
单纯使用 MQL5 语言处理 ZIP 档案

目录
- 简介
- 第一章. ZIP 文件的格式和数据存储
- 第二章. CZip 类与之算法概览
- 第三章. 使用CZip类的实例, 效率衡量
- 第四章. 操作ZIP档案类的文档
- 结论
简介
主题背后的历史
本文的作者曾经被CryptDecode函数的一个有趣的特性所吸引, 就是它能够解压缩一个传送给它的ZIP数组. 这个功能是由MetaTrader 5交易平台的开发人员引入的, 以便解开来自多个服务器的标准WebRequest函数回复. 然而, 由于ZIP文件格式的某些特征, 不能直接使用它.
需要额外的认证: 对于使用 -Adler -32 方式压缩的档案, 如需解压, 首先要知道它的哈希和, 这肯定是不知道的. 然而, 当讨论这个问题的时候, 开发人员遇到了重载CryptDecode以及和它对应的CryptEncode函数的需求, 使用特别的开关允许在解压缩传来的数据时忽略 Alder32哈希. 对于在技术角度上对此创新没有经历的用户, 简单来说就是: 它使得ZIP档案的全部功能都可用了. 本文描述了ZIP文件结构, 它在数据存储上的特点, 也提供了方便的面向对象的CZip类来操作一个档案.
为什么需要它?
数据压缩是最重要的技术之一, 特别在互联网方面广泛应用. 压缩有助于节约传输, 存储和处理数据的资源. 数据压缩在通讯的所有领域都有应用, 也包括在几乎所有的计算机相关任务中.
在经济方面也不例外: 以GB为单位计算的订单历史, 报价数据流, 包括市场深度(等级二数据) 都不能使用未经压缩的原始格式来存储. 许多服务器, 包括提供用于交易分析数据的, 都以ZIP档案的形式保存数据. 过去不可能使用MQL5的标准工具来自动获取此类信息. 现在情况已经有所改变.
通过使用 WebRequest 函数, 您可以下载一个ZIP档案并立即在计算机上把它解压缩. 这些特性都是很重要的, 很多交易者也一定需要它们. 数据压缩甚至可以用于优化计算机内存. 至于如何去做, 我们将在本文的3.2章节来介绍. 最后, 如果我们可以操作ZIP档案, 我们就可以访问微软Office标准的Office Open XML, 然后我们就可以直接使用MQL5来创建简单的Excel或者Word文件, 而不需要使用第三方的DLL库.
你可以看到, ZIP档案应用程序是可以扩展的, 我们创建的类可以服务于所有MetaTrader用户.
在本文的第一章中, 我们将会描述ZIP文件的格式, 并且想办法来得到其中包含的数据块. 这一章的内容不仅对学习MQL的人有帮助, 它也是数据存储方面的一个很好的教学资料. 第二章介绍了CZip, CZipFile 和 CZipDirectory 类, 它们是操作档案的主要面向对象元素. 第三章介绍了与使用存档相关的实际例子. 而第四章包含了与所提供类相关的文档.
就这样, 让我们开始学习这种最常见的存档类型吧.
第一章. ZIP 文件的格式和数据存储
1.1. ZIP 文件的结构
ZIP 格式是由Phil Katz在1989年创造的, 并且首先在MS-DOS的PKZIP 程序中实现, 它是由Katz创建的PKWARE公司发布的. 这种存档格式非常频繁地使用了紧缩(DEFLATE)数据压缩算法. 在Windows中最常用处理这种格式文件的程序是WinZip和WinRAR.
另外很重要的一点是, 随着时间的推移, ZIP存档格式也开发了几个版本. 为了创建一个可以操作ZIP档案的类, 我们需要参照PKWARE公司网站上的官方格式规格中的6.3.4版本: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT. 这是2014年10月1日发布的最新版规格, 它是可以扩展的, 并且包含了与之前版本差别的描述.
在本文中, 我们将以最小精力原则来创建一个工具, 仅使用必需的数据来解压文件和创建新的档案. 这就意味着对ZIP文件的操作在某种程度上有限制 - 不能保证格式的兼容性, 所以也就不需要说档案的各种"多样性"了. 还有一种可能, 有些ZIP档案是第三方创建的, 也不能使用这个工具来解开.
每个ZIP档案都是包含一定顺序字节序列的二进制文件. 另一方面, ZIP档案中的每个文件都有名称, 特性(例如文件修改时间), 以及其他一些我们曾在任意操作系统的文件系统中看到的属性. 另外, 除了压缩的数据, 每个ZIP档案还保存着压缩文件的名称, 特性和其他服务信息. 服务信息是使用非常特别的形式存放的, 并且具有一个通用结构. 例如, 如果一个档案包含两个文件 (File#1 和 File#2), 它就会有如下的结构:
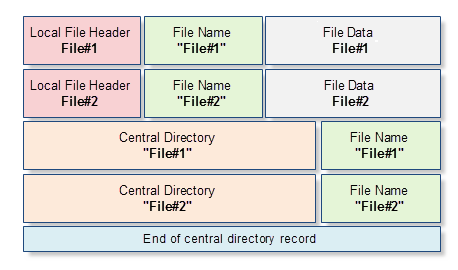
图 1. 包含两个文件的ZIP档案的结构显示: File#1 和 File#2
在晚些时候我们会查看这个结构的每个区块, 但是现在我们只对全部区块作一个简要的介绍:
- 本地文件头(Local File Header) — 这个数据块包含了压缩文件的基本信息: 压缩之前的文件大小, 文件修改时间, CRC-32校验和以及指向文件名的本地指针. 另外, 这个区块还包含着用于解压缩文件的归档工具版本.
- 文件名(File Name)是一个任意长度的字节序列, 构成了压缩文件的名称. 文件名称的长度不能超过65536个字符.
- 文件数据(File Data)是压缩文件的具体内容, 它的形式是任意长度的字节数组. 如果文件为空或者包含一个目录, 这个数组就没有被使用, 描述下一个文件的本地文件头就会跟在文件名或目录之后.
- 中心目录(Central Directory) 在本地文件头中提供了扩展的数据视图. 除了在本地文件头中包含的数据之外, 它还有文件特性, 对本地文件头的本地引用以及其他较少使用的信息.
- 中心目录记录结尾(End of central directory record) - 这个结构在每个档案中都有一份模板, 写在档案的末尾. 它所包含的最有趣的数据就是一些档案的记录(或者说一些文件和目录)以及对中心目录区块起始的本地引用.
这个架构的每个区块都可以用一个常规的结构或者一个任意长度的字节数组来表示. 每个结构都可以用一个structure来描述, 它与在MQL编程中的结构同名.
这个结构总是使用固定数量的字节, 所以它不能包含任意长度的数组和数据行. 但是, 它可以含有指向这些对象的指针. 这就是为什么档案的文件名放在结构之外, 这样它们就可以是任意长度. 同样的情况也适用于压缩的数据文件 - 它们的长度是任意的, 所以它们也保存在结构之外. 通过这种方法我们就可以把ZIP档案定义为一定模式, 数据行和压缩数据的序列了.
