
Die Arbeit mit ZIP-Archiven in MQL5 ohne Bibliotheken von Drittanbietern

Inhaltsverzeichnis
- Einführung
- Kapitel 1. Das Format der ZIP-Datei und die Art der Datenspeicherung
- Kapitel 2. Der Überblick über die Klasse CZIP und ihre Algorithmen
- Kapitel 3. Die beispielhafte Verwendung der Klasse CZIP, Leistungsmessung
- Kapitel 4. Die Dokumentation für Klassen mit ZIP-Archiven
- Fazit
Einführung
Die Geschichte hinter dem Motiv
Eines Tages hat der Autor dieses Artikels die Besonderheit der Funktion CryptDecode interessant bekommen, und eben - die Möglichkeit das ZIP-Array zu entpacken. Dieser Modifier wurde von den Entwicklern des MetaTrader 5-Plattforms eingefügt, um die Antworten von einigen Servern unter Verwendung der standard Funktion WebRequest zu entpacken. Jedoch aufgrund bestimmter Besonderheiten des ZIP-Datei-Formats, war es unmöglich, sie direkt zu verwenden.
Es wurde die zusätzliche Authentifizierung erfordert: um ein Archiv zu entpacken, war es erforderlich, seine Hash-Summe zu wissen, bevor Adler-32 gepackt wurde, der eindeutig nicht zur Verfügung stand. Jedoch bei der Diskussion dieses Problems trafen die Entwickler die Anforderung und starten die CryptDecode und CryptEncode mit einer speziellen Flagge neu,(ihr gleicher Zwilling), welche den Hach Adler32 bei dem übertragenen Daten-Entpacken ignoriert. Für aus technischer Sicht unerfahrene Benutzer könnte diese Innovation leicht erklärt werden: es ermöglicht die volle Funktionalität mit ZIP-Archiven. Dieser Artikel beschreibt das ZIP-Format und dessen Besonderheiten der Datenspeicherung. Es bietet noch eine komfortable objektorientierte Klasse CZIP mit einem Archiv an.
Warum braucht man das?
Die Datenkomprimierung ist eine der wichtigsten Technologien, die besonders in der Web-Welt verbreitet ist. Die Komprimierung ermöglicht Ressourcen zu behalten, die für die Übertragung nötig sind, auch Speicherung und Verarbeitung der Daten zu speichern. Die Datenkomprimierung wurde praktisch in allen Bereichen der Kommunikation verwendet und hat fast alle Computer-bezogenen Aufgaben erreicht.
Der Finanzsektor ist auch keine Ausnahme: die gigabyte Tick-History, riese Menge von Notierungen, einschließlich Markttiefe (Level2-Daten) können nicht in einem rohen, unkomprimierten Form gespeichert werden. Viele Server, einschließlich derjenigen, die die interessanten analytischen Informationen für das Handeln herstellen, speichern ihre Daten auch in ZIP-Archiven. Bisher war es nicht möglich, diese Informationen automatisch mit standarden Mitteln von MQL5 zu behalten. Jetzt hat sich die Situation geändert.
Mit der WebRequest-Funktion können Sie ein ZIP-Archiv herunterladen und sofort auf dem Computer dekomprimieren. Alle diese Eigenschaften sind wichtig und werden auf jeden Fall von vielen Händlern erfordert. Die Datenkomprimierung kann auch zur Optimierung des RAMs verwendet werden. Wie das gemacht wird, werden wir im Kapitel 3.2 dieses Artikels beschreiben. Schließlich gibt die Möglichkeit, mit ZIP-Archiven den Zugriff auf die Dokument-Bildung wie Microsoft Office nach dem Standard Office Open XML herzustellen, das ermöglicht, Dateien aus Excel oder Word direkt von MQL5 zu erstellen, auch ohne Verwendung dritten DLL-Bibliotheken.
Wie Sie sehen können, ist die Anwendung des ZIP-Archivs umfangreich, und von uns erstellte Klasse wird allen MetaTrader-Benutzern gut dienen.
Im ersten Kapitel dieses Artikels werden wir ein Format einer ZIP-Datei beschreiben und bekommen Vorstellung davon, von welchen Daten-Blöcken das enthält. In diesem Kapitel wird nicht nur für diejenigen interessant sein, die MQL studieren, es kann auch als ein gutes Unterrichtsmaterial für diejenigen interessant sein, die sich mit der Archivierung und Datenspeicherung gründlich beschäftigt. Das zweite Kapitel befasst sich mit den Klassen CZIP, CZipFile und CZipDirectory, die sind die wichtigsten objektorientierte Elemente, die mit Archiven funktionieren. Das dritte Kapitel beschreibt praktische Beispiele, die im Zusammenhang mit der Verwendung der Archivierung betrachtet. Und das vierte Kapitel enthält die Dokumentation zu den vorgeschlagenen Klassen zusammen.
Also, lassen Sie uns die am häufigsten verbreiteten Archivierungsart lernen.
Kapitel 1. Das Format der ZIP-Datei und die Art der Datenspeicherung
1.1. Die Struktur der ZIP-Datei
Das ZIP-Format wurde von Phil Katz im Jahr 1989 erstellt und wurde erstmal im Programm PKZIP für MS-DOS realisiert, das von der Firma PKWARE veröffentlicht wurde, dessen Begründer Katz war. Dieses Format der Archivierung verwendet am häufigsten den Datenkompressionsalgorithmus DEFLATE. Die am häufigsten verwendeten Programme in Windows arbeiten mit diesem Format, das sind WinZip und WinRAR.
Es ist wichtig zu verstehen, dass das ZIP-Archiv-Format im Laufe der Zeit entwickelt wurde und hat mehrere Versionen. Um eine Klasse mit einem ZIP-Archiv zu erstellen, werden wir auf der offiziellen Format-Spezifikation der Version 6.3.4 arbeiten, die auf der Unternehmens-Website PKWARE platziert ist: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT Dies ist die neueste Format-Spezifikation vom 1. Oktober 2014. Die Format-Spezifikation ist ziemlich umfangreich und enthält Beschreibungen von zahlreichen Nuancen.
In diesem Artikel werden wir von dem Prinzip des geringsten Aufwands ausgehen und erstellen ein Werkzeug, das nur die notwendigen Daten für eine erfolgreiche Dateiextrahierung und die Erstellung neuer Archive verwendet. Dies bedeutet, dass die Arbeit mit ZIP-Dateien zu einem gewissen Grad eingeschränkt wird - die Formatkompatibilität wird nicht garantiert, und das heißt, es gibt dann keinen Sinn, über die komplette "omnivory" der Archiven zu reden. Es besteht die Möglichkeit, dass einige ZIP-Archive, die von drittmitteln erstellt wurden, können nicht durch das vorgeschlagene Werkzeug extrahiert werden.
Jedes ZIP-Archiv ist eine binäre Datei, die eine geordnete Folge von Bytes enthält. Auf der anderen Seite hat jede Datei von einem ZIP-Archiv einen Namen, Attribute (wie Dateiänderungszeit) und andere Eigenschaften, die wir normalerweise in einem Dateisystem jedes Betriebssystems sehen. Von daher wird jedes ZIP-Archiv mit komprimierten Daten noch zusätzlich den Namen einer komprimierten Datei, deren Attribute und andere Serviceinformationen speichern. Die Dienstinformation wird in einer ganz bestimmten Art und Weise angeordnet und hat eine regelmäßige Struktur. Zum Beispiel, wenn ein Archiv zwei Dateien (File#1 и File#2) enthält, dann wird das Archiv das folgende Schema haben:
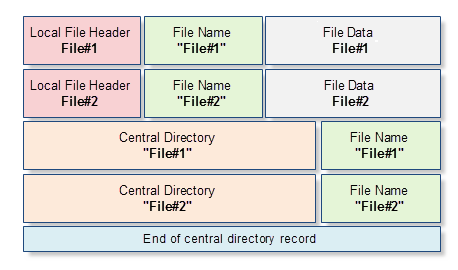
in Abb. 1. Die schematische Darstellung eines ZIP-Archivs, das zwei Dateien enthält: File#1 und File#2
Später werden wir jeden Block von diesem Schema untersuchen, aber momentan geben wir nur eine kurze Beschreibung aller Blöcke:
- Local File Header — dieser Datenblock enthält grundlegende Informationen über die komprimierte Datei: die Dateigröße vor und nach der Kompression, die Dateiänderungszeit, CRC-32-Prüfsumme und lokale Zeiger auf den Namen der Datei. Außerdem enthält dieser Block die Archivierungs-Version, die für das Entpacken der Datei notwendig ist.
- File Name — eine Bytes-Folge mit beliebiger Länge, die den komprimierten Datei-Namen bildet. Die Länge des Datei-Namens sollte nicht länger als 65 536 Zeichen sein.
- File Data — ist ein komprimierter Datei-Inhalt in Form einer beliebigen Länge Byte-Array. Wenn die Datei leer ist oder ein Verzeichnis enthält, dann wird dieses Array nicht verwendet, und direkt nach dem Datei-Namen oder dem Verzeichnis wird der Titel Local File Header beschrieben.
- Central Directory — enthält die erweiterte Datenansicht in Local File Header. Zusätzlich zu den Daten, die Local File Header enthält, hat die Dateiattribute, einen lokalen Link auf die Struktur der Local File Header und andere nicht genutzte Informationen.
- End of central directory record — diese Struktur wird als eine einzelne Instanz in jedem Archiv präsentiert und wird am Archivsende geschrieben. Die interessantesten Daten, die er enthält, ist eine Anzahl der Aufnahmen im Archiv (oder die Anzahl der Dateien und Verzeichnissen) und lokale Links auf den Anfang des Blocks Central Directory.
Jeder Block dieses Schemas kann entweder als regelmäßige Struktur dargestellt werden, oder als beliebiger Länge Byte-Array. Jede Struktur kann mit einer Programmierung-Konstruktion beschrieben werden, die den gleichen Namen in MQL hat - Struktur
Die Struktur nimmt immer eine feste Anzahl der Bytes, deshalb enthält es keine beliebige Länge Arrays und Linien. Jedoch kann sie einen Zeiger zu diesen Objekten haben. Deswegen werden die Dateinamen im Archiv außerhalb der Struktur angeordnet, so dass sie eine beliebige Länge haben können. Das gleiche gilt für die komprimierten Datendateien - ihre Größe ist beliebig, deshalb werden sie auch außerhalb der Strukturen gehalten. Auf diese Weise können wir sagen, dass ein ZIP-Archiv durch die Abfolge von Mustern, Linien und komprimierten Daten kennzeichnet.
Dias ZIP-Datei-Format beschreibt zu der oben genannten Struktur noch eine zusätzliche Struktur, die sogenannte Data Descriptor. Diese Struktur wird nur in dem Fall verwendet, wenn die Struktur von Local File Header aus irgendwelchem Grund nicht hergestellt werden kann, und der Anteil der benötigten Daten für Local File Header wird erst nach der Datenkompression zur Verfügung stehen. In der Praxis ist es eine seltene Situation, deshalb wird diese Struktur praktisch nie benutzt, und in unserer Klasse mit Archiven wird dieser Datenblock nicht unterstützt.
| Bitte beachten Sie, dass nach dem ZIP-Archiv-Format jede Datei aus dem Rest separat komprimiert wird. Einerseits ermöglicht es, das Auftreten der Fehler zu lokalisieren: ein "gebrochenes" Archiv kann man wiederherstellen, dafür muss man die Dateien mit falschem Inhalt löschen und den restlichen Inhalt ohne Änderungen im Archiv lassen. Andererseits wird bei jeder Datei während der Komprimierung ihr Kompressionseffizienz verringern, insbesondere wenn jede von Dateien wenig Platz besitzt. |
|---|
1.2. Lernen wir die ZIP-Datei in einem Hexadezimal-Editor
Nun ausgerüstet mit dem nötigen Wissen können wir sehen, was in einem typischen ZIP-Archiv ist. Um dies zu tun, werden wir einen Hexadezimal-Editor WinHex verwenden. Wenn Sie aus irgendwelchem Grund noch keine WinHex haben, können Sie einen anderen Hexadezimal-Editor verwenden. Denn wir wissen noch, dass jedes Archiv eine binäre Datei ist, die als eine einfache Folge von Bytes geöffnet werden kann. Als Experiment erstellen wir ein einfaches ZIP-Archiv, das eine einzelne Textdatei mit einem Satz "HelloWorld!" enthält:

in Abb. 2. Die Erstellung einer Textdatei in Notepad
Dann werden wir alle ZIP-Archiver verwenden, und dadurch erstellen wir ein Archiv. In unserem Fall wird WinRAR ein solcher Archiver sein. Es ist notwendig, in ihm die neu erstellte Datei auszuwählen und im ZIP-Format zu archivieren:
in Abb. 3. Die Erstellung eines Archivs mit WinRAR-Archiver
Nachdem die Archivierung auf der Festplatte des Computers beendet, wird eine neue Datei "HelloWorld.zip" in dem entsprechenden Verzeichnis erscheinen. Die erste auffällige Besonderheit dieser Datei ist, dass seine Größe 135 Bytes ist, das ist wesentlich größer als die Quelltextdatei mit 11 Bytes. Dies kommt von der Tatsache, dass das ZIP-Archiv neben den komprimierten Daten, auch Service-Informationen enthält. Deshalb ist die Archivierung für kleine Datenmengen sinnlos, die nur ein paar hundert Bytes besetzen.
Nun, haben wir das Daten-Schema und das Archiv aus einer Reihe von Bytes scheint uns nicht mehr so erschreckend. Öffnen wir ihn mit einem Hex-Editor WinHex. Die folgende Abbildung zeigt das Byte-Array des Archivs mit einer bedingten Hervorhebung jeder Bereiche, welche im Schema 1 beschrieben wurden:
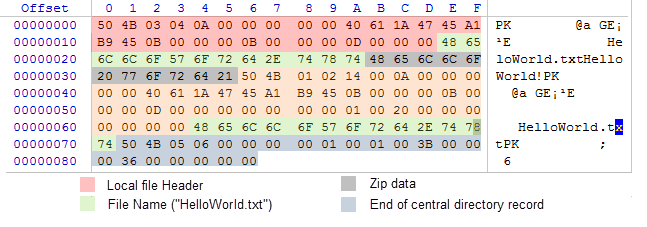
in Abb. 4. Der interne Inhalt von ZIP-Archiv mit der Datei HelloWorld.txt
Eigentlich der Begriff "Hello World!" ist im Bereich von 0x35 bis 0x2B Bytes enthalten und besitzt nur 11 Bytes. Bitte beachten Sie, dass der Komprimierungsalgorithmus die ursprüngliche Phrase nicht kompiliert hat, und in dem ZIP-Archiv ist sie in ihrer ursprünglichen Form. Dies geschah, weil die Kompression solcher Kurznachricht ineffizient ist, und das komprimierte Array kann größer als das unkomprimierte Array sein.
| ZIP-Archiv enthält nicht immer die komprimierten Daten. Manchmal werden die archivierten Daten in ursprünglicher, nicht komprimierter Form zugeordnet, auch wenn es bei der Erstellung der Archivierung deutlich angegeben wurde, die Daten bei der Archivierung zu komprimieren. Diese Situation entsteht, wenn die Datenmenge unbedeutend ist, und die Datenkompression ist ineffizient. |
|---|
Wenn man sich das Bild 4 anschaut, wird deutlich, wie verschiedene Datenblöcke in einem komprimierten Archiv gespeichert werden, und wo die Daten der Datei genau halten. Jetzt ist es die Zeit, jeden Datenblock einzeln zu analysieren.
1.3. Die Struktur der Local File Header
Jedes ZIP-Archiv beginnt mit der Struktur Local File Header. Sie enthält Metadaten einer Datei, die als komprimiertes Byte-Array folgt. Jede Struktur eines Archivs hat nach der Formatspezifikation seinen einzigartigen Vier-Byte-Identifikator. Diese Struktur ist keine Ausnahme, ihr eindeutiger Identifikator ist 0x04034B50.
Sie sollten berücksichtigen, dass die x86-basierten Prozessoren aus den binären Dateien in den RAM in umgekehrter Reihenfolge geladen werden. Die Zahlen werden dabei andersrum zugeordnet: das letzte Byte wird an der Stelle des ersten Bytes und umgekehrt. Ein Verfahren des Daten-Schreibens in der Datei wird von dem Datei-Format bestimmt und für die ZIP-Dateien wird es auch in umgekehrter Reihenfolge durchgeführt. Die weitere Informationen über die Byte-Reihenfolge können Sie auf Wikipedia im Artikel: "Byte-Reihenfolge" lesen. Für uns bedeutet es allerdings, dass der Strukturidentikator als Zahl 0x504B0304 (von innen nach außen 0x04034b50 vorgegeben) geschrieben wird. Jedes ZIP-Archiv beginnt mit dieser Byte-Reihenfolge.
Da die Struktur eine streng definierte Byte-Reihenfolge ist, kann es als eine ähnliche Struktur in MQL5-Programmiersprache dargestellt werden. Die Beschreibung der Local File Header-Struktur in MQL5 ist die folgende:
//+------------------------------------------------------------------+ //| Local file header based on specification 6.3.4: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // ZIP local header, always equals 0x04034b50 ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compression method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC-32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
Diese Struktur ist für die reale Arbeit mit ZIP-Archiven, deswegen enthält es so neben dem Datenfeld noch die zusätzlichen Verfahren, die die Konvertierung der Struktur in eine Reihe von Bytes (Das Byte-Array uchar) ermöglicht und umgekehrt, eine Struktur von den Bytes-Sätzen zu erstellen. Hier sind die Inhalte von den Methoden ToCharArray und LoadFromCharArray, die eine solche Umwandlung ermöglichen:
//+------------------------------------------------------------------+ //|Private struct for convert LocalHeader to uchar array | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // Size of ZipLocalHeader }; //+------------------------------------------------------------------+ //| Convert ZipHeader struct to uchar array. | //| RETURN: | //| Numbers of copied elements. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| Init local header structure from char array | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
Lassen Sie uns die Felder der Struktur (in der Reihenfolge) beschreiben:
- header — das einzigartige Identifikator der Struktur, für File Local Header entspricht 0x04034B50;
- version — die Mindestversion für das Entpacken der Datei;
- bit_flag — Der Byte-Flag hat den Identifikator 0x02;
- comp_method — Der Typ der verwendeten Kompression. Normalerweise wird immer das Komprimierungsverfahren DEFLATE mit dem Identifikator 0x08 verwendet.
- last_mod_time — die Zeit der letzten Modifizierung der Datei. Es enthält Stunden, Minuten und Sekunden der Modifizierung der Datei im MS-DOS-Format. Dieses Format wird auf den Microsoft-Unternehmen Web-Seite beschrieben.
- last_mod_date — die Zeit der letzten Modifizierung der Datei. Es enthält den Tag im Monat, den Monat im Jahr und das Jahr der Modifizierung der Datei im MS-DOS-Format.
- crc_32 — die Prüfsumme CRC-32. Es wird von den Programmen im Zusammenhang mit Archiven verwendet, welche Fehler in Dateiinhalten finden. Wenn dieses Feld nicht gefüllt ist, wird das ZIP-Archiver weigern, die komprimierte Datei unter Bezugnahme auf die beschädigte Datei zu entpacken.
- comp_size — die Größe der komprimierten Daten in Byte;
- uncomp_size — die Größe der Anfangsdaten in Bytes;
- filename_length — Die Länge des Datei-Namens;
- extrafield_length — Das Spezialgebiet, um die zusätzlichen Datenattribute zu schreiben. Es wird fast nie verwendet und ist gleich Null.
Wenn diese Struktur gespeichert wird, dann wird im Archiv eine Reihenfolge von Bytes erstellt, welche die Werte der entsprechenden Felder dieser Struktur hält. Wir werden unser ZIP-Archiv mit der Datei HelloWorld.txt an den Hex-Editor laden, und analysieren das Byte-Array dieser Struktur gründlich:

in Abb. 5. Das Byte-Schema der Struktur Local File Header im Archiv HelloWorld.zip
Das Chart zeigt, welche Bytes, in welchen Struktur-Feldern ausgefüllt sind. Um die seine Daten zu überprüfen, geben wir Acht auf das Feld "File Name length", es besetzt 2 Bytes und ist dem Wert 0x0D00 gleich. Durch Drehen dieser Zahl von innen nach außen und durch die Wandlung im Dezimalformat erhalten wir den Wert 13 - so viele Symbole besitzt der Datei-Name "HelloWorld.txt". Das gleiche kann man mit dem Feld durchführen, das die Größe von komprimierten Daten anzeigt. Es ist 0x0B000000, was zu 11 Byte entspricht. In der Tat, Die Phrase "Hello World!" wird im Archiv unkomprimiert gespeichert und besitzt 11 Bytes.
Die Struktur wird durch die komprimierten Daten gefolgt, und dann wird die neue Struktur beginnen - Central Directory, die im nächsten Kapitel mehr in Details betrachtet wird.
1.4. Die Struktur der Central Directory
Die Struktur Central Directory enthält die erweiterte Datenansicht in Local File Header. In der Tat sind die Daten aus Local File Header ausreichend, um grundlegend mit ZIP-Archiven zu arbeiten. Allerdings ist die Verwendung von Central Directory unbedingt und sein Wert muss korrekt ausgefüllt werden. Diese Struktur hat seinen eindeutigen Identifikator 0x02014B50. In MQL5 wird sie folgendermaßen dargestellt:
//+------------------------------------------------------------------+ //| Central directory structure | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // Central directory header, always equals 0x02014B50 ushort made_ver; // Version made by ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compressed method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data ushort file_comment_length; // Length of comment file ushort disk_number_start; // Disk number start ushort internal_file_attr; // Internal file attributes uint external_file_attr; // External file attributes uint offset_header; // Relative offset of local header bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
Wie Sie sehen können, enthält es bereits mehr Daten, aber die meisten von ihnen doppelten Daten von Local File Header. Genau wie seine früheren Struktur, sie enthält Service-Methoden, um seinen Inhalt zu einem Byte-Array umzuwandeln und umgekehrt.
Lassen Sie uns ihre Felder beschreiben:
- header — das einzigartige Identifikator der Struktur ist 0x02014B50;
- made_ver — die Archivierung-Standardversion, die bei der Archivierung verwendet wird;
- version — die Mindestversion für das Entpacken der Datei;
- bit_flag — Der Byte-Flag hat den Identifikator 0x02;
- comp_method — Der Typ der verwendeten Kompression. Normalerweise wird immer das Komprimierungsverfahren DEFLATE mit dem Identifikator 0x08 verwendet.
- last_mod_time — die Zeit der letzten Modifizierung der Datei. Es enthält Stunden, Minuten und Sekunden der Modifizierung der Datei im MS-DOS-Format. Dieses Format wird auf den Microsoft-Unternehmen Web-Seite beschrieben.
- last_mod_date — die Zeit der letzten Modifizierung der Datei. Es enthält den Tag im Monat, den Monat im Jahr und das Jahr der Modifizierung der Datei im MS-DOS-Format.
- crc_32 — die Prüfsumme CRC-32. Es wird von den Programmen im Zusammenhang mit Archiven verwendet, welche Fehler in Dateiinhalten finden. Wenn dieses Feld nicht gefüllt ist, wird das ZIP-Archiver weigern, die komprimierte Datei unter Bezugnahme auf die beschädigte Datei zu entpacken.
- comp_size — die Größe der komprimierten Daten in Byte;
- uncomp_size — die Größe der Anfangsdaten in Bytes;
- filename_length — Die Länge des Datei-Namens;
- extrafield_length — Das Spezialgebiet, um die zusätzlichen Datenattribute zu schreiben. Es wird fast nie verwendet und ist gleich Null.
- file_comment_length — Die Länge der Dateikommentare;
- disk_number_start — Die Nummer eines Datenträgers, auf dem das Archiv geschrieben wird. Fast immer gleich Null ist.
- internal_file_attr — die Dateiattribute im MS-DOS-Format;
- external_file_attr — die erweiterte Dateiattribute im MS-DOS-Format;
- offset_header — die Adresse, wo der Anfang der Local File Header-Struktur ist.
Wenn diese Struktur gespeichert wird, dann wird im Archiv eine Reihenfolge von Bytes erstellt, welche die Werte der entsprechenden Felder dieser Struktur hält. Hier ist das Byte-Schema in dieser Struktur, wie in Abbildung 5:

in Abb. 6. Das Byte-Schema der Struktur Central Directory im Archiv HelloWorld.zip
Anders als Local File Header stehen die Central Directory-Strukturen in einer fortlaufenden Reihenfolge zur Verfügung. Die Anfangsadresse, vom ersten ist in dem speziellen endgültigen Datenblock angegeben - ECDR Struktur. Diese Struktur beschreiben wir im nächsten Kapitel.
1.5. Die Struktur der End of Central Directory Record (ECDR)
Die Struktur End of Central Directory Record (oder einfach ECDR) schließt eine ZIP-Datei. ihr eindeutiger Identifikator ist 0x06054B50. Sie wird in jedem Archiv in einziger Kopie enthalten. ECDR hält eine Anzahl der Dateien und Verzeichnissen, die im Archiv sind, sowie die Adresse der Reihenfolge der Struktur zCentral Directory und ihre Gesamtgröße. Darüber hinaus speichert der Datenblock auch andere Informationen. Hier ist eine vollständige Beschreibung von ECDR auf MQL5:
//+------------------------------------------------------------------+ //| End of central directory record structure | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // Header of end central directory record, always equals 0x06054b50 ushort disk_number; // Number of this disk ushort disk_number_cd; // Number of the disk with the start of the central directory ushort total_entries_disk; // Total number of entries in the central directory on this disk ushort total_entries; // Total number of entries in the central directory uint size_central_dir; // Size of central directory uint start_cd_offset; // Starting disk number ushort file_comment_lengtt; // File comment length string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
Lassen Sie uns die Felder der Struktur beschreiben:
- header — das einzigartige Identifikator der Struktur ist 0x06054B50;
- disk_number — Die Nummer des Datenträgers;
- disk_number_cd — Die Nummer eines Datenträgers, von dem das Archiv Central Directory beginnt;
- total_entries_disk — die Gesamtzahl der Einträge im Central Directory (die Anzahl der Dateien und Verzeichnisse);
- total_entries — die Gesamtzahl der Einträge (die Anzahl der Dateien und Verzeichnisse);
- size_central_dir — die Größe des Central Directory;
- start_cd_offset — Die Byte-Adresse am Anfang des Central Directory;
- file_comment_length — Die Länge der Dateikommentaren zum Archiv.
Wenn diese Struktur gespeichert wird, dann wird im Archiv eine Reihenfolge von Bytes erstellt, welche die Werte der entsprechenden Felder dieser Struktur hält. Hier ist das Byte-Schema in dieser Struktur:

in Abb. 7. Das Byte-Schema der Struktur ECDR
Wir werden diesen Datenblock verwenden, um eine Anzahl von Elementen im Array zu bestimmen.
Kapitel 2. Der Überblick über die Klasse CZIP und ihre Algorithmen
2.1. Die Struktur der komprimierten Dateien im Archiv, die Klassen CZipFile und CZipFolder
Also, im ersten Kapitel haben wir das Format eines ZIP-Archivs erklärt. Wir haben betrachtet, aus welchen Typen von Daten er besteht, und beschrieben diesen Typen in den entsprechenden Strukturen. Nachdem diese Typs definiert wurden, werden wir die hochwertige Spezialklasse CZip realisieren, mit der man die folgenden Aktionen mit ZIP-Archiven schnell und einfach durchführen kann:
- Die Erstellung eines neuen Archivs;
- So öffnen Sie ein zuvor erstelltes Archiv auf einer Festplatte;
- Das Archiv von einem Remote-Server herunterladen;
- So fügen Sie neue Dateien zum Archiv hinzu;
- Die Löschung der Dateien aus dem Archiv;
- Das Entpacken eines Archivs komplett oder seine Dateien.
Die CZIP Klasse kann verwendet werden, um die notwendigen Strukturen im Archiv zu vervollständigen, die übliche High-Level-Schnittstelle stellt uns die Dateiarchivsammlung zur Verfügung. Die Klasse bietet vielfältige Möglichkeiten für die meisten Aufgaben zur Archivierung im Zusammenhang an.
Offensichtlich kann der Inhalt eines ZIP-Archivs in Ordnern und Dateien aufgeteilt werden. Beide Typen von Inhalten haben eine umfangreiche Reihe Eigenschaften: Name, die Größe, Dateiattribute Dateien, die Zeit der Erstellung usw Einige dieser Eigenschaften sind gemeinsam, sowie für Ordner, auch für Dateien, und einige, wie z.B komprimierte Daten, sind es nicht. Die optimale Lösung für Archive wären spezielle Serviceklassen: CZipFile und CZipDirectory. Diese speziellen Klassen werden Dateien und Ordner zur Verfügung stellen. Die bedingte Klassifizierung des Archivsinhalts wird unten auf dem Schema dargestellt:
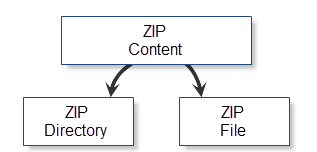
in Abb. 8. Die bedingte Klassifizierung der Archivobjekte
So eine Datei zum CZIP-Archiv hinzuzufügen, müssen Sie zunächst ein Objekt des Typs von CZipFile erstellen, und dann diese Objektdatei zum Archiv hinzufügen. Als Beispiel werden wir eine Textdatei "HelloWorld.txt" erstellen, die den gleichen Namen Text "HelloWorld!" enthält, und fügen Sie ihn zum Archiv:
//+------------------------------------------------------------------+ //| Create file with 'HelloWorld' message | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // Wir erstellen ein leeres ZIP-Archiv uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // Schreiben wir einen Satz "Hello World!" im Byte-Array CZipFile* file = new CZipFile("HelloWorld.txt",content); // Erstellen eine ZIP-Datei mit dem Namen "HelloWorld.txt" // Das enthält ein Byte-Array "HelloWorld!" zip.AddFile(file); // Fügen wir die ZIP-Datei zum Archiv zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // Wir speichern das Archiv auf einer Festplatte und nennen es "HelloWorld.zip" printf("Size: "+(string)zip.Size()); }
Nach dem Ausführen des Codes wird auf der Festplatte des Computers ein neues ZIP-Archiv erscheinen, das eine einzelne Textdatei "HelloWorld.txt" mit der gleichen Phrase enthält. Wenn wir einen Ordner statt einer Datei erstellen wollen, dann müssten wir statt CZipFile eine Kopie der Klasse CZipFolder erstellen. Zu diesem Zweck wäre ausreichend, nur seinen Namen einzugeben.
Wie es bereits erwähnt wurde, haben die Klassen CZipFile und CZipFolder viel gemeinsam. Daher werden beide Klassen von ihrem gemeinsamen Vorfahren geerbt — CZipContent. Diese Klasse enthält die allgemeinen Methoden und Daten für die Arbeit mit dem Inhalt des Archivs.
2.2. Die Erstellung der komprimierten Dateien mit CZipFile
Eine Erstellung einer komprimierten ZIP-Datei ist identisch mit der Erstellung einer Kopie von CZipFile. Wie bereits bekannt ist, um eine Datei zu erstellen, müssen Sie den Namen und Inhalt eingeben. Von daher erfordert CZipFile auch eine explizite Angabe auf die entsprechenden Parameter:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
Im Abschnitt 2.1 wird der Aufruf dieses Konstruktors gezeigt.
Zusätzlich dazu, ist es manchmal nicht erforderlich, eine Datei zu erstellen, sondern muss man eine vorhandene Datei von einer Festplatte laden. Für diesen Fall gibt es einen zweiten Konstruktor in der Klasse CZipFile, die die Erstellung eine ZIP-Datei auf Basis einer normalen Datei auf der Festplatte ermöglicht:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
Alle Arbeiten in diesem Konstruktor werden auf die private Methode AddFile delegiert. Sein Algorithmus ist der folgende:
- Die angegebene Datei wird zum Lesen geöffnet, sein Inhalt wird in einem Byte-Array abgelesen.
- Das erhaltende Byte-Array wird unter Verwendung des Verfahrens AddFileArray komprimiert und wird in einem speziellen dynamischen Array des Typs uchar gespeichert.
Die Methode AddFileArray ist das "Herz" des gesamten Klassensystems für die Arbeit mit Archiven. Schließlich hat dieses Verfahren die wichtigste Systemfunktion— CryptEncode. Hier ist der Quellcode dieser Methode:
//+------------------------------------------------------------------+ //| Add file array and zip it. | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
Die Konfiguration der Funktion CryptEncode wird mit Gelb markiert und es wird anschließend mit einem Byte-Arrays archiviert. So können wir feststellen, dass das Datei-Komprimieren an der Stelle der Erzeugung des Objekts CZipFile auftritt, und nicht bei der Erstellung oder Erhaltung des ZIP-Archivs selbst. Aufgrund dieser Eigenschaft werden alle Daten, die an die CZIP Klasse übertragen werden, automatisch komprimiert und somit erfordern weniger Speicher für ihre Lagerung.
Bitte beachten Sie, dass es in allen Fällen als Daten der zeichenlose Byte-Array uchar verwendet wird. In der Tat, alle Daten, die wir auf einem Computer betrieben, können als eine bestimmte Byte-Reihenfolge dargestellt werden. Von daher für die Erzeugung einen wirklich universellen Behälter für komprimierte Daten als die CZipFile tatsächlich ist, wurde das zeichenlos Array uchar ausgewählt.
| Der Benutzer muss Daten selbst für die Archivierung in das zeichenlos Array uchar [] konvertieren, was wiederum über eine Reihenfolge als der Dateiinhalte für die CZipFile-Klasse übergeben werden muss. Wegen dieser Funktion absolut jede Art von Dateien, die entweder von der Festplatte heruntergeladenen wurde oder während des Prozess vom MQL-Programm erstellt wurde, kann in einem ZIP-Archiv zugeordnet werden. |
|---|
Das Entpacken der Daten ist eine triviale Aufgabe. Zum Entpacken der Daten ins ursprüngliche Byte-Array file_array wird das Verfahren GetUnpackFile verwendet, die im wesentlichen ein Wrapper-Verfahren zur Systemfunktion CryptDecode ist:
//+------------------------------------------------------------------+ //| Get unpack file. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. Erinnern wir uns an MS-DOS. Zeit- und Datumsformat im ZIP-Archiv
Das ZIP-Format der Datenspeicherung wurde in den späten 80er Jahren des letzten Jahrhunderts für die MS-DOS-Plattform erstellt, deren "Rechtsnachfolger" Windows geworden ist. Damals wurden die Mittel für die Datenspeicherung beschränkt, so Datum und die Zeit des MS-DOS-Betriebssystems wurden separat gespeichert: zwei Bytes (oder ein Wort für 16-Bit-Prozessoren dieser Zeit) wurden für das Datum und zwei Bytes wurden für die Zeit zugeordnet. Darüber hinaus war das früheste Datum der 1. Januar 1980 (01.01.1980), das von diesem Format dargestellt werden könnte. Die Minuten, Stunden, Tage, Monate und Jahre besetzten bestimmte Bytebereichen in einem Wort, und Daten zu extrahieren oder zu schreiben ist es immer noch erforderlich auf die Byte-Operationen zurückzugreifen.
Die Spezifikation dieses Formats steht auf der Microsoft-Website unter folgendem Link zur Verfügung: https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx.
Hier ist das Datenspeicherformat im entsprechenden Zwei-Byte-Feld:
| № Bytes | Beschreibung |
|---|---|
| 0-4 | Der Tag des Monats (0-31) |
| 5-8 | Die Nummer des Monats(1 — Januar, 2 — Februar u.s.w.) |
| 9-15 | Die Nummer des Jahres von 1980 |
Tabelle 1. Das Format der Datenspeicherung im zwei-Byte-Feld
Hier ist das Zeitspeicherformat im entsprechenden Zwei-Byte-Feld:
| № Bytes | Beschreibung |
|---|---|
| 0-4 | Sekunden (Lagergenauigkeit +/- 2 Sekunden) |
| 5-10 | Minuten (0-59) |
| 11-15 | Die Zeit im 24-Stunden-Format |
Tabelle 2. Das Format der Zeitspeicherung im zwei-Byte-Feld
Wenn man die Spezifikation dieses Formats kennt und in der Lage, mit Byte-Operationen zu arbeiten, dann kann man die entsprechenden Funktionen schreiben, die das Datum und die Zeit vom MQL-Format ins MS-DOS-Format konvertiert. Es ist auch möglich, umgekehrte Verfahren zu schreiben. Solche Verfahren der Konversation sind für Ordner gleich, so gut für die dargestellten CZipFolder auch für die Dateien, die von CZipFile dargestellt sind. So stellen wir die Daten und die Zeit für sie im üblichen MQL-Format ein und wir können diese Art von Daten ans MS-DOS-Format "hinter den Kulissen" konvertieren. Die Methoden DosDate, DosTime, MqlDate und MqlTime sind mit einer solchen Konversation beteiligt. Lass uns ihren Quellcode unten schreiben.
Die Datenkonvertierung vom MQL-Format zu MS-DOS-Datenformat:
//+---------------------------------------------------------------------------------+ //| Get data in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::RjyDosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
Die Datenkonvertierung vom MQL-Format zu MS-DOS-Datenformat:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
Die Zeitkonvertierung vom MQL-Format zu MS-DOS-Zeitformat:
//+---------------------------------------------------------------------------------+ //| Get Time in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
Die Zeitkonvertierung vom MQL-Format zu MS-DOS-Zeitformat:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
Diese Methoden verwenden interne Variablen zur Speicherung der Daten und Zeit: m_directory.last_mod_time und m_directory.last_mod_date, wo m_directory — die Struktur des Typs Central Directory ist.
2.4. Erzeugung der CRC-32-Prüfsumme
Ein interessantes Merkmal des Formats ZIP-Archiv ist nicht nur die Speicherung über die Service-Daten, sondern auch eine spezifische Information für die Wiederherstellung, die in einigen Fällen bei der Wiederherstellung der beschädigten Daten hilft. Um herauszufinden, ob die empfangenen Daten in Ordnung oder beschädigt sind, enthält das ZIP-Archiv ein spezielles zusätzliches Feld, das einen Zwei-Byte-Hash-Wert CRC-32 hält. Dies ist eine Prüfsumme, die für die Daten vor der Komprimierung berechnet wird. Nach dem Entpacken der Daten aus dem Archiv berechnet der Archiviere die Prüfsumme, und wenn sie nicht übereinstimmt, werden die Daten als beschädigt bezeichnet und werden für den Benutzer nicht zur Verfügung gestellt.
So muss unsere CZIP Klasse einen eigenen Berechnungsalgorithmus CRC-32 haben. Andernfalls werden die von unserer Klasse erstellten Archive sich weigern, die Werkzeuge vom Drittanbieter zu lesen, als Beispiel WinRAR kann eine Fehlerwarnung über beschädigte Daten geben:
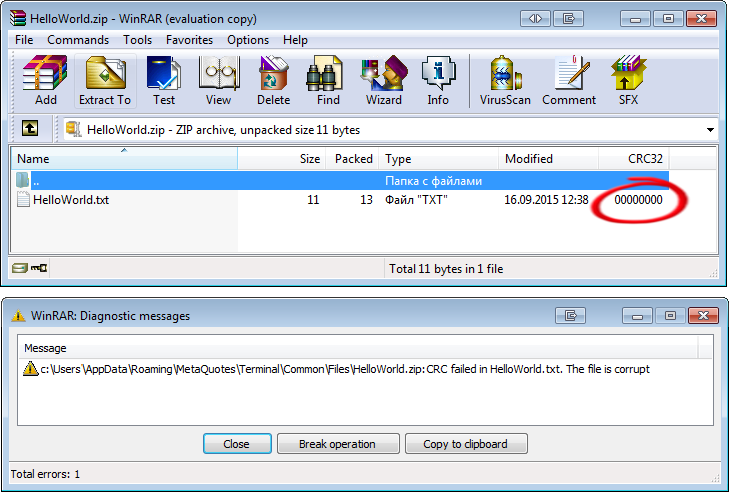
in Abb. 9. Die WinRAR Warnung vom Datenverlust der Datei "HelloWorld.txt"
Da die CRC-32-Prüfsumme nur für Dateien erforderlich ist, wird das Verfahren der Summe-Berechnung allein in der CZipFile Klasse dargestellt. Das Verfahren basiert im Beispiel auf der Programmiersprache C, das unter folgendem Link verfügbar ist: https://ru.wikibooks.org/wiki/Die Realisierung der Algorithmen/Zyklischen Redundanzcode:
//+------------------------------------------------------------------+ //| Return CRC-32 sum on source data 'array' | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
Um eine korrekte Funktionalität der Methode sicherzustellen, ist es ausreichend, ein Archiv im erstellten WinRAR-Archiver über CZIP zu öffnen. Jede Datei wird seinen einzigartigen CRC-32-Code haben:

in Abb. 10. die Prüfsumme CRC-32 im Fenster von WinRAR
Die Archiviere entpackt Dateien im normalen Modus mit einem gültigen CRC-32-Hash, und die Warnmeldung wird nicht angezeigt.
2.5. Das Lesen und Schreiben eines Archivs
Schließlich werden wir Methoden zum Lesen und Schreiben eines ZIP-Archivs diskutieren. Selbstverständlich, wenn wir beispielsweise eine Sammlung CArrayObj haben, die von Elementen CZipFile und CZipFolder besteht, das Problem der Archivbildung wird eine geringere Bedeutung haben. Es ist ausreichend, um jedes Element in eine Byte-Reihenfolge zu konvertieren und in einer Datei zu schreiben. Die folgenden Methoden befassen sich mit solchen Aufgaben:
- SaveZipToFile — öffnet die angegebene Datei und schreibt in der Datei das Byte-Array des erzeugten Archiv.
- ToCharArray — erstellt die Byte-Struktur des entsprechenden Archivs. Erzeugt die endgültige Struktur ECDR.
- ZipElementsToArray — konvertiert den Elementtyp CZipContent zu einer Byte-Reihenfolge.
Die einzige Schwierigkeit besteht darin, dass jedes Element des Archivs mit Typ CZipContent in zwei verschiedenen Dateien dargestellt wird, in Strukturen Local File Header und Central Directory. Es ist von daher notwendig, eine spezielle Call-Methode ZipElementsToArray zu verwenden, die je nachdem von der ENUM_ZIP_PART Modifikator das Byte-Array Local File Header oder Central Directory gibt.
Nun mit der Rücksicht auf diese Besonderheit sollten wir ein gutes Verständnis für die Inhalte aller drei Methoden haben, deren Quellcode im folgenden dargestellt:
//+------------------------------------------------------------------+ //| Return uchar array with ZIP elements | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| Generate ZIP archive as uchar array. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| Save ZIP archive in file zip_name | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
Das Laden des Archivs hat einige Nuancen. Offensichtlich ist das Laden des Archivs - die Operation, die umgekehrt zur Speicherung ist. Wenn die Elemente vom Typ CZipContent bei der Speicherung in eine Byte-Reihenfolge umgewandelt werden, dann wird die Byte-Reihenfolge beim Laden eines Archivs in Elementen vom Typ CZipContent umgewandelt. Auch aufgrund der Tatsache, dass jedes Element des Archivs in zwei verschiedenen Dateiteilen gespeichert wird - Local File Header und Central Directory kann das Element CZipContent nicht nur nach einem Datenlesen erstellt werden.
Es ist erforderlich, einen Zwischenbehälter Klasse CSourceZip zu verwenden, wobei zunächst die notwendigen Elemente nacheinander hinzugefügt werden und dann wird basierend darauf den gewünschten Typ der Daten gebildet - CZipFile oder CZipFolder. Dies ist der Grund, warum diese beiden Klassen einen zusätzlichen Konstruktor haben, die einen Zeiger auf den Elementtyp CSourceZip als Bezugsgröße übernimmt. Diese Art der Initialisierung zusammen mit dem CSourceZip Klasse wurde ausschließlich für den amtlichen Gebrauch vom Klasse CZIP erstellt, und wird nicht empfohlen, in einer klaren Form zu verwenden.
Drei Klassenmethoden CZIP sind für das Laden verantwortlich:
- LoadZipFromFile — öffnet eine angezeigte Datei und liest ihren Inhalt in einem Byte-Array.
- LoadHeader — lädt die Struktur Local File aus dem Byte-Array des Archivs über die vorgeschlagene Adresse.
- LoadDirectory — lädt die Struktur Central Directory aus dem Byte-Array des Archivs über die vorgeschlagene Adresse.
Also, hier ist der Quellcode dieser Methoden:
//+------------------------------------------------------------------+ //| Load Local Header with name file by offset array. | //| RETURN: | //| Return address after local header, name and zip content. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy local header uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //Copy header file name ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //Copy zip array ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+------------------------------------------------------------------+ //| Load Central Directory with name file by offset array. | //| RETURN: | //| Return adress after CD and name. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy central directory uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //Copy directory file name ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+------------------------------------------------------------------+ //| Load ZIP archive from HDD file. | //+------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
Kapitel 3. Die beispielhafte Verwendung der Klasse CZIP, Leistungsmessung
Im vorherigen Kapitel haben wir die Klasse CZIP und das ZIP-Archiv-Datenformat analysiert. Nun, da wir die Struktur des Archivs und die allgemeinen Grundsätze der Klasse CZIP kennen, können wir die praktischen Aufgaben im Zusammenhang mit der Archivierung betrachten. In diesem Kapitel werden wir drei verschiedene Beispiele analysieren, die am besten das gesamte Spektrum der Aufgaben in dieser Klasse abdecken.
3.1. Die Erstellung des ZIP-Archivs mit Notierungen für alle ausgewählten Symbole
Die erste Aufgabe, die oft gelöst werden muss, ist die Speicherung der erhaltenen Daten. Diese Daten werden oft im MetaTrader Terminal erhalten. Solche Daten können eine Folge von akkumulierten Ticken und Notierungen des OHLCV-Formats sein. Wir betrachten die Situation, wenn Notierungen in den speziellen CSV-Dateien gespeichert werden müssen, deren Format wie folgt sein wird:
Date;Time;Open;High;Low;Close;Volume 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
Das ist ein Textdatenformat. Es wird häufig zum Übertragen der Daten zwischen verschiedenen statistischen Analysesystemen eingesetzt. Das Format der Textdateien hat leider eine große Redundanz der Datenspeicherung, da jedes Byte eine sehr begrenzte Anzahl von Zeichen verwendet. Normalerweise sind diese Interpunktion, Zahlen, Groß- und Kleinbuchstaben des Alphabets. Weiterhin treten viele Werte in diesem Format häufig wieder auf, beispielsweise sind es Eröffnungsdatum oder Eröffnungspreis, die normalerweise dieselbe für eine große Datenanordnung sind. Deshalb ist diese Art von Datenkompression effektiv.
Lassen Sie uns also einen Skript schreiben, die erforderlichen Daten aus dem Terminal runterlädt. Sein Algorithmus wird folgendermaßen aussehen:
- Im Fenster Market Watch werden Werkzeuge nacheinander ausgewählt.
- Jedes ausgewählte Werkzeug hat Angebote für alle geforderten 21 Timeframes.
- Die Notierungen des ausgewählten Timeframes werden in ein CSV-Zeilen-Array konvertiert.
- Das CSV-Zeilen-Array wird in ein Byte-Array konvertiert.
- Eine ZIP-Datei(CZipFile) wird erstellt, die ein Byte-Array von Notierungen enthält und das wird anschließend zum Archiv hinzugefügt.
- Nach dem Erstellen allen Dateien der Notierungen wird das CZip-Archiviere auf einer Computer-Festplatte in der Quotes.zip-Datei gespeichert.
Der Quellcode des Skripts, der diese Aktionen ausführt, wird unten dargestellt:
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // Create empty ZIP archive. //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| Create ZIP with quotes from market watch | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
Das Laden der Daten kann einige Zeit dauern, deshalb wurden nur vier Symbole im Market Watch ausgewählt. Zusätzlich dazu laden wir nur die letzten hundert bekannten Bars. Es sollte auch die Skriptausführungszeit reduzieren. Nach seiner Ausführung erscheint in freigegebenen Dateien Ordner MetaTrader das Archiv Quotes.zip. Sein Inhalt kann man in jedem Programm sehen, das mit Archiven arbeitet, wie z.B WinRAR:
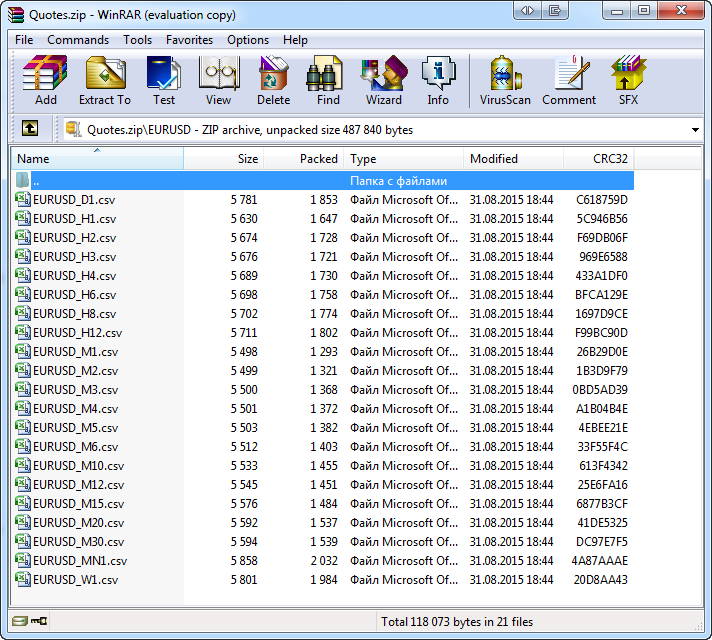
in Abb. 11. Die gespeicherten Dateien der Notierungen, die im Archiver WinRAR angesehen werden
Das erstellte Archiv wird dreimal im Vergleich zu seiner ursprünglichen Größe komprimiert. Diese Informationen werden von WinRAR zur Verfügung gestellt:
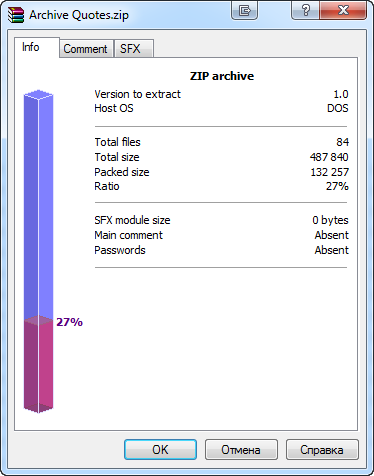
in Abb. 12. Das Verdichtungsverhältnis eines erzeugten Archivs in einem Informationsfenster WinRAR
Das ist ein gutes Ergebnisse der Kompression. Allerdings könnte man noch ein besseres Kompressionsverhältnis mit schweren und wenigen Dateien bekommen.
Das Beispiel eines Skripts, das Notierungen erstellt und speichert sie in einem ZIP-Archiv, wird im Anhang dieses Artikels unter dem Namen ZipTask1.mq5 sein und wird im Ordner Scripts sein.
3.2. Das Archiv von einem Remote-Server herunterladen, wird in MQL5.com als Beispiel gezeigt
Die nächste Aufgabe, die wir untersuchen werden, hat mit Netzwerk zu tun. In unserem Beispiel wird gezeigt, wie Sie die ZIP-Archive von einem Remote-Server herunterladen können. Als Beispiel werden wir den Indikator Alligator laden und der im Base der Quellcoden Code Base auf dem folgenden Link https://www.mql5.com/de/code/9 ist:
Für jeden Indikator Expert Advisor, Skript oder einer Bibliothek, die in Code Base veröffentlicht werden, gibt es eine Archivversion, in der alle Quellcodes des Produkts in einem einzigen Archiv komprimiert sind. Wir werden diese archivierten Version auf einem lokalen Computer herunterladen und entpacken. Aber bevor Sie damit anfangen, müssen Sie eine Zugriff-Genehmigung zum mql5.com bekommen: im Fenster Service -> Einstellungen -> Expert Advisors ist es erforderlich, die folgende Adresse "https://www.mql5.com" in der Liste der erlaubten Servers schreiben.
Die CZIP Klasse hat ihre eigene Methode, die Archive aus den Internet-Ressourcen herunterzuladen. Aber statt sie zu verwenden, lassen Sie uns unseren eigenen Skript schreiben, das das folgende Laden durchführt:
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/de/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("Unable to download ZIP archive from "+mql_url+". Check request and permissions EA."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("Loaded bad ZIP archive. Check results array."); return; } printf("Archive successfully loaded. Total files: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
Wie Sie sehen können, ist der Quellcode des Skripts ganz einfach. Zu Beginn wird WebRequest mit der Adresse des Remote-ZIP-Archivs aufgerufen. Die WebRequest lädt das Byte-Array des Archivs ins Array zip_array, und dann wird es in die CZIP Klasse durch die Methode CreateFromCharArray geladen. Dieses Verfahren ermöglicht ein Archiv direkt von der Byte-Reihenfolge zu erstellen, die manchmal für die interne Arbeit mit Archiven notwendig ist.
Neben der Methode CreateFromCharArray enthält CZIP eine speziellee Methode LoadZipFromUrl , um Archive von einem Web-Link herunterzuladen. Er arbeitet etwa wie unser vorheriger Skript. Hier ist sein Quellcode:
//+------------------------------------------------------------------+ //| Load ZIP archive from url | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
Das Ergebnis dieser Methode ist das gleiche: ein ZIP-Archiv wird nach einiger Zeit erstellt, und ihr Inhalt wird von einem Remote-Server heruntergeladen.
Das Beispiel für das Skript, das Archiv von der CodeBase herunterlädt, wird im Anhang dieses Artikels unter dem Namen ZipTask2.mq5 sein und wird im Ordner Scripts sein.
3.3. Das Komprimieren Programms-Servicedaten in RAM
Das Komprimieren Programms-Servicedaten in RAM - eine nicht triviale Weise der Archivierung-Verwendung. Dieses Verfahren kann verwendet werden, wenn zu viele verarbeiten Daten in RAM zur Platzierung gibt. Jedoch bei der Verwendung dieses Verfahrens wird die gesamte Leistung des Programms verringert, da zusätzliche Aktionen für die Archivierung/ Entpacken der Servicestrukturen oder Daten nötig werden.
Stellen wir uns vor, dass die MQL-Programme eine Sammlung der historischen Orders speichern muss. Jeder Order wird durch eine spezielle Struktur Order beschrieben, die alle seine Eigenschaften enthält: einen Identifikator, Der Typ der Order, die Ausführungszeit, Volumen, usw Lassen Sie uns diese Struktur beschreiben:
//+------------------------------------------------------------------+ //| History order | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // Ticket order datetime time_setup; // Time setup order ENUM_ORDER_TYPE type; // Type order ENUM_ORDER_STATE state; // State order datetime time_exp; // Expiration time datetime time_done; // Time done or canceled order long time_setup_msc; // Time setup in msc long time_done_msc; // Time done in msc ENUM_ORDER_TYPE_FILLING filling; // Type filling ENUM_ORDER_TYPE_TIME type_time; // Type living time ulong magic; // Magic of order ulong position_id; // ID position double vol_init; // Volume init double vol_curr; // Volume current double price_open; // Price open double sl; // Stop-Loss level double tp; // Take-Profit level double price_current; // Price current double price_stop_limit; // price stop limit string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| Init by ticket | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| Return comment of order | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| Return symbol of order | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| Set comment order | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| Set symbol order | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| Converter for uchar array. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| Convert order structure to uchar array | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
Der Aufruf des Operatorssizeof zeigt, dass diese Struktur 200 Byte besitzt. Auf diese Weise besitzt die Speicherung der historischen Orders die Anzahl der Bytes, die durch die folgende Formel berechnet werden kann: sizeof(Order) * die Anzahl der historischen Orders. Das heißt, für die Sammlung, die 1000 historische Orders enthält, werden wir den folgenden Speicherplatz 200 * 1000 = 200 000 байт Bytes oder fast 200 KB erfordern. Es ist nicht viel von den heutigen Standard, aber wenn die Sammlung-Größe aus über Zehntausende Elementen besteht, wird die Menge des verwendeten Speicherplatz eine wichtige Bedeutung haben.
Dennoch ist es möglich, einen speziellen Behälter zur Speicherung dieser Orders zu entwickeln, der ihre Inhalte komprimieren konnte. Dieser Behälter, zusätzlich zu den üblichen Methoden der Zugabe und Löschung der neuen Elementen Order, wird auch die Methoden Pack und Unpack enthalten, die den Inhalt der Strukturen des Typs Order komprimieren wird. Hier ist der Quellcode des Behälters:
//+------------------------------------------------------------------+ //| Container of orders. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| Add new order. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| Return order at index. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| Return total orders. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| Delete order by index. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| Return orders size. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
Die Idee ist, dass der Benutzer neue Elemente im Behälter hinzufügen kann, und, falls es erforderlich ist, seinen Inhalt direkt im Computer-RAM komprimieren. Mal sehen, wie es funktioniert. Schreiben wir einen Demo-Skript:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="Unpack size: "+(string)unpack_size+"bytes; "+ "Pack size: "+(string)pack_size+" bytes ("+per+" percent compressed. "+ "Pack execute msc: "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("First id ticket: "+(string)first.ticket); } } //+------------------------------------------------------------------+
Der Moment der Sammlungskompression ist gelb markiert. Gestartet in einem von Konten, welches 858 historische Orders hat, hat dieses Skript die folgenden Ergebnisse geliefert:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) Unpack size: 171600 bytes; Pack size: 1521 bytes (0.89 percent compressed. Pack execute microsec.: 2534
Wie Sie sehen können, war die Größe nicht gepackter Sammlung 171600 Bytes. Die Größe der Sammlung nach der Kompression war nur 1521 Bytes. Das heißt, das Verdichtungsverhältnis über hundertmal ist! Dies ist aufgrund der Tatsache, dass viele Strukturfelder ähnliche Daten enthalten. Auch viele Felder haben leere Werte, unter denen jedoch Speicherplatz zugeordnet ist.
Um sicherzustellen, dass die Kompression richtig funktioniert, müssen Sie eine Order aus der Sammlung auswählen und seine Eigenschaften drucken. Wir haben die erste Order ausgewählt und ihren eindeutigen Identifikator ausgewählt. Nach der Packung wurde der Identifikator der Order korrekt angezeigt:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) First id ticket: 10279280
Der beschriebene Algorithmus wird beim Aufruf zu seiner Sammlung die zuvor gepackten Daten entpacken. Das verringert die Produktivität. Von daher müssen die Daten erst nach ihrer Entstehung komprimiert werden. Für ein besseres Komprimierungsverhältnis werden alle Daten in einem einzigen Array gesammelt und dann komprimiert. Der umgekehrte Vorgang gilt für das Entpacken.
Interessanterweise verlangt die Kompression der 858 Elemente nur 2,5 Millisekunden auf einem ausreichend leistungsfähigen Computer. Das Entpacken der gleichen Daten läuft schneller und dauert etwa 0,9 Millisekunden. Somit findet eine Loop der Komprimierung / Entpacken des Arrays, welches aus tausenden von Elementen besteht, etwa 3,5-4,0 Millisekunden. Dies ermöglicht mehr als hundert Mal den Speicherplatz zu sparen. Solche Eigenschaften sehen beeindruckend genug aus, um eine ZIP-Komprimierung für die großen Datenmengen zu verwenden.
Das Beispiel für das Skript, das Daten in einem Computer-Speicher komprimiert, wird im Anhang dieses Artikels unter dem Namen ZipTask3.mq5 sein und wird im Ordner Scripts sein. Außerdem wird für seine Funktionalität die Datei Orders.mqh benötigt, die im Ordner Include sein wird.
Kapitel 4. Die Dokumentation für Klassen mit ZIP-Archiven
4.1. Die Dokumentation für die Klasse CZipContent
Dieses Kapitel beschreibt die Methoden und Aufzählungen, die in Klassen bei der Arbeit mit ZIP-Archivs verwendet werden. Die CZipContent Klasse wird nicht direkt auf einer Benutzerebene verwendet, aber alle seine öffentlichen Methoden werden von Klassen CZipFile und CZipFolder übertragen, auf dieser Weise werden auch die beschriebenen Methoden und Eigenschaften für die Klassen gelten.
Die Methode ZipType()
Die ZipType Methode gibt einen aktuellen Elementtyp in einem Archiv. Es gibt zwei Arten von Elementen, die in einem Archiv gespeichert sind: ein Ordner (Verzeichnis) und eine Datei. Der Typ des Ordners wird durch die CZipDirectory Klasse dargestellt, Der Dateityp durch die CZipFile Klasse. Weitere Informationen über die Typen des ZIP-Archivs können Sie im Abschnitt 2.1 des aktuellen Kapitels lesen: "Die Struktur der komprimierten Dateien im Archiv, die Klassen CZipFile und CZipFolder".
ENUM_ZIP_TYPE ZipType(void);Rückgabewert
Es liefert die Aufzählung ENUM_ZIP_TYPE zurück, die beschreibt, zu welcher Art die aktuelle Kopie CZipContent gehört.
Die Methode Name(void)
Es liefert den Ordnernamen oder Dateinamen ins Archiv zurück.string Name(void);
Rückgabewert
Der Ordnername oder Dateiname.
Die Methode Name(string name)
Er setzt den aktuellen Ordnernamen oder Dateinamen im Archiv. Es wird verwendet, wenn der aktuelle Ordnername oder Dateiname geändert werden muss.
void Name(string name);
Parameter:
- [in] name — der neue Ordner oder Dateiname. Der Name muss eindeutig sein und nicht mit anderen Namen der Ordner oder Dateien im Archiv zusammenfallen.
Die Methode CreateDateTime(datetime date_time)
Er setzt das aktuelle Datum der Änderung des Ordners oder einer Datei im Archiv.
void CreateDateTime(datetime date_time);
Parameter:
- [in] date_time — Das Datum und die Uhrzeit, die für einen aktuellen Ordner oder eine Datei gesetzt werden muss.
Hinweis:
Das Datum und die Zeit werden dem MS-DOS-Format konvertiert und werden in den inneren Strukturen der Typen ZipLocalHeader und ZipCentralDirectory gespeichert. Weitere Informationen über die Möglichkeiten der Konvertierung und Präsentation dieses Format finden Sie im Kapitel 2.3 dieses Artikels: "Erinnern wir uns an MS-DOS. Zeit- und Datumsformat im ZIP-Archiv".
Die Methode CreateDateTime(void)
Es liefert das Datum und die Uhrzeit eines aktuellen Ordners oder Datei zurück.
datetime CreateDateTime(void);
Rückgabewert
Das Datum und die Uhrzeit der Änderung eines aktuellen Ordners oder einer Datei.
Die Methode CompressedSize()
Es liefert die Größe der komprimierten Daten in der Datei zurück. Die Größe der komprimierten Daten für Verzeichnisse ist immer gleich Null.
uint CompressedSize(void);
Rückgabewert
Die Größe der komprimierten Daten in Bytes.
Die Methode UncompressedSize()
Es liefert die Größe der anfangs unkomprimierten Daten in der Datei zurück. Die Größe der unkomprimierten Daten für Verzeichnisse ist immer gleich Null.
uint UncompressedSize(void);
Rückgabewert
Die Größe der anfangs Daten in Bytes.
Die Methode TotalSize()
Es liefert die Gesamtgröße der Archivselementen. Jede Datei oder jedes Verzeichnis im Archiv speichert neben seinem Namen und Inhalte (Dateien) die zusätzlichen Service-Strukturen, deren Größe auch berücksichtigt wird, wenn die Gesamtgröße der Archivselemente berechnet wird.
int TotalSize(void);
Rückgabewert
Die Gesamtgröße des aktuellen Elements im Archiv, die der zusätzlichen Service-Daten berücksichtigt.
Die Methode FileNameLength()
Es liefert die Länge des Verzeichnissnamens oder der Datei, der in der Anzahl der verwendeten Zeichens ausgedrückt wird.
ushort FileNameLength(void);
Rückgabewert
Die Länge des Verzeichnissnamens oder der Datei, der in der Anzahl der verwendeten Zeichens ausgedrückt wird.
Die Methode UnpackOnDisk()
Es dekomprimiert den Inhalt des Elements und speichert ihn in einer Datei mit dem Elementnamen auf der Festplatte des Computers. Wenn ein Verzeichnis entpackt wird, dann statt einer Datei wird ein entsprechender Ordner erstellt.
bool UnpackOnDisk(string folder, int file_common);
Parameter
- [in] folder — Der Name eines Root-Ordners, in dem eine aktuelle Ordner oder eine Datei komprimiert werden muss. Wenn ein Element, ohne ein Archivsordner entpackt werden muss, so muss dieser Wert leer bleiben und gleich "".
- [in] file_common — dieser Modifikator gibt an, in welchem Abschnitt des Dateisystems im MetaTrader-Programm ein Element entpackt werden muss. Stellen Sie diesen Parameter gleich FILE_COMMON ein, wenn Sie eine Dekompression in einer gemeinsamen Datei aller MetaTrader 5 Terminals durchführen möchten.
Rückgabewert
Es liefert den realen Wert zurück, wenn die Dekompression einer Datei oder eines Ordners auf der Festplatte erfolgreich gelaufen ist. Ansonsten liefert es false Wert zurück.
4.2. Die Dokumentation für die Klasse CZipFile
Die CZipFile Klasse wird von CZipContent geerbt und wird zur Speicherung der Archivdateien verwendet. Die CZipFile speichert den Inhalt der Datei nur in komprimierter Form. Das bedeutet, dass der Inhalt automatisch komprimiert wird, wenn eine Datei zur Speicherung übertragen wird. Das Dekomprimieren der Datei wird auch automatisch laufen, wenn die Methode GetUnpackFile aufgerufen wird. Neben einer Reihe von den Methoden CZipContent, CZipFile unterstützt es auch spezielle Methoden, um mit Dateien zu arbeiten. Unten finden Sie eine Beschreibung dieser Methoden.
Die Methode AddFile()
Fügt die Datei von der Festplatte zum aktuellen Element CZipFile hinzu. Um eine Datei zum Archivtyp CZIP hinzuzufügen, müssen Sie zunächst eine Kopie der Klasse CZipFile erstellen und seinen Namen zum Speicherort angeben. Nachdem die Kopie der Klasse erstellt wird, muss es durch den Aufruf der entsprechenden Methode zur Klasse CZIP hinzugefügt werden. Die tatsächliche Komprimierung des übertragenen Inhalts erfolgt in dem Moment, in dem es hinzugefügt wird (Aufruf dieser Methode).
bool AddFile(string full_path, int file_common);
Parameter
- [in] full_path — der vollständige Name der Datei, einschließlich der Weg zu ihr bezüglich des zentralen Dateikatalogs von MQL-Programmen.
- [in] file_common — dieser Modifikator zeigt an, in welchem Abschnitt des Dateisystems von MetaTrader Programmen es erforderlich ist, um ein Element zu dekomprimieren. Stellen Sie diesen Parameter gleich FILE_COMMON ein, wenn Sie eine Dekompression in einer gemeinsamen Datei aller MetaTrader 5 Terminals durchführen möchten.
Rückgabewert
Es liefert den realen Wert zurück, wenn das Hinzufügen der Datei erfolgreich gelaufen ist. Ansonsten liefert es false Wert zurück.
Die Methode AddFileArray()
Es fügt ein Byte-Array vom Typ uchar als der Inhalt CZipFile. Diese Methode wird verwendet, wenn der Dateiinhalt dynamisch erstellt wird. Die tatsächliche Komprimierung des übertragenen Inhalts erfolgt in dem Moment, in dem es hinzugefügt wird (Aufruf dieser Methode).
bool AddFileArray(uchar& file_src[]);
Parameter
- [in] file_src — das Byte-Array, das hinzugefügt werden muss.
Rückgabewert
Es liefert den realen Wert zurück, wenn das Hinzufügen der Datei erfolgreich gelaufen ist. Ansonsten liefert es false Wert zurück.
Die Methode GetPackFile()
Es liefert den komprimierten Inhalt der Datei zurück.
void GetPackFile(uchar& file_array[]);
Parameter
- [out] file_array — das Byte-Array, in dem der komprimierte Inhalt der Datei genommen werden muss.
Die Methode GetUnpackFile()
Es liefert den dekomprimierten Inhalt der Datei zurück. Der Inhalt wird im Moment des Methodenaufrufs dekomprimiert.
void GetUnpackFile(uchar& file_array[]);
Parameter
- [out] file_array — das Byte-Array, in dem der dekomprimierte Inhalt der Datei genommen werden muss.
4.3. Die Dokumentation für die Klasse CZip
Die CZIP-Klasse implementiert die Hauptarbeit mit ZIP-Archiven. Die Klasse ist generell ein ZIP-Archiv, zu dem zwei Arten von ZIP-Elemente hinzugefügt werden können: die Elemente, die einen Ordner (CZipDirectory) darstellen und Elemente für eine ZIP-Datei (CZipFile). Unter anderem ermöglicht die Klasse CZIP bereits bestehenden Archive sowohl von der Festplatte des Computers auch in Form einer Byte-Reihenfolge zu laden.
Die Methode ToCharArray()
Er konvertiert den Inhalt eines ZIP-Archivs in eine Byte-Reihenfolge vom Typ uchar.
void ToCharArray(uchar& zip_arch[]);
Parameter
- [out] zip_arch — das Byte-Array, in dem der Inhalt des ZIP-Archivs genommen werden muss.
Die Methode CreateFromCharArray()
Lädt das ZIP-Archiv aus der Byte-Reihenfolge.
bool CreateFromCharArray(uchar& zip_arch[]);
Parameter
- [out] zip_arch — das Byte-Array, aus dem der Inhalt des ZIP-Archivs geladen werden muss.
Rückgabewert
Der reale Wert, wenn das Archiv aus einer Byte-Reihenfolge erfolgreich erstellt wurde, ansonsten false Wert.
Die Methode SaveZipToFile()
Es speichert das aktuelle ZIP-Archiv mit seinem Inhalt in der angegebenen Datei.
bool SaveZipToFile(string zip_name, int file_common);
Parameter
- [in] zip_name — der vollständige Name der Datei, einschließlich der Weg zu ihr bezüglich des zentralen Dateikatalogs von MQL-Programmen.
- [in] file_common — dieser Modifikator zeigt an, in welchem Abschnitt des Dateisystems von MetaTrader Programmen es erforderlich ist, um ein Element zu dekomprimieren. Stellen Sie diesen Parameter gleich FILE_COMMON ein, wenn Sie eine Dekompression in einer gemeinsamen Datei aller MetaTrader 5 Terminals durchführen möchten.
Rückgabewert
Der reale Wert, wenn das Archiv in der Datei erfolgreich gespeichert wurde, ansonsten false Wert.
Die Methode LoadZipFromFile()
Es lädt den Archivinhalt aus der Datei auf der Festplatte des Computers.
bool LoadZipFromFile(string full_path, int file_common);
Parameter
- [in] full_path — der vollständige Name der Datei, einschließlich der Weg zu ihr bezüglich des zentralen Dateikatalogs von MQL-Programmen.
- [in] file_common — dieser Modifikator zeigt an, in welchem Abschnitt des Dateisystems von MetaTrader Programmen es erforderlich ist, um ein Element zu dekomprimieren. Stellen Sie diesen Parameter gleich FILE_COMMON ein, wenn Sie eine Dekompression in einer gemeinsamen Datei aller MetaTrader 5 Terminals durchführen möchten.
Rückgabewert
Der reale Wert, wenn das Archiv aus der Datei erfolgreich geladen wurde, ansonsten false Wert.
Die Methode LoadZipFromUrl()
Es lädt den Archivinhalt über den Web-Link url. Für die Funktionalität dieser Methode ist es notwendig, die Zugriff-Genehmigung der angeforderten Ressource zu setzen. Weitere Einzelheiten dieser Methode können Sie im Abschnitt 3.2 dieses Artikels lesen: "Das Archiv von einem Remote-Server herunterladen, wird in MQL5.com als Beispiel gezeigt"
bool LoadZipFromUrl(string url);
Parameter
- [in] url — der Link zum Archiv.
Die Methode UnpackZipArchive()
Es dekomprimiert alle Dateien und Verzeichnisse des aktuellen Archivs ins vorgeschlagene Verzeichnis.
bool UnpackZipArchive(string folder, int file_common);
Parameter
- [in] folder — der Ordner, in dem das aktuelle Archiv dekomprimiert werden muss. Wenn es nicht notwendig ist, einen Archiv-Ordner zu erstellen, müssen Sie einen Nullwert als Parameter übergeben "".
- [in] file_common — dieser Modifikator zeigt an, in welchem Abschnitt des Dateisystems von MetaTrader Programmen es erforderlich ist, um ein Element zu dekomprimieren. Stellen Sie diesen Parameter gleich FILE_COMMON ein, wenn Sie eine Dekompression in einer gemeinsamen Datei aller MetaTrader 5 Terminals durchführen möchten.
Rückgabewert
Der reale Wert, wenn das Archiv in der Datei erfolgreich dekomprimiert wurde, ansonsten false Wert.
Die Methode Size()
Es liefert die Größe des Archivs in Byte zurück.
int Size(void);Rückgabewert
Die Größe des Archivs in Byte.
Die Methode TotalElements()
Es liefert die Anzahl der Elemente im Archiv. Das Archivselement kann ein Verzeichnis oder eine komprimierte Datei sein.
int TotalElements(void);
Rückgabewert
Die Anzahl der Elemente im Archiv.
Die Methode AddFile()
Es fügt neue ZIP-Datei zum aktuellen Archiv hinzu. Die Datei muss in der Form CZipFile vorgelegt werden und vor dem Hinzufügen zum Archiv muss sie erstellt werden.
bool AddFile(CZipFile* file);Parameter
- [in] file — Die ZIP-Datei, die zum Archiv hinzugefügt werden muss.
Rückgabewert
Der reale Wert, wenn das Hinzufügen zum Archiv erfolgreich durchgeführt wurde, ansonsten false Wert.
Die Methode DeleteFile()
Es löscht die Datei vom Typ CZipFile über den Index index aus dem Archiv.
bool DeleteFile(int index);
Parameter
- [in] index — Der Index der Datei, der aus dem Archiv gelöscht werden muss.
Rückgabewert
Der reale Wert, wenn die Löschung der Datei aus dem Archiv erfolgreich gelaufen ist. Ansonsten false Wert.
Die Methode ElementAt()
Er erhält das Element vom Typ CZipFile, der auf dem Index index gesetzt wurde.
CZipContent* ElementAt(int index)const;
Parameter
- [in] index — Der Index der Datei, der aus dem Archiv erhalten werden muss.
Rückgabewert
Das Element vom Typ CZipFile, das auf dem Index index gesetzt wurde.
4.4. Die Struktur ENUM_ZIP_ERROR und die Erhaltung der erweiterten Fehlerinformationen
Während der Arbeit mit Klassen CZIP, CZipFile und CZipDirectory können verschiedene Fehler auftreten, wie zum Beispiel ein Fehler, der beim Versuch zum Zugriff der nicht vorhandenen Datei auftritt, usw. Die meisten Methoden, die in diesen Klassen vorgestellten sind, liefern die entsprechende Flagge von Typ bool zurück, die Signale über die erfolgreichen Transaktionen gibt. Falls ein negativer Wert (false) zurückgeliefert wird, können Sie zusätzliche Informationen über die Gründe des Scheiterns erhalten. Die Ursachen des Scheiterns können Standard, Systemfehler sein, auch gibt es bestimmte Fehler, die mit ZIP-Archiven im Laufe der Operation auftreten. Zur Übertragung der spezifischen Fehler werden die Übertragungsrichtungen von Benutzerfehlern mit der Funktion SetUserError verwendet. Die Codes von Benutzerfehlern werden durch die Aufzählung ENUM_ZIP_ERROR gegeben:
Die Aufzählung ENUM_ZIP_ERROR
| Werte | Beschreibung |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | Die Datei, die für die Komprimierung übertragen wurde, ist leer. |
| ZIP_ERROR_BAD_PACK_ZIP | Der Fehler des internen Kompressors / Dekompressors. |
| ZIP_ERROR_BAD_FORMAT_ZIP | Das übertragen ZIP-Dateiformat ist nicht auf einem Standard entspricht oder beschädigt. |
| ZIP_ERROR_NAME_ALREADY_EXITS | Der Name einer Datei, die der Benutzer speichern versucht, ist bereits in einem Archive verwendet. |
| ZIP_ERROR_BAD_URL | Der übertragene Link bezieht sich nicht auf ein ZIP-Archiv, oder der Zugriff zur angegebenen Web-Ressource wird von Terminal-Einstellungen verboten. |
Nach dem Empfang eines Benutzerfehlers müssen Sie ihn explizit auf die Aufzählung ENUM_ZIP_ERROR bringen und entsprechend verarbeiten. Ein Beispiel für die Arbeit mit Fehlern, die mit den Archivierungsklassen im Laufe entstehen, wird im Folgenden als Skript dargestellt:
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf(" Ein System-Fehler beim Laden des Archivs ist aufgetreten. Die Nummer des Fehlers: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("Ein Fehler der Verarbeitung beim Laden des Archivs ist aufgetreten: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
4.5. Die Beschreibung der Dateien, die zu diesem Artikel hinzugefügt sind
Unten finden Sie die Beschreibung der Dateien, die zu diesem Artikel hinzugefügt sind:
- Zip\Zip.mqh — enthält die Hauptklasse für die Arbeit mit CZIP Archiven.
- Zip\ZipContent.mqh — enthält die Kernklasse CZipContent für Basisklassen der Archivselemente: CZipFile und CZipDirectory.
- Zip\ZipFile.mqh — enthält die Klasse für die Arbeit mit ZIP-Dateien des Archivs.
- Zip\ZipDirectory.mqh — enthält die Klasse für die Arbeit mit ZIP-Ordern des Archivs.
- Zip\ZipHeader.mqh — in der Datei wurden die Strukturen File Local Header, Central Directory und End Central Directory Record beschrieben.
- Zip\ZipDefines.mqh — die Liste aus Definitionen, Konstanten und Fehlercodes, die für die Arbeit mit Archivierungsklassen verwendet werden.
- Dictionary.mqh — die zusätzliche Klasse, die über dem Archiv eine einzigartige Kontrolle der Datei- und Verzeichnisnamen bietet, die zum Archiv hinzugefügt werden. Der Arbeitsalgorithmus dieser Klasse wurde in dem Artikel beschrieben " Rezepten MQL5 - die Realisierung eines assoziativen Arrays oder ein Wörterbuch für den schnellen Datenzugriff".
Alle Dateien in diesem Artikel, die wir aufgeführt haben, müssen in Bezug auf das interne Verzeichnis platziert werden<Verzeichnis_Daten_Terminal>\MQL5\Include. Am Anfang der Arbeit mit Klassen müssen Sie eine Zip \ Zip.mqh Datei zum Projekt hinzufügen Als Beispiel werden wir ein Skript beschreiben, der ein ZIP-Archiv erstellt und schreibt eine Textdatei mit der Meldung "Test" darin:
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // Fügen Sie alle notwendigen Klassen für die Arbeit mit dem ZIP-Archiv //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // Wir erstellen ein leeres ZIP-Archiv uchar array[]; // Wir erstellen ein leeres ZIP-Archiv array StringToCharArray("test", array); // Wir konvertieren die Meldung "test" in das Byte-Array array CZipFile* file = new CZipFile("test.txt", array); // Wir erstellen eine neue ZIP-Datei 'file', die basierend auf dem Array mit dem Namen "test.txt" ist Zip.AddFile(file); // Wir fügen die erstellte ZIP-Datei 'file' zu einem ZIP-Archiv Zip.SaveZipToFile("Test.zip", FILE_COMMON); //Wir speichern das ZIP-Archiv mit dem Namen "Test.zip" auf dem Datenträger. } //+------------------------------------------------------------------+
Nach dem Ausführen wird auf der Festplatte des Computers im Verzeichnis der Dateien für MetaTrader 5 ein neues ZIP-Archiv unter dem Namen Test.zip erscheinen, das eine Textdatei mit dem Schreiben "test" enthält.
| Das Archiv, das zu diesem Artikel hinzugefügt ist, wurde mittels des CZIP MQL-Archivators erstellt, der hier beschrieben wurde. |
|---|
Fazit
Wir haben gründlich eine Struktur des ZIP-Archivs untersucht und haben Klassen erstellt, die die Arbeit mit dieser Art von Archiven realisiert. Ein solches Archivierungsformat wurde in den späten 80er Jahren des letzten Jahrhunderts entwickelt, und es bleibt immer noch als beliebtestes Datenkompressionsformat. Eine Reihe dieser Daten-Klassen kann einem Handelssystem-Entwickler unschätzbare Hilfe bieten. Mit seiner Hilfe können Sie effizient die gesammelten Daten speichern, egal ob es die Ticks-History ist oder andere Handelsinformation ist. Oft werden verschiedene analytische Information auch in komprimierter Form zur Verfügung gestellt. In diesem Fall kann die Fähigkeit, solche Informationen zu verarbeiten, selbst in einer komprimierten Form sehr nützlich sein.
Die beschriebenen Klassen verbergen viele technische Aspekte der Arbeit mit Archiven, bietet auf einer einfachen Benutzersprache verständliche Methoden für die Arbeit, ähnlich denen, die Benutzer meistens mit Archivierungsprogrammen arbeitet: das Hinzufügen und Extrahieren der Dateien aus Archiven, die Erstellung neuer Archiven und Laden von bereits bestehenden Archiven, einschließlich auch die Archiven, die auf den Remote-Server der Drittanbietern platziert sind. Diese Möglichkeiten lösen völlig die meisten Probleme, die im Zusammenhang mit der Archivierung kommen und machen die Programmierung in MetaTrader noch einfacher und funktional.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/1971
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 MQL5 für Anfänger: Antivandalismusschutz der grafischen Objekten
MQL5 für Anfänger: Antivandalismusschutz der grafischen Objekten
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich bin auf ein Archiv gestoßen, das CZip nicht entpacken konnte. 7ZIP und das Windows-Archivierungsprogramm entpackten es jedoch ohne Probleme.
...
Ich kann Ihnen die Archivdatei in einer privaten Nachricht schicken, wenn Sie daran interessiert sind, sie zu verstehen.Bitte senden Sie mir die Archivdatei in einer privaten Nachricht zu.
Bitte senden Sie mir die Archivdatei in einer privaten Nachricht.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-01-18_BTCUSDT_ob500.data.zip
hier im Archivkörper (nicht im Header) steht cdheader = 0x504b0102;
Auch in der nächsten Datei nach Datum. Ich denke, es wird oft gefunden.
header = 0x504b0304; steht in jeder Datei im Header, also den ersten 4 Zeichen.
Aber es kommt auch vor und im Body des Archivs, selten. Ich werde jetzt danach suchen.
Hier https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-03-15_BTCUSDT_ob500.data.zip.
Ich denke, es ist notwendig, für diese Header nur zwischen den Körpern der Archive zu suchen.
Und es gibt auch einen Link zu einer großen Datei, die sich nicht richtig entpacken lässt. Ich setze die Größe für sie auf 0, und dann versteht das aufrufende Programm durch diese 0, dass es einen Fehler gibt und es notwendig ist, ein anderes Archivierungsprogramm zu verwenden.
Vielleicht fällt Ihnen etwas Besseres anstelle von 0 ein.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip
Ich habe die Dateien (entpackt) aussortiert, die ein bestimmtes Volumen überschreiten (für verschiedene Dateien von 1.7Gb bis 2136507776 - d.h. fast bis MAX_INT=2147483647, und Arrays können nicht mehr Elemente haben) und die bei der Ausgabe abgeschnitten werden. Es stellte sich heraus, dass alle von ihnen als fehlerhaft markiert wurden:
D.h. Ausgabewert = 0.
Aber CZIP kontrolliert das nicht. Ich habe die Größe des Ausgabe-Arrays auf Null gesetzt.
So kann ich in meinen Funktionen mit 100%iger Sicherheit feststellen, dass die Datei erfolgreich entpackt ist.
Vorher habe ich das korrekte Ende der JSON-Datei überprüft - aber diese Lösung ist nicht universell, und es scheint, dass mehrere Dateien von ~1000 versehentlich durch eine Zwischenzeile abgeschnitten wurden und als erfolgreich dekomprimiert akzeptiert wurden, aber die Daten in ihnen sind nicht vollständig.
Neue Version der Funktion:
Die neue istgelb hervorgehoben.
Vielleicht sollten die Entwickler auch das Array auf Null zurücksetzen, denn die abgeschnittenen Daten werden kaum von jemandem benötigt. Und sie können zu schwer erkennbaren Fehlern führen.
Und es gibt auch einen Link zu einer großen Datei, die sich nicht richtig entpacken lässt. Ich setze die Größe für sie auf 0, und dann versteht das aufrufende Programm durch diese 0, dass es einen Fehler gibt und es notwendig ist, einen anderen Archiver zu verwenden.
Vielleicht fällt Ihnen etwas Besseres anstelle von 0 ein.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip