
R cuadrado como evaluación de la calidad de la curva del balance de la estrategia

Índice
- Introducción
- Crítica de las estadísticas comunes de la estimación de sistemas comerciales
- Comportamiento de las estadísticas comunes durante el testeo de sistemas comerciales
- Requerimientos para el criterio del testeo del sistema comercial
- Regresión lineal
- Correlación
- Coeficiente de determinación R²
- Teorema del arcoseno y su aportación a la evaluación de la regresión lineal
- Recopilación de la equidad de la estrategia
- Cálculo del coeficiente de la determinación R² usando AlgLib
- El uso del R² en la práctica
- Ventajas y limitaciones en el uso
- Conclusión
Introducción
Cada estrategia comercial necesita una objetiva evaluación de su eficacia. Para eso, se utiliza una amplia serie de parámetros estadísticos. Muchos de ellos son muy simples para los cálculos y muestran las métricas intuitivamente comprensibles. Otros son más compejos en la construcción y en la interpretación de valores. A pesar de toda esta variedad, hay pocas métricas de calidad para estimar una magnitud no trivial pero evidente al mismo tiempo— la regularidad de la línea del balance del sistema comercial. El presente artículo propone la solución de este problema. Vamos a considerar en detalle el indicador no trivial como el coeficiente de determinación, denominado R cuadrado (R²), que calcula la estimación cuantitativa de aquella línea recta, ascendiente, atractiva visualmente, con la que sueña cualquier trader.
Está claro que en el terminal MetaTrader 5 ya existe su informe sumario bien desarrollado que muestra las estadísticas principales del sistema comercial. Pero los parámetros que representa no siempre son suficientes. Afortunadamente, MetaTrader 5 ofrece la posibilidad de escribir su propio parámetro personalizado de la estimación, de lo que nosotros nos ocuparemos. No sólo vamos a construir el coeficiente de determinación R², también intentaremos estimar cuantitativamente sus indicaciones, lo compararemos con otros criterios de optimización, formaremos las regularidades las que siguen las principales estimaciones estadísticas.
Crítica de las estadísticas comunes de la estimación de sistemas comerciales
Cada vez cuando generamos un informe comercial o analizamos los resultados de la simulación del sistema comercial, en seguida nos enferentamos a varios «números mágicos» analizando los cuales se puede sacar conclusiones sobre la calidad de la negociación. Por ejemplo, aquí tenemos un informe común sobre la simulación en el terminal MetaTrader 5:
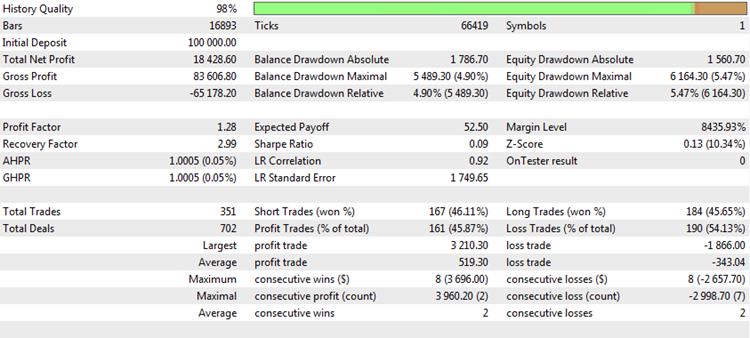
Fig. 1. Resultado de simulación de una estrategia comercial
Contiene una serie de estadísticas o métricas. Analizaremos las más populares de ellas y consideraremos objetivamente sus puntos fuertes y débiles.
Beneficio neto. La métrica muestra el importe que ha sido ganado o perdido durante el período de la simulación o negociación. Es uno de los parámetros más importantes del trading. La tarea principal para cada trader consiste en maximizar el beneficio. Hay varios medios para conseguir eso, pero el resultado final siempre será el único, el beneficio neto. El beneficio neto no siempre depende del número de transacciones y prácticamente no depende del resto de los parámetros, aunque la afirmación contraria no es cierta. De esta manera, es el invariante en relación a las demás métricas, y por eso puede usarse independientemente de ellas. No obstante, este indicador tiene unas desventajas importantes.
En primer lugar, el beneficio neto depende directamente del hecho de que si se utiliza la capitalización o no. Si se usa la capitalización, el beneficio se incrementa de una manera no lineal. A menudo se observa un crecimiento exponencial, impulsivo del depósito. En este caso, las cifras registradas como beneficio neto a menudo alcanzan unas magnitudes astronómicas para el momento de la finalización de la simulación, y no concuerdan en absoluto con la realidad. Si tradeamos usando el lote fijo, los incrementos del depósito serán más lineales, pero incluso en este caso, el beneficio depende del volumen seleccionado. Por ejemplo, si la simulación cuyo resultado se muestra en la tabla de arriba ha sido realizada con el lote fijo de 0,1 del contrato, entonces el importe de 15 757$ del beneficio obtenido puede considerarse como un resultado estupendo. Pero si el volumen de la transacción era 1,0 lote, el resultado de la simulación es más que módico. Precisamente por eso, los probadores experimentados prefieren colocar el lote fijo de 0,1 o 0,01 para el mercado Forex. En este caso, el cambio mínimo del balance es igual a un punto del instrumento, lo cual hace que el análisis de esta característica sea más objetivo.
En segundo lugar, el resultado final depende de la longitud del período de prueba o de la duración del historial del trading. Por ejemplo, el beneficio neto indicado en la tabla de arriba podía ser obtenido en 1 año, o tal vez, en 5 años. Y en cada caso, el mismo importe puede significar una eficacia de la estrategia absolutamente diferente.
Y en tercer lugar, el beneficio total se registra en el momento de la última fecha. Sin embargo, en este momento puede observarse una fuerte reducción (drawdown) del capital, mientras que hace una semana pudía no existir. En otras palabras, este parámetro depende mucho del punto inicial y final seleccionado para la simulación y confección del informe.
Factor de Beneficio. Tal vez, es la métrica más popular entre los traders profesionales. Cuando los principiantes queren ver sólo el beneficio neto, a los profesionales les interesa conocer la rotación de los medios invertidos. Si consideramos la pérdida en una operación como una especie de inversión, el factor de beneficio (ProfitFactor) muestra la rentabilidad de nuestro comercio. Por ejemplo, si hemos realizado sólo dos transacciones, y en la primera hemos perdido 1 000$ y en la segunda hemos ganado 2 000$, el factor de beneficio de nuestra estrategia será de 2 000$/1 000 = 2,0. Es un buen indicador. Es más, el Profit Factor no depende del intervalo de la simulación, ni del volumen del lote base. Por eso es tan popular entre los profesionales. No obstante, tiene sus desventajas.
Una de ellas consiste en que el valor del factor de beneficio depende mucho del número de transacciones. Si las transacciones son pocas, es muy posible conseguir el ProfitFactor igual a 2,0, o incluso 3,0. Si el número de transacciones es excesivo, tenderemos mucha suerta de obtener el factor de beneficio igual a 1,5.
Esperanza matemática del beneficio. Es una carceterística importante que indica en el resultado medio de la transacción. Si la estrategia es rentable, el beneficio esperado es positivo, si la estrategia es de pérdidas, tiene el valor negativo. Si el beneficio esperado es equiparable al spread o a las comisiones, entonces surgen dudas en la posibilidad de que esta estrategia sea capaz de ganar en una cuenta real. Normalmente, cuando las condiciones de la ejecución son ideales en el Probador de estrategias, el beneficio esperado puede ser positivo y el gráfico del balance representar una línea recta ascendiente. Sin embargo, cuando se trata del trading real, debido a así llamadas recotizaciones o deslizamientos, el resultado medio de la operación puede resultar ser un poco peor que el resultado calculado teóricamente, lo que influirá críticamente en el resultado de la estrategia y provocará unas pérdidas reales.
Aquí también hay sus desventajas. La principal de ellas también está relacionada con el número de transacciones. Si las transacciones son pocas, no es tan difícil conseguir un beneficio esperado elevado. Si el número de transacciones es grande, el beneficio esperado, al revés, tiende a cero. Puesto que se trata de un indicador lineal, no se puede usarlo en las estrategias que utilizan el sistema de la gestión de capital. Pero los traders profesionales lo aprecian y utilizan en los sistemas lineales con el lote fijo, comporando con el lote fijo.
Número de transacciones. Es un parámetro importante que influye en la mayoría de las demás características directamente o indirectamente. Supongamos que nuestro sistema comercial gana en 70% de ocasiones. Además, los valores absolutos de ganancias y pérdidas son iguales, y la táctica comercial no permite otras variantes del resultado de la transacción. Este sistema parece excepcional, pero ¿qué ocurrirá si intentamos medir su eficacia sólo por dos últimas transacciones? En 70% de ocasiones, una de ellas va a ser rentable, pero la probabilidad de la rentabilidad de ambas transacciones sólo es de un 49%. Es decir, el resultado de dos transacciones será nulo en más de la mitad de ocasiones. Por consiguiente, la estadística nos va a decir que la estrategia no gana en la mitad de ocasiones. Su factor de beneficio será igual a 1, su esperanza matemática y su beneficio serán nulos, otros parámetros también indicarán en la eficacia nula.
Precisamente por eso, el número de transacciones debe ser suficientemente grande. ¿Pero qué es lo que se entiende bajo la suficiencia? Es costumbre considerar que cualquier muestra debe contener como mínimo 37 mediciones. Es el número mágico en la estadística, y precisamente esta cifra es la banda inferior de la representatividad del parámetro. Está claro que esta cantidad de transacciones no es suficiente para evaluar un sistema comercial. Para un resultado seguro, es deseable realizar como mínimo 100-150 transacciones. Es más, muchos traders profesionales consideran esta cantidad insuficiente. Ellos diseñan los sistemas que realizan no menos de 500-1000 transacciones, y sólo después, basándose en estos resultados, considerar la posibilidad de iniciar el sistema en sesiones reales.
Comportamiento de los parámetros estadísticos comunes durante el testeo de sistemas comerciales
Hemos examinado los principales parámetros de la estadística de los sistemas comerciales. Veremos cómo se comportan en la práctica. Además, vamos a concentrar la atención en sus desventajas con el fin de comprender cómo la adición propuesta en forma de la estadística R² ayudará a superarlas. Para eso usaremos el Asesor Experto (EA) CImpulse 2.0 cuyo trabajo se describe en el artículo "Experto comercial universal: Indicador CUnIndicator y trabajo con órdenes pendientes". Ha sido seleccionado por su sencillez y porque, a deferencia de los EAs de la entrega estándar de MetaTrader 5, es optimizable, lo que es sumamente importante para los propósitos de nuestro artículo. Además, necesitaremos una determinada infraestructuras de códigos que ya está escrita para el motor comercial CStrategy, por eso no hay necesidad de realizar el mismo trabajo dos veces. En este caso, todos los códigos del coeficiente de determinación están escritos de tal manera que sea fácil de usarlos fuera de CStrategy, por ejemplo, en las librería ajenas o EAs procesales.
Beneficio neto. Como ya ha sido dicho antes, el beneficio neto (o total) es el resultado final de lo que pretende conseguir el trader. Cuanto más grande el beneficio, mejor para nosotros. Sin embargo, no siempre la estimación de la estrategia según su beneficio neto garantiza el éxito. Vamos a considerar los resultados del trabajo de la estrategia CImpulse 2.0 en EURUSD, con el intervalo de la simulación de 2015.01.15 a 2017.10.10:
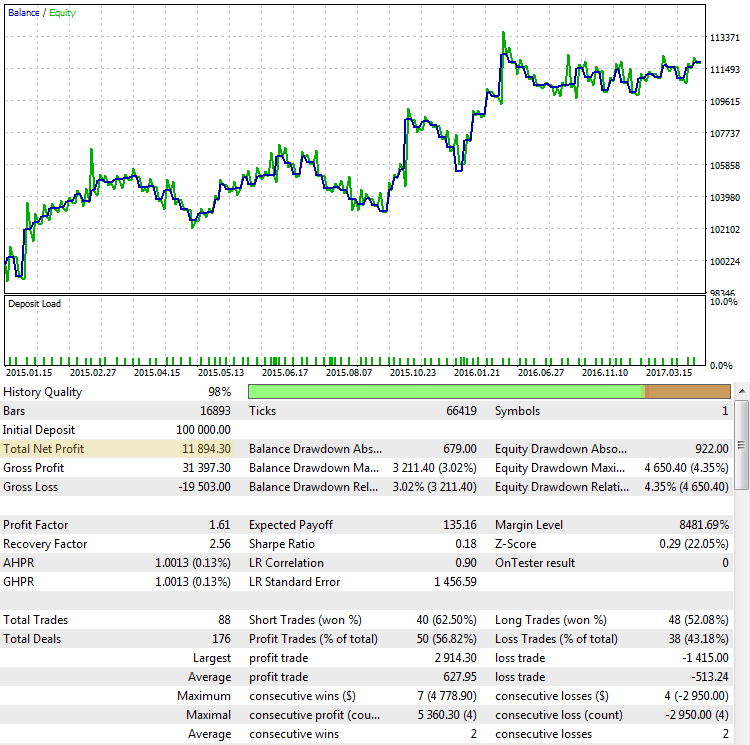
Fig. 2. Estartegia CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 120, StopPercent: 0,67
Como se puede observar, la estrategia muestra un crecimiento estable del beneficio neto en este intevalo de la simulación. Es positio y asciende a 11 894 dólares durante el trading con un contrato. Es un buen resultado, pero vamos a ver otra versión de eventos cuando el beneficio neto parece al primer caso:
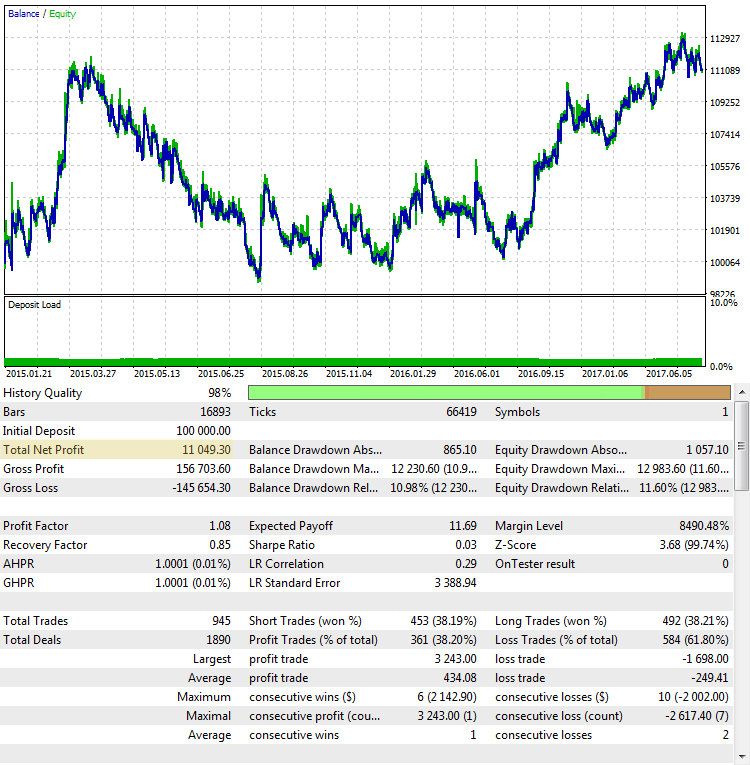
Fig. 3. Estrategia CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 110, StopPercent: 0,24
A pesar de que el beneficio en ambos casos es casi igual, se puede pensar que se trata de dos sistemas comerciales diferentes. En el segundo caso, el beneficio neto parece absolutamente ocasional. Si terminasemos la prueba a mediados del año 2015, estaría cerca de cero.
Aquí tenemos otro repaso no acertado de la estrategia, cuyo resultado final, a pesar de todo, también está muy cerca del primer caso:
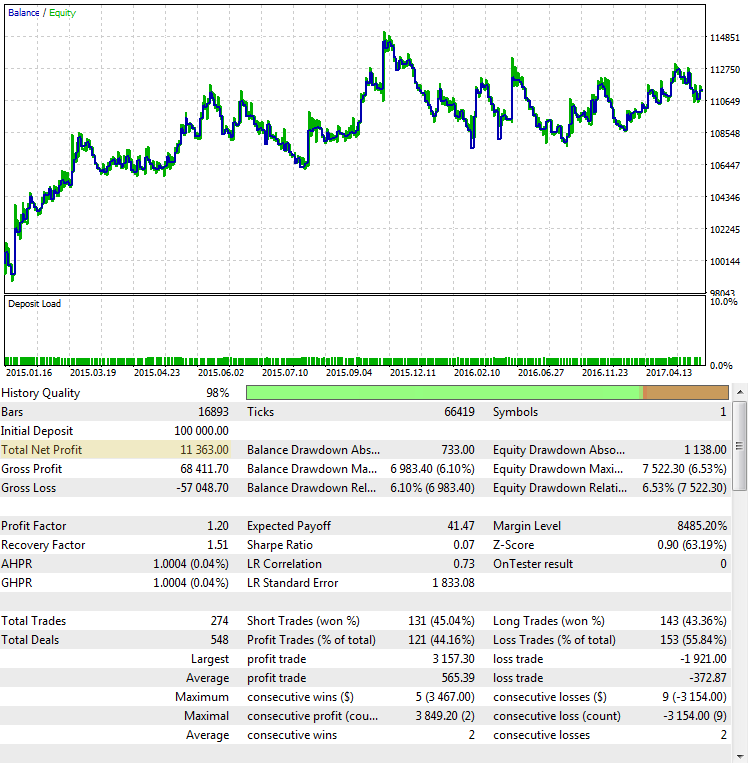
Fig. 4. CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 45, StopPercent: 0,44
En el gráfico se ve muy bien que el benefico principal fue obtenido en la primera mitad de 2015. Luego, se mantuvo un largo período de estancamiento. Esta estrategia no es una opción conveniente para trabajar en cuentas reales.
Factor del beneficio (Profit Factor). La métrica ProfitFactor ya depende mucho menos del resultado final. Este indicador depende de cada transacción y muestra la relación entre todo el dinero ganado y el dinero perdido. Se ve que en la imagen 2 el ProfitFactor es bastante alto, en la imagen 4 es más bajo, y en la imagen 3 es casi se acerca al nivel entre el sistema rentable y de pérdidas. Sin embargo, el ProfitFactor no es una característica universal que no se puede engañar. Vamos a examinar otros ejemplos donde las indicaciones del factor de beneficio no son tan evidentes:
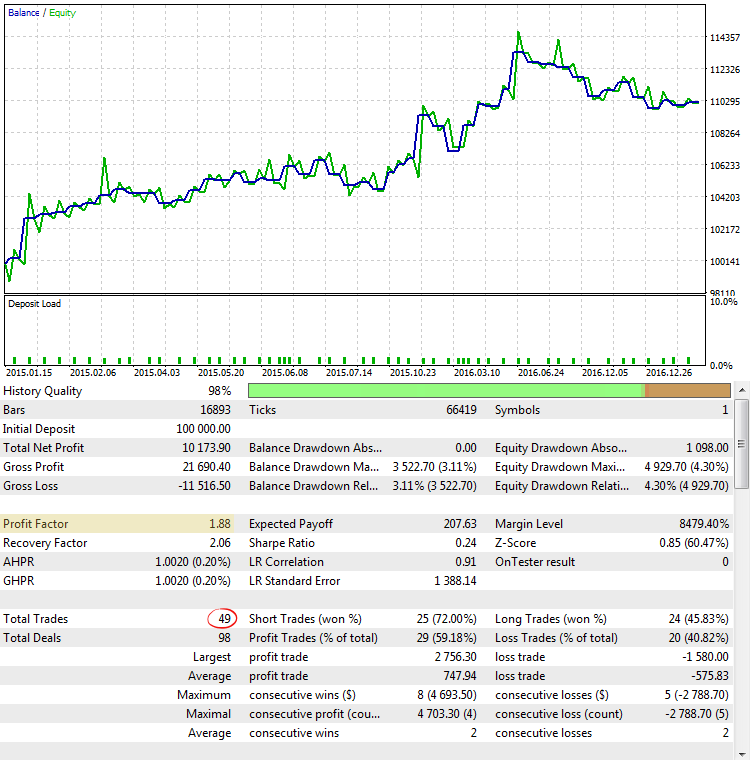
Fig. 5. CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 60, StopPercent: 0,82
En la imagen 5 vemos los resultados del repaso de la estrategia con uno de los indicadores más altos del ProfitFactor. El gráfico del balance parece bastante bien, pero la estadística obtenida nos induce a error, ya que los indicadores del ProfitFactor están sobreestimados debido a una pequeña cantidad de transacciones.
Vamos a comprobar esta afirmación de dos modos. El primer modo: vamos a aclarar la dependencia del ProfitFactor del número de transacciones. Para eso vamos a optimizar la estrategia CImpulse en el Probador de estrategias usando un amplio rango de parámetros:

Fig. 6. Optimización de CImpulse usando un amplio rango de parámetros
Guardamos los resultados de optimización:
Fig. 7. Exportación de los resultados de optimización
Ahora se puede construir el gráfico de la dependencia del indicador ProfitFactor del número de transacciones. Por ejemplo, en Excel basta con seleccionar las columnas necesarias y pulsar el botón de construcción del diagrama de puntos en la pestaña Diagrama:
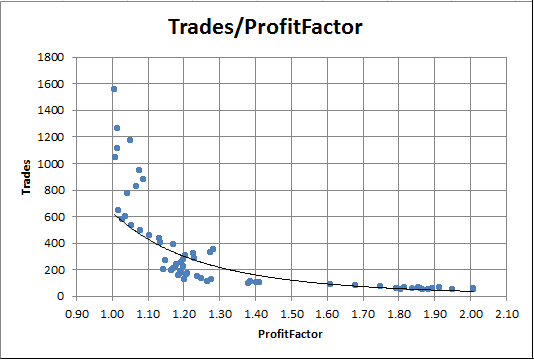
Fig. 8. Dependencia del ProfitFactor del número de transacciones
En el gráfico se ve muy bien que en los repasos con el factor de beneficio alto siempre hay pocas transacciones. Y al revés, cuando el número de transacciones es grande, el factor de beneficio es prácticamente igual a 1.
El segundo modo de determinar que los indicadores del ProfitFactor en este caso dependen del número de transacciones, y no de la calidad de la estrategia, está relacionado con la realización de la simulación fuera de la muestra (Out Of Sample o OOS). Por cierto, es uno de los modos más seguros para determinar la robustez de los resultados obtenidos. La robustez es una medida de la estabilidad del método estadístico en las estimaciones. Es eficaz usar el método OOS para testear no solo el ProfitFactor, sino también otros indicadores. Pero para nuestras tareas vamos a seleccionar los mismos parámetros pero otro intervalo temporal, de 2012.01.01 a 2015.01.01:
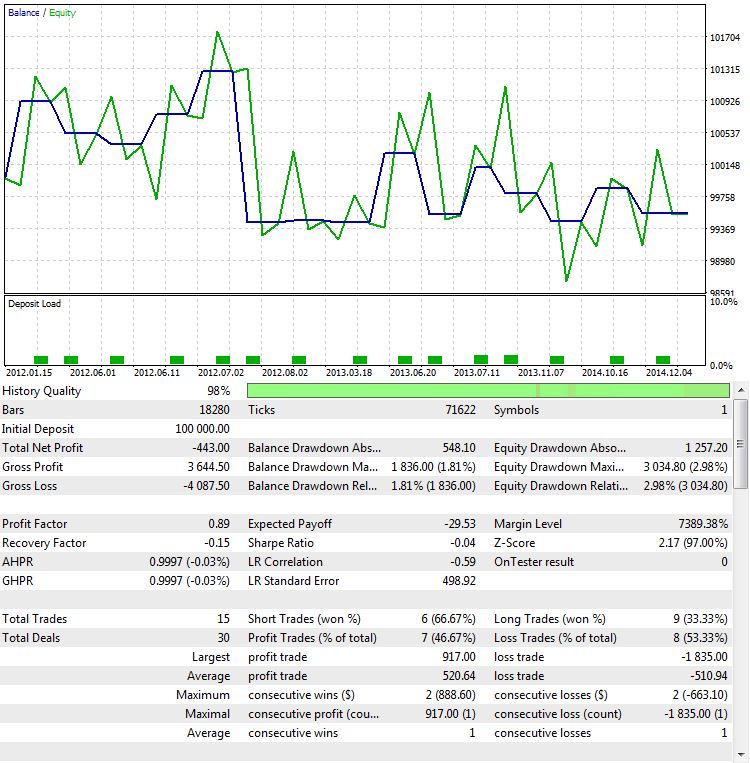
Fig. 9. Simulación de estrategia fuera de la muestra
Como se ve, el comportamiento de la estrategia se hace diametralmente contrario. En vez del beneficio, ella genera la pérdida. Es un final natural, ya que teniendo tan pocas transacciones, prácticamente siempre obtenemos un resultado casual. Eso significa que la ganancia aleatoria en un intervalo temporal se compensa con la pérdida en otro, lo que se muestra muy bien en la imagen 9.
Esperanza matemática del beneficio. No vamos a hablar mucho de este parámetro porque sus puntos débiles son idénticos al ProfitFactor. Este es gráfico de la dependencia del factor de beneficio del número de transacciones:
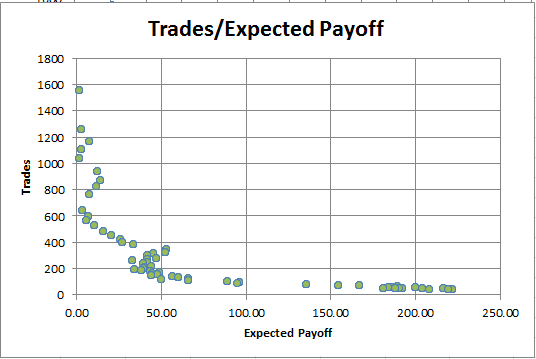
Fig. 10 Dependencia del factor de beneficio del número de transacciones
Vemos que cuanto más grande sea el número de transacciones, menor será el beneficio esperado. Esta dependencia simpre se mantiene tanto para las estrategias rentables, como para la de pérdidas. Por eso, el beneficio esperado no puede servir del único criterio del óptimo de la estrategia comerial.
Requerimientos para el criterio del testeo del sistema comercial
Después de considerar los principales criterios de la estimación estadística del sistema comercial, hacemos conclusión que cada criterio tiene limitaciones en la aplicación, y para cada uno se puede escoger un contraejemplo cuando la estad”istica va a mostrar un buen resultado y la estrategia no.
No hay criterios ideales que determinan la robustez del sistema comercial. Pero se puede formular las propiedades las que debe poseer un criterio estadístico fuerte.
- Independencia en relación a la duración del período de prueba Muchos parámetros de la estrategia comercial dependen de la duración del período de prueba. Por ejemplo, cuanto más largo sea el período de prueba para una estrategia rentable, más grande será el beneficio neto. El factor de recuperación también depende de la duración. Se calcula como la relación entre el beneficio neto y la reducción máxima (Maximal Drawdown). Dado que el beneficio depende del período, el factor de recuperación también crece con el aumento del período de prueba. La invariancia (independencia) respecto al período es necesaria para comparar la eficacia de diferentes estrategias en diferentes períodos de prueba.
- Independencia del punto final de la prueba. Por ejemplo, si la estrategia «juega» con que simplemente sobrepasa las pérdidas, el punto final de la prueba puede cambiar considerablemente el balance final. Si la simulación se termina en el momento de este «sobrepaso», la pérdida de variación (equity) se convierte en el balance y en la cuenta se forma una reducción (drawdown) considerable. El indicador debe estar protegido de estas maquinaciones y ofrecer una imagen clara del trabajo del sistema comercial.
- Sencillez de la interpretación. Todos los parámetros del sistema comercial son cuantitativos, es decir, cada indicador se caracteriza por una determinada cifra. Esta cifra debe ser intuitivamente comprensible. Cuanto más simple sea la interpretación del valor obtenido, el parámetro estará más disponible para la comprensión. También es deseable que el parámetro se encuentre dentro de unos límites, ya que resulta bastante complicado analizar los números grandes y potencialmente infinitos.
- Resultados representativos con pocas transacciones. Probablemente es el requerimiento más complicado en la lista de las características de una buena métrica. Todos los métodos estadísticos dependen de la cantidad de mediciones. Cuanto más haya, la estadística obtenida tiene mayor estabilidad. Desde luego, es imposible solucionar de todo este problema en una muestra pequeña. No obstante, se puede suavizar los efectos que surgen debido a la carencia de datos. Para eso vamos a desarrollar dos tipos de la función de la estimación de R cuadrado: una implementación va a construir este criterio a base de las transacciones existentes, otra va a calcular el criterio a base del beneficio no registrado de la estrategia (equity).
Antes de pasar a la descripción del coeficiente de determinación R², vamos a considerar en detalle sus componentes. Así comprenderemos la esencia de este parámetro y sus principios básicos.
Regresión lineal
A la regresión lineal la llaman a la dependencia lineal de una variable y de otra variable independiente x, expresada con la fórmula y = ax+b. En esta fórmula, а es el multiplicador, b es el coeficiente del desplazamiento. En realidad, puede haber varias variables independientes, este modelo regresivo se llama multiregresivo. No obstante, nosotros vamos a analizar sólo el caso más simple.
La dependencia lineal puede ser representada en forma de un gráfico simple. Vamos a coger el gráfico del día EURUSD de 2017.06.21 a 2017.09.21. Esta sección no ha sido elegida por casualidad: precisamente durante este período en este par se observaba una moderada tendencia alcista. Ejemplo en MetaTrader:
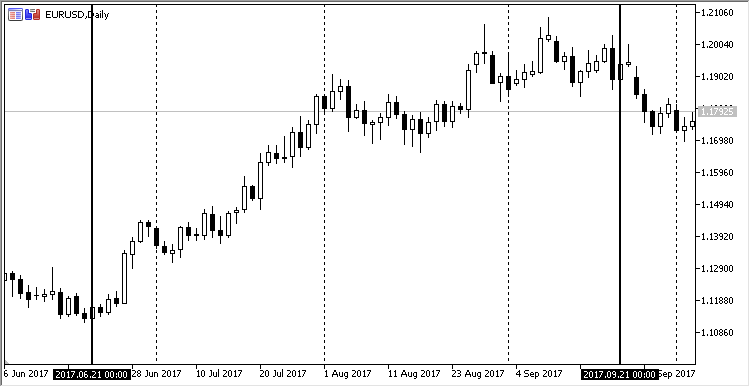
Fig. 11. Dinámica de precio de EURUSD de 21.06.2017 a 21.08.2017, timeframe D1
Guardamos estos datos de precios y construimos un gráfico a su base, por ejemplo en Excel:
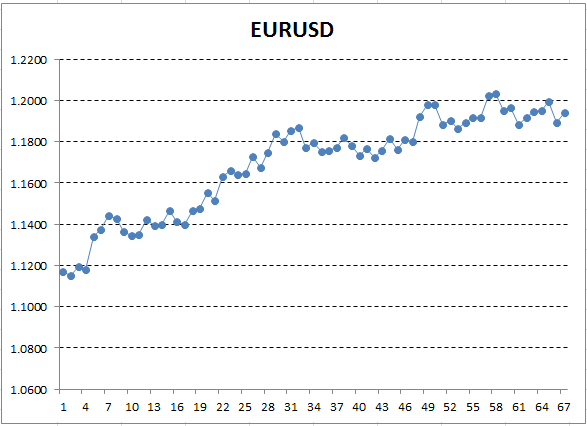
Fig. 12. Cotización de EURUSD (precios del cierre) en forma del gráfico en Excel
Aquí, el eje Y corresponde al precio, y el eje X, al número de orden de la mediación (hemos reemplazado las fechas por los números de orden). En el gráfico obtenido, se observa perfectamente una tendencia alcista, pero nosotros necesitamos obtener la interpretación cuantitativa de esta tendencia. El modo más simple es trazar una recta que estará ajustada con mayor precisión a la tendencia en cuestión. Es la regresión lineal. Por ejemplo, podemos trazar la línea así:
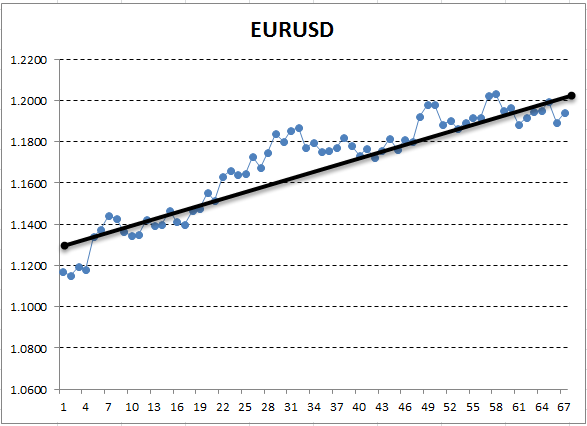
Fig. 13. Regresión lineal que describe la tendencia alcista trazada manualmente
Si el gráfico es bastante uniforme, se puede trazar una línea de la que los puntos van a desviarse a una distancia mínima. Y al revés, para un gráfico con una amplitud grande, no se puede ajustar una línea que describa exactamente sus cambios. La razón es que la regresión lineal tiene sólo dos coeficientes. Efectivamente, del curso de la geometría sabemos que necesitamos sólo dos puntos para construir una línea recta. Gracias a eso, no es tan fácil ajustar una recta a un gráfico «curvo». Es una propiedad valiosa que nos ayudará en el futuro.
¿Pero cómo trazar la recta correctamente? Usando los métodos matemáticos, podemos calcular los coeficientes de la regresión lineal de tal manera que todos los puntos existentes tengan la suma mínima de las distancias hasta esta línea. Lo explicaremos en el siguiente gráfico. Supongamos que tenemos 5 puntos aleatorios y dos líneas que los atraviesan. Tenemos que elegir la línea cuya suma de las distancias hasta los puntos sea menor:
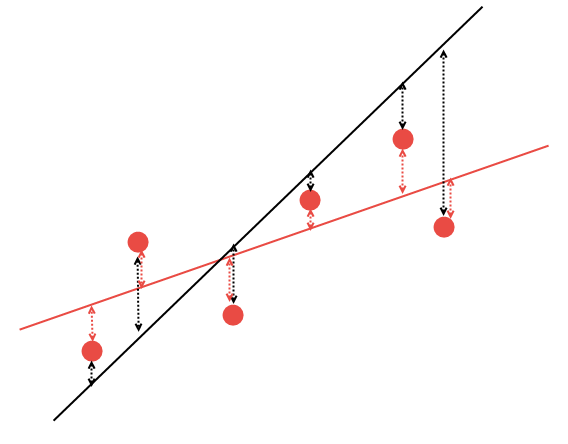
Fig. 14. Selección de la regresión lineal más apropiada
Es obvio que de dos variantes de la regresión lineal, la recta roja describe mejor nuestros datos: los puntos №2 y №6 están más cerca de la línea rojo que de la negra. Los demás puntos están más o menos en la misma distancia de ambas líneas. Podemos calcular matemáticamente las coordenadas de la línea que describa mejor esta regularidad. No vamos a calcular personalmente estos coeficientes, sino usaremos la librería matemática AlgLib.
Correlación
Una vez calculada la regresión lineal, nos hace falta calcular la correlación entre esta línea y los datos en las que se calcula. La correlación es la relación estadística entre dos o más variables aleatorias. La accidentalidad de las variables en este caso significa que las mediciones de estas variables no dependen unas de otras. La correlación se mide de -1,0 a +1,0. El valor cercano a cero significa que no hay relación entre los valores medidos. El valor +1,0 indica en la dependencia directa, -1,0 en la contraria. La correlación se calcula a través de varias fórmulas diferentes. Nosotros usaremos el coeficiente de la correlación de Pearson:
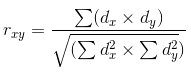
dx y dy corresponden a las dispersiones calculadas para variables aleatorias x y y. La dispersión es la medida de la varianza del indicio. En términos generales se puede describirla como la suma de cuadrados de las distancias entre los datos y la regresión lineal.
El coeficiente de correlación de datos con su regresión lineal muestra hasta qué punto la recta describe los datos. Si los puntos de los datos se encuentran a una distancia grande de la línea, la dispersión es alta y la correlación es baja, y viceversa. Es muy fácil interpretar la correlación: el valor cero dice que no hay relación entre la regresión y los datos; el valor cercano a uno significa que hay una dependencia directa fuerte.
En el informe de MetaTrader hay una métrica estadística especial. Se llama LR Correlation y muestra la correlación entre la línea del balance y la regresión lineal encontrada para esta línea. Si la línea del balance es derecha, entonces la aproximación a la línea recta será buena. En este caso, el coeficiente LR Correlation será cercano a 1,0 o, por lo menos, por encima de 0,5. Si la línea del balance es inestable, eso quiere decir que las subidas van a alternarse con bajadas, y el coeficiente de la correlación va a tender a cero.
LR Correlation es un parámetro interesante. Pero en la estadística no suelen comparar directamente —a través del coeficiente de correlación— los datos y la regresión que los describe. La razón de eso la discutiremos en el siguiente apartado.
Coeficiente de determinación R²
El modo del cálculo del coeficiente de determinación R² es análogo al modo del cálculo de LR Correlation. Pero la cifra resultante se eleva adicionalmente al cuadrado. Puede adquirir el valor de 0,0 a +1,0. Esta cifra muestra una parte de los valores explicados de la muestra total. De modelo explicativo nos sirve la regresión lineal. Hablando estrictamente, no es obligatorio usar la regresión lineal como modelo explicativo, se puede usar otros. Pero sólo para un modelo lineal, los indicadores de R² no requieren el procesamiento posterior. En los modelos más complejos, normalmente, la aproximación es mejor y es necesario menosvalorar adicionalmente los valores de R² usando unas «multas» especiales para una estimación adecuada.
Vamos a analizar detalladamente lo que muestra el modelo explicativo. Para eso, hagamos un pequeño experimento: usaremos un lenguaje de programación especializado R-Project y generaremos el paseo aleatorio para el que calcularemos el coeficiente necesario. El paseo aleatorio es un proceso cuyas características son muy parecidas a los instrumentos financieros reales. Para conseguirlo, basta con sumar consecutivamente varios números aleatorios distribuidos según la ley normal.
Aquí tenemos el código en el lenguaje de programación R con explicaciones detalladas de lo que estamos haciendo:
x <- rnorm(1000) # Generamos 1000 números aleatorios distribuidos entre sí según la distribución normal # Su dispersión es igual a uno, mientras que el beneficio esperado es igual a cero rwalk <- cumsum(x) # Sumamos estos números acumulativamente obteniendo el gráfico clásico del paseo aleatorio plot(rwalk, type="l", col="darkgreen") # Mostramos los datos como gráfico lineal rws <- lm(rwalk~c(1:1000)) # Construimos el modelo lineal y=a*x+b, donde x es el número de la medición, y es el valor del vector del paseo generado title("Line Regression of Random Walk") abline(rws) # Mostramos la regresión lineal obtenida en el gráfico
La función rnorm cada vez devuelve los datos diferentes, por eso si quiere repetir el experimento, obtendrá un gráfico diferente.
Este es el resultado de la ejecución del código:

Fig. 15. Paseo aleatorio y regresión lineal para él.
El gráfico obtenido parece al gráfico de un instrumento financiero aleatorio. Hemos calculado la regresión lineal para él y la hemos visualizado como una línea negra en el gráfico. A primera vista, ella describe la dinámica del paseo aleatorio bastante medianamente. Pero nosotros necesitamos la estimación cuantitativa de la regresión lineal. Para eso, usaremos la función summary que visualiza la estadística sumaria para el modelo regresivo.
summary(rws) Call: lm(formula = rwalk ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.038404 0.001013 37.92 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.5903, Adjusted R-squared: 0.5899 F-statistic: 1438 on 1 and 998 DF, p-value: < 2.2e-16
Lo que más nos interesa aquí es el único número, R-squared o R cuadrado. Esta métrica muestra el valor 0,5903. Por tanto, la regresión lineal explica 59,03% de todos los valores, los demás 41% se quedan inexplicados.
Este indicador es muy sensible y reacciona bien en una línea derecha y suave de datos. Para demostrar eso, sigamos con nuestro experimento: vamos a introducir una componente estable de crecimiento en nuestros datos aleatorios. Para eso, cambiamos el valor medio o el beneficio esperado por un valor igual a 1/20 de la dispersión de los datos iniciales generados:
x_trend1 <- x+(sd(x)/20.0) # Buscamos la desviación estándar de los valores x, la dividimos por 20,0 y añadimos el valor obtenido a cada valor x # Cada valor x modificado va a almacenarse en el array de valores nuevo x_trend1 rwalk <- cumsum(x) # Sumamos estos números acumulativamente obteniendo el gráfico clásico del paseo aleatorio plot(rwalk_t1, type="l", col="darkgreen") # Mostramos los datos como gráfico lineal title("Line Regression of Random Walk #2") rws_t1 <- lm(rwalk_t1~c(1:1000))# Construimos el modelo lineal y=a*x+b, donde x es el número de la medición, y es el valor del vector del paseo generado abline(rws_t1) # Mostramos la regresión lineal obtenida en el gráfico
El gráfico obtenido ya está bastante más cerca de la línea recta:
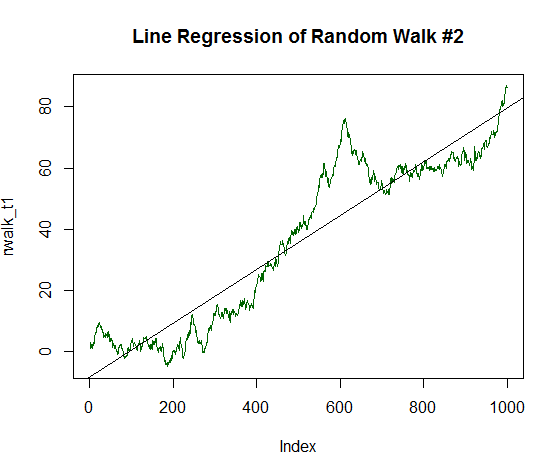
Fig. 16. Paseo aleatorio con un beneficio esperado igual a 1/20 de su despersión.
La estadística es la siguinte:
summary(rws_t1) Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.087854 0.001013 86.75 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.8829, Adjusted R-squared: 0.8828 F-statistic: 7526 on 1 and 998 DF, p-value: < 2.2e-16
Como podemos ver, R² ya es bastante más alto y muestra el valor 0,8829. No vamos a detenernos aquí, aumentamos la componente determinante de nuestro gráfico en dos veces, hasta el valor 1/10 de la desviación estándar de los valores iniciales. El código es igual que el anterior, pero hay que dividir por 10,0 en vez de 20,0. El nuevo gráfico ya casi parece a una línea recta:
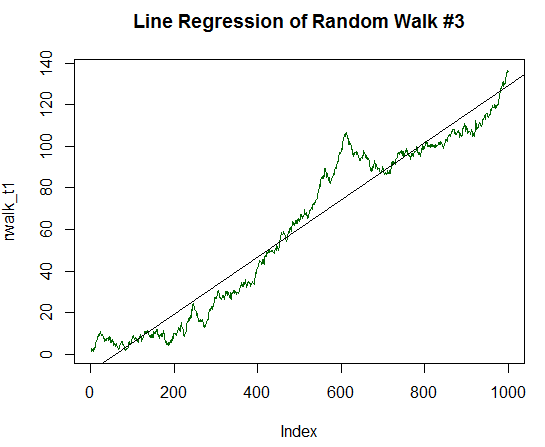
Fig. 17. Paseo aleatorio con un beneficio esperado igual a 1/10 de su despersión.
Vamos a calcular su estadística:
Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 4 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.137303 0.001013 135.59 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.9485, Adjusted R-squared: 0.9485 F-statistic: 1.838e+04 on 1 and 998 DF, p-value: < 2.2e-16
R² ya es más alto y asciende a 0,9485. Este gráfico ya parece mucho a la dinámica del balance de la estrategia comercial rentable tan deseada. Pero no vamos a detenernos en lo alcanzado. Vamos a aumentar el beneficio esperado a 1/5 de la desviación estándar.
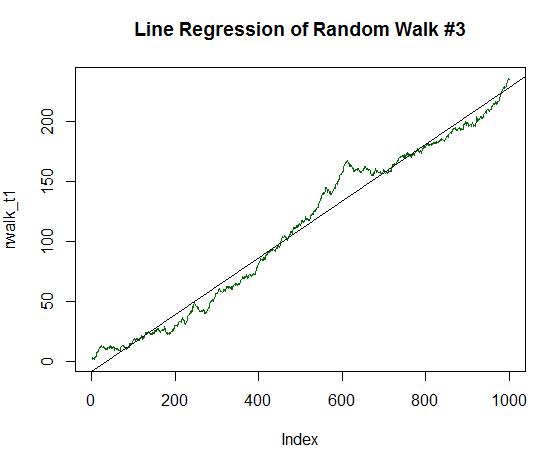
Fig. 18. Paseo aleatorio con un beneficio esperado igual a 1/5 de su despersión.
Su estadística es la siguiente:
Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.236202 0.001013 233.25 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.982, Adjusted R-squared: 0.982 F-statistic: 5.44e+04 on 1 and 998 DF, p-value: < 2.2e-16
Como se puede observar, R² prácticamente ya es igual a uno. En el gráfico, se ve perfectamente que nuestros datos aleatorios en forma de la línea verde se colocan prácticamente en su totalidad en la línea recta.
Teorema del arcoseno y su aportación a la evaluación de la regresión lineal
Existe una argumentación matemática de que un proceso aleatorio se aleja con el tiempo de su punto inicial. Ha adquirido el nombre de la primera y la segunda teorema del arcoseno. No vamos a describirlos en detalle, sólo vamos a definir las secuencias de estos teoremas.
Basándose en ellos, las tendencias en los procesos aleatorios son más bien inevitables que poco probables. En otras palabras, se observan más tendencias aleatorias en estos procesos que las fluctuaciones aleatorias cerca del punto inicial. Es una propiedad muy importante que da una aportación considerable en la estimación de las métricas estadísticas. Sobre todo, eso se nota para el coeficiente de la regresión lineal (LR Correlation). Con la regresión lineal se describen mejor las tendencias que los flats. Eso está relacionado con el hecho de que las tendencias contienen más movimiento en un lado que parece a una línea derecha.
Si hay más tendencias en los procesos aleatorios que los flats, por consiguiente, LR Correlation en general va a aumentar sus valores. Para asegurarse de este efecto no evidente, intentamos generar 10000 paseos aleatorios independientes, con la dispersión 1,0 y beneficio esperado nulo. Calculamos LR Correlation para cada gráfico, y luego construimos la distribución de estos valores. Para este propósito escribiremos un simple script de texto en el lenguaje de programación R:
sample_r2 <- function(samples = 100, nois = 1000) { lags <- c(1:nois) r2 <- 0 # R^2 rating lr <- 0 # Line Correlation rating for(i in 1:samples) { white_nois <- rnorm(nois) walk <- cumsum(white_nois) model <- lm(walk~lags) summary_model <- summary(model) r2[i] <- summary_model$r.squared*sign(walk[nois]) lr[i] <- (summary_model$r.squared^0.5)*sign(walk[nois]) } m <- cbind(r2, lr) }
Nuestro script calcula tanto LR Correlation, como R². Un poco más tarde veremos la diferencia entre ellos. En el script ha sido introducida una pequeña modificación. Vamos a multiplicar el coeficiente de correlación obtenido por el signo resultante del gráfico sintético. Si hemos terminado con un resultado menos cero, la correlación va a ser negativa, si más, positiva. Eso se hace con el fin de separ fácilmente los resultados negativos de los positivos sin recurir a otras estadísticas. Precisamente así LR Correlation trabaja en MetaTrader 5, R² va a construirse de acuerdo con este principio.
Vamos a construir la distribución LR Correlation para 10 000 ejemplos independientes, cada uno de los cuales se compone de 1 000 mediciones:
ms <- sample_r2(10000, nois=1000) hist(ms[,2], breaks = 30, col="darkgreen", density = 30, main = "Distribution of LR-Correlation")
El gráfico obtenido indica en la certeza de nuestra definición:
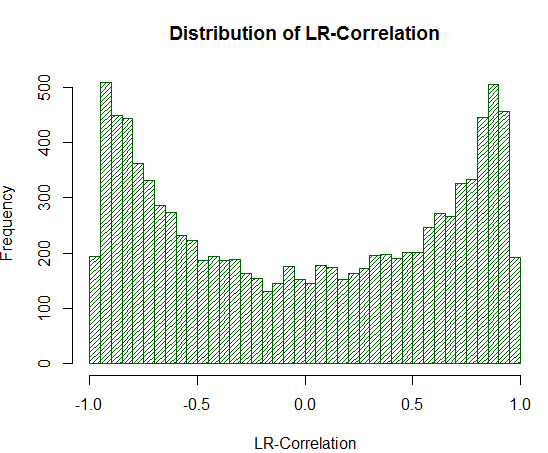
Fig. 19. Distribución LR-Correlation para 10 000 paseos aleatorios
Como se ve de nuestro experimento, los valores de LR-Correlation están subidos considerablemente en el área +/- 0.75 - 0.95. Eso significa que LR-Correlation a menudo da falsemente una estimación positiva ahí donde eso no debe ocurrir.
Ahora veremos cómo se comporta R² en la misma muestra:
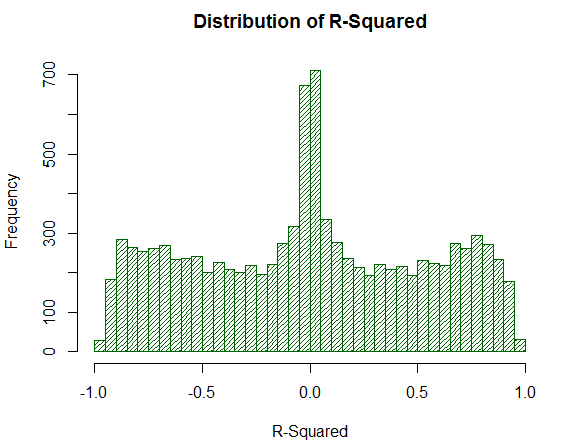
Fig. 20. Distribución R² para 10 000 paseos aleatorios
El valor R² ya no esta sobrevalorado aunque su distribución es uniforme. Es sorprendente que usando una simple acción matemática (elevación a la segunda potencia) hemos quitado completamente los efectos marginales no deseados de la distribución. Precisamente por esta razón, no se puede analizar LR-Correlation directamente, se necesita una conversión matemática adicional. Además, nótese que R² traslada una gran parte de los balances virtuales analizados de las estrategias en un punto cerca de cero, mientras que LR-Correlation les da unas estimaciones medianas estables. Es una propiedad positiva.
Recopilación de la equidad de la estrategia
Ahora, cuando ya hemos aclarado el tema de la teoría, nos queda implementar R² en el terminal MetaTrader. Desde luego, podríamos tomar el camino de la menor resistencia y calcularlo para las transacciones históricas. No obstante, introduciremos una mejora adicional. Como ya ha sido dicho, cualquier parámetro estadístico tiene que ser estable para una cantidad pequeña de las transacciones. Por desgracia, R², igual como cualquier otra estadística, puede aumentar vanamente sus valores si las transacciones en la cuenta son pocas. Para evitar eso, vamos a calcularlo a base de los valores de equity (beneficio no registrado). La idea consiste en lo siguiente: si el EA realiza sólo 20 transacciones durante el año, es bastante difícil comprender hasta qué punto es eficaz. Es muy probable que su resultado sea ocasional. Pero si medimos el estado del balance de este EA con una determinada periodicidad, por ejemplo, cada hora, el número de puntos para construir la estadística será suficiente. En este caso, habrá más de 6 000 mediciones.
Además de eso, esta medición resiste a los sistemas que no registran su pérdida de variación, ocultándola. La equidad de la estrategia se reduce, y el balance, no. La estadística calculada a base del balance no avisa sobre la aparición de problemas. No obstante, la métrica calculada tomando en cuenta la ganancia/pérdida no registrada, reflejará la situación objetiva con la cuenta.
Vamos a recopilar la equidad de la estrategia de una manera especial. Es que se debe tomar en cuenta dos momentos importantes para recopilar estos valores:
- Frecuencia de la recopilación de estadísticas
- Determinación de eventos cuando es necesario realizar la verificación de fondos
Por ejemplo, el EA trabaja sólo a base del temporizador, en el timeframe H1. Se prueba en el modo «Sólo precios de apertura». Por tanto, para este EA no se puede recopilar los datos más que cada hora, y el screening de estos datos se hace sólo en caso del evento OnTimer. La solución más efectiva será usar el motor CStrategy. Es que CStrategy reúne todos los eventos en el mismo manejador de eventos, y el seguimiento del timeframe necesario se hace automáticamente. De esta manera, la solución óptima será escribir un agente-estrategia especial que calcula toda la estadística necesaria. De su creación se encargará el asistente de las estrategias CManagerList. La clase va a añadir su agente a la lista de las estrategias, y éste va a monitorear los cambios en la cuenta.
A continuación va el código fuente de este agente:
//+------------------------------------------------------------------+ //| UsingTrailing.mqh | //| Copyright 2017, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2017, Vasiliy Sokolov." #property link "https://www.mql5.com" #include "TimeSeries.mqh" #include "Strategy.mqh" //+------------------------------------------------------------------+ //| Se integra como EA en la cartera de estrategias y escribe | //| la equidad de la cartera | //+------------------------------------------------------------------+ class CEquityListener : public CStrategy { private: //-- Frecuencia de la escritura CTimeSeries m_equity_list; double m_prev_equity; public: CEquityListener(void); virtual void OnEvent(const MarketEvent& event); void GetEquityArray(double &array[]); }; //+------------------------------------------------------------------+ //| Establecimiento de la frecuencia por defecto | //+------------------------------------------------------------------+ CEquityListener::CEquityListener(void) : m_prev_equity(EMPTY_VALUE) { } //+------------------------------------------------------------------+ //| Realiza la recopilaci”on de la equidad de la cartera siguiendo todos | //| los posibles eventos | //+------------------------------------------------------------------+ void CEquityListener::OnEvent(const MarketEvent &event) { if(!IsTrackEvents(event)) return; double equity = AccountInfoDouble(ACCOUNT_EQUITY); if(equity != m_prev_equity) { m_equity_list.Add(TimeCurrent(), equity); m_prev_equity = equity; } } //+------------------------------------------------------------------+ //| Devuelve la equidad en forma del array double | //+------------------------------------------------------------------+ void CEquityListener::GetEquityArray(double &array[]) { m_equity_list.ToDoubleArray(0, array); }
El agente se compone de dos métodos: OnEvent redistribuido y método de la devolución de los valores de equity. Lo que más interesa aquí es la clase CTimeSeries, que ha aparecido por primera vez en CStrategy. Representa una tabla simple a la que se añaden los datos en el formato: fecha, valor, número de la columna. Todos los valores se almacenan en el estado ordenado por tiempo, el acceso a la fecha necesaria se realiza a través de la búsqueda binaria, lo que acelera considerablemente el trabajo con la colección. El método OnEvent comprueba si el evento actual es la apertura de la nueva barra, y sis es así simplemente guarda el nuevo valor de la equidad.
R² reacciona a la situación cuando no hay transacciones durante un período prolongado. En estos momentos, van a escribirse los valores de la equidad que no sufren cambios. En el gráfico de equity, se forma la llamada «escalera». Para evitar eso, en el método se hace la comparación con el valor anterior. Si los valores coinciden, la entrada se omite. De esta manera, sólo los cambios en la equidad entran en la lista.
Integramos esta clase en el motor de CStrategy. La integración se realizará en la parte de arriba, en el nivel CStrategyList. Es un módulo apropiado para calcular la estadística de usuario. Pueden haber varias estadísticas de usuario, por eso vamos a introducir la enumeración que determina los posibles tipos de la estadística:
//+------------------------------------------------------------------+ //| Determina el tipo del criterio de usuario a calcular | //| después de la optimización. | //+------------------------------------------------------------------+ enum ENUM_CUSTOM_TYPE { CUSTOM_NONE, // Criterio de usuario no se calcula CUSTOM_R2_BALANCE, // R^2 calculado a base del balance de la estrategia CUSTOM_R2_EQUITY, // R^2 calculado a base de equity de la estrategia };
En esta enumeración se puede observar que el criterio de usuario de optimización tiene tres tipos: R² calculado según los resultados de las transacciones, R² calculado según los datos de la equidad, y la falta del cálculo de la estadística
Podemos añadir la posibilidad del ajuste del tipo del cálculo personalizado. Para eso añadimos a la clase CStrategyList los métodos adicionales SetCustomOptimaze*:
//+------------------------------------------------------------------+ //| Establece R² como criterio de optimización. El coeficiente | //| se calcula para las transacciones realizadas. | //+------------------------------------------------------------------+ void CStrategyList::SetCustomOptimizeR2Balance(ENUM_CORR_TYPE corr_type) { m_custom_type = CUSTOM_R2_BALANCE; m_corr_type = corr_type; } //+------------------------------------------------------------------+ //| Establece R² como criterio de optimización. El coeficiente | //| se calcula según la equidad guardada. | //+------------------------------------------------------------------+ void CStrategyList::SetCustomOptimizeR2Equity(ENUM_CORR_TYPE corr_type) { m_custom_type = CUSTOM_R2_EQUITY; m_corr_type = corr_type; }
Cada uno de estos métodos establece su configuración para la variable ENUM_CUSTOM_TYPE m_custom_type y el segundo parámetro igual al tipo de la correlación ENUM_CORR_TYPE:
//+------------------------------------------------------------------+ //| Tipo de correlación | //+------------------------------------------------------------------+ enum ENUM_CORR_TYPE { CORR_PEARSON, // Correlación del Pearson CORR_SPEARMAN // Correlacion de rango de Spearman };
Es necesario saber de este parámetro adicional. Es que, R² es nada más que la correlación entre el gráfico y su modelo lineal. No obstante, el tipo de correlación puede ser diferente. Usamos la librería matemática AlgLib. Ella soporta dos métodos del cálculo de la correlación: según Pearson y según Spearman. La fórmula de Pearson es clásica y conviene bien para los datos uniformes y distribuidos de manera normal. La correlación de rango de Spearman es más estable a los picos de precios (en inglés spikes) que son bastante frecuentes en el mercado. Por eso nuestro cálculo permitirá trabajar con cada variante del cálculo de R².
Ahora, cuando ya tenemos todos los datos preparados, pasamos directamente al cálculo de R². Lo meteremos en las funciones separadas:
//+------------------------------------------------------------------+ //| Devuelve la estimación de R² calculado a base del balance de la estrategia | //+------------------------------------------------------------------+ double CustomR2Balance(ENUM_CORR_TYPE corr_type = CORR_PEARSON); //+------------------------------------------------------------------+ //| Devuelve la estimación de R² calculado a base de la equidad de la estrategia | //| El valor equity se pasa como el array equity | //+------------------------------------------------------------------+ double CustomR2Equity(double& equity[], ENUM_CORR_TYPE corr_type = CORR_PEARSON);
Van a ubicarse en el archivo separado RSquare.mqh. El cálculo está realizado en forma de la función para que cualquier usuario pueda incluir fácil y rápidamente este modo del cálculo en su proyecto. Además, no es necesario usar CStrategy. Por ejemplo, para calcular R² en su EA, basta con redeterminar la función de sistema OnTester:
double OnTester() { return CustomR2Balance(); }
Claro que cuando será necesario calcular la equidad de la estrategia, el usuario que no usa CStrategy tendrá que hacerlo personalmente.
Lo último que nos queda hacer en CStrategyList es determinar el método OnTester:
//+------------------------------------------------------------------+ //| Añade el monitoreo de equity | //+------------------------------------------------------------------+ double CStrategyList::OnTester(void) { switch(m_custom_type) { case CUSTOM_NONE: return 0.0; case CUSTOM_R2_BALANCE: return CustomR2Balance(m_corr_type); case CUSTOM_R2_EQUITY: { double equity[]; m_equity_exp.GetEquityArray(equity); return CustomR2Equity(equity, m_corr_type); } } return 0.0; }
Ahora vamos a considerar la implementación de las funciones CustomR2Equity y CustomR2Balance.
Cálculo del coeficiente de la determinación R² usando AlgLib
Vamos a implementar el coeficiente de la determinación R² usando AlgLib (librería multiplataforma del análisis numérico). Nos permite calcular diferentes criterios estadísticos, de los más simples hasta los más avanzados.
Vamos a indicar los pasos del cálculo del coeficiente.
- Obtenemos los valores de equity y los convertimos en la matriz M[x, y], donde x es el número de la medición, y es el valor de la equidad.
- Calculamos los coeficientes a y b de la ecuación de la regresión lineal para la matriz obtenida.
- Generamos los valores de la regresión lineal para cada X y los colocamos en el array.
- Encontramos el coeficiente de la correlación de la regresión lineal y valores de equity, usando una de dos fórmulas de correlación.
- Calculamos R² y su signo.
- Devolvemos el valor normalizado de R² de la función llamante.
Estos pasos se realizan por la función CustomR2Equity. A continuación, se muestra su código fuente:
//+------------------------------------------------------------------+ //| Devuelve la estimación de R² calculado a base de la equidad de la estrategia | //| El valor equity se pasa como el array equity | //+------------------------------------------------------------------+ double CustomR2Equity(double& equity[], ENUM_CORR_TYPE corr_type = CORR_PEARSON) { int total = ArraySize(equity); if(total == 0) return 0.0; //-- Llenamos la matriz Y - valor de equity, X - número de orden del valor CMatrixDouble xy(total, 2); for(int i = 0; i < total; i++) { xy[i].Set(0, i); xy[i].Set(1, equity[i]); } //-- Buscamos los coeficientes a y b del modelo lineal y = a*x + b; int retcode = 0; double a, b; CLinReg::LRLine(xy, total, retcode, a, b); //-- Generamos los valores de la regresión lineal para cada X; double estimate[]; ArrayResize(estimate, total); for(int x = 0; x < total; x++) estimate[x] = x*a+b; //-- Encontramos el coeficiente de la correlación de los valores con su regresión lineal double corr = 0.0; if(corr_type == CORR_PEARSON) corr = CAlglib::PearsonCorr2(equity, estimate); else corr = CAlglib::SpearmanCorr2(equity, estimate); //-- Encontramos R² y su signo double r2 = MathPow(corr, 2.0); int sign = 1; if(equity[0] > equity[total-1]) sign = -1; r2 *= sign; //-- Devolvemos la estimación normalizada de R² con precisi”on hasta centésimos return NormalizeDouble(r2,2); }
Este código accede a tres métodos estadísticos: CAlgLib::LRLine, CAlglib::PearsonCorr2 y CAlglib::SpearmanCorr2. El principal de ellos desde luego es CAlgLib::LRLine, que calcula los coeficientes de la regresión lineal.
Ahora, describiremos la segunda función del cálculo de R²: CustomR2Balance. Su nombre nos indica que la función calcula este índice a base de las transacciones realizadas. Su trabajo consiste en la formación del array double que contiene la dinámica del balance, para eso se repasan todas las transacciones históricas:
//+------------------------------------------------------------------+ //| Devuelve la estimación de R² calculado a base del balance de la estrategia | //+------------------------------------------------------------------+ double CustomR2Balance(ENUM_CORR_TYPE corr_type = CORR_PEARSON) { HistorySelect(0, TimeCurrent()); double deals_equity[]; double sum_profit = 0.0; int current = 0; int total = HistoryDealsTotal(); for(int i = 0; i < total; i++) { ulong ticket = HistoryDealGetTicket(i); double profit = HistoryDealGetDouble(ticket, DEAL_PROFIT); if(profit == 0.0) continue; if(ArraySize(deals_equity) <= current) ArrayResize(deals_equity, current+16); sum_profit += profit; deals_equity[current] = sum_profit; current++; } ArrayResize(deals_equity, current); return CustomR2Equity(deals_equity, corr_type); }
Una vez formado el array, se traspasa a la entrada de la función que ya conocemos, CustomR2Equity. Efectivamente, la función CustomR2Equity es universal, ella calcula el valor de R² para los datos de cuelquier tipo que forman parte del array equity[], sea la dinámica del balance , sea el valor del beneficio no realizado.
Nuestro último paso será una pequeña modificación en el código del EA CImpulse, a saber, redeterminación del evento de sistema OnTester:
//+------------------------------------------------------------------+ //| Tester event | //+------------------------------------------------------------------+ double OnTester() { Manager.SetCustomOptimizeR2Balance(CORR_PEARSON); return Manager.OnTester(); }
En esta función se establece el tipo del parámetro de usuario, y luego se devuelve su valor.
Ahora podemos ver nuestro coeficiente de cálculo en acción. Después del inicio de la prueba histórica de la estrategia CImpulse, nuestro parámetro aparece en el informe:
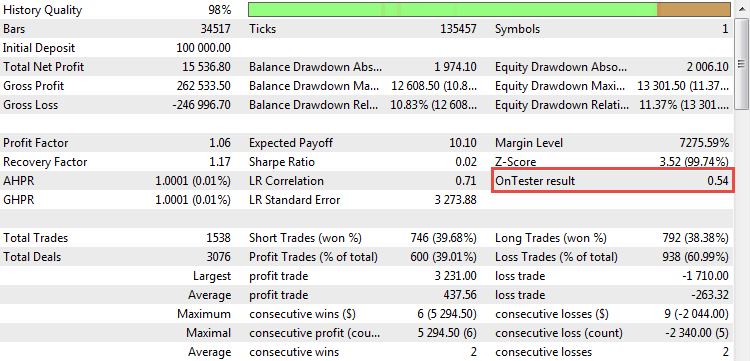
Fig. 21. Valor R² como criterio de optimización de usuario.
Uso del parámetro R² en la práctica
Ahora, cuando el R² estaá incorporado como un criterio de optimización personalizado, ha llegado el momento de aprobarlo en la práctica. Para eso optimizamos CImpulse en el timeframe М15 del símbolo EURUSD. Guardamos el informe de optimización obtenido en el archivo Excel, y a base de las estadísticas obtenidas procedemos a comparar varios repasos seleccionados según diferentes criterios.
Es la lista completa de los parámetros:
- Símbolo: EURUSD
- Timeframe: 1H
- Período: 2015.01.03 - 2017.10.10
El rango de los parámetros del EA se especifica en la lista:
| Parámetro | Inicio | Paso | Stop | Número de pasos |
|---|---|---|---|---|
| PeriodMA | 15 | 5 | 200 | 38 |
| StopPercent | 0.1 | 0.05 | 1.0 | 19 |
Una vez realizada la optimización, hemos obtenido la nube de optimización compuesta de 722 variantes:
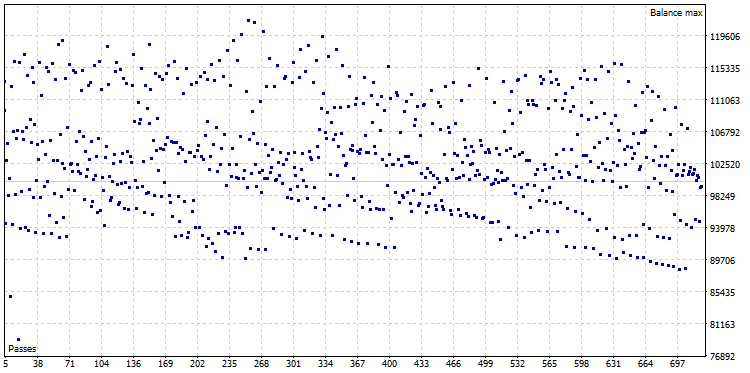
Fig. 22. Nube de optimización CImpulse, símbolo EURUSD, timeframe 1H
Seleccionamos el repaso cuyo beneficio es máximo y visualizamos su gráfico del balance:
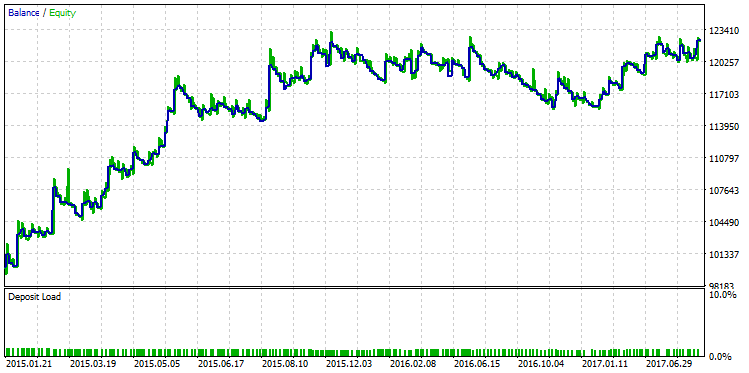
Fig. 23. Gráfico del balance de la estrategia seleccionada según el criterio del beneficio máximo
Ahora, vamos a buscar el mejor repaso según el parámetro R². Para eso, guardamos los repasos de la optimización en el archivo XML. Si tenemos instalado Microsoft Excel, el archivo se abrirá automáticamente en él. Nosotros vamos a trabajar con la ordenación y los filtros, por eso seleccionamos el encabezado de la tabla y pulsamos el botón homónimo (Inicio -> Ordenación y filtro -> Filtro). Después de eso, aparecerá la posibilidad de una visualización flexible de las columnas. Ordenamos los repasos según el criterio personalizado de la optimización:
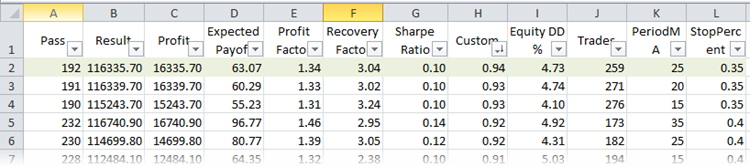
Fig. 24. Repasos de la optimización en Microsoft Exce ordenados según R²
La primera línea de la tabla va a contener el mejor R² de toda la muestra. Está marcada con color verde en la imagen de arriba. En el Probador de estrategias, el conjunto de estos parámetros nos da el siguiente gráfico del balance:
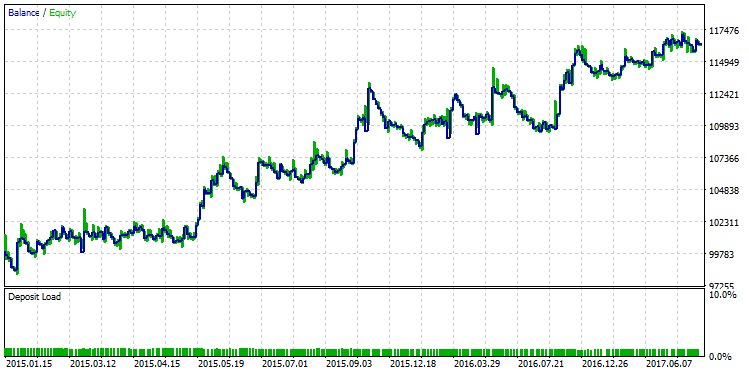
Fig. 25. Gráfico del balance de la estrategia seleccionada según R² máximo.
La diferencia de la claidad de estas dos líneas del balance se observa perfectamente. Mientras que el repaso con el beneficio máximo «se ha quebrado» en diciembre de 2015, la otra variante con R² máximo ha continuado un aumento estable.
A menudo R² depende del número de transacciones, y habitualmente puede exagerar sus indicaciones. En esta relación R² correlaciona con ProfitFactor. En algunos tipos de las estrategias, un índice alto de ProfitFactor va hombro con hombro con un valor alto de R². Sin embargo, eso no siempre puede ser así. Para ilustrar eso, vamos a seleccionar un contraejemplo de la muestra que demuestra la diferencia entre R² y ProfitFactor. En la imagen de abajo se muestra el repaso de la estrategia que tiene uno del índices más altos de ProfitFactor, igual a 2,98:
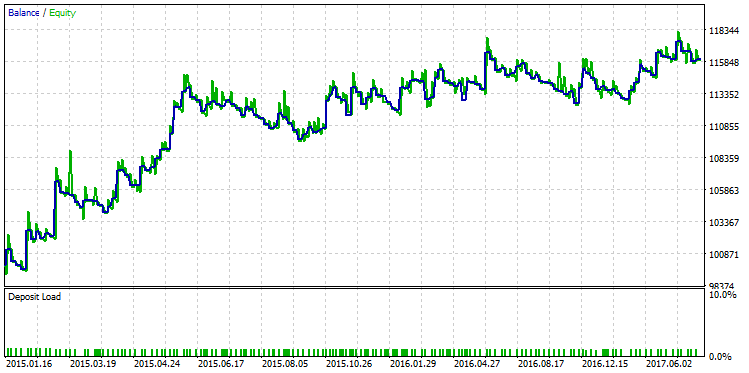
Fig. 26. Repaso de la estrategia con ProfitFactor igual a 2,98
En el gráfico se ve que aunque la estrategia muestra un crecimiento seguro, la calidad de la curva del balance es más baja que la variante con el índice máximo de R².
Ventajas y limitaciones en el uso
Cada métrica estadística tiene sus ventajas y desventajas. En este sentido, R² no es una excepción. La tabla de abajo contiene sus lados débiles y las soluciones que pueden corregirlos:
| Desventajas | Solución |
|---|---|
| Dependen del número de transacciones. Exagera los índices con pocas transacciones. | Cálculo del índice R² a base de los valores de equity de la estrategia soluciona parcialmente este problema. |
| Correlaciona con las métricas ya existentesde la eficacia de la estrategia, en particular, correlaciona con Profit Factor y beneficio neto de la estrategia. | La correlación no es igual a 100%. Dependiendo de las particularidades de la estrategia, R² puede no correlacionar con cualquier métrica en absoluto, o correlacionar debilmente. |
| Para el cálculo, hacen falta unos cómputos metemáticos complicados. | El algoritmo se implementa a través de la librería AlgLib, a la que se delega toda la complejidad. |
| Es aplicable exclusivamente para la estimación de los procesos lineales, o los sistemas que negocian con un lote fijo. | No aplicar para los sistemas comerciales que usan el sistemade capitalización (Gestión de capital). |
Vamos a describir el problema de la aplicación de R² a los sistemas no lineales (por ejemplo, a los sistemas comerciales con un lote dinámico) más detalladamente.
Vuelvo a decir que la tarea principal de cada trader consiste en maximizar el beneficio. La condición imprescindible para eso es la aplicación de diferentes sistemas de capitalización. El sistema de capitalización es la conversión del proceso lineal en no lineal (por ejemplo, exponencial). Pero después de esta conversión, la mayor parte de los parámetros estadísticos pierde su sentido. Por ejemplo, para los sistemas capitalizados, el parámetro «beneficio neto» no tiene sentido, ya que un pequeño desplazamiento del intervalo temporal de la simulación o el cambio del parámetro de la estrategia por una centésima del por ciento puede alterar el resultado final en decenas o incluso centenares de veces.
Otros parámetros de la estrategia también pierden sentido, como, por ejemplo, el factor de beneficio, beneficio esperado, ganancia/pérdida máxima, y los demás. En este sentido, R² tampoco es una excepción. Puesto que está creado para la estimación lineal de la regularidad de la curva del balance, se hace impotente durante la estimación de los procesos no lineales. Por esa razón, hay que simular cualquier estrategia en forma no lineal, y sólo después de eso añadir el sistema de capitalización a la versión escogida. Es mejor estimar los sistemas no lineales usando unas métricas estadísticas especiales (por ejemplo, GHPR), o bien calcular la rentabilidad en por cientos anuales.
Conclusión
- Los parámetros estadísticos estándar de la estimación de los sistemas comerciales tienen sus desventajas que deben tomarse en cuenta.
- De las métricas estándar de MetaTrader 5, sólo LR Correlation conviene para estimar la regularidad de la curva del balance de la estrategia. No obstante, sus valores a menudo se exageran.
- R cuadrado (R²) es una de las pocas métricas que calculan la regularidad de la curva tanto de la línea del balance, como del beneficio no registrado de la estrategia. En este caso, R² no tiene desventajas de LR Correlation.
- Para el cálculo de R², se aplica la librería matemática AlgLib. Este cálculo tiene varias modificaciones y se describe en detalle en el ejemplo correspondiente.
- Es posible incorporar el criterio personalizado de optimización en el Asesor Experto de tal manera que todos los EAs tengan la posibilidad de calcular esta métrica automáticamente sin su participación. La manera de hacerlo se describe en el ejemplo de la incorporación de R² en el motor comercial CStrategy.
- Mediante la incorporación similar se puede calcular los datos adicionales, que son necesarios para la estadística de usuario. Para R² estos datos son los datos sobre el beneficio no registrado de la estrategia (equity). El motor comercial CStrategy se encarga de memorizar la dinámica del beneficio no registrado.
- El coeficiente de determinación permite seleccionar las estrategias con el crecimiento regular del balance/equity. En este caso, el proceso de selección basado en otros parámetros puede omitir semejantes variantes.
- R², igual como cualquier otra métrica estadística, tiene sus defectos que deben ser considerados para el trabajo con este indicador.
De esta manera, se puede decir con certeza que el coeficiente de determinación R² es un suplemento importante para el conjunto de métricas existente en MetaTrader 5. Permite estimar la regularidad de la curva de la línea del balance de la estrategia, lo que ya por sí mismo es un indicador no trivial. R² es fácil de usar: su rango de valores es fijo y se encuentra dentro de los límites de -1,0 a +1,0, avisando de la tendencia negativa del balance de la estrategia (valores cercanos a -1,0), falta de la tendencia (valores cerca de 0,0) y una dentencia positiva (valores que tienden a +1,0). Gracias a todas estas propiedades, robustez y la sencilles, R² puede ser recomendado para el uso en la construcción de un sistema comercial rentable.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/2358
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Asesor Experto multiplataforma: las clases CExpertAdvisor y CExpertAdvisor
Asesor Experto multiplataforma: las clases CExpertAdvisor y CExpertAdvisor
 Neuroredes profundas (Parte IV). Creación, entrenamiento y simulación de un modelo de neurored
Neuroredes profundas (Parte IV). Creación, entrenamiento y simulación de un modelo de neurored
 Colocando las entradas por los indicadores
Colocando las entradas por los indicadores
 Usando el filtro de Kalman en la predicción del precio
Usando el filtro de Kalman en la predicción del precio
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hay mucha información aquí explicando el razonamiento y tu código, y te lo agradezco. Aquí está la versión Tl;dr para aquellos de nosotros para quienes la mayor parte de esto pasó por encima de nuestras cabezas:
1. Añade los includes
2. Y el OnTester:
Eso es todo para implementarlo basado en el equilibrio.
Si su EA utiliza CStrategy (como lo hacen los EAs asistentes), a continuación, añadir el mismo incluye, y se puede cambiar a la equidad de esta manera:
Lo que NO he averiguado todavía, y espero que alguien me pueda ayudar, es qué hacer para implementar el equity listener en tu propio EA que no esté basado en CStrategy. Todo lo que el artículo dice es:
Y no sé cómo hacerlo.Corregidos los errores. Se adjunta el archivo.
Gracias, actualizado el artículo.
Debería ser muy similar... ¡tengo una comparación en mi larga y desorganizada lista de cosas por hacer!
Normalice el volumen : Tome el beneficio y divídalo por el tamaño del lote
O divida el saldo[0] por el saldo[1] para obtener la rentabilidad, y calcule r^2 para la curva de rentabilidad