ZIP文件的格式, 除此之外还定义了其他结构, 称为 数据描述(Data Descriptor). 此结构只在一定情况下使用, 就是当本地文件头结构因为某些原因未能创建, 而在数据压缩后还是需要本地文件头中的部分数据时. 在实际应用中, 这种情况很少出现, 所以这个结构几乎不会被用到, 在我们的用于操作档案数据块的类中也不支持此功能.
| 请注意, 根据ZIP档案的格式, 每个文件的压缩都是相互独立的. 一方面, 这样可以定位出错的部位, 一个"损坏"的档案可以通过删除有错误的内容而保留其余内容的方法进行修复. 另一方面, 当独立压缩每个文件时, 压缩效率会降低, 特别是在每个文件都占用很小空间的情况下. |
|---|
1.2. 在十六进制编辑器中研究ZIP文件
通过学习所需的知识, 我们可以看到一个典型的ZIP档案都包含什么. 为此, 我们将使用一个十六进制编辑器WinHex. 如果由于某些原因您没有WinHex, 您可以使用任意其他的十六进制编辑器. 毕竟, 我们都记得任何胆敢都是一个二进制文件, 可以当作一个简单的字节序列打开. 作为一个实验, 我们将创建一个包含单个文本文件的ZIP档案, 文本文件的内容就是一个短语"HelloWorld!":
程序中创建一个文本文件")
图 2. 在写字板(Notepad)程序中创建一个文本文件
然后我们将使用任意一个ZIP压缩工具创建一个档案. 在我们的例子中将使用 WinRAR. 需要选择我们刚刚创建的文件并把它以ZIP格式加入到档案中:
图 3. 使用 WinRAR 压缩工具创建一个档案
在我们把档案存到计算机磁盘上之后, 在对应目录中会出现一个新的文件"HelloWorld.zip". 这个文件第一个奇怪的特征就是它有135个字节大, 明显大于源文本文件的11个字节. 这是因为除了压缩数据之外, ZIP档案还包含了服务信息. 所以, 对于只有几百字节的少量数据进行压缩归档是没有多大意义的.
现在我们有了数据布局结构, 这个档案只包含少量数据, 我们就不会被它吓到了. 我们将使用十六进制编辑器WinHex打开它. 下图显示了档案的字节数组, 在Scheme 1中描述的每个部分都有高亮显示:
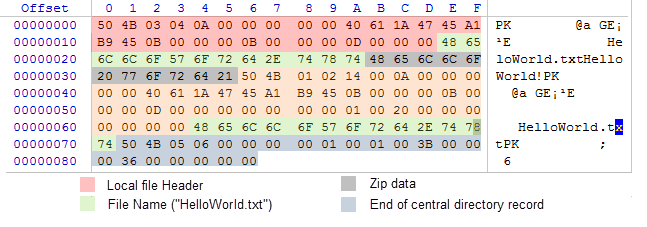
图 4. 包含HelloWorld.txt的ZIP档案的内部内容
实际上, "HelloWorld!"短句在从0x35到0x2B字节范围内, 只占用11个字节. 请注意, 我们决定使用的压缩算法是不对原始短句进行压缩, 所以ZIP档案以其最初形式显示. 这是因为压缩这样短的信息是不够经济的, 压缩后的数组可能比没有压缩的还要长.
| 一个ZIP档案并不总是包含压缩的数据. 有些时候归档的数据会保持其原始, 未压缩的形式, 哪怕在档案创建时, 明确声明了归档时压缩数据. 当数据量较小, 数据压缩不划算的时候就会发生这种情况. |
|---|
如果您看一下图4, 就可以很清楚看到压缩的档案中数据块是如何存放的, 文件数据在何处保存. 现在是时候单独分析每个数据块了.
1.3. 本地文件头的结构
每个ZIP档案的开头都是本地文件头. 它包含了文件的元数据, 其后是压缩的字节数组. 根据格式规格, 每个档案结构都有其唯一的四字节标识符. 此结构也不例外, 它的唯一标识符等于0x04034B50.
您应该知道, 基于x86架构的处理器从二进制文件载入数据到内存时, 字节顺序是相反的. 数字在其中是这样分布的: 处理器的最后一个字节放置数字的第一个字节, 反之亦然. 在文件中写入数据的方法也是由文件格式决定的, 对于ZIP文件, 写入的顺序也是相反的. 如需了解更多关于字节顺序的信息, 请阅读来自维基百科的文章 - "字节顺序(Endianness)". 对于我们来说, 结构的标示符将被写成0x504B0304 (内在真实数值是 0x04034B50). 任何 ZIP 档案都以此字节序列开始.
因为此结构是以这样的字节序列定义的, 在MQL5编程语言中也可以用相同的结构来表示. 在MQL5中对本地文件头的描述如下:
//+------------------------------------------------------------------+ //| 基于 6.3.4 规格的本地文件头: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // ZIP 本地文件头, 永远等于 0x04034b50 ushort version; // 解压的最小版本号 ushort bit_flag; // 位标志 ushort comp_method; // 压缩方法 (0 - 未压缩, 8 - 紧缩) ushort last_mod_time; // 文件修改时间 ushort last_mod_date; // 文件修改日期 uint crc_32; // CRC-32 哈希值 uint comp_size; // 压缩大小 uint uncomp_size; // 未压缩大小 ushort filename_length; // 文件名长度 ushort extrafield_length; // 额外数据的长度栏位 bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
这个结构用于ZIP档案的实际操作, 所以除了它包含的数据栏位之外, 它还含有额外的方法来把结构转换为字节集合(uchar字节数组), 以及对应的从字节集合创建结构. 以下就是用于这些转换的ToCharArray和LoadFromCharArray方法:
//+------------------------------------------------------------------+ //|把LocalHeader转换为字符数组的内部结构 | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // ZipLocalHeader的大小 }; //+------------------------------------------------------------------+ //| 把 ZipHeader 结构转换为字符数组. | //| 返回: | //| 复制元素的数量. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| 从字符数组获得LocalHeader结构 | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
让我们描述一下结构的栏位 (按顺序排列):
- header — 唯一结构标识符, 对于本地文件头(Local File Header)等于 0x04034B50;
- version — 用于解压文件的最低版本;
- bit_flag — 字节标志, 等于 0x02;
- comp_method — 使用的压缩类型. 通常情况下压缩方法是紧缩(DEFLATE), 标识号为0x08.
- last_mod_time — 文件最新修改时间. 它是以MS-DOS的格式表示的文件修改的小时数, 分钟数和秒数. 格式描述在微软公司网站上.
- last_mod_date — 文件最新修改日期. 它是以MS-DOS的格式表示的文件修改的日, 月, 年.
- crc_32 — CRC-32 校验和. 它是程序用于定位档案中错误内容的. 如果此栏位为空, ZIP档案就不会解开损坏的压缩文件.
- comp_size — 压缩数据大小的字节数;
- uncomp_size — 原始数据大小的字节数;
- filename_length — 文件名的长度;
- extrafield_length — 用于记录数据属性的特殊栏位. 它几乎从不使用, 等于0.
当把此结构保存到档案时, 就会根据结构的对应栏位创建一个字节序列来保存其内容. 我们将在十六进制编辑器中重新载入含有HelloWorld.txt的ZIP档案, 这一次我们会彻底分析这个结构的字节数组:

图 5. HelloWorld.zip 档案的本地文件头结构的字节图表
图表中显示了结构的栏位中填充的是哪些字节. 为了验证它的数据, 我们要注意"文件名称长度"栏位, 它占两个字节, 等于0x0D00. 把这个数字字节反转并把它转为10进制, 我们就得到了13 - 这也等于"HelloWorld.txt"的字符数量. 使用同样的方法, 我们也能得到压缩数据的大小. 它等于0x0B000000, 也就是11 个字节. 事实上, "HelloWorld!" 短语以未压缩的形式保存在档案中, 正好占用11个字节.
这个结构的后面就是压缩的数据, 再往后是一个新的结构 - 中心目录(Central Directory), 在下面的部分中我们将详细介绍.
中心目录的结构是本地文件头数据的扩展. 实际上, 操作ZIP档案数据的基本工作, 使用本地文件头就足够了. 但是, 使用中心目录结构是必须的, 它的数值必须正确填充. 这个结构的唯一标识符等于0x02014B50. 在MQL5中, 它可以如下表示:
//+------------------------------------------------------------------+ //| 中心目录(Central directory)结构 | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // 中心目录头, 永远等于 0x02014B50 ushort made_ver; // 创建版本 ushort version; // 解压的最小版本号 ushort bit_flag; // 位标志 ushort comp_method; // 压缩方法 (0 - 未压缩, 8 - deflate) ushort last_mod_time; // 文件修改时间 ushort last_mod_date; // 文件修改日期 uint crc_32; // CRC32 哈希 uint comp_size; // 压缩大小 uint uncomp_size; // 未压缩大小 ushort filename_length; // 文件名长度 ushort extrafield_length; // 额外数据的长度栏位 ushort file_comment_length; // 文件注释长度 ushort disk_number_start; // 磁盘起始编号 ushort internal_file_attr; // 内部文件属性 uint external_file_attr; // 外部文件属性 uint offset_header; // 本地文件头相对偏移 bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
您可以看到, 它已经包含了更多的数据, 它们中的大多数都与本地文件头重复. 和之前的结构一样, 它也包含服务方法以把它和字节数组相互转换.
我们定义它的栏位:
- header — 唯一标识符, 等于 0x02014B50;
- made_ver — 用于归档的归档标准版本;
- version — 文件解压缩所需的最低标准版本;
- bit_flag — 字节标志, 标识符为 0x02;
- comp_method — 使用的压缩类型. 一般情况下, 会使用 DEFLATE 压缩方法, 这种压缩类型的标示符是0x08.
- last_mod_time — 文件最新修改时间. 它是以MS-DOS的格式表示的文件修改的小时数, 分钟数和秒数. 格式描述在微软公司网站上.
- last_mod_date — 文件最新修改日期. 它是以MS-DOS的格式表示的文件修改的日, 月, 年.
- crc_32 — CRC-32 校验和. 它是程序用于定位档案中错误内容的. 如果此栏位为空, ZIP档案就不会解开损坏的压缩文件.
- comp_size — 压缩数据大小的字节数;
- uncomp_size — 原始数据大小的字节数;
- filename_length — 文件名的长度;
- extrafield_length — 用于记录数据属性的特殊栏位. 它几乎从不使用, 等于0.
- file_comment_length — 文件描述长度;
- disk_number_start — 归档时磁盘编号起始. 几乎永远等于0.
- internal_file_attr — MS-DOS 格式的文件属性;
- external_file_attr — MS-DOS 格式的扩展文件属性;
- offset_header — 本地文件头结构的偏移地址.
当在档案中保存此结构时, 会创建一个字节序列以保存它的栏位. 图6中显示的是此结构的字节布局:

图 6. HelloWorld.zip档案的中心目录结构字节图表
和本地文件头不同, 中心目录结构在顺序上是连续的. 它第一部分的起始地址在最后的数据块 - ECDR 结构中指定. 下一阶段会提供这个结构的详细信息.
一个ZIP文件的结尾就是中心目录记录末尾(或简写为 ECDR). 它的唯一标识符等于0x06054B50. 每个文档都有一份这个结构的拷贝. ECDR 保存着档案中的文件和目录, 以及中心目录的起点地址和它们的总长度. 另外, 这个数据块还存储着其他信息. 这里是MQL5中对ECDR的完整描述:
//+------------------------------------------------------------------+ //| 中心目录末尾(ECDR)结构 | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // ECDR标识符, 永远等于 0x06054b50 ushort disk_number; // 本磁盘的编号 ushort disk_number_cd; // 中心目录起点的磁盘编号 ushort total_entries_disk; // 中心目录在磁盘上的记录数量 ushort total_entries; // 中心目录的记录总数 uint size_central_dir; // 中心目录的大小 uint start_cd_offset; // 起始磁盘编号 ushort file_comment_lengtt; // 文件注释长度 string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
我们来详细描述此结构的栏位:
- header — 唯一结构标识符, 等于 0x06054B50;
- disk_number — 磁盘编号;
- disk_number_cd — 中心目录开始的磁盘编号;
- total_entries_disk — 在中心目录中记录的总数(文件和目录的数量);
- total_entries — 所有记录的数量(文件和目录的数量);
- size_central_dir — 中心目录部分的大小;
- start_cd_offset — 中心目录部分起点的字节地址;
- file_comment_length — 档案注释的长度.
当在档案中保存此结构时, 会创建一个字节序列以保存它的栏位. 以下是结构的字节布局:

图 7. ECDR 结构的字节图表
我们将使用此数据块来确定数组中元素的数量.
第二章. CZip 类与之算法概览
2.1. 档案内压缩文件, CZipFile 和 CZipFolder 类的结构
就这样, 在第一章中, 我们已经学习了ZIP档案的格式. 我们已经分析过, 它包含了哪些类型的数据, 以及把这些数据类型定义为相关的结构. 在定义了这些类型之后我们将会实现一个高级的专用类CZip, 它可以简单快速地用于执行以下ZIP档案的操作:
- 创建一个新的档案;
- 开启一个在硬盘上之前创建的档案;
- 从远程服务器下载档案;
- 在档案中增加新的文件;
- 在档案中删除文件;
- 解开整个档案或者单独展开某些文件.
CZip 类可以用于通过提供我们通用的用于操作文件档案集合的高级接口来正确完成档案的必要结构. 这个类提供了与操作档案任务相关的多种接口.
很明显, ZIP档案的内容可以分为文件夹和文件. 这两种内容都有一系列扩展的特性: 名称, 大小, 文件 属性, 创建时间等等. 这些属性中的一部分是文件夹和文件所共有的, 另外一些, 例如压缩数据就不是这样了. 使用档案的优化方案将是提供特别的服务类:CZipFile 和 CZipDirectory. 这些类分别对应着文件和文件夹的服务. 档案内容的条件分类在以下图表中显示:
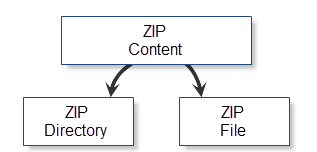
图 8. 档案对象的条件分类
所以, 要在一个CZip档案中增加文件, 您必须首先创建一个CZipFile类型的对象, 然后把这个对象文件加到档案中. 作为实例, 我们将创建一个文本文件"HelloWorld.txt", 它包含着与名称相同的文字"HelloWorld!", 然后把它加到档案中:
//+------------------------------------------------------------------+ //| 使用 'HelloWorld' 消息创建文件 | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // 我们创建一个空白ZIP档案 uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // 我们把 "HelloWorld!" 短语写到字节数组中 CZipFile* file = new CZipFile("HelloWorld.txt",content); // 我们使用 "HelloWorld.txt" 作为名称创建ZIP文件 // 其中包含字节数组 "HelloWorld!" zip.AddFile(file); // 把ZIP文件加到档案中 zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // 我们把档案保存到磁盘中并命名为 "HelloWorld.zip" printf("文件大小: "+(string)zip.Size()); }
在计算机上执行了此代码之后, 包含了这个单个"HelloWorld.txt"文本文件的新的同名ZIP档案将会出现. 如果我们想创建一个文件夹而不是文件, 我们就需要创建一个CZipFolder类的拷贝, 用它替换CZipFile. 为了这个目标, 我们只需要指定它的名称就足够了.
我们已经说过, CZipFile和CZipFolder类有很多共同之处. 因而, 这两个类都继承于它们共同的父类 — CZipContent. 这个类包含了通用的数据和方法用于处理档案的内容.
2.2. 使用CZipFile创建压缩文件
创建一个压缩的ZIP文件和创建一个CZipFile的拷贝是一样的. 我们已经知道, 为了创建一个文件, 您必须指定它的名称和内容. 所以, CZipFile 的创建需要明确指定相关参数:
//+------------------------------------------------------------------+ //| 根据文件数组和名称创建ZIP文件 | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
在 2.1 章节, 显示了对这个构造函数的调用方式.
另外, 有时候并不需要创建文件, 而是从磁盘上下载一个已经存在的文件. 这种情况下, 就需要CZipFile类具有另外的构造函数来用于基于硬盘上的普通文件来创建一个ZIP文件:
//+------------------------------------------------------------------+ //| 根据文件数组和名称创建ZIP文件 | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
这个构造函数的工作都指派到AddFile私有方法中. 它的操作算法如下:
- 被指定的文件被打开用于读取, 它的内容被读取到字节数组中.
- 得到的字节数组使用AddFileArray方法进行压缩, 并保存到一个特别的uchar类型的动态数组中.
AddFileArray 方法是整个操作档案的类系统的"核心". 而这个方法中就有最重要的系统函数 - CryptEncode. 这里是这个方法的源代码:
//+------------------------------------------------------------------+ //| 添加文件数组并压缩它 | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
CryptEncode 函数的配置使用黄色标示, 之后是字节数组的档案. 这样, 我们就可以确定在创建CZipFile对象时就进行了文件的压缩, 而不是在ZIP档案的创建或存储时进行的了. 因而, 所有传输到CZip类的数据会自动压缩, 这样在存储时只需要较少的内存.
请注意, 所有情况下都使用无符号字节(uchar)数组来保存数据. 实际上, 我们在计算机上操做的所有数据都可以用一定的字节序列来表示. 所以, 为了创建一个真正通用的压缩数据容器, 就像CZipFile这样的, 我们选择了无符号字节(uchar)数组.
| 用户必须自己把数据转换成uchar[]无符号字节数组以便归档, 之后数据会以引用的方式作为文件内容传给CZipFile类. 正因为这个特性针对任何类型的文件, 所以不论是从磁盘下载的还是使用MQL程序运行创建的, 都可以放到ZIP档案中. |
|---|
数据展开是更简单的工作. 要把数据展开到基本的字节数组file_array中, 可以使用GetUnpackFile方法, 它本质上是CryptDecode系统函数的封装方法:
//+------------------------------------------------------------------+ //| 取得展开的文件. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. 记住 MS-DOS. ZIP 档案内的时间和日期格式
ZIP 格式的数据存储创立于上世纪80年代末的MS-DOS平台, 之后才有了它的"合法继承者"Windows. 当时数据存储的资源非常有限, 所以MS-DOS操作系统的日期和时间是分开存储的: 2个字节(或者当时16位处理器的一个word)用于日期而另外两个字节用于时间. 而且, 用这种格式标示的最早的日期是1980年1月1日 (01.01.1980). 分钟, 小时, 日, 月和年都占用着word的一定字节范围, 从中展开或者构造数据都要进行一些位操作.
这种格式的规格说明在微软网站的如下链接可以找到: https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx.
这里就是对应双字节栏位的数据存储格式:
| 字节序号 | 描述 |
|---|---|
| 0-4 | 日期 (0-31) |
| 5-8 | 月份编号 (1 — 一月, 2 — 二月 等等.) |
| 9-15 | 从1980 开始的年份编号 |
表格 1. 双字节栏位中日期存储的格式
同样, 我们来看一下双字节栏位中时间的存储格式:
| 字节序号 | 描述 |
|---|---|
| 0-4 | 秒 (保存精确度 +/- 2 秒) |
| 5-10 | 分钟 (0-59) |
| 11-15 | 24小时格式的小时数 |
表格 2. 双字节栏位中时间的存储格式
知道了这种格式的规格并且进行位的操作计算后, 您就可以写出对应的函数来把日期和时间从MQL格式转换到MS-DOS格式了. 也可以进行相反方向的转换. 这样的转换技术在使用CZipFolder的文件夹和使用CZipFile的文件中是一样的. 通过在其中使用MQL格式来设置日期和时间, 我们可以在其内部把这种类型的数据转换为MS-DOS格式. 其中的 DosDate, DosTime, MqlDate 和 MqlTime 方法都包含在这样的转换中. 请参照以下的源代码.
从 MQL 格式到 MS-DOS 数据格式的转换:
//+---------------------------------------------------------------------------------+ //| 以 MS-DOS 格式获得日期. 规格说明链接: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
把日期从 MS-DOS 格式转换到 MQL 格式:
//+---------------------------------------------------------------------------------+ //| 以 MQL 格式取得数据. 规格说明链接: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
把时间从 MS-DOS 格式转换到 MQL 格式:
//+---------------------------------------------------------------------------------+ //| 以MS-DOS格式取得时间. 规格说明链接: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
把时间从 MS-DOS 格式转换到 MQL 格式:
//+---------------------------------------------------------------------------------+ //| 以 MQL 格式取得数据. 规格说明链接: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
这些方法使用内部变量来保存日期和时间: m_directory.last_mod_time 和 m_directory.last_mod_date, 其中 m_directory 是中心目录结构类型.
2.4. 生成 CRC-32 校验和
ZIP档案格式中一个有趣的特性是, 它不仅存储服务数据, 还有一种用于修复功能的特殊信息, 它可以用于恢复损坏的数据. 为了了解接收到的数据是完好无损还是被破坏了, ZIP档案还有特殊栏位包含了两个字节大小的CRC-32哈希值. 这是计算所得的数据压缩前的校验和. 在归档程序从档案中解压缩数据时, 它会重新计算校验和, 如果不能匹配, 就会认为数据是损坏的并且不能提供给用户.
所以, 我们的CZip类需要有自己的CRC-32计算算法. 否则, 使用我们的类创建的档案会无法被第三方工具读取, 例如WinRAR会报错, 警告那是损坏的数据:
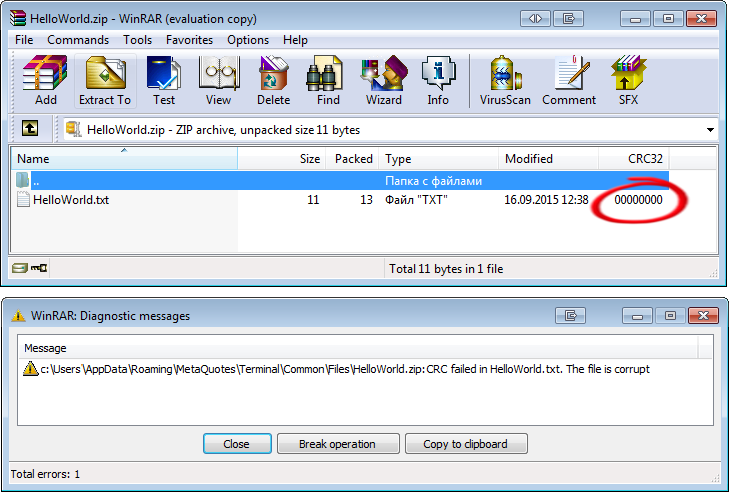
图 9. WinRAR 警告 "HelloWorld.txt" 文件已经损坏.
因为CRC-32校验和只是在文件中需要, 所以只是在CZipFile类中提供了计算校验和的方法. 本方法是基于以下的C语言编程实例实现的: https://ru.wikibooks.org:
//+------------------------------------------------------------------+ //| 返回源数据数组的 CRC-32 和 | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
为了确认方法运行正确, 只需要在WinRAR中打开一个使用CZip创建的档案就可以了. 每个文件都有它唯一的 CRC-32 代码:

图 10. WinRAR 归档工具窗口中的CRC-32校验和
归档程序可以在正常模式下使用有效的CRC-32哈希解开文件, 警告信息就不会出现了.
2.5. 档案的读写
最后, 我们将讨论ZIP档案的读写. 显然, 如果我们有一个集合, 例如CArrayObj, 包含了CZipFile和CZipFolder的元素, 档案信息就不会有什么问题了. 只需要把每个元素转换成一个字节序列再把它写入文件. 以下的方法就是处理此类任务的:
- SaveZipToFile — 打开指定的文件并把它写到档案的字节数组中.
- ToCharArray — 创建对应档案的字节结构. 生成最终的 ECDR 结构.
- ZipElementsToArray — 把 CZipContent 元素类型转换为字节序列.
唯一的难点是, 使用CZipContent类型表示的档案元素都被存储到两个不同的文件部分, 也就是本地文件头结构和中心目录. 所以需要调用一个特殊方法ZipElementsToArray, 它会根据传给它的 ENUM_ZIP_PART 设置来提供本地文件头或者中心目录类型的字节数组.
现在, 知道了这个特性后我们就能够更好地了解这三种方法构成的内容, 它们的源代码如下:
//+------------------------------------------------------------------+ //| 返回 ZIP 元素的uchar数组 | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| 以uchar数组方式生成ZIP档案. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| 把ZIP档案保存到文件 zip_name 中 | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
档案的读取有些细微差别需要考虑. 显然, 这是一个与存储相反的操作. 如果我们保存档案时, CZipContent类型的元素被转换为字节序列, 那么在载入档案时, 字节序列就应该被转换为CZipContent类型的元素. 同样地, 因为每个档案元素被保存于两个不同的文件部分 - 本地文件头和中心目录, CZipContent元素无法从一段数据读取到.
需要一个中间容器类CSourceZip, 首先按顺序把必要的元素读取出来, 然后再确定数据的类型 - CZipFile 或是 CZipFolder. 这也就是为什么这两个类有额外的构造函数, 它们都接受一个CSourceZip元素类型的指针作为引用参数. 这种类型的初始化, 以及CSourceZip类, 只是为了在CZip类中使用的, 不推荐直接使用它们.
用于载入数据的三个 CZip 类方法:
- LoadZipFromFile — 打开指定的文件并把内容读取到字节数组中.
- LoadHeader — 从档案的字节数组中根据地址载入本地文件头结构.
- LoadDirectory — 从档案的字节数组中根据地址载入中心目录结构.
以下请参照这些方法的源代码:
//+------------------------------------------------------------------+ //| 从文件中载入本地文件头. | //| 返回: | //| 返回本地文件头地址, 名称和zip内容. | //| 如果读取失败返回-1. | //+------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //复制本地文件头 uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //复制文件名 ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //复制zip数组 ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+------------------------------------------------------------------+ //| 从文件中载入中心目录. | //| 返回: | //| 返回中心目录地址和名称 | //| 如果读取失败返回-1. | //+------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //复制中心目录 uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //复制目录文件名 ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+------------------------------------------------------------------+ //| 从硬盘上的文件载入ZIP档案. | //+------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
第三章. 使用CZip类的实例, 效率衡量
在前面的章节中, 我们已经分析了CZip类和ZIP档案的数据格式. 现在我们知道了档案的结构和CZip类的一般原则, 我们可以继续进行与归档相关的任务了. 在本章中我们将分析三种不同的例子来掌握这个类的全部功能.
3.1. 引用全部选择的字符创建ZIP档案
第一个经常需要解决的任务是保存之前取得的数据. 通常数据是在MetaTrader终端中获得的. 这样的数据可以是一系列OHLCV格式的订单和报价数据. 我们会研究这种情形, 当报价被保存为特定的CSV文件时, 它的格式如下:
日期;时间;开盘价;最高价;最低价;收盘价;成交量 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
这是文本数据格式. 它经常用于在不同统计分析系统之间传递数据. 很不幸的是, 文本文件的格式在数据存储上有很大的冗余, 因为每个字节只能用于很有限数量的字符. 一般情况下, 只有标点, 数字, 字母表上的大小写字符. 另外, 这种格式中很多数值是频繁出现的, 例如, 在一个较大的数据数组中, 开盘日期或者价格通常很多是相同的. 因而, 这种数据压缩会是很有效率的.
那就让我们写一个脚本程序来从终端下载所需的数据吧. 它的算法如下:
- 按顺序选择在市场报价窗口中的交易品种.
- 对于每个选定的交易品种, 每21个时段请求一次报价.
- 选定时段的报价被转换为一行CSV数组形式.
- CSV行数组转换为字节数组.
- 然后创建一个ZIP文件(CZipFile)包含报价的字节数组, 再把它添加到档案中.
- 在创建了所有的报价文件后, 把CZip保存到计算机磁盘上并命名为Quotes.zip.
执行这些工作的脚本程序源代码提供如下:
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // 创建空白ZIP档案. //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| 根据市场报价从中创建ZIP | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
就算只有四个交易品种在市场报价中选中, 载入数据也会花费相当长的时间. 另外, 我们将只载入最近100个柱. 这也能缩短脚本程序的执行时间. 当它执行过后, 在MetaTrader的共享文件目录中就会出现Quotes.zip. 它的内容可以在任何归档程序中看到, 例如WinRAR:
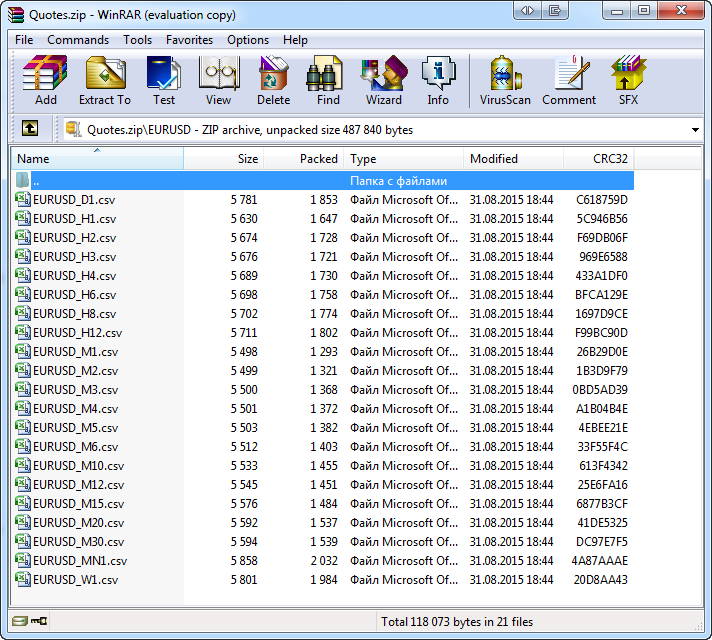
图 11. 在WinRAR程序中查看保存的报价文件
创建的文件和它之前的大小相比压缩了3倍. 此信息是由WinRAR提供的:
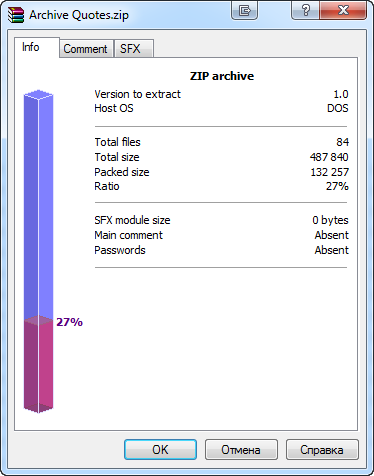
图 12. 在WinRAR信息窗口中看到的生成文件的压缩率
这是压缩得到的好结果. 然而, 如果有更多的数字文件, 压缩率会更好.
这个创建报价并把它们保存到ZIP档案中的脚本程序实例附在本文的附件中, 它的名称是ZipTask1.mq5, 位于 Scripts 文件夹中.
3.2. 从远程服务器下载档案, 使用MQL5.com作为例子
下一个我们将要学习的任务是网络相关的. 我们的实例将会展示, 您如何从远程服务器上下载ZIP档案作为例子, 我们将会载入叫做Alligator的指标, 它的源代码在代码库中, 链接为https://www.mql5.com/en/code/9:
对于发布在代码库中的每个指标, EA交易, 脚本程序或者函数库, 都有一个归档的版本, 其中产品的源代码都压缩到一个单个的文档中. 我们将在本地计算机上下载并解开这个归档版本. 在我们执行此任务之前, 您必须允许访问mql5.com: 在 服务->设置->EA交易的窗口中, 把如下地址"https://www.mql5.com"写到允许访问的服务器列表中.
CZip 类中有自己的方法来从互联网资源中下载档案. 但是我们会用自己的脚本而不是用它的方法来载入档案:
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/en/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("无法下载ZIP档案, 链接: "+mql_url+". 请检查EA的许可."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("下载了损坏的ZIP档案. 请检查结果数组."); return; } printf("成功载入档案. 总文件数: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
您可以看到, 脚本程序的源代码非常简单. 一开始, 使用远程ZIP档案的地址调用WebRequest. WebRequest 会载入档案的字节数组, 并传输到目标数组zip_array中, 然后它使用 CreateFromCharArray 方法把它载入到CZip类中. 通过这种方法, 可以从字节序列直接创建档案, 而这在互联网上操作档案时是需要用到的.
除了CreateFromCharArray方法之外, CZip类还有一个特别的LoadZipFromUrl方法来从网络链接来直接下载档案. 它的运行和我们前面的脚本程序类似. 这里是源代码:
//+------------------------------------------------------------------+ //| 从 url 载入ZIP档案 | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
这种方法的运行结果是相同的: 在一段时间后, 会创建一个ZIP档案, 而它的内容是从远程服务器上下载的.
从代码库下载档案的示例脚本程序附加在本文中, 名称是ZipTask2.mq5, 位于Scripts 文件夹.
3.3. 把程序的服务数据压缩到内存中
把程序的内部数据压缩到内存中是使用归档的一种较少的用法. 当内存中有很多处理的数据时, 可以使用这种方法. 然而, 当使用这种方法时, 整个程序的效率会降低, 因为需要额外的工作来进行数据结构的归档/解压.
让我们考虑这样的MQL程序, 它保存历史订单的集合. 每个订单都使用一个特定的Order结构来定义, 它包含所有的属性: 编号, 订单类型, 执行时间, 交易量, 等等. 我们将如下定义此结构:
//+------------------------------------------------------------------+ //| 历史订单 | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // 订单编号 datetime time_setup; // 订单设置时间 ENUM_ORDER_TYPE type; // 订单类型 ENUM_ORDER_STATE state; // 订单状态 datetime time_exp; // 过期时间 datetime time_done; // 完成时间或者取消的订单 long time_setup_msc; // 订单设置时间(msc) long time_done_msc; // 订单完成时间(msc) ENUM_ORDER_TYPE_FILLING filling; // 执行类型 ENUM_ORDER_TYPE_TIME type_time; // 类型时间 ulong magic; // 订单幻数 ulong position_id; // 仓位ID double vol_init; // 初始交易量 double vol_curr; // 当前交易量 double price_open; // 建仓价格 double sl; // 止损水平 double tp; // 获利水平 double price_current; // 当前价格 double price_stop_limit; // 挂单水平 string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| 根据订单编号初始化 | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| 返回订单注释 | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| 返回订单的交易品种 | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| 设置订单注释 | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| 设置订单交易品种 | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| 把订单转换为uchar数组. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| 把uchar数组转换为Order结构 | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
调用sizeof操作符显示, 这个结构占用 200 个字节. 通过这种方法, 历史订单集合的存储字节数可以通过以下公式计算: sizeof(Order) * 历史订单数量. 结果, 对于包含1000个历史订单的集合, 我们将需要以下的内存大小: 200 * 1000 = 200 000 字节 或者几乎 200 KB. 对于当今来说这不算多, 但是如果集合的大小超过了数以万计的元素, 使用内存的数量就会变得严重了.
然而, 我们可以开发一个特殊的容易来保存这些订单, 它允许压缩订单内容. 这个容器, 除了传统的用于增加和删除Order元素的方法之外, 还含有Pack和Unpack方法, 用于压缩Order结构类型的内容. 这里是容器的源代码:
//+------------------------------------------------------------------+ //| 订单容器. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| 返回打包状态. | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| 增加新订单. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| 根据索引返回订单. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| 返回订单总数. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| 根据索引删除订单. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| 返回打包状态. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| 返回打包状态. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| 返回订单大小. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
这里的思路是, 用户可以在容器中增加新元素, 并且如果需要可以直接在计算机的内存中压缩它的内容. 让我们看它是如何工作的. 这里是一个演示脚本程序:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="解压大小: "+(string)unpack_size+"字节; "+ "压缩大小: "+(string)pack_size+" 字节 ("+per+" %压缩率. "+ "压缩执行时间(微秒): "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("第一个订单编号: "+(string)first.ticket); } } //+------------------------------------------------------------------+
压缩集合的时刻使用黄色高亮标记. 在一个有858个历史订单的账户中运行此脚本程序, 得到了如下的结果 :
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) 解压大小: 171600 bytes; 压缩大小: 1521 bytes (0.89 %压缩率. 压缩执行时间(微秒).: 2534
您可以看到, 没有压缩的集合大小是 171,600 字节. 而压缩后集合的大小变成只有1521 字节, 这意味着压缩了超过100倍!这是因为很多结构的栏位都包含着同样的数据. 而且很多栏位是空值, 但是内存还是被分配了.
为了确认压缩执行正确, 您需要从集合中选择任意订单并打印它的属性. 我们已经选择了第一个订单和它的编号. 在压缩后, 订单编号能够正确显示:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) 第一个订单编号: 10279280
上述的算法在解压之前压缩的集合时会降低效率. 所以, 数据只有在它的工作完成后才应该被压缩. 为了取得更好的压缩率, 所有数据都放到一个数组中再压缩. 解压的过程是相反的.
有趣的是, 压缩858个元素在功能强大的计算机上只需要2.5毫秒. 解压相同的数据更快, 只需要大约0.9毫秒. 因而, 对含有数千元素的数组进行压缩/解压循环大约需要3.5-4.0毫秒. 这使我们省下了上百倍的内存空间. 这些特点使得使用ZIP方式压缩和组织大量数据非常可观.
在计算机内存中压缩数据的脚本程序实例可以在本文附件中找到, 它的名称是ZipTask3.mq5 并且位于Script 文件夹. 另外, Orders.mqh位于Include文件夹, 也是必需的.
第四章. 操作ZIP档案类的文档
4.1. CZipContent 类的文档
本章描述了用于操作ZIP档案类中的方法和枚举. CZipContent 类在用户级别没有直接使用, 它的共有方法都是给CZipFile和CZipFolder来继承的, 所以它属性和方法的描述也适用于这些类.
ZipType() 方法
ZipType 方法返回档案中当前元素的类型. 档案中有两种元素类型: 文件夹 (目录) 和文件. 文件夹类型以CZipDirectory 类表示, 而文件类型对应 - CZipFile 类. 如需取得ZIP档案类型的更多信息, 您可以阅读本章的2.1节: "档案内压缩文件的结构, CZipFile 和 CZipFolder 类".
ENUM_ZIP_TYPE ZipType(void);返回值
它返回 ENUM_ZIP_TYPE 枚举, 它定义了当前 CZipContent 数据的类型.
Name 方法(void)
它返回档案中的文件夹名或者文件名.string Name(void);
返回值
文件名或文件夹名.
Name(string name) 方法
它用于设置档案中当前文件夹或者文件的名称. 它可以用于修改当前文件夹或者文件的名称.
void Name(string name);
参数:
- [in] name — 文件夹或者文件的新名称. 名称必须是唯一的, 不能和档案中其他文件重名.
CreateDateTime 方法 (datetime date_time)
它设置档案中文件夹或者文件的新的日期.
void CreateDateTime(datetime date_time);
参数:
- [in] date_time — 需要设置的当前文件夹或文件的日期和时间.
注意:
日期和时间会转换为 MS-DOS 格式, 并保存于ZipLocalHeader 和 ZipCentralDirectory 类型的内部结构中. 为了获得这种格式转换和表示的更多信息, 请阅读本文的2.3节: "记住 MS-DOS. ZIP档案中的时间和日期格式".
CreateDateTime 方法 (void)
它返回当前文件夹或文件的修改日期和时间.
datetime CreateDateTime(void);
返回值
当前文件夹或文件的修改日期和时间.
CompressedSize()方法
它返回文件中压缩数据的大小, 对于目录永远返回0.
uint CompressedSize(void);
返回值
压缩数据的字节数.
UncompressedSize() 方法
它返回文件原本未压缩数据的大小, 对于目录永远返回0.
uint UncompressedSize(void);
返回值
原始数据字节数.
TotalSize() 方法
它返回档案中元素的总的大小. 档案中的每个文件和目录, 包括它的名字和内容(对于文件), 保存的额外的服务结构, 它们的大小都在计算之内.
int TotalSize(void);
返回值
当前档案中元素和额外服务数据的总大小.
FileNameLength() 方法
它返回目录或者文件名称的字符数.
ushort FileNameLength(void);
返回值
目录或者文件名称的字符长度.
UnpackOnDisk()方法
它解开元素的内容并把它们根据元素的名称保存到磁盘的文件中. 如果目录被解压缩, 就会创建一个对应的目录.
bool UnpackOnDisk(string folder, int file_common);
参数
- [in] folder — 将要压缩的目录或者文件所在根目录的名称. 如果在解压缩时不需创建目录, 这个参数可以设为空, 等于"".
- [in] file_common — 这个参数指出MetaTrader程序在展开档案的元素时目标为文件系统的哪个部分. 如果您打算在MetaTrader 5终端的通用文件部分解压缩, 就请把这个参数设为FILE_COMMON..
返回值
如果一个文件或者文件夹成功解压缩, 它返回true. 否则, 它会返回false.
4.2. CZipFile 类的文档
CZipFile 类继承于CZipContent, 用于保存档案的文件. CZipFile 只以压缩的形式存储文件内容. 这就意味着当传输文件用于保存时, 它会自动压缩文件内容. 在调用GetUnpackFile方法时, 也会自动进行解压缩. 除了CZipContent所支持的一些方法之外, CZipFile也有些操作文件的特定方法. 请在下面参考这些方法的描述.
AddFile() 方法
把文件从硬盘上读取并创建为当前的CZipFile元素. 为了把文件添加到CZip档案类型, 您必须首先创建一个CZipFile类的拷贝并指定它的名称和位置. 在类样本创建之后, 将需要调用CZip类中对应的方法把它加入其中. 在添加它们(调用此方法)时会进行实际的压缩和传输内容.
bool AddFile(string full_path, int file_common);
参数
- [in] full_path — 文件的完整名称, 包含它相对MQL程序目录的路径.
- [in] file_common — 此参数指出在MetaTrader 程序的文件系统的哪一部分来展开元素. 如果您打算在MetaTrader 5终端的通用文件部分解压缩, 就请把这个参数设为FILE_COMMON..
返回值
如果成功添加文件, 它会返回true. 否则, 它会返回false.
AddFileArray() 方法
它添加一个 uchar 类型的字节数组作为 CZipFile 的内容. 这个方法用于动态创建文件内容. 在它们被添加时(调用此方法)会进行真正的压缩和内容的传输.
bool AddFileArray(uchar& file_src[]);
参数
- [in] file_src — 需要添加的字节数组.
返回值
如果成功添加文件, 它会返回true. 否则, 它会返回false.
GetPackFile() 方法
它返回压缩文件的内容.
void GetPackFile(uchar& file_array[]);
参数
- [out] file_array — 需要用来接受文件内容的字节数组.
GetUnpackFile() 方法
它返回解压缩的文件内容. 在调用此方法时会解压缩内容.
void GetUnpackFile(uchar& file_array[]);
参数
- [out] file_array — 用于接受解压缩文件内容的字节数组.
4.3. CZip 类的文档
CZip 类实现了ZIP类型档案的主要操作. 本类是一个通用的ZIP档案, 它可以添加两种类型的ZIP元素: 文件夹元素(CZipDirectory)和ZIP文件元素(CZipFile). 其他方面, CZip类允许从计算机的硬盘上载入已经存在的档案, 也可以是字节序列的形式.
ToCharArray() 方法
它把ZIP档案的内容转换为一个uchar类型的字节序列.
void ToCharArray(uchar& zip_arch[]);
参数
- [out] zip_arch — 用于接受ZIP档案内容的字节数组.
CreateFromCharArray() 方法
从字节序列载入ZIP档案.
bool CreateFromCharArray(uchar& zip_arch[]);
参数
- [out] zip_arch — 用于接受ZIP档案内容的字节数组.
返回值
如果从一个字节序列成功创建了档案, 返回true, 否则返回 false.
SaveZipToFile() 方法
它把ZIP档案的当前内容保存为指定的文件.
bool SaveZipToFile(string zip_name, int file_common);
参数
- [in] zip_name — 包含相对MQL程序路径的完整的文件名称.
- [in]file_common - 次参数指出需要在MetaTrader程序文件系统的哪个部分来解压缩元素的数据. 如果您打算在MetaTrader 5终端的通用文件部分解压缩, 就请把这个参数设为FILE_COMMON..
返回值
如果成功把档案保存为文件就返回true, 否则返回false.
LoadZipFromFile() 方法
它从计算机的硬盘上载入档案内容.
bool LoadZipFromFile(string full_path, int file_common);
参数
- [in] full_path — 文件的完整名称, 包含它相对MQL程序目录的路径.
- [in]file_common - 次参数指出需要在MetaTrader程序文件系统的哪个部分来解压缩元素的数据. 如果您打算在MetaTrader 5终端的通用文件部分解压缩, 就请把这个参数设为FILE_COMMON..
返回值
如果成功从文件中载入档案, 返回true, 否则返回false.
LoadZipFromUrl() 方法
它从网络链接url载入档案内容. 为了此方法的正确运行, 需要设置访问所请求资源的许可. 为了了解此方法的详细信息, 请阅读本文的3.2节: "从远程服务器下载档案, 以MQL5.com作为示例."
bool LoadZipFromUrl(string url);
参数
- [in] url — 档案的引用.
UnpackZipArchive() 方法
在指定的目录中展开当前档案的全部文件和目录.
bool UnpackZipArchive(string folder, int file_common);
参数
- [in] folder — 当前档案需要被展开所在的文件夹. 如果不需要创建档案文件夹, 您必须传入null值或者""参数.
- [in] file_common — 此参数指出在MetaTrader 程序的文件系统的哪一部分来展开元素. 如果您打算在MetaTrader 5终端的通用文件部分解压缩, 就请把这个参数设为FILE_COMMON..
返回值
如果档案被成功解压缩, 会返回true, 否则返回false.
Size() 方法
返回档案大小的字节数.
int Size(void);返回值
档案字节数大小.
TotalElements() 方法
返回档案中元素的数量. 档案中的元素可以是目录或者压缩文件.
int TotalElements(void);
返回值
档案中元素的数量.
AddFile() 方法
把一个新的ZIP文件添加到当前档案. 文件必须用CZipFile的形式表示并且在添加到档案之前就创建好.
bool AddFile(CZipFile* file);参数
- [in] file — 将要添加到档案的ZIP文件.
返回值
如果成功添加了文件就返回true, 否则返回false.
DeleteFile()方法
根据在档案中的索引删除CZipFile类型的文件.
bool DeleteFile(int index);
参数
- [in] index — 将要从档案删除的文件的索引.
返回值
如果成功从档案中删除了文件就返回true. 否则返回false.
ElementAt() 方法
根据位置的索引获得CZipFile类型的元素.
CZipContent* ElementAt(int index)const;
参数
- [in] index — 将要获取的文件在档案中的索引.
返回值
位于index索引位置的CZipFile类型的元素.
4.4. ENUM_ZIP_ERROR 的结构以及接收扩展的错误信息
在运行和处理 CZip, CZipFile 和 CZipDirectory 的过程中, 可能出现各种错误, 例如当试图访问一个不存在的文件, 等等. 大多数这些类方法都返回对应的bool型返回值来说明执行是否成功. 如果返回负值 (false) , 您可以取得失败原因相关的详细信息. 失败的原因可以是标准的系统错误, 也可以是操作ZIP档案过程中出现的特殊错误. 为了传递特别错误, 用户错误的传输机制是使用SetUserError函数. 用户错误编号使用 ENUM_ZIP_ERROR 枚举类型设定:
传递 ENUM_ZIP_ERROR
| 数值 | 描述 |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | 传输的用于压缩的文件为空. |
| ZIP_ERROR_BAD_PACK_ZIP | 内部压缩器/解压器错误. |
| ZIP_ERROR_BAD_FORMAT_ZIP | 传来的ZIP文件格式不标准或者已损坏. |
| ZIP_ERROR_NAME_ALREADY_EXITS | 用户想要保存的文件名已经存在. |
| ZIP_ERROR_BAD_URL | 传输链接不是一个ZIP档案, 或者根据终端的设置禁止访问指定的网络资源. |
根据收到的用户错误, 您必须明确使用 ENUM_ZIP_ERROR 枚举值来进行指定. 作为实例, 以下脚本程序演示了操作档案类中出现错误的处理方法:
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf("载入档案时出现系统错误. 错误编号: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("在载入档案时出错: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
以下是本文附件中文件的简要描述:
- Zip\Zip.mqh — 包含用于操作CZip档案的主类.
- Zip\ZipContent.mqh — 包含 CZipContent 核心类, 用于档案的基本元素类: CZipFile 和 CZipDirectory.
- Zip\ZipFile.mqh — 包含用于操作ZIP档案文件的类.
- Zip\ZipDirectory.mqh — 包含用于操做ZIP档案文件夹的类.
- Zip\ZipHeader.mqh — 此文件包含本地文件头, 中心目录和ECDR结构的定义.
- Zip\ZipDefines.mqh — 用于档案类的定义列表, 包括常数和错误编号等.
- Dictionary.mqh — 用于控制添加到档案的文件和文件夹名称唯一性的类. 这个类的操作算法在这篇文章中有所描述 "MQL5秘笈之:采用关联数组或字典实现快速数据访问".
这篇文章中列出的所有文件都应该放到内部目录 <terminal_data_folder>\MQL5\Include. 如需使用这些类, 您必须在项目中包含 Zip\Zip.mqh 文件. 作为实例, 我们将使用一个脚本程序来创建ZIP档案, 并在其中写入一个文本文件, 文件内容是"test"信息:
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // 包含用于ZIP档案操作的全部所需的类 //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // 我们创建一个空白ZIP档案 uchar array[]; // 我们创建一个空白字节数组 StringToCharArray("test", array); // 我们把 "test" 信息转换到字节数组中 CZipFile* file = new CZipFile("test.txt", array); // 我们基于数组创建一个新的ZIP文件, 其名称为"test.txt" Zip.AddFile(file); // 我们把创建好的 'file' ZIP 文件添加到 ZIP 档案中 Zip.SaveZipToFile("Test.zip", FILE_COMMON); // 我们把ZIP档案命名为"Test.zip"并保存到磁盘上. } //+------------------------------------------------------------------+
在执行过这个脚本程序后, 在MetaTrader 5 文件目录下会出现一个新的名为Test.zip的ZIP档案, 其中包含一个文本文件, 内容是"test"的一个词.
| 本文附件中的档案就是使用这里描述的MQL5实现的CZip归档工具创建的. |
|---|
结论
我们已经完整学习了ZIP档案的结构, 也创建了用于操作此种类型档案的类. 这种档案类型开发于上世纪80年代晚期, 但是至今仍然是最流行的数据压缩格式. 这些类的数据可以给交易系统的开发人员带来很大的帮助. 在它的帮助下, 您可以更高效地存储收集到的数据, 不论它是订单历史或是其他交易信息. 其他一些分析数据也常常是压缩格式的. 在这种情况下, 能够操作这些信息, 甚至是压缩状态的, 将会很有帮助.
上面提到的类隐藏了许多操作档案的技术细节, 提供了用户水平的简单易用, 容易理解的操作方法. 和用户了解的其他归档程序一样: 添加以及从档案展开文件, 创建新档案和从已有档案载入文件, 包括发布于远程第三方服务器上的档案. 兼容性的问题已经完全解决, 在MetaTrader中进行归档有关的工作将更加简单和高效.
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/1971
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 机器学习模型的变量评估和选择
机器学习模型的变量评估和选择


 显示支撑/阻力位
显示支撑/阻力位
我遇到一个 CZip 无法解压的压缩包。不过,7ZIP 和 Windows 存档器却能顺利解压。
...
如果您有兴趣了解,我可以通过私人信息将存档文件发送给您。请将存档文件以私人消息的形式发送给我。
请通过私人信息将存档文件发给我。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-01-18_BTCUSDT_ob500.data.zip
在存档正文中(而不是在文件头中)有 cdheader = 0x504b0102;
在下一个日期文件中也有。
header = 0x504b0304; 出现在每个文件的页眉中,即前 4 个字符。
但它也出现在存档正文中,但很少出现。
这里是https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-03-15_BTCUSDT_ob500.data.zip。
我认为有必要只在档案正文中搜索这些标题。
还有一个链接指向一个无法正常解压的大文件。我将它们的大小设置为 0,然后调用程序就会通过这个 0 理解到出现了错误,有必要使用另一个存档器。
也许你能想出更好的办法来代替 0。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip
我整理了超过一定容量(不同文件的容量从 1.7Gb 到 2136507776 - 即几乎达到 MAX_INT=2147483647,数组不能有更多元素)且在输出时被切断的文件(已解压缩)。结果发现,所有这些文件都被标记为错误文件:
但 CZIP 无法控制这一点。我将输出数组的大小清零。
因此,在我的函数中,我可以 100% 保证文件已成功解压缩。
在此之前,我检查了 JSON 文件的正确结尾 }\r\n - 但这一解决方案并不通用,在 ~1000 个文件中,似乎有几个文件被中间行意外截断,并被视为成功解压缩,但其中的数据并不完整。
新版本的函数:
新版本以黄色 标出。
也许开发人员还应该将数组重置为零,因为几乎没有人需要经过修剪的数据。而且可能会导致难以察觉的错误。
还有一个链接指向一个无法正常解压的大文件。我把它们的大小设置为 0,然后调用程序就会通过这个 0 理解到出现了错误,有必要使用另一个存档器。
也许你能想到更好的办法来代替 0。
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip