えて、直近の100本をロードします。また、スクリプトの実行時間は短縮すべきです。メタトレーダーの共有ファイルフォルダにパフォーマンス後、Quotes.zipアーカイブが表示されます。その内容は、WinRARのアーカイブについてであり、動作する任意のプログラムで見ることができます。
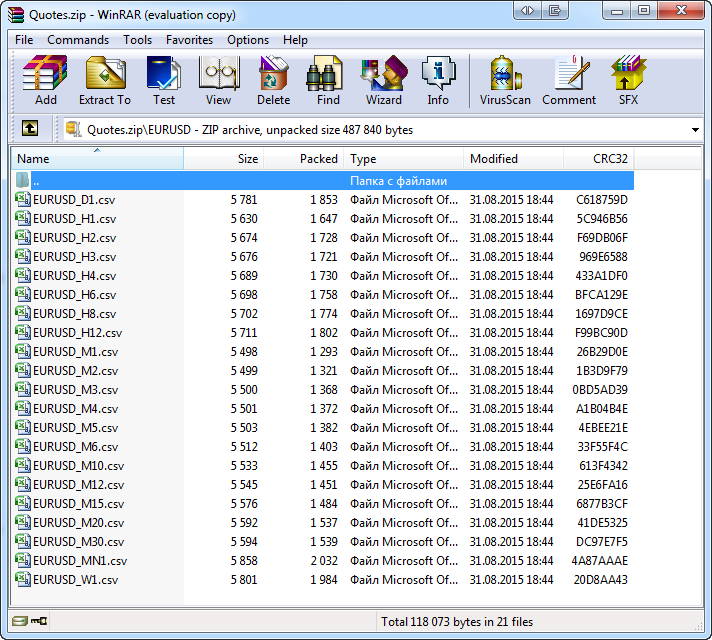
図11. WinRARのアーカイバで見引用符で保存されたファイル
作成されたアーカイブは、元のサイズと比較して、三回圧縮されます。この情報は、WinRARのによって提供されています。
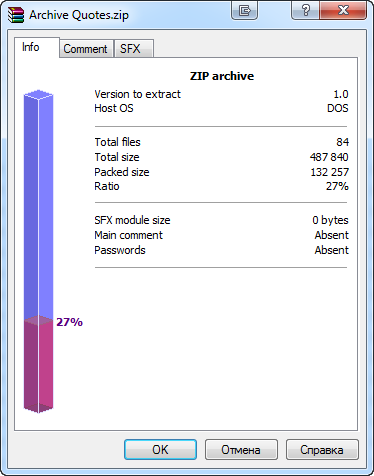
図12WinRARの情報ウィンドウで生成されるアーカイブの圧縮比
これらは、圧縮の良好な結果です。しかし、より良い圧縮比は、少なく大きいファイルを用いて達成することができます。
クオートを作成し、ZIPアーカイブに保存したスクリプトの例は、 ZipTask1.mq5の名で、この記事に添付されており、Scriptsフォルダにあります。
3.2. MQL5.comが例として利用しているリモートサーバーからアーカイブのダウンロード
次のタスクは、ネットワーク関連です。今回の例では、リモートサーバーからのZIPアーカイブをダウンロードすることができるように、デモンストレーションを行います。例として、アリゲーターと呼ばれる、次のリンクコードベースの https://www.mql5.com/en/code/9のインジケーターをロードします。:
各指標については、コードベースで公開されています。エキスパートアドバイザー、スクリプト、ライブラリ、すべての製品ソースコードは、そこにあります。ダウンロードし、ローカルコンピュータ上でこのアーカイブされたバージョンを解凍します。これに進む前に、mql5.comにアクセスする許可を出す必要があります:ウィンドウの サービス - >設定 - >エキスパートアドバイザー で次のアドレス「https://www.mql5.com"を入力してください。
CZipクラスには、インターネットリソースからアーカイブをダウンロードする独自の方法があります。しかし、それを使用するのではなく、独自のスクリプトを書いてみましょう。
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/ru/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("Unable to download ZIP archive from "+mql_url+". Check request and permissions EA."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("Loaded bad ZIP archive. Check results array."); return; } printf("Archive successfully loaded. Total files: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
ご覧の通り、スクリプトのソースコードは非常に簡単です。最初に、リモートZIPアーカイブアドレスを持つWebリクエストが呼び出されます。WebRequestクラスが得られ、アレイzip_arrayにアーカイブのバイト配列をロードし、それがCreateFrom toCharArrayメソッドを使用してCZipクラスにロードされます。この方法では、アーカイブと内部動作するために必要なバイト列から直接アーカイブを作成することができます。
CreateFromCharArrayメソッドに加えて、CZip LoadZipFromUrlは、Webリンクからアーカイブをダウンロードするための特別なLoadZipFromUrlメソッドがあります。これは前のスクリプトとほぼ同じように動作します。ソースコードは次のとおりです。
//+------------------------------------------------------------------+ //| Load ZIP archive from url | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
ZIPアーカイブは後に作成され、その内容は、リモートサーバーからダウンロードされます。このメソッド操作の結果は同じです。
コードベースからアーカイブをダウンロードするスクリプトの例は、 ZipTask2.mq5です。この記事の下に添付されており、Scriptsフォルダにあります。
3.3. プログラムデータをRAMに圧縮
RAMにプログラムの内部データを圧縮することは、アーカイブを使用するための自明な方法です。あまりにも多くのメモリ内のデータが処理されるとき、この方法を使用します。このアプローチを使用する場合、追加のアクションはサービス構造またはデータを解凍/アーカイブのために必要とされ、プログラム全体の性能が低下します。
MQLプログラムはヒストリカルオーダーのコレクションを格納するとを想定してみましょう。識別子、注文タイプ、時間の変更、ボリュームなど、各注文は特別なオーダーによって、そのすべてのプロパティが含まれています。この構造を記述します。
//+------------------------------------------------------------------+ //| History order | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // チケットオーダー datetime time_setup; // 時間設定の順序 ENUM_ORDER_TYPE type; // タイプ順 ENUM_ORDER_STATE state; // 状態の順序 datetime time_exp; // 呼気時間 datetime time_done; // 時間が行われたり、注文をキャンセル long time_setup_msc; // MSCのタイムセットアップ long time_done_msc; // 時間MSCで行われ ENUM_ORDER_TYPE_FILLING filling; // タイプ充填 ENUM_ORDER_TYPE_TIME type_time; // 生きている時間を入力 ulong magic; // オーダーのマジック ulong position_id; // ID double vol_init; // ボリュームのinit double vol_curr; // 体積電流 double price_open; // オープン価格 double sl; // ストップロスのレベル double tp; // レベル-利益取ります double price_current; // 価格電流 double price_stop_limit; // 価格停止制限 string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| Init by ticket | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| Return comment of order | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| Return symbol of order | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| Set comment order | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| Set symbol order | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| Converter for uchar array. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| Convert order structure to uchar array | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
オペレータのコールsizeofは、この構造が200バイトをとることを示しています。sizeof(注文)*過去の注文の数:この方法で、過去の注文の保管は、式によって算出されたバイト数を取ります。その結果、1000件のヒストリカル注文を含んだために、以下のメモリ200*1000=200000バイトまたはほぼ200キロバイトが必要になります。それは、今日のスペックでは多くはありませんが、場合によってサイズが十万を超えてしまう場合には、メモリ使用量が非常に重要になります。
にもかかわらず、それらを圧縮できるコンテナを開発することが可能です。このコンテナは、新しい要素の注文を追加および削除する従来の方法に加えて、構造体の内容を圧縮する方法注文が含まれています。コンテナのソースコードは、次のとおりです。
//+------------------------------------------------------------------+ //| Container of orders. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| Add new order. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| Return order at index. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| Return total orders. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| Delete order by index. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| Return orders size. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
この考え方は、ユーザーが直接コンピュータのRAMでコンテナに新しい要素を追加し、そして、必要に応じて、その内容をを圧縮することができます。どのように動作するか見てみましょう。これがデモスクリプトです:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="Unpack size: "+(string)unpack_size+"bytes; "+ "Pack size: "+(string)pack_size+" bytes ("+per+" percent compressed. "+ "Pack execute msc: "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("First id ticket: "+(string)first.ticket); } } //+------------------------------------------------------------------+
圧縮の瞬間、黄色で強調表示されます。858ヒストリカルオーダーを持っているアカウントでローンチされたら、このスクリプトは次のような結果を出します。:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) Unpack size: 171600 バイト; パックサイズ: 1521 バイト (0.89 パーセント圧縮. マイクロ秒の実行パック.: 2534
これからもわかるように、解凍されたサイズは171,600バイトでした。圧縮後のサイズは、圧縮比が100倍を超えて1521バイトです!これは、多くの構造のフィールドに類似データが含まれているという事実によるものです。また、多くのフィールドではメモリが割り当てられていますが、空の値です。
圧縮が正しく動作しているか確認するには、任意のオーダーを選択し、そのプロパティを出力する必要があります。最初のオーダーとその一意の識別子を選択しました。注文の識別子は圧縮した後に正しく表示されていました:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) 応急チケット: 10279280
参照する場合のアルゴリズムは、以前に生産性が低下したデータをパックアンパックすることです。したがって、データは、その形成作業が完了した後にのみ圧縮される必要があります。より高い圧縮率のためには、すべてのデータが圧縮された後、単一の配列に集めます。逆のプロセスは、解凍のために適用されます。
興味深いことに、858要素の圧縮は、十分に強力なコンピュータ上で2.5ミリ秒かかります。同じデータを解凍すると、より高速で、約0.9ミリ秒かかります。したがって、数千からなる配列を解凍の1サイクルは約3.5から4.0ミリ秒かかります。これは、メモリを百倍以上節約できます。この特性は、大規模なデータセットでZIP圧縮をする場合、十分に効果的に見えます。
コンピュータのメモリ内のデータを圧縮するスクリプトの例 ZipTask3.mq5がScriptsフォルダにあります。また、 Orders.mqhファイルは、インクルードフォルダにあり、その動作に必要とされます。
チャプター4. ZIPアーカイブのオペレーションクラスのドキュメント
4.1. GZipコンテンツクラスのドキュメント
この章では、ZIPアーカイブで動作するクラスで使用されるメソッドについて説明します。CZipContentクラスは、ユーザレベルで直接使用されません。しかし、そのすべてのパブリックメソッドは、クラスCZipFileおよびCLipFolderによって委任されています。したがって、プロパティとメソッドはまた、それらのクラスに適応されます。
ZipType() メソッド
ZipTypeメソッドは、アーカイブ内の現在の要素の型を返します。フォルダ(ディレクトリ)およびファイル:アーカイブに格納されているアイテムには2種類があります。ZIPファイルクラス - フォルダのタイプはCZipDirectoryクラス、ファイルの種類によって表されます。現在の章のセクション2.1のZIPアーカイブタイプの詳細については、圧縮されたアーカイブ、CZipFileとCZipFolderクラスを参照してください。
ENUM_ZIP_TYPE ZipType(void);返り値
これは、現在でCZipContentのコピーが属する、ENUM ZIP_TYPEの列挙を返します。
Nameメソッド(void)
これは、アーカイブ内のフォルダ名やファイル名を返します。string Name(void);
返り値
ファイル名やフォルダ名。
メソッド名(string名)
アーカイブ内の現在のフォルダ名やファイル名を設定します。現在のフォルダまたはファイル名を変更するために使用されます。
void Name(string name);
パラメータ:
- [in] name — 新しいフォルダもしくはファイル名名前は一意であり、アーカイブフォルダまたはファイル内の他の名前はユニークでなければなりません。
CreateDateTime メソッド (datetime date_time)
アーカイブ内のフォルダやファイルの変更の新しい日付を設定します。
void CreateDateTime(datetime date_time);
パラメータ:
- <I0>[中] DATE_TIME</ I0> - 現在のフォルダまたはファイルに設定するために必要な日付と時刻。
注意:
日付と時刻は、MS-DOSフォーマットに変換され、ZipLocalHeaderとZipCentralDirectoryの内部構造に格納されています。このフォーマットを提示する方法の詳細については、次の記事をお読みください MS-DOSのリメンバZIPアーカイブ内の日付と時刻のフォーマット".
CreateDateTime メソッド (void)
現在のフォルダまたはファイルを変更した日付と時刻を返します。
datetime CreateDateTime(void);
返り値
日付と現在のフォルダまたはファイルを変更
CompressedSize()method
常にファイルで圧縮されたデータのサイズを返し、ディレクトリに対してはゼロに等しくなります。
uint CompressedSize(void);
Return value
バイト単位で圧縮されたデータのサイズ。
UncompressedSize() メソッド
常にファイルの元の非圧縮データのサイズを返し、ディレクトリに対してはゼロに等しくなります。
uint UncompressedSize(void);
Return value
バイト単位での元データのサイズ。
TotalSize() メソッド
アーカイブ要素の合計サイズを返します。名前と(ファイル用)コンテンツに加えて、各アーカイブファイルまたはディレクトリは、追加のサービス構造を保存します。
int TotalSize(void);
Return value
追加のサービスデータと現在のアーカイブの要素の合計サイズ。
FileNameLength() メソッド
名前のディレクトリの長さや使用するシンボルの量で表したファイルを返します。
ushort FileNameLength(void);
Return value
ディレクトリの長さや使用するシンボルの量で表したファイルの名前を指定します。
UnpackOnDisk()メソッド
コンピュータのハードディスク上の要素名を持つファイル内の要素の内容を解凍します。ディレクトリが解凍されている場合は、代わりにファイルの関連フォルダが作成されます。
bool UnpackOnDisk(string folder, int file_common);
パラメータ
- [in] folder — 現在のフォルダまたはファイルを圧縮する必要があるルートフォルダの名前。要素がアーカイブフォルダを作成せずに解凍する必要がある場合は、この値は空""に等しいままにしています。
- [in] file_common — この修飾子はメタトレーダープログラムが要素を解凍する必要があるファイルシステムのセクションに示します。すべてのメタトレーダー5のターミナルに共通のファイルセクションで解凍を実行したい場合は、FILE_COMMONにこのパラメータを設定してください。
返り値
ハードディスク上のファイルやフォルダの復元が成功した場合は、trueを返します。そうでない場合、falseを返します。
4.2. CZipFileクラスのドキュメント
ZIPファイルのクラスは、GZIPコンテンツから継承され、アーカイブファイルを格納するために使用されます。Zipファイルは圧縮形式でファイルの内容を格納します。これは、保存のためにファイルを転送するとき、自動的にその内容を圧縮することを意味します。GetUnpackFileメソッドを呼び出すときにファイルの解凍も自動的に行われます。CZipContentのサポートメソッドの数とは別に、CZipFileもファイルで動作する特別なメソッドをサポートしています。以下はこれらのメソッドの詳細です。
AddFile() メソッド
現在のZIPファイルの要素へハードディスクからファイルを追加します。CZipアーカイブにファイルを追加するには、まずCZipFileのクラスのコピーを作成し、その名前と場所を指定する必要があります。クラスのサンプルを作成した後、適切なメソッドを呼び出すことによってCZipクラスに追加されなければなりません。転送された内容の実際の圧縮は、(このメソッドを呼び出す)、それらを追加した瞬間に発生します。
bool AddFile(string full_path, int file_common);
パラメータ
- [in] full_path — MQLプログラムの中央のファイルカタログに対して、そのパスを含むファイルの完全な名前。
- [in] file_common — この修飾子は、メタトレーダープログラムのファイル・システムのセクションで、要素を圧縮するために必要とされていることを示します。すべてのメタトレーダー5のターミナルに共通のファイルセクションで解凍を実行したい場合は、FILE_COMMONにこのパラメータを設定してください。
返り値
ファイルが正常に行われた場合trueを返します。そうでない場合、falseを返します。
AddFileArray() メソッド
CZipFileのコンテンツとしてuchar型のバイト配列を追加します。この方法は、ファイルの内容を動的に作成する場合に使用されます。転送された内容の実際の圧縮は、(このメソッドの呼び出し)を追加された時点で発生します。
bool AddFileArray(uchar& file_src[]);
パラメータ
- [in] file_src — バイト配列を追加。
返り値
ファイルが正常に行われた場合trueを返します。そうでない場合、falseを返します。
GetPackFile() メソッド
圧縮ファイルの内容を返します。
void GetPackFile(uchar& file_array[]);
パラメータ
- [out] file_array — 圧縮ファイルの内容を受け入れるために必要とするバイト配列。
GetUnpackFile() メソッド
解凍されたファイルの内容を返します。コンテンツはメソッド呼び出しの瞬間に解凍されます。
void GetUnpackFile(uchar& file_array[]);
パラメータ
- [out] file_array — 解凍されたファイルの内容を受け入れるために必要となるバイト配列。
4.3. CZip クラスのドキュメント
CZipクラスはZIPタイプのアーカイブの主な動作を実装しています。ZIPファイル(CZipFile)のフォルダ(GZipDirectory)を表す要素、クラスは、ZIP要素の2種類の追加を持つことができる一般的なZIPアーカイブです。CZipクラスは同様にバイト列の形式で、両方のコンピュータのハードディスクからロードする既存のアーカイブを可能にします。
ToCharArray() メソッド
UCHAR型のバイト列にZIPアーカイブの内容を変換します。
void ToCharArray(uchar& zip_arch[]);
パラメータ
- [out] zip_arch — ZIPアーカイブの内容を受け入れるために必要とするバイト配列。
CreateFromCharArray() メソッド
バイト配列からのZIPアーカイブをロードします。
bool CreateFromCharArray(uchar& zip_arch[]);
パラメータ
- [out] zip_arch — ZIPアーカイブの内容をロードするために必要とされたバイト配列。
返り値
バイト配列からのアーカイブの作成が成功した場合trueを返し、そうでない場合falseを返します。
SaveZipToFile() メソッド
指定されたファイル内の内容と現在のZIPアーカイブを保存します。
bool SaveZipToFile(string zip_name, int file_common);
パラメータ
- [in] zip_name — MQLプログラムの中心的なファイルディレクトリに関する、そのパスを含むファイルの完全な名前。
- [in]file_common - この修飾子は、要素を圧縮する必要があるメタトレーダープログラムのファイルシステムのセクションに示します. すべてのメタトレーダー5のターミナルに共通のファイルセクションで解凍を実行したい場合は、FILE_COMMONにこのパラメータを設定してください。
返り値
ファイルにアーカイブを保存に成功するとtrue,そうでない場合falseを返します。
LoadZipFromFile() メソッド
コンピュータのハードディスクにアーカイブの内容をロードします。
bool LoadZipFromFile(string full_path, int file_common);
パラメータ
- [in] full_path — MQLプログラムの中央のファイルカタログに対して、そのパスを含むファイルの完全な名前。
- [in]file_common - この修飾子は、要素を圧縮する必要があるメタトレーダープログラムのファイルシステムのセクションに示します. すべてのメタトレーダー5のターミナルに共通のファイルセクションで解凍を実行したい場合は、FILE_COMMONにこのパラメータを設定してください。
返り値
ファイルからアーカイブの読み込みはtrue、そうでない場合はfalseを返します。
LoadZipFromUrl() メソッド
Webリンク URLにアーカイブの内容をロードします。このメソッドを正しく動作させるためには、要求されたリソースへのアクセス許可を設定する必要があります。この方法の詳細については、この記事のセクション3.2を参照してください。:"MQL5.comは例として使用したアーカイブリモートサーバからのダウンロード。"
bool LoadZipFromUrl(string url);
パラメータ
- [in] url — アーカイブを参照します。
UnpackZipArchive() メソッド
ディレクトリに現在のアーカイブのすべてのファイルとディレクトリを解凍します。
bool UnpackZipArchive(string folder, int file_common);
パラメータ
- [in] folder — 現在のアーカイブを解凍する必要があるフォルダ. アーカイブフォルダを作成する必要がない場合は、パラメータ""としてnull値を渡す必要があります。
- [in] file_common — この修飾子は、メタトレーダープログラムのファイル・システムのセクションで、要素を圧縮するために必要とされていることを示します。すべてのメタトレーダー5のターミナルに共通のファイルセクションで解凍を実行したい場合は、FILE_COMMONにこのパラメータを設定してください。
返り値
アーカイブ解凍が成功したらtrue、そうでない場合falseを返します。
Size() メソッド
バイト単位のアーカイブサイズを返します。
int Size(void);返り値
バイト単位のアーカイブのサイズ。
TotalElements() メソッド
アーカイブ内の要素の数を返します。アーカイブ要素は、ディレクトリまたは圧縮ファイルのいずれかになります。
int TotalElements(void);
返り値
アーカイブ内の要素の数。
AddFile() メソッド
現在のアーカイブに新しいZIPファイルを追加します。ファイルがアーカイブに追加される前に、CZipFileの形で提示し、事前に作成する必要があります。
bool AddFile(CZipFile* file);パラメータ
- [in] file — ZIPファイルは、アーカイブに追加.
返り値
アーカイブに追加することが成功したらtrue、そうでない場合false
DeleteFile() メソッド
アーカイブから、インデックスとファイルタイプのCZipFIleを削除します。
bool DeleteFile(int index);
パラメータ
- [in] index — ファイルのインデックスは、アーカイブから削除します.
返り値
アーカイブからファイルを削除した場合にはtrueそうでない場合false。
ElementAt() メソッド
インデックスにある要素型のCZipFileを取得します。
CZipContent* ElementAt(int index)const;
パラメータ
- [in] index — 持っているファイルインデックスは、アーカイブから取得します.
返り値
インデックスにあるCZipFile型素子。
4.4. ENUM_ZIP_ERRORの構造と拡張エラー情報の受け取り
存在しないファイルにアクセスしようとすると、CZipFileとCZipDirectoryに様々なエラーが発生する可能性があります. これらのクラスは、boolタイプのトランザクションの成功を伝えるフラグを返すクラス内で行われます。失敗した場合には負の値(false)を返しますが、失敗の理由に関する追加情報を取得することができます。失敗の原因として、ZIPアーカイブでの操作の過程で発生する、標準的なシステムエラーを特定することができます。エラーの特定にSetUserError関数で使用します。ユーザー・エラーのコードが列挙ENUM_ZIP_ERRORによって設定されます。
ENUM_ZIP_ERRORの転送
| 値 | 説明 |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | 圧縮のために転送されたファイルは、空白です。 |
| ZIP_ERROR_BAD_PACK_ZIP | 内部圧縮/伸張器のエラーが発生しました。 |
| ZIP_ERROR_BAD_FORMAT_ZIP | 転送されたZIPファイル形式は、標準に対応していないか破損しています。 |
| ZIP_ERROR_NAME_ALREADY_EXITS | ユーザが保存したいファイルの名前は、既にアーカイブに使用されます。 |
| ZIP_ERROR_BAD_URL | 転送されたリンクは、ZIPアーカイブを参照していない、または指定したWebリソースへのアクセスは、端末の設定によって禁止されています。 |
ユーザーエラーを受信すると、ENUM_ZIP_ERRORに応じて扱う必要があります。アーカイブクラスの動作の過程で発生するエラーの対策例のスクリプトは以下の通りです。
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf("ロードファイル中にシステムエラーが発生しました. Номер ошибки: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("荷重点でのアーカイブ処理中にエラーが発生しました: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
以下は、この記事に添付されたファイルの簡単な説明です。
- Zip\Zip.mqh — CZipアーカイブを操作するためのメインクラスが含まれています.
- Zip\ZipContent.mqh — CZipFileとCZipDirectory:アーカイブの要素の基本的なクラスのためのコアクラスのCZipContentが含まれています。
- Zip\ZipFile.mqh — ZIPアーカイブで動作するクラスが含まれています.
- Zip\ZipDirectory.mqh — アーカイブのZIPフォルダで動作するクラスが含まれています。
- Zip\ZipHeader.mqh — ファイルに、ファイルのローカルヘッダ、中央ディレクトリおよびエンドセントラルディレクトリレコード構造の記述が含まれています。
- Zip\ZipDefines.mqh — アーカイブクラスで使用される定義、定数およびエラー・コードを示しています.
- Dictionary.mqh — アーカイブに追加されたユニークなファイル名やディレクトリ名の制御する追加クラス。このクラスの動作アルゴリズムは、 MQL5クックブック "連想配列または迅速なデータアクセスのための辞書を実装するに記載されています。
この資料に記載されているすべてのファイルは、内部ディレクトリ<terminal_data_folder>\ MQL5\Includeに配置しなければなりません。クラスの使用するには、プロジェクト内のZip\Zip.mqhファイルを含める必要があります。例として、ZIPアーカイブを作成し、その中に"test"メッセージでテキストファイルを書き込むためのスクリプトを記述します:
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // ZIPアーカイブでの動作のために必要なすべてのクラスを含む //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // 空のZIPアーカイブを作成 uchar array[]; // 空のバイト配列を作成 StringToCharArray("test", array); // バイト配列に「テキスト」のメッセージを変換 CZipFile* file = new CZipFile("test.txt", array); // "test.txt"という名前の配列に基づいて、新しい「ファイル 'ZIPファイルを作成 Zip.AddFile(file); // ZIPアーカイブに作成した「ファイル 'ZIPファイルを追加 Zip.SaveZipToFile("Test.zip", FILE_COMMON); // ディスク上の「Test.zip」という名前のZIPアーカイブを保存 } //+------------------------------------------------------------------+
コンピュータのハードディスクの"test"と、1つのテキストファイルを含むTest.zipという名前の新しいZIPアーカイブが、上のパフォーマンスの後、メタトレーダー5中央のファイルディレクトリに表示されます。
| この文書に添付されているアーカイブが、ここで説明されるMQL5のためのCZipアーカイバによって作成されました。 |
|---|
結論
ZIPアーカイブの構造を検討している際、アーカイブのこの実装するクラスを作成しました。このようなアーカイブ形式は、前世紀の80年代後半に開発されたが、それは最も人気のあるデータ圧縮フォーマットとして残っています。これらのクラスのデータのセットは、取引システムの開発者に非常に貴重なサポートを提供することができます。その助けを借りて、効率的に、他の取引情報を収集し、データを保存することができます。多くの場合、様々な分析データも圧縮された形で提供されています。この場合には、さらに圧縮して、そのような情報を処理する能力も非常に有用です。
ここで説明されたクラスは多くの技術的な側面が隠れています。ユーザーのレベルに合った単純なオペレーションモデルから、特殊なプログラムをアーカイブするユーザーまで使えます。 :サードパーティ製のサーバを遠隔操作することも含め、あたらしいロード法にもなります。この機能はアーカイブに関連する問題の大半を解決し、より簡単に、より機能的なメタトレーダーでプログラミングを行うことができます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/1971
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 合同通貨の動きのフラクタル解析
合同通貨の動きのフラクタル解析
 遺伝的アルゴリズムー数学
遺伝的アルゴリズムー数学
 トレーダーキット:Drag Trader Library
トレーダーキット:Drag Trader Library
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
CZipが解凍できないアーカイブに出くわした。しかし、7ZIPとWindowsアーカイバは問題なく解凍できた。
...
もしご興味があれば、プライベートメッセージでアーカイブファイルをお送りします。プライベートメッセージでアーカイブファイルを送ってください。
プライベートメッセージでアーカイブファイルを送ってください。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-01-18_BTCUSDT_ob500.data.zip
ここで、アーカイブ本体(ヘッダーではなく)にcdheader = 0x504b0102があります;
次の日付のファイルにもあります。
header = 0x504b0304; がヘッダ、つまり最初の4文字でどのファイルにもある。
でも、まれにアーカイブ本体にもある。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-03-15_BTCUSDT_ob500.data.zip です。
これらのヘッダは、アーカイブ本体の間だけで探す必要があると思います。
また、正しく解凍できない大きなファイルへのリンクもあります。私はそれらのサイズを0に設定し、呼び出し側のプログラムはこの0によってエラーが発生し、別のアーカイバを使用する必要があることを理解します。
おそらく、0の代わりに何か良い方法を思いつくでしょう。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip
ある容量(1.7Gbから2136507776まで、つまりほぼMAX_INT=2147483647まで、配列はそれ以上の要素を持つことができない)を超え、出力時にカットされるファイル(解凍済み)を整理した。その結果、これらすべてが出力時にエラーとしてマークされることが判明した:
しかしCZIPはこれを制御できない。私は出力配列のサイズをゼロにした。
だから私の関数では、ファイルが正常に解凍されたかどうかを100%の保証で判断できる。
その前に、JSONファイルの末尾が正しいかどうかをチェックした。しかし、この解決策は万能ではなく、~1000個のファイルのうち、いくつかのファイルが誤って中間行で切断され、正常に解凍されたものとして受け入れられたが、その中のデータは完全ではなかったようだ。
関数の新バージョン:
新しいものは黄色で ハイライトされている。
トリミングされたデータはほとんど誰にも必要とされないので、開発者は配列もゼロにリセットすべきかもしれない。そして、見えにくいエラーにつながるかもしれない。
そして、正しく解凍できない大きなファイルへのリンクもある。私はそれらのサイズを0に設定し、呼び出し側のプログラムはこの0によってエラーが発生し、別のアーカイバを使用する必要があることを理解します。
おそらく、0の代わりに何か良い方法を思いつくでしょう。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip