
Handling ZIP Archives in Pure MQL5

Table of Contents
- Introduction
- Chapter 1. Format of ZIP file and data storage
- Chapter 2. Overview of CZip class and its algorithms
- Chapter 3. Examples of using CZip class, performance measurement
- Chapter 4. Documentation for classes operating with ZIP archives
- Conclusion
Introduction
History behind the subject
Once this article's author got attracted by an interesting feature of CryptDecode function, in particular its ability to decompress a ZIP array transferred to it. This modifier was introduced by the developers of MetaTrader 5 trading platform in order to extract answers from several servers using the standard WebRequest function. However, due to certain features of the ZIP file format, it was impossible to use it directly.
Additional authentication was required: to decompress an archive it was required to know its hash sum before compressing - Adler-32 which, clearly, wasn't available. However, when discussing this issue, the developers met the request to overload CryptDecode and CryptEncode, its mirror-image twin, with a special flag that allowed to ignore Adler32 hash when decompressing the transmitted data. For inexperienced from technical perspective users this innovation could be easily explained: it enabled full functionality of ZIP archives. This article describes the ZIP file format, its specifics of data storage and offers convenient object-oriented CZip class to operate with an archive.
Why is it needed?
Data compression is one of the most important technologies, particularly widespread on the Web. The compression helps to save resources required for transmission, storage and processing of data. Data compression is used in practically all areas of communications and has reached almost all computer related tasks.
The financial sector is no exception: gigabytes of tick history, flow of quotes, including Depth of Market (Level2-data) cannot be stored in a raw, uncompressed form. Many servers, including the ones providing analytical information useful for trading, also store data in ZIP archives. Previously it was impossible to obtain this information automatically using standard tools of MQL5. Now the situation has changed.
Using the WebRequest function you can download a ZIP archive and instantly decompress it on the computer. All of these features are important and will definitely be in demand by many traders. Data compression can even be used for optimizing the computer's memory. How this is done, we will describe in Section 3.2 of this article. Finally, the ability to operate with ZIP archives gives access to the document formation like Microsoft Office standard Office Open XML, which in turn enables to create simple Excel or Word files directly from MQL5, also without using third party DLL libraries.
As you can see, the ZIP archive application is extensive, and the class we are creating will serve all MetaTrader users well.
In the first chapter of this article we will describe a format of a ZIP file and get idea about what blocks of data it contains. This chapter will be of interest not only to those who study MQL, but it can also serve as a good educational material for those involved in matters related to archiving and data storage. The second chapter is concerned with CZip, CZipFile and CZipDirectory classes which are the major object-oriented elements operating with archives. The third chapter describes practical examples related to the use of archiving. And the fourth chapter contains documentation related to the proposed classes.
So, let's proceed to studying the most common archiving type.
Chapter 1. Format of ZIP file and data storage
1.1. Structure of ZIP file
ZIP format was created by Phil Katz in 1989 and was first implemented in the PKZIP program for MS-DOS, released by the company PKWARE that Katz founded. This format of archiving most frequently uses DEFLATE data compression algorithm. The most common programs to work in Windows with this format are WinZip and WinRAR.
It is important to understand that the ZIP archive format has developed over time and has several versions. To create a class that will operate with a ZIP archive we will rely on official format specification of version 6.3.4 placed on the PKWARE company website: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT. This is the latest format specification dated October 1, 2014, which is extensive and includes descriptions of numerous nuances.
In this article we are guided by the principle of least effort and will create a tool that will use only the most necessary data for a successful file extraction and creation of new archives. This means that operation with ZIP files will be limited to a certain extent - format compatibility is not guaranteed, hence there is no need to mention the complete "omnivory" of archives. There is a possibility, that some ZIP archives created by third-party funds can't be extracted by the proposed instrument.
Each ZIP archive is a binary file that contains an ordered sequence of bytes. On the other hand, every file of a ZIP archive has a name, attributes (such as file modification time), and other properties, that we are used to seeing in a file system of any operating system. Therefore, in addition to the compressed data, each ZIP archive stores the name of a compressed file, its attributes, and other service information. The service information is placed in a very specific manner and has a regular structure. For example, if an archive contains two files (File#1 and File#2), then it will have the following scheme:
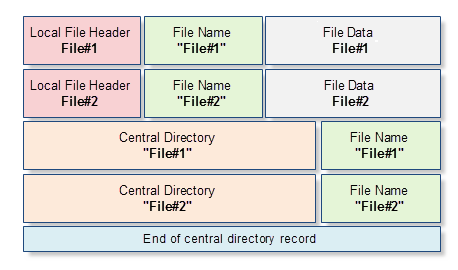
Fig. 1. Schematic representation of a ZIP archive that contains two files: File#1 and File#2
At a later stage we will examine each block of this scheme, but at the moment we will give a brief description of all the blocks:
- Local File Header — this data block contains basic information about the compressed file: the file size before and after compression, file modification time, CRC-32 checksum and local pointer to the file's name. In addition to that, this block contains the archiver version necessary for decompressing the file.
- File Name is a sequence of bytes with arbitrary length that forms the compressed file's name. The length of the file's name should not exceed 65 536 characters.
- File Data is a compressed file's content in the form of an arbitrary length byte array. If the file is empty or comprises a directory, then this array is not used, and the Local File Header title describing the next file follows the file's name or directory.
- Central Directory provides expanded data view in Local File Header. In addition to the data contained in the Local File Header, it has file attributes, a local reference to the structure of Local File Header and other mostly unused information.
- End of central directory record - this structure is presented as a singleton template in every archive and is written in the archive's end. The most interesting data it contains is a number of archive's records (or a number of files and directories) and local references to the start of the Central Directory block.
Each block of this scheme can be presented either as a regular structure, or as an arbitrary length byte array. Each structure can be described with a structure, which is the same name programming construction of MQL.
The structure always takes a fixed number of bytes, therefore it can't contain arbitrary length arrays and lines. However, it can have pointers to these objects. This is the reason the archive's file names are placed outside the structure, so they can be of any length. The same applies to the compressed data files - their size is arbitrary, therefore they are also kept outside the structures. This way we can conclude that a ZIP archive is presented by the sequence of patterns, lines and compressed data.
The ZIP file format, in addition to the above, describes the additional structure, the so-called Data Descriptor. This structure is used only in the case, when the structure of Local File Header for some reason cannot be formed, and the fraction of data required for Local File Header becomes available after the data compression. In practice, current situation appears to be very exotic, therefore this structure is almost never used, and in our class for operating with archives this data block is not supported.
| Please note that according to the ZIP archive format, each file is compressed separately from the rest. On the one hand, it allows to locate the occurrence of errors, a "broken" archive can be restored by deleting files with wrong contents and leaving the remaining contents without any changes. On the other hand, when compressing each file separately, the compression efficiency is decreased, in particular when each file only takes little space. |
|---|
1.2. Studying ZIP file in a hexadecimal editor
Armed with the most necessary knowledge we can see what is inside a typical ZIP archive. To do this, we are going to use a hexadecimal editor WinHex. If for some reason you don't have WinHex, you can use any other hexadecimal editor. After all, we remember that any archive is a binary file that can be opened as a simple sequence of bytes. As an experiment we will create a simple ZIP archive that contains a single text file with a phrase "HelloWorld!":

Fig. 2. Creating a text file in Notepad
Then we will use any ZIP archiver to create an archive. In our case WinRAR will be such an archiver. It is necessary to select the file we just created and archive it in the ZIP format:
Fig. 3. Using WinRAR archiver to create an archive
After we are finished with archiving on the computer's hard disk, a new file "HelloWorld.zip" will appear in the corresponding directory. The first striking feature of this file is that its size of 135 bytes is considerably bigger than the source text file of 11 bytes. This is due to the fact that besides the compressed data, the ZIP archive also contains service information. Therefore, archiving is pointless for small volumes of data that only take a few hundred of bytes.
Now that we have the data layout scheme, the idea of an archive consisting of a set of bytes does not seem so frightening to us. We will open it with a hexadecimal editor WinHex. The figure below shows the archive's byte array with a conditional highlighting of each area described in Scheme 1:
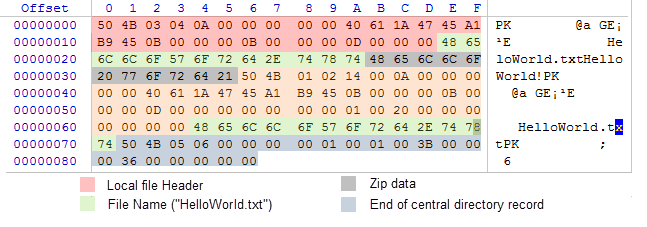
Fig. 4. Internal contents of ZIP archive containing HelloWorld.txt file
Actually, the phrase "HelloWorld!" is contained in the range of 0x35 to 0x2B bytes and occupies only 11 bytes. Please note that the compression algorithm has decided not to compress the original phrase, and in the ZIP archive it is present in its original form. This happened because the compression of such short message is inefficient, and the compressed array can become heavier than the uncompressed one.
| A ZIP archive doesn't always contain compressed data. Sometimes the archived data is located in the original, uncompressed form, even if when the archive was created, it was clearly stated to compress data during archiving. This situation arises when the data volume is insignificant, and the data compression is inefficient. |
|---|
If you look at Fig. 4, it becomes clear how different data blocks are stored in a compressed archive, and where the file's data is held exactly. Now it is time to analyze each of the data blocks individually.
1.3. Structure of Local File Header
Each ZIP archive begins with the Local File Header structure. It contains metadata of a file that follows it as a compressed byte array. Each structure of an archive according to the format specification has its unique four-byte identifier. This structure is no exception, its unique identifier equals 0x04034B50.
You should know, that the x86-based processors load data from the binary files to RAM in a reverse order. The numbers are located inside out: the last byte takes the place of the first byte and vice versa. A method of writing data in the file is determined by the file's format, and for the ZIP files it is also carried out in a reverse order. For more information about the byte sequence please read the article on Wikipedia - "Endianness". For us it means, that the structure identifier will be written as a figure 0x504B0304 (inside out value 0x04034B50). Any ZIP archive starts with this byte sequence.
Since the structure is a strictly defined byte sequence, it can be presented as a similar structure in the MQL5 programming language. The description of the Local File Header structure on MQL5 is the following:
//+------------------------------------------------------------------+ //| Local file header based on specification 6.3.4: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // ZIP local header, always equals 0x04034b50 ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compression method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC-32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
This structure is used for real operation with ZIP archives, so besides the data field it contains additional methods allowing to convert structure into a set of bytes (byte array uchar) and, conversely, to create a structure from the sets of bytes. Here are the contents of ToCharArray and LoadFromCharArray methods that enable such conversion:
//+------------------------------------------------------------------+ //|Private struct for convert LocalHeader to uchar array | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // Size of ZipLocalHeader }; //+------------------------------------------------------------------+ //| Convert ZipHeader struct to uchar array. | //| RETURN: | //| Numbers of copied elements. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| Init local header structure from char array | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
Let's describe the fields' structure (listed in order):
- header — unique structure identifier, for File Local Header equals 0x04034B50;
- version — minimum version for unzipping files;
- bit_flag — byte flag, has identifier 0x02;
- comp_method — type of compression used. Normally a compression method DEFLATE with an identifier 0x08 is used.
- last_mod_time — last file modification time. It contains hours, minutes and seconds of the file modification in the MS-DOS format. This format is described on the Microsoft company web page.
- last_mod_date — last file modification date. It contains a day of a month, a number of a month in a year and a year of the file modification in the MS-DOS format.
- crc_32 — checksum CRC-32. It is used by the programs working with archives to locate errors of file contents. If this field is not filled, a ZIP archiver will refuse to unpack the compressed file referring to the corrupted file.
- comp_size — size of compressed data in bytes;
- uncomp_size — size of original data in bytes;
- filename_length — length of file name;
- extrafield_length — special field for writing additional data attributes. It is almost never used, equals zero.
When saving this structure in the archive, a sequence of bytes that holds values of the corresponding fields of this structure is created. We will reload our ZIP archive with the file HelloWorld.txt to the hex editor and this time will thoroughly analyze the byte array of this structure:

Fig. 5. Byte chart of Local File Header structure in the HelloWorld.zip archive
The chart shows, which bytes fill up the structure's fields. To verify its data we will pay attention to the field "File Name length", it takes 2 bytes and equals the value of 0x0D00. By turning this number inside out and placing it in decimal format we get a value of 13 - which is also the number of symbols the file "HelloWorld.txt" has. The same can be done with a field that indicates the size of compressed data. It equals 0x0B000000 which corresponds to 11 bytes. In fact, the phrase "HelloWorld!" is stored in the archive uncompressed and takes up 11 bytes.
The structure is followed by the compressed data, and then the new structure begins - Central Directory, which in the next sections we will cover in more details.
1.4. Structure of Central Directory
The structure of Central Directory is an expanded data presentation in Local File Header. In fact, for the basic work with ZIP archives data from the Local File Header is sufficient. However, the use of Central Directory structure is mandatory and its value must be filled out correctly. This structure has its unique identifier 0x02014B50. In MQL5 its presentation will be the following:
//+------------------------------------------------------------------+ //| Central directory structure | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // Central directory header, always equals 0x02014B50 ushort made_ver; // Version made by ushort version; // Minimum version for extracting ushort bit_flag; // Bit flag ushort comp_method; // Compressed method (0 - uncompressed, 8 - deflate) ushort last_mod_time; // File modification time ushort last_mod_date; // File modification date uint crc_32; // CRC32 hash uint comp_size; // Compressed size uint uncomp_size; // Uncompressed size ushort filename_length; // Length of the file name ushort extrafield_length; // Length field with additional data ushort file_comment_length; // Length of comment file ushort disk_number_start; // Disk number start ushort internal_file_attr; // Internal file attributes uint external_file_attr; // External file attributes uint offset_header; // Relative offset of local header bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
As you can see, it already contains more data, however, most of them duplicate data of Local File Header. Just like its previous structure, it contains service methods to convert its contents to a byte array and vice versa.
We describe its field:
- header — unique structure identifier, equals 0x02014B50;
- made_ver — archiving standard version used for archiving;
- version — minimum standard version for successful file decompression;
- bit_flag — byte flag, has identifier 0x02;
- comp_method — type of compression used. Normally, DEFLATE compression method is used, this type of compression has an identifier0x08.
- last_mod_time — last file modification time. It contains hours, minutes and seconds of the file modification in the MS-DOS format. This format is described on the Microsoft company web page.
- last_mod_date — last file modification date. It contains a day of a month, a number of a month in a year and a year of the file modification in the MS-DOS format.
- crc_32 — checksum CRC-32. It is used by the programs working with archives to locate errors of file contents. If this field is not filled, a ZIP archiver will refuse to unpack the compressed file referring to the corrupted file.
- comp_size — size of compressed data in bytes;
- uncomp_size — size of original data in bytes;
- filename_length — length of file name;
- extrafield_length — special field for writing additional data attributes. It is almost never used, equals zero.
- file_comment_length — length of file comments;
- disk_number_start — number of a disk where archive is written. Almost always equals zero.
- internal_file_attr — file attributes in MS-DOS format;
- external_file_attr — extended file attributes in MS-DOS format;
- offset_header — address where the beginning of Local File Header structure is.
When saving this structure in an archive, a sequence of bytes that stores values of its fields, is created. Here is the bytes' layout in this structure, as in Figure 5:

Fig. 6. Byte-chart of Central Directory structure in the archive HelloWorld.zip
Unlike Local File Header, Central Directory structures have a consecutive order. The beginning address of the first one is specified in the special final data block - ECDR structure. More detailed information about the structure will be provided in the next section.
1.5. Structure of End of Central Directory Record (ECDR)
The structure of End of Central Directory Record (or simply ECDR) completes a ZIP file. Its unique identifier equals 0x06054B50. Each archive contains a single copy of the structure. ECDR stores a number of files and directories that are in the archive, as well as the address of the sequence beginning of the Central Directory structure and their total size. In addition, the data block also stores other information. Here is a complete description of ECDR on MQL5:
//+------------------------------------------------------------------+ //| End of central directory record structure | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // Header of end central directory record, always equals 0x06054b50 ushort disk_number; // Number of this disk ushort disk_number_cd; // Number of the disk with the start of the central directory ushort total_entries_disk; // Total number of entries in the central directory on this disk ushort total_entries; // Total number of entries in the central directory uint size_central_dir; // Size of central directory uint start_cd_offset; // Starting disk number ushort file_comment_lengtt; // File comment length string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
We are going to describe the fields of this structure in more details:
- header — unique structure identifier, equals 0x06054B50;
- disk_number — disk's number;
- disk_number_cd — disk's number from which the Central Directory begins;
- total_entries_disk — total number of entries in the Central Directory (number of files and directories);
- total_entries — all entries (number of files and directories);
- size_central_dir — size of Central Directory section;
- start_cd_offset — byte address of the Central Directory section's beginning;
- file_comment_length — length of archive's comment.
When saving this structure in an archive, a sequence of bytes that stores values of its fields, is created. Here is the bytes' layout of the structure:

Fig. 7. Byte chart of ECDR structure
We will use this data block to determine a number of elements in the array.
Chapter 2. Overview of CZip class and its algorithms
2.1. Structure of compressed files inside an archive, CZipFile and CZipFolder classes
So, in the first chapter we have looked at the format of a ZIP archive. We have analyzed, what types of data it consists of and described these types in the relevant structures. After defining these types we will implement high-level specialized class CZip, which can be used to perform the following actions with ZIP archives quick and easy:
- To create a new archive;
- To open a previously created archive on a hard drive;
- To download archive from a remote server;
- To add new files to an archive;
- To delete files from an archive;
- To unpack a complete archive or its files separately.
The CZip class can be used to complete the necessary structures of an archive correctly by providing us with the usual high-level interface for working with file archive collection. The class provides multiple opportunities suitable for most tasks related to archiving.
Obviously, the contents of a ZIP archive can be divided into folders and files. Both types of content have an extensive set of features: name, size, file attributes, time of creation etc. Some of these properties are common for both folders and files, and some, such as compressed data, are not. The optimal solution for using archives would be to provide special service classes: CZipFile and CZipDirectory. These particular classes will be providing files and folders, respectively. Conditional classification of archive's content is shown on the chart below:
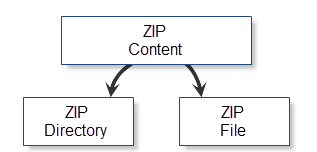
Fig. 8. Conditional classification of archive objects
Thus, to add a file to the CZip archive you must first create an object of CZipFile type, and then add this object file in the archive. As an example, we will create a text file "HelloWorld.txt", that contains the same name text "HelloWorld!", and add it to the archive:
//+------------------------------------------------------------------+ //| Create file with 'HelloWorld' message | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // we create an empty ZIP archive uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // we write a phrase "HelloWorld!" in a byte array CZipFile* file = new CZipFile("HelloWorld.txt",content); // we create a ZIP file with a name "HelloWorld.txt" // that contains a byte array "HelloWorld!" zip.AddFile(file); // we add ZIP file to archive zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // we save the archive on a disk and call it "HelloWorld.zip" printf("Size: "+(string)zip.Size()); }
After executing this code on the computer's disk, a new ZIP archive containing a single text file "HelloWorld.txt" with the same name phrase will appear. If we wanted to create a folder instead of a file, then instead of the CZipFile we would need to create a copy of the CZipFolder class. For this purpose specifying only its name would be sufficient.
As already stated, CZipFile and CZipFolder classes have a lot in common. Therefore, both classes are inherited from their common ancestor — CZipContent. This class contains generic methods and data for operation with the archive's contents.
2.2. Creating compressed files with CZipFile
Creating a compressed ZIP file is identical to creating a copy of CZipFile. As already known, in order to create a file you must specify its name and contents. Therefore, the CZipFile builder also requires an explicit indication of relevant parameters:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
In section 2.1 the call of this constructor is shown.
In addition to that, sometimes it is not required to create a file, but to download an existing file from a disk. In this case there is a second builder in the CZipFile class that enables the creation of a ZIP file based on a regular file of a hard disk:
//+------------------------------------------------------------------+ //| Create ZIP file from file array and name | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
All work in this builder is delegated to the AddFile private method. Its operation algorithm is the following:
- The indicated file is opened for reading, its contents are read off into a byte array.
- The obtained byte array is compressed using the AddFileArray method and is stored in a special dynamic array of uchar type.
The AddFileArray method is the "heart" of the entire class system for working with archives. After all, this method has the most important system function - CryptEncode. Here is the source code for this method:
//+------------------------------------------------------------------+ //| Add file array and zip it. | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
The configuration of the CryptEncode function is marked with yellow with subsequent archiving of a byte array. Thus, we can conclude that the file compressing occurs at the point of creation of the CZipFile object, rather than the point of creation or preservation of the ZIP archive itself. Due to this quality all data transmitted to the CZip class is automatically compressed and thus require less memory for their storage.
Please note that in all cases the unsigned byte array uchar is used as data. In fact, all data that we operate on a computer can be represented as a certain byte sequence. Therefore, to create a truly universal container for compressed data, which CZipFile actually is, an unsigned uchar array was selected.
| The user must convert data for archiving in the uchar[] unsigned array himself, which in turn must be passed via a reference as the file contents for the CZipFile class. Because of this feature absolutely any type of files, either downloaded from the disk or created in the process of MQL-programme operation, can be placed in a ZIP archive. |
|---|
Extracting data is a more trivial task. To extract data into the original byte array file_array the GetUnpackFile method is used, which is essentially a wrapper method for the CryptDecode system function:
//+------------------------------------------------------------------+ //| Get unpack file. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. Remembering MS-DOS. Time and date format in a ZIP archive
The ZIP format of data storage was created in the late 80s of the last century for the MS-DOS platform whose "legal successor" became Windows. Back then the resources for data storage were limited, so date and time of the MS-DOS operating system were stored separately: two bytes (or a word for 16-bit processors of that time) were allocated for data and two bytes - for time. Moreover, the earliest date that could be represented by this format was 1 January 1980 (01.01.1980). Minutes, hours, days, months and years occupied certain byte ranges in a word, and to extract or burn data it is still required to resort to the byte operations.
The specification of this format is available on the Microsoft website at the following link: https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx.
Here is the data storage format in the corresponding two-byte field:
| N of bytes | Description |
|---|---|
| 0-4 | Day of month (0-31) |
| 5-8 | Month number (1 — January, 2 — February etc.) |
| 9-15 | Year number from 1980 |
Table 1. Format of date storage in two-byte field
Similarly, we will indicate the time storage format in the corresponding two-byte field:
| N of bytes | Description |
|---|---|
| 0-4 | Seconds (storage accuracy +/- 2 seconds) |
| 5-10 | Minutes (0-59) |
| 11-15 | Time in 24-hour format |
Table 2. Format of time storage in two-byte field
Knowing the specification of this format and being able to work with byte operations, you can write the corresponding functions that convert date and time in MQL format to MS-DOS format. It is also possible to write reverse procedures. Such conversion techniques are common for both folders provided by CZipFolder, and files provided by CZipFile. By setting data and time for them in the usual MQL format, we can convert this type of data to the MS-DOS format "behind the scenes". The methods DosDate, DosTime, MqlDate and MqlTime are involved with such conversion. Please find their source code below.
Data conversion of MQL format to MS-DOS data format:
//+---------------------------------------------------------------------------------+ //| Get data in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::RjyDosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
Data conversion of MS-DOS format to MQL format:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
Time conversion of MS-DOS format to MQL time format:
//+---------------------------------------------------------------------------------+ //| Get Time in MS-DOS format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
Time conversion of MS-DOS format to MQL time format:
//+---------------------------------------------------------------------------------+ //| Get data in MQL format. See specification on: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
These methods use internal variables to store data and time: m_directory.last_mod_time and m_directory.last_mod_date, where m_directory is the Central Directory type structure.
2.4. Generating CRC-32 checksum
An interesting feature of the ZIP archive format is not only about storing the service data, but also a specific information for the recovery purposes, which in some cases helps to restore corrupted data. In order to understand whether the received data is intact or damaged, the ZIP archive contains a special extra field that holds a two-byte hash value CRC-32. This is a checksum which is calculated for data prior to compressing. After the archiver uncompresses data from the archive, it recalculates the checksum, and if it doesn't match, data is considered to be corrupted and cannot be provided to the user.
Thus, our CZip class needs to have its own calculation algorithm CRC-32. Otherwise, the archives created by our class will refuse to read third-party tools, as an example WinRAR can give an error warning about corrupted data:
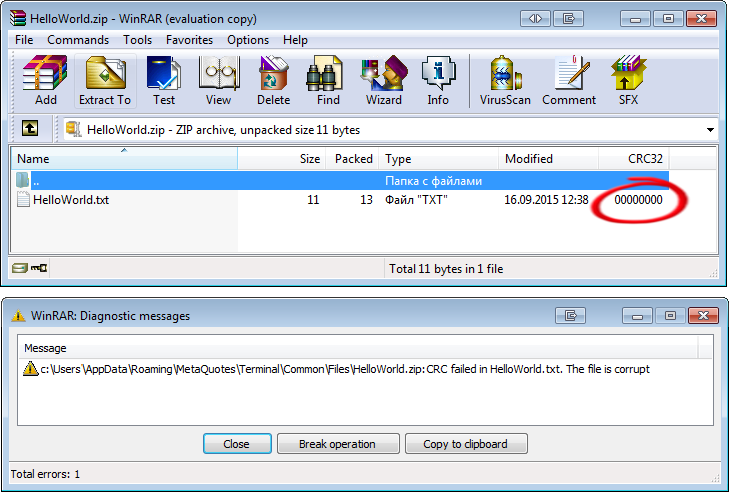
Fig. 9. WinRAR warning about data damage of the "HelloWorld.txt" file.
Since the CRC-32 checksum is required for files only, a method which calculates the sum is provided solely in the CZipFile class. The method is implemented based on the C programming language example available at the following link: https://ru.wikibooks.org:
//+------------------------------------------------------------------+ //| Return CRC-32 sum on source data 'array' | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
To ensure correct method operation it is sufficient to open an archive created in the WinRAR archiver via CZip. Each file will have its unique CRC-32 code:

Fig. 10. Checksum CRC-32 in the window of WinRAR archiver
The archiver unpacks files in the normal mode with a valid CRC-32 hash, and the warning message doesn't appear.
2.5. Reading and writing an archive
Finally, we are going to discuss methods of reading and writing a ZIP archive. Obviously, if we have a collection, for example CArrayObj that consists of elements CZipFile and CZipFolder, the problem of archive formation will be of little importance. It is sufficient to convert each element into a byte sequence and write it in a file. The following methods deal with such tasks:
- SaveZipToFile — opens the indicated file and writes the generated archive's byte array.
- ToCharArray — creates the corresponding archive's byte structure. Generates the final ECDR structure.
- ZipElementsToArray — converts the element type CZipContent to a sequence of bytes.
The only difficulty is that every archive's element presented with type CZipContent is stored in two different files' parts, in the structures Local File Header and Central Directory. It is therefore necessary to use a special call method ZipElementsToArray, which depending on the ENUM_ZIP_PART modifier transferred to him provides a byte array of the Local File Header or Central Directory types.
Now, bearing this feature in mind we should have a good understanding of the contents of all three methods, whose source code is presented below:
//+------------------------------------------------------------------+ //| Return uchar array with ZIP elements | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| Generate ZIP archive as uchar array. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| Save ZIP archive in file zip_name | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
Archive's loading has few nuances to consider. Obviously, this is an operation inverse to saving. If when saving an archive, the elements of type CZipContent are converted to a byte sequence, then when loading an archive a byte sequence is converted to elements of type CZipContent. Again, due to the fact that each archive's element is stored in two different file parts - File Header and Local Central Directory, the CZipContent element cannot be created after just one data reading.
It is required to use an intermediate container class CSourceZip, where, first, necessary elements are added sequentially, and then the desired types of data — CZipFile or CZipFolder, are formed based on it. This is the reason, why these two classes have an additional constructor, that accepts a pointer to the element type CSourceZip as a reference parameter. This type of initialization, along with the CSourceZip class, has been created exclusively for official use of the CZip class, and is not recommended to be used in a clear form.
Three CZip class methods responsible for loading:
- LoadZipFromFile — opens an indicated file and reads its content into a byte array.
- LoadHeader — loads the Local File structure from the archive's byte array on the proposed address.
- LoadDirectory — loads the Central Directory structure from the archive's byte array on the proposed address.
Please see the source code of these methods below:
//+------------------------------------------------------------------+ //| Load Local Header with name file by offset array. | //| RETURN: | //| Return address after local header, name and zip content. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy local header uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //Copy header file name ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //Copy zip array ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+------------------------------------------------------------------+ //| Load Central Directory with name file by offset array. | //| RETURN: | //| Return adress after CD and name. | //| Return -1 if read failed. | //+------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy central directory uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //Copy directory file name ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+------------------------------------------------------------------+ //| Load ZIP archive from HDD file. | //+------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
Chapter 3. Examples of using CZip class, performance measurement
In the previous chapter we have analyzed the CZip class and the ZIP archive data format. Now that we know the archive's structure and the general principles of the CZip class, we can proceed with practical tasks linked with archiving. In this chapter we are going to analyze three different examples that best cover the full range of tasks in this class.
3.1. Creating ZIP archive with quotes for all selected symbols
The first task that is often required to be solved involves saving previously obtained data. Often data is obtained in the MetaTrader terminal. Such data can be a sequence of accumulated ticks and quotes of the OHLCV format. We will look into the situation, when quotes have to be saved in the special CSV-files, whose format will be as follows:
Date;Time;Open;High;Low;Close;Volume 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
This is a text data format. It is frequently used to transfer data between different statistical analysis systems. The format of text files, unfortunately, has a large redundancy of data storage, because each byte has a very limited number of characters used. Normally, these are punctuation, numbers, uppercase and lowercase letters of the alphabet. Furthermore, many values in this format frequently occur, for example, opening date or price normally is the same for a large data array. Therefore, this type of data compression has to be effective.
So let's write a script that downloads required data from the terminal. Its algorithm will be the following:
- The instruments featuring in the Market Watch window are sequentially selected.
- Each selected instrument has quotes requested for every 21 timeframe.
- Quotes of the selected timeframe are converted into a CSV line array.
- CSV line array is converted into a byte array.
- A ZIP file (CZipFile) containing a byte array of quotations is created and afterwards added to the archive.
- After creating all the quote files CZip is saved on a computer disk in the Quotes.zip file.
The script's source code performing these actions is provided below:
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // Create empty ZIP archive. //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| Create ZIP with quotes from market watch | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
Loading data may take considerable time, therefore only four symbols were selected in the Market Watch. In addition to that, we will load only the last one hundred known bars. It should also reduce the script execution time. After its performance in the MetaTrader shared files folder, the Quotes.zip archive appears. Its contents can be seen in any program that operates with archives, such as WinRAR:
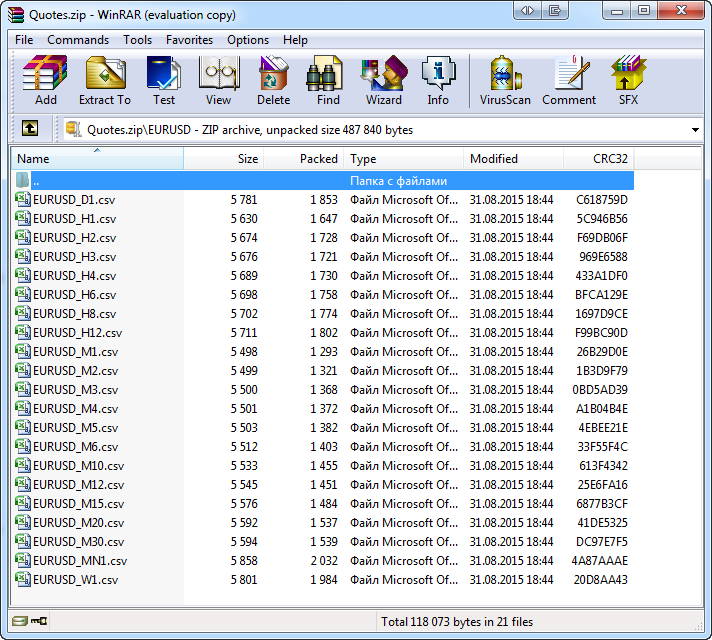
Fig. 11. Saved files with quotes viewed in the WinRAR archiver
The created archive is compressed three times in comparison to its original size. This information is provided by WinRAR:
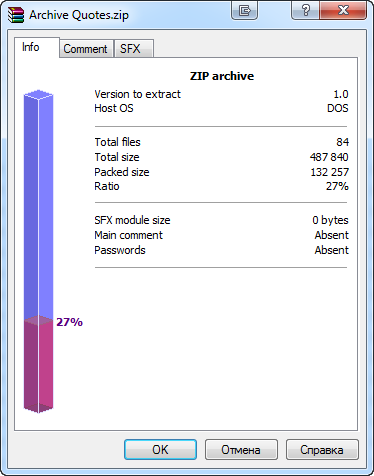
Fig. 12. Compression ratio of a generated archive in a WinRAR information window
These are good results of compression. However, an even better compression ratio could be achieved with heavy files that are few in number.
The example of a script that creates quotes and saves them in a ZIP archive is attached to this article under the ZipTask1.mq5 name and is located in the Scripts folder.
3.2. Downloading archive from a remote server, MQL5.com is used as an example
The next task we are going to study is network related. Our example will demonstrate, how you can download ZIP archives from remote servers. As an example, we will load the indicator called Alligator and located in the source code base Code Base on the following link https://www.mql5.com/en/code/9:
For each indicator, Expert Advisor, script or library that are published in the Code Base, there is an archive version, where all product's source codes are compressed in a single archive. We will download and unpack this archived version on a local computer. Before proceeding with this you must put authorization to access mql5.com: in the window Service --> Settings --> Expert Advisors it is required to write the following address "https://www.mql5.com" in the list of permitted servers.
The CZip class has its own method of downloading archives from the Internet resources. But instead of using it, let's write our own script, that performs the following loading:
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/en/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("Unable to download ZIP archive from "+mql_url+". Check request and permissions EA."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("Loaded bad ZIP archive. Check results array."); return; } printf("Archive successfully loaded. Total files: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
As you can see, the script's source code is quite simple. Initially, the WebRequest with the remote ZIP archive address is called. The WebRequest loads the archive's byte array into the obtained array zip_array, and then it is loaded to the CZip class using the CreateFromCharArray method. This method enables to create an archive directly from the byte sequence which is sometimes necessary for internal operation with archives.
In addition to the CreateFromCharArray method , CZip LoadZipFromUrl includes a special LoadZipFromUrl method to download archives from a web link. It operates approximately as our previous script. Here is the source code:
//+------------------------------------------------------------------+ //| Load ZIP archive from url | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
The result of this method's operation is the same: a ZIP archive will be created after some time, and its contents will be downloaded from a remote server.
Example of the script that downloads archives from the CodeBase is attached to this article under the name ZipTask2.mq5 and is located in the Scripts folder.
3.3. Compressing program's service data into RAM
Compressing the program's internal data into RAM is a nontrivial way to use archiving. This method can be used, when there is too much processed data in the memory. However, when using this approach the overall program's performance is decreased, as additional actions are required for archiving/unpacking service structures or data.
Let's imagine that the MQL-program has to store a collection of historical orders. Each order will be described by a special Order structure which will contain all of its properties: an identifier, order type, rendering time, volume, etc. We are going to describe this structure:
//+------------------------------------------------------------------+ //| History order | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // Ticket order datetime time_setup; // Time setup order ENUM_ORDER_TYPE type; // Type order ENUM_ORDER_STATE state; // State order datetime time_exp; // Expiration time datetime time_done; // Time done or canceled order long time_setup_msc; // Time setup in msc long time_done_msc; // Time done in msc ENUM_ORDER_TYPE_FILLING filling; // Type filling ENUM_ORDER_TYPE_TIME type_time; // Type living time ulong magic; // Magic of order ulong position_id; // ID position double vol_init; // Volume init double vol_curr; // Volume current double price_open; // Price open double sl; // Stop-Loss level double tp; // Take-Profit level double price_current; // Price current double price_stop_limit; // price stop limit string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| Init by ticket | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| Return comment of order | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| Return symbol of order | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| Set comment order | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| Set symbol order | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| Converter for uchar array. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| Convert order structure to uchar array | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
The operator's call sizeof shows that this structure takes 200 bytes. This way, the storage of historical order collection takes the number of bytes calculated by the formula: sizeof(Order) * number of historical orders. Consequently, for the collection that includes 1000 historical orders, we will require the following memory 200 * 1000 = 200 000 bytes or almost 200 KB. It is not a lot by today's standards, but in the case when the collection size will exceed tens of thousands of elements, the amount of used memory will become crucial.
Nevertheless, it is possible to develop a special container for storing these orders, which would allow to compress their content. This container, in addition to conventional methods of adding and deleting new elements Order, will also contain the methods Pack and Unpack that are compressing the contents of structures type Order. Here is the source code of the container:
//+------------------------------------------------------------------+ //| Container of orders. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| Add new order. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| Return order at index. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| Return total orders. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| Delete order by index. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| Return packed status. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| Return orders size. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
The idea is, that the user can add new elements to the container, and, if necessary, compress its contents directly in a computer's RAM. Let's see how it works. This is a demo script:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="Unpack size: "+(string)unpack_size+"bytes; "+ "Pack size: "+(string)pack_size+" bytes ("+per+" percent compressed. "+ "Pack execute msc: "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("First id ticket: "+(string)first.ticket); } } //+------------------------------------------------------------------+
The moment of the collection compression is highlighted in yellow. Launched at one of the accounts that has 858 historical orders, this script has provided the following results:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) Unpack size: 171600 bytes; Pack size: 1521 bytes (0.89 percent compressed. Pack execute microsec.: 2534
As you can see, the size of unpacked collection was 171,600 bytes. The size collection after the compression becomes only 1521 bytes, which means that the compression ratio has exceeded a hundred times! This is due to the fact that many structure fields contain similar data. Also many fields have empty values, under which, however, memory is allocated.
To ensure that the compression works correctly, you need to choose any order from the collection and print its properties. We have chosen the first order and its unique identifier. After compressing the order's identifier was displayed correctly:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) First id ticket: 10279280
The described algorithm in the case of referring to its collection unpacks previously packed data which reduces productivity. Therefore, data needs to be compressed only after its formation work is complete. For a better compression ratio all data is collected in a single array and then compressed. The reverse process applies for decompressing.
Interestingly, the compression of 858 elements takes only 2.5 milliseconds on a sufficiently powerful computer. Decompressing the same data is faster and takes about 0.9 milliseconds. Thus, one cycle of compressing/decompressing the array consisting of thousands of elements takes about 3.5-4.0 milliseconds. This helps to achieve memory saving in more than one hundred times. Such characteristics look impressive enough to use a ZIP compression for the organization of large data sets.
The example of a script that compresses data in a computer's memory is attached to this article under the name ZipTask3.mq5 and is located in the Scripts folder. Also, the Orders.mqh file located in the Include folder is required for its operation.
Chapter 4. Documentation for classes operating with ZIP archives
4.1. Documentation for CZipContent class
This chapter describes methods and enumerations used in classes operating with ZIP archive. The CZipContent class is not used directly at a user level, however, all its public methods are delegated by classes CZipFile and CZipFolder, therefore properties and methods described there also apply to those classes.
ZipType() method
The ZipType method returns a current element type in an archive. There are two types of items stored in an archive: a folder (directory) and a file. A folder's type is represented by the CZipDirectory class, a file's type - the CZipFile class. For more information about the ZIP archive types you can read in the section 2.1 of the current chapter: "Structure of compressed files inside an archive, CZipFile and CZipFolder classes".
ENUM_ZIP_TYPE ZipType(void);Returned value
It returns ENUM_ZIP_TYPE enumeration, which describes what type a current CZipContent copy belongs to.
Name method (void)
It returns a folder name or file name in an archive.string Name(void);
Returned value
File name or folder name.
Method Name(string name)
It sets a current folder or file name in an archive. It is used for changing a current folder or file name.
void Name(string name);
Parameters:
- [in] name — new folder or file name. The name must be unique and have no concurrency among other names in archive folders or files.
CreateDateTime method (datetime date_time)
It sets a new date of a folder or file change in an archive.
void CreateDateTime(datetime date_time);
Parameters:
- [in] date_time — date and time needed to set for a current folder or file.
Note:
Date and time are converted to the MS-DOS format, and are stored in the internal structures of the ZipLocalHeader and ZipCentralDirectory types. For more information about ways of converting and presenting this format please read the chapter 2.3 of this article: "Remembering MS-DOS. Time and date format in a ZIP archive".
CreateDateTime method (void)
It returns a date and time of changing a current folder or file.
datetime CreateDateTime(void);
Returned value
Date and time of changing a current folder or file.
CompressedSize()method
It returns size of compressed data in a file, always equals zero for directories.
uint CompressedSize(void);
Return value
Size of compressed data in bytes.
UncompressedSize() method
It returns size of original uncompressed data in a file, always equals zero for directories.
uint UncompressedSize(void);
Return value
Size of original data in bytes.
TotalSize() method
It returns total size of an archive's element. Each archive's file or directory, in addition to its name and content (for files), stores additional service structures, and their size is also included in a calculation of archive's total size.
int TotalSize(void);
Return value
Total size of a current archive element with additional service data.
FileNameLength() method
It returns name length of a directory or a file expressed in the amount of symbols used.
ushort FileNameLength(void);
Return value
Name length of a directory or a file expressed in the amount of symbols used.
UnpackOnDisk()method
It decompresses element's contents and stores them in a file with an element name on a computer's hard disk. If a directory is decompressed, then instead of a file a relevant folder is created.
bool UnpackOnDisk(string folder, int file_common);
Parameters
- [in] folder — name of a root folder where a current folder or file has to be compressed. If an element has to be unzipped without creating an archive folder, then this value has to remain empty and equal to "".
- [in] file_common — this modifier indicates in which section of a file system the MetaTrader program has to unzip an element. Please set this parameter equal to FILE_COMMON, if you wish to perform a decompression in a common file section of all MetaTrader 5 terminals.
Returned value
It returns true value, if a file or folder decompression on a hard disk was successful. It returns false value, if otherwise.
4.2. Documentation for CZipFile class
The CZipFile class is inherited from the CZipContent and is used for storing archive files. The CZipFile stores the file contents only in a compressed form. It means that when transferring a file for storage, it automatically compresses its contents. File decompressing also occurs automatically when calling the GetUnpackFile method. Apart from a number of the CZipContent supporting methods, the CZipFile also supports special methods operating with files. Please find a description of these methods below.
AddFile() method
Adds a file from a hard disk to a current CZipFile element. To add a file to the CZip archive type, you must first create a copy of the CZipFile class and specify its name and location. After the class sample is created, it will have to be added to the CZip class by calling the appropriate method. Actual compressing of the transfered contents occurs at the moment of adding them (calling this method).
bool AddFile(string full_path, int file_common);
Parameters
- [in] full_path — a full name of a file, including its path against the central file catalogue of MQL programmes.
- [in] file_common — this modifier indicates in which section of the MetaTrader program's file system it is required to decompress an element. Please set this parameter equal to FILE_COMMON, if you wish to perform a decompression in a common file section of all MetaTrader 5 terminals.
Returned value
It returns true value, if adding a file was successful. It returns false value, if otherwise.
AddFileArray() method
It adds a byte array of uchar type as the CZipFile content. This method is used in the case of a dynamic creation of file contents. The actual compressing of transferred contents occur at the moment they are added (call of this method).
bool AddFileArray(uchar& file_src[]);
Parameters
- [in] file_src — a byte array that has to be added.
Returned value
It returns true value, if adding a file was successful. It returns false value, if otherwise.
GetPackFile() method
It returns compressed file contents.
void GetPackFile(uchar& file_array[]);
Parameters
- [out] file_array — a byte array which requires to accept compressed file contents.
GetUnpackFile() method
It returns decompressed file contents. Contents are decompressed at the moment of a method call.
void GetUnpackFile(uchar& file_array[]);
Parameters
- [out] file_array — a byte array which requires to accept decompressed file contents.
4.3. Documentation for CZip class
The CZip class implements the main operation with ZIP type archives. The class is a generic ZIP archive which can have two types of ZIP elements added: elements that represent a folder (CZipDirectory), and elements for a ZIP file (CZipFile). Among other things, the CZip class allows loading already existing archives from both computer's hard disk, as well as in the form of a byte sequence.
ToCharArray() method
It converts contents of a ZIP archive into a byte sequence of uchar type.
void ToCharArray(uchar& zip_arch[]);
Parameters
- [out] zip_arch — byte array which requires to accept contents of a ZIP archive.
CreateFromCharArray() method
It loads a ZIP archive from a byte sequence.
bool CreateFromCharArray(uchar& zip_arch[]);
Parameters
- [out] zip_arch — a byte array from which it is required to load ZIP archive's contents.
Returned value
True value, if archive creation from a byte sequence was successful, and false value if otherwise.
SaveZipToFile() method
It saves a current ZIP archive with its content in the indicated file.
bool SaveZipToFile(string zip_name, int file_common);
Parameters
- [in] zip_name — a full name of a file including its path in regards to the central file directory of the MQL programs.
- [in]file_common - this modifier indicates in which section of the MetaTrader program's file system it is necessary to decompress an element. Please set this parameter equal to FILE_COMMON, if you wish to perform a decompression in a common file section of all MetaTrader 5 terminals.
Returned value
True value, if saving an archive into a file was successful, and false value, if otherwise.
LoadZipFromFile() method
It loads archive's contents on a computer's hard disk.
bool LoadZipFromFile(string full_path, int file_common);
Parameters
- [in] full_path — a full name of a file, including its path against the central file catalogue of MQL programmes.
- [in]file_common - this modifier indicates in which section of the MetaTrader program's file system it is necessary to decompress an element. Please set this parameter equal to FILE_COMMON, if you wish to perform a decompression in a common file section of all MetaTrader 5 terminals.
Returned value
True value, if an archive's loading from a file was successful, and false value, if otherwise.
LoadZipFromUrl()method
It loads archive contents on a web link url. For correct operation of this method it is required to set the permission to access the requested resource. For more details of this method read the section 3.2 of this article: "Downloading archive from a remote server, MQL5.com is used as an example."
bool LoadZipFromUrl(string url);
Parameters
- [in] url — reference to an archive.
UnpackZipArchive() method
Decompresses all files and directories of a current archive in a proposed directory.
bool UnpackZipArchive(string folder, int file_common);
Parameters
- [in] folder — folder where a current archive has to be decompressed. If there is no need to create an archive folder, you must pass a null value as a parameter "".
- [in] file_common — this modifier indicates in which section of the MetaTrader program's file system it is required to decompress an element. Please set this parameter equal to FILE_COMMON, if you wish to perform a decompression in a common file section of all MetaTrader 5 terminals.
Returned value
True value, if an archive's decompression is successful, and false value, if otherwise.
Size() method
Returns an archive's size in bytes.
int Size(void);Returned value
An archive's size in bytes.
TotalElements() method
Returns a number of elements in an archive. An archive's element can be either a directory or a compressed file.
int TotalElements(void);
Returned value
Number of elements in an archive.
AddFile() method
It adds a new ZIP file to a current archive. A file must be presented in the CZipFile form and created in advance before being added to an archive.
bool AddFile(CZipFile* file);Parameters
- [in] file — a ZIP file that has to be added to an archive.
Returned value
True value, if adding to an archive was successful, and false, if otherwise.
DeleteFile()method
It deletes the file type CZipFile with index from an archive.
bool DeleteFile(int index);
Parameters
- [in] index — a file's index that has to be deleted from an archive.
Returned value
True value, if deleting a file from an archive was successful. False value, if otherwise.
ElementAt() method
It obtains the element type CZipFile located at the index.
CZipContent* ElementAt(int index)const;
Parameters
- [in] index — a file index that has to be obtained from an archive.
Returned value
The CZipFile type element located at the index.
4.4. Structure of ENUM_ZIP_ERROR and receiving extended error information
In the process of working with classes CZip, CZipFile and CZipDirectory various errors may occur, such as an error when trying to access a non-existent file, etc. Most of the methods presented in these classes return the relevant flag of bool type that signals the transaction's success. In the case a negative value (false) returns, you can get additional information about the reasons of failure. The causes of failure can be standard, system errors, and specific errors that occur in the process of operation with ZIP archives. To transfer specific errors the mechanism of transmission of user errors is used with the SetUserError function. Codes of user errors are set by the enumeration ENUM_ZIP_ERROR:
Transferring ENUM_ZIP_ERROR
| Value | Description |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | A file transferred for compression, it is blank. |
| ZIP_ERROR_BAD_PACK_ZIP | Error of internal compressor/decompressor. |
| ZIP_ERROR_BAD_FORMAT_ZIP | A transferred ZIP file format doesn't correspond to a standard or is corrupted. |
| ZIP_ERROR_NAME_ALREADY_EXITS | The name of a file that a user wishes to save is already used in an archive.d |
| ZIP_ERROR_BAD_URL | Transferred link doesn't refer to a ZIP archive, or access to the specified web resource is forbidden by terminal settings. |
Upon receipt of a user error, you must explicitly bring it to the ENUM_ZIP_ERROR enumeration and treat it accordingly. An example of working with errors that arise in the course of operating with the archiving classes is presented below as a script:
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf("System error when loading archive. Error code: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("There was an error in archive processing at the point of loading: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
4.5. Description of files attached to this article
Below is a brief description of the files attached to this article:
- Zip\Zip.mqh — contains the main class for working with CZip archives.
- Zip\ZipContent.mqh — contains the core class CZipContent for basic classes of archive's elements: CZipFile and CZipDirectory.
- Zip\ZipFile.mqh — contains the class operating with ZIP archives.
- Zip\ZipDirectory.mqh — contains the class operating with archive's ZIP folders.
- Zip\ZipHeader.mqh — the file contains description of File Local Header, Central Directory and End Central Directory Record structures.
- Zip\ZipDefines.mqh — lists definitions, constants and error codes used with archiving classes.
- Dictionary.mqh — additional class that provides control of a unique file and directory names added to an archive. This class operation algorithm is described in the article "MQL5 Cookbook - implementing an associative array or a dictionary for quick data access".
All files listed in this article have to be placed with respect to the internal directory <terminal_data_folder>\MQL5\Include. To get started with classes you must include a Zip\Zip.mqh file in the project. As an example, we will describe a script for creating a ZIP archive and writing a text file with a "test" message in it:
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // Include all necessary classes for operation with ZIP archive //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // We create an empty ZIP archive uchar array[]; // We create an empty byte array StringToCharArray("test", array); // We covert a "test" message to a byte array CZipFile* file = new CZipFile("test.txt", array); // We create a new 'file' ZIP file based on the array named "test.txt" Zip.AddFile(file); // We add the created 'file' ZIP file to a ZIP archive Zip.SaveZipToFile("Test.zip", FILE_COMMON); // We save the ZIP archive named "Test.zip" on the disk. } //+------------------------------------------------------------------+
After its performance on the computer's hard disk a new ZIP archive named Test.zip, containing one text file with a word "test", will appear in the MetaTrader 5 central file directory.
| The archive attached to this article was created by means of the CZip archiver for MQL5 described here. |
|---|
Conclusion
We have thoroughly examined a ZIP archive structure and have created classes, that implement work with this type of archives. Such archiving format was developed in the late 80s of the last century, but that does not stop it from remaining the most popular data compression format. A set of these classes' data can offer invaluable assistance to a trading system developer. With its help you can efficiently store the collected data, whether it is a tick history or other trading information. Often various analytical data is also available in a compressed form. In this case, the ability to work with such information, even in a compressed form, may also be very useful.
The described classes hide many technical aspects of working with archives, providing simple and understandable operation methods at a user level, similar to those that users got accustomed with archiving programs: adding and extracting files from archives, creating new and loading already existing ones, including those posted on the remote third party servers. These capabilities have completely solved the majority of problems related to archiving and made programming in MetaTrader even easier and more functional.
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/1971
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

 Evaluation and selection of variables for machine learning models
Evaluation and selection of variables for machine learning models
 Error Handling and Logging in MQL5
Error Handling and Logging in MQL5
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
I came across an archive that CZip could not unpack. However, 7ZIP and the Windows archiver unpacked it without problems.
...
I can send the archive file to you in a private message if you are interested to understand it.Please send the archive file to me in a private message.
Please send me the archive file in a private message.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-01-18_BTCUSDT_ob500.data.zip
here in the archive body (not in the header) there is cdheader = 0x504b0102;
In the next by date file too. I think it is often found.
header = 0x504b0304; is in every file in the header, ie the first 4 characters.
But it also met and in the body of the archive, rarely. I'll look for it now.
Here https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2023-03-15_BTCUSDT_ob500.data.zip.
I think it is necessary to search for these headers only between the bodies of archives.
And there is also a link to a large file that can't be unpacked properly. I set the size for them to 0, and then the calling program understands by this 0 that there is an error and it is necessary to use another archiver.
Perhaps you can think of something better instead of 0.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip
I sorted out the files (unpacked) exceeding a certain volume (for different files from 1.7Gb to 2136507776 - i.e. almost to MAX_INT=2147483647, and arrays can't have more elements) and which are cut off at the output. It turned out that all of them were marked as erroneous at:
I.e. output value = 0.
But CZIP does not control this. I made zeroing of the output array size.
So in my functions I can determine with 100% guarantee that the file is successfully unpacked.
Before that I checked the correct end of JSON file }\r\n - but this solution is not universal and it seems that several files out of ~1000 were accidentally cut off by an intermediate line and were accepted as successfully decompressed, but the data in them is not complete.
New version of the function:
The new one is highlightedin yellow .
Perhaps the developers should also reset the array to zero, because the trimmed data is hardly needed by anyone. And may lead to hard-to-see errors.
And there is also a link to a large file that can't unpack properly. I set the size for them to 0, and then the calling program understands by this 0 that there is an error and it is necessary to use another archiver.
Perhaps you can think of something better instead of 0.
https://quote-saver.bycsi.com/orderbook/linear/BTCUSDT/2025-05-09_BTCUSDT_ob500.data.zip